In this web scraping tutorial, we'll explain how to scrape yelp.com in Python. We'll start by reverse engineering the search functionality so we can find businesses. Then, we'll scrape and parse the business data and reviews. Finally, we'll explore avoiding Yelp web scraping blocking when scraping at scale.
Key Takeaways
Learn to scrape Yelp.com business data and reviews using Python with httpx and parsel, handling search functionality and anti-bot measures for comprehensive business directory extraction.
- Use Yelp's search API endpoints to access business listings and review data without JavaScript rendering
- Parse JSON responses with jmespath to extract structured business and review information efficiently
- Handle Yelp's anti-scraping measures with realistic headers, user agents, and request spacing
- Extract comprehensive business data including ratings, reviews, addresses, and contact information
- Implement proper error handling and retry logic for rate limiting and temporary blocking scenarios
- Use ScrapFly SDK for automated Yelp scraping with anti-blocking and geographic targeting features
Latest Yelp.com Scraper Code
Why Scrape Yelp?
Yelp is one of the largest websites for business directories. It includes various businesses in different categories, such as restaurants and local service providers. Therefore, scraping Yelp data can be beneficial for researchers, allowing them to understand market trends and analyze competitors.
Yelp also includes thousands of detailed reviews. Business owners can scrape Yelp reviews and use them with machine learning techniques to analyze users' opinions and evaluate their users' experience.
Moreover, if you are an individual explorer for Yelp, navigating tons of reviews can be tedious and time-consuming. Instead, scraping Yelp can retrieve thousands of data quickly with a more precise search.
Project Setup
To scrape Yelp, we'll use a few Python community packages:
- httpx - An HTTP client we'll use to request Yelp pages.
- parsel - HTML parsing library we'll use for parsing the HTML using selectors like XPath and CSS.
- asyncio - For running our Yelp scraper code asynchronously, increasing our web scraping speed.
- JMESPath - For parsing and refining the JSON datasets to execlude the unnecessary data.
Since asyncio comes pre-installed in Python, we'll only have to install the other libraries using the following pip command:
$ pip install httpx parsel jmespath
Alternatively, feel free to swap httpx out with any other HTTP client package such as requests, as we'll only need basic HTTP functions, which can be found among differet HTTP clients. As for parsel, another great alternative is beautifulsoup package.
Discovering Yelp Company Pages
Before we start scraping Yelp, let's find a way to discover businesses on the website. If we look at Yelp's Yelp's robots.txt instructions, we can see that it doesn't provide sitemaps or any directory pages. So, to navigate the website, we have to reverse engineer their search functionality and replicate it within our scraper.
How to Scrape Yelp Search
To start, let's submit a search query and see the result we get:

We can see that upon entering search details, we get redirected to a URL with the following search keywords:
https://www.yelp.com/search?find_desc=plumbers&find_loc=Toronto%2C+Ontario%2C+Canada&ns=1&start=220
We'll use the above URL parameters to navigate search pages. But before that, let's parse the search result data itself. For this, we'll extract the web page hidden web data.
To locate the hidden web data on search pages, follow below steps:
- Open the browser developer tools by clicking the
F12key - Search for the
scripttag with the tagdata-id='react-root-props']
Upon following the above steps, we'll find the target script tag containing the search data in JSON:

To scrape search pages, we'll select the script tag containing the data and parse its JSON data:
import asyncio
import json
import httpx
async def _search_yelp_page(keyword: str, location: str, session: httpx.AsyncClient, offset=0):
"""scrape single page of yelp search"""
# final url example:
# https://www.yelp.com/search/snippet?find_desc=plumbers&find_loc=Toronto%2C+Ontario%2C+Canada&ns=1&start=210&parent_request_id=54233ce74d09d270&request_origin=user
resp = await session.get(
"https://www.yelp.com/search/snippet",
params={
"find_desc": keyword,
"find_loc": location,
"start": offset,
"parent_request": "",
"ns": 1,
"request_origin": "user"
}
)
assert resp.status_code == 200, "request is blocked, refer to bypassing Yelp scraping blocking section"
return json.loads(resp.text)
🤖 Yelp is known for its high blocking rate and it is very likely to get blocked while running the code tabs. To avoid blocking, run the ScrapFly code version, which can be found on the full Yelp scraper code on GitHub.
In the above code, we replicate the request used for searching. Next, let's define hte logic responsible for selecting the script tag containing the hidden data and parse it:
def parse_search(response: Response):
"""parse listing data from the search XHR data"""
search_data = []
selector = Selector(text=response.text)
script = selector.xpath("//script[@data-id='react-root-props']/text()").get()
data = json.loads(script.split("react_root_props = ")[-1].rsplit(";", 1)[0])
for item in data["legacyProps"]["searchAppProps"]["searchPageProps"]["mainContentComponentsListProps"]:
# filter search data cards
if "bizId" in item.keys():
search_data.append(item)
# filter the max results count
elif "totalResults" in item["props"]:
total_results = item["props"]["totalResults"]
return {"search_data": search_data, "total_results": total_results}
Here, we get rid of unnecessary metadata, such as ads and tracking data to keep the actual search data. Finally, let's wrap up this part of our Yelp scraper with an iteration logic to scrape all the available search pages. We'll start by scraping the first search page and then scraping the remaining pages concurrently:
import json
import math
import asyncio
from parsel import Selector
from typing import List, Dict
from urllib.parse import urlencode
from httpx import AsyncClient, Response
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Cookie": "intl_splash=false"
},
follow_redirects=True
)
def parse_search(response: Response) -> List[Dict]:
"""parse listing data from the search XHR data"""
search_data = []
selector = Selector(text=response.text)
script = selector.xpath("//script[@data-id='react-root-props']/text()").get()
data = json.loads(script.split("react_root_props = ")[-1].rsplit(";", 1)[0])
for item in data["legacyProps"]["searchAppProps"]["searchPageProps"]["mainContentComponentsListProps"]:
# filter search data cards
if "bizId" in item.keys():
search_data.append(item)
# filter the max results count
elif "totalResults" in item["props"]:
total_results = item["props"]["totalResults"]
return {"search_data": search_data, "total_results": total_results}
async def scrape_search(keyword: str, location: str, max_pages: int = None):
"""scrape single page of yelp search"""
def make_search_url(offset):
base_url = "https://www.yelp.com/search?"
params = {"find_desc": keyword, "find_loc": location, "start": offset}
return base_url + urlencode(params)
# final url example:
# https://www.yelp.com/search?find_desc=plumbers&find_loc=Seattle%2C+WA&start=1
print("scraping the first search page")
first_page = await client.get(make_search_url(1))
data = parse_search(first_page)
search_data = data["search_data"]
total_results = data["total_results"]
# find total page count to scrape
total_pages = math.ceil(total_results / 10) # each page contains 10 results
if max_pages and max_pages < total_pages:
total_pages = max_pages
# add the remaining pages to a scraping list and scrape them concurrently
print(f"scraping search pagination, remaining ({total_pages - 1}) more pages")
other_pages = [
client(make_search_url(offset))
for offset in range(11, total_pages * 10, 10)
]
for response in asyncio.as_completed(other_pages):
response = await response
assert response.status_code == 200, "request is blocked"
search_data.extend(parse_search(response)["search_data"])
print(f"scraped {len(search_data)} listings from search pages")
return search_data
Run the code
async def run():
search_data = await scrape_search(
keyword="plumbers", location="Seattle, WA", max_pages=3
)
print(json.dumps(search_data, indent=2))
if __name__ == "__main__":
asyncio.run(run())
Above, we use a common pagination idiom used to speed up web scraping using asynchronous requests. We retrieve the first page for the total page count, and then we can schedule concurrent requests for the rest of the pages.
Here's an example output of the above Yelp scraper code:
Example output
[
{
"bizId": "_Wv9uLrzQ1dZ6fgMYjgygg",
"searchResultBusiness": {
"ranking": null,
"isAd": true,
"renderAdInfo": false,
"name": "Rooter-Man",
"alternateNames": [],
"businessUrl": "/adredir?ad_business_id=_Wv9uLrzQ1dZ6fgMYjgygg&campaign_id=jpQhVJGCG8ILi71Et0XDdQ&click_origin=search_results&placement=vertical_0&placement_slot=1&redirect_url=https%3A%2F%2Fwww.yelp.com%2Fbiz%2Frooter-man-orting%3Foverride_cta%3DGet%2Bpricing%2B%2526%2Bavailability&request_id=9d07f67caab0b9cc&signature=919646537897431750a9ec41b1240262d0e8596eed098a3d2776e9c9afe1898f&slot=0",
"categories": [
{
"title": "Plumbing",
"url": "/search?find_desc=Plumbing&find_loc=Seattle%2C+WA"
}
],
"priceRange": "",
"rating": 0.0,
"isClickableReview": false,
"reviewCount": 0,
"formattedAddress": "",
"neighborhoods": [],
"phone": "",
"serviceArea": null,
"parentBusiness": null,
"servicePricing": null,
"bizSiteUrl": "https://biz.yelp.com",
"serviceOfferings": [],
"businessAttributes": {
"licenses": [
{
"license_number": "ROOTE**792MT",
"license_expiration_date": "2025-08-12",
"license_verification_url": "https://secure.lni.wa.gov/verify/Detail.aspx?UBI=602584774&LIC=ROOTE**792MT&SAW=",
"license_verification_status": "verified",
"license_verification_date": "2023-11-17",
"license_issuing_authority": "WA DLI ",
"license_type": "Journey Level",
"license_source": "biz_owner",
"licensee": null
}
]
},
"alias": "rooter-man-orting",
"website": {
"href": "/adredir?ad_business_id=_Wv9uLrzQ1dZ6fgMYjgygg&campaign_id=jpQhVJGCG8ILi71Et0XDdQ&click_origin=search_results_visit_website&placement=vertical_0&placement_slot=1&redirect_url=https%3A%2F%2Fwww.yelp.com%2Fbiz_redir%3Fcachebuster%3D1701335261%26s%3D853c7f42baedaddb12d3a47cbf0c7c30e7bb3cf5d0408740f1e1ee56ec69c2a7%26src_bizid%3D_Wv9uLrzQ1dZ6fgMYjgygg%26url%3Dhttp%253A%252F%252Fwww.rooterman.com%26website_link_type%3Dwebsite&request_id=9d07f67caab0b9cc&signature=8842df091a5b79be57b4bf6122644039b1f6c07fac0c2fdb235c8ff076ce2520&slot=0",
"rel": "noopener nofollow"
},
"city": "Orting"
},
"scrollablePhotos": {
"isScrollable": false,
"photoList": [
{
"src": "https://s3-media0.fl.yelpcdn.com/bphoto/-31eN7ypNCIJCHRO0Xjf3g/ls.jpg",
"srcset": "https://s3-media0.fl.yelpcdn.com/bphoto/-31eN7ypNCIJCHRO0Xjf3g/258s.jpg 1.03x,https://s3-media0.fl.yelpcdn.com/bphoto/-31eN7ypNCIJCHRO0Xjf3g/300s.jpg 1.20x,https://s3-media0.fl.yelpcdn.com/bphoto/-31eN7ypNCIJCHRO0Xjf3g/348s.jpg 1.39x"
}
],
"photoHref": "/adredir?ad_business_id=_Wv9uLrzQ1dZ6fgMYjgygg&campaign_id=jpQhVJGCG8ILi71Et0XDdQ&click_origin=search_results&placement=vertical_0&placement_slot=1&redirect_url=https%3A%2F%2Fwww.yelp.com%2Fbiz%2Frooter-man-orting%3Foverride_cta%3DGet%2Bpricing%2B%2526%2Bavailability&request_id=9d07f67caab0b9cc&signature=919646537897431750a9ec41b1240262d0e8596eed098a3d2776e9c9afe1898f&slot=0",
"allPhotosHref": "/biz_photos/_Wv9uLrzQ1dZ6fgMYjgygg",
"isResponsive": false
},
"childrenBusinessInfo": null,
"searchResultBusinessPortfolioProjects": null,
"searchResultBusinessHighlights": {
"bizSiteUrl": "https://biz.yelp.com/business_highlights?utm_source=disclaimer_www_searchresults",
"businessHighlights": [
{
"bizPageIconName": "",
"group": {},
"bizPageIconV2Name": "40x40_locally_owned_v2",
"iconName": "18x18_locally_owned",
"id": "LOCALLY_OWNED_OPERATED",
"title": "Locally owned & operated"
},
{
"bizPageIconName": "",
"group": {},
"bizPageIconV2Name": "40x40_family_owned_v2",
"iconName": "18x18_family_owned",
"id": "FAMILY_OWNED_OPERATED",
"title": "Family-owned & operated"
},
{
"bizPageIconName": "",
"group": {},
"bizPageIconV2Name": "40x40_workmanship_guaranteed_v2",
"iconName": "18x18_workmanship_guaranteed",
"id": "WORKMANSHIP_GUARANTEED",
"title": "Workmanship guaranteed"
},
{
"bizPageIconName": "",
"group": {},
"bizPageIconV2Name": "40x40_years_in_business_v2",
"iconName": "18x18_years_in_business",
"id": "YEARS_IN_BUSINESS",
"title": "20 years in business"
},
{
"bizPageIconName": "",
"group": {},
"bizPageIconV2Name": "40x40_veteran_owned_v2",
"iconName": "18x18_veteran_owned",
"id": "VETERAN_OWNED_OPERATED",
"title": "Veteran-owned & operated"
},
{
"bizPageIconName": "",
"group": {},
"bizPageIconV2Name": "40x40_free_estimates_v2",
"iconName": "18x18_free_estimates",
"id": "FREE_ESTIMATES",
"title": "Free estimates"
}
],
"numGemsAllowed": 2
},
"tags": [],
"serviceOfferings": [],
"snippet": {
"readMoreText": "more",
"readMoreUrl": "/adredir?ad_business_id=_Wv9uLrzQ1dZ6fgMYjgygg&campaign_id=jpQhVJGCG8ILi71Et0XDdQ&click_origin=read_more&placement=vertical_0&placement_slot=1&redirect_url=https%3A%2F%2Fwww.yelp.com%2Fbiz%2Frooter-man-orting%3Foverride_cta%3DGet%2Bpricing%2B%2526%2Bavailability&request_id=9d07f67caab0b9cc&signature=919646537897431750a9ec41b1240262d0e8596eed098a3d2776e9c9afe1898f&slot=0",
"text": "Give us a call for a free consultatiom.",
"thumbnail": {
"src": "https://s3-media0.fl.yelpcdn.com/bphoto/A0e8SoYZthSqITMDTjB0sA/30s.jpg",
"srcset": "https://s3-media0.fl.yelpcdn.com/bphoto/A0e8SoYZthSqITMDTjB0sA/ss.jpg 1.33x,https://s3-media0.fl.yelpcdn.com/bphoto/A0e8SoYZthSqITMDTjB0sA/60s.jpg 2.00x,https://s3-media0.fl.yelpcdn.com/bphoto/A0e8SoYZthSqITMDTjB0sA/90s.jpg 3.00x"
},
"id": "",
"type": "specialty"
},
"searchActions": [],
"markerKey": "ad_business:below_organic:U5LNtOZST6_9gpNAbqw8Lg",
"searchResultLayoutType": "scrollablePhotos",
"verifiedLicenseInfo": {
"licenses": [
{
"licensee": null,
"licenseNumber": "ROOTE**792MT",
"issuedBy": "WA DLI ",
"trade": "Journey Level",
"verifiedDate": "2023-11-17",
"expiryDate": "2025-08-12"
}
],
"bizSiteUrl": "https://biz.yelp.com/verified_license?utm_source=legal_disclaimer_www"
},
"verifiedLicenseLayout": "BadgeAndTextBelowBizName",
"yelpGuaranteedInfo": {
"yelp_guaranteed_status": false,
"yg_info_modal_url": "https://www.yelp.com/yelp-guaranteed"
},
"adLoggingInfo": {
"placement": "vertical_0",
"slot": 0,
"placementSlot": 1,
"opportunityId": "9d07f67caab0b9cc",
"adCampaignId": "jpQhVJGCG8ILi71Et0XDdQ",
"flow": "search",
"isShowcaseAd": false
},
"offerCampaignDetails": null
},
....
]
We can successfully scrape Yelp for search data. In the following section, we'll scrape company pages using each company URL.
How to Scrape Yelp Company Data
Let's start by looking at the company pages to the data location on the HTML:
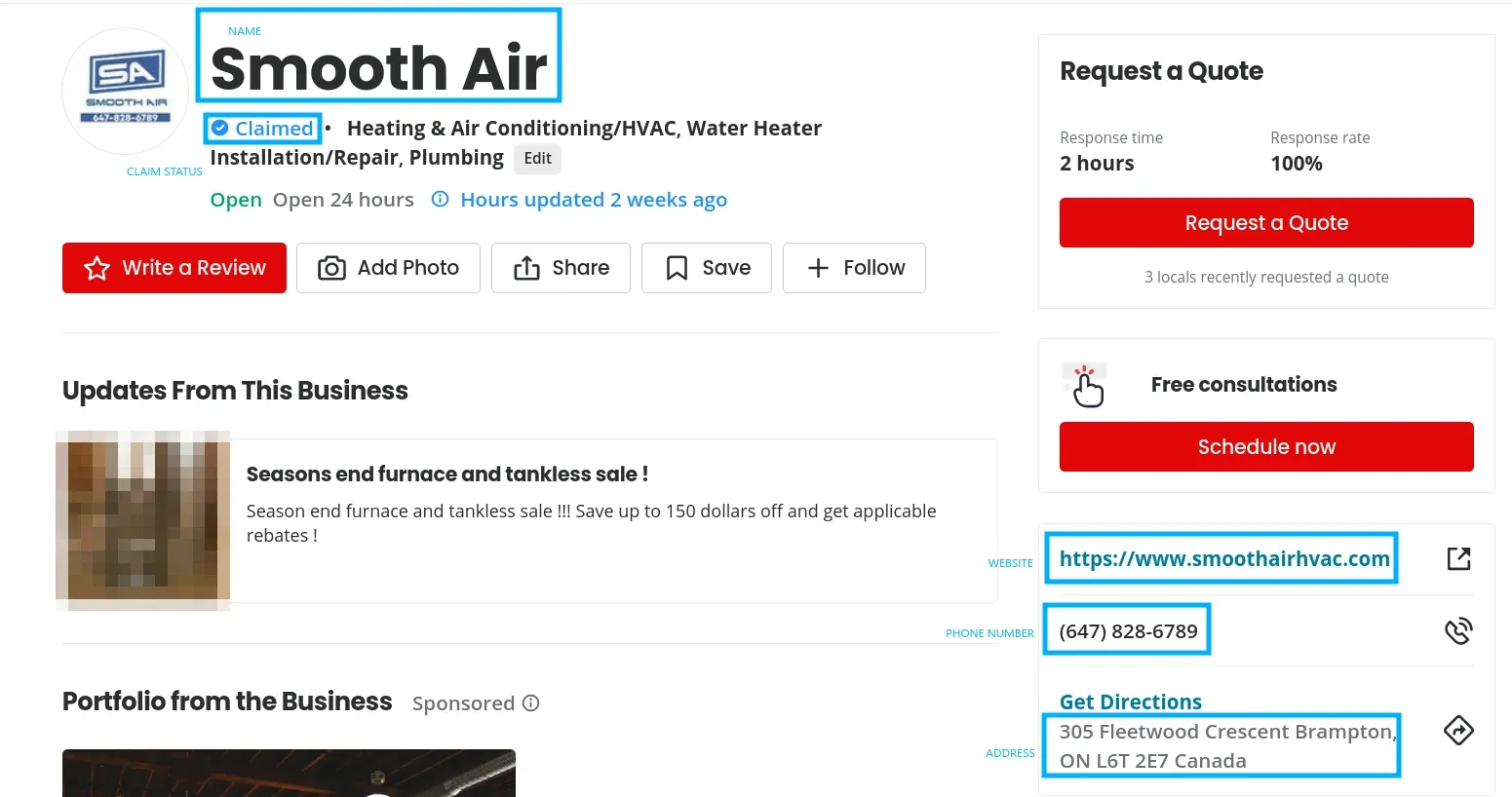
From the above image, we can see the HTML contains all the necessary data needed. That being said, the HTML structure is messy:

The above class names are dynamically generated, meaning that these class names are prone to change - making our Yelp scraper unreliable.
So, instead of using these class names, we'll use more robust techniques, such as matching by text or using strict elements' values.

Luckily for us, XPath allows for various selectors' tricks, such as the contains() and .. features:
//a[contains(text(),"Get Directions")]/../following-sibling::p/text()
We'll use the above parsing approach to get the necessary company data. And to evaluate the selectors with the HTML we get, we'll use parsel:
import httpx
import asyncio
import json
from typing import List, Dict
from parsel import Selector
def parse_company(resp: httpx.Response):
sel = Selector(text=resp.text)
xpath = lambda xp: sel.xpath(xp).get(default="").strip()
open_hours = {}
for day in sel.xpath('//th/p[contains(@class,"day-of-the-week")]'):
name = day.xpath('text()').get().strip()
value = day.xpath('../following-sibling::td//p/text()').get().strip()
open_hours[name.lower()] = value
return dict(
name=xpath('//h1/text()'),
website=xpath('//p[contains(text(),"Business website")]/following-sibling::p/a/text()'),
phone=xpath('//p[contains(text(),"Phone number")]/following-sibling::p/text()'),
address=xpath('//a[contains(text(),"Get Directions")]/../following-sibling::p/text()'),
logo=xpath('//img[contains(@class,"businessLogo")]/@src'),
claim_status="".join(sel.xpath('//span[span[contains(@class,"claim")]]/text()').getall()).strip().lower(),
open_hours=open_hours
)
async def scrape_yelp_companies(company_urls:List[str], session: httpx.AsyncClient) -> List[Dict]:
"""Scrape yelp company details from given yelp company urls"""
responses = await asyncio.gather(*[
session.get(url) for url in company_urls
])
results = []
for resp in responses:
results.append(parse_company(resp))
return results
Here, we define aparse_company function, which uses XPath queries to capture the data fields we highlighted earlier. Next, we utilize this function with the scrape_yelp_companies function, which requests the Yelp company pages.
Let's run the code to see the result we get:
Run the code
BASE_HEADERS = {
"authority": "www.yelp.com",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate",
}
async def run():
async with httpx.AsyncClient(headers=BASE_HEADERS, timeout=10.0) as session:
data = await scrape_yelp_companies(["https://www.yelp.com/biz/smooth-air-brampton"], session=session)
print(json.dumps(data, indent=2))
if __name__ == "__main__":
asyncio.run(run())
[
{
"name": "Smooth Air",
"website": "smoothairhvac.com",
"phone": "(647) 828-6789",
"address": "305 Fleetwood Crescent Brampton, ON L6T 2E7 Canada",
"logo": "https://s3-media0.fl.yelpcdn.com/businessregularlogo/hj2SF8VPHxKaLMNIcf5qCQ/ms.jpg",
"claim_status": "claimed",
"open_hours": {
"mon": "Open 24 hours",
"tue": "Open 24 hours",
"wed": "Open 24 hours",
"thu": "Open 24 hours",
"fri": "Open 24 hours",
"sat": "Open 24 hours",
"sun": "12:00 AM - 12:00 AM (Next day)"
}
}
]
How to Scrape Yelp Reviews
To scrape Yelp company reviews, we'll utilize another hidden API. To find this API, follow the below steps:
- Go to any company page on Yelp.
- Open the browser developer tools by pressing the
F12key. - Click the next review page.
After following the above steps, you will find the reviews API recorded on the network tab:
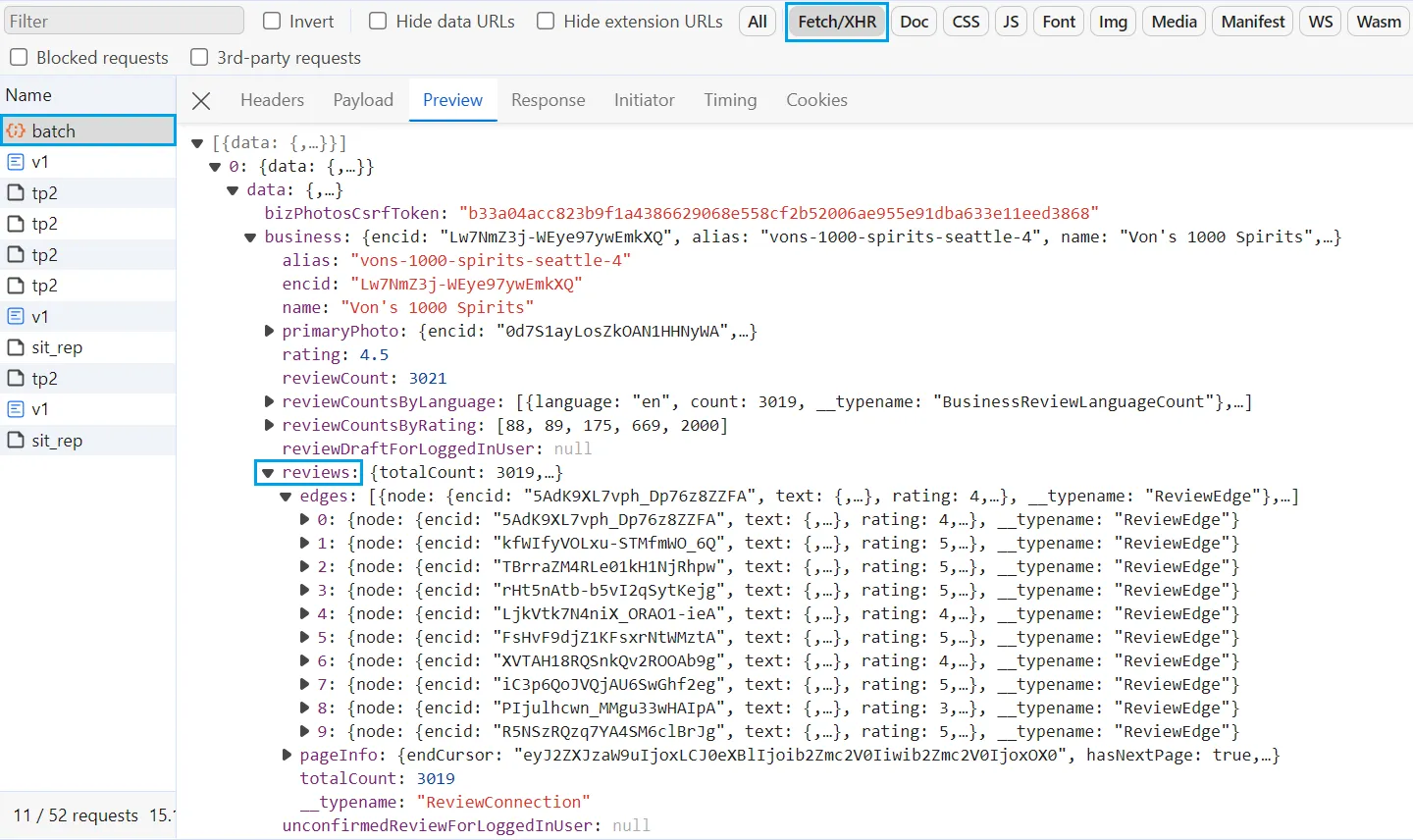
The above API call represent a GraphQL request. It uses a few payload values, including the BUSINESS_ID to fetch review data.

To extract review data, we'll replicate the above GraphQL request within our Yelp scraper. But first, we need to get the BUSINESS_ID from the company page:
How to find yelp's business ID?
The Yelp's company business ID can be found in the HTML source of the business page itself. Scraping it is fairly straightforward:
import httpx
from parsel import Selector
def scrape_business_id(url):
response = httpx.get(url)
selector = Selector(response.text)
return selector.css('meta[name="yelp-biz-id"]::attr(content)').get()
print(scrape_business_id("https://www.yelp.com/biz/vons-1000-spirits-seattle-4"))
"Lw7NmZ3j-WEye97ywEmkXQ"
Next, we'll define a request_reviews_api function to replicate the GraphQL request:
async def request_reviews_api(url: str, start_index: int, business_id):
"""request the graphql API for review data"""
pagionation_data = {
"version": 1,
"type": "offset",
"offset": start_index
}
pagionation_data = json.dumps(pagionation_data)
after = base64.b64encode(pagionation_data.encode('utf-8')).decode('utf-8') # decode the pagination values for the payload
payload = json.dumps([
{
"operationName": "GetBusinessReviewFeed",
"variables": {
"encBizId": business_id,
"reviewsPerPage": 10,
"selectedReviewEncId": "",
"hasSelectedReview": False,
"sortBy": "DATE_DESC",
"languageCode": "en",
"ratings": [
5,
4,
3,
2,
1
],
"isSearching": False,
"after": after, # pagination parameter
"isTranslating": False,
"translateLanguageCode": "en",
"reactionsSourceFlow": "businessPageReviewSection",
"minConfidenceLevel": "HIGH_CONFIDENCE",
"highlightType": "",
"highlightIdentifier": "",
"isHighlighting": False
},
"extensions": {
"operationType": "query",
# static value
"documentId": "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
}
}
])
headers = {
'authority': 'www.yelp.com',
'accept': '*/*',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'no-cache',
'content-type': 'application/json',
'origin': 'https://www.yelp.com',
'referer': url, # main business page URL
'x-apollo-operation-name': 'GetBusinessReviewFeed'
}
client = httpx.AsyncClient(timeout=10.0)
response = await client.post(
url="https://www.yelp.com/gql/batch",
json=payload,
headers=headers
)
return response
The above request uses basic headers and a JSON payload, which represent the GraphQL query. The payload include pre-configured paramaters that's required by the server along with two configurable paramaters. Let's break them down:
encBizId: The business ID for the company page.after: An encoded JSON object that controls the reviews offset, which we'll use to paginate over review pages.
Now that our function for requesting the reviews API is ready, let's use it crawl the reviews data:
import base64
import asyncio
import jmespath
import httpx
import json
from typing import List, Dict
from parsel import Selector
def parse_review_data(response: httpx.Response):
"""parse review data from the JSON response"""
data = json.loads(response.text)
reviews = data[0]["data"]["business"]["reviews"]["edges"]
parsed_reviews = []
for review in reviews:
result = jmespath.search(
"""{
encid: encid,
text: text.{full: full, language: language},
rating: rating,
feedback: feedback.{coolCount: coolCount, funnyCount: funnyCount, usefulCount: usefulCount},
author: author.{encid: encid, displayName: displayName, displayLocation: displayLocation, reviewCount: reviewCount, friendCount: friendCount, businessPhotoCount: businessPhotoCount},
business: business.{encid: encid, alias: alias, name: name},
createdAt: createdAt.utcDateTime,
businessPhotos: businessPhotos[].{encid: encid, photoUrl: photoUrl.url, caption: caption, helpfulCount: helpfulCount},
businessVideos: businessVideos,
availableReactions: availableReactionsContainer.availableReactions[].{displayText: displayText, reactionType: reactionType, count: count}
}""",
review["node"]
)
parsed_reviews.append(result)
total_reviews = data[0]["data"]["business"]["reviewCount"]
return {"reviews": parsed_reviews, "total_reviews": total_reviews}
async def request_reviews_api(url: str, start_index: int, business_id):
"""request the graphql API for review data"""
# the rest of the function logic
async def scrape_reviews(session: httpx.AsyncClient, url: str, max_reviews: int = None) -> List[Dict]:
# first find business ID from business URL
print("scraping the business id from the business page")
response_business = await session.get(url)
assert response_business.status_code == 403, "request is blocked"
selector = Selector(text=response_business.text)
business_id = selector.css('meta[name="yelp-biz-id"]::attr(content)').get()
print("scraping the first review page")
first_page = await request_reviews_api(url=url, business_id=business_id, start_index=1)
review_data = parse_review_data(first_page)
reviews = review_data["reviews"]
total_reviews = review_data["total_reviews"]
# find total page count to scrape
if max_reviews and max_reviews < total_reviews:
total_reviews = max_reviews
# next, scrape the remaining review pages
print(f"scraping review pagination, remaining ({total_reviews // 10}) more pages")
for offset in range(11, total_reviews, 10):
response = await request_reviews_api(url=url, business_id=business_id, start_index=offset)
new_review_data = parse_review_data(response)["reviews"]
reviews.extend(new_review_data)
print(f"scraped {len(reviews)} reviews from review pages")
return reviews
Run the code
BASE_HEADERS = {
"authority": "www.yelp.com",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate",
}
async def run():
async with httpx.AsyncClient(headers=BASE_HEADERS, timeout=10.0) as session:
review_data = await scrape_reviews(
url="https://www.yelp.com/biz/vons-1000-spirits-seattle-4",
session=session,
max_reviews=28
)
# save the results to a JSON file
with open("reviews.json", "w", encoding="utf-8") as file:
json.dump(review_data, file, indent=2, ensure_ascii=False)
if __name__=="__main__":
asyncio.run(run())
In the above code, we define two functions. Let's break them down:
parse_review_data: For parsing the review data from the API response and extracting the total number of reviews available. It also refines the object of the long review to execute the unnecessary data using JMESPath.scrape_reviews: The main Yelp reviews scraping logic. It starts by retrieving theBUSINESS_IDfrom the company page. Next, it uses the previously definedrequest_reviews_apito get the first review page data, including the total number of reviews available. Finally, it crawls over the remaining review pages to extract the desired amount of review pages.
Here is a sample output of the results we got:
Sample output
[
{
"encid": "0c0ASru2cWdP3XkaPBaJpQ",
"text": {
"full": "I'm literally still salivating thinking about that pasta I ate and I am currently contemplating driving there right now for more while writing this review. I'm usually quite particular about my pastas, but I haven't stopped talking about this place with my boyfriend since we left. We headed to to Von's for a late night dinner around 10:30pm and called ahead to see if they had spots. It was easy to find street parking across the restaurant around this time, but usually theres no parking garage/spot nearby during the day. When we walked in, we were greeted by a really kind hotness who said they weren't busy and could seat us right away. They were doing rotation, so seats were as is at that time. Our server let us know everything's made to order and last call was at 11:30pm for bar & food. The ambiance of the restaurant was intimate and chill with the dim lights. The brightest part was the liquor shelving by the bar and there's quite an extensive inventory. There didn't seem to be a dress code with people dressing up for date night or down in sweats for a quick drink. They have a fun little board they spin during happy hour for discounts off certain drinks. During dinner time, it's not too loud though which I appreciated. \n\nWe ordered separate entrees and drinks this time around. \npepperoni sour dough pizza: the cheese pull with this pizza was insane! the first bite my boyfriend took was well balanced he said the pepperoni had a nice lingering of spice. The toppings were also well distributed and the dough tasted fresh. It was more of a thin crust. \n\nmediterranean sourdough pasta w/ dog island mushroom: i could eat this every week and not get sick of it. I often feel like pasta sauces are under seasoned, but the red sauce was well salted and had a little kick too. I asked for additional red pepper flakes and that hit the spot. The pasta i could tell was also cooked fresh and I loved the texture/shape. The sun dried tomatoes add a nice texture as well as the mushrooms I added in. There's fresh basil on top and acidity from the kalamata olive cuts through each bite. \n\nstrawberry lemonade: I cannot recommend this enough!!!! I love lemonade, but usually when I order it at restaurants, it's way too sour for my liking or just taste like diabetes. I felt like this drink was a good balance of tang and fresh strawberries were refreshing. It's also a huge portion and they don't offer refills, but took me until the end of dinner to finish it anyways.\n\nside piece: I forgot to take a picture of this drink, but my boyfriend didn't like this too much. It was too harsh on his palate and wasn't giving any of the fruit notes we were expecting. \n\nI would definitely recommend this place for their food and will be back ourselves. The service hasn't been the best both times we went: the first time, it was during peak hours so understandable, but we felt rushed and ignored during our meal. Then the second time, our server was a bit too aggressive.. that's why I would give this more of a 4.6 star; service aside, I enjoyed the ambiance w/ my pasta & lemonade :)",
"language": "en"
},
"rating": 5,
"feedback": {
"coolCount": 0,
"funnyCount": 0,
"usefulCount": 0
},
"author": {
"encid": "9qQypRSJ6SYbTwblOT6YMw",
"displayName": "Faith B.",
"displayLocation": "Seattle, WA",
"reviewCount": 34,
"friendCount": 3,
"businessPhotoCount": 294
},
"business": {
"encid": "Lw7NmZ3j-WEye97ywEmkXQ",
"alias": "vons-1000-spirits-seattle-4",
"name": "Von's 1000 Spirits"
},
"createdAt": "2024-02-22T21:16:42Z",
"businessPhotos": [
{
"encid": "t7a29I8nLiovtAlmpoFgkA",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/t7a29I8nLiovtAlmpoFgkA/348s.jpg",
"caption": "classic pepperoni sourdough pizza",
"helpfulCount": 0
},
{
"encid": "2pkjJztoRTjKpw3VZXONOw",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/2pkjJztoRTjKpw3VZXONOw/348s.jpg",
"caption": "pasta station :)",
"helpfulCount": 0
},
{
"encid": "-peH2xcHSAwTdV99Mr9TBQ",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/-peH2xcHSAwTdV99Mr9TBQ/348s.jpg",
"caption": "size comparison of strawberry lemonade to water glass!",
"helpfulCount": 0
},
{
"encid": "3UYJuoTbXzk0PXW2F9OYWQ",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/3UYJuoTbXzk0PXW2F9OYWQ/348s.jpg",
"caption": "bar view from front dining room",
"helpfulCount": 0
},
{
"encid": "vLqejhL8l-FrxvedoxGG8Q",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/vLqejhL8l-FrxvedoxGG8Q/348s.jpg",
"caption": "scratch strawberry lemonade",
"helpfulCount": 0
},
{
"encid": "PIMUK18mxCDkn0Egm2eNIw",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/PIMUK18mxCDkn0Egm2eNIw/348s.jpg",
"caption": "food menu as of 2-18-24",
"helpfulCount": 0
},
{
"encid": "Si1wOMk6oSzC5r-hf4nFNA",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/Si1wOMk6oSzC5r-hf4nFNA/348s.jpg",
"caption": "food menu as of 2-18-24",
"helpfulCount": 0
},
{
"encid": "vFwmnKDyIOzX4ieEXiTnVQ",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/vFwmnKDyIOzX4ieEXiTnVQ/348s.jpg",
"caption": "mediterranean vegan sourdough pasta",
"helpfulCount": 0
},
{
"encid": "6lbe38MuJs0Q_YFITJjeWQ",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/6lbe38MuJs0Q_YFITJjeWQ/348s.jpg",
"caption": "drinks board",
"helpfulCount": 0
},
{
"encid": "AyTiGuuylivLGIDotapC5g",
"photoUrl": "https://s3-media0.fl.yelpcdn.com/bphoto/AyTiGuuylivLGIDotapC5g/348s.jpg",
"caption": "1st drinks menu as of 2-18-24",
"helpfulCount": 0
}
],
"businessVideos": [],
"availableReactions": [
{
"displayText": "Helpful",
"reactionType": "HELPFUL",
"count": 0
},
{
"displayText": "Thanks",
"reactionType": "THANKS",
"count": 0
},
{
"displayText": "Love this",
"reactionType": "LOVE_THIS",
"count": 0
},
{
"displayText": "Oh no",
"reactionType": "OH_NO",
"count": 0
}
]
},
....
]
Although we specified the total number of reviews in our scraper to be only 30, we can scrape further reviews in mere seconds. This is because requesting the API is much faster than requesting HTML pages!
Bypass Yelp Blocking with Scrapfly
Web scraping Yelp is a very popular case and the website employs different techniques to block web scrapers.
To resist its blocking, we replicated common browser headers with our scraper. However, we are very likely to get blocked as soon as we scale our scraping requests.
Here is what the blocked requests on Yelp look like:
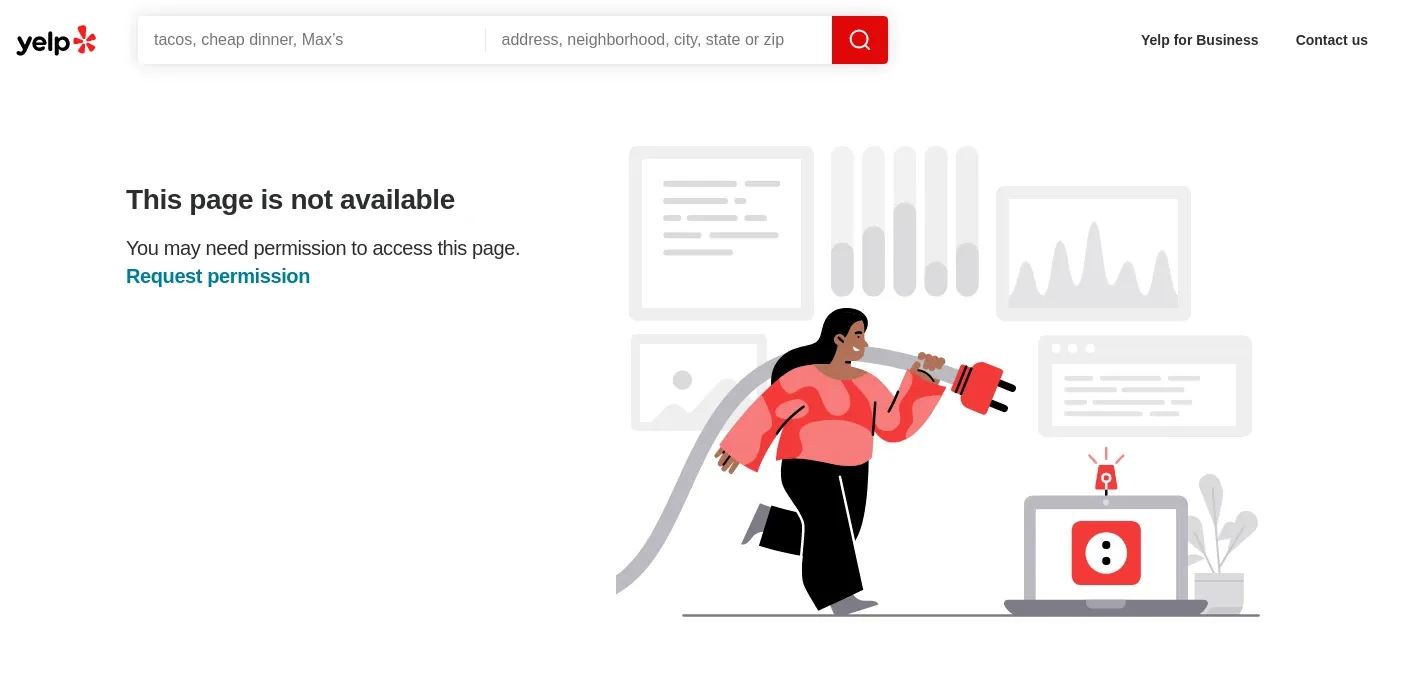
Once Yelp realizes the client is a web scraper, it will redirect all the requests to the above page. To avoid blocking in this project, we'll use ScrapFly's web scraping API.
ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
To scrape Yelp.com using ScrapFly and Python all we have to do is install the ScrapFly Python SDK:
$ pip install scrapfly-sdk
Then, replace the httpx client with ScrapFly's SDK. For example, here is how we can scrape business phone numbers on Yelp's company page:
import httpx
response = httpx.get("https://www.yelp.com/biz/smooth-air-brampton")
selector = Selector(text=response.text)
phone_number = selector.xpath('//p[contains(text(),"Phone number")]/following-sibling::p/text()').get()
# in ScrapFly SDK becomes
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient("YOUR SCRAPFLY KEY")
result = client.scrape(ScrapeConfig(
"https://www.yelp.com/biz/smooth-air-brampton",
# we can select specific proxy country
country="US",
# and enable anti scraping protection bypass:
asp=True,
render_js=True # enable JS rendering if needed
))
phone_number = result.selector.xpath('//p[contains(text(),"Phone number")]/following-sibling::p/text()').get()
print(phone_number)
Check out Scrapfly's web scraping API for all the details.
FAQ
To wrap this guide up let's take a look at some frequently asked questions about web scraping Yelp:
Is web scraping yelp legal?
Yes, all the data on Yelp.com are publicly available, and it's legal to scrape them as long as the scraping rate is reasonable and doesn't cause any harm to the website. For more details, refer to our previous guide on web scraping legality.
Is there a public API for Yelp?
At the time of writing, Yelp doesn't offer APIs for public use. However, we did find private APIs for company search and reviews, which we can utilize for web scraping.
Are there alternatives for Yelp?
Yes, there are several popular alternatives for business and review data. We have covered scraping Yellowpages, scraping TripAdvisor for travel reviews, scraping Trustpilot for product reviews, and scraping Google Maps for local business data.
How to scrape Yelp reviews?
To retrieve specific company reviews on Yelp, you need to replicate a request to the reviews API. To view this API, open browser developer tools and click on the 2nd review page to inspect the outgoing requests. Refer to the scraping Yelp reviews section for more details.
Yelp Sraping Summary
In this guide, we explained how to scrape Yelp to retrieve company data. We have also explained how to utilize Yelp's private APIs to scrape search and review data from the website.
For our Yelp scraper, we have used Python with a few community packages, httpx and parsel. To avoid Yelp scraping blocking, we have used ScrapFly - a smart API that configures every request's connection to avoid blocking.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.