

Leboncoin.fr is one of the biggest websites for marketplace peer to peer markets in France. It's a major data target, so it can be challenging to scrape due to many anti-scraping challenges.
In this article, we'll explain how to web scrape leboncoin.fr without getting blocked. We'll also explain how to scrape data from leboncoin.fr search and ad pages. Let's dive in!
Key Takeaways
Master leboncoin scraper development with Python to extract marketplace data, property listings, and search results while bypassing anti-scraping measures for comprehensive French market analysis.
- Reverse engineer Leboncoin's API endpoints by intercepting browser network requests and analyzing JSON responses
- Extract structured marketplace data including prices, locations, and product details from French listings
- Implement pagination handling and search parameter management for comprehensive marketplace data collection
- Configure proxy rotation and fingerprint management to avoid detection and rate limiting
- Use specialized tools like ScrapFly for automated Leboncoin scraping with anti-blocking features
- Implement data validation and error handling for reliable French marketplace information extraction
Latest Leboncoin.fr Scraper Code
Why Scrape Leboncoin.fr?
Lebonocin.com includes millions of ads in various categories, from household essentials and vehicles to real estate offerings. Therefore, web scraping leboncoin can provide valuable insights by allowing for:
- Market Research
Listing data can be scraped and analyzed to get insights into trends, pricing patterns and product demand.
- Competitive Analysis
Scraping Leboncoin can help businesses gain a competitive edge through competitors' offering analytics.
- Price Tracking
Individuals looking to buy or sell products can use web scraping to track product prices over time to predict future price changes or score great deals.
- Inventory Management
Sellers can scrape Leboncoin to update their personal inventory with products available online on leboncoin.
Project Setup
In this leboncoin scraping guide, we'll use a few Python libraries:
Scrapfly-sdk- a web scraping API and Python SDK that allows for scraping at scale without blocking.parsel- a HTML parsing library
We'll be running our scrapers asynchronously using Python's asyncio which drastically increases web scraping speed.
All of these libraries can be installed using pip:
pip install scrapfly-sdk parselBypass Leboncoin Scraping Blocking Wtih ScrapFly
Leboncoin.fr is a highly protected website that can detect web scrapers. For example, let's try to web scrape leboncoin using a simple headless browser using Playwright browser automation library for Python:
from playwright.sync_api import sync_playwright
with sync_playwright() as playwight:
# Lanuch a chrome browser
browser = playwight.chromium.launch(headless=False)
page = browser.new_page()
# Go to leboncoin.fr
page.goto("https://www.leboncoin.fr")
# Take a screenshot
page.screenshot(path="screenshot.png")The website detected us as web scrapers and we were required to solve a captcha challenge:
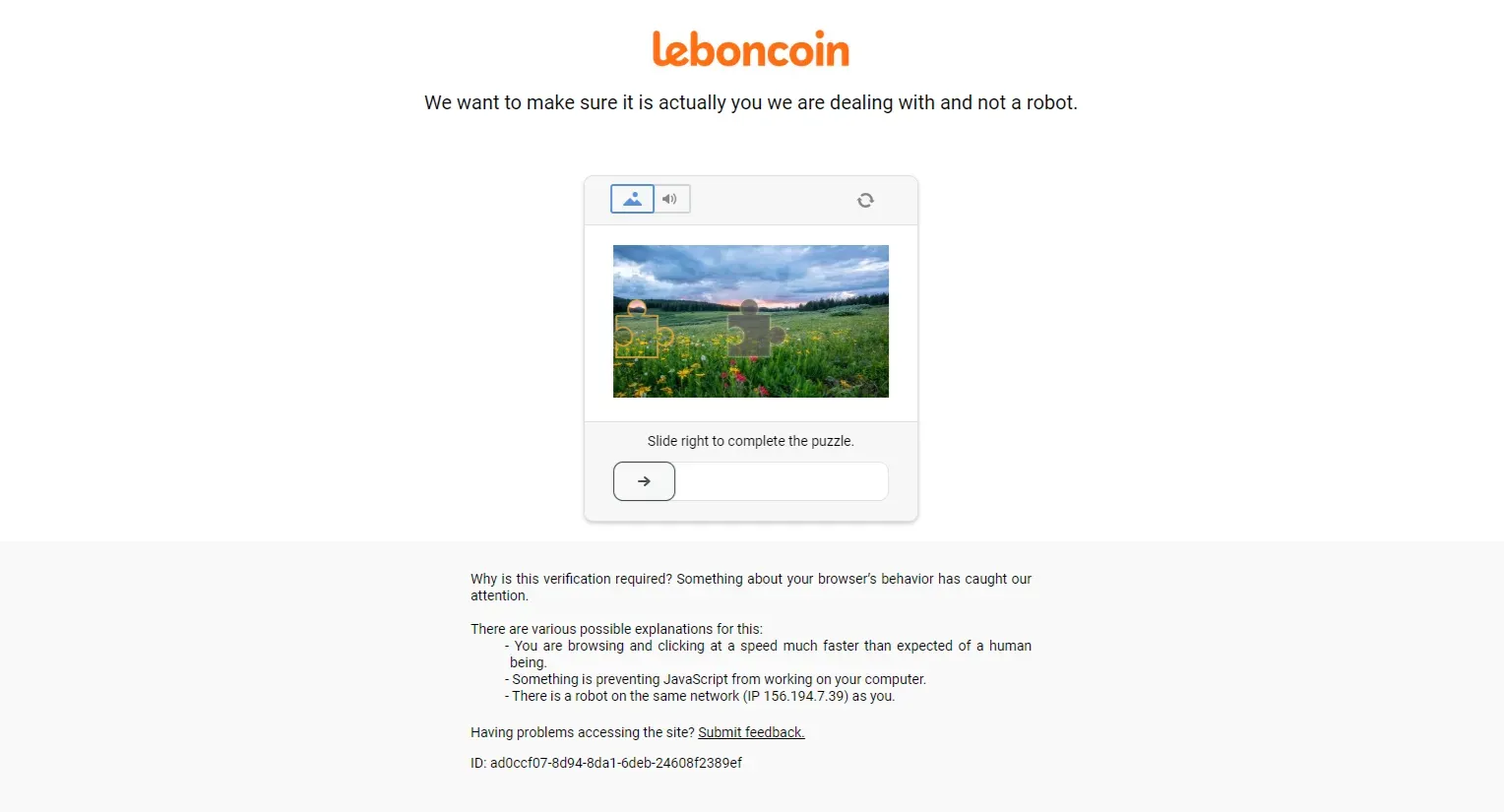
To bypass leboncoin.fr web scraping blocking checkout Scrapfly!

For more, explore web scraping API and its documentation.
For example, by using the ScrpaFly asp feature with the ScrapFly SDK. We can easily bypass leboncoin.fr scraper blocking:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
ScrapeConfig(
url="https://www.leboncoin.fr",
# Cloud headless browser similar to Playwright
render_js=True,
# Bypass anti scraping protection
asp=True,
# Set the geographical location to France
country="FR",
)
)
# Print the website's status code
print(api_response.upstream_status_code)
"200"Now that we can bypass leboncoin.fr blocking with ScrapFly, let's use it to create a leboncoin scraper.
How to Scrape Leboncoin Search?
To start, let's take a look at how searching works on leboncoin.fr.
First, if we go to the homepage and search for any keyword we'll see a result page similar to this:
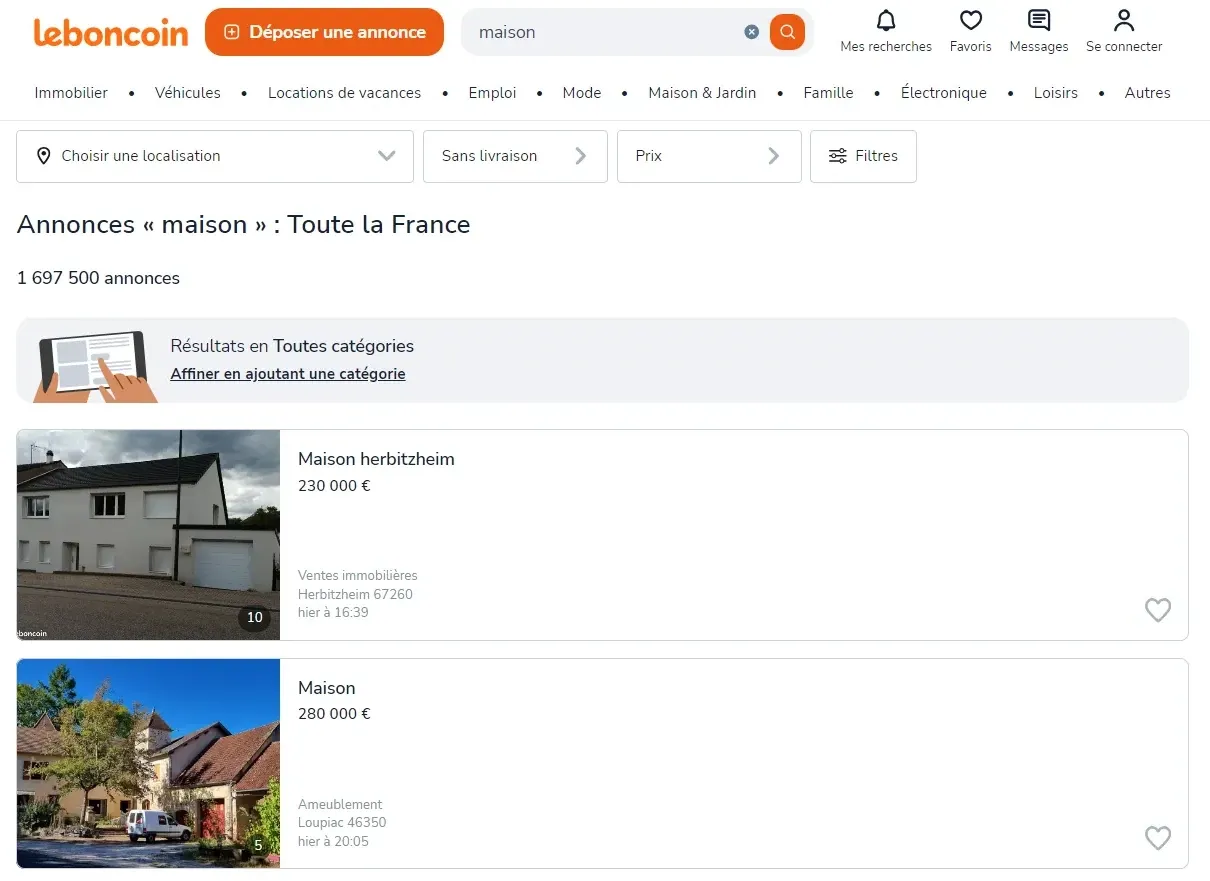
This example search page for real estate listings supports pagination with the following URL structure:
https://www.leboncoin.fr/recherche?text=maison&page=1We'll use this URL as our main search URL and use the page parameter to crawl over search pages.
We'll start by taking a look at how to scrape the first page, then we'll add paging to scrape the remainder.
As for result parsing, we'll use a hidden web data approach. Instead of using parsing selectors like Parsing HTML with Xpath or CSS selectors we'll get all the data in JSON directly from script tags in the HTML.
To locate this script tag, open browser developer tools by pressing the F12 key. Then, scroll down the page till you find the script tag with the __NEXT_DATA__ ID:
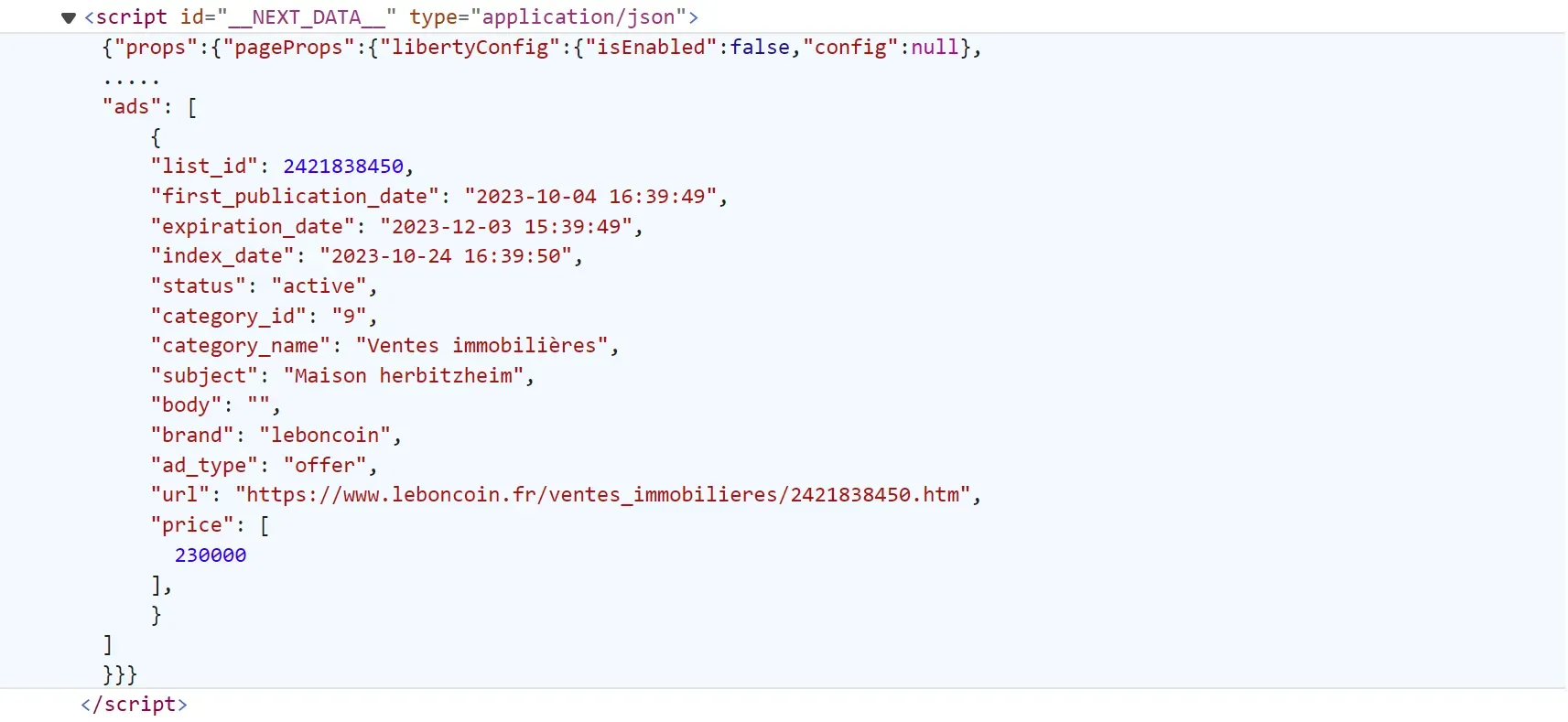
We'll select this script tag from the HTML and extract its data within our scraper:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
import asyncio
from typing import Dict, List
import json
SCRAPFLY = ScrapflyClient(key="Your API key")
# scrapfly config
BASE_CONFIG = {
# bypass web scraping blocking
"asp": True,
# set the proxy location to France
"country": "fr",
}
def parse_search(result: ScrapeApiResponse):
"""parse search result data from nextjs cache"""
# select the __NEXT_DATA__ script from the HTML
next_data = result.selector.css("script[id='__NEXT_DATA__']::text").get()
# extract ads listing data from the search page
ads_data = json.loads(next_data)["props"]["pageProps"]["initialProps"]["searchData"]["ads"]
return ads_data
async def scrape_search(url: str) -> List[Dict]:
"""scrape leboncoin search"""
print(f"scraping search {url}")
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
search_data = parse_search(first_page)
# print the data in JSON format
print(json.dumps(search_data, indent=2))
# run the scraping search function
asyncio.run(scrape_search(url="https://www.leboncoin.fr/recherche?text=coffe"))Here, we use the parse_search function to parse and select the search data from the HTML. Next, we use the scrape_search to scrape the first search page using ScrapFly. Finally, we print the results in JSON format and run the code using asyncio.
The above leboncoin scraper can scrape data from the first search page only. Let's modify it to scrape more than one page:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
from typing import Dict, List
import asyncio
import json
SCRAPFLY = ScrapflyClient(key="Your API key")
# scrapfly config
BASE_CONFIG = {
# bypass web scraping blocking
"asp": True,
# set the proxy location to France
"country": "fr",
}
def parse_search(result: ScrapeApiResponse):
"""parse search result data from nextjs cache"""
# select the __NEXT_DATA__ script from the HTML
next_data = result.selector.css("script[id='__NEXT_DATA__']::text").get()
# extract ads listing data from the search page
ads_data = json.loads(next_data)["props"]["pageProps"]["initialProps"]["searchData"]["ads"]
return ads_data
async def scrape_search(url: str, max_pages: int) -> List[Dict]:
"""scrape leboncoin search"""
print(f"scraping search {url}")
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
search_data = parse_search(first_page)
# add the ramaining pages in a scraping list
_other_pages = [
ScrapeConfig(f"{first_page.context['url']}&page={page}", **BASE_CONFIG)
for page in range(2, max_pages + 1)
]
# scrape the remaining pages concurrently
async for result in SCRAPFLY.concurrent_scrape(_other_pages):
ads_data = parse_search(result)
search_data.extend(ads_data)
print(json.dumps(search_data, indent=2))
# run the scraping search function
asyncio.run(scrape_search(url="https://www.leboncoin.fr/recherche?text=coffe", max_pages=2))Here, we add a max_pages parameter to the scrape_search function, which specifies the number of search pages to scrape. The scraping result is a list that contains all ad data found in two search pages:
Output
[
{
"list_id": 2421838450,
"first_publication_date": "2023-10-04 16:39:49",
"expiration_date": "2023-12-03 15:39:49",
"index_date": "2023-10-24 16:39:50",
"status": "active",
"category_id": "9",
"category_name": "Ventes immobilières",
"subject": "Maison herbitzheim",
"body": "",
"brand": "leboncoin",
"ad_type": "offer",
"url": "https://www.leboncoin.fr/ventes_immobilieres/2421838450.htm",
"price": [
230000
],
"price_cents": 23000000,
"images": {
"thumb_url": "https://img.leboncoin.fr/api/v1/lbcpb1/images/87/f2/79/87f2792c34241f74302c20f885bef5f64bb5fe13.jpg?rule=ad-thumb",
"small_url": "https://img.leboncoin.fr/api/v1/lbcpb1/images/87/f2/79/87f2792c34241f74302c20f885bef5f64bb5fe13.jpg?rule=ad-small",
"nb_images": 10,
"urls": [
"https://img.leboncoin.fr/api/v1/lbcpb1/images/87/f2/79/87f2792c34241f74302c20f885bef5f64bb5fe13.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/d2/88/ee/d288ee39252a5537a84895e70ce44ce7bbb88b99.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/84/83/5f/84835fb2031622dfd6b843cc1b8c9161d0e1eb5c.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/11/71/1b/11711bc541bcc34a090a494010181ab28672c9bb.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/04/3c/59/043c592eb87d9ee94da30ab36effe5e806e2a7e5.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/98/74/88/98748874a6c5d78d7f327c6571ca19f58cb358e9.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/57/2f/b1/572fb1587f95cc45a6fc7cc50cb4129ca0708395.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/09/fa/d6/09fad6d55431fe742454888af559a2349f3c9df5.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/d1/13/46/d113467ec874d1ed9db91b38a620b0284c9532fa.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/db/e5/9d/dbe59dfeac1989211f01b9535d707d3c06ce6a49.jpg?rule=ad-image"
],
"urls_thumb": [
"https://img.leboncoin.fr/api/v1/lbcpb1/images/87/f2/79/87f2792c34241f74302c20f885bef5f64bb5fe13.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/d2/88/ee/d288ee39252a5537a84895e70ce44ce7bbb88b99.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/84/83/5f/84835fb2031622dfd6b843cc1b8c9161d0e1eb5c.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/11/71/1b/11711bc541bcc34a090a494010181ab28672c9bb.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/04/3c/59/043c592eb87d9ee94da30ab36effe5e806e2a7e5.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/98/74/88/98748874a6c5d78d7f327c6571ca19f58cb358e9.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/57/2f/b1/572fb1587f95cc45a6fc7cc50cb4129ca0708395.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/09/fa/d6/09fad6d55431fe742454888af559a2349f3c9df5.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/d1/13/46/d113467ec874d1ed9db91b38a620b0284c9532fa.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/db/e5/9d/dbe59dfeac1989211f01b9535d707d3c06ce6a49.jpg?rule=ad-thumb"
],
"urls_large": [
"https://img.leboncoin.fr/api/v1/lbcpb1/images/87/f2/79/87f2792c34241f74302c20f885bef5f64bb5fe13.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/d2/88/ee/d288ee39252a5537a84895e70ce44ce7bbb88b99.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/84/83/5f/84835fb2031622dfd6b843cc1b8c9161d0e1eb5c.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/11/71/1b/11711bc541bcc34a090a494010181ab28672c9bb.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/04/3c/59/043c592eb87d9ee94da30ab36effe5e806e2a7e5.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/98/74/88/98748874a6c5d78d7f327c6571ca19f58cb358e9.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/57/2f/b1/572fb1587f95cc45a6fc7cc50cb4129ca0708395.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/09/fa/d6/09fad6d55431fe742454888af559a2349f3c9df5.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/d1/13/46/d113467ec874d1ed9db91b38a620b0284c9532fa.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/db/e5/9d/dbe59dfeac1989211f01b9535d707d3c06ce6a49.jpg?rule=ad-large"
]
},
"attributes": [
{
"key": "profile_picture_url",
"value": "https://img.leboncoin.fr/api/v1/tenants/9a6387a1-6259-4f2c-a887-7e67f23dd4cb/domains/20bda58f-d650-462e-a72a-a5a7ecf2bf88/buckets/21d2b0bc-e54c-4b64-a30b-89127b18b785/images/profile/pictures/default/abb62201-581c-5c78-bd51-ded3b307ea80?rule=pp-small",
"values": [
"https://img.leboncoin.fr/api/v1/tenants/9a6387a1-6259-4f2c-a887-7e67f23dd4cb/domains/20bda58f-d650-462e-a72a-a5a7ecf2bf88/buckets/21d2b0bc-e54c-4b64-a30b-89127b18b785/images/profile/pictures/default/abb62201-581c-5c78-bd51-ded3b307ea80?rule=pp-small"
],
"value_label": "https://img.leboncoin.fr/api/v1/tenants/9a6387a1-6259-4f2c-a887-7e67f23dd4cb/domains/20bda58f-d650-462e-a72a-a5a7ecf2bf88/buckets/21d2b0bc-e54c-4b64-a30b-89127b18b785/images/profile/pictures/default/abb62201-581c-5c78-bd51-ded3b307ea80?rule=pp-small",
"generic": false
},
{
"key": "type_real_estate_sale",
"value": "ancien",
"values": [
"ancien"
],
"key_label": "Type de vente",
"value_label": "Ancien",
"generic": true
},
{
"key": "real_estate_type",
"value": "1",
"values": [
"1"
],
"key_label": "Type de bien",
"value_label": "Maison",
"generic": true
},
{
"key": "square",
"value": "167",
"values": [
"167"
],
"key_label": "Surface habitable",
"value_label": "167 m²",
"generic": true
},
{
"key": "rooms",
"value": "8",
"values": [
"8"
],
"key_label": "Nombre de pièces",
"value_label": "8",
"generic": true
},
{
"key": "energy_rate",
"value": "c",
"values": [
"c"
],
"key_label": "Classe énergie",
"value_label": "C",
"generic": true
},
{
"key": "ges",
"value": "c",
"values": [
"c"
],
"key_label": "GES",
"value_label": "C",
"generic": true
},
{
"key": "nb_floors_house",
"value": "2",
"values": [
"2"
],
"key_label": "Nombre de niveaux",
"value_label": "2",
"generic": true
},
{
"key": "nb_parkings",
"value": "2",
"values": [
"2"
],
"key_label": "Places de parking",
"value_label": "2",
"generic": true
},
{
"key": "outside_access",
"value": "",
"values": [
"terrace",
"garden"
],
"key_label": "Extérieur",
"value_label": "Terrasse, Jardin",
"values_label": [
"Terrasse",
"Jardin"
],
"generic": true
},
{
"key": "district_id",
"value": "67191",
"values": [
"67191"
],
"value_label": "67191",
"generic": false
},
{
"key": "district_visibility",
"value": "false",
"values": [
"false"
],
"value_label": "false",
"generic": false
},
{
"key": "district_type_id",
"value": "2",
"values": [
"2"
],
"value_label": "2",
"generic": false
},
{
"key": "district_resolution_type",
"value": "integration",
"values": [
"integration"
],
"value_label": "integration",
"generic": false
},
{
"key": "immo_sell_type",
"value": "old",
"values": [
"old"
],
"value_label": "old",
"generic": false
},
{
"key": "is_import",
"value": "false",
"values": [
"false"
],
"value_label": "false",
"generic": false
},
{
"key": "lease_type",
"value": "sell",
"values": [
"sell"
],
"value_label": "sell",
"generic": false
}
],
"location": {
"country_id": "FR",
"region_id": "1",
"region_name": "Alsace",
"department_id": "67",
"department_name": "Bas-Rhin",
"city_label": "Herbitzheim 67260",
"city": "Herbitzheim",
"zipcode": "67260",
"lat": 49.01082,
"lng": 7.07903,
"source": "address",
"provider": "here",
"is_shape": false,
"feature": {
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
7.07903,
49.01082
]
},
"properties": null
}
},
"owner": {
"store_id": "63584499",
"user_id": "3d95663f-b972-46c8-bc69-4791e99fa360",
"type": "private",
"name": "SYLVIE",
"no_salesmen": true,
"activity_sector": ""
},
"options": {
"has_option": true,
"booster": false,
"photosup": true,
"urgent": false,
"gallery": true,
"sub_toplist": true
},
"has_phone": false,
"is_boosted": true,
"similar": null
}
]We successfully got all listing data using Leboncoin's search. Next, let's take a look at how to scrape individual listing pages!
How to Scrape Leboncoin.fr Listing Ads?
Although listing data on search pages and listing pages is the same the location in the HTML differs. For this, we'll need to slightly change the object keys we use to obtain the hidden web data:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
from typing import Dict
import asyncio
import json
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
# scrapfly config
BASE_CONFIG = {
# bypass web scraping blocking
"asp": True,
# set the proxy location to France
"country": "fr",
}
def parse_ad(result: ScrapeApiResponse):
"""parse ad data from nextjs cache"""
next_data = result.selector.css("script[id='__NEXT_DATA__']::text").get()
# extract ad data from the ad page
ad_data = json.loads(next_data)["props"]["pageProps"]["ad"]
return ad_data
async def scrape_ad(url: str, _retries: int = 0) -> Dict:
"""scrape ad page"""
print(f"scraping ad {url}")
try:
result = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
ad_data = parse_ad(result)
except:
print("retrying failed request")
if _retries < 2:
return await scrape_ad(url, _retries=_retries + 1)
return ad_dataRun the code
async def run():
ad_data = []
to_scrape = [
scrape_ad(url)
for url in [
"https://www.leboncoin.fr/ad/ventes_immobilieres/2809308201",
"https://www.leboncoin.fr/ad/ventes_immobilieres/2820947069",
"https://www.leboncoin.fr/ad/ventes_immobilieres/2643327428"
]
]
for response in asyncio.as_completed(to_scrape):
ad_data.append(await response)
# save to JSON file
with open("ads.json", "w", encoding="utf-8") as file:
json.dump(ad_data, file, indent=2, ensure_ascii=False)
asyncio.run(run())As we did earlier, we use the parse_ad function to parse and select ad data from the listing page HTML. Next, we use the scrape_ad function to scrape the ad page using ScrapFly. Here is the result we got:
Output
{
"list_id": 2420410225,
"first_publication_date": "2023-10-01 20:05:18",
"index_date": "2023-10-24 20:05:18",
"status": "active",
"category_id": "19",
"category_name": "Ameublement",
"subject": "Maison",
"body": "",
"brand": "leboncoin",
"ad_type": "offer",
"url": "https://www.leboncoin.fr/ameublement/2420410225.htm",
"price": [
280000
],
"price_cents": 28000000,
"images": {
"thumb_url": "https://img.leboncoin.fr/api/v1/lbcpb1/images/1a/ed/21/1aed21614a7b1edc5d9a9a02f3d135c811dc7619.jpg?rule=ad-thumb",
"small_url": "https://img.leboncoin.fr/api/v1/lbcpb1/images/1a/ed/21/1aed21614a7b1edc5d9a9a02f3d135c811dc7619.jpg?rule=ad-small",
"nb_images": 5,
"urls": [
"https://img.leboncoin.fr/api/v1/lbcpb1/images/1a/ed/21/1aed21614a7b1edc5d9a9a02f3d135c811dc7619.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/12/20/31/1220318d179c49f33547549e79739d1c51bf7d3b.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/4a/3e/d5/4a3ed5340aee52828917e708771879abc5265318.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/a4/11/e9/a411e92fdf278bb19ac6b5f71e1f532165addda0.jpg?rule=ad-image",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/b0/e9/a9/b0e9a97b4b31b8ace3017b6b6f5b94a9b6ead4fe.jpg?rule=ad-image"
],
"urls_thumb": [
"https://img.leboncoin.fr/api/v1/lbcpb1/images/1a/ed/21/1aed21614a7b1edc5d9a9a02f3d135c811dc7619.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/12/20/31/1220318d179c49f33547549e79739d1c51bf7d3b.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/4a/3e/d5/4a3ed5340aee52828917e708771879abc5265318.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/a4/11/e9/a411e92fdf278bb19ac6b5f71e1f532165addda0.jpg?rule=ad-thumb",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/b0/e9/a9/b0e9a97b4b31b8ace3017b6b6f5b94a9b6ead4fe.jpg?rule=ad-thumb"
],
"urls_large": [
"https://img.leboncoin.fr/api/v1/lbcpb1/images/1a/ed/21/1aed21614a7b1edc5d9a9a02f3d135c811dc7619.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/12/20/31/1220318d179c49f33547549e79739d1c51bf7d3b.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/4a/3e/d5/4a3ed5340aee52828917e708771879abc5265318.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/a4/11/e9/a411e92fdf278bb19ac6b5f71e1f532165addda0.jpg?rule=ad-large",
"https://img.leboncoin.fr/api/v1/lbcpb1/images/b0/e9/a9/b0e9a97b4b31b8ace3017b6b6f5b94a9b6ead4fe.jpg?rule=ad-large"
]
},
"attributes": [
{
"key": "profile_picture_url",
"value": "https://img.leboncoin.fr/api/v1/tenants/9a6387a1-6259-4f2c-a887-7e67f23dd4cb/domains/20bda58f-d650-462e-a72a-a5a7ecf2bf88/buckets/21d2b0bc-e54c-4b64-a30b-89127b18b785/images/profile/pictures/default/45ac3135-adc5-5561-8b16-05abc480770e?rule=pp-small",
"values": [
"https://img.leboncoin.fr/api/v1/tenants/9a6387a1-6259-4f2c-a887-7e67f23dd4cb/domains/20bda58f-d650-462e-a72a-a5a7ecf2bf88/buckets/21d2b0bc-e54c-4b64-a30b-89127b18b785/images/profile/pictures/default/45ac3135-adc5-5561-8b16-05abc480770e?rule=pp-small"
],
"value_label": "https://img.leboncoin.fr/api/v1/tenants/9a6387a1-6259-4f2c-a887-7e67f23dd4cb/domains/20bda58f-d650-462e-a72a-a5a7ecf2bf88/buckets/21d2b0bc-e54c-4b64-a30b-89127b18b785/images/profile/pictures/default/45ac3135-adc5-5561-8b16-05abc480770e?rule=pp-small",
"generic": false
},
{
"key": "estimated_parcel_weight",
"value": "7493",
"values": [
"7493"
],
"value_label": "7493",
"generic": false
},
{
"key": "is_bundleable",
"value": "true",
"values": [
"true"
],
"value_label": "true",
"generic": false
},
{
"key": "purchase_cta_visible",
"value": "true",
"values": [
"true"
],
"value_label": "true",
"generic": false
},
{
"key": "negotiation_cta_visible",
"value": "true",
"values": [
"true"
],
"value_label": "true",
"generic": false
},
{
"key": "country_isocode3166",
"value": "FR",
"values": [
"FR"
],
"value_label": "FR",
"generic": false
},
{
"key": "shipping_type",
"value": "face_to_face",
"values": [
"face_to_face"
],
"value_label": "face_to_face",
"generic": false
},
{
"key": "shippable",
"value": "false",
"values": [
"false"
],
"value_label": "false",
"generic": false
},
{
"key": "is_import",
"value": "false",
"values": [
"false"
],
"value_label": "false",
"generic": false
}
],
"location": {
"country_id": "FR",
"region_id": "16",
"region_name": "Midi-Pyrénées",
"department_id": "46",
"department_name": "Lot",
"city_label": "Loupiac 46350",
"city": "Loupiac",
"zipcode": "46350",
"lat": 44.81746,
"lng": 1.46079,
"source": "city",
"provider": "here",
"is_shape": true,
"feature": {
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
1.46079,
44.81746
]
},
"properties": null
}
},
"owner": {
"store_id": "70139500",
"user_id": "25f78467-c640-4726-876d-878203a3bb26",
"type": "private",
"name": "Jacques",
"no_salesmen": true,
"activity_sector": ""
},
"options": {
"has_option": true,
"booster": false,
"photosup": false,
"urgent": false,
"gallery": false,
"sub_toplist": true
},
"has_phone": false,
"is_boosted": true,
"similar": null
}Cool - we are able to scrape leboncoin.fr data from both search and ad pages!
FAQ
Is it legal to scrape leboncoin.fr?
Yes, all ad data on leboncoin is public, so it's legal to scrape them as long as you keep your scraping rate reasonable. However, you should pay attention to the GDRP compliance in the EU when scraping personal data, such as seller's data. For more information, refer to our article on web scraping legality.
Is there a public API for leboncoin.fr?
Currently, there is no available public API for leboncoin.fr. However, scraping leboncoin.fr is straightforward and you can easily use it to create your own web scraping API.
How to avoid leboncoin.fr web scraping blocking?
There are many factors that lead to web scraping blocking including headers, IP addresses and security handshakes. To avoid leboncoin.fr web scraping blocking, you need to pay attention to these details. For more information, refer to our previous guide on scraping without getting blocked.
Can I scrape other European real estate sites with a similar approach?
Yes, many European real estate platforms use similar structures. You can apply the same hidden JSON data extraction technique to sites like Idealista, and ImmobilienScout24,Each site may require different anti-bot handling, but the core scraping approach remains the same.
Leboncoin.fr Scraping Summary
Leboncoin.fr is one of the most popular marketplaces for ads in France. Which is a highly protected website that can detect and block web scrapers, requiring the use of an anti-scraping solution.
In this article, we took a deep dive at how to scrape leboncoin.fr to get ad and search data. We have also seen how to avoid leboncoin web scraping blocking using ScrapFly.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


