

Background XHR calls often contain valuable data loaded when navigating web pages. But what about inspecting and modifying while scraping?
In this guide, we'll explore web scraping with Selenium Wire. We'll define what it is, how to install it, and how to use it to inspect and manipulate background requests. Let's get started!
Key Takeaways
Learn selenium wire to intercept requests and responses during web scraping, capture XHR calls, and modify network traffic for data extraction.
- Implement Selenium Wire for intercepting XHR calls and background requests during web scraping automation
- Configure request manipulation and response analysis for API endpoint discovery and data extraction
- Use request interception to bypass complex authentication and session management in web applications
- Implement request modification and header manipulation for advanced web scraping scenarios
- Use specialized tools like ScrapFly for automated request interception with anti-blocking features
- Configure request filtering and data extraction from JSON responses for structured data collection
What is Selenium Wire?
The selenium-wire library is a Python binding that extends the Selenium headless browser library. It uses the regular Selenium API, making the implementation code the same.
Selenium Wire captures all the outgoing background requests, allowing for:
- Inspecting the requests along with their configuration and responses.
- Manipulating the requests by modifying their configurations or limiting them.

What Are XHR Calls and Why Intercept Them?
Background XHR calls are HTTP requests activated while navigating websites using web browsers through different actions, such as:
- Scrolling down.
- Clicking on a specific button or link.
- Clicking on the next pagination button.
- Filtering the data using filter buttons.
- Searching for particular data.
The above actions activate specific API endpoints to load the requested data. In most cases, the data returned from these requests are in JSON. Therefore, it's more convenient to scrape the data directly from the XHR call response objects rather than parsing it from the HTML using selectors like XPath or CSS.
Background requests are regular API calls, commonly known as hidden APIs, with headers, body, cookies, and local storage. These APIs can be called directly by any HTTP client. However, they often contain complicated or comprehensive request configurations that are hard to replicate, like GraphQL. Therefore, using selenium-wire as a request interceptor by activating these requests from the browser makes it easier to get the data directly or copy their configuration.

How to Install Selenium Wire?
To install the selenium-wire library, all we have to do is execute the below pip command:
pip install selenium-wire
The above command will install the Selenium4 binaries along with the extra APIs required to inspect requests. It will also install the required driver binaries for the different browser types:
from seleniumwire import webdriver
# choose a specific browser driver
driver = webdriver.Chrome()
driver = webdriver.Firefox()
driver = webdriver.Edge()
Inspecting Response Objects
Let's start by creating a selenium-wire response interceptor. For this, we'll use web-scraping.dev/testimonials as our target website:
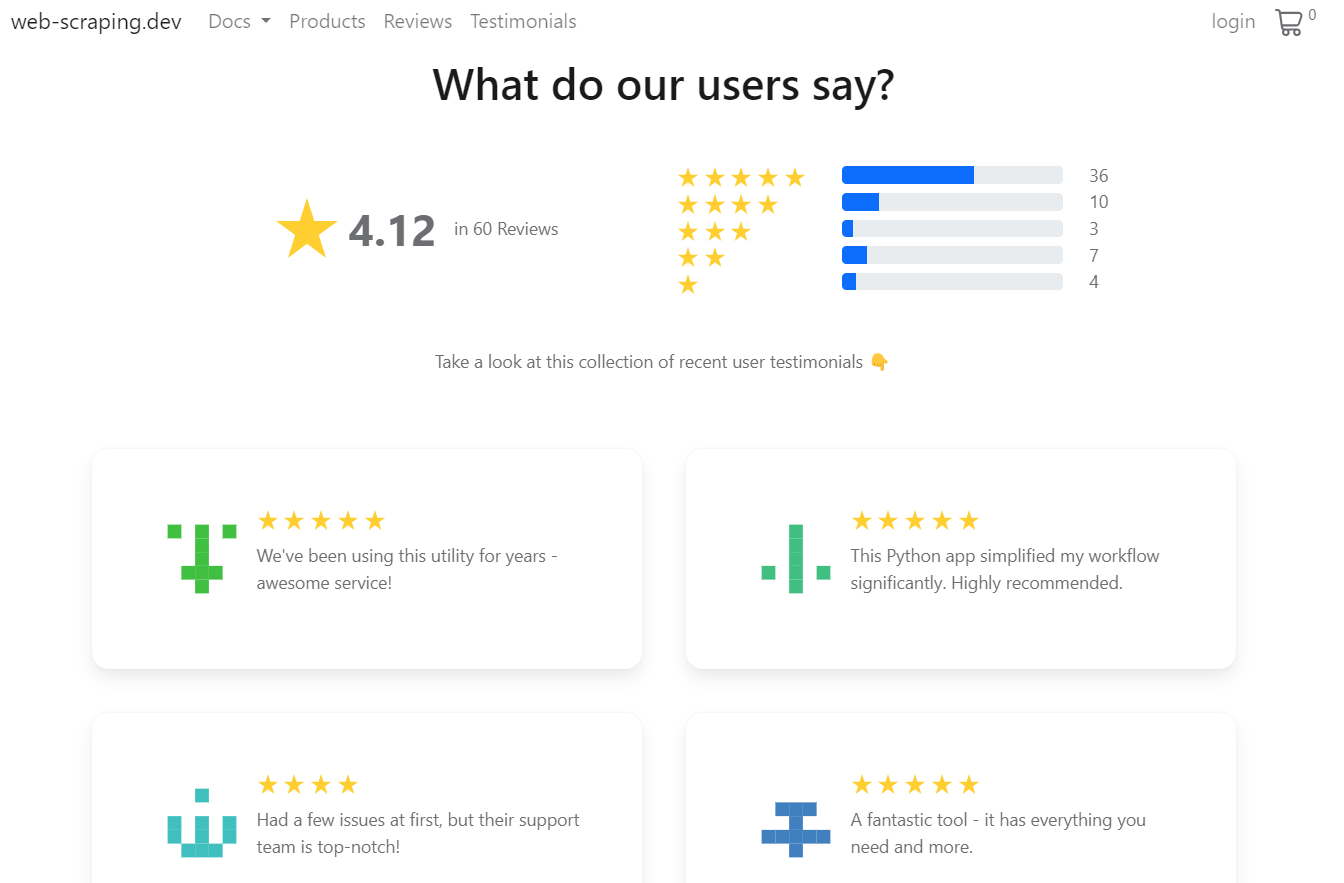
The above review data are loaded dynamically through background XHR calls, which get activated through scroll actions. First, we'll use a selenium-wire scraping code that requests the above page and scroll it:
from seleniumwire import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument("log-level=3") # disable logs
driver = webdriver.Chrome(options=options)
driver.get("https://web-scraping.dev/testimonials")
def scroll(driver: webdriver):
for i in range(0, 6):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
scroll(driver)
driver.quit()
Here, we use selenium-wire to initialize a headless Chrome instance, request the target web page, and scroll down with Selenium.
The above code will activate the background XHR calls, yet we haven't inspected them. To inspect responses with selenium-wire, we can use the driver.requests method:
from seleniumwire import webdriver
import time
#....
scroll(driver)
# iterate over all the recorded XHR requests
for request in driver.requests:
print(request)
driver.quit()
In the above code, we iterate over the recorded XHR requests and print them:
https://accounts.google.com/ListAccounts?gpsia=1&source=ChromiumBrowser&json=standard
https://web-scraping.dev/testimonials
https://web-scraping.dev/assets/css/main.css
https://web-scraping.dev/assets/css/bootstrap-icons.css
https://web-scraping.dev/assets/css/bootstrap.min.css
https://web-scraping.dev/assets/css/highlight-nord.css
https://web-scraping.dev/assets/js/cash.min.js
https://web-scraping.dev/assets/js/bootstrap.js
https://web-scraping.dev/assets/js/main.js
https://web-scraping.dev/assets/js/htmx.js
https://cdn.jsdelivr.net/npm/minidenticons@3.1.2/minidenticons.min.js
https://web-scraping.dev/assets/media/icon.png
https://web-scraping.dev/api/testimonials?page=2
https://web-scraping.dev/api/testimonials?page=3
https://optimizationguide-pa.googleapis.com/v1:GetModels?key=AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw
https://web-scraping.dev/api/testimonials?page=4
https://web-scraping.dev/api/testimonials?page=5
We can see that selenium-wire captured all the requests sent from the browser, including the ones for assets, which aren't useful. Next, let's have a look at filtering these responses and returning the details of each response.
Filtering
Since we are web scraping data from the HTML, we aren't interested in third-party or asset requests. Let's filter the inspected responses to only match what we are looking for:
from seleniumwire import webdriver
import time
#....
# iterate over all the recorded XHR requests
for request in driver.requests:
if "/testimonials" in request.url:
print(request.url)
driver.quit()
Here, we filter the captured XHR calls to only return the ones for review data:
https://web-scraping.dev/testimonials
https://web-scraping.dev/api/testimonials?page=2
https://web-scraping.dev/api/testimonials?page=3
https://web-scraping.dev/api/testimonials?page=4
https://web-scraping.dev/api/testimonials?page=5
Great! We have all the responses in place. Next, let's return the details of each XHR call response:
from seleniumwire import webdriver
import time
import json
#....
def format_response(response):
formatted_response = {
"status_code": response.status_code,
"reason": response.reason,
"headers": dict(response.headers),
"date": response.date.strftime("%Y-%m-%d %H:%M:%S"),
"body": response.body[:50].decode('utf-8') # decode the body as it's encoded
}
return formatted_response
# iterate over all the recorded XHR requests
for request in driver.requests:
if "/testimonials" in request.url:
formatted_response = format_response(request.response)
print(json.dumps(formatted_response, indent=2))
driver.quit()
Here, we return the response properties provided by selenium-wire. Let's break them down:
| Attribute | Description |
|---|---|
status_code |
The response status code. |
reason |
A text representation of the status code. |
headers |
The response headers. |
date |
The response date, when it was returned. |
body |
The response body, HTML, JSON, etc. |
Here's a sample output of the returned response details:
{
"status_code": 200,
"reason": "",
"headers": {
"content-type": "text/html; charset=utf-8",
"date": "Mon, 25 Mar 2024 23:32:15 GMT",
"permissions-policy": "fullscreen=(self), autoplay=*, geolocation=(), camera=()",
"referrer-policy": "strict-origin-when-cross-origin",
"server": "uvicorn",
"strict-transport-security": "max-age=31536000; includeSubDomains; preload",
"x-content-type-options": "nosniff",
"x-xss-protection": "1; mode=block",
"content-length": "28266"
},
"date": "2024-03-26 01:32:17",
"body": "\n<!doctype html>\n<html lang=\"en\">\n <head>\n <me"
}
The above details can make the web scraping process much easier. For example, we can parse each response body to obtain the data. Let's have a look!
Parsing
In this section, we'll parse the HTML found in each response body inspected by selenium-wire to retrieve the full review data using Parsel:
from seleniumwire import webdriver
from parsel import Selector
import time
import json
options = webdriver.ChromeOptions()
options.add_argument("log-level=3") # disable logs
driver = webdriver.Chrome(options=options)
driver.get("https://web-scraping.dev/testimonials")
def scroll(driver: webdriver):
for i in range(0, 5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
scroll(driver)
def parse_xhr_html(html: str):
"""parse review data from each xhr response body"""
data = []
selector = Selector(html)
for review in selector.css("div.testimonial"):
data.append({
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
})
return data
# iterate over all the recorded XHR requests and parse each response body
data = []
for request in driver.requests:
if "/testimonials" in request.url:
xhr_data = parse_xhr_html(request.response.body.decode('utf-8'))
data.extend(xhr_data)
print(json.dumps(data, indent=2, ensure_ascii=False))
driver.quit()
The above code is pretty straightforward. We use selenium-wire to inspect the responses of the background requests and parse each response body using CSS selectors to retrieve the review data. Here is what the results we got look like:
[
{
"rate": 5,
"text": "We've been using this utility for years - awesome service!"
},
{
"rate": 5,
"text": "This Python app simplified my workflow significantly. Highly recommended."
},
{
"rate": 4,
"text": "Had a few issues at first, but their support team is top-notch!"
},
{
"rate": 5,
"text": "A fantastic tool - it has everything you need and more."
},
{
"rate": 5,
"text": "The interface could be a little more user-friendly."
},
....
]
Parsing data from XHR calls eliminates the need to replicate complex HTTP requests while scraping. The browser manages all the required configurations for us, such as headers or private API keys.
Inspecting Request Objects
Just like how we intercepted the responses of the background XHR calls, we can use the same approach to inspect the outgoing requests along with their configurations:
from seleniumwire import webdriver
import time
import json
options = webdriver.ChromeOptions()
options.add_argument("log-level=3") # disable logs
driver = webdriver.Chrome(options=options)
driver.get("https://web-scraping.dev/testimonials")
def scroll(driver: webdriver):
for i in range(0, 5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
scroll(driver)
def format_response(request):
formatted_request = {
"url": request.url,
"method": request.method,
"date": request.date.strftime("%Y-%m-%d %H:%M:%S.%f"),
"ws_messages": request.ws_messages,
"querystring": request.querystring,
"params": request.params,
"path": request.path,
"host": request.host,
"response": {
"status_code": request.response.status_code,
"reason": request.response.reason,
"headers": dict(request.response.headers),
"date": request.response.date.strftime("%Y-%m-%d %H:%M:%S") if request.response.date else None,
"body": request.response.body[:50].decode('utf-8') if request.response.body else None
}
}
return formatted_request
# inspect the outgoing XHR requests
data = []
for request in driver.requests:
if "/testimonials" in request.url:
formatted_request = format_response(request)
print(json.dumps(formatted_request, indent=2))
driver.quit()
Here, we inspect the outgoing XHR requests and return their configurations. The full request properties are the following:
| Attribute | Description |
|---|---|
url |
The full request URL. |
method |
The HTTP method used by the request, GET, POST, etc. |
date |
The request date, when it was sent. |
cert |
The target website SSL certificate details. |
ws_messages |
Applicable for WebSocket requests, the messages sent and recieved. |
querystring |
The request query paremeters represented as a string. |
params |
The request query paremeters represented as an object. |
body |
The request body. |
host |
The request URL path. |
host |
The request URL host. |
response |
The full response object of the request. |
Here's a sample output of the inspected requests retrieved:
{
"url": "https://web-scraping.dev/api/testimonials?page=2",
"method": "GET",
"date": "2024-03-26 03:19:14.208584",
"ws_messages": [],
"querystring": "page=2",
"params": {
"page": "2"
},
"body": "",
"path": "/api/testimonials",
"host": "web-scraping.dev",
"response": {
"status_code": 200,
"reason": "",
"headers": {
"content-type": "text/html; charset=utf-8",
"date": "Tue, 26 Mar 2024 01:19:13 GMT",
"permissions-policy": "fullscreen=(self), autoplay=*, geolocation=(), camera=()",
"referrer-policy": "strict-origin-when-cross-origin",
"server": "uvicorn",
"strict-transport-security": "max-age=31536000; includeSubDomains; preload",
"x-content-type-options": "nosniff",
"x-xss-protection": "1; mode=block",
"content-length": "12366"
},
"date": "2024-03-26 03:19:14",
"body": "\n \n <div class=\"testimonial\">\n \n <identicon-"
}
}
When it comes to web scraping, the reason why XHR calls are inspected can vary based on the use case:
- Inspecting requests
It comes in handy when replicating an HTTP request independently, such as obtaining specific header keys required for the requests.
- Inspecting responses
It's useful for retrieving the data directly from the body without managing the requests ourselves. It's particularly convenient when the requests' configuration is complex.
Intercepting Requests
So far, we have only inspected recorded XHR calls. However, selenium-wire also enables modifying background requests, including their responses.
For this, selenium-wire provides two interceptor functions: driver.request_interceptor and driver.response_interceptor. Once the request or response reaches selenium-wire, these functions get invoked.
Let's explore intercepting requests through examples.
Modifying Request Headers
Headers play a vital role in every HTTP request. A common trick used by web scrapers is rotating request headers, such as the User-Agent. Here's how to manipulate background request headers using the interceptor function
from seleniumwire import webdriver
from parsel import Selector
import json
driver = webdriver.Chrome()
# define the request interceptor
def interceptor(request):
"""Modify headers of the outgoing background calls"""
request.headers['Cookie'] = 'key1=value1;key2=value2;' # add a new request header
# replacing a request header
del request.headers['User-Agent'] # remove the header first (it's automatically provided)
request.headers['User-Agent'] = 'Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/113.0' # add a new header value
driver.request_interceptor = interceptor
driver.get("https://httpbin.dev/headers")
# get the used request header values from the response
selector = Selector(driver.page_source)
response = json.loads(selector.xpath("//pre/text()").get())
print(json.dumps(response, indent=2))
driver.quit()
In the above code, we define a request interceptor function. It observes all the outgoing requests sent from the browser and modifies their headers. From the response, we'll find the new header values used:
{
"headers": {
....
"Cookie": [
"key1=value1;key2=value2;",
"User-Agent": [
"Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/113.0"
]
}
}
Modifying Response Headers
Similar to the above section, we can create a response interceptor function to modify the response headers:
from seleniumwire import webdriver
import json
driver = webdriver.Chrome()
# define the request interceptor
def interceptor(request, response):
"""Modify headers of the outgoing background calls"""
response.headers['Cookie'] = 'key1=value1;key2=value2;' # add a new request header
# replacing a request header
del response.headers['User-Agent'] # remove the header first (it's automatically provided)
response.headers['User-Agent'] = 'Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/113.0' # add a new header value
driver.response_interceptor = interceptor
driver.get("https://httpbin.dev/headers")
# review the xhr response changes
for request in driver.requests:
if request.url == "https://httpbin.dev/headers":
print(json.dumps(dict(request.response.headers), indent=2))
driver.quit()
Here, we create a selenium-wire request interceptor to modify the response headers. The same approach can also be used to manipulate other response properties, such as the HTML found in the response body.
Blocking Requests
Another advantage of using selenium-wire interceptors is blocking specific background requests from getting executed:
from seleniumwire import webdriver
driver = webdriver.Chrome()
# define the request interceptor blocker
def interceptor(request):
"""Block specific requests"""
# Block image requests
if request.path.endswith(('.png', '.jpg', '.gif', '.webp', '.mp4', '.mp3')):
request.abort()
for partial_host in ['analytics', 'facebook', 'google', 'google-analytics', 'optimizationguide']:
if partial_host in request.host:
request.abort()
driver.request_interceptor = interceptor
driver.get("https://web-scraping.dev/products")
driver.quit()
The above code defines a request interceptor to block certain background requests, such as images, videos, or requests sent to third-party services like Google Analytics.
This can significantly optimize the web scraper speed by eliminating unnecessary requests while also saving bandwidth, which is beneficial when using proxies to reduce cost.
Limiting Requests Capture
When using selenium-wire, background requests are redirected to an internal server where they get captured. This can throttle down the performance when navigating complex websites.
For this, selenium-wire allows limiting the driver scope to only capture background requests on a specific host or domain:
from seleniumwire import webdriver
driver = webdriver.Chrome()
# define the driver score
driver.scopes = [
'.*web-scraping.dev.*'
]
driver.get("https://web-scraping.dev/products")
# only requests sent to the host "web-scraping.dev" will get captured
for request in driver.requests:
print(request)
driver.quit()
Avoiding Selenium Wire Scraping Blocking
Websites use protection mechanisms to block automated requests, such as web scrapers, from accessing their pages. Let's explore two tricks we can use to avoid selenium-wire blocking!

Using Proxies With Selenium Wire
The IP address is an essential property that's sent with every HTTP request. Websites and protection services can access each request's IP address. Once the requesting rate exceeds a specific threshold, the IP address gets blocked for a certain period of time.
Hence, using a proxy server distributes the requesting traffic across multiple IP addresses, which makes it harder to detect the IP address origin, preventing its blocking!
Selenium Wire allows changing the headless browser IP address through proxies: HTTP and SOCKS5. It also supports an exciting feature: changing proxy on the fly. Let's have a look!
HTTP Proxies
To use HTTP proxies with selenium-wire, we can add the proxy URLs to the driver options:
from seleniumwire import webdriver
options = {
'proxy': {
'http': 'http://123.12.12.12:1234', # HTTP
'https': 'https://123.12.12.12:1234', # HTTPS
'https': 'https://user:pass@123.12.12.12:1234', # authenticated proxies
}
}
driver = webdriver.Chrome(seleniumwire_options=options)
SOCKS Proxies
Similar to the above snippet, we can use SOCKS proxies with selenium-wire by adding them to the driver options:
options = {
'proxy': {
'http': 'socks4://123.12.12.12:1234', # SOCKS4
'https': 'socks5://123.12.12.12:1234', # SOCKS5
'https': 'socks5://user:pass@123.12.12.12:1234', # authenticated SOCKS proxies
}
}
driver = webdriver.Chrome(seleniumwire_options=options)
Changing Proxies Dynamically
Headless browsers often execute time-consuming tasks, such as navigating different page links in one session. Hence, maintaining the same IP address for such a long period isn't optimal in terms of blocking.
Selenium Wire allows switching proxies with running driver instances using the driver.proxy attribute:
# A driver using initial proxy
driver.get(...)
# Switch proxy
driver.proxy = {
'https': 'https://123.12.12.12:1234',
}
# Driver will use the new proxy
driver.get(...)
We have only touched the surface of avoiding IP address blocking. For further details, refer to our dedicated guide.

Using Undedected ChromeDriver With Selenium Wire
The Undetected ChromeDriver is a modified version of the regular Selenium Web Driver meant to avoid the protections of popular anti-bot services. It mimics regular browser behavior through various techniques, such as:
- Changing Selenium's variable names to appear normal.
- Randomizing User-Agent strings.
- Adding randomized delays between requests.
- Maintaining cookies and sessions correctly.
- Adding random mouse clicks and moves.

Selenium Wire integrates with the Undetected ChromeDriver to initiate the browser. The first step is installing the Undetected ChromeDriver using the following pip command:
pip install undetected-chromedriver
Here's how to use the UndetectedChrome Driver with selenium-wire. We'll request nowsecure.nl, a web page with a Cloudflare challenge:
import seleniumwire.undetected_chromedriver as uc
chrome_options = uc.ChromeOptions()
# Initialize a selenium-wire driver
driver = uc.Chrome(
options=chrome_options, # UndetectedChrome driver options
seleniumwire_options={} # selenium-wire options
)
driver.get("https://www.nowsecure.nl/")
driver.quit()
🙋 Note that the Cloudflare challenge on the above target website requires the SSL certificate to be available in the browser. However, selenium-wire uses a self-signed certificate, preventing access to the page with a "Not Secure" message. Therefore, we have to import a root certificate. For more details, refer to the official GitHub docs and this Stack Overflow answer.
The Undetected ChromeDriver can help avoid bot detection with its modified browser configurations. However, websites use TLS fingerprinting techniques to detect selenium-wire.
For example, let's use the above selenium-wire code to access G2:
import seleniumwire.undetected_chromedriver as uc
chrome_options = uc.ChromeOptions()
driver = uc.Chrome()
driver.get("https://www.nowsecure.nl/")
driver.quit()
From the response, we can see that the browser couldn't bypass the challenge:

Let's have a look at a better alternative for bypassing scraping blocking!
Powering Up With ScrapFly
Capturing background requests is a very convenient scraping method but it's still succeptible to anti-bot and scraper blocking. This is where we can help out!

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
To avoid scraping blocking with ScrapFly. All we have to do is replace the HTTP client with the ScrapFly client, enable the asp parameter, and select a proxy country. ScrapFly also saves all the background XHR requests with each response. Here's how we can inspect them:
# standard web scraping code
import requests
from parsel import Selector
response = requests.get("https://web-scraping.dev/testimonials")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="https://web-scraping.dev/testimonials",
asp=True, # enable the anti scraping protection to bypass blocking
proxy_pool="public_residential_pool", # select a proxy pool
country="US", # set the proxy location to a specfic country
render_js=True, # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
# execute custom JavaScript code to scroll down till the end
js="for (let i = 0; i < 6; i++) setTimeout(() => window.scrollTo(0, document.body.scrollHeight), i * 2000);"
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']
# access the browser background XHR requests
xhr_calls = response.scrape_result["browser_data"]["xhr_call"]
for call in xhr_calls:
if "/testimonials" in call["url"]:
print(call["url"])
"https://web-scraping.dev/api/testimonials?page=2"
# remaining pagination requests
FAQ
To wrap up this guide on intercepting background requests with selenium-wire for web scraping, let's have a look at some frequently asked questions.
What is the difference between Welenium Wire and Selenium?
Selenium is an automation tool used to run and manipulate web browsers. Selenium Wire is a Python binding for Selenium that allows it to inspect and modify background requests made by the browser driver.Are there alternatives for selenium-wire?
Yes, other headless browsers like Playwright and Puppeteer enable capturing background requests natively. Refer to our guide on web scraping background requests for more details.
Summary
In this guide, we explained how to use selenium-wire to capture background requests, specifically for web scraping. We started by exploring how to:
- Inspect requests and responses, filter and parsing them.
- Create interceptor functions to request configurations.
- Optimize selenium wire by blocking or limiting certain domains.
Then, we explored how to avoid selenium-wire scraping blocking by:
- Adding proxies to split the request traffic across multiple IPs.
- Using the Undetected ChromeDriver to mimic normal browsers.



