

In this web scraping tutorial, we'll take a deep dive into web crawling with Python - a powerful form of web scraping that not only collects data but figures out how to find it too.
The main appeal of web crawling is broad-spectrum application - a crawler can deal with many different domains and document structures implicitly. It's a great tool used for two purposes:
- indexing, like building search engines and discovering specific web pages.
- broad scraping, which means scraping multiple websites with the same web scraping script.
In this tutorial, we'll take an in-depth look at how to build a web crawler in Python. We'll also take a look at the common crawling concepts and challenges. To solidify all of this knowledge, we'll write an example project of our own by creating a crawler for any Shopify-powered websites like the NYTimes store!
Key Takeaways
Build intelligent web crawlers with exploration capabilities using Python, httpx, and parsel for broad-spectrum data extraction across multiple domains and document structures.
- Implement intelligent web crawler algorithms with URL discovery, filtering, and deduplication mechanisms
- Use httpx for asynchronous HTTP requests and parsel for HTML parsing with CSS selector and XPath support
- Configure URL structure parsing with w3lib and tldextract for domain validation and link extraction
- Apply intelligent crawling strategies for e-commerce platforms like Shopify with product discovery
- Implement proper logging, error handling, and rate limiting for reliable large-scale crawling operations
- Use specialized tools like ScrapFly for automated web crawling with anti-blocking features
What Does Crawling Mean in Web Scraping?
In essence, crawling is web scraping with exploration capabilities.
When we web scrape, we often have very well-defined list of URLs like "scrape these product web pages on this e-commerce shop". On the other hand, when we're crawling we have a much looser set of rules like "find all product web pages and scrape them on any of these websites".
The key difference is that web crawlers are intelligent explorers while web scrapers are focused workers.
If crawling is so great why don't we crawl everything?
Web crawling is simply more resource-intensive and harder to develop as we need to consider a whole series of new problems related to this exploration component.
What are the common cases of crawling in web scraping?
Most commonly, web crawlers are used to discover targets when the website doesn't have a target directory or a sitemap. For example, if an e-commerce website doesn't have a product directory we could crawl all of its web pages and find all of the products through backlinks like the "related products" section and so on.
What is broad crawling?
Broad crawling is a form of crawling when instead of crawling a single domain or website a crawler is capable of navigating multiple different domains. Broad crawlers need to be extra diligent to consider many different web technologies and be able to avoid spam, invalid documents and even resource attacks.
Setup
In this guide, we'll be writing a Python crawler using a few packages:
- httpx as our HTTP client to retrieve URLs. Alternatively, feel free to follow along with requests which is a popular alternative.
- parsel to parse HTML trees. Alternatively, feel free to follow along with beautifulsoup which is a popular alternative.
- w3lib and tldextract for parsing URL structures.
- loguru for nicely formatted logs so we can follow along more easily.
These Python packages can be installed through pip install console command:
pip install httpx parsel w3lib tldextract loguruWe'll also run our web crawlers asynchronously using asyncio to increase our web scraping speed as crawling is very connection intensive.
Crawler Components
The most important component of a web crawler is its exploration mechanism, which introduces many new components like URL discovery and filtering. To understand this, let's take a look at the general flow of the crawl loop:

The crawler starts with a pool of URLs (the initial seed is often called start urls) and scrapes their responses (HTML data). Then one or two processing steps are performed:
- Responses are parsed for more URLs to follow which are being filtered and added to the next crawl loop pool.
- Optional: callback is fired to process responses for indexing, archival or just general data parsing.
This loop is repeated until no new URLs are found or a certain end condition is met like crawling depth or collected URL count is reached.
This sounds pretty simple, so let's make a crawler of our own! We'll start with parser and filter since these two are the most important part of our Python crawler - the exploration.
HTML Parsing and URL Filtering
We can easily extract all URLs from an HTML document by extracting the href attributes of all <a> nodes. For this, we can use parsel package with either CSS selectors or XPath selectors.
Let's add a simple URL extractor function:
from typing import List
from urllib.parse import urljoin
from parsel import Selector
import httpx
def extract_urls(response: httpx.Response) -> List[str]:
tree = Selector(text=response.text)
# using XPath
urls = tree.xpath('//a/@href').getall()
# or CSS
urls = tree.css('a::attr(href)').getall()
# we should turn all relative urls to absolute, e.g. /foo.html to https://domain.com/foo.html
urls = [urljoin(str(response.url), url.strip()) for url in urls]
return urlsRun Code & Example Output
response = httpx.get("https://httpbin.dev/links/10/1")
for url in extract_urls(response):
print(url)https://httpbin.dev/links/10/0
https://httpbin.dev/links/10/2
https://httpbin.dev/links/10/3
https://httpbin.dev/links/10/4
https://httpbin.dev/links/10/5
https://httpbin.dev/links/10/6
https://httpbin.dev/links/10/7
https://httpbin.dev/links/10/8
https://httpbin.dev/links/10/9Our url extractor is very primitive and we can't use it in our crawler as it produces duplicate and non-crawlable urls (like downloadable files). The next component of our Python crawler is a filter that can:
- Normalize found URLs and deduplicate them.
- Filter out offsite URLs (of a different domain like social media links etc.)
- Filter out uncrawlable URLs (like file download links)
For this, we'll be using w3lib and tldextract libraries which offer great utility functions for processing URLs. Let's use it to write our URL filter which will filter out bad and seen URLs:
from typing import List, Pattern
import posixpath
from urllib.parse import urlparse
from tldextract import tldextract
from w3lib.url import canonicalize_url
from loguru import logger as log
class UrlFilter:
IGNORED_EXTENSIONS = [
# archives
'7z', '7zip', 'bz2', 'rar', 'tar', 'tar.gz', 'xz', 'zip',
# images
'mng', 'pct', 'bmp', 'gif', 'jpg', 'jpeg', 'png', 'pst', 'psp', 'tif', 'tiff', 'ai', 'drw', 'dxf', 'eps', 'ps', 'svg', 'cdr', 'ico',
# audio
'mp3', 'wma', 'ogg', 'wav', 'ra', 'aac', 'mid', 'au', 'aiff',
# video
'3gp', 'asf', 'asx', 'avi', 'mov', 'mp4', 'mpg', 'qt', 'rm', 'swf', 'wmv', 'm4a', 'm4v', 'flv', 'webm',
# office suites
'xls', 'xlsx', 'ppt', 'pptx', 'pps', 'doc', 'docx', 'odt', 'ods', 'odg', 'odp',
# other
'css', 'pdf', 'exe', 'bin', 'rss', 'dmg', 'iso', 'apk',
]
def __init__(self, domain:str=None, subdomain: str=None, follow:List[Pattern]=None) -> None:
# restrict filtering to specific TLD
self.domain = domain or ""
# restrict filtering to sepcific subdomain
self.subdomain = subdomain or ""
self.follow = follow or []
log.info(f"filter created for domain {self.subdomain}.{self.domain} with follow rules {follow}")
self.seen = set()
def is_valid_ext(self, url):
"""ignore non-crawlable documents"""
return posixpath.splitext(urlparse(url).path)[1].lower() not in self.IGNORED_EXTENSIONS
def is_valid_scheme(self, url):
"""ignore non http/s links"""
return urlparse(url).scheme in ['https', 'http']
def is_valid_domain(self, url):
"""ignore offsite urls"""
parsed = tldextract.extract(url)
return parsed.registered_domain == self.domain and parsed.subdomain == self.subdomain
def is_valid_path(self, url):
"""ignore urls of undesired paths"""
if not self.follow:
return True
path = urlparse(url).path
for pattern in self.follow:
if pattern.match(path):
return True
return False
def is_new(self, url):
"""ignore visited urls (in canonical form)"""
return canonicalize_url(url) not in self.seen
def filter(self, urls: List[str]) -> List[str]:
"""filter list of urls"""
found = []
for url in urls:
if not self.is_valid_scheme(url):
log.debug(f"drop ignored scheme {url}")
continue
if not self.is_valid_domain(url):
log.debug(f"drop domain missmatch {url}")
continue
if not self.is_valid_ext(url):
log.debug(f"drop ignored extension {url}")
continue
if not self.is_valid_path(url):
log.debug(f"drop ignored path {url}")
continue
if not self.is_new(url):
log.debug(f"drop duplicate {url}")
continue
self.seen.add(canonicalize_url(url))
found.append(url)
return foundRun Code & Example Output
import httpx
from parsel import Selector
from urllib.parse import urljoin
def extract_urls(response: httpx.Response) -> List[str]:
tree = Selector(text=response.text)
# using XPath
urls = tree.xpath('//a/@href').getall()
# or CSS
urls = tree.css('a::attr(href)').getall()
# we should turn all relative urls to absolute, e.g. /foo.html to https://domain.com/foo.html
urls = [urljoin(str(response.url), url.strip()) for url in urls]
return urls
nytimes_filter = UrlFilter("nytimes.com", "store")
response = httpx.get("https://store.nytimes.com")
urls = extract_urls(response)
filtered = nytimes_filter.filter(urls)
filtered_2nd_page = nytimes_filter.filter(urls)
print(filtered)
print(filtered_2nd_page)Notice that the second run will produce no results as they have been filtered out by our filter:
['https://store.nytimes.com/collections/best-sellers', 'https://store.nytimes.com/collections/gifts-under-25', 'https://store.nytimes.com/collections/gifts-25-50', 'https://store.nytimes.com/collections/gifts-50-100', 'https://store.nytimes.com/collections/gifts-over-100', 'https://store.nytimes.com/collections/gift-sets', 'https://store.nytimes.com/collections/apparel', 'https://store.nytimes.com/collections/accessories', 'https://store.nytimes.com/collections/babies-kids', 'https://store.nytimes.com/collections/books', 'https://store.nytimes.com/collections/home-office', 'https://store.nytimes.com/collections/toys-puzzles-games', 'https://store.nytimes.com/collections/wall-art', 'https://store.nytimes.com/collections/sale', 'https://store.nytimes.com/collections/cooking', 'https://store.nytimes.com/collections/black-history', 'https://store.nytimes.com/collections/games', 'https://store.nytimes.com/collections/early-edition', 'https://store.nytimes.com/collections/local-edition', 'https://store.nytimes.com/collections/pets', 'https://store.nytimes.com/collections/the-verso-project', 'https://store.nytimes.com/collections/custom-books', 'https://store.nytimes.com/collections/custom-reprints', 'https://store.nytimes.com/products/print-newspapers', 'https://store.nytimes.com/collections/special-sections', 'https://store.nytimes.com/pages/corporate-gifts', 'https://store.nytimes.com/pages/about-us', 'https://store.nytimes.com/pages/contact-us', 'https://store.nytimes.com/pages/faqs', 'https://store.nytimes.com/pages/return-policy', 'https://store.nytimes.com/pages/terms-of-sale', 'https://store.nytimes.com/pages/terms-of-service', 'https://store.nytimes.com/pages/image-licensing', 'https://store.nytimes.com/pages/privacy-policy', 'https://store.nytimes.com/search', 'https://store.nytimes.com/', 'https://store.nytimes.com/account/login', 'https://store.nytimes.com/cart', 'https://store.nytimes.com/products/the-custom-birthday-book', 'https://store.nytimes.com/products/new-york-times-front-page-reprint', 'https://store.nytimes.com/products/stacked-logo-baseball-cap', 'https://store.nytimes.com/products/new-york-times-front-page-jigsaw', 'https://store.nytimes.com/products/new-york-times-swell-water-bottle', 'https://store.nytimes.com/products/super-t-sweatshirt', 'https://store.nytimes.com/products/cooking-apron', 'https://store.nytimes.com/products/new-york-times-travel-tumbler', 'https://store.nytimes.com/products/debossed-t-mug', 'https://store.nytimes.com/products/herald-tribune-breathless-t-shirt', 'https://store.nytimes.com/products/porcelain-logo-mug', 'https://store.nytimes.com/products/the-ultimate-birthday-book', 'https://store.nytimes.com/pages/shipping-processing']
[]This generic filter will make sure our Python web crawler avoids crawling redundant or invalid targets. We could further extend this with more rules like a link scoring system or explicit follow rules but for now, let's take a look at the rest of our crawler.
Crawling Loop
Now that we have our explore logic ready, all we're missing is a crawl loop that would take advantage of it.
To start, we'll need a client to retrieve page data. Most commonly, an HTTP client like httpx or requests can be used to scrape any HTML pages.
However, using an HTTP client we may not be able to scrape highly dynamic content like that of javascript-powered web apps or single-page applications (SPAs). To crawl such targets, we need a JavaScript execution context like a headless web browser runner, which can be achieved through browser automation tools (like Playwright, Selenium or Puppeteer).
So for now, let's stick with httpx:
import asyncio
from typing import Callable, Dict, List, Optional, Tuple
from urllib.parse import urljoin
import httpx
from parsel import Selector
from loguru import logger as log
from Filter import UrlFilter # Add the previous code to a file called Filter
class Crawler:
async def __aenter__(self):
self.session = await httpx.AsyncClient(
timeout=httpx.Timeout(60.0),
limits=httpx.Limits(max_connections=5),
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
},
).__aenter__()
return self
async def __aexit__(self, *args, **kwargs):
await self.session.__aexit__(*args, **kwargs)
def __init__(self, filter: UrlFilter, callbacks: Optional[Dict[str, Callable]] = None) -> None:
self.url_filter = filter
self.callbacks = callbacks or {}
def parse(self, responses: List[httpx.Response]) -> List[str]:
"""find valid urls in responses"""
all_unique_urls = set()
found = []
for response in responses:
sel = Selector(text=response.text, base_url=str(response.url))
_urls_in_response = set(
urljoin(str(response.url), url.strip())
for url in sel.xpath("//a/@href").getall()
)
all_unique_urls |= _urls_in_response
urls_to_follow = self.url_filter.filter(all_unique_urls)
log.info(f"found {len(urls_to_follow)} urls to follow (from total {len(all_unique_urls)})")
return urls_to_follow
async def scrape_url(self, url):
return await self.session.get(url, follow_redirects=True)
async def scrape(self, urls: List[str]) -> Tuple[List[httpx.Response], List[Exception]]:
"""scrape urls and return their responses"""
responses = []
failures = []
log.info(f"scraping {len(urls)} urls")
tasks = [self.scrape_url(url) for url in urls]
for result in await asyncio.gather(*tasks, return_exceptions=True):
if isinstance(result, httpx.Response):
responses.append(result)
else:
failures.append(result)
return responses, failures
async def run(self, start_urls: List[str], max_depth=5) -> None:
"""crawl target to maximum depth or until no more urls are found"""
url_pool = start_urls
depth = 0
while url_pool and depth <= max_depth:
responses, failures = await self.scrape(url_pool)
log.info(f"depth {depth}: scraped {len(responses)} pages and failed {len(failures)}")
url_pool = self.parse(responses)
await self.callback(responses)
depth += 1
async def callback(self, responses):
for response in responses:
for pattern, fn in self.callbacks.items():
if pattern.match(str(response.url)):
log.debug(f'found matching callback for {response.url}')
fn(response=response)🙋 Make sure to add the code that contain the `UrlFilter` class in a file named `Filter` in the same project directory of this code.
Above, we defined our crawler object which implements all of the steps from our crawling loop graph:
scrapemethod implements URL retrieval viahttpx's HTTP client.parsemethod implements response parsing for more URLs viaparsel's XPath selector.callbackmethod implements product parsing functional10ty as some of the pages we're crawling are products.runmethod implements our crawl loop.
To further understand this, let's take our Python crawler for a spin with an example project!
Example Python Crawler: Crawling Shopify
Web crawlers are great for web scraping generic websites that we don't know the exact structure. In particular, crawlers allow us to easily scrape websites built with the same web frameworks or web platforms. Write once - apply everywhere!
In this section, we'll take a look at how we can crawl any website built with Shopify using Python.
For example, let's start with NYTimes store which is powered by Shopify.
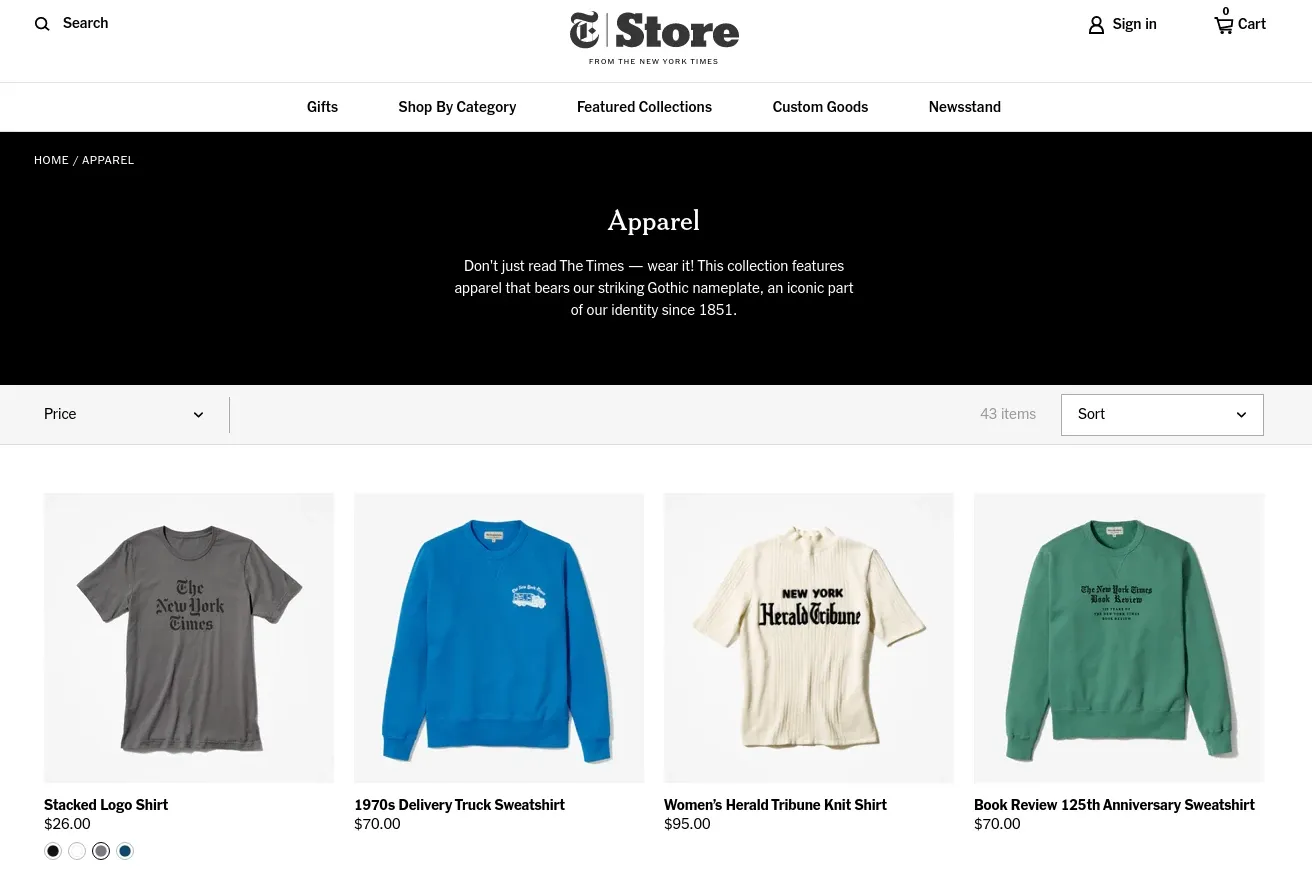
We can start by identifying our target - a product that is for sale. For example, let's take this t-shirt Stacked Logo Shirt
Just by looking at the URL, we can see that all product URLs contain /products/ part in them - that's how we can tell to our crawler which responses to callback on for parsing - every URL that contains this text:
import asyncio
import re
def parse_product(response):
print(f"found product: {response.url}")
async def run():
callbacks = {
# any url that contains "/products/" is a product page
re.compile(".+/products/.+"): parse_product
}
url_filter = UrlFilter(domain="nytimes.com", subdomain="store")
async with Crawler(url_filter, callbacks=callbacks) as crawler:
await crawler.run(["https://store.nytimes.com/"])
if __name__ == "__main__":
asyncio.run(run())In the example above, we add a callback for any crawled response that contains /product/ in the URL. If we run this, we'll see several hundred lines printed with product URLs. Let's take a look at how we can parse product information during a crawl.
Parsing Crawled Data
Often we don't know what sort of content structure our Python crawler will encounter so when parsing crawled content we should look for generic parsing algorithms.
In Shopify's case, we can see that product data is often present in the HTML body as JSON objects. For example, we would commonly see it in <script> nodes:

This means we can design a generic parse to extract all JSON objects from all <script> tags that contain known keys. If we take a look at NYTimes store's product object we can see some common patterns:
{
"id": 6708867694662,
"title": "Stacked Logo Shirt",
"handle": "stacked-logo-shirt",
"published_at": "2022-07-15T11:36:23-04:00",
"created_at": "2021-10-20T11:10:55-04:00",
"vendor": "NFS",
"type": "Branded",
"tags": [
"apparel",
"branded",
"category-apparel",
"discontinued",
"discountable-product",
"gifts-25-50",
"price-50",
"processing-nfs-regular",
"recipient-men",
"recipient-women",
"sales-soft-goods",
"sizeway"
],
"price": 2600,
"price_min": 2600,
"price_max": 2600,
"available": true,
"..."
}All products contain keys like "published_at" or "price". With a bit of parsing magic we can easily extract such objects:
from parsel import Selector
import json
import httpx
def extract_json_objects(text: str, decoder=json.JSONDecoder()):
"""Find JSON objects in text, and yield the decoded JSON data"""
pos = 0
while True:
match = text.find('{', pos)
if match == -1:
break
try:
result, index = decoder.raw_decode(text[match:])
yield result
pos = match + index
except ValueError:
pos = match + 1
def find_json_in_script(response: httpx.Response, keys):
"""find all json objects in HTML <script> tags that contain specified keys"""
scripts = Selector(text=response.text).xpath('//script/text()').getall()
objects = []
for script in scripts:
if not all(f'"{k}"' in script for k in keys):
continue
objects.extend(extract_json_objects(script))
return [obj for obj in objects if all(k in str(obj) for k in keys)]Run Code & Example Output
url = "https://store.nytimes.com/collections/apparel/products/a1-stacked-logo-shirt"
response = httpx.get(url)
products = find_json_in_script(response, ["published_at", "price"])
print(json.dumps(products, indent=2, ensure_ascii=False)[:500])Which will scrape results (truncated):
{
"id": 6708867694662,
"title": "Stacked Logo Shirt",
"handle": "stacked-logo-shirt",
"description": "\u003cp\u003eWe’ve gone bigger and bolder with the iconic Times logo, spreading it over three lines on this unisex T-shirt so our name can be seen from a distance when you walk down the streets of Brooklyn or Boston.\u003c/p\u003e\n\u003c!-- split --\u003e\n\u003cp\u003eThese days T-shirts are the hippest way to make a statement or express an emotion, and our Stacked Logo Shirt lets you show your support for America’s preeminent newspaper.\u003c/p\u003e\n\u003cp\u003eOur timeless masthead logo is usually positioned on one line, but to increase the lettering our designers have stacked the words. The result: The Times name is large, yet discreet, so you can keep The Times close to your heart without looking like a walking billboard.\u003c/p\u003e\n\u003cp\u003eThis shirt was made by Royal Apparel, who launched in the early '90s on a desk in the Garment District of Manhattan. As a vast majority of the fashion industry moved production overseas, Royal Apparel stayed true to their made in USA mission and became a leader in American-made and eco-friendly garment production in the country.\u003c/p\u003e",
"published_at": "2022-07-15T11:36:23-04:00",
"created_at": "2021-10-20T11:10:55-04:00",
"vendor": "NFS",
"type": "Branded",
"tags": [
"apparel",
"branded",
"category-apparel",
"discontinued",
"discountable-product",
"gifts-25-50",
"price-50",
"processing-nfs-regular",
"recipient-men",
"recipient-women",
"sales-soft-goods",
"sizeway"
],
"price": 2600,
"price_min": 2600,
"price_max": 2600,
"available": true,
...
}This approach can help us extract data from the web of many different Shopify-powered websites! Finally, let's apply it to our crawler:
# ...
import asyncio
results = []
def parse_product(response):
products = find_json_in_script(response, ["published_at", "price"])
results.extend(products)
if not products:
log.warning(f"could not find product data in {response.url}")
async def run():
callbacks = {
# any url that contains "/products/" is a product page
re.compile(".+/products/.+"): parse_product
}
url_filter = UrlFilter(domain="nytimes.com", subdomain="store")
async with Crawler(url_filter, callbacks=callbacks) as crawler:
await crawler.run(["https://store.nytimes.com/"])
print(results)
if __name__ == "__main__":
asyncio.run(run())
Now, if we run our crawler again we'll not only explore and find products but scrape all of their data as well!
We got through the most important parts of web crawling with Python. Let's take a look at how can we power up our web crawler with JavaScript rendering and block bypass.
Power-up with ScrapFly
When crawling or broad-crawling we have significantly less control over our program's flow than when web scraping. Some links might be protected against web scrapers and some might be dynamic javascript-powered web pages.

We can easily power up our crawlers with these features by replacing our HTTP client httpx with scrapfly-sdk which can be installed through pip:
$ pip install scrapfly-sdkLet's take a look at how can we enable ScrapFly in our crawler to crawl javascript-powered websites and avoid blocking:
Crawler with ScrapFly
import asyncio
import json
import posixpath
import re
from typing import Callable, Dict, List, Optional, Tuple
from urllib.parse import urljoin, urlparse
from scrapfly import ScrapflyClient, ScrapeConfig, ScrapeApiResponse
from loguru import logger as log
from tldextract import tldextract
from w3lib.url import canonicalize_url
class UrlFilter:
IGNORED_EXTENSIONS = [
# archives
'7z', '7zip', 'bz2', 'rar', 'tar', 'tar.gz', 'xz', 'zip',
# images
'mng', 'pct', 'bmp', 'gif', 'jpg', 'jpeg', 'png', 'pst', 'psp', 'tif', 'tiff', 'ai', 'drw', 'dxf', 'eps', 'ps', 'svg', 'cdr', 'ico',
# audio
'mp3', 'wma', 'ogg', 'wav', 'ra', 'aac', 'mid', 'au', 'aiff',
# video
'3gp', 'asf', 'asx', 'avi', 'mov', 'mp4', 'mpg', 'qt', 'rm', 'swf', 'wmv', 'm4a', 'm4v', 'flv', 'webm',
# office suites
'xls', 'xlsx', 'ppt', 'pptx', 'pps', 'doc', 'docx', 'odt', 'ods', 'odg', 'odp',
# other
'css', 'pdf', 'exe', 'bin', 'rss', 'dmg', 'iso', 'apk',
]
def __init__(self, domain=None, subdomain=None, follow=None) -> None:
self.domain = domain or ""
self.subdomain = subdomain or ""
log.info(f"filter created for domain {self.subdomain}.{self.domain}")
self.seen = set()
self.follow = follow or []
def is_valid_ext(self, url):
"""ignore non-crawlable documents"""
return posixpath.splitext(urlparse(url).path)[1].lower() not in self.IGNORED_EXTENSIONS
def is_valid_scheme(self, url):
"""ignore non http/s links"""
return urlparse(url).scheme in ["https", "http"]
def is_valid_domain(self, url):
"""ignore offsite urls"""
parsed = tldextract.extract(url)
return parsed.registered_domain == self.domain and parsed.subdomain == self.subdomain
def is_valid_path(self, url):
"""ignore urls of undesired paths"""
if not self.follow:
return True
path = urlparse(url).path
for pattern in self.follow:
if pattern.match(path):
return True
return False
def is_new(self, url):
"""ignore visited urls (in canonical form)"""
return canonicalize_url(url) not in self.seen
def filter(self, urls: List[str]) -> List[str]:
"""filter list of urls"""
found = []
for url in urls:
if not self.is_valid_scheme(url):
log.debug(f"drop ignored scheme {url}")
continue
if not self.is_valid_domain(url):
log.debug(f"drop domain missmatch {url}")
continue
if not self.is_valid_ext(url):
log.debug(f"drop ignored extension {url}")
continue
if not self.is_valid_path(url):
log.debug(f"drop ignored path {url}")
continue
if not self.is_new(url):
log.debug(f"drop duplicate {url}")
continue
self.seen.add(canonicalize_url(url))
found.append(url)
return found
class Crawler:
async def __aenter__(self):
self.sesion = ScrapflyClient(
key="YOUR_SCRAPFLY_KEY",
max_concurrency=2,
).__enter__()
return self
async def __aexit__(self, *args, **kwargs):
self.sesion.__exit__(*args, **kwargs)
def __init__(self, filter: UrlFilter, callbacks: Optional[Dict[str, Callable]] = None) -> None:
self.url_filter = filter
self.callbacks = callbacks or {}
def parse(self, results: List[ScrapeApiResponse]) -> List[str]:
"""find valid urls in responses"""
all_unique_urls = set()
for result in results:
_urls_in_response = set(
urljoin(str(result.context["url"]), url.strip()) for url in result.selector.xpath("//a/@href").getall()
)
all_unique_urls |= _urls_in_response
urls_to_follow = self.url_filter.filter(all_unique_urls)
# log.info(f"found {len(urls_to_follow)} urls to follow (from total {len(all_unique_urls)})")
return urls_to_follow
async def scrape(self, urls: List[str]) -> Tuple[List[ScrapeApiResponse], List[Exception]]:
"""scrape urls and return their responses"""
log.info(f"scraping {len(urls)} urls")
to_scrape = [
ScrapeConfig(
url=url,
# note: we can enable anti bot protection bypass
# asp=True,
# note: we can also enable rendering of javascript through headless browsers
# render_js=True
)
for url in urls
]
failures = []
results = []
async for result in self.sesion.concurrent_scrape(to_scrape):
if isinstance(result, ScrapeApiResponse):
results.append(result)
else:
# some pages might be unavailable: 500 etc.
failures.append(result)
return results, failures
async def run(self, start_urls: List[str], max_depth=10) -> None:
"""crawl target to maximum depth or until no more urls are found"""
url_pool = start_urls
depth = 0
while url_pool and depth <= max_depth:
results, failures = await self.scrape(url_pool)
log.info(f"depth {depth}: scraped {len(results)} pages and failed {len(failures)}")
url_pool = self.parse(results)
await self.callback(results)
depth += 1
async def callback(self, results):
for result in results:
for pattern, fn in self.callbacks.items():
if pattern.match(result.context["url"]):
fn(result=result)
def extract_json_objects(text: str, decoder=json.JSONDecoder()):
"""Find JSON objects in text, and yield the decoded JSON data"""
pos = 0
while True:
match = text.find("{", pos)
if match == -1:
break
try:
result, index = decoder.raw_decode(text[match:])
yield result
pos = match + index
except ValueError:
pos = match + 1
def find_json_in_script(result: ScrapeApiResponse, keys: List[str]) -> List[Dict]:
"""find all json objects in HTML <script> tags that contain specified keys"""
scripts = result.selector.xpath("//script/text()").getall()
objects = []
for script in scripts:
if not all(f'"{k}"' in script for k in keys):
continue
objects.extend(extract_json_objects(script))
return [obj for obj in objects if all(k in str(obj) for k in keys)]
results = []
def parse_product(result: ScrapeApiResponse):
products = find_json_in_script(result, ["published_at", "price"])
results.extend(products)
if not products:
log.warning(f"could not find product data in {result}")
async def run():
callbacks = {re.compile(".+/products/.+"): parse_product}
url_filter = UrlFilter(domain="nytimes.com", subdomain="store")
async with Crawler(url_filter, callbacks=callbacks) as crawler:
await crawler.run(['https://store.nytimes.com/'])
print(results)
if __name__ == "__main__":
asyncio.run(run())Just by replacing httpx with ScrapFly SDK we can enable JavaScript rendering and avoid being blocked!
Fully Managed Crawling with Crawler API
For projects where you need to crawl entire domains without building and maintaining crawler infrastructure, Scrapfly's Crawler API handles the entire process automatically:
- Automatic URL Discovery: Recursively finds and follows links across domains without writing spider logic
- Built-in Anti-Bot Bypass: Handles Cloudflare, DataDome and other protections automatically
- JavaScript Rendering: Crawls dynamic SPAs and AJAX-heavy sites with full browser execution
- Smart Filtering: Automatically deduplicates URLs and filters non-HTML content
The Crawler API is ideal when you need reliable large-scale crawling without managing the URL filtering, deduplication, and rate limiting logic covered in this guide.
Scrapy Framework for Crawling
Scrapy is a popular web scraping framework in Python and it has a great feature set writing a Python web crawler. Scrapy's web spider class CrawlSpider implements the same crawling algorithm we covered in this article.
Scrapy comes with many batteries-included features like bad response retrying and efficient request scheduling and even integrates with ScrapFly. However, Scrapy - being a full framework - can be difficult to patch and integrate with other python technologies.
FAQ
What's the difference between scraping and crawling?
Crawling is web scraping with exploration capability. Where web scrapers are programs with explicit scraping rules crawlers tend to have more creative navigation algorithms. Crawlers are often used in broad crawling - where many different domains are crawled by the same program.
What is crawling used for?
Crawling is commonly used in generic dataset collection like data science and machine learning training.
It's also used to generate web indexes for search engines (e.g. Google). Finally, crawling is web scraping where target discovery cannot be implemented through sitemaps or directory systems - crawlers can find all product links just by exploring every link on the website.
How to speed up crawling?
The best way to speed up crawling is to convert your crawler to an asynchronous program. Since crawling performs a lot more requests than directed web scraping crawler programs suffer from a lot of IO blocks. In other words, crawlers often wait doing nothing waiting for web server to respond. Good async program design can speed up programs a thousand times!
Can I crawl dynamic javascript websites or SPAs?
Yes! However, to crawl dynamic javascript websites and SPAs crawler needs to be able to execute javascript. The easiest approach to this is to use a headless browser automated through Web Scraping with Playwright and Python, Web Scraping with Selenium and Python, How to Web Scrape with Puppeteer and NodeJS in 2026 or ScrapFly's very own Javascript Rendering function.
For more on details, see our introduction tutorial How to Scrape Dynamic Websites Using Headless Web Browsers.
Summary
In this article, we've taken an in-depth look into what is web crawling and how it differs from web scraping. We built a web with Python alongside with a few Python packages.
To solidify our knowledge we explained how to crawl data from website using Python, which can crawl any Shopify-powered website.
Finally, we've taken a look at advanced crawling problems like working with dynamic javascript-powered websites and blocking and how can we solve that using ScrapFly web API - so, give it a shot!


