

In this tutorial, we'll take a look at how to scrape Wellfound.com (previously angel.co) - a major directory for tech startup companies and job listing data.
Wellfound is a popular web scraping target for data related to jobs and tech industry. In this guide we'll cover job listing and company information scraping which consists of data fields like:
- Company overview like funding details, performance and culture
- Funding details
- Job listings
We'll be using Python together with hidden web data scraping technique to scrape Wellfound in just a few lines of code. However, since Wellfound is notorious for blocking all web scrapers we'll be using Scrapfly SDK to bypass their anti-scraping protection. Let's dive in!
Key Takeaways
Learn to scrape Wellfound startup data using Python with GraphQL reverse engineering, Apollo state parsing, and anti-blocking techniques for comprehensive tech industry analysis.
- Reverse engineer Wellfound's GraphQL-powered data by extracting Apollo state from
__NEXT_DATA__script tags and parsing complex graph structures - Extract structured startup data including company information, funding details, and job listings from tech directory using graph node unpacking
- Implement pagination handling and search parameter management for comprehensive startup data collection across multiple pages
- Configure proxy rotation and fingerprint management to avoid detection and rate limiting on protected startup directory sites
- Use specialized tools like ScrapFly for automated Wellfound scraping with anti-blocking features and concurrent processing
- Implement data validation and error handling for reliable startup information extraction from complex GraphQL data structures
Why Scrape Wellfound?
Wellfound (previously AngelList) contains loads of data related to tech startups. By scraping details like company information, employee data, company culture, funding and jobs we can create powerful business intelligence datasets. This can be used for competitive advantage or general market analysis. Job data and company contacts are also used to generate business leads by recruiters for growth hacking.
For more on scraping use cases see our extensive web scraping use case article
Project Setup
In this guide we'll be using Python (3.7+) and ScrapFly SDK package - which will allow us to bypass vast anti-scraping technologies used by Wellfound to retrieve the public HTML data.
Optionally, for this tutorial, we'll also use loguru - a pretty logging library that'll help us keep track of what's going on via nice colorful logs.
These packages can be easily installed via pip command:
$ pip install scrapfly-sdk loguruWhy are we using ScrapFly?
Scraping Wellfound isn't particularly difficult but it can be difficult to scale up web scraping projects like this and this is where Scrapfly can lend a hand!

Wellfound uses many anti-scrape protection technologies to prevent automated access to their public data. So, to access it we'll be using ScrapFly's Anti Scraping Protection Bypass feature which can be enabled for any request in the Python SDK:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key='YOUR_SCRAPFLY_KEY')
result = client.scrape(ScrapeConfig(
url="https://wellfound.com/company/moxion-power-co",
# we need to enable Anti Scraping Protection bypass with a keyword argument:
asp=True,
))We'll be using this technique for every page we'll be scraping in this tutorial, let's take a look at how it all adds up!
Finding Wellfound Companies and Jobs
Let's start our Wellfound scraper by taking a look at scraping the search system. This will allow us to find companies and jobs listed on the website.
The are several ways to find these details on wellfound.com but we'll take a look at the two most popular ones - searching by role and/or location:
- To find jobs by role
/role/<role name>endpoint can be used, for example: wellfound.com/role/python-developer - For location a similar
/location/<location name>endpoint is used, for example: wellfound.com/location/france - We can combine both using
/role/l/<role name>/<location name>endpoint, for example: https://wellfound.com/role/l/python-developer/san-francisco
In the video above we see URL progression of the search - now let's replicate it in our scraper code!
Scraping Wellfound Search
To scrape the search first let's take a look at the contents of a single search page. Where is the wanted data located and how can we extract it from the HTML page?
If we take a look at a search page like wellfound.com/role/l/python-developer/san-francisco and view-source of the page we can see search result data embedded in a javascript variable:

This is a common pattern for GraphQL-powered websites where page cache is stored as JSON in HTML. Angel.co in particular, is powered by Apollo graphQL
This is super convenient for our AngelList web scraper because we don't need to parse the HTML and can pick up all of the data at once. Let's see how to scrape this:
import json
import asyncio
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
from loguru import logger as log
def extract_apollo_state(result: ScrapeApiResponse):
"""extract apollo state graph from a page"""
data = result.selector.css("script#__NEXT_DATA__::text").get()
data = json.loads(data)
graph = data["props"]["pageProps"]["apolloState"]["data"]
return graph
async def scrape_search(session: ScrapflyClient, role: str = "", location: str = ""):
"""scrape wellfound.com search"""
# wellfound.com has 3 types of search urls: for roles, for locations and for combination of both
if role and location:
url = f"https://wellfound.com/role/l/{role}/{location}"
elif role:
url = f"https://wellfound.com/role/{role}"
elif location:
url = f"https://wellfound.com/location/{location}"
else:
raise ValueError("need to pass either role or location argument to scrape search")
log.info(f'scraping search of "{role}" in "{location}"')
scrape = ScrapeConfig(
url=url, # url to scrape
asp=True, # this will enable anti-scraping protection bypass
)
result = await session.async_scrape(scrape)
graph = extract_apollo_state(result)
return graphLet's run this code and see the results it generates:
Run code and example output
if __name__ == "__main__":
with ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=2) as session:
result = asyncio.run(scrape_search(session, role="python-developer"))
print(json.dumps(result, indent=2, ensure_ascii=False)){
"props": {
"pageProps": {
"page": null,
"role": "python-developer",
"apollo": null,
"apolloState": {
"data": {
...
"StartupResult:6427941": {
"id": "6427941",
"badges": [
{
"type": "id",
"generated": false,
"id": "Badge:ACTIVELY_HIRING",
"typename": "Badge"
}
],
"companySize": "SIZE_11_50",
...
"JobListingSearchResult:2275832": {
"autoPosted": false,
"atsSource": null,
"description": "**Company: Capitalmind**\n\nAt Capitalmind we ...",
"jobType": "full-time",
"liveStartAt": 1656420205,
"locationNames": {
"type": "json",
"json": ["Bengaluru"]
},
"primaryRoleTitle": "DevOps",
"remote": false,
"slug": "python-developer",
"title": "Python Developer",
"compensation": "₹50,000 – ₹1L",
...The first thing we can notice is that there are a lot of results in a very complicated format. The data we receive here is a data graph which is a data storage format where various data objects are connected by references. To make better sense of this, let's parse it into a familiar, flat structure instead:
def unpack_node_references(node, graph, debug=False):
"""
unpacks references in a graph node to a flat node structure:
>>> unpack_node_references({"field": {"id": "reference1", "type": "id"}}, graph={"reference1": {"foo": "bar"}})
{'field': {'foo': 'bar'}}
"""
def flatten(value):
try:
if value["type"] != "id":
return value
except (KeyError, TypeError):
return value
data = deepcopy(graph[value["id"]])
# flatten nodes too:
if data.get("node"):
data = flatten(data["node"])
if debug:
data["__reference"] = value["id"]
return data
node = flatten(node)
for key, value in node.items():
if isinstance(value, list):
node[key] = [flatten(v) for v in value]
elif isinstance(value, dict):
node[key] = unpack_node_references(value, graph)
return nodeAbove, we defined a function to flatten complex graph structures. It works by replacing all references with data itself. In our case, we want to get the Company object from the graph set and all of the related objects like jobs, people etc.:

In the illustration above, we can visualize reference unpacking better.
Next, let's add this graph parsing to our scraper as well as paging ability so we can collect nicely formatted company data from all of the job pages:
class JobData(TypedDict):
"""type hint for scraped job result data"""
id: str
title: str
slug: str
remtoe: bool
primaryRoleTitle: str
locationNames: Dict
liveStartAt: int
jobType: str
description: str
# there are more fields, but these are basic ones
class CompanyData(TypedDict):
"""type hint for scraped company result data"""
id: str
badges: list
companySize: str
highConcept: str
highlightedJobListings: List[JobData]
logoUrl: str
name: str
slug: str
# there are more fields, but these are basic ones
async def scrape_search(session: ScrapflyClient, role: str = "", location: str = "") -> List[CompanyData]:
"""scrape wellfound.com search"""
# wellfound.com has 3 types of search urls: for roles, for locations and for combination of both
if role and location:
url = f"https://wellfound.com/role/l/{role}/{location}"
elif role:
url = f"https://wellfound.com/role/{role}"
elif location:
url = f"https://wellfound.com/location/{location}"
else:
raise ValueError("need to pass either role or location argument to scrape search")
async def scrape_search_page(page_numbers: List[int]) -> Tuple[List[CompanyData], Dict]:
"""scrape search pages concurrently"""
companies = []
log.info(f"scraping search of {role} in {location}; pages {page_numbers}")
search_meta = None
async for result in session.concurrent_scrape(
[ScrapeConfig(url + f"?page={page}", asp=True, cache=True) for page in page_numbers]
):
graph = extract_apollo_state(result)
search_meta = graph[next(key for key in graph if "seoLandingPageJobSearchResults" in key)]
companies.extend(
[unpack_node_references(graph[key], graph) for key in graph if key.startswith("StartupResult")]
)
return companies, search_meta
# scrape first page
first_page_companies, pagination_meta = await scrape_search_page([1])
# scrape other pages
pages_to_scrape = list(range(2, pagination_meta["pageCount"] + 1))
other_page_companies, _ = await scrape_search_page(pages_to_scrape)
return first_page_companies + other_page_companiesRun code and example output
if __name__ == "__main__":
with ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=2) as session:
result = asyncio.run(scrape_search(session, role="python-developer"))
print(json.dumps(result, indent=2, ensure_ascii=False))[
{
"id": "6427941",
"badges": [
{
"id": "ACTIVELY_HIRING",
"name": "ACTIVELY_HIRING_BADGE",
"label": "Actively Hiring",
"tooltip": "Actively processing applications",
"avatarUrl": null,
"rating": null,
"__typename": "Badge"
}
],
"companySize": "SIZE_11_50",
"highConcept": "India's First Digital Asset Management Company",
"highlightedJobListings": [
{
"autoPosted": false,
"atsSource": null,
"description": "**Company: Capitalmind**\n\nAt Capitalmind <...truncacted...>",
"jobType": "full-time",
"liveStartAt": 1656420205,
"locationNames": {
"type": "json",
"json": [
"Bengaluru"
]
},
"primaryRoleTitle": "DevOps",
"remote": false,
"slug": "python-developer",
"title": "Python Developer",
"compensation": "₹50,000 – ₹1L",
"id": "2275832",
"isBookmarked": false,
"__typename": "JobListingSearchResult"
}
],
"logoUrl": "https://photos.wellfound.com/startups/i/6427941-9e4960b31904ccbcfe7e3235228ceb41-medium_jpg.jpg?buster=1539167505",
"name": "Capitalmind",
"slug": "capitalmindamc",
"__typename": "StartupResult"
},
...
]
If you are having troubles executing this code see the [Full Scraper Code](#full-scraper-code) section for full code
Our updated scraper now is capable of scraping all search pages and flattening graph data to something more readable. We could further parse it to get rid of unwanted fields but we'll leave this up to you.
One thing to notice here is that the company and job data is not complete. While there's a lot of data here, there's even more of it in the full dataset available on the /company/ endpoint pages. Next, let's take a look at how can we scrape that!
Scraping Wellfound Companies and Jobs
Company pages on wellfound.com contain even more details than we can see during search. For example, if we take a look at a page like wellfound.com/company/moxion-power-co we can see much more data available in the visible part of the page:
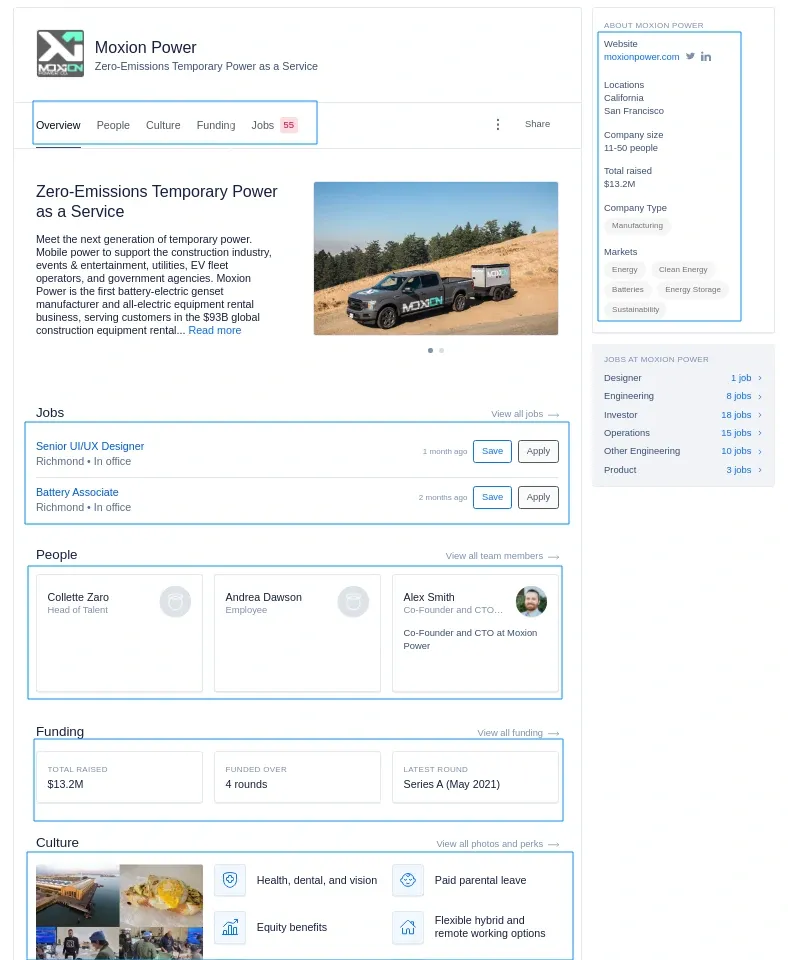
We can apply the same scraping techniques we used in scraping search for company pages as well. Let's take a look how:
def parse_company(result: ScrapeApiResponse) -> CompanyData:
"""parse company data from wellfound.com company page"""
graph = extract_apollo_state(result)
company = None
for key in graph:
if key.startswith("Startup:"):
company = graph[key]
break
else:
raise ValueError("no embedded company data could be found")
return unpack_node_references(company, graph)
async def scrape_companies(company_ids: List[str], session: ScrapflyClient) -> List[CompanyData]:
"""scrape wellfound.com companies"""
urls = [f"https://wellfound.com/company/{company_id}/jobs" for company_id in company_ids]
companies = []
async for result in session.concurrent_scrape([ScrapeConfig(url, asp=True, cache=True) for url in urls]):
companies.append(parse_company(result))
return companiesRun code and example output
if __name__ == "__main__":
with ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=2) as session:
result = await scrape_companies(["moxion-power-co"], session=session)
print(json.dumps(result[0], indent=2, ensure_ascii=False)){
"id": "8281817",
"__typename": "Startup",
"slug": "moxion-power-co",
"completenessScore": 92,
"currentUserCanEditProfile": false,
"currentUserCanRecruitForStartup": false,
"completeness": {"score": 95},
"name": "Moxion Power",
"logoUrl": "https://photos.wellfound.com/startups/i/8281817-91faf535f176a41dc39259fc232d1b4e-medium_jpg.jpg?buster=1619536432",
"highConcept": "Zero-Emissions Temporary Power as a Service",
"hiring": true,
"isOperating": null,
"companySize": "SIZE_11_50",
"totalRaisedAmount": 13225000,
"companyUrl": "https://www.moxionpower.com/",
"twitterUrl": "https://twitter.com/moxionpower",
"blogUrl": "",
"facebookUrl": "",
"linkedInUrl": "https://www.linkedin.com/company/moxion-power-co/",
"productHuntUrl": "",
"public": true,
"published": true,
"quarantined": false,
"isShell": false,
"isIncubator": false,
"currentUserCanUpdateInvestors": false,
"jobPreamble": "Moxion is looking to hire a diverse team across several disciplines, currently focusing on engineering and production.",
"jobListingsConnection({\"after\":\"MA==\",\"filters\":{\"jobTypes\":[],\"locationIds\":[],\"roleIds\":[]},\"first\":20})": {
"totalPageCount": 3,
"pageSize": 20,
"edges": [
{
"id": "2224735",
"public": true,
"primaryRoleTitle": "Product Designer",
"primaryRoleParent": "Designer",
"liveStartAt": 1653724125,
"descriptionSnippet": "<ul>\n<li>Conduct user research to drive design decisions</li>\n<li>Design graphics to be vinyl printed onto physical hardware and signage</li>\n</ul>\n",
"title": "Senior UI/UX Designer",
"slug": "senior-ui-ux-designer",
"jobType": "full_time",
...
}Just by adding a few lines of code, we collect each company's job, employee, culture and funding details. Because we used a generic way of scraping Apollo Graphql powered websites like wellfound.com we can apply this to many other pages with ease!
Let's wrap this up by taking a look at the full scraper code and some other tips and tricks when it comes to scraping this target.
FAQ
Is it legal to scrape Wellfound (aka AngelList)?
Yes. Wellfound's data is publicly available, and we're not extracting anything private. Scraping wellfound.com at respectful rates is both ehtical and legal. That being said, attention should be paid to GDRP compliance in the EU when working with scraped personal data such as people's (employee) identifiable data. For more, see our Is Web Scraping Legal? article.
How to find all company pages on Wellfound?
Finding company pages without job listings is a bit more difficult since wellfound.com doesn't provide a site directory or a sitemap for crawlers.
For this wellfound.com/search endpoint can be used. Alternatively, we can take advantage of public search indexes such as google.com or bing.com using queries like: site:wellfound.com inurl:/company/
Can Wellfound be crawled?
Yes. Web crawling is an alternative web scraping technique that explores website to find links and follow them. This is a great way to discover new pages and scrape them. However, as Wellfound is using hidden web data it's much easier to scrape it explicitly as covered in this tutorial.
Wellfound Scraping Summary
In this tutorial, we built an wellfound.com scraper. We've taken a look at how to discover company pages through AngelList's search functionality. Then, we wrote a generic dataset parser for GraphQL-powered websites that we applied to wellfound.com search result and company data parsing.
For this, we used Python with a few community packages included in the scrapfly-sdk and to prevent being blocked we used ScrapFly's API which smartly configures every web scraper connection to avoid being blocked. For more on ScrapFly see our documentation and try it out for free!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


