YouTube is one of the most popular platforms for video sharing and social engagement, featuring millions of videos across various topics.
Such a complicated domain heavily relies on JavaScript, making its data extraction process appear complex and resource-intensive. However, we'll explain a few tricks for scraping YouTube directly in JSON. Let's get started!
Latest Youtube Scraper Code
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.
Why Scrape YouTube?
Web scraping YouTube enables valuable metadata extraction about videos, channels, and comments, empowering various use cases.
Competitive Analysis
Scraping YouTube enables content creators to extract engagement details about their competitors or target audience, enhancing decision-making and providing a competitive edge.
Sentiment Analysis
With the recent advancements in AI-related technology, building sentiment analysis models and RAG applications has become more accessible. Hence, a YouTube scraper for comments is considered a rich data streaming source for training such models.
SEO and Keyword Research
User preferences and search trends tend to change aggressively within a short period of time. Hence, scraping YouTube provides an effective solution to track trending topics and keywords.
For similar use cases related to scraping YouTube, refer to our introduction on web scraping use cases.
Prerequisites
Before we start building our YouTube scraping tool, let's explore the tools required and explain a few technical concepts we'll use.
Setup
To web scrape YouTube, we'll be using a few Python community packages:
- scrapfly-sdk: To request YouTube pages without getting blocked and retrieve their HTML sources.
- parsel: To parse the HTML documents using XPath and CSS selectors.
- jsonpath-ng: To automatically find deeply nested objects from JSON documents.
- loguru: To monitor and log our YouTube scraper through colorful outputs.
- asyncio: To execute the script code asynchronously, increasing its web scraping speed.
To install all the above packages, we can use the pip command below. :
pip install "scrapfly-sdk[all]" jsonpath-ng loguru
Note that asyncio comes pre-installed in Python, and parsel is part of the scrapfly-sdk and hence not explicitly installed.
Technical Concepts
In this guide, we'll utilize two web scraping idioms. Let's breifly explore them.
Hidden Data Scraping
Hidden data scraping involves extracting data from script tags found in HTML documents. These hidden data are often JSON, making them a great alternative to the common HTML parsing approach.
Hidden web data is often found on SPAs built using JavaScript. When a browser requests a page, it dynamically renders this hidden data into the DOM.
To further explain this approach, let's find hidden data on this mock product page. Press the F12 key and search the selector //script[@id='reviews-data']. Upon this, you will identify the below script tag:

We can see the review data exist in the above tag. Therefore, instead of parsing the related data, we can extract them as JSON from this tag!
How to Scrape Hidden Web Data
The visible HTML doesn't always represent the whole dataset available on the page. In this article, we'll be taking a look at scraping of hidden web data. What is it and how can we scrape it using Python?

Hidden API Scraping
Most modern web page applications rely on APIs to retrieve the required data and then render it into HTML. The hidden API scraping approach represents extracting the responses of these APIs or calling them directly.
To further illustrate this approach, let's explore a practical example using the below steps:
- Navigate to the example URL web-scraping.dev/testimonials
- Open the browser tools by pressing the
F12key - Head over the
Networktab and filter byFetch/XHRrequests - Load more reviews by scrolling down the page
- Upon following the above steps, you will identify the below captured request:

We can replicate the above XHR request to directly retrieve the pagination data instead of scrolling using a headless browser.
How to Scrape Hidden APIs
In this tutorial we'll be taking a look at scraping hidden APIs which are becoming more and more common in modern dynamic websites - what's the best way to scrape them?

How to Scrape YouTube Search?
Let's start implementing our YouTube web scraping code by a navigation feature. For this, we can utilize the search functionality. YouTube provides a powerful search system allowing users to find channels, videos, and shorts with a wide range of filtering options.
YouTube search data are retrieved using the private YouTube API. To locate it, submit a search query such as Python videos and observe the Fetch/XHR requests on the browser developer tools. You will identify the XHR request below:
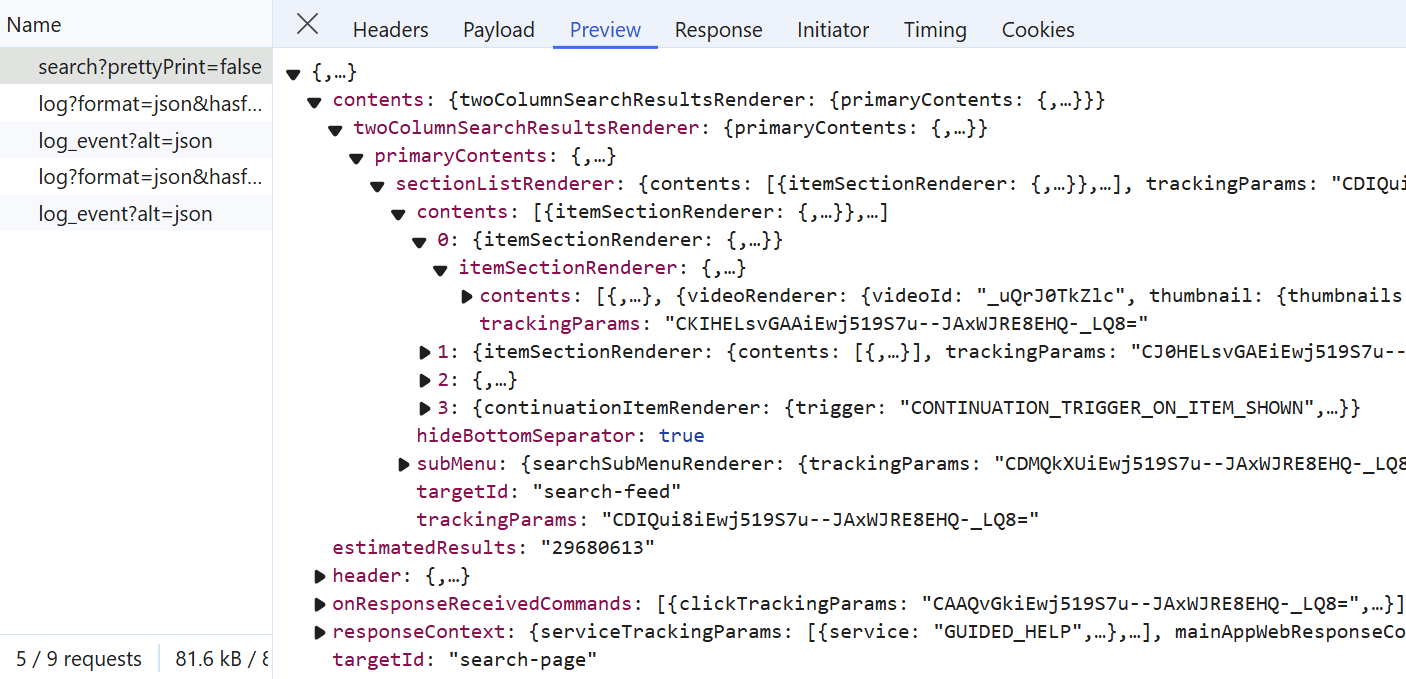
To scrape YouTube search directly in JSON, we can replicate the above XHR request. But first, we need to import the HTTP request details into Python using the cURL to Python tool or any HTTP client, such as Postman.
After importing the request details, let's write a utility function to create the required payload and request the YouTube API endpoint:
async def call_youtube_api(
base_url: str,
continuation_token: str = None,
search_query: str = None,
search_params: str = None,
) -> List[Dict]:
"""call the YouTube comments API for continuation or search queries"""
payload = {
"context": {
"client": {
"hl": "en",
"gl": "US",
"remoteHost": "",
"deviceMake": "",
"deviceModel": "",
"visitorData": "",
"userAgent": "",
"clientName": "WEB",
"clientVersion": "2.20241111.07.00",
"osName": "",
"osVersion": "",
"originalUrl": "",
"platform": "DESKTOP",
"clientFormFactor": "UNKNOWN_FORM_FACTOR",
"configInfo": {"appInstallData": ""},
"userInterfaceTheme": "USER_INTERFACE_THEME_DARK",
"timeZone": "",
"browserName": "",
"browserVersion": "",
"acceptHeader": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"deviceExperimentId": "",
"screenWidthPoints": None,
"screenHeightPoints": None,
"screenPixelDensity": None,
"screenDensityFloat": None,
"utcOffsetMinutes": None,
"connectionType": "CONN_CELLULAR_4G",
"memoryTotalKbytes": "8000000",
"mainAppWebInfo": {
"graftUrl": "",
"pwaInstallabilityStatus": "PWA_INSTALLABILITY_STATUS_UNKNOWN",
"webDisplayMode": "WEB_DISPLAY_MODE_BROWSER",
"isWebNativeShareAvailable": True,
},
},
"user": {"lockedSafetyMode": False},
"request": {
"useSsl": True,
"internalExperimentFlags": [],
"consistencyTokenJars": [],
},
"clickTracking": {"clickTrackingParams": ""},
}
}
if search_query is not None:
payload["query"] = search_query
payload["params"] = search_params
if continuation_token is not None:
payload["continuation"] = continuation_token
response = await SCRAPFLY.async_scrape(
ScrapeConfig(
base_url,
method="POST",
body=json.dumps(payload),
**BASE_CONFIG,
headers={"content-type": "application/json"},
)
)
return response
Above, we define a call_youtube_api function to replicate the hidden API call. It manipulates the base URL and the payload to support the different endpoints we'll cover in this guide.
Since we have the required HTTP details, let's use the call_youtube_api function to crawl YouTube search paged:
import json
import asyncio
import jmespath
from jsonpath_ng.ext import parse
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass youtube scraper blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
jp_all = lambda query, data: [match.value for match in parse(query).find(data)]
jp_first = lambda query, data: (
parse(query).find(data)[0].value if parse(query).find(data) else None
)
async def call_youtube_api(
base_url: str,
continuation_token: str = None,
search_query: str = None,
search_params: str = None,
) -> List[Dict]:
"""call the YouTube comments API for continuation or search queries"""
# previous function definition
def parse_search_response(response: ScrapeApiResponse) -> List[Dict]:
"""parse search results from the YouTube API response"""
results = []
data = json.loads(response.content)
search_boxes = jp_all("$..videoRenderer", data)
for i in search_boxes:
if "videoId" not in i:
continue
result = jmespath.search(
"""{
id: videoId,
title: title.runs[0].text,
description: detailedMetadataSnippets[0].snippetText.runs[0].text,
publishedTime: publishedTimeText.simpleText,
videoLength: lengthText.simpleText,
viewCount: viewCountText.simpleText,
videoBadges: badges[].metadataBadgeRenderer.label,
channelBadges: ownerBadges[].metadataBadgeRenderer.accessibilityData.label,
viewCount: shortViewCountText.simpleText,
videoThumbnails: thumbnail.thumbnails,
channelThumbnails: channelThumbnailSupportedRenderers.channelThumbnailWithLinkRenderer.thumbnail.thumbnails
}""",
i,
)
result["url"] = f"https://youtu.be/{result['id']}"
results.append(result)
return {
"videos": results,
"continuationToken": jp_first("$..continuationCommand.token", data),
}
async def scrape_search(
search_query: str, max_scrape_pages: int = None, search_params: str = None
) -> List[Dict]:
"""scrape search results from YouTube search query"""
cursor = 0
search_data = []
response = await call_youtube_api(
base_url="https://www.youtube.com/youtubei/v1/search?prettyPrint=false",
search_query=search_query,
search_params=search_params,
)
data = parse_search_response(response)
search_data.extend(data["videos"])
continuation_token = data["continuationToken"]
while continuation_token and (
cursor < max_scrape_pages if max_scrape_pages else True
):
cursor += 1
log.info(f"scraping search page with index {cursor}")
response = await call_youtube_api(
base_url="https://www.youtube.com/youtubei/v1/search?prettyPrint=false",
continuation_token=continuation_token, # use the continuation token after the first page
)
data = parse_search_response(response)
search_data.extend(data["videos"])
continuation_token = data["continuationToken"]
log.success(f"scraped {len(search_data)} video for the query {search_query}")
return search_data
Run the code
async def run():
search_data = await scrape_search(
search_query="python",
# params are the additional search query filter
# to get the search query param string, apply filters on the web app and copy the sp value
search_params="EgQIAxAB", # filter by video results only
max_scrape_pages=2
)
with open("search_results.json", "w") as f:
json.dump(search_data, f, indent=2)
if __name__ == "__main__":
asyncio.run(run())
Here, we define a crawling logic to scrape YouTube search results, which is wrapped under the scrape_search function. Let's break its execution flow down:
- A request is sent to the YouTube API to return the first page results.
- The
parse_search_responsefunction is used to extract the video data and the pagination parameters to scrape the next page. - The retrieved
continuationTokenfrom the first search page is used as a cursor pagination.
The above crawling process is repeated until the specified total pages to scrape is reached. Below is an example output of the results retrieved:
Example output
[
{
"id": "HCgJoSuICAk",
"title": "Why I Always Do This In Python",
"description": "This channel has grown big through the past couple of years, and one of the most frequent comments I get is: \"why do you ...",
"publishedTime": "5 days ago",
"videoLength": "6:10",
"viewCount": "13K views",
"videoBadges": [
"New",
"4K"
],
"channelBadges": [
"Verified"
],
"videoThumbnails": [
{
"url": "https://i.ytimg.com/vi/HCgJoSuICAk/hq720.jpg?sqp=-oaymwEcCOgCEMoBSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLDDqar63TPg1IRDBq2jJ0N1zlCXlw",
"width": 360,
"height": 202
},
{
"url": "https://i.ytimg.com/vi/HCgJoSuICAk/hq720.jpg?sqp=-oaymwEcCNAFEJQDSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLCMjnC306bclMUn9vJTbsX3M_0S7A",
"width": 720,
"height": 404
}
],
"channelThumbnails": [
{
"url": "https://yt3.ggpht.com/Youvw32wKJ5n4OJv3IXESEtEZnPdF49rXnpxKeLCpXB0yM3oda0ICnTGff00pWi1ZZm90x6AXw=s68-c-k-c0x00ffffff-no-rj",
"width": 68,
"height": 68
}
],
"url": "https://youtu.be/HCgJoSuICAk"
},
....
]
The extracted search results represent video data only. However, other data types can be selected by changing the used search_params value, which can be extracted from the search URL:

How to Scrape YouTube Channels?
In this section, we'll explore scraping YouTube channel metadata, which represents general information about the channel. The easiest way to retrieve this data on the browser is using the dedicated channel info view:
Upon clicking the above view, an XHR call is sent to retrieve the channel data as JSON, which later get rendered:

Let's replicate the above XHR call within our YouTube scraper to extact the channel metadata:
import json
import asyncio
import jmespath
from jsonpath_ng.ext import parse
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass youtube web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
jp_first = lambda query, data: (
parse(query).find(data)[0].value if parse(query).find(data) else None
)
async def call_youtube_api(
base_url: str,
continuation_token: str = None,
search_query: str = None,
search_params: str = None,
) -> List[Dict]:
"""call the YouTube comments API for continuation or search queries"""
# previous function definition
def parse_channel(response: ScrapeApiResponse) -> Dict:
"""parse channel metadata from YouTube channel page"""
_xhr_calls = response.scrape_result["browser_data"]["xhr_call"]
info_call = [c for c in _xhr_calls if "youtube.com/youtubei/v1/browse" in c["url"]]
data = json.loads(info_call[0]["response"]["body"]) if info_call else None
metadata = jp_first("$..aboutChannelViewModel", data)
links = []
if "links" in metadata:
for i in metadata["links"]:
i = i["channelExternalLinkViewModel"]
links.append(
{
"title": i["title"]["content"],
"url": i["link"]["content"],
"favicon": i["favicon"],
}
)
result = jmespath.search(
"""{
description: description,
url: displayCanonicalChannelUrl,
subscriberCount: subscriberCountText,
videoCount: videoCountText,
viewCount: viewCountText,
joinedDate: joinedDateText.content,
country: country
}""",
metadata,
)
result["links"] = links
return result
async def scrape_channel(channel_ids: List[str]) -> List[Dict]:
"""scrape channel metadata from YouTube channel pages"""
to_scrape = [
ScrapeConfig(
f"https://www.youtube.com/@{channel_id}",
proxy_pool="public_residential_pool",
**BASE_CONFIG,
render_js=True,
wait_for_selector="//yt-description-preview-view-model//button",
js_scenario=[
# click on the "show more" button to load the full description
{
"click": {
"selector": "//yt-description-preview-view-model//button",
"ignore_if_not_visible": False,
"timeout": 10000,
}
},
{
"wait_for_selector": {
"selector": "//yt-formatted-string[@title='About']",
"timeout": 10000,
}
},
],
)
for channel_id in channel_ids
]
data = []
log.info(f"scraping {len(to_scrape)} channels")
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
channel_data = parse_channel(response)
data.append(channel_data)
log.success(f"scraped {len(data)} cahnnel info")
return data
Run the code
async def run():
channel_metadata = await scrape_channel(
channel_ids=[
"scrapfly"
]
)
with open("channel_metadata.json", "w") as f:
json.dump(channel_metadata, f, indent=2)
if __name__ == "__main__":
asyncio.run(run())
Above, we rely on the XHR call responsible for fetching the channel metadata. However, instead of calling the API endpoint directly, we follow another approach explained in the below steps:
- Simulate a click action using the headless browser to trigger the metadata XHR call.
- Extract the XHR call response and parse it using the
parse_channelfunction.
Below is an example output of the results retrieved:
Example output
{
"description": "Experience seamless web scraping with our proven solution:\n\n- Automatic Proxy Rotation\n- Bypass anti-bot solutions\n- Managed Headless Browsers\n\nScale up your workload effortlessly without infrastructure concerns.\n\nEliminate the need for tedious tasks like proxy management, handling headless browsers, and bypassing blocking protection.\n\nOur state-of-the-art solution unifies the entire toolchain, enabling effortless scraping of any target.\n\nWe've assisted numerous clients across various industries, including real estate, e-commerce, human resources, competitive intelligence, news, stock market, and travel. Let us help you achieve your web scraping goals today.\n",
"url": "www.youtube.com/@scrapfly",
"subscriberCount": "46 subscribers",
"videoCount": "5 videos",
"viewCount": "1,739 views",
"joinedDate": "Joined Feb 27, 2023",
"country": "France",
"links": [
{
"title": "Scrapfly",
"url": "scrapfly.io",
"favicon": {
"sources": [
....
{
"url": "https://encrypted-tbn0.gstatic.com/favicon-tbn?q=tbn:ANd9GcSWG5xRzHtD8-SZbZPg8eIF8OwayBiVysCB1PvRfgiPtaXqMPAhNQc5y2KWf4hkWfVLRubHP87K5MYwXz1dIWQOKLgl0Ow4aEi5TWtyAVMIfUA",
"width": 256,
"height": 256
}
]
}
},
....
]
}
Scraping Channel Videos
Now that our YouTube scraper is able to extract channel metadata. Let's scrape channel video data. To do this, yet we'll rely on another hidden YouTube API. But first, let's inspect it by navigating to any YouTube channel and then scrolling down to load more video data:

To scrape the channel video data, let's replicate the above API call while manipulating its payload for pagination:
import re
import json
import asyncio
import jmespath
from jsonpath_ng.ext import parse
from typing import Dict, List, Literal
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your Scrapfly API key")
BASE_CONFIG = {
# bypass youtube scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
jp_all = lambda query, data: [match.value for match in parse(query).find(data)]
jp_first = lambda query, data: (
parse(query).find(data)[0].value if parse(query).find(data) else None
)
def parse_video_api(response: ScrapeApiResponse) -> Dict:
"""parse video data from YouTube API response"""
parsed_videos = []
data = json.loads(response.content)
continuation_tokens = jp_all("$..continuationCommand.token", data)
# first API response includes indexing data
videos = jp_all("$..reloadContinuationItemsCommand.continuationItems", data)
videos = videos[-1] if len(videos) > 1 else jp_first("$..continuationItems", data)
for i in videos:
if "richItemRenderer" not in i:
continue
result = jmespath.search(
"""{
videoId: videoId,
title: title.runs[0].text,
description: descriptionSnippet.runs[0].text,
publishedTime: publishedTimeText.simpleText,
lengthText: lengthText.simpleText,
viewCount: viewCountText.simpleText,
thumbnails: thumbnail.thumbnails
}""",
i["richItemRenderer"]["content"]["videoRenderer"],
)
result["url"] = f"https://youtu.be/{result['videoId']}"
parsed_videos.append(result)
return {
"videos": parsed_videos,
"continuationToken": continuation_tokens[-1] if continuation_tokens else None,
}
def parse_yt_initial_data(response: ScrapeApiResponse) -> Dict:
"""parse ytInitialData script from YouTube pages"""
selector = response.selector
data = selector.xpath("//script[contains(text(),'ytInitialData')]/text()").get()
data = json.loads(
re.search(r"var ytInitialData = ({.*});", data, re.DOTALL).group(1)
)
return data
async def scrape_channel_videos(
channel_id: str,
sort_by: Literal["Latest", "Popular", "Oldest"] = "Latest",
max_scrape_pages: int = None,
) -> List[Dict]:
"""scrape video metadata from YouTube channel page"""
# 1. extract the continuation token from the HTML to call the API
response = await SCRAPFLY.async_scrape(
ScrapeConfig(
f"https://www.youtube.com/@{channel_id}/videos",
proxy_pool="public_residential_pool",
**BASE_CONFIG,
)
)
initial_script_data = parse_yt_initial_data(response)
continuation_tokens = jp_all("$..chipCloudChipRenderer", initial_script_data)
# there are different continuation tokens based on the sorting order
continuation_token = [
i["navigationEndpoint"]["continuationCommand"]["token"]
for i in continuation_tokens
if i["text"]["simpleText"] == sort_by
][0]
# 2. call the API to get the video data
videos = []
cursor = 0
while continuation_token and (
cursor < max_scrape_pages if max_scrape_pages else True
):
cursor += 1
log.info(f"scraping video page with index {cursor}")
try:
response = await call_youtube_api(
base_url="https://www.youtube.com/youtubei/v1/browse?key=yt_web",
continuation_token=continuation_token,
)
except NameError:
log.error("call_youtube_api isn't defined. You can define it from the ealier snippet.")
break
data = parse_video_api(response)
videos.extend(data["videos"])
continuation_token = data["continuationToken"]
log.success(f"scraped {len(videos)} video for the channel {channel_id}")
return videos
Run the code
async def run():
channel_videos = await scrape_channel_videos(
channel_id="statquest", sort_by="Latest", max_scrape_pages=2
)
with open("channel_videos.json", "w", encoding="utf-8") as file:
json.dump(channel_videos, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
The above snippet's code may seem comprehensive. However, if we go through its execution flow, we can easily grasp it:
- A request is sent to the URL pattern for channel videos:
youtube.com/@<channel_id>/videosto get the HTML response of the page containing the first batch of videos. - The HTML retrieved is parsed using the
parse_yt_initial_datafunction to get thecontinuation_tokens, which will be used with hidden API. - A
whileloop is created to keep paginating the results until either the maximum number of results or the maximum number of pages to scrape is reached. - The hidden YouTube API for the channel video data is requested using the
call_youtube_apifunction and its response is refined with theparse_video_apifunction.
Below is an example output of the results extracted by the above YouTube scraping code:
Example output
[
{
"videoId": "qPN_XZcJf_s",
"title": "Reinforcement Learning with Human Feedback (RLHF), Clearly Explained!!!",
"description": "Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire Wikipedia. However, this training alone fails to teach the models how...",
"publishedTime": "1 month ago",
"lengthText": "18:02",
"viewCount": "16,768 views",
"thumbnails": [
{
"url": "https://i.ytimg.com/vi/qPN_XZcJf_s/hqdefault.jpg?sqp=-oaymwEmCKgBEF5IWvKriqkDGQgBFQAAiEIYAdgBAeIBCggYEAIYBjgBQAE=&rs=AOn4CLDAK3Xw9Hx1bJ5O-gBxKUlKaenEdA",
"width": 168,
"height": 94
},
....
],
"url": "https://youtu.be/qPN_XZcJf_s"
},
....
]
So far, we have been able to crawl YouTube for video data from channels and search pages. Next, let's scrape the YouTube video pages themselves!
How to Scrape YouTube Videos?
The video metadata are saved into the HTML as JSON datasets within script tags. To identify them, search for the XPath selector //script[contains(text(),'ytInitialPlayerResponse')]/text() from the browser developer tools:

As illustrated in the above image, the script tag contains the full video metadata. Let's update our YouTube scraper to extract them:
import re
import json
import asyncio
from jsonpath_ng.ext import parse
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your Scrapfly API key")
BASE_CONFIG = {
# bypass youtube.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
jp_all = lambda query, data: [match.value for match in parse(query).find(data)]
jp_first = lambda query, data: (
parse(query).find(data)[0].value if parse(query).find(data) else None
)
def convert_to_number(value):
if value is None:
return None
value = value.strip().upper()
if value.endswith("K"):
return int(float(value[:-1]) * 1_000)
elif value.endswith("M"):
return int(float(value[:-1]) * 1_000_000)
else:
return int(float(value))
def parse_video_details(response: ScrapeApiResponse) -> Dict:
"""parse video metadata from YouTube video page"""
selector = response.selector
video_details = selector.xpath(
"//script[contains(text(),'ytInitialPlayerResponse')]/text()"
).get()
video_details = json.loads(video_details.split(" = ")[1].split(";var")[0]).get(
"videoDetails"
)
return video_details
def parse_yt_initial_data(response: ScrapeApiResponse) -> Dict:
"""parse ytInitialData script from YouTube pages"""
selector = response.selector
data = selector.xpath("//script[contains(text(),'ytInitialData')]/text()").get()
data = json.loads(
re.search(r"var ytInitialData = ({.*});", data, re.DOTALL).group(1)
)
return data
def parse_video(response: ScrapeApiResponse) -> Dict:
"""parse video metadata from YouTube video page"""
video_details = parse_video_details(response)
content_details = parse_yt_initial_data(response)
likes = [
i["title"]
for i in jp_all("$..buttonViewModel", content_details)
if "iconName" in i and i["iconName"] == "LIKE"
]
channel_id = jp_first(
"$..channelEndpoint.browseEndpoint.canonicalBaseUrl", content_details
)
verified = jp_all(
"$..videoOwnerRenderer..badges[0].metadataBadgeRenderer", content_details
)
result = {
"video": {
"videoId": video_details.get("videoId"),
"title": video_details.get("title"),
"publishingDate": jp_first("$..dateText.simpleText", content_details),
"lengthSeconds": convert_to_number(video_details.get("lengthSeconds")),
"keywords": video_details.get("keywords"),
"description": video_details.get("shortDescription"),
"thumbnail": video_details.get("thumbnail").get("thumbnails"),
"stats": {
"viewCount": convert_to_number(video_details.get("viewCount")),
"likeCount": convert_to_number(likes[0]) if likes else None,
"commentCount": convert_to_number(
jp_first("$..contextualInfo.runs[0].text", content_details)
),
},
},
"channel": {
"name": video_details.get("author"),
"identifierId": video_details.get("channelId"),
"id": channel_id.replace("/", "") if channel_id else None,
"verified": (
True
if verified and [i for i in verified if i["tooltip"] == "Verified"][0]
else False
),
"channelUrl": (
f"https://www.youtube.com{channel_id}" if channel_id else None
),
"subscriberCount": jp_first(
"$..subscriberCountText.simpleText", content_details
),
"thumbnails": jp_first(
"$..engagementPanelSectionListRenderer..channelThumbnail.thumbnails",
content_details,
),
},
"commentContinuationToken": jp_first(
"$..continuationCommand.token", content_details
),
}
return result
async def scrape_video(ids: List[str]) -> List[Dict]:
"""scrape video metadata from YouTube videos"""
data = []
to_scrape = [
ScrapeConfig(f"https://youtu.be/{video_id}", proxy_pool="public_residential_pool", **BASE_CONFIG)
for video_id in ids
]
log.info(f"scraping {len(to_scrape)} video metadata from video pages")
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
post_data = parse_video(response)
data.append(post_data)
log.success(f"scraped {len(data)} video metadata from video pages")
return data
Run the code
async def run():
video_data = await scrape_video(
ids = [
"1Y-XvvWlyzk",
"muo6I9XY8K4",
"y7FbFJ4jOW8"
]
)
with open("videos.json", "w", encoding="utf-8") as file:
json.dump(video_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
In the above code, we define a scrape_video function that takes a list of video IDs as input, adds them to a scraping list, and concurrently requests the video page URLs. Then, we utilize the parse_video function to extract the video and channel metadata from the HTML using the hidden data extraction approach in both functions parse_video_details and parse_yt_initial_data.
Here's what the extracted video data looks like:
Example output
[
{
"video": {
"videoId": "y7FbFJ4jOW8",
"title": "Intro to Web Scraping using ScrapFly SDK and Python",
"publishingDate": "Jul 17, 2024",
"lengthSeconds": 994,
"keywords": null,
"description": "https://scrapfly.io/ \nhttps://scrapfly.io/docs/sdk/python\n\nThe code used in the video:\nhttps://github.com/scrapfly/sdk-demo\n\nFor more web scraping tutorials, see our blog:\n• Scraping with Python and BeautifulSoup\nhttps://scrapfly.io/blog/web-scraping-with-python-beautifulsoup/\n• Parsing HTML with XPath\nhttps://scrapfly.io/blog/parsing-html-with-xpath/\n• Parsing HTML with CSS selectors\nhttps://scrapfly.io/blog/parsing-html-with-css/\n\nSections:\n00:00 introduction\n00:14 setup \n00:25 Use Overview\n01:25 HTML parser\n01:55 Cache feature\n02:09 Debug feature\n02:26 Request options\n03:00 Anti Scraping Blocking bypass\n03:24 Proxies\n03:50 Cloud Web Browsers\n04:31 Browser Control\n04:50 Extraction API\n08:09 Screenshot API\n10:18 Example Project Overview\n10:46 Setup\n11:32 Scraping Yelp Business Pages\n12:23 Parsing Business Pages\n13:26 Example Scrape Run\n14:04 Scraping Yelp Search\n14:49 Parsing Search Pages\n15:22 Example Scrape Run\n15:48 Summary",
"thumbnail": [
{
"url": "https://i.ytimg.com/vi/y7FbFJ4jOW8/hqdefault.jpg?sqp=-oaymwEmCKgBEF5IWvKriqkDGQgBFQAAiEIYAdgBAeIBCggYEAIYBjgBQAE=&rs=AOn4CLAgJcecyotc-ZtaflbigMDrbCBdIg",
"width": 168,
"height": 94
},
....
],
"stats": {
"viewCount": 2032,
"likeCount": 24,
"commentCount": 2
}
},
"channel": {
"name": "Scrapfly",
"identifierId": "UCoX3U_dywuQf_KbLhWoUCmw",
"id": "@scrapfly",
"verified": false,
"channelUrl": "https://www.youtube.com/@scrapfly",
"subscriberCount": "72 subscribers",
"thumbnails": [
{
"url": "https://yt3.ggpht.com/vZaW8h45pjSWX0AEif82ImzhIhb5vMk9fz3j3S8PNaGhXr5F4qoHp9veDrL8bmCFr25D__fq=s88-c-k-c0x00ffffff-no-rj"
}
]
},
"commentContinuationToken": "Eg0SC3k3RmJGSjRqT1c4GAYyJSIRIgt5N0ZiRko0ak9XODAAeAJCEGNvbW1lbnRzLXNlY3Rpb24%3D"
}
]
In the JSON dataset above, our YouTube scraper has successfully extracted the metadata for both the video and related channels. Additionally, we have the key commentContinuationToken that we'll use for the video comment scraping. Let's see it in action in the following section!
Scraping Video Comments
To scrape YouTube comments, we'll use the hidden API scraping approach. But first, let's identify the comments API. To do this, go to any YouTube video page and scroll down the comments section to load more comments while having the browser developer tools open. You will find a similar XHR call captured:

To scrape video comments, we'll replicate the above XHR call:
import re
import json
import asyncio
import jmespath
from jsonpath_ng.ext import parse
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your Scrapfly API key")
BASE_CONFIG = {
# bypass youtube.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
jp_all = lambda query, data: [match.value for match in parse(query).find(data)]
jp_first = lambda query, data: (
parse(query).find(data)[0].value if parse(query).find(data) else None
)
def parse_comments_api(response: ScrapeApiResponse) -> List[Dict]:
"""parse comments API response for comment data"""
parsed_comments = []
data = json.loads(response.content)
continuation_tokens = jp_all("$..continuationCommand.token", data)
comments = jp_all("$..commentEntityPayload", data)
for comment in comments:
result = jmespath.search(
"""{
comment: {
id: properties.commentId,
text: properties.content.content
publishedTime: properties.publishedTime
},
author: {
id: author.channelId,
displayName: author.displayName,
avatarThumbnail: author.avatarThumbnailUrl,
isVerified: author.isVerified,
isCurrentUser: author.isVerified,
isCreator: author.isVerified
},
stats: {
likeCount: toolbar.likeCountLiked,
replyCount: toolbar.replyCount
}
}""",
comment,
)
parsed_comments.append(result)
return {
"comments": parsed_comments,
"continuationToken": continuation_tokens[-1] if continuation_tokens else None,
}
async def scrape_comments(video_id: str, max_scrape_pages=None) -> List[Dict]:
"""scraper comments from a YouTube video"""
comments = []
cursor = 0
log.info(f"scraping video page for the comments continuation token")
try:
video_data = await scrape_video([video_id])
except NameError:
log.error("scrape_video function is not defined. You can define it from the ealier snippet.")
return
continuation_token = video_data[0].get("commentContinuationToken")
while continuation_token and (
cursor < max_scrape_pages if max_scrape_pages else True
):
cursor += 1
log.info(f"scraping comments page with index {cursor}")
try:
response = await call_youtube_api(
base_url="https://www.youtube.com/youtubei/v1/next?prettyPrint=false",
continuation_token=continuation_token,
)
except NameError:
log.error("call_youtube_api function is not defined. You can define it from the search scraping section.")
return
data = parse_comments_api(response)
comments.extend(data["comments"])
continuation_token = data["continuationToken"]
log.success(f"scraped {len(comments)} comments for the video {video_id}")
return comments
In order to request the hidden comments API, we first have to obtain the commentContinuationToken. Therefore, we start our comment scraper by extracting using the scrape_video function we defined earlier. Then, we use the obtained token to call the YouTube API while using the parse_comments_api function to parse the API responses.
Below is an example output of the data extracted:
Example output
[
{
"comment": {
"id": "UgxdoHZn3pilg4Sa9Pp4AaABAg",
"text": "NOTE 1: The StatQuest PCA Study Guide is available! https://app.gumroad.com/statquest\nNOTE 2: A lot of people ask about how, in 3-D, the 3rd PC can be perpendicular to both PC1 and PC2. Regardless of the number of dimensions, all principal components are perpendicular to each other. If that sounds insane, consider a 2-d graph, the x and y axes are perpendicular to each other. Now consider a 3-d graph, the x, y and z axes are all perpendicular to each other. Now consider a 4-d graph..... etc.\nNOTE 3: A lot of people ask about the covariance matrix. There are two ways to do PCA: 1) The old way, which applies eigen-decomposition to the covariance matrix and 2) The new way, which applies singular value decomposition to the raw data. This video describes the new way, which is preferred because, from a computational stand point, it is more stable.\nNOTE 4: A lot of people ask how fitting this line is different from Linear Regression. In Linear Regression we are trying to maintain a relationship between a value on the x-axis, and the value it would predict on the y-axis. In other words, the x-axis is used to predict values on the y-axis. This is why we use the vertical distance to measure error - because that tells us how far off our prediction is for the true value. In PCA, no such relationship exists, so we minimize the perpendicular distances between the data and the line.\nNOTE 5: A lot of people wonder why we divide the sums of the squares by n-1 instead of n. To be honest, in this context, you can probably use 'n' or 'n-1'. 'n-1' is traditionally used because it prevents us from underestimating the variance - in other words, it's related to how statistics are calculated. If you want to learn more, see: https://youtu.be/vikkiwjQqfU https://youtu.be/SzZ6GpcfoQY and https://youtu.be/sHRBg6BhKjI (the last video specifically addresses the 'n' vs 'n-1' thing, but the first two give background that you need to understand first).\n\nSupport StatQuest by buying my books The StatQuest Illustrated Guide to Machine Learning, The StatQuest Illustrated Guide to Neural Networks and AI, or a Study Guide or Merch!!! https://statquest.org/statquest-store/",
"publishedTime": "5 years ago (edited)"
},
"author": {
"id": "UCtYLUTtgS3k1Fg4y5tAhLbw",
"displayName": "@statquest",
"avatarThumbnail": "https://yt3.ggpht.com/Lzc9YzCKTkcA1My5A5pbsqaEtOoGc0ncWpCJiOQs2-0win3Tjf5XxmDFEYUiVM9jOTuhMjGs=s88-c-k-c0x00ffffff-no-rj",
"isVerified": true,
"isCurrentUser": true,
"isCreator": true
},
"stats": {
"likeCount": "145",
"replyCount": "12"
}
},
....
]
Scraping YouTube Shorts
YouTube shorts have a different UI and media player than regular YouTube videos. However, both of them can be scraped in the same way using hidden data extraction from script tags.
That means we can reuse our previous parsing logic used while scraping YouTube videos:
import json
import asyncio
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your Scrapfly API key")
BASE_CONFIG = {
# bypass youtube.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
def parse_video_details(response: ScrapeApiResponse) -> Dict:
"""parse video metadata from YouTube video page"""
selector = response.selector
video_details = selector.xpath(
"//script[contains(text(),'ytInitialPlayerResponse')]/text()"
).get()
video_details = json.loads(video_details.split(" = ")[1].split(";var")[0]).get(
"videoDetails"
)
return video_details
async def scrape_shorts(ids: List[str]) -> List[Dict]:
"""scrape metadata from YouTube shorts"""
to_scrape = [
ScrapeConfig(
f"https://youtu.be/{short_id}",
proxy_pool="public_residential_pool",
**BASE_CONFIG,
)
for short_id in ids
]
data = []
log.info(f"scraping {len(to_scrape)} short video metadata from video pages")
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
post_data = parse_video_details(response)
post_data["thumbnail"] = post_data["thumbnail"]["thumbnails"]
data.append(post_data)
log.success(f"scraped {len(data)} video metadata from short pages")
return data
Run the code
async def run():
shorts_data = await scrape_shorts(
ids=[
"rZ2qqtNPSBk"
]
)
with open("shorts.json", "w", encoding="utf-8") as file:
json.dump(shorts_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
The above YouTube scraper snippet is fairly straightforward. We request the shorts' URLs and then parse their data from the script tag using the parse_video_details function.
Below is an example output of the results we got:
Example output
[
{
"videoId": "rZ2qqtNPSBk",
"title": "How to find background requests a website makes",
"lengthSeconds": "44",
"channelId": "UCoX3U_dywuQf_KbLhWoUCmw",
"isOwnerViewing": false,
"shortDescription": "Every website can make background request to download more data and here's how to use chrome developer tools to find this. #webdevelopment #webdev #webscraping #security",
"isCrawlable": false,
"thumbnail": [
{
"url": "https://i.ytimg.com/vi/rZ2qqtNPSBk/hq2.jpg?sqp=-oaymwFACKgBEF5IWvKriqkDMwgBFQAAiEIYANgBAeIBCggYEAIYBjgBQAHwAQH4AbYIgAKAD4oCDAgAEAEYTCBaKGUwDw==&rs=AOn4CLC6GXzeWJmX1-m1SioWIHI1f2sy2Q",
"width": 168,
"height": 94
},
....
],
"allowRatings": true,
"viewCount": "8",
"author": "Scrapfly",
"isPrivate": false,
"isUnpluggedCorpus": false,
"isLiveContent": false
}
]
Powering Up With ScrapFly
We have explored scraping different parts of YouTube by either requesting the HTML web pages or calling hidden APIs. That being said, on such a highly protected domain like YouTube, attempting to scale our scraper will lead us to getting blocked. YouTube can detect us as sending a large number of requests in a short time window, hence getting our IP address blocked

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
Here's how to use to bypass YouTube web scraping blocking. All we have to do is enable the anti-scraping protection bypass (asp=True) and select a proxy country:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some youtube.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="web page URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
proxy_pool="public_residential_pool", # select a proxy pool
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']
FAQ
To wrap up this guide, let's have a look at a few commonly asked questions about web scraping YouTube.
Are there public APIs for YouTube?
Yes, public YouTube APIs are available through the Google developer console. It covers various data sources, including channels, videos, and search functionality. For more details, refer to the official YouTube API documentation.
What are the limitations of YouTube API?
Google provides public access to YouTube APIs. However, such access is limited by a daily quota system. Such a system can be a limiting factor for scaled YouTube scrapers.
Can I scrape YouTube for sentiment analysis?
Additionally, obtaining the necessary API keys involves setting up a new project on the Google Developer Console, which can be complicated for those who are new to the process and the platform.
Yes, scraping YouTube comments allows the extraction of large amounts of text data, which can be used to run sentiment analysis campaigns on given topics. For more, refer to our guide on using web scraping for sentiment analysis.
Web Scraping YouTube Summary
In this guide, we explained how to scrape YouTube through a step-by-step guide. We were able to extract data from YouTube from various resources:
- Search pages for video search results
- Channel pages for channel and video metadata
- Video, shorts, and comment data
Instead of parsing the HTML using XPath and CSS selectors, we developed our YouTube scraper using two common approaches. We used YouTube's hidden APIs and the hidden data parsing approach to extract YouTube data directly as JSON.