Ebay is the world's biggest peer-to-peer e-commerce web market, making it an attractive target for public data collection in 2026! eBay also offers an official SDK for programmatic API access, though web scraping remains popular for data not covered by the official endpoints.
In this guide, we'll explain how to scrape Ebay search and listing pages for various details, inlcuding pricing, variant information, features, and descriptions.
We'll use Python, a few community packages, and some clever parsing techniques. Let's get started!
Key Takeaways
Master ebay scraper development using Python with httpx and parsel, extracting product data from hidden web data and handling anti-bot measures for comprehensive e-commerce data collection.
Reverse engineer eBay's search API endpoints by intercepting browser network requests and analyzing JSON response structures
Parse dynamic JSON data embedded in HTML using XPath selectors for product details and variants
Bypass eBay's anti-scraping measures with realistic headers, user agents, and request spacing
Extract structured product data including titles, prices, descriptions, and seller information
Implement exponential backoff retry logic with 403 status code detection for rate limiting
Handle multi-variant products and dynamic pricing through advanced JSON parsing and data extraction techniques
Get web scraping tips in your inboxTrusted by 100K+ developers and 30K+ enterprises. Unsubscribe anytime.
Why Scrape Ebay?
Ebay is one of the world's biggest product marketplaces, especially for more niche and rare items. This makes Ebay a great target for e-commerce data analytics.
Scraping Ebay data empoers various use cases, including:
Competitor analysis by gathering data on competitors' sales and reviews.
Market research by tracking product prices for hot deals or trends.
Empowered navigation through automated search patterns and custom alerts.
nested-lookup: To find nested keys in the Ebay JSON datasets
The above packages can be installed using the below pip command:
shell
$ pip install scrapfly-sdk jmespath nested-lookup
Scraping Ebay Listings
Let's get started by scraping Ebay for single listing pages. Ebay listings consists of two types:
Single variant listings with fixed selections
Multiple variant listings with different selections, like tech devices
First, we'll start scraping single variants since they are more straightforward to extract.
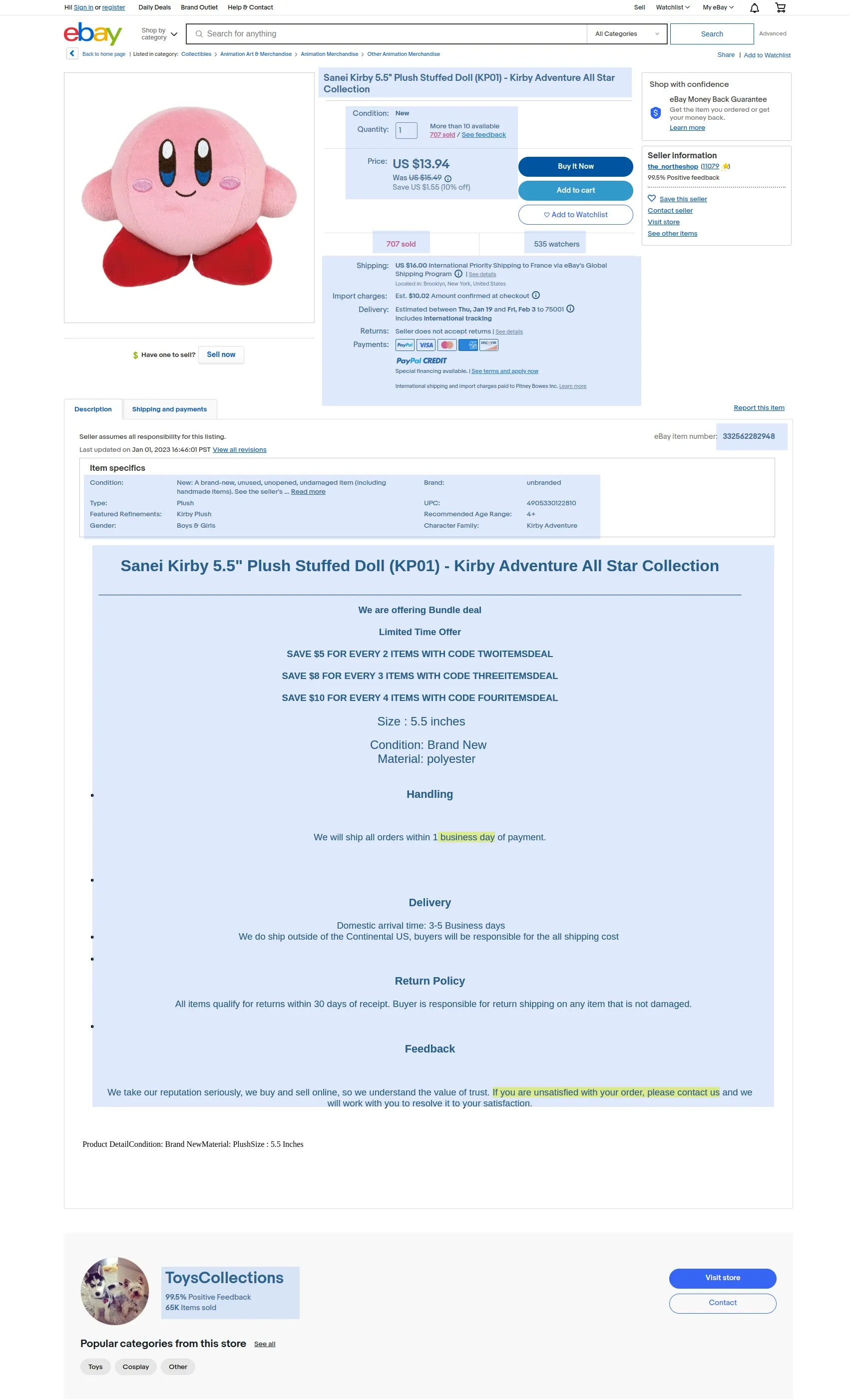
We'll be using single variants since they are more straightforward to extract. Let's take this product for example, we'll be extracting data from the below fields:
We'll capture the most important fields: pricing, description and product and seller details
In the image above we marked our fields and to build CSS selectors to select these fields we can use the Browser Developer Tools (F12 key or right click -> inspect option).
To scrape the above Ebay listing data, we'll be using CSS and XPath selectors:
Let's break down the above Ebay scraping code. We start by defining a new Scrapfly client and define two functions:
parse_product: to parse the product HTML pages using CSS and XPath selectors
scrape_product: To request Ebay product pages using Scrapfly to bypass its antibot and retrieve the HTML
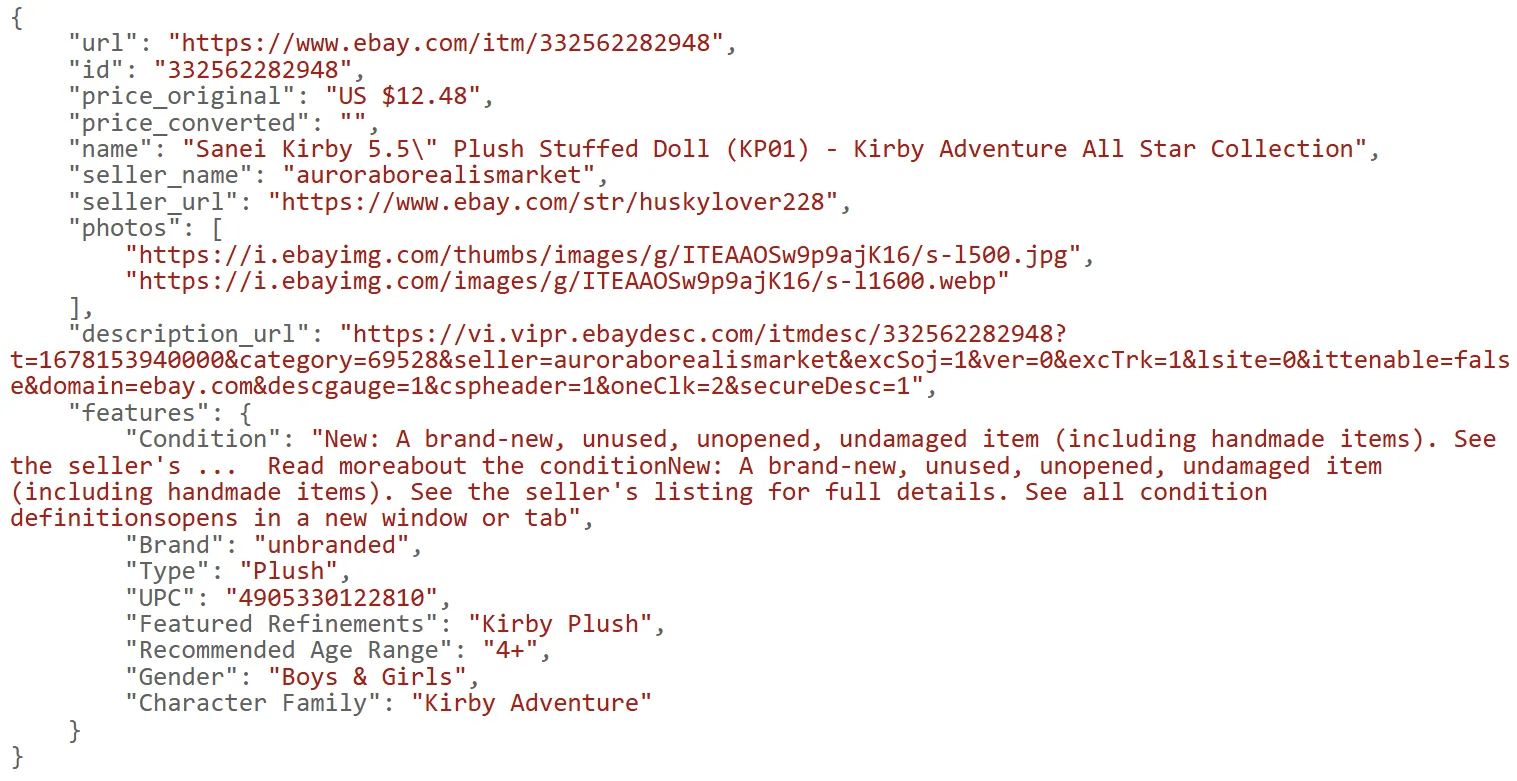
Below is example output of the Ebay data retrieved
Next, for products with variants we'll have to go a bit further and extract the page's hidden web data. It might seem like a complex process, though we'll cover it step-by-step!
Scraping Ebay Listing Variant Data
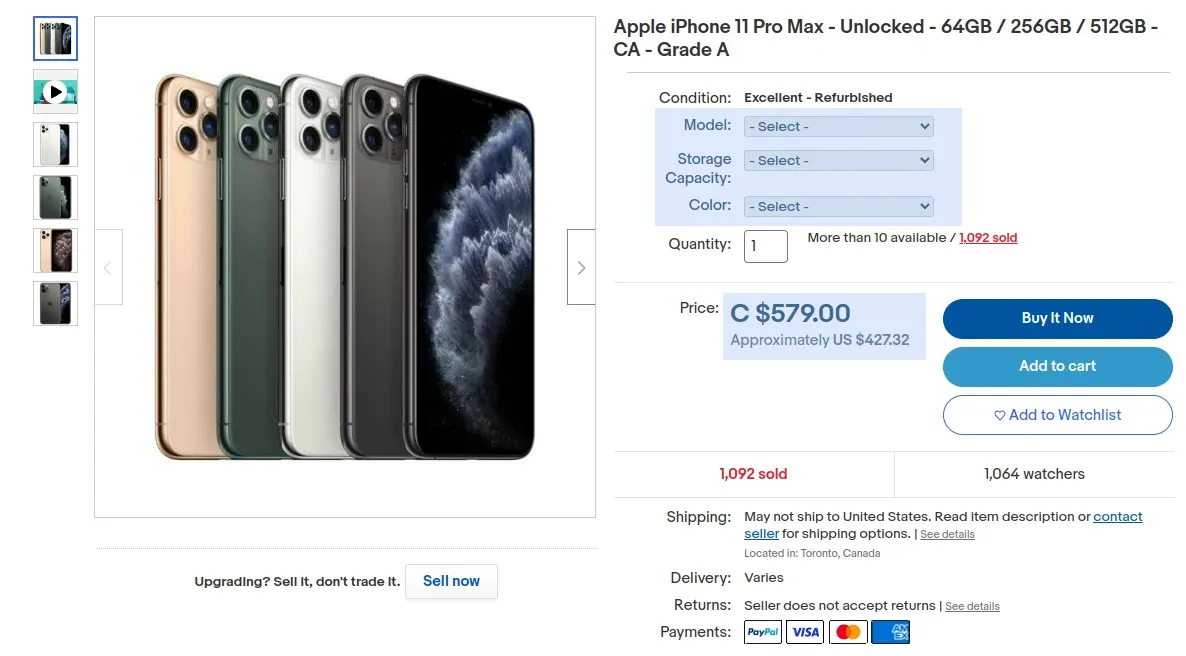
Ebay's listings can contain multiple products through a feature called variants. For example, let's take this iPhone listing:
Listings with variants have multiple selection options
We can see several variant options: model, storage capacity, and color. These options are updated using JavaScript each time we a select one.
Ebay is using JavaScript to update the page with a different price every time we choose a different option. That means that the varaint data exist in a JavaScript variable. Extracting these data is commonly known as hidden web data.
We'll briefly mention the hidden web data extraction in this guide. For the full details, refer to our dedicated tutorial.
To scrape the product variant data, we'll extract them as JSON under hidden script tags:
In the above Ebay scraper, we extract the variant listing data using the below steps:
Selecting the script tag containing the MSKU variable.
Extracting the JSON datasets using the find_json_objects utility.
Iterating over the various options and selecting the useful fields.
Here's what the retrieved Ebay scraping results should look like:
Next, let's see how to scrape Ebay search.
Scraping Ebay Search
To start scraping Ebay search results, let's reverse engineer it. When we input a search keyword we can see that Ebay is redirecting us to a different URL where the search results are located. For example, if we search for the term iphone we'll be taken to an URL similar to ebay.com/sch/i.html?_nkw=iphone&_sacat=0.
When a search query is submitted, Ebay redirects the requests to a search result document. For instance, searh the keyword iphone, and you will get reidrected to a URL similar to ebay.com/sch/i.html?_nkw=iphone&_sacat=0.
The page of the above URL uses several URL parameters to define the search query:
_nkw for search keyword.
_sacar the category restriction.
_sop sorting type.
_pgn page number.
_ipg listings per page (default is 60).
We can find more arguments by clicking around and exploring the search. To keep our Ebay web scraper short, let's stick with the below five parameters:
Here's what the extracted Ebay data looks like:
Avoiding Ebay Scraping Blocking
Creating an Ebay scraper seems straightforward. However, attempting the scale is the tricky part! Ebay can differentiate our requests as being automated, hence asking for CAPTCHA challenges or even block the scraping process entirely!
To take advantage of ScrapFlys API in our Ebay scraper, all we have to do is replace httpx with scrapfly-sdk client:
python
import httpx
response = httpx.get("some ebay.com url")
# in ScrapFly SDK becomes 👇
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient("YOUR SCRAPFLY KEY")
result = client.scrape(ScrapeConfig(
# some ebay URL
"https://www.ebay.com/itm/393531906094",
# we can select specific proxy country
country="US",
# and enable anti scraping protection bypass:
asp=True,
# enable JavaScript rendering if required
render_js=True
))
For more on how to scrape Ebay.com using ScrapFly, see the Full Scraper Code section.
FAQ
Is it legal to scrape ebay.com?
Yes. Ebay's data is publically available - scraping Ebay at slow, respectful rates would fall under the ethical scraping definition.
That being said, be aware of GDRP compliance in the EU when storing personal data such as sellers personal details like names or location. For more, see our Is Web Scraping Legal? article.
How to crawl Ebay.com?
To web crawl Ebay we can adapt the scraping techniques covered in this article. Every ebay listing contains related products which we can extract and feed into our scraping loop turning our scraper into a crawler that is capable of finding new details to crawl.
Is there an Ebay API?
No. While Ebay does have a private catalog API it contains only metadata fields like product ids. For the full product details, the only way is to scrape Ebay as described in this guide.
In this guide, we wrote a Python Ebay scraper for product listing data using Python.
We've scraped data from three parts of the Ebay domain:
Single variant products - using basic CSS selector parsing logic.
Multiple variant products - using hidden web data extraction.
Search pages - using search parameters and basic crawling rules.
Finally, to avoid Ebay scraping blocking, we used ScrapFly's API to automatically configure the HTTP connection. For more about ScrapFly, see our documentation and try it out for FREE!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
Do not scrape at rates that could damage the website.
Do not scrape data that's not available publicly.
Do not store PII of EU citizens protected by GDPR.
Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.
Scale Your Web Scraping
Anti-bot bypass, browser rendering, and rotating proxies — all in one API. Start with 1,000 free credits.
No credit card required 1,000 free API credits Anti-bot bypass included