

SEO keywords are an essential part of Search Engine Optimization for ranking higher on search results. However, identifying the right SEO keywords can be quite challenging, involving lots of research and analysis. All of which can be made easier by applying web scraping for SEO.
In this article, we'll take a look at SEO web scraping - what it is and how to use it for better SEO keyword optimization. We'll also create an SEO keyword scraper that scrapes Google search rankings and suggested keywords. Let's dive in!
Key Takeaways
Master Google SEO keyword scraping with advanced Python techniques, search ranking analysis, and keyword research automation for comprehensive SEO optimization.
- Implement Google search scraping with Python for keyword research and ranking analysis
- Configure SEO keyword extraction including short-tail, long-tail, and LSI keywords
- Implement search ranking monitoring and competitor analysis for SEO optimization
- Configure proxy rotation and fingerprint management to avoid detection and rate limiting
- Use specialized tools like ScrapFly for automated Google SEO scraping with anti-blocking features
- Implement data analysis and visualization for comprehensive SEO keyword research workflows
Latest Google SEO Scraper Code
What are SEO keywords?
Search engine optimization (SEO) keywords are words or phrases that users type into search engines to get results. These keywords are generally categorized into three types:
- Short-tail keywords are broad, generic popular terms that have high search volume.
- Long-tail keywords are more specific, less popular terms that have low search volume.
- Latent Semantic Indexing (LSI) keywords are semantically related to the main keyword. For example, "web scraping" and "web scraper" are LSI keywords that are related to the main "web scraping google" short-tail keyword.
Each keyword can be a single word, a multi-word or even a long phrase. However, all keywords are processed for stopwords and punctuation. For example, the keyword "web scraping using typescript" will be processed as "web scraping typescript" as the word "using" is a low-value word known as a stopword.
Search engines use SEO keywords to rank results on the search engine results pages (SERPs). Thus, SEO keyword-optimized websites get more traffic and revenue than other websites as they rank higher in the search results.
So, how exactly do search engines use SEO to rank search engine results?
How SEO Affects Search Results?
Search engine result pages (SERPs) are what users see when they search for keywords using search engines. These search results are ranked by the search engine based on several factors, including:
- Relevance of the search keyword to the topic.
- Content quality on the web page, including readability and information accuracy.
- Geographic distance between users and local business locations.
- Compatibility and responsive design.
- Domain authorization of the website, including the number of quality backlinks, domain age and overall reputation of the website.
- Updated content as search engines may set higher ranks for newly updated content for certain topics like news or trends.
Search engine results are also personalized based on the browser's history and location expressed through HTTP cookies and the client's IP address.
Meaning, that by scraping SEO keyword rankings we can better understand how search engines rank results and boost our own rankings.
In the following sections, we'll scrape Google search results for keyword rankings along with SEO metadata. But before that, let's take a look at the tools we'll use.
Setup
In this SEO web scraping guide, we'll scrape SEO keywords related to the Typescript web scraping topic. We'll also scrape SEO metadata, such as suggestions and related questions.
To do that, we'll use httpx for sending HTTP requests and parsel for parsing HTML using XPath. These Python packages can be installed using the pip terminal command:
pip install httpx parsel
Scrape SEO Keyword Rankings
To scrape SEO keyword rankings, we'll search for SEO keywords to get the search results for each keyword. Then, we'll scrape Google search page to get the rank of each result box. With this scraping tool, we'll be able to monitor competitors and gain insights to select SEO keywords effectively.
For comprehensive competitor analysis beyond keyword rankings, tools like SimilarWeb scraping provide website traffic analytics, audience insights, and market intelligence to complement your SEO strategy.
Let's start by creating an httpx client and a CSV file for storing the scraping results:
import httpx
import csv
client = httpx.Client(
headers={
"Accept": "*/*",
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"
},
)
filecsv = open("seo_ranks.csv", "w", encoding="utf8")
csv_columns = ["keyword", "title", "text", "date", "domain", "url", "position"]
writer = csv.DictWriter(filecsv, fieldnames=csv_columns)
writer.writeheader()
Above, we create a CSV file named seo_ranks.csv and add the fields we'll scrape as column names. For our httpx.Client we use basic headers like Accept and User-Agent string to avoid being instantly blocked.
Next, we'll iterate over SEO keywords and scrape ranking results for each keyword:
from parsel import Selector
from urllib.parse import quote
from typing import List
def scrape_seo_ranks(keywords: List, max_pages: int):
for keyword in keywords:
position = 0
# Iterate over Google search pages
for page in range(1, max_pages + 1):
print(f"scraping keyword {keyword} at page number {page}")
url = f"https://www.google.com/search?hl=en&q={quote(keyword)}" + (
f"&start={10*(page-1)}" if page > 1 else ""
)
request = client.get(url=url)
selector = Selector(text=request.text)
for result_box in selector.xpath(
"//h1[contains(text(),'Search Results')]/following-sibling::div[1]/div"
):
# Scrape search result boxes only
try:
title = result_box.xpath(".//h3/text()").get()
text = "".join(
result_box.xpath(".//div[@data-sncf]//text()").getall()
)
date = text.split("—")[0] if len(text.split("—")) > 1 else "None"
url = result_box.xpath(".//h3/../@href").get()
domain = url.split("/")[2].replace("www.", "")
position += 1
writer.writerow(
{
"keyword": keyword,
"title": title,
"text": text,
"date": date,
"domain": domain,
"url": url,
"position": position,
}
)
except:
pass
# Example use:
scrape_seo_ranks(["Web Scraping using Typescript", "Typescript web scraper"], 1)
Here, we use httpx to send a request to the first Google search page of each SEO keyword. Then, since Google's HTML structure is complex and unstable, we use text-based XPath parsing using parsel. Finally, we save the data we got into the CSV file we created earlier:
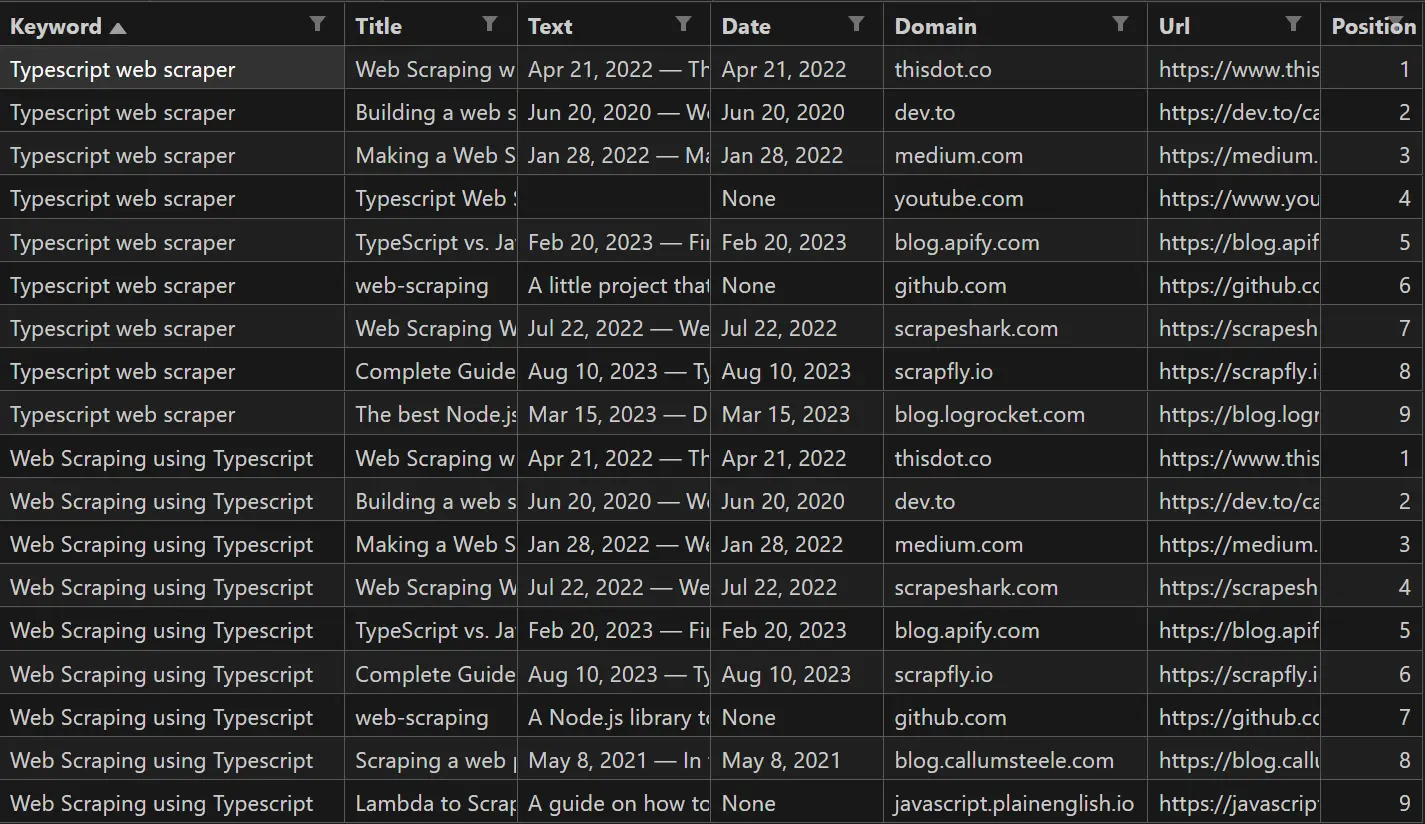
Cool! We got the search result rankings for each SEO keyword along with the title, text, date, domain and URL.
Now that our SEO keyword scraper can scrape search result ranks, let's extend it to scrape SEO keyword suggestions as well.
Scrape SEO Keyword Suggestions
Google search suggestions include related topics to the search keyword. It includes sections like "People also ask" and "Related searches" - which provide keywords related to the main search keyword:
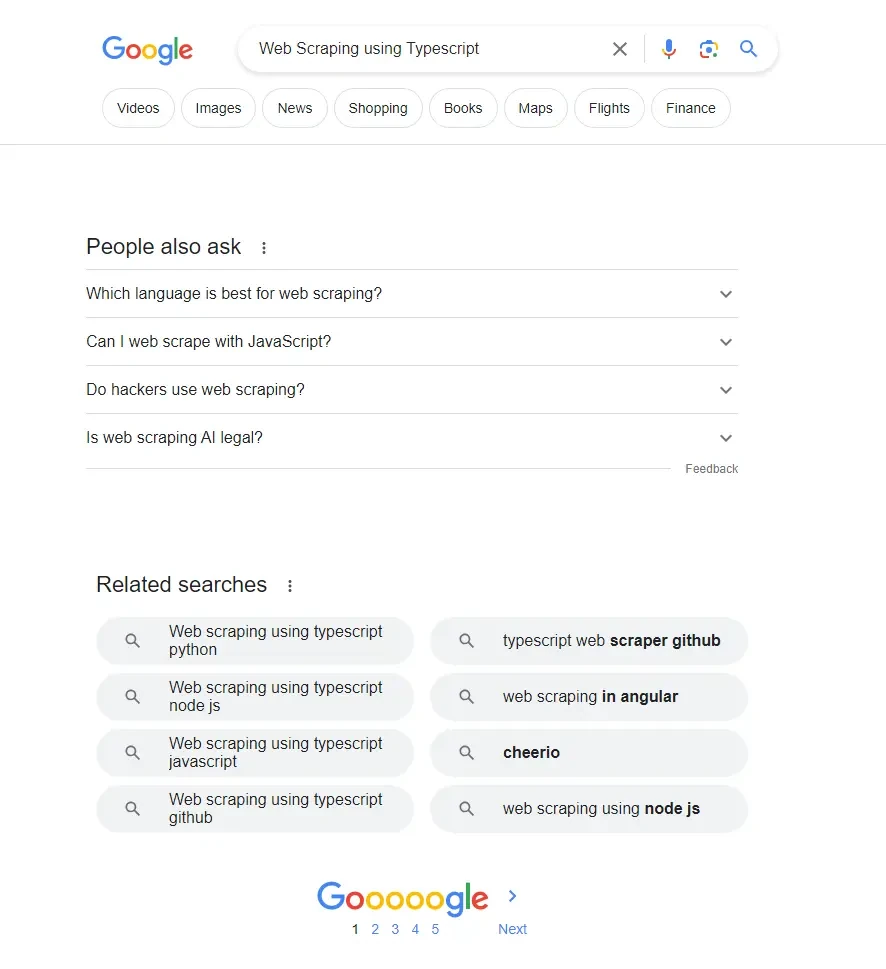
Above, we can see that Google suggests additional keywords and related questions. We can use this data to extend our own keyword pool and include related questions in our content to rank higher in the search results.
Let's extend our SEO keyword scraper to scrape these fields:
import httpx
from parsel import Selector
import json
from urllib.parse import quote
from collections import defaultdict
client = httpx.Client(
headers={
"Accept": "*/*",
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
},
)
def scrape_keyword_metadata(keyword: str, page: int):
related_search = []
# Create a dictionary container for the results
results = defaultdict(list)
url = f"https://www.google.com/search?hl=en&q={quote(keyword)}" + (
f"&start={10*(page-1)}" if page > 1 else ""
)
request = client.get(url=url)
selector = Selector(text=request.text)
# Get all questions in a list
people_ask_for = selector.xpath(
".//div[contains(@class, 'related-question-pair')]//text()"
).getall()
# Iterate over keywords suggestions
for suggestion in selector.xpath(
"//div[div/div/span[contains(text(), 'Related searches')]]/following-sibling::div//a"
):
# Extract all suggestions text and append to the list
related_search.append("".join(suggestion.xpath(".//text()").getall()))
# Add each field result to result dictionary
results["people_ask_for"].extend(people_ask_for)
results["related_search"].extend(related_search)
# Print the result in a JSON format
print(json.dumps(dict(results), indent=2))
scrape_keyword_metadata("Web Scraping using Typescript", 1)
Above, we use XPath selectors to extract text in the "people ask for" and "related search" sections. Then, we append the text we got to the results dictionary and print it in JSON format. Here is the result we got:
{
"people_ask_for": [
"Which language is best for web scraping?",
"Can I web scrape with JavaScript?",
"Do hackers use web scraping?",
"Is web scraping AI legal?"
],
"related_search": [
"Web scraping using typescript python",
"Web scraping using typescript node js",
"Web scraping using typescript javascript",
"Web scraping using typescript github",
"typescript web scraper github",
"web scraping in angular",
"cheerio",
"web scraping using node js"
]
}
We have seen how to scrape SEO keywords to scrape search ranks and optimize SEO. However, our SEO web scraping code isn't very scalable. And since Google is notorious for web scraping blocking, let's see how to scrape SEO keywords at scale next!
Powering Up with ScrapFly
Web scraping Google isn't particularly difficult but to scale up such scrapers can be a challenge and this is where Scrapfly can lend a hand!

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
For example, to use our SEO web scraping code with ScrapFly SDK, we can easily scrape SEO keywords in a specific location without the risk of getting blocked:
from scrapfly import ScrapeConfig, ScrapflyClient
from urllib.parse import quote
from collections import defaultdict
import json
scrapfly = ScrapflyClient(key="Your API key")
keyword = "Web Scraping using Typescript"
page = 1
related_search = []
results = defaultdict(list)
url = f"https://www.google.com/search?hl=en&q={quote(keyword)}" + (
f"&start={10*(page-1)}" if page > 1 else ""
)
result = scrapfly.scrape(
scrape_config=ScrapeConfig(
url=url,
headers={
"Accept": "*/*",
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
},
# Enable the anti-scraping protection bypass
asp=True,
# Set proxies to a specfic country
country="US",
)
)
# Parse HTML using the pre-added selector
people_ask_for = result.selector.xpath(
".//div[contains(@class, 'related-question-pair')]//text()"
).getall()
for suggestion in result.selector.xpath(
"//div[div/div/span[contains(text(), 'Related searches')]]/following-sibling::div//a"
):
related_search.append("".join(suggestion.xpath(".//text()").getall()))
results["people_ask_for"].extend(people_ask_for)
results["related_search"].extend(related_search)
print(json.dumps(dict(results), indent=2))
FAQ
To wrap up this web scraping for SEO guide, let's take a look at some frequently asked questions.
What is web scraping for SEO?
SEO web scraping means scraping Google search results, including search ranks and suggested searches and using this data for SEO optimization insights.
How to scrape Google search results?
Google search results can be scraped using XPath and CSS selectors like we did in the SEO rankings scraper. However, Google is known for its complicated HTML structure and blocking scrapers. For that, see our dedicated articles on scraping google search and scraping without getting blocked.
Scraping SEO Keywords - Summary
SEO keywords are search keywords passed by users to get search results. Search engines rank keywords based on several factors:
- Keywords relevancy.
- Content quality.
- Geographic distance.
- Responsive design.
- Domain authorization.
- Updated content.
We've explored how to apply web scraping for SEO use by scraping Google search ranks and suggested searches. For this, we wrote a small SEO scraper using Python, httpx and parsel with XPath.
Web scraping keywords allows for SEO optimization, leading to higher search ranking. That being said, scraping Google can have challenges like complex HTML parsing and scraper blocking.




