

BeautifulSoup is one of the most popular libraries used in web scraping. It's used to parse HTML documents for data either through Python scripting or the use of CSS selectors.
In this practical tutorial, we'll cover these subjects:
- Overview of HTML structures and how to navigate them.
- How to parse HTML using Beautifulsoup's
findandfind_allmethods. - How to use Beautifulsoup's CSS Selectors using
selectandselect_onemethods. - Beautifulsoup extras like: text cleanup, pretty formatting and HTML tree modification
Finally, to solidify all of this, we'll take a look at a real-life example web scraping project and scrape job listing data from remotepython.com.
Key Takeaways
Learn beautifulsoup HTML parsing with Python using find() methods, CSS selectors, and text extraction. Build web scrapers that parse HTML documents, extract data from elements, and handle complex page structures for data collection.
- Use find() and find_all() methods with tag names, class attributes, and text content for element selection
- Implement CSS selectors with select() and select_one() for complex element targeting and navigation
- Extract text content using get_text() method with proper whitespace handling and encoding
- Navigate HTML tree structures using parent, child, and sibling element relationships
- Handle different HTML structures and edge cases in real-world scraping scenarios
- Combine BeautifulSoup with requests for complete web scraping workflows
What is Web Scraping?
Web scraping is the process of collecting data from the web. In other words, it's a program that retrieves data from websites (usually HTML pages) and parses it for specific data.
Web scraping is used to collect datasets for market research, real estate analysis, business intelligence and so on - see our Web Scraping Use Cases article for more.
The tool we're covering today - beautifulsoup4 - is used for parsing collected HTML data and it's really good at it. Let's take look!
Setup
In this article, we'll be using Python 3.7+ and beautifulsoup4. We'll also be using requests package in our example to download the web content. All of these can be installed through the pip install console command:
$ pip install bs4 requestsOr alternatively, in a new virtual environment using poetry package manager:
$ mkdir bs4-project && cd bs4-project
$ poetry init -n --dependency bs4 requestsQuick Start
Before we start, let's see a quick beautifulsoup example of what this python package is capable of:
html = """
<div class="product">
<h2>Product Title</h2>
<div class="price">
<span class="discount">12.99</span>
<span class="full">19.99</span>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
product = {
"title": soup.find(class_="product").find("h2").text,
"full_price": soup.find(class_="product").find(class_="full").text,
"price": soup.select_one(".price .discount").text,
}
print(product)
{
"title": "Product Title",
"full_price": "19.99",
"price": "12.99",
}This example illustrates how easily we can parse web pages for product data and a few key features of beautifulsoup4. To fully understand HTML parsing let's take a look at what makes HTML such a powerful data structure.
How is HTML parsed?
HTML (HyperText Markup Language) is designed to be easily machine-readable and parsable. In other words, HTML follows a tree-like structure of nodes (HTML tags) and their attributes, which we can easily navigate programmatically.
Let's start, with a small example page and illustrate its structure:
<head>
<title>
</title>
</head>
<body>
<h1>Introduction</h1>
<div>
<p>some description text: </p>
<a class="link" href="http://example.com">example link</a>
</div>
</body>In this basic example of a simple web page source code, we can see that the document already resembles a data tree just by looking at the indentation.
Let's go a bit further and illustrate this:

Here, we can wrap our heads around it a bit more easily - it's a tree of nodes and each node consists of:
- Node Name - aka HTML tag, e.g.
<div> - Natural Properties - the text value and position.
- Keyword Properties - keyword values like
class,hrefetc.
With this basic understanding, we can see how python and beautifulsoup can help us traverse this tree to extract the data we need.
Parsing HTML with BeautifulSoup
Beautifulsoup is a python library that is used for parsing HTML documents. Using it we can navigate HTML data to extract/delete/replace particular HTML elements. It also comes with utility functions like visual formatting and parse tree cleanup.
Tip: Choosing a Backend
Bs4 is pretty big and comes with several backends that provide HTML parsing algorithms that differ very slightly:
- html.parser - python's built-in parser, which is written in python meaning it's always available though it's a bit slower.
- lxml - C-based library for HTML parsing: very fast, but can be a bit more difficult to install.
- html5lib - another parser written in python that is intended to be fully html5 compliant.
To summarize, it's best to stick with lxml backend because it's much faster, however html.parser is still a good option for smaller projects. As for html5lib it's mostly best for edge cases where html5 specification compliance is necessary.
The backend can be chosen every time we create a beautiful soup object:
from bs4 import BeautifulSoup
html = "<h1>test</h1>"
# automatically select the backend (not recommended as it makes code hard to share)
soup = BeautifulSoup(html)
# lxml - most commonly used backend
soup = BeautifulSoup(html, "lxml")
# html.parser - included with python
soup = BeautifulSoup(html, "html.parser")
# html5lib - parses pages same way modern browser does
soup = BeautifulSoup(html, "html5lib")Now, that we got our soup hot and ready let's see what it can do!
Basic Navigation
Let's start with a very simple piece of HTML data that contains some basic elements of an article: title, subtitle, and some text paragraphs:
from bs4 import BeautifulSoup
# this is our HTML page:
html = """
<head>
<title class="page-title">Hello World!</title>
</head>
<body>
<div id="content">
<h1>Title</h1>
<p>first paragraph</p>
<p>second paragraph</p>
<h2>Subtitle</h2>
<p>first paragraph of subtitle</p>
</div>
</body>
"""
# 1. build soup object from html text
soup = BeautifulSoup(html, 'lxml')
# then we can navigate the html tree via python API:
# for example title is under `head` node:
print(soup.head.title)
'<title class="page-title">Hello World!</title>'
# this gives us a whole HTML node but we can also just select the text:
print(soup.head.title.text)
"Hello World!"
# or it's other attributes:
print(soup.head.title["class"])
"page-title"The example above explores what's called "dot-based navigation" - we can traverse the whole HTML tree top-to-bottom and even select specific attributes like text contents and class names or data attributes.
However, in real life we'll be working with much bigger pages, so imagine if a page parse tree had 7 levels of depth, we'd have to write something like:
soup.body.div.div.div.p.a['href']This is rather inconvenient, for this beautiful soup introduces two special methods called find() and find_all():
from bs4 import BeautifulSoup
html = """
<head>
<title class="page-title">Hello World!</title>
</head>
<body>
<div id="content">
<h1>Title</h1>
<p>first paragraph</p>
<p>second paragraph</p>
<h2>Subtitle</h2>
<p>first paragraph of subtitle</p>
</div>
</body>
"""
soup = BeautifulSoup(html, 'lxml')
soup.find('title').text
"Hello World"
# we can also perform searching by attribute values
soup.find(class_='page-title').text
"Hello World"
# We can even combine these two approaches:
soup.find('div', id='content').h2.text
"Subtitle"
# Finally, we can perform partial attribute matches using regular expressions
# let's select paragraphs that contain the word "first" in it's text:
soup.find_all('p', text=re.compile('first'))
["<p>first paragraph</p>", "<p>first paragraph of subtitle</p>"]As you can see, by combining beautiful soups dot-based navigation with the magic find() and find_all() methods we can easily and reliably navigate the HTML tree to extract specific information very easily!
Using CSS Selectors
Another way to find specific elements deep inside a page's structure is to use CSS selectors through beautifulsoup's select() and select_one() functions:
from bs4 import BeautifulSoup
html = """
<head>
<title class="page-title">Hello World!</title>
</head>
<body>
<div id="content">
<h1>Title</h1>
<p>first paragraph</p>
<p>second paragraph</p>
<h2>Subtitle</h2>
<p>first paragraph of subtitle</p>
</div>
</body>
"""
soup = BeautifulSoup(html, 'lxml')
soup.select_one('title').text
"Hello World"
# we can also perform searching by attribute values such as class names
soup.select_one('.page-title').text
"Hello World"
# We can also find _all_ amtching values:
for paragraph in soup.select('#content p'):
print(paragraph.text)
"first paragraph"
"second paragraph"
"first paragraph of subtitile"
# We can also combine CSS selectors with find functions:
import re
# select node with id=content and then find all paragraphs with text "first" that are under it:
soup.select_one('#content').find_all('p', text=re.compile('first'))
["<p>first paragraph</p>", "<p>first paragraph of subtitle</p>"]CSS selectors are the standard way of parsing HTML web data and combined with beautiful soup's find methods we can easily parse even the most complex HTML data structures.
Next, let's take a look at some special extra features of bs4 and some real-life web-scraping scenarios.
Beautifulsoup's Extras
Other than being a great HTML parser, bs4 also includes a lot of HTML-related utils and helper functions. Let's take a quick overview of utils that are often used in web scraping.
Extract All Text
Often complex text structures are represented through multiple HTML nodes which can be difficult to extract.
For this, BeautifulSoup's get_text() method can be used to extract all the HTML element's text. For example:
from bs4 import BeautifulSoup
html = """
<div>
<a>The Avangers: </a>
<a>End Game</a>
<p>is one of the most popular Marvel movies</p>
</div>
"""
soup = BeautifulSoup(html, 'lxml')
# join all text values with space, and strip leading/trailing whitespace:
soup.div.get_text(' ', strip=True)
'The Avangers: End Game is one of the most popular Marvel movies'Using get_text() method we can extract all of the text under our selected node and have it nicely formatted
Pretty formatting HTML
Another great utility is the HTML visual formatter which prettifies HTML output.
Frequently, when web-scraping we want to either store or display HTML content somewhere for ingesting it with other tools or debugging.
The .prettify() method restructures HTML output to be more readable by humans:
from bs4 import BeautifulSoup
html = """
<div><h1>The Avangers: </h1><a>End Game</a><p>is one of the most popular Marvel movies</p></div>
"""
soup = BeautifulSoup(html)
soup.prettify()
"""
<html>
<body>
<div>
<h1>
The Avangers:
</h1>
<a>
End Game
</a>
<p>
is one of the most popular Marvel movies
</p>
</div>
</body>
</html>
"""Selective Parsing
Some web scrapers might not need the entire HTML document to extract valuable data. For example, typically when web crawling, we want to only parse <a> nodes for the links.
For this BeautifulSoup offers SoupStrainer object which allows to restrict our parsing to specific HTML elements only:
from bs4 import BeautifulSoup, SoupStrainer
html = """
<head><title>hello world</title></head>
<body>
<div>
<a>Link 1</a>
<a>Link 2</a>
<div>
<a>Link 3</a>
/div>
</div>
</body>
"""
link_strainer = SoupStrainer('a')
soup = BeautifulSoup(html, parse_only=link_strainer)
print(soup)
#<a>Link 1</a><a>Link 2</a><a>Link 3</a>Modifying HTML
Since bs4 loads all of HTML tree as a Python object we can easily modify, delete or replace each node attached to it:
from bs4 import BeautifulSoup
html = """
<div>
<button class="flat-button red">Subscribe</button>
</div>
"""
soup = BeautifulSoup(html)
soup.div.button['class'] = "shiny-button blue"
soup.div.button.string = "Unsubscribe"
print(soup.prettify())
# <html>
# <body>
# <div>
# <button class="shiny-button blue">
# Unsubscribe
# </button>
# </div>
# </body>
# </html>In this section, we've covered the 4 most common extra features. As you can see, this library is not only an HTML parsing library but a whole HTML suite! Finally, let's finish off this article with a real-world example.
Example Project
Let's put what we've learned to use. In this real-world example we'll be scraping Python job listings from https://www.remotepython.com/jobs/.
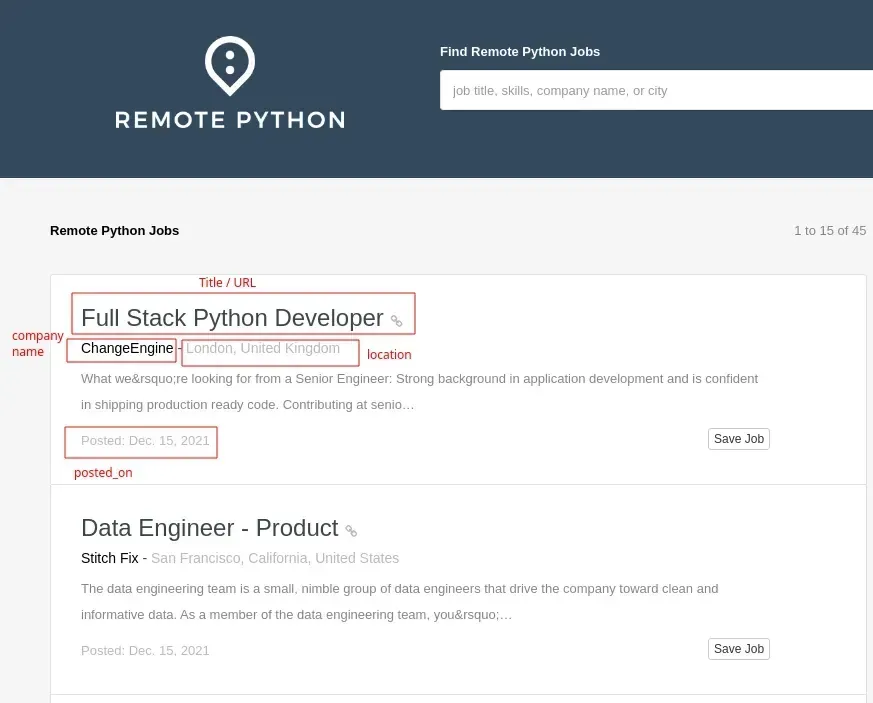
We want to scrape these fields, though how do we find them with beautiful soup?
For that, we can use our web browser's developer tools to easily understand the HTML structure of the website we're about to scrape. Every browser comes with a devtools suite - let's take a quick look at how to use it in web scraping.
tip: turn off javascript in your browser to see what a beautifulsoup powered web scrapers see
We can right-click and select "inspect" on the heading element and see exactly where the job title is located in the HTML tree. Chrome devtools is a great way to visualize web scrapped HTML trees.
Now we can write our scraper which retrieves HTML pages and parses out job details using BeautifulSoup find and select methods:
import re
import json
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
url = "https://www.remotepython.com/jobs/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
results = []
# first find all job listing boxes:
job_listing_boxes = soup.find_all(class_="item")
# then extract listing from each box:
for item in job_listing_boxes:
parsed = {}
if title := item.find("h3"):
parsed["title"] = title.get_text(strip=True)
if item_url := item.find("h3").a["href"]:
parsed["url"] = urljoin(url, item_url)
if company := item.find("h5").find("span", class_="color-black"):
parsed["company"] = company.text
if location := item.select_one("h5 .color-white-mute"):
parsed["location"] = location.text
if posted_on := item.find("span", class_="color-white-mute", text=re.compile("posted:", re.I)):
parsed["posted_on"] = posted_on.text.split("Posted:")[-1].strip()
results.append(parsed)
print(results)
[{
"title": "Hiring Senior Python / DJANGO Developer",
"url": "https://www.remotepython.com/jobs/3edf4109d642494d81719fc9fe8dd5d6/",
"company": "Mathieu Holding sarl",
"location": "Rennes, France",
"posted_on": "Sept. 1, 2022"
},
... # etc.
]In the scraper above we used requests to retrieve the page data and load it to a beautiful soup. Then, we found all of the boxes containing job listing data, iterated through them and parsed job details.
Scraping beautiful soup is pretty straightforward forward however when scraping more difficult targets our scrapers could be blocked from retrieving the HTML data. Next, let's take a look how we can use ScrapFly to avoid web scraper blocking.
Avoiding Blocking with ScrapFly
Beautifulsoup is a powerful tool for web scraping though there's much more to scraping than data parsing and this is where Scrapfly can be of assistance!

Let's try it out by updating our job listings scraper to use ScrapFly's Python SDK which can be installed through pip:
$ pip install scrapfly-sdkNow, all we have to do is replace requests calls with scrapfly ones:
import re
import json
from urllib.parse import urljoin
from scrapfly import ScrapflyClient, ScrapeConfig, ScrapeApiResponse
url = "https://www.remotepython.com/jobs/"
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
result: ScrapeApiResponse = client.scrape(ScrapeConfig(
url=url,
# we can select specific country:
country="US",
# proxy type:
proxy_pool="public_residential_pool",
# we can also enable headless browser powered js rendering
render_js=True,
))
# scrapfly SDK comes with beautifulsoup built-in:
job_listing_boxes = result.soup.find_all(class_="item")
results = []
for item in job_listing_boxes:
parsed = {}
if title := item.find("h3"):
parsed["title"] = title.get_text(strip=True)
if item_url := item.find("h3").a["href"]:
parsed["url"] = urljoin(url, item_url)
if company := item.find("h5").find("span", class_="color-black"):
parsed["company"] = company.text
if location := item.select_one("h5 .color-white-mute"):
parsed["location"] = location.text
if posted_on := item.find("span", class_="color-white-mute", text=re.compile("posted:", re.I)):
parsed["posted_on"] = posted_on.text.split("Posted:")[-1].strip()
results.append(parsed)
print(results)
[{
"title": "Hiring Senior Python / DJANGO Developer",
"url": "https://www.remotepython.com/jobs/3edf4109d642494d81719fc9fe8dd5d6/",
"company": "Mathieu Holding sarl",
"location": "Rennes, France",
"posted_on": "Sept. 1, 2022"
},
...
]FAQ
What are some BeautifulSoup alternatives?
How to parse HTML table data using beautifulsoup?
One of the most common parsing targets are HTML tables which can be parsed by bs4 quite easily. Let's take a look at this example:
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(requests.get("https://www.w3schools.com/html/html_tables.asp").text)
# first we should find our table object:
table = soup.find('table', {"id": "customers"})
# then we can iterate through each row and extract either header or row values:
header = []
rows = []
for i, row in enumerate(table.find_all('tr')):
if i == 0:
header = [el.text.strip() for el in row.find_all('th')]
else:
rows.append([el.text.strip() for el in row.find_all('td')])
print(header)
['Company', 'Contact', 'Country']
for row in rows:
print(row)
['Alfreds Futterkiste', 'Maria Anders', 'Germany']
['Centro comercial Moctezuma', 'Francisco Chang', 'Mexico']
['Ernst Handel', 'Roland Mendel', 'Austria']
['Island Trading', 'Helen Bennett', 'UK']
['Laughing Bacchus Winecellars', 'Yoshi Tannamuri', 'Canada']
['Magazzini Alimentari Riuniti', 'Giovanni Rovelli', 'Italy']Above, we first use the find function to find the table itself. Then, we find all of the table rows and iterate through them extracting their text contents. Note, that the first row is likely to be the table header.
Can BeautifulSoup be used with Scrapy?
Yes, though scrapy has its own HTML parsing library called parsel which is preferred over beautifulsoup4.
Why does HTML in beautifulsoup differ from HTML in a web browser?
Often we can see HTML tree mismatch between BeautifulSoup and web browsers.
For example, if we open up developer tools (F12 key) in our browser on a page that contains more complex structures like table tags (e.g. this w3school table demo page)) we might notice that HTML trees differ slightly.
This is caused by different HTML interpretation rules of each backend. To get around this use html5lib backend which keeps HTML trees identical to a web browser.
Why can't beautifulsoup see some HTML elements?
It's likely that these elements are loaded dynamically by javascript. As python doesn't execute javascript it'll not see that content. For more see our article on How to Scrape Dynamic Websites Using Headless Web Browsers
Is BeautifulSoup a web scraping library?
Not exactly, Beautifulsoup is an HTML parsing library so while it's used for web scraping it's not a full web scraping suite/framework like scrapy. Beautifulsoup HTML parser needs to be paired with HTTP client library like the requests library (or other alternatives like httpx, selenium) to retrieve HTML pages.
Summary and Further Reading
In this tutorial, we've introduced ourselves to web scraping with python and beautifulsoup.
We had a quick look at what are HTML structures and how can they be parsed using bs4's find functions and dot notation as well as how to use CSS selectors using select functions.
We've also taken a look at some utility functions beautiful soup package offers like clean text extraction and HTML formatting - all of which come are very useful web scraping functionalities.
Finally, we wrapped everything up with a real python with beautifulsoup example by scraping job listing information from remotepython.com.
For more on parsing, see our articles tagged with parsing keyword, like:


