

Most of web scraping is requesting web pages and parsing the HTML using web selectors. However, much of modern web is also accessible through hidden APIs!
In this article, we'll explore the use of API clients for web scraping. We'll start by explaining how to locate hidden API requests on websites. Then, we'll explore importing, manipulating, and exporting API connections using Postman to develop efficient API-based web scrapers. Let's dive in!
Key Takeaways
Master API-based web scraping with Postman for discovering hidden APIs, testing endpoints, and building efficient scrapers that bypass HTML parsing challenges.
- Use Postman to discover hidden API endpoints by intercepting browser network requests and analyzing JSON responses
- Configure API testing and debugging with Postman's request/response inspection and authentication handling
- Implement API-based scraping to avoid HTML parsing challenges and improve performance over traditional scraping
- Export Postman collections to Python/JavaScript code for automated API-based scrapers
- Configure proper authentication and headers for API requests to access protected endpoints
- Use specialized tools like ScrapFly for automated API discovery and management with anti-blocking features
What Are Web Scraping APIs?
Web scraping APIs are commonly referred to as hidden APIs. They are called hidden because they are seamlessly triggered while browsing web pages.
To better demonstrate this, let's explore this triggering scenario of how an average product search page works 👇
When a request is sent to the search web page asking for certain dynamic information (i.e. products to search) the website engine sends a background request to the database asking for this information. These background requests happen through a real web API which is usually in JSON. Then, the received data is rendered into the website's visible HTML.
Hence, the website in this scenario acts as a middleware. We can skip it and get to the data directly instead! But what are the advantages and disadvantages of web scraping through APIs?
Why Use APIs For Web Scraping?
Using APIs for web scraping eliminates all the challenges associated with HTML parsing. These challenges include the frequent changes in the HTML layout and the complexity of developing web selectors for complicated documents.
Relying on the APIs for web scraping can increase the performance and execution time. This is due to eliminating the time-consuming front-end tasks, such as rendering HTML, JavaScript or image files.
Moreover, API-based web scrapers often allow retrieving more data points than those found on the HTML. This is because hidden APIs are not filtered and directly fetch data fields from the database.
Setup
In this guide, we'll use Postman as our API client. However, the technical concept is the same and can be applied to any other API client, such as Insomnia or httpie.
Postman is available for all platforms (Windows, Mac, and Linux). To install it, follow the official installation page.
Optional
Postman also provides a Chrome extension: Postman Interceptor. It automatically captures background API requests on websites and replicates them into the Postman client.
API Clients For Web Scraping
We will divide our guide on web scraping through APIs into three main parts:
- Using the browser to find and locate hidden APIs on web pages.
- Importing and manipulating the APIs we found on the browser to Postman.
- Exporting the requests on Postman to different programming languages to automate the API requests for web scraping.
This guide will focus on utilizing Postman to replicate hidden APIs for web scraping. For more details on the actual hidden API scraping details, refer to our previous guide:

Find Hidden APIs
In this guide, we'll use hidden APIs to scrape review data on How to Scrape Trustpilot.com Reviews and Company Data. However, the technical concept described is the same and can also be applied to other web pages as well.
Let's start by exploring our target web page. Go to any reviews page on Trustpilot and you will get a page similar to this:
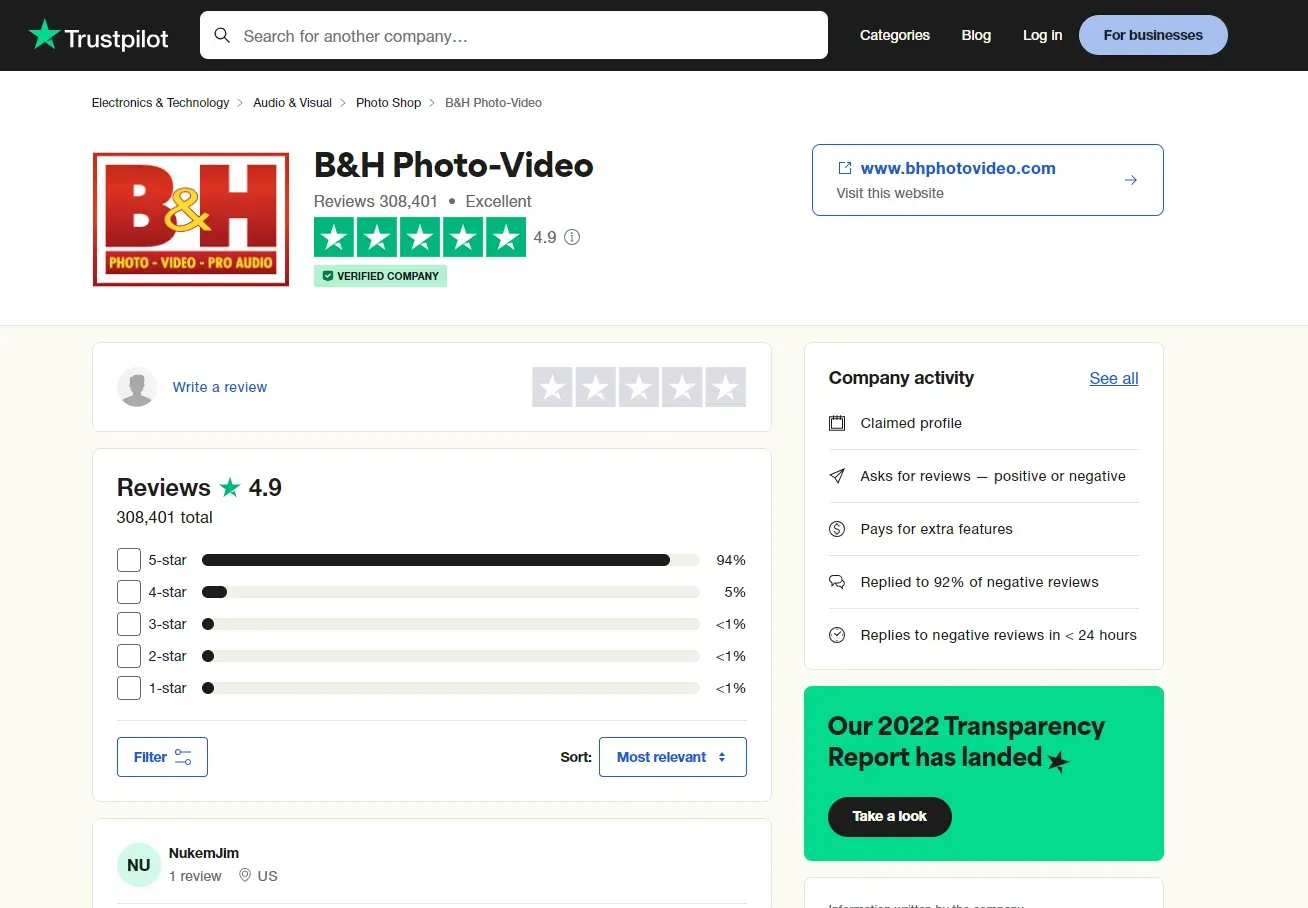
First, open the browser developer tools by clicking the F12 key, then click on the Network tab and filter by Fetch/XHR requests to capture the background XHR calls.
Next, we'll have to interact with the web page to trigger the data fetch requests. Depending on the target website, activating the hidden API can be done in several ways like clicking the button to load the next page or applying data filters.
In our case, we'll activate the reviews API by loading the next review page. By doing that, we'll capture the API request responsible for loading the next review page on the browser developer tools:
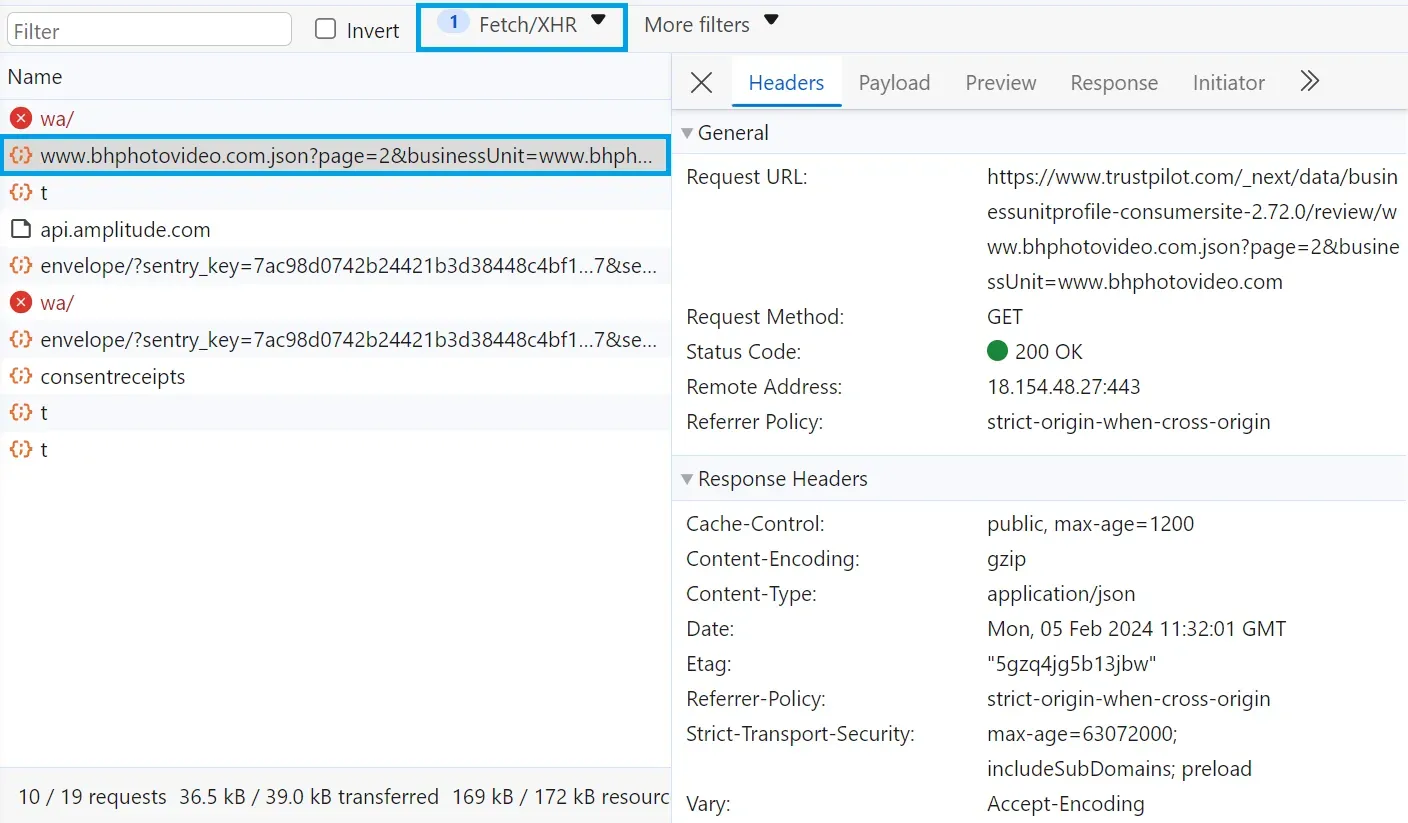
Above, we have successfully captured the API request responsible for fetching the review data. To verify it, we can click on the response tab to ensure it returns the desired data:
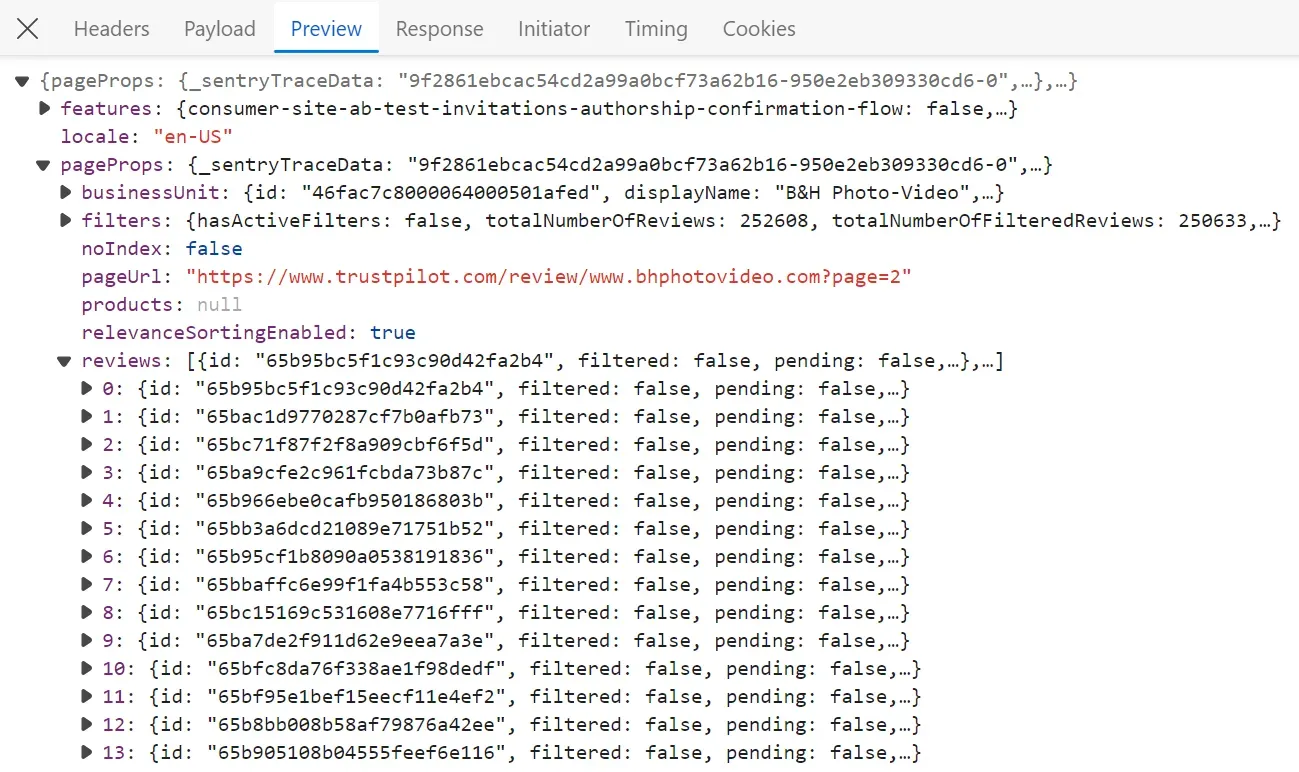
Now that we have successfully identified the API request using the developer tools. Let's import it into Postman in the next section.
Note that the request we are working with is REST. GraphQL requests use a slightly different configuration. For more details, refer to our previous guide on web scraping GraphQL.

Import Hidden API Requests Into Postman
To import the reviews API request we captured into Postman, we have to copy it as cURL. To do that, rich-click on the request, click copy and then copy as cURL:
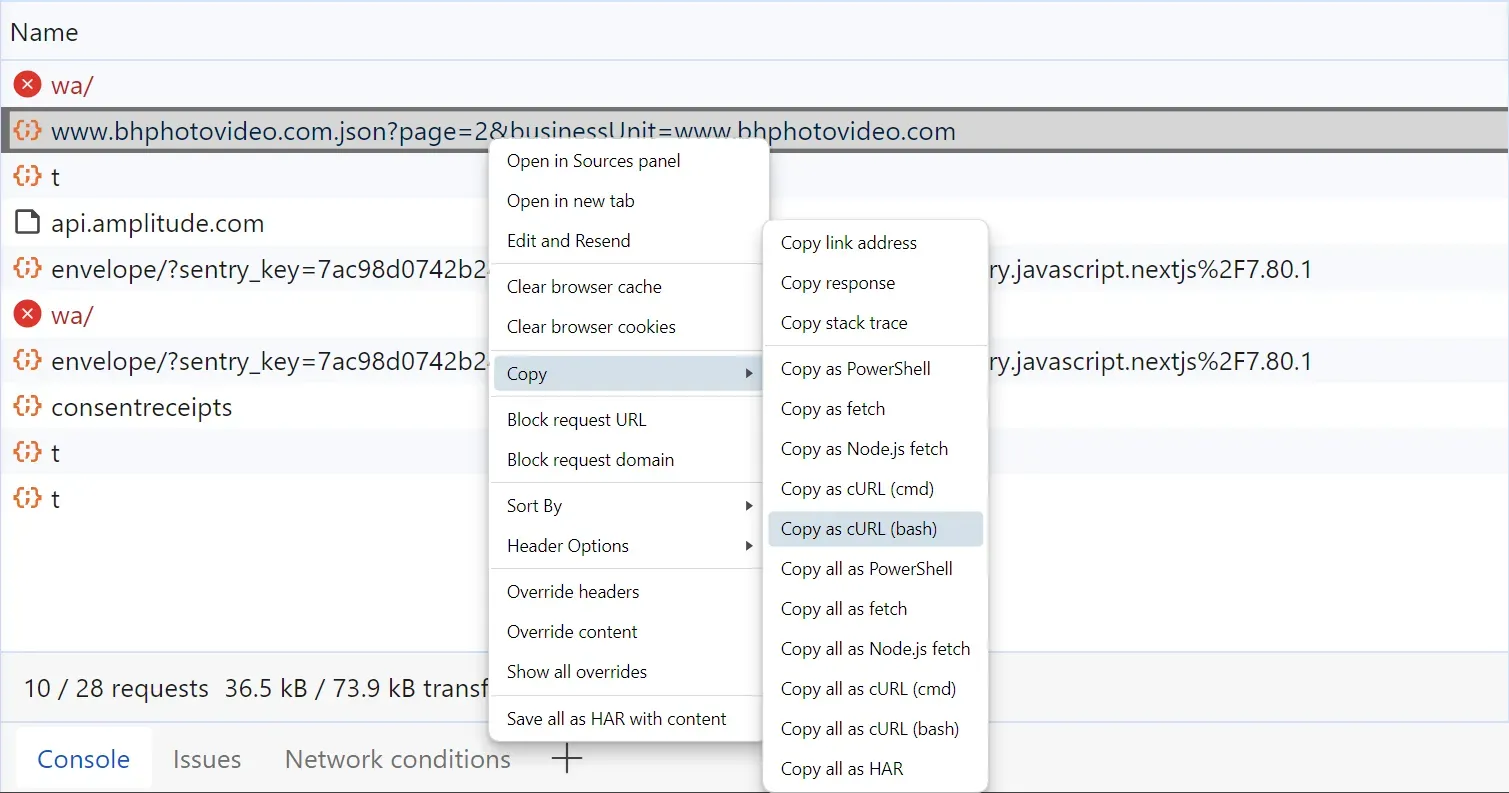
The cURL request we copied looks like this:
curl 'https://www.trustpilot.com/_next/data/businessunitprofile-consumersite-2.72.0/review/www.bhphotovideo.com.json?page=2&businessUnit=www.bhphotovideo.com' \
-H 'authority: www.trustpilot.com' \
-H 'accept: */*' \
-H 'accept-language: en-US,en;q=0.9' \
-H 'cookie: ajs_anonymous_id=f38614b0-1f07-4aa9-a626-b89b16143897; _ga=GA1.1.1620487471.1698331535; _tt_enable_cookie=1; _ttp=_RsLO4IKVA9y0x6TsoRtiROZiME; TP.uuid=d1a44848-82a3-43ac-a83f-644023848760; OptanonConsent=isGpcEnabled=0&datestamp=Mon+Feb+05+2024+13%3A18%3A03+GMT%2B0200+(Eastern+European+Standard+Time)&version=6.28.0&isIABGlobal=false&hosts=&consentId=cd806c9c-da4e-4be6-82fe-e547822c8b2d&interactionCount=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false; _hjSessionUser_391767=eyJpZCI6ImFjYjAyYjU2LTIyZGMtNTA0Mi05YTU1LTZiNjA5YWUyMWU3NyIsImNyZWF0ZWQiOjE2OTgzMzE1MzM0NTMsImV4aXN0aW5nIjp0cnVlfQ==; _hjSession_391767=eyJpZCI6ImIxMzliNjZlLWY2OWQtNDM2MC1iNmU2LWU5ZTZhODcwY2M5OSIsImMiOjE3MDcxMzE4ODM3OTMsInMiOjAsInIiOjAsInNiIjowLCJzciI6MCwic2UiOjAsImZzIjowLCJzcCI6MH0=; amplitude_idundefinedtrustpilot.com=eyJvcHRPdXQiOmZhbHNlLCJzZXNzaW9uSWQiOm51bGwsImxhc3RFdmVudFRpbWUiOm51bGwsImV2ZW50SWQiOjAsImlkZW50aWZ5SWQiOjAsInNlcXVlbmNlTnVtYmVyIjowfQ==; amplitude_id_67f7b7e6c8cb1b558b0c5bda2f747b07trustpilot.com=eyJkZXZpY2VJZCI6IjIzNWExZjQzLWNlZjEtNDBiNy1iY2NkLTYxYzlmYjYzZmNhNVIiLCJ1c2VySWQiOm51bGwsIm9wdE91dCI6ZmFsc2UsInNlc3Npb25JZCI6MTcwNzEzMTg4NTAyMiwibGFzdEV2ZW50VGltZSI6MTcwNzEzMTg4NTAzMSwiZXZlbnRJZCI6MSwiaWRlbnRpZnlJZCI6MCwic2VxdWVuY2VOdW1iZXIiOjF9; _gcl_au=1.1.1799677703.1707131885; _hjHasCachedUserAttributes=true; _ga_11HBWMC274=GS1.1.1707131885.2.0.1707132714.60.0.0; __tld__=1' \
-H 'referer: https://www.trustpilot.com/review/www.bhphotovideo.com' \
-H 'sec-ch-ua: "Not A(Brand";v="99", "Microsoft Edge";v="121", "Chromium";v="121"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0' \
-H 'x-nextjs-data: 1' \
--compressedIt includes all the API request details, including the HTTP method, URL, parameters, How Headers Are Used to Block Web Scrapers and How to Fix It and How to Handle Cookies in Web Scraping. To import this request into Postman, all we have to do is open the Postman import menu and paste the cURL we copied:
From this Postman interface, we can adjust our request parameters and headers to specific results. Furthermore, we can inspect the headers used by the request to find auth keys and identify them in the page HTML, local storage or background XHR calls to use them for future requests.
Let's ensure our request configuration on Postman by retrieving review data from a different page number:
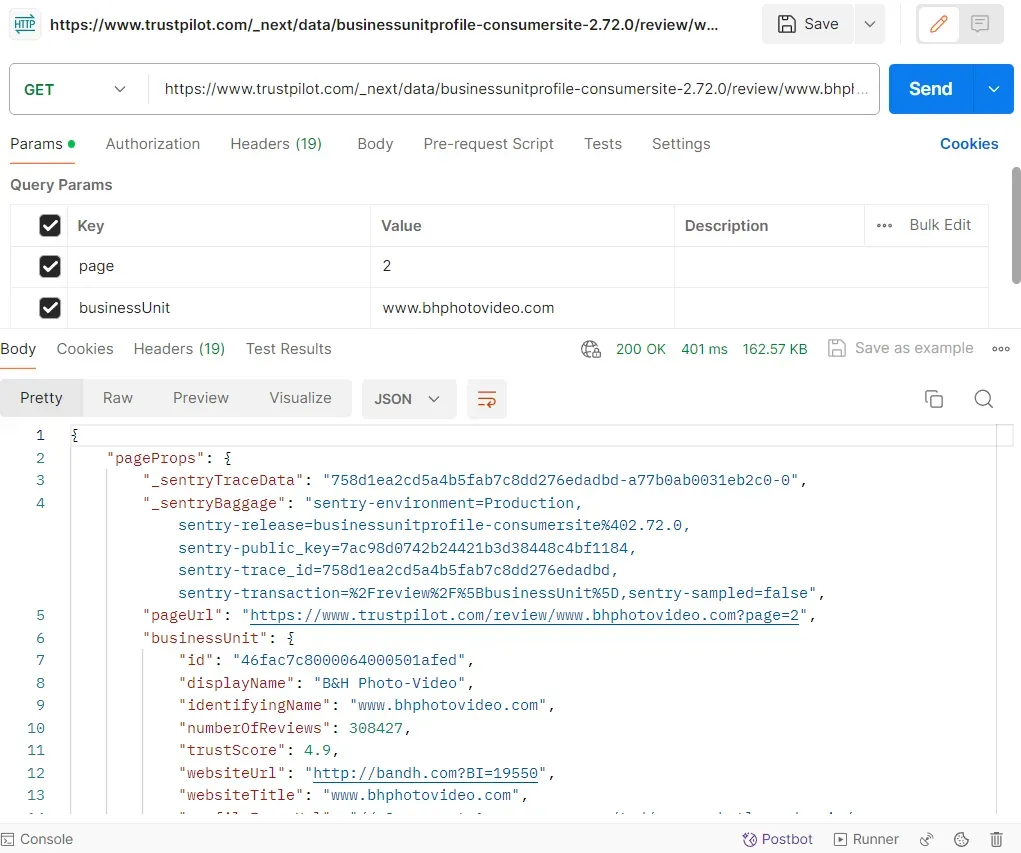
From the above image, we can see that the response request execution time didn't exceed two seconds. Web scraping through APIs can notably increase our web scraping speed!
Our API request has been set up successfully on Postman. However, we can't really web scrape using Postman so let's export the API request to Python! (or any other programming language)
Export Postman API Request to Python
Postman comes with a built-in API request exporter capable of exporting requests to almost any programming language. Let's export it into Python with the requests library:
The Python request we copied from Postman is ready for use:
import requests
url = "https://www.trustpilot.com/_next/data/businessunitprofile-consumersite-2.72.0/review/www.bhphotovideo.com.json?page=2&businessUnit=www.bhphotovideo.com"
payload = {}
headers = {
'authority': 'www.trustpilot.com',
'accept': '*/*',
'accept-language': 'en-US,en;q=0.9',
'cookie': 'ajs_anonymous_id=f38614b0-1f07-4aa9-a626-b89b16143897; _ga=GA1.1.1620487471.1698331535; _tt_enable_cookie=1; _ttp=_RsLO4IKVA9y0x6TsoRtiROZiME; TP.uuid=d1a44848-82a3-43ac-a83f-644023848760; OptanonConsent=isGpcEnabled=0&datestamp=Mon+Feb+05+2024+13%3A18%3A03+GMT%2B0200+(Eastern+European+Standard+Time)&version=6.28.0&isIABGlobal=false&hosts=&consentId=cd806c9c-da4e-4be6-82fe-e547822c8b2d&interactionCount=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false; _hjSessionUser_391767=eyJpZCI6ImFjYjAyYjU2LTIyZGMtNTA0Mi05YTU1LTZiNjA5YWUyMWU3NyIsImNyZWF0ZWQiOjE2OTgzMzE1MzM0NTMsImV4aXN0aW5nIjp0cnVlfQ==; _hjSession_391767=eyJpZCI6ImIxMzliNjZlLWY2OWQtNDM2MC1iNmU2LWU5ZTZhODcwY2M5OSIsImMiOjE3MDcxMzE4ODM3OTMsInMiOjAsInIiOjAsInNiIjowLCJzciI6MCwic2UiOjAsImZzIjowLCJzcCI6MH0=; amplitude_idundefinedtrustpilot.com=eyJvcHRPdXQiOmZhbHNlLCJzZXNzaW9uSWQiOm51bGwsImxhc3RFdmVudFRpbWUiOm51bGwsImV2ZW50SWQiOjAsImlkZW50aWZ5SWQiOjAsInNlcXVlbmNlTnVtYmVyIjowfQ==; amplitude_id_67f7b7e6c8cb1b558b0c5bda2f747b07trustpilot.com=eyJkZXZpY2VJZCI6IjIzNWExZjQzLWNlZjEtNDBiNy1iY2NkLTYxYzlmYjYzZmNhNVIiLCJ1c2VySWQiOm51bGwsIm9wdE91dCI6ZmFsc2UsInNlc3Npb25JZCI6MTcwNzEzMTg4NTAyMiwibGFzdEV2ZW50VGltZSI6MTcwNzEzMTg4NTAzMSwiZXZlbnRJZCI6MSwiaWRlbnRpZnlJZCI6MCwic2VxdWVuY2VOdW1iZXIiOjF9; _gcl_au=1.1.1799677703.1707131885; _hjHasCachedUserAttributes=true; _ga_11HBWMC274=GS1.1.1707131885.2.0.1707132714.60.0.0; __tld__=1',
'referer': 'https://www.trustpilot.com/review/www.bhphotovideo.com',
'sec-ch-ua': '"Not A(Brand";v="99", "Microsoft Edge";v="121", "Chromium";v="121"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0',
'x-nextjs-data': '1'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)The above code can send a successful request. However, it doesn't utilize any parsing logic to filter or save the data. Let's modify it to ensure an effective Python API scraping process.
Let's add a parsing login to remove the redundant and unnecessary data:
import json
def parse_reviews_api(response):
"""parse the reviews API response"""
data = json.loads(response.text)
review_data = data["pageProps"]["reviews"]
review_pages = data["pageProps"]["filters"]["pagination"]["totalPages"]
return review_data, review_pagesHere, we define a parse_reviews_api() function. It loads the response data into a JSON object and then extracts the review data and the total number of review pages.
Next, we'll utilize the function we defined while sending requests to crawl review pages:
import requests
import json
def parse_reviews_api(response):
"""parse the reviews API response"""
data = json.loads(response.text)
review_data = data["pageProps"]["reviews"]
review_pages = data["pageProps"]["filters"]["pagination"]["totalPages"]
return review_data, review_pages
def request_reviews_api(page_number: int):
"""send an API request using the reviews API"""
url = f"https://www.trustpilot.com/_next/data/businessunitprofile-consumersite-2.72.0/review/www.bhphotovideo.com.json?page={page_number}&businessUnit=www.bhphotovideo.com"
# first page doesn't use the 'page' parameter
if page_number == 1:
url = "https://www.trustpilot.com/_next/data/businessunitprofile-consumersite-2.72.0/review/www.bhphotovideo.com.json?businessUnit=www.bhphotovideo.com"
headers = {
'authority': 'www.trustpilot.com',
'accept': '*/*',
'accept-language': 'en-US,en;q=0.9',
'cookie': 'ajs_anonymous_id=f38614b0-1f07-4aa9-a626-b89b16143897; _ga=GA1.1.1620487471.1698331535; _tt_enable_cookie=1; _ttp=_RsLO4IKVA9y0x6TsoRtiROZiME; TP.uuid=d1a44848-82a3-43ac-a83f-644023848760; OptanonConsent=isGpcEnabled=0&datestamp=Mon+Feb+05+2024+13%3A18%3A03+GMT%2B0200+(Eastern+European+Standard+Time)&version=6.28.0&isIABGlobal=false&hosts=&consentId=cd806c9c-da4e-4be6-82fe-e547822c8b2d&interactionCount=1&landingPath=NotLandingPage&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1&AwaitingReconsent=false; _hjSessionUser_391767=eyJpZCI6ImFjYjAyYjU2LTIyZGMtNTA0Mi05YTU1LTZiNjA5YWUyMWU3NyIsImNyZWF0ZWQiOjE2OTgzMzE1MzM0NTMsImV4aXN0aW5nIjp0cnVlfQ==; _hjSession_391767=eyJpZCI6ImIxMzliNjZlLWY2OWQtNDM2MC1iNmU2LWU5ZTZhODcwY2M5OSIsImMiOjE3MDcxMzE4ODM3OTMsInMiOjAsInIiOjAsInNiIjowLCJzciI6MCwic2UiOjAsImZzIjowLCJzcCI6MH0=; amplitude_idundefinedtrustpilot.com=eyJvcHRPdXQiOmZhbHNlLCJzZXNzaW9uSWQiOm51bGwsImxhc3RFdmVudFRpbWUiOm51bGwsImV2ZW50SWQiOjAsImlkZW50aWZ5SWQiOjAsInNlcXVlbmNlTnVtYmVyIjowfQ==; amplitude_id_67f7b7e6c8cb1b558b0c5bda2f747b07trustpilot.com=eyJkZXZpY2VJZCI6IjIzNWExZjQzLWNlZjEtNDBiNy1iY2NkLTYxYzlmYjYzZmNhNVIiLCJ1c2VySWQiOm51bGwsIm9wdE91dCI6ZmFsc2UsInNlc3Npb25JZCI6MTcwNzEzMTg4NTAyMiwibGFzdEV2ZW50VGltZSI6MTcwNzEzMTg4NTAzMSwiZXZlbnRJZCI6MSwiaWRlbnRpZnlJZCI6MCwic2VxdWVuY2VOdW1iZXIiOjF9; _gcl_au=1.1.1799677703.1707131885; _hjHasCachedUserAttributes=true; _ga_11HBWMC274=GS1.1.1707131885.2.0.1707132714.60.0.0; __tld__=1',
'referer': 'https://www.trustpilot.com/review/www.bhphotovideo.com',
'sec-ch-ua': '"Not A(Brand";v="99", "Microsoft Edge";v="121", "Chromium";v="121"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0',
'x-nextjs-data': '1'
}
response = requests.request("GET", url, headers=headers)
return response
def scrape_reviews(max_scrape_pages: int = None):
"""scrape and crawl review pages using the reviews API"""
# scrape the first review page first to get the total number of reviews
first_page = request_reviews_api(page_number=1)
review_data, review_pages = parse_reviews_api(first_page)
# get the total number of pages to scrape
if max_scrape_pages and max_scrape_pages < review_pages:
review_pages = max_scrape_pages
# scrape the remaining review pages
for page in range(2, review_pages + 1):
response = request_reviews_api(page)
data = parse_reviews_api(response)
review_data.extend(data)
print(f"scraped {len(review_data)} reviews from the reviews API")
return review_data
data = scrape_reviews(max_scrape_pages=3)
# save the results to a JSON file (data.json)
with open("data.json", "w", encoding="utf") as file:
json.dump(data, file, indent=2)In the above code, we define two additional functions. Let's break them down:
request_reviews_api()which sends a request to a specific trustpilot review page.scrape_reviews()which crawls over trustpilot review pages and scrapes them using the hidden reviews API.
The result is a clean JSON file containing the review data of each page:
[
{
"id": "65c1d4509740bb309922f3f5",
"filtered": false,
"pending": false,
"text": "Fast service",
"rating": 5,
"labels": {
"merged": null,
"verification": {
"isVerified": true,
"createdDateTime": "2024-02-06T08:40:17.000Z",
"reviewSourceName": "InvitationLinkApi",
"verificationSource": "invitation",
"verificationLevel": "invited",
"hasDachExclusion": false
}
},
"title": "Fast service",
"likes": 0,
"dates": {
"experiencedDate": "2024-02-06T00:00:00.000Z",
"publishedDate": "2024-02-06T08:40:17.000Z",
"updatedDate": null
},
"report": null,
"hasUnhandledReports": false,
"consumer": {
"id": "655fcd805f1f1b001276c172",
"displayName": "CH",
"imageUrl": "",
"numberOfReviews": 2,
"countryCode": "US",
"hasImage": false,
"isVerified": false
},
"reply": null,
"consumersReviewCountOnSameDomain": 1,
"consumersReviewCountOnSameLocation": null,
"productReviews": [],
"language": "en",
"location": null
},
....
]With this last step, our process of using API clients for web scraping is complete!
However, when scraping at scale the target website is likely to fingerprint our IP address and block it after sending additional requests. Let's have a look at a solution!
ScrapFly: Avoid Scraping Blocking
API clients are great tools for web scraper development though for scaling up web scraping Scrapfly can offer even greater amount of varying tools!

Here is how we can use ScrapFly to avoid blocking while scraping through APIs. All we have to do is replace the HTTP client with the ScrapFly client and enable the asp parameter:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
ScrapeConfig(
# target website URL
url="https://www.trustpilot.com/_next/data/businessunitprofile-consumersite-2.72.0/review/www.bhphotovideo.com.json?businessUnit=www.bhphotovideo.com",
# bypass anti scraping protection
asp=True,
# select a proxy pool (residential or datacenter)
proxy_pool="public_residential_pool",
# set the proxy location to a specific country
country="US",
# add request headers if needed
headers={"content-type": "application/json"},
# specify the request type
method="POST",
)
)
# get the response body
data = api_response.contentFor more, explore web scraping API and its documentation.
FAQ
What are the limitations of web scraping using hidden APIs?
Hidden APIs frequently change as they aren't exposed to the public, making the web scraping logic obsolete. Moreover, these APIs often require using auth keys and tokens, which expire quickly and lead to web scraping blocking.
Can I scrape hidden APIs using headless browsers?
Yes, headless browsers can capture background XHR calls, which can then be replicated with HTTP clients. For more details, refer to our previous guide on web scraping background requests.
Can I use the web scraping through APIs approach for any website?
No, many websites don't use hidden APIs to fetch the data and retrieve it as HTML from the server side. However, you can scrape these websites through HTML parsing and turn the web scrapers into APIs.
How do I handle expired authentication tokens when scraping APIs with Postman?
Implement token refresh logic by monitoring API responses for 401/403 errors, extracting new tokens from authentication endpoints, and updating Postman environment variables or request headers automatically.
What's the difference between scraping hidden APIs vs traditional HTML parsing?
Hidden APIs return structured JSON data directly, eliminating HTML parsing complexity and providing faster, more reliable data extraction. Traditional HTML parsing requires CSS selectors/XPath and is more susceptible to layout changes.
How do I find hidden API endpoints using browser developer tools?
Open browser dev tools (F12), go to Network tab, filter by XHR/Fetch requests, interact with the page (click buttons, scroll, search), and look for JSON responses that contain the data you need.
Can I export Postman requests to languages other than Python?
Yes, Postman supports code generation for many languages including JavaScript, cURL, Go, Java, C#, PHP, Ruby, Swift, and more. Use the "Code" button in Postman to generate code snippets.
Why do some APIs block requests from Postman but work in the browser?
APIs may block Postman due to missing browser-specific headers (like sec-ch-ua, sec-fetch-*), different User-Agent strings, or lack of proper referrer headers. Copy all headers from browser dev tools to Postman to match browser behavior.
Summary
In this article, we explained the use of API clients to develop API-based web scrapers. These web scrapers use hidden APIs to retrieve the data directly in JSON, allowing for faster execution time and higher data coverage.
We started by explaining how to find hidden APIs on websites. Then, we explained how to import and manipulate these API requests on Postman. Finally, we have explored how to export API requests to different programming languages and integrate them with parsing and crawling logic.


