

Ruby is a popular general purpose programming language with a strong presence in the web world, but can it be used for web scraping?
In this introduction tutorial article we'll take a deep dive into Ruby as a web scraping platform. What are the best gems to use for web scraping? What are common challenges, idioms and tips and tricks? How to scale web scrapers with parallel requests?
Finally, we'll wrap everything up with a real life example scraper which collects job listing information from indeed.com!
Key Takeaways
Master Ruby web scraping using Typhoeus HTTP client and Nokogiri parser for efficient data extraction with parallel requests and robust HTML parsing.
- Use Typhoeus HTTP client for Ruby web scraping with excellent parallel request support and HTTP/2 compatibility
- Parse HTML with Nokogiri library for powerful CSS selector and XPath-based data extraction
- Handle concurrent scraping with Typhoeus parallel requests for improved performance and efficiency
- Implement proper error handling and retry logic using Ruby's exception handling patterns
- Use CSS selectors and XPath expressions for flexible HTML element targeting and data extraction
- Build scalable Ruby scrapers with proper session management and connection pooling
Making Connection
To collect data from a public resource, we need to establish connection with it first. Most of the web is served over HTTP protocol, which is rather simple: we (the client) send a request for a specific document to the website (the server), once the server processes our request it replies with the requested document - a very straight forward exchange!

As you can see in this illustration: we send a request object, which consists of method (aka type), location and headers, in turn we receive a response object, which consists of status code, headers and document content itself.
HTTP Clients in Ruby
Ruby has many HTTP client packages that implement this logic: Faraday, Httparty and Typhoeus.
In this article we'll focus on Typhoeus as it's the most feature rich client with two killer features: parallel connections and HTTP2 protocol support. However, most of http clients can be used almost interchangeably.
[% info "To experiment and follow along in ruby we recommend installing interactive ruby shell irb, which is a great way to explore a new web scraping environment: we can make inline requests and analyze returned objects to better understand our http client and the protocol itself." %]
Next, let's take Typhoeus for a spin and explore HTTP protocol basics!
Understanding Requests and Responses
When it comes to web-scraping we don't exactly need to know every little detail about http requests and responses, however it's good to have a general overview and to know which parts of this protocol are especially useful in web-scraping. Let's take a look at exactly that!
Request Method
Http requests are conveniently divided into few types that perform distinct function:
GETrequests are intended to request a document.POSTrequests are intended to request a document by sending a document.HEADrequests are intended to request documents meta information.PATCHrequests are intended to update a document.PUTrequests are intended to either create a new document or update it.DELETErequests are intended to delete a document.
When it comes to web scraping, we are mostly interested in collecting documents, so we'll be mostly working with GET and POST type requests. To add, HEAD requests can be useful in web scraping to optimize bandwidth - sometimes before downloading the document we might want to check its metadata whether it's worth the effort.
Request Location
To understand what is resource location, first we should take a quick look at URL's structure itself:

Here, we can visualize each part of a URL: we have protocol, which when it comes to HTTP is either http or https, then we have host, which is essentially address of the server, and finally we have the location of the resource and some custom parameters.
If you're ever unsure of a URL's structure, you can always fire up Ruby's interactive shell (irb in the terminal) and let it figure it out for you:
$ irb
irb(main):1:0> uri = URI.parse('http://www.domain.com/path/to/resource?arg1=true&arg2=false')
=> #<URI::HTTP http://www.domain.com/path/to/resource?arg1=true&arg2=false>
irb(main):2:0> uri.scheme
=> "http"
irb(main):3:0> uri.host
=> "www.domain.com"
irb(main):4:0> uri.path
=> "/path/to/resource"
irb(main):5:0> uri.query
=> "arg1=true&arg2=false"Request Headers
While it might appear like request headers are just minor metadata details in web scraping, they are extremely important. Headers contain essential details about the request, like: who's requesting the data? What type of data they are expecting? Getting these wrong might result in the web scraper being denied access.
Let's take a look at some of the most important headers and what they mean:
User-Agent is an identity header that tells the server who's requesting the document.
# example user agent for Chrome browser on Windows operating system:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36Whenever you visit a web page in your web browser identifies itself with a User-Agent string that looks something like "Browser Name, Operating System, Some version numbers". This helps the server to determine whether to serve or deny the client. In web scraping, we don't want to be denied content, so we have to blend in by faking our user agent to look like that one of a browser.
[% info "There are many online databases that contain latest user-agent strings of various platforms, like this Chrome user agent list by whatismybrowser.com" %]
Cookie is used to store persistent data. This is a vital feature for websites to keep tracking of user state: user logins, configuration preferences etc. Cookies are a bit out of scope of this article, but we'll be covering them in the future.
Accept headers (also Accept-Encoding, Accept-Language etc.) contain information about what sort of content we're expecting. Generally when web-scraping we want to mimic this of one of the popular web browsers, like Chrome browser use:
text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8[% info "For more, see list of default Accept header values" %]
X- prefixed headers are special custom headers. These are important to keep an eye on when web scraping, as they might configure important functionality of the scraped website/webapp.
These are a few of most important observations, for more see extensive full documentation page: MDN HTTP Headers
Response Status Code
Conveniently, all HTTP responses come with a status code that indicates whether this request is a success, failure or some alternative action is requested (like request to authenticate). Let's take a quick look at status codes that are most relevant to web scraping:
- 200 range codes generally mean success!
- 300 range codes tend to mean redirection - in other words if we request content at
/product1.htmlit might be moved to a new location/products/1.htmland server would inform us about that. - 400 range codes mean request is malformed or denied. Our web scraper could be missing some headers, cookies or authentication details.
- 500 range codes typically mean server issues. The website might be unavailable right now or is purposefully disabling access to our web scraper.
[% info "For more on http status codes, see documentation: HTTP Status definitions by MDN" %]
Response Headers
When it comes to web scraping, response headers provide some important information for connection functionality and efficiency. For example, Set-Cookie header requests our client to save some cookies for future requests, which might be vital for website functionality. Other headers such as Etag, Last-Modified are intended to help client with caching to optimize resource usage.
[% info "For the entire list of all HTTP headers, see MDN HTTP Headers" %]
Finally, just like with request headers, headers prefixed with an X- are custom web functionality headers.
We took a brief overlook of core HTTP components, and now it's time we give it a go and see how HTTP works in practical Ruby!
Making GET Requests
Now that we're familiar with the HTTP protocol and how it's used in web-scraping let's take a look of how we access it in Ruby's Typhoeus package.
Let's start off with a basic GET request:
require 'typhoeus'
response = Typhoeus.get(
"https://httpbin.dev/headers",
followlocation: true,
)
puts "request/url:\n #{response.request.url}" # request that resulted in this response
puts "body:\n #{response.body}"
puts "code:\n #{response.code}" # status code of response, e.g. 200
puts "headers:\n #{response.headers}" # response headers indicating metadata about response
puts "elapsed:\n #{response.total_time}" # total time elapsedHere we're using [%url https://httpbin.dev/ %] HTTP testing service, in this case we're using /headers endpoint which shows request headers the server received from us. One particular thing to note here is followlocation: true argument which ensures that our scraper will follow url redirects if server has moved the content somewhere else.
When run, this script should print basic details about our made request:
request/url:
https://httpbin.dev/headers
body:
{
"headers": {
"Accept": "*/*",
"Host": "httpbin.dev",
"User-Agent": "Typhoeus - https://github.com/typhoeus/typhoeus",
}
}
code:
200
headers:
{"date"=>"Thu, 17 Feb 2022 12:41:37 GMT", "content-type"=>"application/json", "content-length"=>"209", "server"=>"gunicorn/19.9.0", "access-control-allow-origin"=>"*", "access-control-allow-credentials"=>"true"}
elapsed:
1.464545Making POST requests
Sometimes our web-scraper might need to submit some sort of forms to retrieve HTML results. For example, search queries often use POST requests with query details as either JSON or Formdata values:
require 'typhoeus'
# POST formdata
response = Typhoeus.post(
"https://httpbin.dev/post",
followlocation: true,
body: {"query" => "cats", "page" => 1},
)
# POST json
require 'json'
response = Typhoeus.post(
"https://httpbin.dev/post",
followlocation: true,
headers: {"Content-Type": "application/json"},
body: {"query": "cats", "page": 1}.to_json,
)Ensuring Headers
As we've covered before our requests must provide metadata about themselves which helps server determine what content to return. Often, this metadata can be used to identify web scrapers and block them. Modern web browsers automatically include specific metadata details with every request so if we wish to not stand out as a web scraper we should replicate this behavior.
Primarily, User-Agent and Accept headers are often dead giveaways so we should set them some common values:
require 'typhoeus'
response = Typhoeus.get(
"https://httpbin.dev/headers",
followlocation: true,
headers: {
# Chrome browser User-Agent and Accept headers:
'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
},
)
puts "server got headers:\n #{response.body}" Tracking cookies
Sometimes when web-scraping we care about persistent connection state. For website where we need to login or configure website (like change currency) cookies are vital part of web scraping process.
Since Typhoeus is using curl behind the scenes it has full cookie support implemented through file-based tracking:
require 'typhoeus'
resp = Typhoeus.get(
"https://httpbin.dev/cookies/set/foo/bar",
followlocation: true,
# cookies filename where cookies will be READ from
cookiefile: "cookies.jar",
# cookiejar filename where cookies will be SAVED to
cookiejar: "cookies.jar",
)
print resp.bodyIn the example above, we're using httpbin.dev's /cookies endpoint to set some cookies for the session. Once cookies are set we're being redirected to a page that displays sent cookies:
{
"cookies": {
"foo": "bar"
}
}published_at: 2022-01-01
Now that we know our way around HTTP in Ruby and Typhoeus let's take a look at connection speed! How can we make these connections faster and more efficient?
Parallel Requests
Since HTTP protocol is data exchange protocol between two parties there's a lot of waiting involved. In other words when our client sends a request it needs to wait for it to travel all the way to the server and comeback which stalls our program. Why should our program sit idly and wait for request to travel around the globe? This is called an IO (input/output) block.
In Ruby's Typhoeus we can achieve parallel requests by using special scheduler called Hydra. We can either apply callback functions to requests and schedule them:
require 'typhoeus'
$hydra = Typhoeus::Hydra.new(max_concurrency: 10)
urls = [
"https://httpbin.dev/links/4/0",
"https://httpbin.dev/links/4/1",
"https://httpbin.dev/links/4/2",
"https://httpbin.dev/links/4/3",
]
for url in urls
request = Typhoeus::Request.new(url)
request.on_complete do |response|
puts "#{response.request.url} got #{response.body}"
end
$hydra.queue(request)
end
$hydra.runor alternatively, we can gather requests and execute them together:
require 'typhoeus'
$hydra = Typhoeus::Hydra.new(max_concurrency: 10)
def pararell_requests(requests)
for request in requests
$hydra.queue(request)
end
$hydra.run
return requests.map { |request|
request.response
}
end
urls = [
"https://httpbin.dev/links/4/0",
"https://httpbin.dev/links/4/1",
"https://httpbin.dev/links/4/2",
"https://httpbin.dev/links/4/3",
]
responses = pararell_requests(
urls.map{|url| Typhoeus::Request.new(url)}
)
for response in responses
puts "#{response.request.url} got #{response.body}"
endBoth of these approaches have their benefits: callbacks can be easier to optimize for speed while gathering is often much easier to work with. Either way, using parallel requests can speed up our web scrapers from tens to thousands of times so it's a must for any bigger scrapers!
Now that we're familiar and comfortable with HTTP protocol in Ruby's Typhoeus let's take a look how can we make sense from the HTML data we're retrieving. In the next section we'll take a look at HTML parsing using CSS and XPATH selectors.
Parsing HTML: Nokogiri
Retrieving HTML documents is only one part of web scraping process - we also have to parse them for data we're looking for. Luckily, the HTML format is designed to be machine parsable, so we can take advantage of this and use special CSS or XPATH selector languages to find exact parts of the page to extract.
We've covered both CSS and XPATH selectors in great detail previous articles:
In Ruby, the most popular package for these selectors is Nokogiri. Let's take a quick look how can we use it to find our data.
Nokogiri is a full feature XML and HTML parser. Let's take a look at some practical examples of using CSS and XPATH selectors:
require 'nokogiri'
html_doc = Nokogiri::HTML(
'<div class="links">
<a href="https://twitter.com/@scrapfly_dev">Twitter</a>
<a href="https://www.linkedin.com/company/scrapfly/">LinkedIn</a>
</div>'
)
# we can extra nodes text:
puts html_doc.css('div').text
# or nodes attributes:
puts html_doc.css('div').attribute('class')
# or xpath:
puts html_doc.xpath('//div/a[contains(@href,"twitter")]/@href').text
# we can also iterate through multiple nodes
for link in html_doc.css('a')
puts link.text
endIn the example above we see that Nokogiri features all parsing features a web scraper might require: selecting node's text and attribute values as well as supporting multiple node selection!
Let's put this parsing knowledge to use in an example project. In the next section we'll combine Typhoeus and Nokogiri to scrape jobs of indeed.com!
Putting It All Together: indeed.com scraper
To solidify our knowledge of web scraping in Ruby let's write a short web scraper for [%url https://www.indeed.com %].
First, we should take a look at the job listings page and design our scraping strategy:
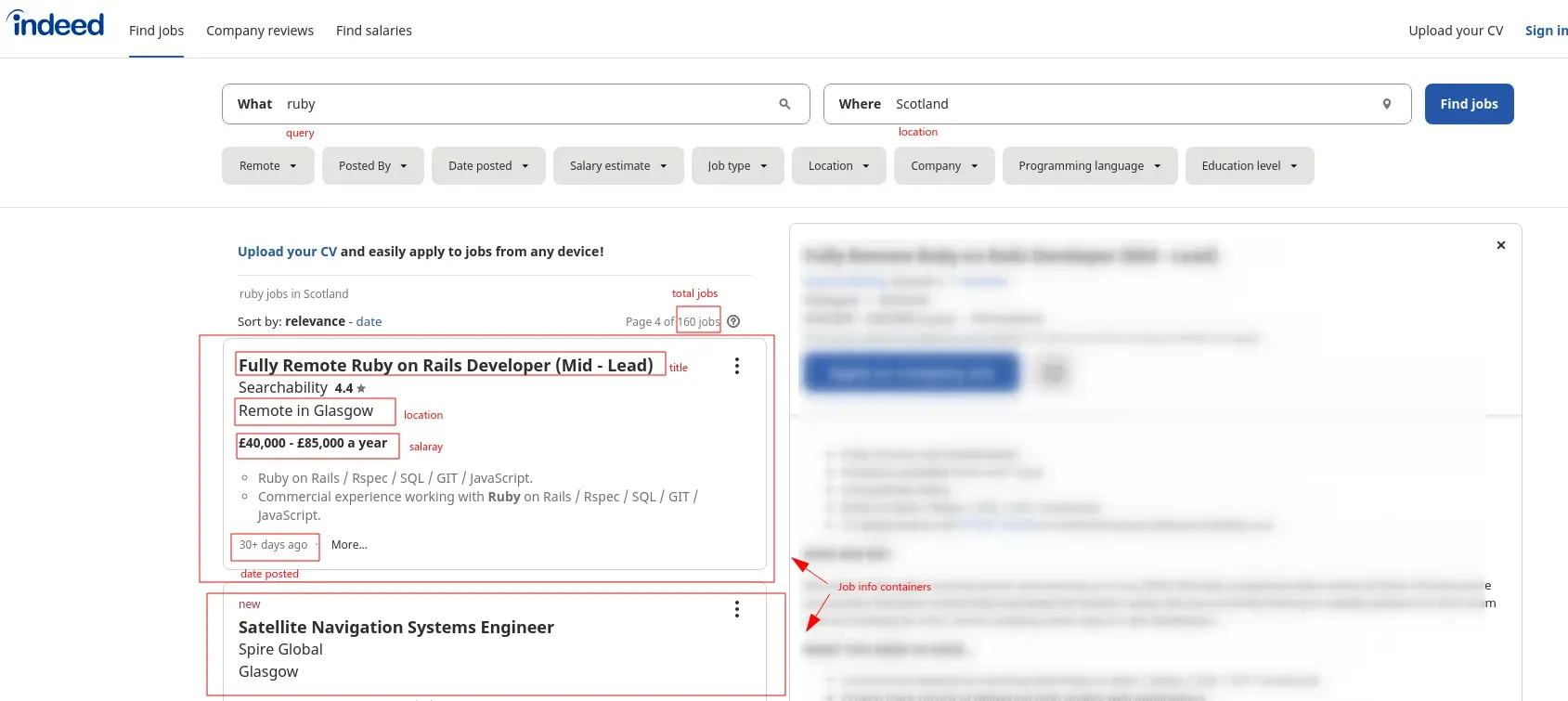
With this markup we can design our scraping and html parsing algorithms. Our general algorithm will look something like this:
- Go to [%url "https://uk.indeed.com/jobs?q=ruby&l=Scotland&start\=10" %]
Here note that we can replicate search page by using url parameters:
qfor query,lfor location andstartfor page offset. - Collect job information from each of the job info containers: title, location, company and resource urls
- Find total amount of pages
- Collect job information from following pages
For this we'll be using simple functional programming script with the tools we've covered in this article: Typhoeus for http connections and Nokogiri for parsing.
Let's start off with our script skeleton that defined all the utils we'll be using and the final run function:
require 'typhoeus'
require 'nokogiri'
require 'json'
$hydra = Typhoeus::Hydra.new(max_concurrency: 20)
# 1.
def parallel_requests(requests)
# helper function that executes multiple requests in parallel
for request in requests
$hydra.queue(request)
end
$hydra.run
return requests.map { |request|
request.response
}
end
# 2.
def run(query, location)
# main function which runs our scraper
# since our scraper doesn't know how many results are there in total we must
# scrape the first page of the query:
results, total_pages = scrape_jobs_page(query, location)
# once we have total pages we can then scrape the remaining pages in parallel:
results.concat(
scrape_jobs_page(query, location, 10, total_pages)[0]
)
puts "scraped #{results.length} results"
# output results of all pages as nicely formatted json:
return JSON.pretty_generate(results)
end
# call our scrape loop:
run('ruby', 'Scotland')Here, the first we do is define our global Hydra engine object which we'll later use to schedule requests in parallel. Then we define our run() function that implements core scraping loop logic.
The key ingredient here is a common web scraping idiom for scraping pagination: scrape first page and figure out how many pages are there, then scrape remaining pages in parallel! This technique provides significant web scraping speed boost.
Finally, we have two functions that implement the actual scraping logic:
parse_jobs_page- Extracts job listing data using Nokogiri and a mixture of CSS and XPATH selectors.scrape_jobs_page- Scrapes all jobs for given search query, location and page number.
Let's implement them to complete our scraper:
require 'typhoeus'
require 'nokogiri'
require 'json'
$hydra = Typhoeus::Hydra.new(max_concurrency: 20)
def parallel_requests(requests)
# helper function that executes multiple requests in parallel
requests.each do |request|
$hydra.queue(request)
end
$hydra.run
requests.map do |request|
request.response
end
end
# -------------------------------------------------------------------
# NEW CODE
def parse_jobs_page(response)
##
# finds job listing data in job listing page HTML
# e.g. https://uk.indeed.com/jobs?q=ruby&l=Scotland&start=10
puts "#{response.request.url} got #{response.code}"
tree = Nokogiri::HTML(response.body)
jobs = []
base_url = response.request.url
# to accurately extract jobs first we need to find job boxes
tree.css('a.result').each do |job|
jobs.push({
"title": job.css('h2').text,
"company": job.css('.companyOverviewLink').text,
"location": job.css('.companyLocation').text,
"date": job.xpath(".//span[contains(@class,'date')]/text()").text,
# turn urls to absolute urls (include domain name)
"url": base_url + job.xpath('@href').text,
"company_url": base_url + job.xpath('.//a[contains(@class,"companyOverviewLink")]/@href').text
})
end
# we can extract job count from "Page N of N jobs" string using regular expressions:
total_jobs = Integer(/(\d+) jobs/.match(tree.css('#searchCountPages').text)[1])
[jobs, total_jobs]
end
def scrape_jobs_page(query, location, offset = 0, limit = 10)
##
# scrapes jobs of a given query, location and pagination range
# e.g. offset=0 and limit=100 will scrape first 100 results
requests = []
# first we create all of the request objects for the request page range
(offset + 10..limit).step(10).each do |i|
puts "scheduling: https://uk.indeed.com/jobs?q=#{query}&l=#{location}&start=#{i}"
requests.push(
Typhoeus::Request.new(
url = "https://uk.indeed.com/jobs?q=#{query}&l=#{location}&start=#{i}",
followlocation: true,
# NOTE: here we are using Chrome browser User-Agent and Accept headers to prevent being blocked
headers: {
'User-Agent' => 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
}
)
)
end
# then we execute these request in parallel:
responses = parallel_requests(requests)
results = []
# and finally parse job data from all of the results:
responses.each do |response|
found, _ = parse_jobs_page(response)
results.concat(found)
end
[results, total_results]
end
# ---------------------------------------------------------------------------
def run(query, location)
##
# main function which runs our scraper
# since our scraper doesn't know how many results are there in total we must
# scrape the first page of the query:
results, total_pages = scrape_jobs_page(query, location)
# once we have total pages we can then scrape the remaining pages in parallel:
results.concat(
scrape_jobs_page(query, location, 10, total_pages)[0]
)
puts "scraped #{results.length} results"
# output results of all pages as nicely formatted json:
JSON.pretty_generate(results)
end
# call our scrape loop:
run('ruby', 'Scotland')In the functions above, we used all the knowledge we've learned in this article:
- We used Nokogiri to extra parts of HTML using CSS and XPATH selectors
- We used
Hydrascheduler ofTyphoeusto execute multiple requests in parallel. - We ensure our scraper is not blocked by providing browser like headers to our requests.
If we run this script we should see results similar to:
[
{
"title": "Software Development Engineer - PXF Team",
"url": "https://uk.indeed.com/jobs?q=ruby&l=Scotland&start=10/rc/clk?jk=c46386f2a2b68d2e&fccid=fe2d21eef233e94a&vjs=3",
"company": "Amazon Dev Centre(Scotland)Ltd",
"company_url": "https://uk.indeed.com/jobs?q=ruby&l=Scotland&start=10/cmp/Amazon.com",
"location": "Edinburgh",
"date": "30+ days ago"
},
{
"title": "Senior Software Architect",
"url": "https://uk.indeed.com/jobs?q=ruby&l=Scotland&start=10/rc/clk?jk=68588a02b773cfec&fccid=643a553ccd7fba02&vjs=3",
"company": "GE Digital",
"company_url": "https://uk.indeed.com/jobs?q=ruby&l=Scotland&start=10/cmp/GE-Digital",
"location": "Edinburgh EH3 5DA",
"date": "8 days ago"
},
...
]Using these existing tools in Ruby's ecosystem we wrote a full, fast scraper in few lines of code but skipped major pain points of web scraping: error handling and retries. Since we're working with an internet source we can never be sure of its stability and accessibility. Sometimes the website might be down, or our scraper can be identified and blocked from accessing the website.
To improve the stability and the success chance of our scrapers let's take a look at another tool: ScrapFly's middleware!
ScrapFly
Web scraping with Ruby can be surprisingly accessible however scaling up Ruby scrapers can be difficult due to lacking infrastructure in Ruby language for bypass blocking and scaling. This is where Scrapfly can lend a hand!

Let's take a look how can we use ScrapFly's API to scrape content with all of these features in Ruby!
require 'typhoeus'
require 'json'
$SCRAPFLY_KEY = 'YOUR-SCRAPFLY-KEY'
def scrapfly_request(
url,
# whether to use browser emulation to render javascript
render_js: false,
# if render_js is enabled we can also explicitly wait for an element to appear
wait_for_selector: nil,
# we can enable "anti scraping protection" solution
asp: false,
# we can set geographical location
country: 'us',
# we can choose proxy from 3 different pools:
proxy_pool: 'public_datacenter_pool' # or public_mobile_pool or public_residential_pool
)
Typhoeus::Request.new(
'https://api.scrapfly.io/scrape',
params: {
'key': $SCRAPFLY_KEY,
'url': url,
'asp': asp,
'render_js': render_js,
'wait_for_selector': wait_for_selector,
'country': country,
'proxy_pool': proxy_pool
}
)
end
response = scrapfly_request(
'https://uk.indeed.com/?r=us',
render_js: true
).run
data = JSON.parse(response.body)
puts data['result']['content'] # rendered response html
puts data['result']['response_headers'] # response headers
puts data['result']['cookies'] # response cookies
puts data['config'] # request infoIn the example above, we define a simple factory function that creates ScrapFly requests given various functionality parameters such as proxy settings, javascript rendering and other ScrapFly features!
For more features, usage scenarios and other info see ScrapFly's documentation!
Summary
In this extensive tutorial we covered web scraping basics in Ruby. We've explored a powerful HTTP client library Typhoeus which uses libcurl for feature rich, parallel requests in Ruby. Further, we looked into Nokogiri - a powerful HTML parsing library which allows us to use CSS and XPATH selectors to extract data we need from HTML documents. Finally, we've solidified our knowledge with a real life web scraping example and scraped job listings of [%url https://www.indeed.com %]!
We finished off the article by taking a look at ScrapFly's web scraping service - an API that solves many web scraping complexities. Check out ScrapFly for free today!


