

The Go programming language is a popular statically typed language. Its memory management, garbage collection, and concurrency features make it an excellent choice for building extensive and scalable applications. But what about utilizing these capabilities through web scraping?
In this guide, we’ll take a deep dive into web scraping with Golang. We’ll start by exploring the core concepts of sending HTTP requests, parsing, crawling, and data manipulation. Then, we’ll go through a step-by-step guide to using Go Colly - the most popular package for building Go scrapers.
With Go, you can create a web scraper with only a few lines of code. Let's get started!
Key Takeaways
Master go colly web scraping using native HTTP clients and the Colly framework for concurrent data extraction with strong performance and scalability.
- Use Go's native net/http package for basic web scraping with excellent performance and concurrency support
- Parse HTML with goquery library for jQuery-like selectors and DOM manipulation in Go applications
- Leverage Colly framework for advanced scraping with built-in concurrency, callbacks, and rate limiting
- Handle concurrent scraping with Go's goroutines for high-performance data collection at scale
- Implement proper error handling and retry logic using Go's robust error handling patterns
- Build scalable scrapers with Go's memory management and garbage collection for production deployments
Setup
Let's start by going through the steps required to build and run a Golang web scraper.
Setting Up Environment
To set the Go environment on your machine, start by downloading the Go release according to your operating system. After this, follow the installation guide to configure the PATH environment.
To verify your installation, use the below command to view the installed version:
$ go version
go version go1.20.3 windows/amd64
Installing Required Packages
In this Golang scraping guide, we'll be using a few packages:
- goquery: An HTML parsing library that implements common jQuery features in Go, allowing for full-featured DOM tree manipulation.
- htmlquery: An HTML querying package that enables parsing with XPath selectors.
- colly: A popular scraping framework providing a clear interface for writing web crawlers.
Before installing the above packages, create a new project using the go mod init followed by the project name:
go mod init product-scraper
Next, add the below package requirements to the go.mod file:
module product-scraper
go 1.20
// only add the below code
require (
github.com/PuerkitoBio/goquery v1.9.2
github.com/antchfx/htmlquery v1.3.2
github.com/gocolly/colly v1.2.0
)
Finally, use the go mod tidy command to actually download all the required dependencies.
Web Scraping With Golang: Core Concepts
Just like any programming language, building an efficient Go scraper to perform web scraping is possible through native HTTP requests and basic parsing capabilities.
In the following sections, we'll review some Go web scraping quick start guides into the core concept required for extracting data.
🙋 The _ (underscore) identifier is frequently used throughout this guide. It's to ignore error handling when errors are returned. To process them, use err instead of _ and handle them: if (err != nil) {return err}.
Sending HTTP Requests
HTTP requests are the core of all web scrapers, allowing them to automatically retrieve data from various endpoints. In order to retrieve any endpoint'’s data, a request must be sent to the server to retrieve the data in the response body:

Request Method
Sending HTTP requests in a Golang scraper is possible through the native net/http package. Here's how to use it to send a simple GET request:
package main
import (
"fmt"
"io"
"net/http"
"time"
)
func main() {
url := "https://httpbin.dev/headers"
client := &http.Client{
Timeout: 30 * time.Second, // Define client timeout
}
req, _ := http.NewRequest("GET", url, nil) // Create new request
resp, _ := client.Do(req) // Send the request
defer resp.Body.Close()
// Read the HTML
body, _ := io.ReadAll(resp.Body)
fmt.Println(string(body))
}
Above, an HTTP client is created with 30s timeout. Then, it's used to define a simple GET request to httpbin.dev/headers to retrieve the basic request details. Finally, we sent the request and read the response body.
To change the HTTP request method, all we have to do is declare the method to use:
func main() {
url := "https://httpbin.dev/post"
client := &http.Client{
Timeout: 30 * time.Second, // Define client timeout
}
req, _ := http.NewRequest("POST", url, nil) // Specify request method
resp, _ := client.Do(req)
// ....
}
Request Headers
To set header values in a Go webscraper, set them while defining the request:
func main() {
url := "https://httpbin.dev/headers"
client := &http.Client{
Timeout: 30 * time.Second,
}
req, _ := http.NewRequest("POST", url, nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (Android 12; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0")
req.Header.Set("Cookie", "cookie_key=cookie_value;")
resp, _ := client.Do(req)
// ...
}
// "Cookie": [
// "cookie_key=cookie_value"
// ],
// "User-Agent": [
// "Mozilla/5.0 (Android 12; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0"
// ],
Above, we add a cookie header and override the client's User-Agent to match a real web browser.
Headers play a vital role in the web scraping context. Websites and antibot systems use them to detect automated requests, and hence block them. For further details on HTTP headers, refer to our dedicated guide below:

Request Body
Finally, here's how to pass a payload to an HTTP request in Go:
func main() {
url := "https://httpbin.dev/anything"
payload := "page=1&test=2&foo=bar"
client := &http.Client{}
req, _ := http.NewRequest("POST", url, strings.NewReader(payload)) // Pass the payload
req.Header.Set("Content-Type", "application/x-www-form-urlencoded")
resp, _ := client.Do(req)
defer resp.Body.Close()
body, _ := io.ReadAll(resp.Body)
fmt.Println(string(body))
}
HTML Parsing
HTML parsing is required to extract data points from a retrieved HTML web page. As mentioned earlier, we'll be using two Golang HTML parsers to extract data:
- goquery for evaluating CSS selectors.
- htmlquery for evaluating XPath selectors.
For our example, we'll use a mock target website and extract the product data on web-scraping.dev/products:
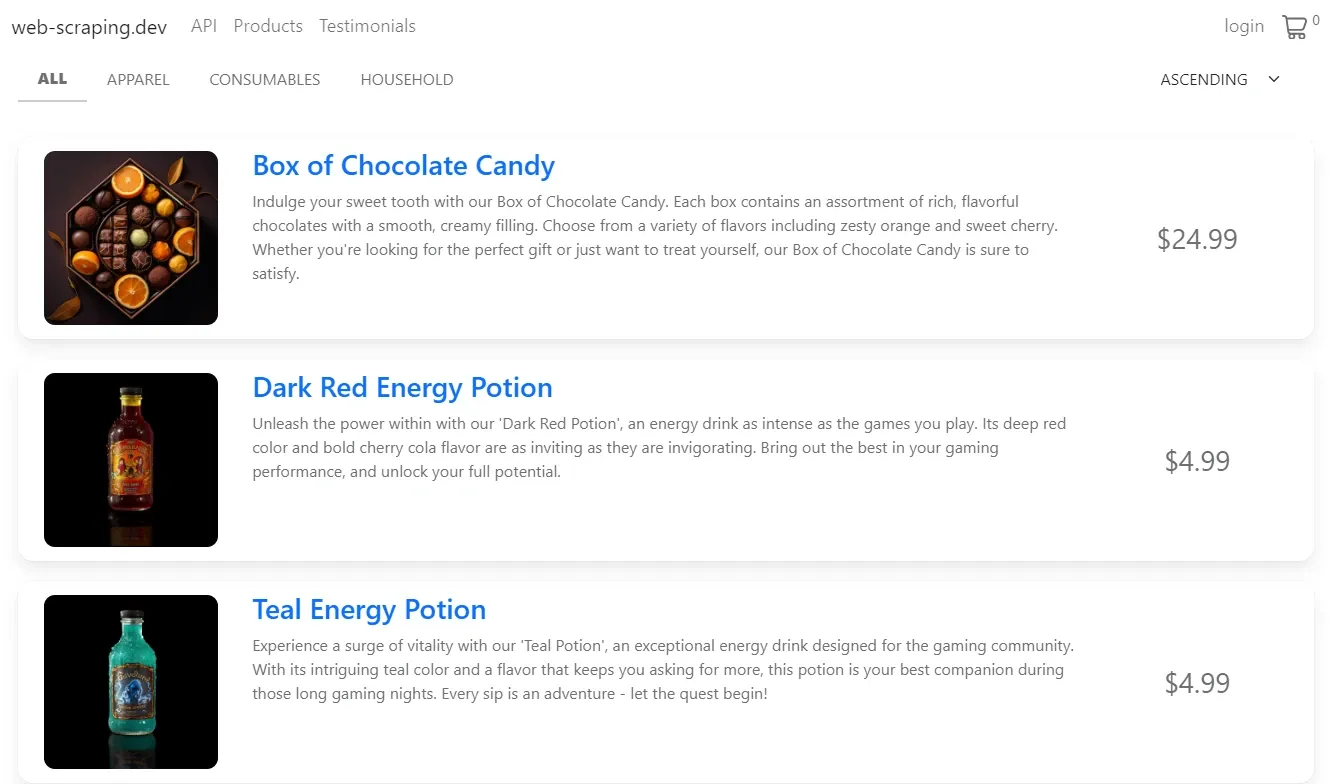
We'll parse the above product data with both CSS and XPath selectors to demonstrate both methods. But before this, let's request our target web page to retrieve the HTML:
func scrapeProducts(url string) *http.Response {
client := &http.Client{}
req, _ := http.NewRequest("GET", url, nil)
resp, _ := client.Do(req)
return resp
}
Above, we define a scrapeProducts() function. It requests the target web page URL and returns its response.
Parsing With CSS Selectors
CSS selectors are by far the most common way to parse HTML documents and they're available in go through the goquery package.
Here's how we can use goquery and css selectors to extrac product data from our example page:
package main
import (
"encoding/json"
"fmt"
"net/http"
"strconv"
"github.com/PuerkitoBio/goquery"
)
// Define a type for the extracted data
type Product struct {
Name string
Price float64
Currency string
Image string
Desciption string
Link string
}
func parseProducts(resp *http.Response) []Product {
// Empty list to save the results
var products []Product
// Load the HTML into a document
doc, _ := goquery.NewDocumentFromReader(resp.Body)
// Find the element containing the product list
selector := doc.Find("div.products > div")
// Iterate over the product list
for i := range selector.Nodes {
sel := selector.Eq(i) // Define a selector for each product element
priceStr := sel.Find("div.price").Text()
price, _ := strconv.ParseFloat(priceStr, 64) // Change the price data type
// Create a new Product and append the results
product := Product{
Name: sel.Find("a").Text(),
Price: price,
Currency: "$",
Image: sel.Find("img").AttrOr("src", ""),
Desciption: sel.Find(".short-description").Text(),
Link: sel.Find("a").AttrOr("href", ""),
}
products = append(products, product)
}
return products
}
func scrapeProducts(url string) *http.Response {
// Previous function definition
}
func main() {
resp := scrapeProducts("https://web-scraping.dev/products")
products := parseProducts(resp)
jsonData, _ := json.MarshalIndent(products, "", " ") // Convert to JSON string
fmt.Println(string(jsonData))
}
Let's break down the execution of the above Golang web scraping logic:
- A request is sent to the target web page URL to retrieve its HTML.
- A
goquerydocument object is created using the response body. - The goquery
Find()method is used to select the HTML element containing the product list. Then, it's iterated over to retrieve the individual product details and define each into aProductobject. - The final
productsresult list is logged as JSON.
The above Go scraping script results are saved to the products object. It can be saved to JSON or a CSV file. Here's what it should look like:
Example output
[
{
"Name": "Box of Chocolate Candy",
"Price": 24.99,
"Currency": "$",
"Image": "https://web-scraping.dev/assets/products/orange-chocolate-box-medium-1.webp",
"Desciption": "Indulge your sweet tooth with our Box of Chocolate Candy. Each box contains an assortment of rich, flavorful chocolates with a smooth, creamy filling. Choose from a variety of flavors including zesty orange and sweet cherry. Whether you're looking for the perfect gift or just want to treat yourself, our Box of Chocolate Candy is sure to satisfy.",
"Link": "https://web-scraping.dev/product/1"
},
....
]
For further details on parsing with CSS selectors, refer to our dedicated guide.

Parsing With XPath Selector
XPath provides a friendly syntax for selecting HTML elements through virtual attributes and matches while also being much more powerful than CSS selectors. This makes Xpath a great replacement for cases where goquery and CSS selectors aren't enough.
Here's how to use XPath selectors with htmlquery using our product example again:
import (
// ....
"github.com/antchfx/htmlquery"
)
// ....
func parseProducts(resp *http.Response) []Product {
var products []Product
doc, _ := htmlquery.Parse(resp.Body)
selector := htmlquery.Find(doc, "//div[@class='products']/div")
for _, sel := range selector {
price, _ := strconv.ParseFloat(htmlquery.InnerText(htmlquery.FindOne(sel, ".//div[@class='price']")), 64)
product := Product{
Name: htmlquery.InnerText(htmlquery.FindOne(sel, ".//a")),
Price: price,
Currency: "$",
Image: htmlquery.SelectAttr(htmlquery.FindOne(sel, ".//img"), "src"),
Desciption: htmlquery.InnerText(htmlquery.FindOne(sel, ".//div[@class='short-description']")),
Link: htmlquery.SelectAttr(htmlquery.FindOne(sel, ".//a"), "href"),
}
products = append(products, product)
}
return products
}
Since the code for requesting the target web page remains the same, we only update the parseProducts function to change our parsing from CSS selectors to XPath.
Similar to goquery, we use the Find() and FindOne() methods to select the desired elements. Then, InnerText() is used to select the element's text value and SelectAttr() is used to select attributes.
For further details on parsing with XPath selectors, including advanced navigation techniques, refer to our dedicated guide:

Crawling
Crawling is an extremely useful technique in the data scraping context. It provides the web data scraper with navigation capabilities by requesting specific href tag links inside the HTML page.
Let's create a Golang web crawler based on the previous code snippet. We'll crawl over the product links and extract all variant links on each product document:
import (
"fmt"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
var productLinks []string
var variantLinks []string
// First, request the main products page
req, _ := http.NewRequest("GET", "https://web-scraping.dev/products", nil)
resp, _ := http.DefaultClient.Do(req)
doc, _ := goquery.NewDocumentFromReader(resp.Body)
// Get each main product link
doc.Find("h3 a").Each(func(i int, s *goquery.Selection) {
link := s.AttrOr("href", "")
productLinks = append(productLinks, link)
})
// Next, request each product link
for _, value := range productLinks {
req, _ := http.NewRequest("GET", value, nil)
resp, _ := http.DefaultClient.Do(req)
doc, _ := goquery.NewDocumentFromReader(resp.Body)
doc.Find("a[href*='variant']").Each(func(i int, s *goquery.Selection) {
link := s.AttrOr("href", "")
variantLinks = append(variantLinks, link)
})
}
fmt.Println(variantLinks)
}
The above code successfully scraped all the product variant links:
Example output
[
"https://web-scraping.dev/product/1?variant=orange-small",
"https://web-scraping.dev/product/1?variant=orange-medium",
"https://web-scraping.dev/product/1?variant=orange-large",
"https://web-scraping.dev/product/1?variant=cherry-small",
"https://web-scraping.dev/product/1?variant=cherry-medium",
"https://web-scraping.dev/product/1?variant=cherry-large",
....
]
The previous Golang webscraper example is minimal, representing the core crawling logic. For further web crawling details, refer to our dedicated guide. The concepts mentioned can be applied to this tutorial.

Example Go Scraper
Let's create a Go crawler based on the previous code snippet. It will crawl over web-scraping.dev/products pages to scrape every product detail:
package main
import (
"encoding/json"
"fmt"
"log"
"net/http"
"os"
"regexp"
"strconv"
"github.com/PuerkitoBio/goquery"
)
type Review struct {
Date string
Rating int
Text string
}
type Product struct {
Name string
Price float64
Currency string
Image string
Desciption string
Link string
Reviews []Review
}
// Crawl the product reviews
func crawlReviews(url string) []Review {
resp := requestPage(url)
doc, _ := goquery.NewDocumentFromReader(resp.Body)
// Find the product reviews in hidden script tag
reviewsScript := doc.Find("script#reviews-data").Text()
var reviews []Review
json.Unmarshal([]byte(reviewsScript), &reviews)
return reviews
}
// Parse the product details
func parseProducts(resp *http.Response) []Product {
var products []Product
doc, _ := goquery.NewDocumentFromReader(resp.Body)
selector := doc.Find("div.products > div")
for i := range selector.Nodes {
sel := selector.Eq(i)
price, _ := strconv.ParseFloat(sel.Find("div.price").Text(), 64)
sel.Find("a").AttrOr("href", "")
link := sel.Find("a").AttrOr("href", "")
// crawl the product reviews from its product page
reviews := crawlReviews(link)
product := Product{
Name: sel.Find("a").Text(),
Price: price,
Currency: "$",
Image: sel.Find("img").AttrOr("src", ""),
Desciption: sel.Find(".short-description").Text(),
Link: link,
Reviews: reviews,
}
products = append(products, product)
}
return products
}
// Get the max pages available for pagination
func getMaxPages(resp *http.Response) int {
doc, _ := goquery.NewDocumentFromReader(resp.Body)
pagingStr := doc.Find(".paging-meta").Text()
// Find the max pages number using regex
re := regexp.MustCompile(`(\d+) pages`)
match := re.FindStringSubmatch(pagingStr)[1]
maxPages, _ := strconv.Atoi(match)
return maxPages
}
// Request a target URL with basic browser headers
func requestPage(url string) *http.Response {
client := &http.Client{}
req, _ := http.NewRequest("GET", url, nil)
// Set browser-like headers
req.Header.Set("Accept", "text/html")
req.Header.Set("Accept-Encoding", "gzip, deflate, br")
req.Header.Set("Accept-Language", "en-US,en;q=0.9")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0")
resp, _ := client.Do(req)
return resp
}
// Main scrape logic
func scrapeProducts(url string) []Product {
var data []Product
resp := requestPage(url)
maxPages := getMaxPages(resp)
for pageNumber := 1; pageNumber <= maxPages; pageNumber++ {
resp := requestPage(fmt.Sprintf("%s?page=%d", url, pageNumber))
log.Printf("Scraping page: %s", resp.Request.URL)
products := parseProducts(resp)
data = append(data, products...)
}
return data
}
// Save the scraped data to a JSON file
func saveToJson(products []Product, fileName string) {
file, _ := os.Create(fileName + ".json")
defer file.Close()
jsonData, _ := json.MarshalIndent(products, "", " ")
file.Write(jsonData)
fmt.Printf("Saved %d products to %s\n", len(products), fileName)
}
func main() {
products := scrapeProducts("https://web-scraping.dev/products")
saveToJson(products, "product_data")
}
The above Go web scraping logic seems quite complex. Let's break down its core functions:
requestPage: Requests a specific target web page URL with basic browser-like headers.getMaxPages: Retrieves the total number of pages available for pagination.parseProducts: Iterates over the product list and parses the data for each product.crawlReviews: Crawls the review data by requesting the dedicated product URL.
This Go scraper starts by retrieving the total number of pages and then iterates over them while extracting each page's data. Finally, the results to a JSON file.
So far, we have explored creating a web scraper with Golang using only packages for sending HTTP requests and HTML parsing. Next, let's explore a dedicated scraping framework: Go Colly.
Web Scraping With Colly
Colly is one of the popular Golang web scraping libraries for building web scrapers and crawlers.It supports various features to facilitate the web scraping tasks:
- Built-in caching middleware.
- Fast execution at 1k requests/sec on a single core.
- Asynchronous, synchronous, and parallel execution.
- Distributed scraping, request delays, and maximum concurrency.
- Automatic cookie and session handling.
How Colly Works?
Before getting started with building web scrapers with Colly, let's review its core technical concepts.
Collectors
A Golang colly scraper requires at least one collector. A collector is the core component responsible for managing the entire scraping process. For example, below is a very minimal Colly collector:
func main() {
c := colly.NewCollector()
// Start scraping
c.Visit("https://httpbin.dev")
}
Here, we use the NewCollector method to create a new collector with the default configuration. Then, we use the Visit to request the target web page and wait for the collector to finish using the Wait method.
A collector can be configured using an options object. Below are some of its common parameters:
| Option | Description |
|---|---|
UserAgent |
Modifies the used User-Agent HTTP header. |
MaxDepth |
Limits the recursion depth of visited URLs when crawling. Set to 0 for infinite recursion. |
AllowedDomains |
List of allowed domains to visit. Set to blank to allow any domain. |
DisallowedDomains |
List of domains to blacklist. |
AllowURLRevisit |
Whether to allow multiple requests of the same URL. |
MaxBodySize |
Limit the retrieved response body in bytes, leave it to 0 for unlimited bandwidth. |
CacheDir |
A location to save cached files of sent GET requests for future use. If not specified, cache is disabled. |
IgnoreRobotsTxt |
Whether to ignore restrictions defined by the host robots.txt file. |
Async |
Whether to enable asynchronous network communication. |
Here's an example of configuring a Colly collector. We can refer to a path environment variable or directly pass the options object values:
func main() {
c := colly.NewCollector(
colly.UserAgent("Mozilla/5.0 (Windows NT 6.1; rv:109.0) Gecko/20100101 Firefox/113.0"),
colly.Async(true),
// Futher options
)
}
For the full available options, refer to the official API specifications.
Callbacks
The next essential component of Golang Colly is callbacks. These are manually defined functions to handle specific events happening during the HTTP lifecycle.
Callbacks are triggered based on specific scraper events in a specified collector. Let's briefly mention them.
OnRequest
The OnRequest callback event is triggered just before an HTTP request is sent from a collector. It's useful for modifying the request configuration before it's sent or for taking other custom actions, such as logging.
collector.OnRequest(func(r *colly.Request) {
log.Println("Scraping", r.URL)
r.Headers.Set("key", "value")
})
OnResponse
The OnResponse callback event is the opposite of OnRequest. It's triggered once an HTTP response is received. It's useful for processing the response before being passed to other scraper components:
collector.OnResponse(func(r *colly.Response) {
log.Println("Request was executed with status code :", r.StatusCode)
// Decompress the response body for example
if r.Headers.Get("Content-Encoding") == "gzip" {
reader, _ := gzip.NewReader(bytes.NewReader(r.Body))
decompressedBody, _ := io.ReadAll(reader)
// ....
}
})
OnHTML
The OnHTML callback is triggered once a specified CSS selector is found in the HTML. It's mainly used for HTML parsing or crawling by requesting specific HTML elements.
collector.OnHTML("div.main", func(e *colly.HTMLElement) {
// Crawl to other links
productLink := e.Attr("href")
collector.Visit(productLink)
// Parse the HTML
price := e.Attr("div.price")
})
OnXML
The OnXML callback is the same as OnHTML, but it's triggered by receiving XML responses.
collector.OnXML("sitemap", func(e *colly.XMLElement) {
log.Println(e.Attr("loc"))
})
OnError
The OnError callback is triggered when an error occurs while making HTTP requests.
collector.OnError(func(r *colly.Response, err error) {
log.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
OnScraped
The OnScraped callback is triggered once the response is processed by other callbacks: OnHTML and OnXML.
collectorc.OnScraped(func(r *colly.Response) {
log.Println("Finished scraping", r.Request.URL)
})
Example Go Colly Scraper
In this section, we'll create a Colly web crawler to extract product data on web-scraping.dev/products.
First, let's start by creating a new collector to crawl product pages:
package main
import (
"fmt"
"log"
"strings"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector(
colly.CacheDir("./web-scraping.dev_cache"), // Cache responses to prevent multiple downloads
colly.Async(true), // Enable asynchronous execution
)
// Clone the cerated collector
searchCollector := c.Clone()
// Paginate search pages
searchCollector.OnHTML("div.paging", func(e *colly.HTMLElement) {
links := e.ChildAttrs("a", "href")
nextPage := links[len(links)-1]
if strings.Contains(nextPage, "https://web-scraping.dev") {
e.Request.Visit(nextPage)
}
})
// Log before visiting each search page
searchCollector.OnRequest(func(r *colly.Request) {
log.Println("Visiting search page", r.URL.String())
})
// On every product link, visit the product details page
searchCollector.OnHTML("div.row.product div h3 a", func(e *colly.HTMLElement) {
productLink := e.Attr("href")
fmt.Println(productLink)
})
// Start scraping from the main products page
searchCollector.Visit("https://web-scraping.dev/products")
// Wait for the asynchronous searchCollector to
searchCollector.Wait()
}
Let's break down the above Colly scraping code. We start by defining a new collector c with asynchronous execution and cache enabled. Then, we clone the defined c collector into a new searchCollector, which will be responsible for pagination requests.
Then, we utilize two callbacks:
OnHTML: To paginate the product listing pages, 5 in total.OnRequest: To log the requested page URLs.
The above crawler output looks like the following:
2024/07/19 08:11:37 Visiting search page https://web-scraping.dev/products
https://web-scraping.dev/product/1
....
Now that we can retrieve all product page URLs let's request them and parse their data:
func main() {
// ....
// Log before visiting each search page
searchCollector.OnRequest(func(r *colly.Request) {
log.Println("Visiting search page", r.URL.String())
})
type Review struct {
Date string
Rating int
Text string
}
type Product struct {
Name string
Price float64
Currency string
Image string
Description string
Link string
Reviews []Review
}
var products []Product
// Create a new collector
productCollector := c.Clone()
// On every product link, visit the product details page
searchCollector.OnHTML("div.row.product div h3 a", func(e *colly.HTMLElement) {
productLink := e.Attr("href")
productCollector.Visit(productLink) // Request all the product pages using the productCollector
})
// Log before visiting each product page
productCollector.OnRequest(func(r *colly.Request) {
log.Println("Visiting product page", r.URL.String())
})
// Parse the productCollector responses by ierating over each product HTML element
productCollector.OnHTML("body", func(e *colly.HTMLElement) {
var reviews []Review
reviewsScript := e.ChildText("script#reviews-data")
json.Unmarshal([]byte(reviewsScript), &reviews)
priceStr := strings.Split(e.ChildText("span.product-price"), "$")[1]
price, _ := strconv.ParseFloat(priceStr, 64)
product := Product{
Name: e.ChildText("h3.card-title"),
Price: price,
Currency: "$", // Example currency, replace with actual scraping logic
Image: e.ChildAttr("img", "src"),
Description: e.ChildText(".description"),
Link: e.Request.URL.String(),
Reviews: reviews,
}
products = append(products, product)
})
// Start scraping from the main products page
searchCollector.Visit("https://web-scraping.dev/products")
// Wait for the collectors to finish
searchCollector.Wait()
productCollector.Wait()
fmt.Println(products)
}
Above, we create a new collector productCollector to request product pages. Similar to the previous collector, we use OnRequest and OnHTML callbacks to log the requested log URLs and parse the retrieved HTML document. Finally, the script waits for both collectors to finish using colly's Wait() method.
Proxies
Websites and anti-bots define rate-limit rules to detect and block IP addresses exceeding their limits. Hence, rotating proxies to split the traffic across multiple IP addresses is essential to scrape at scale.
Colly provides a built-in proxy switcher to randomly change the IP address:
func main() {
c := colly.NewCollector()
p, _ := proxy.RoundRobinProxySwitcher(
"socks5://some_proxy_domain:1234",
"http://some_proxy_domain:1234",
)
c.SetProxyFunc(p)
// ....
}
The above Colly data scraper uses the popular round-robin proxy rotation algorithm to switch IP addresses. However, a custom implementation can be passed:
var proxies []*url.URL = []*url.URL{
&url.URL{Host: "socks5://some_proxy_domain:1234"},
&url.URL{Host: "http://some_proxy_domain:1234"},
}
func randomProxySwitcher(_ *http.Request) (*url.URL, error) {
return proxies[random.Intn(len(proxies))], nil
}
func main() {
c := colly.NewCollector()
c.SetProxyFunc(randomProxySwitcher)
// ....
}
For further details on using proxies for web scraping, refer to our dedicated guide.

Parallel Scraping
The Go runtime is managed using lightweight threads called __Goroutines_-, which allows for efficient parallel execution.
Colly leverages Go's goroutines to request pages in parallel, allowing for a decreased execution time while web scraping at scale. For example, let's crawl a website with and without using parallel execution and calculate the execution time:
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
start := time.Now()
c := colly.NewCollector(
colly.MaxDepth(3), // Recursion depth of visited URLs.
colly.Async(true), // Enable asynchronous communication
)
// Parallelism can be controlled also by spawning fixed number of go routines
c.Limit(&colly.LimitRule{DomainGlob: "*", Parallelism: 20})
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
e.Request.Visit(link)
})
c.Visit("https://web-scraping.dev/")
c.Wait()
end := time.Now()
duration := end.Sub(start)
fmt.Printf("Script finished in %v\n", duration)
// Script finished in 7.1324493s
}
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
start := time.Now()
c := colly.NewCollector(
colly.MaxDepth(3),
)
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
e.Request.Visit(link)
})
c.Visit("https://web-scraping.dev/")
end := time.Now()
duration := end.Sub(start)
fmt.Printf("Script finished in %v\n", duration)
// Script finished in 52.3559989s
}
Compared to 52 seconds for the synchronous execution, it only took 7 seconds when using parallel request execution. That's a huge performance boost!
Other Golang Web Scraping Libraries
We have explored web scraping with Go using goquery and htmlquery as parsing packages, and Colly as a crawling framework. Other useful Go packages for web scraping are:
- webloop - A Golang headless browser with the WebKit engine, similar to PhantomJS.
- golang-selenium - A Selenium Webdriver client for Go.
- geziyor - A web scraping and crawling framework similar to Colly with additional JavaScript rendering capabilities.
Powering Up with Scrapfly
While Go is a great language for web scraping it can be challenging to scale and manage scrapers and anti-bot bypass and this is Scrapfly can provide some assistance.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - extract web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- LLM prompts - extract data or ask questions using LLMs
- Extraction models - automatically find objects like products, articles, jobs, and more.
- Extraction templates - extract data using your own specification.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
Here's how to web scrape with Go using Scrapfly. It's as simple as sending an HTTP request:
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"net/url"
"strconv"
)
func main() {
baseURL := "https://api.scrapfly.io/scrape"
params := url.Values{}
params.Add("key", "Your Scrapfly API key")
params.Add("url", "https://web-scraping.dev/products") // Target web page URL
params.Add("asp", strconv.FormatBool(true)) // Enable anti-scraping protection to bypass blocking
params.Add("render_js", strconv.FormatBool(true)) // Enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
params.Add("country", "us") // Set the proxy location to a specfic country
params.Add("proxy_pool", "public_residential_pool") // Select the proxy pool
URL := fmt.Sprintf("%s?%s", baseURL, params.Encode())
client := &http.Client{}
req, err := http.NewRequest("GET", URL, nil)
if err != nil {
log.Fatal(err)
}
res, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
body, err := io.ReadAll(res.Body)
if err != nil {
log.Fatal(err)
}
// Parse the JSON response
var result struct {
Result struct {
Content string `json:"content"`
} `json:"result"`
}
err = json.Unmarshal(body, &result)
if err != nil {
log.Fatal(err)
}
// log the page HTML
fmt.Println(result.Result.Content)
}
FAQ
To wrap up this guide, let's have a look at some frequently asked questions about web scraping with Go.
What is gocolly?
Colly is a web scraping framework for building scrapers and crawlers in Go using collectors and callbacks. It enables data extraction at scale throug a number of features including caching supprot, parallel execution, and automatic cookie and session handling.
What are the pros and cons of using Go for web scraping?
In terms of pros, Golang is known for its high performance and automatic garbage collection for effective memory management. This makes Go suitable for building and managing web scrapers at scale.
As for cons, data parsing and processing with Go can require a steep learning curve for its low-level data structure operations. Moreover, it lacks support for headless browser libraries found in other languages, such as Selenium, Playwright, and Puppeteer.
Go Scraping Summary
In this guide, we introduced using Go for web scraping. We started by going through the steps required to install and set up the Go environment. Then, we detailed the core concepts required to create Golang scrapers: sending HTTP requests, HTML parsing, and crawling.
Lastly, we wrapped up the guide by exploring Colly, the popular Go web crawling framework. We explored its components and how to use it for a real-life web scraping Golang example.




