When web scraping, it's often useful to monitor network requests. This enables retrieving crucial values found in response headers, body, or even cookies.
To better illustrate this, let's see what the request interception actually looks like using the below steps:
- Go to the login example on web-scraping.dev/login
- Open the devtools protocol by pressing the
F12 - Select the
Networktab - Fill in the login credentials and click login
After following the above steps, you will find each request event is captured, including its response details:
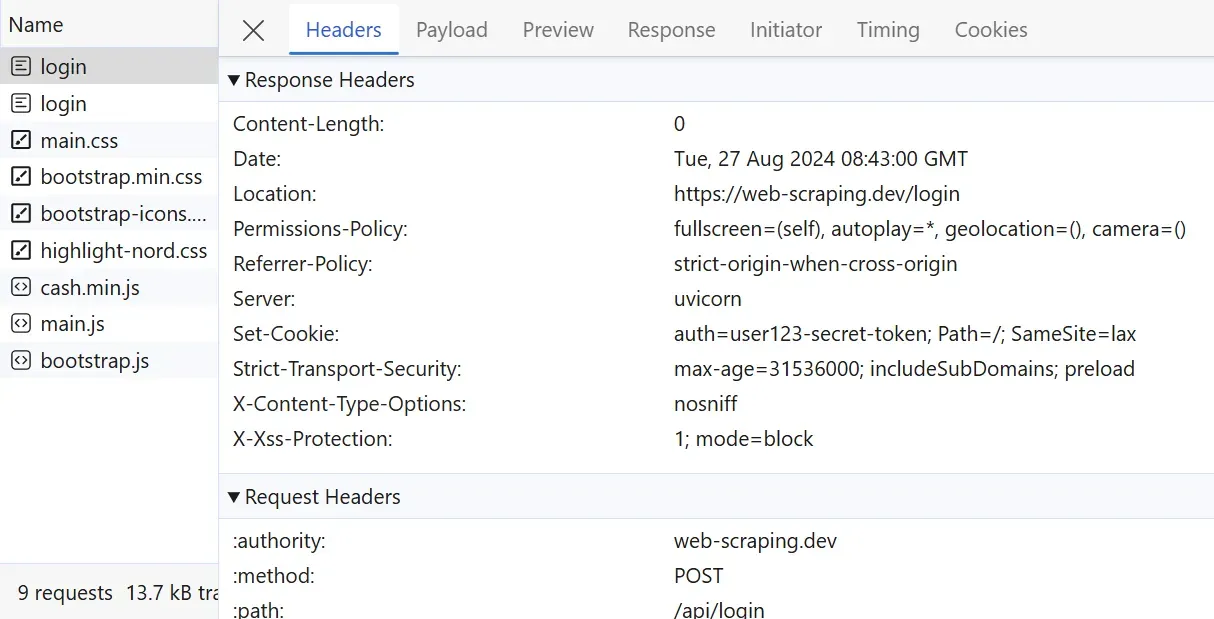
Above, we can observe the full details of the outgoing request. These details can be parsed to extract specific request-response values.
To allow Playwright get network requests and responses, we can use the page.on() method. This callback allows the headless browser to interept all network calls. Here's how to approach it using both Playwright's Python and NodeJS APIs:
from playwright.sync_api import sync_playwright
def intercept_request(route, request):
# We can update requests with custom headers
if "login" in request.url:
headers = request.headers.copy()
headers["Cookie"] = "cookiesAccepted=true; auth=user123-secret-token;"
route.continue_(headers=headers)
# Or adjust sent data
elif request.method == "POST":
route.continue_(post_data="patched")
print("patched POST request")
else:
route.continue_()
def intercept_response(response):
# We can extract details from background requests
if "login" in response.url:
print(response.headers)
return response
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=False)
context = browser.new_context(viewport={"width": 1920, "height": 1080})
page = context.new_page()
# Intercept requesets and responses
page.route("**/*", intercept_request)
page.on("response", intercept_response)
page.goto("https://web-scraping.dev/login")
# Ensure login request header was successfully patched
secret_message = page.inner_text("div#secret-message")
print(f"The secret message is {secret_message}")const { chromium } = require('playwright');
async function interceptRequest(route, request) {
// We can update requests with custom headers
if (request.url().includes("login")) {
const headers = { ...request.headers(), "Cookie": "cookiesAccepted=true; auth=user123-secret-token;" };
await route.continue({ headers });
}
// Or adjust sent data
else if (request.method() === "POST") {
await route.continue({ postData: "patched" });
console.log("patched POST request");
} else {
await route.continue();
}
}
async function interceptResponse(response) {
// We can extract details from background requests
if (response.url().includes("login")) {
console.log(response.headers());
}
return response;
}
(async () => {
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext({ viewport: { width: 1920, height: 1080 } });
const page = await context.newPage();
// Intercept requesets and responses
await page.route("**/*", interceptRequest);
page.on('response', interceptResponse);
await page.goto("https://web-scraping.dev/login");
// Ensure login request header was successfully patched
const secretMessage = await page.innerText("div#secret-message");
console.log(`The secret message is ${secretMessage}`);
await browser.close();
})();Here, we create two functions to capture background requests and responses. We override the cookie header for requests containing the /login endpoint. From the parsing results, we can see that the request was authorized, ensuring successful request modification.
Often, these background requests can contain important dynamic data. Blocking some requests can also reduce the bandwidth used while scraping, see our guide on blocking resources in Playwright for more.
For further details on web scraping with Playwright, refer to our dedicated guide.



