

Bing.com is the second most popular search engine out there. It includes tons of valuable data found as search results. However, it's challenging to scrape due to its obfuscation challenges and high blocking rate.
In this article, we'll explain how to scrape Bing using Python. We'll be scraping valuable data fields, such as keywords and search ranking results. Let's dive in!
Key Takeaways
Master bing search python scraping with advanced techniques, SERP data extraction, and SEO monitoring for comprehensive search engine analysis.
- Reverse engineer Bing's API endpoints by intercepting browser network requests and analyzing JSON responses
- Extract structured search data including results, keywords, and ranking information from search engine results
- Implement pagination handling and search parameter management for comprehensive SERP data collection
- Configure proxy rotation and fingerprint management to avoid detection and rate limiting
- Use specialized tools like ScrapFly for automated Bing scraping with anti-blocking features
- Implement data validation and error handling for reliable search engine information extraction
Latest Bing Scraper Code
Why Scrape Bing Search?
Bing indexes a large sector of the public internet, including some websites that aren't indexed by other search engines, such as Google. So, by scraping Bing, we can access different data sources and numerous data insights.
Web scraping Bing is also a popular use case for SEO practices. Businesses can scrape Bing for search results to know their competitors' ranks and what keywords they are using.
Bing also features results as AI-answered snippets or summary snippets from popular websites, such as Wikipedia. These snippets can be directly scraped from the search results instead of extracting them from the origin website.
Project Setup
To scrape Bing, we'll be using Python with Scrapfly's Python SDK.
It can be easily installed using the below pip command:
$ pip install scrapfly-sdkThis guide will be focused on scraping Bing's search. However, the concepts can be applied to other search engines like Google, Duckduckgo, Kagi etc.

How to Scrape Bing Search Results
Let's start our guide by scraping Bing search result rankings (SERPs).
Search for any keyword, such as web scraping emails. The SERPs on the search page should look like this:
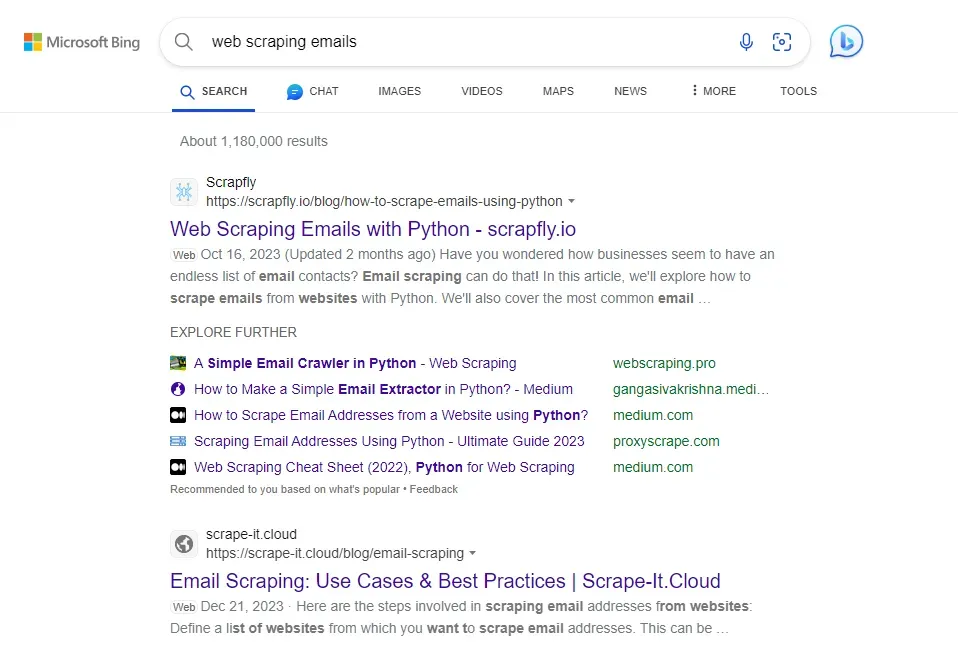
This search page contains other data snippets about the search keyword. However, we are only interested in the SERP results in this section. These results look like this in the HTML:
<main aria-label="Search Results">
......
<li class="b_algo" data-tag="" data-partnertag="" data-id="" data-bm="8">
....
<h2><a> .... SERP title .... </a></h2>
</li>
<li class="b_algo" data-tag="" data-partnertag="" data-id="" data-bm="9">
....
<h2><a> .... SERP title .... </a></h2>
</li>
<li class="b_algo" data-tag="" data-partnertag="" data-id="" data-bm="10">
....
<h2><a> .... SERP title .... </a></h2>
</li>
....
</main>Bing's search pages HTML is dynamic. This means the class names are often changing which can break our parsing selectors. Therefore, we'll match elements against distinct class attributes and avoid dynamic class names.For this, we'll use the XPath selector to parse the SERPs' data from the HTML, such as the rank position, title, description, link and website. The next step is utilizing this function while sending requests to scrape the data:
In the above Bing scraping code, we utilize the scrape_search function to crawl over search ages. The first parameter is used to start the page from a specific index. For example, if the first search page ends at the index 9, then the second page starts with the index 10. Then, we use the parse_serps to parse the HTML and extract Bing SERP data.
Here is a sample output of the result we got:
Example output:
[
{
"position": 1,
"title": "email-scraper · GitHub Topics · GitHub",
"url": "https://github.com/topics/email-scraper",
"origin": "Github",
"domain": "github.com",
"description": "WebNov 24, 2023 · An email scraper that finds email addresses located on a website. Made with Python Django. Emails are scraped using the requests, BeautifulSoup and regex …",
"date": "Nov 24, 2023"
},
{
"position": 2,
"title": "Web Scraping Emails with Python - scrapfly.io",
"url": "https://scrapfly.io/blog/posts/how-to-scrape-emails-using-python/",
"origin": "Scrapfly",
"domain": "scrapfly.io",
"description": "WebOct 16, 2023 (Updated 2 months ago) Have you wondered how businesses seem to have an endless list of email contacts? Email scraping can do that! In this article, we'll explore …",
"date": null
},
{
"position": 3,
"title": "Email scraping: Use cases, challenges & best practices in 2023",
"url": "https://research.aimultiple.com/email-scraping/",
"origin": "AIMultiple",
"domain": "research.aimultiple.com",
"description": "WebOct 13, 2023 · What is Email Scraping? Email scraping is the technique of extracting email addresses in bulk from websites using email scrapers. Top 3 benefits of email …",
"date": "Oct 13, 2023"
},
{
"position": 4,
"title": "Scrape Email Addresses From Websites using Python …",
"url": "https://www.scrapingdog.com/blog/scrape-email-addresses-from-website/",
"origin": "Scrapingdog",
"domain": "scrapingdog.com",
"description": "Web13-01-2023 Email Scraping has become a popular and efficient method for obtaining valuable contact information from the internet. By learning how to scrape emails, businesses and individuals can expand their networks, …",
"date": "13-01-2023"
},
{
"position": 5,
"title": "How to Scrape Emails on the Web? [8 Easy Steps and Tools]",
"url": "https://techjury.net/blog/how-to-scrape-emails-on-the-web/",
"origin": "Techjury",
"domain": "techjury.net",
"description": "WebNov 21, 2023 · Email scraping (or email address harvesting) is the process of gathering email addresses of potential clients from the Internet using automated tools. This method …",
"date": "Nov 21, 2023"
}
]Our Bing scraper can successfully scrape search pages for SERP data. Next, we'll scrape keyword data.
How to Scrape Bing Keyword Data
Knowing what users search for or ask about is an essential part of the SEO keyword research. This keyword data can be found on Bing search pages under the related queries section:
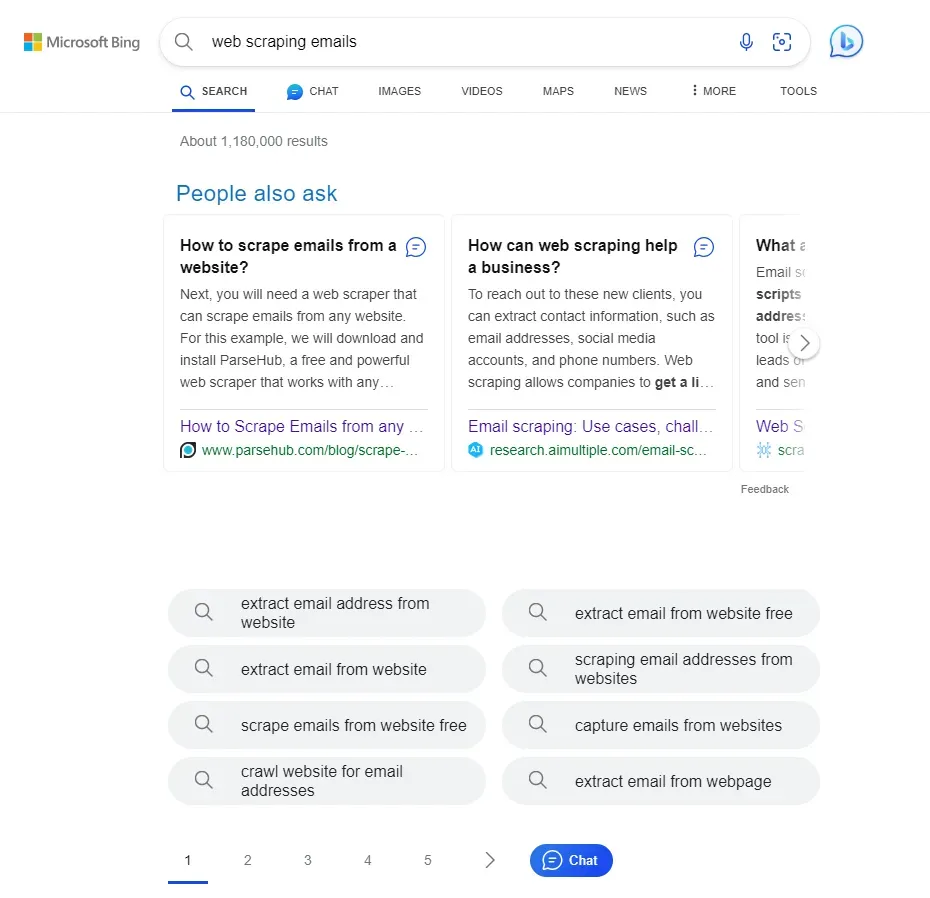
Like we did before, we'll use XPath selectors and match against elements' attributes to extracts the FAQs and related queries data. This data is often found on the first search page. So, pagination isn't required for this Bing scraping section:
The result is a list of keywords related to the used query on Bing search:
[
"extract email from website free",
"extract email address from website",
"extract email addresses from website",
"free email extractor from website",
"extract email from website online",
"extract emails from website",
"email extractor from websites",
"scrape emails from website free",
"scrape website for email addresses",
"online email extractor from website"
]With this last piece, our Bing scraper is complete! It scrapes SERPs, keywords and rich snippet data from search page HTMLs. However, our scraper is very likely to get blocked after sending additional requests. Let's have a look at a solution!
Avoid Bing Scraping Blocking With ScrapFly
To avoid Bing web scraping blocking, we'll use ScrapFly - a web scraping API that bypasses any website scraping blocking.

For scraping Bing with Scrapfly all we have to do is replace our HTTP client with the ScrapFly client:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some bing.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML contentLearn more about Web Scraping API and how it works.
FAQ
Is there a public API for Bing search?
Yes, Microsoft offers a subscription-based API for Bing search.
Is it legal to scrape Bing?
Yes, all the data on Bing search pages are publicly available, and it's legal to scrape them as long as you don't harm the website by keeping your scraping rate reasonable.
Are there alternatives for scraping Bing?
Yes, Google is the most popular alternative to the Bing search engine. We have explained how to scrape Google in a previous article. Many other search engines use Bing's data (like duckduckgo, kagi) so scraping bing covers scraping of these targets as well!
Web Scraping Bing - Summary
In this article, we explained how to scrape Bing search. We went through a step-by-step guide on creating a Bing scraper to scrape SERPs, keywords and rich snippet data. We also explained how to overcome the Bing scraping challenges:
-
Complex and dynamic HTML structure. By parsing the HTML by matching against distinct elements' attributes and avoiding dynamic class names.
-
Scraping blocking and localized searches. By adding explicit language headers and using ScrapFly to avoid Bing web scraping blocking.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


