

Web scraping allows for the creation of amazing projects that help in market tracking, identifying patterns, and decision-making. In this article, we'll build a price monitoring tool that tracks product prices by exploring a real-life example using Etsy.com. We'll also schedule this web scraping tool and create visualization charts to get data insights. Let's dive in!
Key Takeaways
Master ecommerce app scraping with advanced techniques, price monitoring automation, and data visualization for comprehensive market intelligence.
- Implement automated price monitoring systems using Python with Playwright and BeautifulSoup for real-time market analysis
- Configure data visualization with pandas, matplotlib, and seaborn for comprehensive market trend analysis
- Implement scheduling and notification systems for automated price change detection and market alerts
- Configure proxy rotation and fingerprint management to avoid detection and rate limiting
- Use specialized tools like ScrapFly for automated e-commerce scraping with anti-blocking features
- Implement data storage and analytics for comprehensive market trend tracking and business intelligence
Setup
We’ll be monitoring these products prices on Etsy:
To scrape price data from this page, we’ll use both Web Scraping with Playwright and Python and How to Parse Web Data with Python and Beautifulsoup. And for a faster execution time, we'll apply asynchronous web scraping using asyncio and aiohttp. These libraries can be installed using pip:
pip install playwright beautifulsoup4 asyncio aiohttp
After running the above command, install Playwright headless browser binaries using this command:
playwright installFor the visualization charts, we’ll use Pandas, Matplotlib and Seaborn. Let’s install them:
pip install pandas matplotlib seabornFinally, we’ll use desktop_notifier to send notifications:
pip install schedule desktop_notifierCreate Price Monitoring Tool
Our price monitoring tool code will be divided into 3 parts:
- Web scraper, that scrapes products data and saves it to a CSV file.
- Data visualizer, that reads the CSV file and creates visualization charts.
- Scheduler, that runs the scraping and visualization code every certain amount of time.
Let’s start with the web scraping code.
Scraping Price Data
Our target website has multiple pagination pages, and each page has multiple products that are rendered using JavaScript. We’ll use Playwright to create a web crawler that loops through pages to get all product links. We’ll then scrape price data using each product link.
Let's start with crawling the pagination pages. Create a new python file named scraper.py and add the following code:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
# Get all products links
async def crawl_etsy_search(url, max_pages=3):
links = []
# Intitialize an async playwright instance
async with async_playwright() as playwight:Fals # todo
# Launch a chrome headless browser
browser = await playwight.chromium.launch(headless=True)
page = await browser.new_page()
# Loop scrape paging
page_number = 1
while True:
print(f"Scraping page: {page_number}")
# go to URL
await page.goto(url, wait_until="domcontentloaded")
# wait for page to load (when product boxes appear)
await page.wait_for_selector('li.wt-list-unstyled')
# parse product links from HTML
page_content = await page.content()
soup = BeautifulSoup(page_content, "html.parser")
products = soup.select("li.wt-list-unstyled a.listing-link")
links.extend([item.attrs["href"] for item in products])
# parse next page URL if any
try:
next_page = soup.select_one('ul.search-pagination li:last-child a').attrs['href']
assert next_page != url
url = next_page
except Exception as e:
print(f"finished paging got exception: {e}")
break
page_number += 1
if page_number > max_pages:
print(f"finished paging reached max pages: {page_number}/{max_pages}")
break
return links
# Example use
if __name__ == "__main__":
for link in asyncio.run(crawl_etsy_search("https://www.etsy.com/search?q=laptop+stand")):
print(link)Example Output
https://www.etsy.com/listing/1086254748/laptop-dock-for-setup-cockpit-monitor
https://www.etsy.com/listing/1525653159/custom-lap-desk-lap-desk-for-laptop-lap
https://www.etsy.com/listing/290228675/lapboard-lapdesk-wooden-lap-table-laptop
https://www.etsy.com/listing/1445202541/premium-monitor-stand-monitor-riser-for
https://www.etsy.com/listing/1249376424/wood-laptop-stand-for-desk-wooden
https://www.etsy.com/listing/1296109951/laser-cut-wooden-laptop-stand-for-desk
https://www.etsy.com/listing/1534334103/solid-wood-laptop-storage-elevated
https://www.etsy.com/listing/1241150340/wooden-laptop-stand-for-desk-laptop
https://www.etsy.com/listing/949905096/oakywood-dual-laptop-stand-wood-vertical
https://www.etsy.com/listing/1444169919/foldable-laptop-stand
https://www.etsy.com/listing/808471877/laptop-stand-macbook-wood-stand
https://www.etsy.com/listing/1234161308/wood-vertical-laptop-stand-for-desk
https://www.etsy.com/listing/957399396/wooden-foldable-laptop-stand-portable
https://www.etsy.com/listing/515959680/laptop-stand-macbook-stand-wood-computer
https://www.etsy.com/listing/1552835035/wooden-laptop-stand-portable-stand
https://www.etsy.com/listing/1537026965/vertical-laptop-stand-wooden-laptop-dock
https://www.etsy.com/listing/1350671382/acrylic-stand-holder-for
https://www.etsy.com/listing/1018826806/portable-laptop-stand-aluminum
https://www.etsy.com/listing/1489450895/work-from-from-accessories-laptop
https://www.etsy.com/listing/1199945711/natural-laptop-stand-wood-notebook-stand
https://www.etsy.com/listing/1268617907/free-how-to-make-a-laptop-stand-pdf
https://www.etsy.com/listing/1504862416/wooden-laptop-stand-for-workspace-desk
https://www.etsy.com/listing/1520332361/10mm-wooden-laptop-stand-digital-file
https://www.etsy.com/listing/1526644251/laptop-stand-sleek-design-custom-colors
https://www.etsy.com/listing/971354535/wood-lap-desk-foldable-laptop-stand
https://www.etsy.com/listing/1552840119/laptop-stand-for-bed-portable-stand-for
https://www.etsy.com/listing/502368335/laptop-table-lap-desk-lap-trays-laptop
https://www.etsy.com/listing/992610346/laptop-tray-table-or-tv-stand-for
https://www.etsy.com/listing/1547077513/rotatable-laptop-stand-laptop-cooling
https://www.etsy.com/listing/1283097544/macbook-double-stand-dock-dual-docking
https://www.etsy.com/listing/1240817872/macbook-stand-vertical-laptop-stand
https://www.etsy.com/listing/1486821918/laptop-holder-wooden-laptop-stand
https://www.etsy.com/listing/1012919153/portable-laptop-stand-with-recycled
https://www.etsy.com/listing/1461172148/laptop-stand-laptop-holder-macbook
https://www.etsy.com/listing/529764275/docking-station-macbook-pro-air-laptop
https://www.etsy.com/listing/1270173554/personalized-laptop-stand-adjustableTo start, we launch a Playwright headless browser and create a pagination loop. For each loop iteration, we scrape the page HTML for product links using BeautifulSoup and check whether the next page link is available.
With this crawler, we can collect product links from any Etsy.com search. We'll the links to scrape each product's data.
For this, let's write a product scraper that will:
- Retrieve page HTML using playwright
- Parse HTML using BeautifulSoup for product fields:
- title
- price
- whether product is on sale
- total sale count
- product rating
- seller's name
import asyncio
import re
from typing import Dict, List
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
def parse_etsy_product(soup: BeautifulSoup) -> dict:
"""Parse Etsy.com product page html for product details"""
def css_digits(selector):
"""
Get the first digit from the first matching CSS selector
e.g. "25 product reviews" -> 25.0
"4.5 stars out of 5" -> 4.5
"current price 25.99 USD" -> 25.99
"""
element = soup.select_one(selector)
if not element:
return None
try:
return float(
re.findall(r"(\d+(?:\.\d+)*)", element.text.replace(",", ""))[0]
)
except (IndexError, AttributeError):
return None
product = {}
product["title"] = str(soup.select_one("h1.wt-text-body-01").text.strip())
product["price"] = css_digits("p.wt-text-title-03")
# if discount price is present means product is on sale:
product["sale"] = bool(soup.select_one("p.wt-text-caption.wt-text-gray > span"))
product["sales"] = int(
css_digits("h2.wt-mr-xs-2") or css_digits("div.reviews__header-stars > h2")
)
product["rating"] = css_digits("span.wt-display-inline-block.wt-mr-xs-1 > span")
product["seller"] = soup.select_one("span.wt-text-title-small > a").text
return product
async def scrape_etsy_products(urls: List[str]) -> Dict[str, dict]:
"""Scrape Etsy.com product pages"""
async with async_playwright() as playwight:
# Launch a chrome headless browser
browser = await playwight.chromium.launch(headless=True)
page = await browser.new_page()
for url in urls:
try:
await page.goto(url, wait_until="domcontentloaded")
await page.wait_for_selector("p.wt-text-title-03")
soup = BeautifulSoup(await page.content(), "html.parser")
product = parse_etsy_product(soup)
product["link"] = url
product["id"] = url.split("listing/")[-1].split("/")[0]
yield product
except Exception as e:
print(f"failed to scrape product {url} got exception:\n {e}")
# Example run:
if __name__ == "__main__":
async def example_run():
links = [
"https://www.etsy.com/listing/1526644251/laptop-stand-sleek-design-custom-colors",
"https://www.etsy.com/listing/971354535/wood-lap-desk-foldable-laptop-stand",
"https://www.etsy.com/listing/1552840119/laptop-stand-for-bed-portable-stand-for",
]
async for product in scrape_etsy_products(links):
print(product)
asyncio.run(example_run())Example Output
{'title': 'Laptop Stand, Sleek Design, Custom colors / 3D Printed Universal design / Apple / Dell / HP', 'price': 527.47, 'sale': True, 'sales': 1823, 'rating': 5.0, 'seller': '3DdesignBros', 'link': 'https://www.etsy.com/listing/1526644251/laptop-stand-sleek-design-custom-colors', 'id': '1526644251'}
{'title': 'Wood Lap Desk, Foldable Laptop Stand, Laptop Bed Tray, Breakfast Serving Tray, Adjustable Legs Laptop Table, Portable Storage Drawers Desk', 'price': 3608.06, 'sale': True, 'sales': 11402, 'rating': 5.0, 'seller': 'FalkelDesign', 'link': 'https://www.etsy.com/listing/971354535/wood-lap-desk-foldable-laptop-stand', 'id': '971354535'}
{'title': 'Laptop Stand for Bed, Portable Stand for MacBook, Portable Workstation, Laptop Stand for Sofa, Portable Study Table, Wooden Laptop Stand', 'price': 2833.7, 'sale': True, 'sales': 97, 'rating': 5.0, 'seller': 'WoodenParadiseUA', 'link': 'https://www.etsy.com/listing/1552840119/laptop-stand-for-bed-portable-stand-for', 'id': '1552840119'}Above our scrape_etsy_products is asynchronous generator that scrapes provided product links using playwright. We use beautifulsoup with regular expressions and css selectors to parse the HTML content.
We have now completed the first part of our price monitoring tool, which is price scraping. Let’s move on to the visualization charts.
Saving Data to CSV
To start working on our analytics we first should save data to a CSV file. To do that let's wrap our scraper functions with data saving logic:
import csv
async def scrape_to_csv(filename: str, url: str, max_pages=3):
"""Scrape Etsy.com product pages and save to CSV file"""
filecsv = open(filename, "w", encoding="utf8")
csv_columns = ["id", "title", "price", "sale", "seller", "sales", "rating", "link"]
# Initialize the writer
writer = csv.DictWriter(filecsv, fieldnames=csv_columns)
# Write columns names to the file
writer.writeheader()
print(f"finding products for search: {url}")
links = await crawl_etsy_search(url, max_pages=max_pages)
print(f"found {len(links)} product")
print(f"scraping products for search: {url}")
async for product in scrape_etsy_products(links):
writer.writerow(product)
print(f"saved to {filename}")
# example run - scrape 3 pages of laptop stands products:
import asyncio
asyncio.run(scrape_to_csv(
filename="./laptop-stands.csv",
url="https://www.etsy.com/search?q=laptop+stand",
max_pages=3,
))With this we wrapped our playwright product scraper with data store options that should produce laptop-stands.csv that looks something like this:
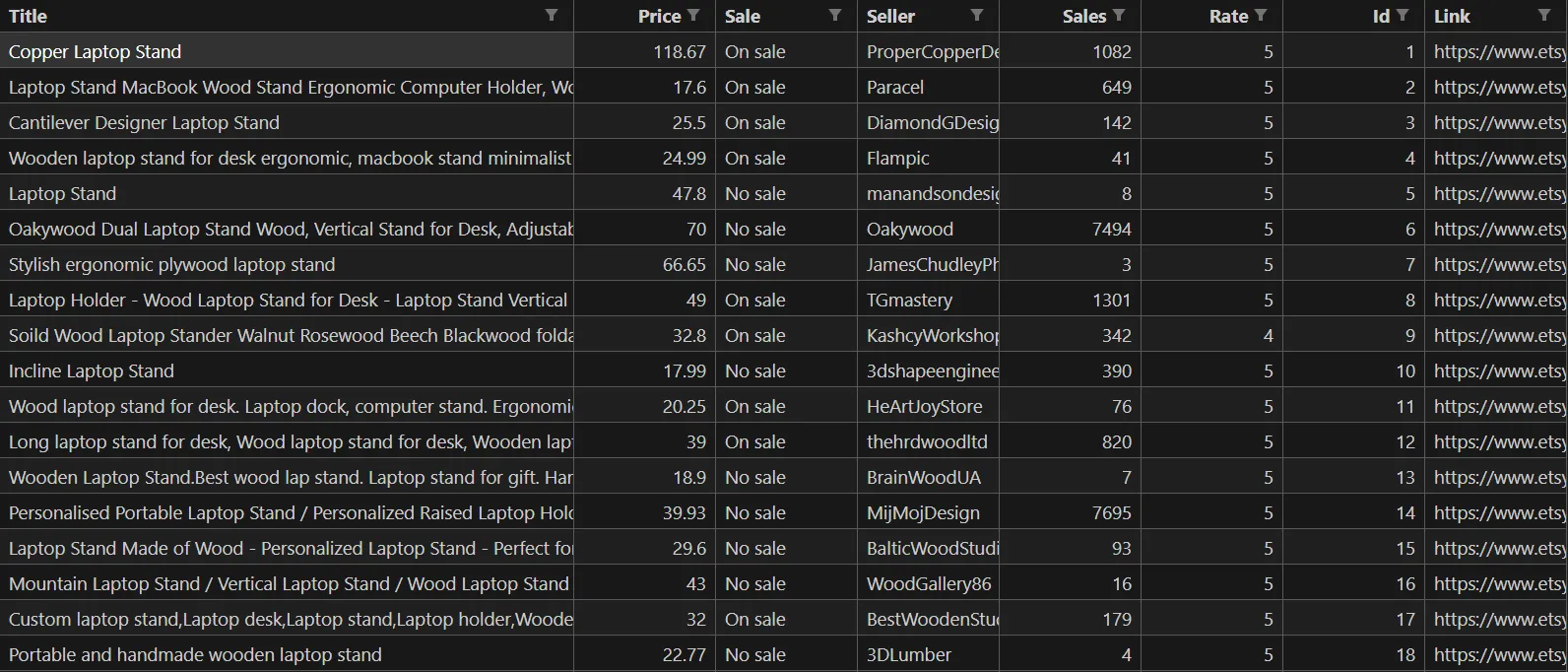
Now that we have our data stored we can perform visual analytics - let's take a look!
Creating Visualization Charts
Now that we have the data in a CSV file, we’ll use it to draw some insightful charts.
For this, we'll be using pandas, seaborn and matplotlib. We'll open our CSV dataset, load it as pandas dataframe which can be easily interpreted by seaborn to create beautiful graphs:
def make_charts(csv_filename: str):
"""Make analytics charts and html index for Etsy.com product CSV dataset"""
dataframe = pd.read_csv(csv_filename)
chart_filenames = []
# create ./charts directory where all data will be saved
Path("./charts").mkdir(parents=True, exist_ok=True)
plt.figure(figsize=(14, 6))
sns.kdeplot(
dataframe[dataframe["sale"] == True]["price"],
fill=True,
color="mediumseagreen",
alpha=0.6,
)
sns.kdeplot(
dataframe[dataframe["sale"] == False]["price"],
fill=True,
color="mediumpurple",
alpha=0.6,
warn_singular=False,
)
plt.xlim([10, 300])
plt.legend(["On Sale", "No Sale"], loc="upper right")
plt.title("Price Distribution for Products On Sale vs. No Sale")
plt.xlabel("Price")
plt.ylabel("Density")
plt.savefig("./charts/products price distribution.png")
chart_filenames.append("products price distribution.png")
# Number of products on sale vs. no sale
plt.figure(figsize=(10, 6))
sale_counts = dataframe["sale"].value_counts()
sns.barplot(x=sale_counts.index, y=sale_counts.values, palette="viridis")
plt.title("Number of Products On Sale vs. No Sale")
plt.xlabel("Sale Status")
plt.ylabel("Count")
plt.savefig("./charts/products on sale.png")
chart_filenames.append("products on sale.png")
# Average sales for products on sale vs. no sale
plt.figure(figsize=(10, 6))
avg_sales = dataframe.groupby("sale")["sales"].mean()
sns.barplot(x=avg_sales.index, y=avg_sales.values, palette="viridis")
plt.title("Average Sales for Products On Sale vs. No Sale")
plt.xlabel("Sale Status")
plt.ylabel("Average Sales")
plt.savefig("./charts/average products sales by sale.png")
chart_filenames.append("average products sales by sale.png")
# Average sales across different ratings
plt.figure(figsize=(10, 6))
avg_sales_per_rate = dataframe.groupby("rating")["sales"].mean()
sns.barplot(
x=avg_sales_per_rate.index, y=avg_sales_per_rate.values, palette="viridis"
)
plt.title("Average Sales across Different Ratings")
plt.xlabel("Rating")
plt.ylabel("Average Sales")
plt.savefig("./charts/average sales across ratings.png")
chart_filenames.append("average sales across ratings.png")
# Top 10 sellers by total sales
plt.figure(figsize=(12, 6))
top_sellers = (
dataframe.groupby("seller")["sales"].sum().sort_values(ascending=False)[:10]
)
sns.barplot(
y=top_sellers.index, x=top_sellers.values, palette="viridis", orient="h"
)
plt.title("Top 10 Sellers by Total Sales")
plt.xlabel("Total Sales")
plt.ylabel("Seller")
plt.savefig("./charts/top 10 sellers.png")
chart_filenames.append("top 10 sellers.png")
# Top 20 products by total sales
plt.figure(figsize=(12, 6))
sorted_products = (
dataframe.groupby("id")["sales"].sum().sort_values(ascending=False)[:20]
)
sns.barplot(
y=sorted_products.index.astype(str),
x=sorted_products.values,
palette="viridis",
orient="h",
)
plt.xlim(0, 14000)
plt.title("Top 20 Products by Sales")
plt.xlabel("Total Sales")
plt.ylabel("Product ID")
plt.savefig("./charts/top 20 prdoucts.png")
chart_filenames.append("top 20 prdoucts.png")
# Price effect on sales
plt.figure(figsize=(12, 6))
bins = [0, 10, 20, 30, 40, 60, 100]
dataframe["price_bins"] = pd.cut(dataframe["price"], bins=bins)
sns.barplot(
x="price_bins",
y="sales",
data=dataframe,
estimator=sum,
ci=None,
palette="viridis",
)
plt.title("Total Sales for Different Price Bins")
plt.xlabel("Price Range")
plt.ylabel("Total Sales")
plt.tight_layout()
plt.savefig("./charts/Price effect on sales.png")
chart_filenames.append("Price effect on sales.png")
# also create a simple HTML file that displays all images
body = ""
for chart_filename in chart_filenames:
body += f"<h2>{chart_filename.replace('.png', '').title()}</h2>\n"
body += f'<img src="{chart_filename}" alt="{chart_filename}">\n'
with open("./charts/index.html", "w") as f:
f.write(dedent(f"""
<html>
<head>
<title>Analytics Charts</title>
<link rel="stylesheet" href="https://unpkg.com/sakura.css/css/sakura.css" type="text/css">
</head>
<body>
{body}
</body>
</html>
""").strip())
# Run the code
make_charts()This code will create some charts and save it in the ./charts directory and create an index.html file that contains all of the charts. So, if we open up the result in a web browser we should see output charts similar to this:
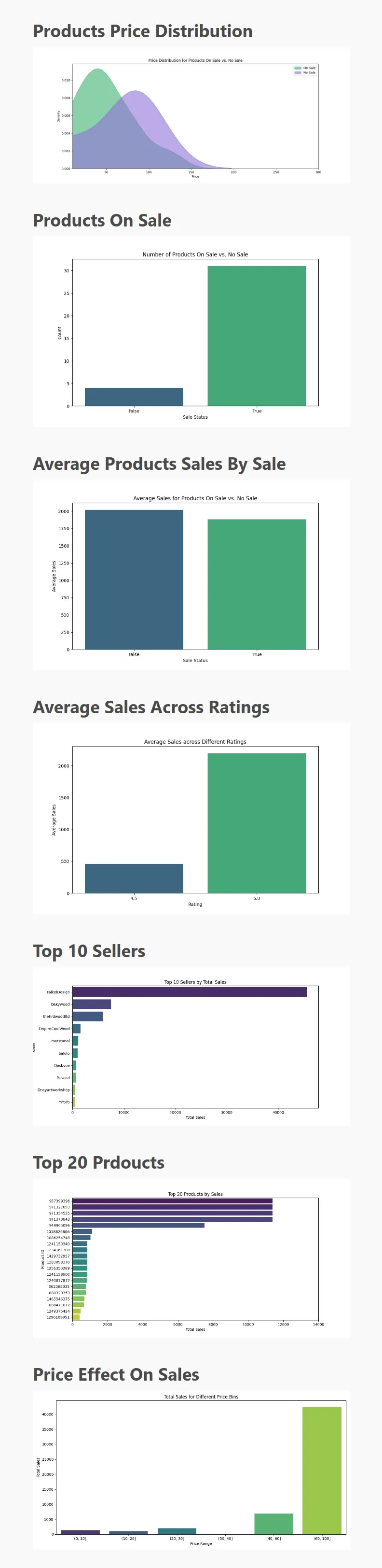
In these charts, we have displayed the price distribution of products and the top sellers and products. We have also shown how rate and sale impact total sales, we can see that products on sale and high rate have more sales than other products.
Our price monitoring tool can now scrape data and display charts. Let’s schedule it to run every certain amount of time.
Web Scraping Scheduling
In this section, we’ll desktop_notifier to send us a notification our price tracking tool and send a simple notification that informs us whenever results are ready.
Create a new Python file and add the following code:
from desktop_notifier import DesktopNotifier, Button
import asyncio
from visualization import make_charts
from scraper import scrape_data
notifier = DesktopNotifier()
# Send a desktop notification
async def send_notification():
await notifier.send(
title="Price monitoring tool",
message="Your web scraping results are ready!",
buttons=[
Button(
title="Mark as read",
),
],
)
# Main price monitoring function
async def montior_prices():
print("----- Scheduler has started -----")
await scrape_data()
make_charts()
await send_notification()
print("----- Scheduler has finished -----")
async def main():
while True:
# Run the script every 3 hours
await montior_prices()
await asyncio.sleep(3 * 3600)
if __name__ == "__main__":
asyncio.run(main())🙋 Make sure that you don't run the scrape_data and make_charts functions in any other files before running this file.
Here, we create a simple function that sends a desktop notification. Then, we combine all our code into the monitor_prices function. Which runs every 3 hours to scrape data, create visualization charts and send a notification.
Powering Up with Scrapfly
E-commerce monitoring requires scraping a lot of data regularly, which in turn requires scalable environments.

Here's an example of how to use Scrapfly to scrape Etsy.com products:
import os
from scrapfly import ScrapflyClient, ScrapeConfig
scrapfly = ScrapflyClient(key=os.environ['SCRAPFLY_KEY'])
result = scrapfly.scrape(
ScrapeConfig(
url="https://www.etsy.com/listing/1241150340/wooden-laptop-stand-for-desk-laptop",
# enable Headless Browsers (like Playwright)
render_js=True,
# use a US proxy
country="US",
# enable Anti-Bot Protection bypass
asp=True,
)
)
# with scrapfly css selectors a directly available:
print({
"title": result.selector.css("h1.wt-text-body-01::text").get().strip(),
"price": ''.join(result.selector.css("p.wt-text-title-03::text").getall()).strip(),
})
{
'title': 'Wooden Laptop Stand for desk, Laptop Riser Wood, macbook pro stand, wood laptop holder desk, macbook riser, computer stand for laptop',
'price': '$38.40'
}FAQ
How to observe E-commerce from different currencies or regions?
To observe ecommerce from different currencies or regions, you can either use an appropriate proxy IP of that region or localize scraper to use desired localization.
How can I avoid getting blocked when scraping e-commerce sites at scale?
E-commerce websites often employ anti-bot protections that can block automated scrapers. To avoid this, you can use Scrapfly's anti-scraping protection bypass which handles proxy rotation, browser fingerprinting, and CAPTCHA solving automatically.
Why use web scraping for e-commerce observation?
Web scraped data represents what real users see on the website. This allows for accurate data collection and analysis. Web scraping also allows for the collection of large amounts of data in a short time for relatively low costs making e-commerce analytics accessible to everyone.
Summary
In this article, we went through a step-by-step guide on building an e-commerce analytics tool using Python. We scraped the data using Playwright browser automation tool by crawling Etsy.com search. Then, we scraped each individual product's data to a CSV file which we used to generate visualization charts. Finally, we scheduled the tool to run every certain amount of time and send us a notification.
Using Python and simple web scraping techniques, we can monitor e-commerce markets for free and get insights that help us make better market decisions.


