

Scrapy is one of the most popular web scraping frameworks out there. However, it can't render JavaScript-loaded web pages. But what about using Selenium with Scrapy to scrape dynamic web pages?
In this article, we'll explore web scraping with Scrapy Selenium. We'll start by explaining how to integrate Selenium with Scrapy projects through an example web scraper. Then, we'll explain how to use Scrapy Selenium for common scraping use cases, such as waiting for elements, clicking buttons and scrolling. Let's get started!
Key Takeaways
Master scrapy selenium integration for dynamic web scraping with JavaScript rendering, element interaction, and advanced automation workflows using scrapy selenium.
- Integrate Selenium with Scrapy framework for scraping JavaScript-rendered content and dynamic web pages
- Configure scrapy-selenium middleware for redirecting Scrapy requests to Selenium WebDriver
- Implement element waiting, button clicking, and scrolling for complex user interaction scenarios
- Configure Selenium 4 compatibility and proper driver management for modern web scraping
- Handle dynamic content loading with explicit waits and element visibility strategies
- Implement proper error handling and retry logic for reliable dynamic web scraping workflows
What is Scrapy Selenium?
scrapy-selenium is a Scrapy middleware that redirects Scrapy requests into a Selenium driver. This enables scraping dynamic web pages with Scrapy along with other headless browser automation features, such as:
- Waiting for specific time or elements.
- Clicking buttons and filling out forms.
- Taking screenshots.
- Executing custom JavaScript code.
The scrapy-selenium middleware hasn't been updated in a while, and it only supports Selenium 3. However, we'll explain how to alter its middleware to support Selenium 4, the most recent version of Selenium.
How to Install Scrapy Selenium?
To web scrape with Scrapy Selenium, we'll have to install a few Python packages:
- Scrapy: For creating a Scrapy project and running the spiders.
- scrapy-selenium: A middleware that redirects the Spider requests to Selenium.
- Selenium: An API for automating the browser driver using
scrapy-selenium.
The above packages can be installed using pip. Since the scrapy-selenium middleware only supports Selenium 3, we'll have to install this version:
pip install scrapy-selenium selenium==3.14.0 scrapy🙋 It's recommended to install the above packages in a fresh Python environment to avoid any conflicts with previously installed packages.
In this Scrapy Selenium tutorial, we'll use ChromeDriver as the headless browser engine. Its binaries is also required by Scrapy Selenium. Go over the ChromeDriver download page and download the version that matches the installed Chrome browser on your operating system.
How to Install Scrapy With Selenium 4
The above installation instructions install Scrapy with Selenium 3 as the scrapy-selenium package doesn't support Selenium 4 natively. However, there is a community solution allows for supporting Selenium 4 by overriding its middleware. It also download the ChromeDriver automatically using webdriver-manager.
- Install the required libraries:shell
pip install scrapy-selenium selenium scrapy webdriver-manager - Locate the
scrapy-seleniumsub-folder in thesite-packagesfolder:shellpip show scrapy-selenium - Replace the code in the
middlewares.pywith the following one:middlewares.py
"""This module contains the ``SeleniumMiddleware`` scrapy middleware"""
from importlib import import_module
from scrapy import signals
from scrapy.exceptions import NotConfigured
from scrapy.http import HtmlResponse
from selenium.webdriver.support.ui import WebDriverWait
from .http import SeleniumRequest
class SeleniumMiddleware:
"""Scrapy middleware handling the requests using selenium"""
def __init__(self, driver_name, driver_executable_path,
browser_executable_path, command_executor, driver_arguments):
"""Initialize the selenium webdriver
Parameters
----------
driver_name: str
The selenium ``WebDriver`` to use
driver_executable_path: str
The path of the executable binary of the driver
driver_arguments: list
A list of arguments to initialize the driver
browser_executable_path: str
The path of the executable binary of the browser
command_executor: str
Selenium remote server endpoint
"""
webdriver_base_path = f'selenium.webdriver.{driver_name}'
driver_klass_module = import_module(f'{webdriver_base_path}.webdriver')
driver_klass = getattr(driver_klass_module, 'WebDriver')
driver_options_module = import_module(f'{webdriver_base_path}.options')
driver_options_klass = getattr(driver_options_module, 'Options')
driver_options = driver_options_klass()
if browser_executable_path:
driver_options.binary_location = browser_executable_path
for argument in driver_arguments:
driver_options.add_argument(argument)
driver_kwargs = {
'executable_path': driver_executable_path,
f'{driver_name}_options': driver_options
}
# locally installed driver
if driver_executable_path is not None:
driver_kwargs = {
'executable_path': driver_executable_path,
f'{driver_name}_options': driver_options
}
self.driver = driver_klass(**driver_kwargs)
# remote driver
elif command_executor is not None:
from selenium import webdriver
capabilities = driver_options.to_capabilities()
self.driver = webdriver.Remote(command_executor=command_executor,
desired_capabilities=capabilities)
# webdriver-manager
else:
# selenium4+ & webdriver-manager
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
if driver_name and driver_name.lower() == 'chrome':
# options = webdriver.ChromeOptions()
# options.add_argument(o)
self.driver = webdriver.Chrome(options=driver_options,
service=ChromeService(ChromeDriverManager().install()))
@classmethod
def from_crawler(cls, crawler):
"""Initialize the middleware with the crawler settings"""
driver_name = crawler.settings.get('SELENIUM_DRIVER_NAME')
driver_executable_path = crawler.settings.get('SELENIUM_DRIVER_EXECUTABLE_PATH')
browser_executable_path = crawler.settings.get('SELENIUM_BROWSER_EXECUTABLE_PATH')
command_executor = crawler.settings.get('SELENIUM_COMMAND_EXECUTOR')
driver_arguments = crawler.settings.get('SELENIUM_DRIVER_ARGUMENTS')
if driver_name is None:
raise NotConfigured('SELENIUM_DRIVER_NAME must be set')
# let's use webdriver-manager when nothing specified instead | RN just for Chrome
if (driver_name.lower() != 'chrome') and (driver_executable_path is None and command_executor is None):
raise NotConfigured('Either SELENIUM_DRIVER_EXECUTABLE_PATH '
'or SELENIUM_COMMAND_EXECUTOR must be set')
middleware = cls(
driver_name=driver_name,
driver_executable_path=driver_executable_path,
browser_executable_path=browser_executable_path,
command_executor=command_executor,
driver_arguments=driver_arguments
)
crawler.signals.connect(middleware.spider_closed, signals.spider_closed)
return middleware
def process_request(self, request, spider):
"""Process a request using the selenium driver if applicable"""
if not isinstance(request, SeleniumRequest):
return None
self.driver.get(request.url)
for cookie_name, cookie_value in request.cookies.items():
self.driver.add_cookie(
{
'name': cookie_name,
'value': cookie_value
}
)
if request.wait_until:
WebDriverWait(self.driver, request.wait_time).until(
request.wait_until
)
if request.screenshot:
request.meta['screenshot'] = self.driver.get_screenshot_as_png()
if request.script:
self.driver.execute_script(request.script)
body = str.encode(self.driver.page_source)
# Expose the driver via the "meta" attribute
request.meta.update({'driver': self.driver})
return HtmlResponse(
self.driver.current_url,
body=body,
encoding='utf-8',
request=request
)
def spider_closed(self):
"""Shutdown the driver when spider is closed"""
self.driver.quit()
How to Scrape With Scrapy Selenium?
In this section, we'll go over a practical example on web scraping with Scrapy Selenium. We'll create a Scrapy project from scratch, integrating the scrapy-selenium middleware and creating Scrapy spiders for crawling and parsing.
This guide will briefly mention the basics of Scrapy. For more details, refer to our dedicated guide on Scrapy.

Setting Up Scrapy Project
Let's start off by creating a Scrapy project using the scrapy commands:
$ scrapy startproject scrapingexample scrapingexample-scraper
# ^ name ^ project directoryThe above command will create a Scrapy project in the scrapingexample-scraper directory. Let's inspect its files:
$ cd scrapingexample-scraper
$ tree
.
├── scrapingexample
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
└── scrapy.cfgOur Scrapy setup has been successful. Next, let's integrate it with Selenium!
Integrating Selenium With Scrapy
To use Selenium with Scrapy, all we have to do is follow two simple steps:
- Add the ChromeDriver downloaded earlier to the main
scrapingexample-scraperdirectory. - Add the following code to the
settings.pyfile in the Scrapy project folder:pythonfrom shutil import which
SELENIUM_DRIVER_NAME = 'chrome' SELENIUM_DRIVER_EXECUTABLE_PATH = which('chromedriver') SELENIUM_DRIVER_ARGUMENTS=[] # change it to ['-headless'] run in headless mode
DOWNLOADER_MIDDLEWARES = { 'scrapy_selenium.SeleniumMiddleware': 800 }
For Scrapy with Selenium 3, we have to specify the ChromeDriver path. However, __the Selenium 4 configuration defined earlier manages the ChromeDriver__ under the hood using `webdriver-manager`. So, if you are using Selenium 4, add the following code instead:
```python
SELENIUM_DRIVER_NAME = 'chrome'
SELENIUM_DRIVER_EXECUTABLE_PATH = None # webdriver-manager will manage it by itself
SELENIUM_DRIVER_ARGUMENTS=[] # change it to ['-headless'] run in headless mode
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800
}Now that our Scrapy Selenium scraping project is configured. Let's create the first Scrapy spider!
Creating Scraping Spider
In this Scrapy Selenium tutorial, we'll scrape review data from web-scraping.dev:
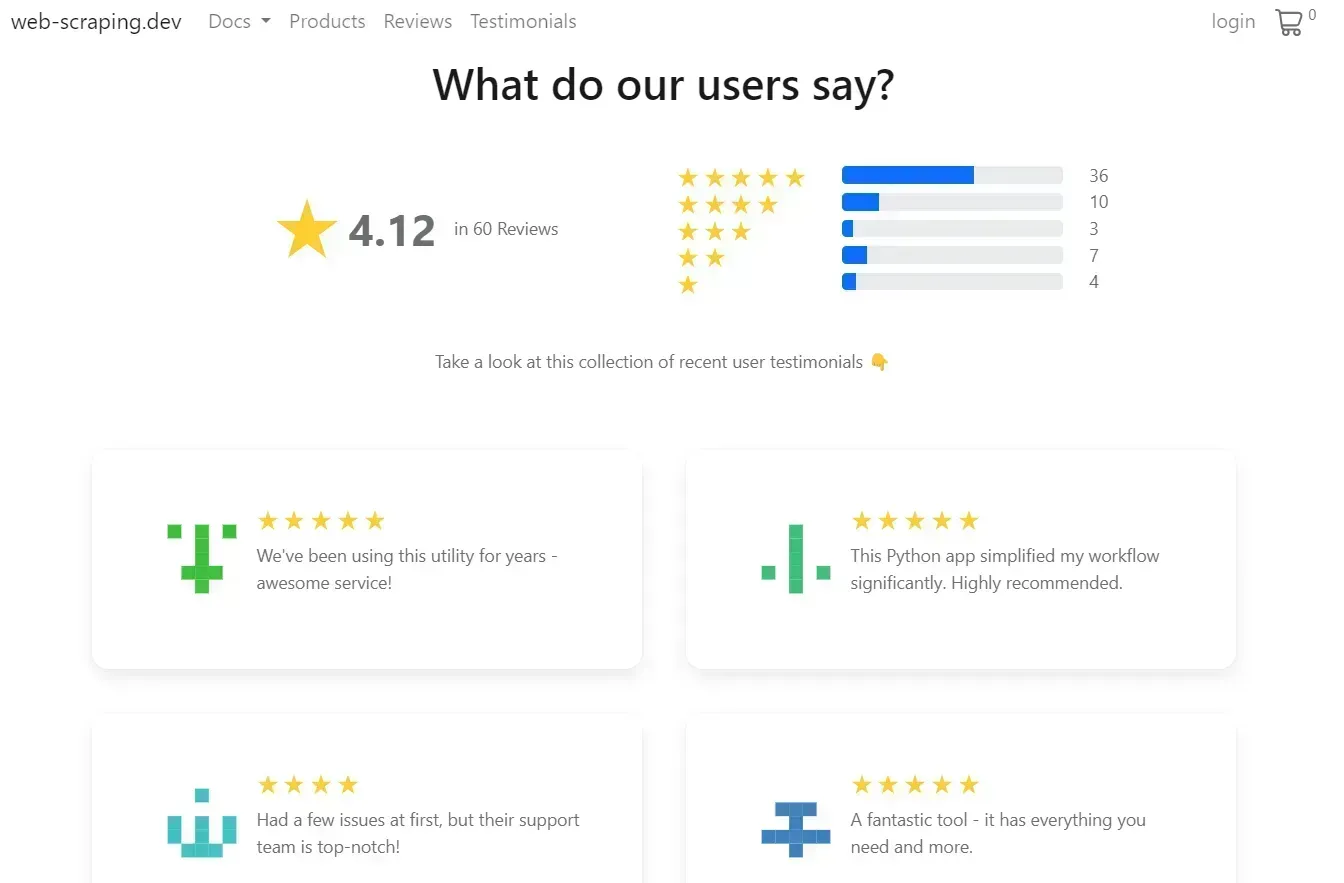
The above review data are loaded dynamically through JavaScript, where scrolling loads more data. To scrape it, we have to create a Scrapy sider:
$ cd scrapingexample-scraper
$ scrapy genspider reviews web-scraping.dev
# ^ name ^ host to scrapeThe above command will create a reviews.py file in the spiders direcotry:
import scrapy
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
start_urls = ["https://web-scraping.dev"]
def parse(self, response):
passScrapy added a template for a creating crawler with an empty parse() callback function. Let's change to request the review page with Selenium and parse the reviews:
import scrapy
from scrapy_selenium import SeleniumRequest
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse
)
def parse(self, response):
reviews = response.css("div.testimonial")
for review in reviews:
yield {
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
}Let's break down the above code changes:
- Add
start_requestsfunction to request the review page usingSeleniumRequest. - Iterate over all the reviews on the HTML and parse them using CSS selectors.
Next, let's execute this spider and save the scraping results:
scrapy crawl reviews --output reviews.jsonThe above Scrapy command will execute the spider and save the scraping results into the reviews.json file:
[
{"rate": 5, "text": "We've been using this utility for years - awesome service!"},
{"rate": 4, "text": "This Python app simplified my workflow significantly. Highly recommended."},
{"rate": 3, "text": "Had a few issues at first, but their support team is top-notch!"},
{"rate": 5, "text": "A fantastic tool - it has everything you need and more."},
{"rate": 2, "text": "The interface could be a little more user-friendly."},
{"rate": 5, "text": "Been a fan of this app since day one. It just keeps getting better!"},
{"rate": 4, "text": "The recent updates really improved the overall experience."},
{"rate": 3, "text": "A decent web app. There's room for improvement though."},
{"rate": 5, "text": "The app is reliable and efficient. I can't imagine my day without it now."},
{"rate": 1, "text": "Encountered some bugs. Hope they fix it soon."}
]The above review data was scraped using Selenium with the ChromeDriver. However, since we didn't instruct Selenium to scroll and load more reviews, we only got the first page reviews. Let's explore scrolling with Scrape Selenium next!
Implement Common Use Cases With Scrapy Selenium
In the following sections, we'll explore controlling the Selenium headless browser with Scrapy for common web scraping use cases, such as scrolling, clicking buttons, taking screenshots and executing custom JavaScript code.
The scrapy-selenium integration uses Selenium API to control the headless browser driver and most Selenium functionalities can also be implemented with Scrapy. For further details on Selenium, refer to our dedicated guide.

Scrolling
Infinite scroll web pages are common across modern web applications, which fetch new data with scroll actions.
Infinite scroll web pages are common across modern web applications, which fetch new data with scroll actions. Handling infinite scrolling in Scrapy Selenium can be done several methods:
- Executing custom JavaScript code that simulates scroll action.
- Using native Selenium driver scroll actions.
Since we'll cover executing custom JavaScript code with Scrapy Selenium later, let's use the native driver methods in this section. Selenium driver can be accessed within Scrapy Selenium requests through the request meta:
driver = response.request.meta["driver"]Now that we can access the driver instance. Let's use it for scrolling to scrape all the reviews in the previous example:
import time
import scrapy
from scrapy.selector import Selector
from scrapy_selenium import SeleniumRequest
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse
)
def parse(self, response):
driver = response.request.meta["driver"]
for i in range(1, 10):
ActionChains(driver).scroll_by_amount(0, 10000).perform()
time.sleep(1)
# get the HTML from the actual driver
selector = Selector(text=driver.page_source)
for review in selector.css("div.testimonial"):
yield {
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
}Here, we use the same SeleniumRequest function. We only change its callback function. Let's break its workflow:
- Access the request driver instance.
- Simulate a scroll-down action using the
scroll_by_amountand wait for a second between each scroll. - Create the selector again from the driver HTML, as the response passed from the request contains the HTML before the scroll.
- Iterate over all the reviews, extract each review text and rate.
The above code can scroll down, load more data and parse it. However, our Scrapy Selenium scraper doesn't utilize any timeouts, meaning that we can't know if the latest review has loaded or not. To address this, let's have a look at setting timeouts and waiting for elements!
Timeouts and Waiting For Elements
Timeouts can be configured in Scrapy Selenium in two different ways:
- Defining them as parameters in the
SeleniumRequest. - Defining them in the callback logic.
Defining timeout through parameters is used for waiting for natural network activities that don't involve explicit driver actions defined in callbacks, such as the scroll we used earlier.
To solidify this concept, let's add dynamic waits for the previous scroll code:
import time
import scrapy
from scrapy.selector import Selector
from scrapy_selenium import SeleniumRequest
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse
)
def parse(self, response):
driver = response.request.meta["driver"]
for i in range(1, 10):
ActionChains(driver).scroll_by_amount(0, 10000).perform()
time.sleep(1)
wait = WebDriverWait(driver, timeout=60)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".testimonial:nth-child(60)")))
# get the HTML from the actual driver
selector = Selector(text=driver.page_source)
for review in selector.css("div.testimonial"):
yield {
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
}In the above code, we define a timeout using the WebDriverWait method with a maximum timeout of 60 seconds. Then, we use the timeout defined while waiting for the latest review to appear.
Next, let's utilize the parameter timeouts, which wait until the page load or a specific element that load naturally with the page:
import scrapy
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse,
# wait for an element on the page to load, with maximum timeout of 20 seconds
wait_time=20,
wait_until=EC.presence_of_element_located((By.XPATH, "//h1[text()='What do our users say?']"))
)In the above code, we use two SeleniumRequest parameters:
wait_time: For waiting for the page to fully load, or for a specific condition to be met ifwait_untilis declared.wait_until: For waiting for a specific condition or an element.
Taking Screenshots
Scrapy Selenium includes a parameter named screenshot to capture a screenshot and pass it to the callback function:
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse,
# take a screenshot
screenshot=True
)
def parse(self, response):
with open('screenshot.png', 'wb') as image_file:
image_file.write(response.meta['screenshot']) The above code will take a screenshot and save it. However, there is a downside to using the above approach. The screenshot is captured with the default ChromeDriver viewport and usually it's adjusted through the callback function. This means that the screenshot will be taken before the viewport is configured.
Therefore, we'll capture the screenshot in the Scrapy Selenium scraper with the actual driver used by the request:
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse,
)
def parse(self, response):
driver = response.request.meta["driver"]
# adjust the ChromeDriver viewport
driver.set_window_size(1920, 1080)
driver.save_screenshot("screenshot.png")Here, we adjust the ChromeDriver viewport within the callbacl function. It can also be configured from the settings.py file in the Scrapy project:
SELENIUM_DRIVER_ARGUMENTS=["--window-size=1920,1080"]Clicking Buttons And Filling Forms
Since we can access the driver instance used with the SeleniumRequest, we can click buttons and fill forms with Scrapy Selenium using the Selenium API.
Let's apply this to the web-scraping.dev/login page. We'll use the ChromeDriver to accept the cookie policy, enter the login credentials and click the login button:
# scrapy crawl login
import scrapy
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
class LoginSpider(scrapy.Spider):
name = "login"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/login?cookies="
yield SeleniumRequest(
url=url,
callback=self.parse,
wait_time=10,
wait_until=EC.element_to_be_clickable((By.CSS_SELECTOR, "button#cookie-ok"))
)
def parse(self, response):
driver = response.request.meta["driver"]
# define a timeout
wait = WebDriverWait(driver, timeout=5)
# accept the cookie policy
driver.find_element(By.CSS_SELECTOR, "button#cookie-ok").click()
# wait for the login form
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button[type='submit']")))
# fill in the login credentails
username_button = driver.find_element(By.CSS_SELECTOR, "input[name='username']")
username_button.clear()
username_button.send_keys("user123")
password_button = driver.find_element(By.CSS_SELECTOR, "input[name='password']")
password_button.clear()
password_button.send_keys("password")
# click the login submit button
driver.find_element(By.CSS_SELECTOR, "button[type='submit']").click()
# wait for an element on the login redirected page
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div#secret-message")))
secret_message = driver.find_element(By.CSS_SELECTOR, "div#secret-message").text
print(f"The secret message is: {secret_message}")The above script requests the target page and attempts to login through a few steps. Let's break down its execution steps:
- Request the login page and wait for the accept cookie element to appear.
- Define a driver timeout for the elements with a maximum of 5 seconds.
- Accept the cookie policy by clicking its button and fill the login credentials.
- Click the submit button and wait for an element on the redirect page.
Executing Custom JavaScript Code
The scrapy-selenium middleware allows for passing custom JavaScript code through the script parameter. Let's use it to simulate a scroll action using native JavaScript code:
import scrapy
from scrapy.selector import Selector
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse,
script="for (let i = 0; i < 10; i++) setTimeout(() => window.scrollTo(0, document.body.scrollHeight), i * 2000);",
)
def parse(self, response):
# get the HTML from the actual driver
driver = response.request.meta["driver"]
wait = WebDriverWait(driver, timeout=60)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".testimonial:nth-child(60)")))
selector = Selector(text=driver.page_source)
for review in selector.css("div.testimonial"):
yield {
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
}In the above code, we scroll down with Scrapy Selenium using custom JavaScript code passed into the script parameter. Then, we wait for the last review item to appear in the HTML within the callback function.
Alternatively, the above JavaScript code can be executed using the ChromeDriver itself:
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield SeleniumRequest(
url=url,
callback=self.parse
)
def parse(self, response):
# get the HTML from the actual driver
driver = response.request.meta["driver"]
# execute the JavaScript code using ChromeDriver
driver.execute_script("for (let i = 0; i < 10; i++) setTimeout(() => window.scrollTo(0, document.body.scrollHeight), i * 2000);")
wait = WebDriverWait(driver, timeout=60)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".testimonial:nth-child(60)")))
selector = Selector(text=driver.page_source)
for review in selector.css("div.testimonial"):
yield {
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
}The above code is the same as the previous one. We only execute the custom JavaScript code with the Scrapy Selenium ChromeDriver instead of passing it through a parameter.
ScrapFly: Scrapy Selenium Alternative
Selenium is a powerful web scraping tool though it can be difficult to scale up and this is where Scrapfly can lend a hand!

For example, the equivalent of the previous Scrapy Selenium scraping code is straightforward in ScrapFly. We'll enable the asp parameter to avoid scraping blocking, enable render_js and control the headless browser using JavaScript scenarios.
The above API parameters can be applied with the ScrapFly Python SDK or as a Scrapy integration. First, add the following two lines to the settings.py file in the Scrapy project:
SCRAPFLY_API_KEY = "Your ScrapFly API key"
CONCURRENT_REQUESTS = 2 # Adjust according to your plan limit rate and your needsNext, replace the scrapy.Spider with the ScrapflySpider and configure the ScrapeConfig:
from scrapfly import ScrapeConfig
from scrapfly.scrapy import ScrapflyScrapyRequest, ScrapflySpider, ScrapflyScrapyResponse
class LoginSpider(ScrapflySpider):
name = 'login'
allowed_domains = ['web-scraping.dev']
def start_requests(self):
yield ScrapflyScrapyRequest(
scrape_config=ScrapeConfig(
# target website URL
url="https://web-scraping.dev/login?cookies=",
# bypass anti scraping protection
asp=True,
# set the proxy location to a specific country
country="US",
# enable JavaScript rendering
render_js=True,
# scroll down the page automatically
auto_scroll=True,
# add JavaScript scenarios
js_scenario=[
{"click": {"selector": "button#cookie-ok"}},
{"fill": {"selector": "input[name='username']","clear": True,"value": "user123"}},
{"fill": {"selector": "input[name='password']","clear": True,"value": "password"}},
{"click": {"selector": "form > button[type='submit']"}},
{"wait_for_navigation": {"timeout": 5000}}
],
# take a screenshot
screenshots={"logged_in_screen": "fullpage"}
),
callback=self.parse
)
def parse(self, response: ScrapflyScrapyResponse):
print(f"The secret message is {response.css('div#secret-message::text').get()}")
"The secret message is 🤫"from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
ScrapeConfig(
# target website URL
url="https://web-scraping.dev/login?cookies=",
# bypass anti scraping protection
asp=True,
# set the proxy location to a specific country
country="US",
# # enable the cookies policy
# headers={"cookie": "cookiesAccepted=true"},
# enable JavaScript rendering
render_js=True,
# scroll down the page automatically
auto_scroll=True,
# add JavaScript scenarios
js_scenario=[
{"click": {"selector": "button#cookie-ok"}},
{"fill": {"selector": "input[name='username']","clear": True,"value": "user123"}},
{"fill": {"selector": "input[name='password']","clear": True,"value": "password"}},
{"click": {"selector": "form > button[type='submit']"}},
{"wait_for_navigation": {"timeout": 5000}}
],
# take a screenshot
screenshots={"logged_in_screen": "fullpage"},
debug=True
)
)
# get the HTML from the response
html = api_response.scrape_result['content']
# use the built-in Parsel selector
selector = api_response.selector
print(f"The secret message is {selector.css('div#secret-message::text').get()}")
"The secret message is 🤫"FAQ
How to solve the error "TypeError: WebDriver.__init__() got an unexpected keyword argument 'executable_path'"?
This error happens in Scrapy Selenium due to the Selenium 4 changes. It no longer accepts the executable_path parameter. To solve this issue, you can either downgrade to Selenium 3 or override the scrapy-selenium middleware to use Selenium 4. For more details, refer to this Stack Overflow question.
What is the difference between Scrapy Selenium and Selenium?
Scrapy Selenium is an integration that enables scraping dynamic web pages with Scrapy by redirecting the requests to a Selenium driver instance. API. On the other hand, Selenium is a dedicated library for automating different headless browsers, such as Chrome and Firefox.
Can I use Scrapy Selenium to bypass anti-bot protections?
Scrapy Selenium can help bypass basic JavaScript challenges since it renders pages in a real browser. However, for advanced anti-bot systems like Cloudflare or DataDome, you may need additional tools such as Selenium stealth plugins or a dedicated service like Scrapfly's anti-scraping protection bypass which handles these challenges automatically.
Are there alternatives for Scrapy Selenium?
Yes, there are other integrations that enable dynamic page scraping with Scrapy, such as Scrapy Splash and Scrapy Playwright.
Summary
In this tutorial, we have explained how to scrape dynamic web pages with Scrapy using the scrapy-selenium integration. We started by defining what Scrapy Selenium is and how to configure Scrapy to use Selenium.
We have also explained implementing various scraping use cases with Scrapy Selenium:
- Handling infinite scrolling while scraping.
- Defining timeouts and waiting for elements.
- Taking screenshots.
- Clicking buttons and filling out forms.
- Executing custom JavaScript code.


