

User agents in web scraping play a major role in preventing scraper blocking. In this article, we'll take a look at what user agents are, why they are important in web scraping, and how to rotate user agents for web scraping in Python. We'll also explore how to build a list of user agent strings to use in your crawlers and which user agents are most effective for scraping.
Key Takeaways
Master user agent python techniques for web scraping by implementing rotation strategies and realistic browser fingerprints to avoid detection and blocking.
- Use realistic User-Agent strings that match real browsers to avoid immediate bot detection and blocking
- Implement User-Agent rotation strategies to distribute requests across different browser profiles
- Parse User-Agent strings with ua_parser library to extract browser, OS, and device information
- Choose appropriate User-Agent headers based on target website's typical visitor demographics
- Combine User-Agent rotation with other fingerprinting elements for comprehensive anti-detection
- Use specialized tools and libraries to generate and manage large pools of realistic User-Agent strings
What is User-Agent Header?
The User-Agent header is one of many standard request headers. It identifies the request sender's device and includes information about the device type, operating system, browser name, and version.
Historically, the User-Agent was intended to help websites optimize served content for different devices. However, contemporary responsive websites mostly use this datapoint for tracking.
The value of the User-Agent header is called the user agent string. It follows a straightforward pattern that provides various details about the connecting user:
User-Agent: Mozilla/5.0 (<system-information>) <platform> <browser-info>Let's break down this format:
Mozilla/5.0: A historical artifact (always there).<system-information>: Represents the operating system, its version and the CPU architecture.<platform>: Represent the rendering engine used and its version.<browser-info>: Provides information about the used web browser and it's version.
This pattern creates user agent strings that look like this:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0For example, the above user agent string represents a Firefox 113 browser on a Mac OS X 10.15 system using the Gecko engine. To parse a User-Agent string and extract information, we can use Python’s ua_parser library which can extract user agent details from a given string:
from ua_parser import user_agent_parser
user_agent_string = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0"
parsed_string = user_agent_parser.Parse(user_agent_string)
print(parsed_string)
{
"device": {
"brand": "Apple",
"family": "Mac",
"model": "Mac",
},
"os": {
"family": "Mac OS X",
"major": "10",
"minor": "15",
"patch": None,
"patch_minor": None,
},
"string": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0",
"user_agent": {
"family": "Firefox",
"major": "113",
"minor": "0",
"patch": None,
},
}Using ua_parser, we can clearly see that this user agent string represents a Firefox browser (version 113) running on a Mac OS X 10.15 device, using the Gecko rendering engine.
Now that we understand the User-Agent header's purpose and structure, let’s see why we should use user agents for web scraping.
Why User Agents for Web Scraping?
Websites often analyze User-Agent headers to determine if the request sender is a real user or a bot. Therefore, web scraping headers like User-Agent are vital for scraping without getting blocked.
Many sites are likely to block requests that don't provide any User-Agent header. They may also throttle or block specific User-Agent strings that appear unusual (for example, strings indicating an outdated browser or a non-standard client like an obscure web crawler).
In practice, using a common browser user agent (such as a recent Chrome or Firefox string on Windows or Mac) can help your requests blend in as regular user traffic. Conversely, an outdated or uncommon user agent might raise red flags. Sometimes people ask what the "best" user agent for web scraping is; in reality, there's no single best user agent string that guarantees success for every site. This is why it's important to use and rotate user agents when scraping.
To prevent scrapers from being blocked because of the User-Agent, it’s best to rotate User-Agent headers for each outgoing request. Next, let's take a look at how to establish a pool of user-agent strings and randomly rotate them in web scraping.
How to Get User-Agent Strings?
The easiest way to get a User-Agent header is to obtain it from a real web browser using developer tools. Open any web page in browser like Chrome or Firefox and press the (F12) key to open Browser Developer Tools, then select the Network tab and reload the page:
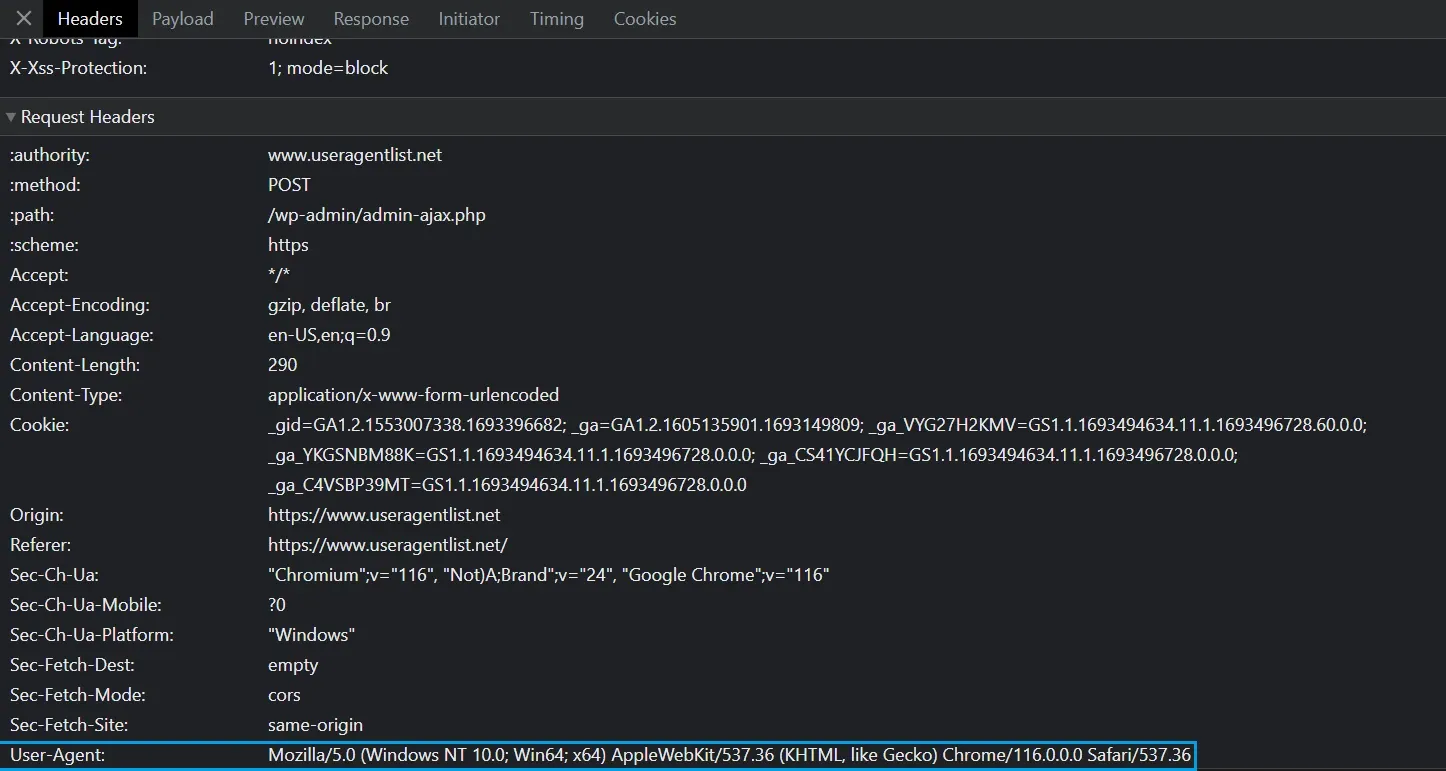
Each request made by the browser includes a set of headers, and one of them is the User-Agent string.
You can copy this user agent for small-scale web scraping. However, when scraping at scale, you'll need more than one user agent string to prevent scraper identification and blocking.
Building a User Agent List for Scraping
To scale up, we need to collect a large list of user agent strings and rotate them semi-randomly for the best scraping results.
There are many online databases of user agent strings. In this example, we'll scrape a list of user agents from useragentlist.net and then use weighted randomization in Python to rotate through them.

To scrape the user-agent strings, we'll use the httpx library along with BeautifulSoup. We'll also use ua_parser to parse each user-agent string into a structured object we can work with. All of these libraries can be installed using pip:
$ pip install httpx beautifulsoup4 ua-parserNow let's retrieve user agents from the online database and parse them:
from bs4 import BeautifulSoup
import httpx
url = "https://www.useragentlist.net/"
request = httpx.get(url)
user_agents = []
soup = BeautifulSoup(request.text, "html.parser")
for user_agent in soup.select("pre.wp-block-code"):
user_agents.append(user_agent.text)
print(user_agents)Here, we send a request to the target website and parse the HTML with BeautifulSoup to extract all user agent strings on the page. Here is what we got:
Output result
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Windows NT 6.1; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Windows NT 10.0; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Android 12; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0
Mozilla/5.0 (Android 13; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0
Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Android 11; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0
Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Windows NT 6.3; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:109.0) Gecko/20100101 Firefox/113.0
Mozilla/5.0 (Android 10; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36
Mozilla/5.0 (Linux; Android 10; Lenovo TB-8505F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; Infinix X656) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; LM-Q730) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; M2004J19C) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; SM-N960F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 11; A509DL) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 11; moto g pure) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 11; SM-A115F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 11; SM-A207F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 11; SM-A207M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; FNE-NX9) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; M2101K7AG) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; motorola edge 5G UW (2021)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; SM-A115F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; SM-A135U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; SM-M515F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 12; SM-S127DL) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 13; SM-A536E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 9; INE-LX2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 9; SM-J530F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; COL-L29) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; CPH1819) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; CPH1931) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; CPH2179) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; ELE-L29) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; HRY-LX1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36
Mozilla/5.0 (Linux; Android 10; JSN-L21) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36As you can see, we gathered a large variety of User-Agent strings (covering Windows, Mac, Linux, Android, etc.). This collection serves as our user agent list for scraping.
Now that we have a list of user agents for scraping, let’s move on to rotating these user agents.
How to Rotate User-Agent Headers
The idea behind rotating user agents is to change the User-Agent for every request made by the scraper. This will prevent simple User-Agent-based blocking, as the traffic is split between many different identifiers.
We could just grab a random user agent string each time; however, not all user agents are of the same quality for scraping. For example:
- Newer browser versions are more likely to be successful.
- Windows and Macos operating systems are more likely to be successful.
- More popular web browsers like Chrome and Firefox are more likely to succeed.
The rotation strategy can be improved by weighting these factors, so that user agents with higher "quality" get used more often. For instance, user agents for modern Mac and Windows browsers might be given higher weights than Linux or Android ones.
Let’s put this into code by creating a simple UserAgent container class and a Rotator class to handle weighted random selection:
from ua_parser import user_agent_parser
from functools import cached_property
from typing import List
from time import time
import random
class UserAgent:
"""container for a User-Agent"""
def __init__(self, string) -> None:
self.string: str = string
# Parse the User-Agent string
self.parsed_string: str = user_agent_parser.Parse(string)
self.last_used: int = time()
# Get the browser name
@cached_property
def browser(self) -> str:
return self.parsed_string["user_agent"]["family"]
# Get the browser version
@cached_property
def browser_version(self) -> int:
return int(self.parsed_string["user_agent"]["major"])
# Get the operation system
@cached_property
def os(self) -> str:
return self.parsed_string["os"]["family"]
# Return the actual user agent string
def __str__(self) -> str:
return self.string
class Rotator:
"""weighted random user agent rotator"""
def __init__(self, user_agents: List[UserAgent]):
# Add User-Agent strings to the UserAgent container
user_agents = [UserAgent(ua) for ua in user_agents]
self.user_agents = user_agents
# Add weight for each User-Agent
def weigh_user_agent(self, user_agent: UserAgent):
weight = 1_000
# Add higher weight for less used User-Agents
if user_agent.last_used:
_seconds_since_last_use = time() - user_agent.last_used
weight += _seconds_since_last_use
# Add higher weight based on the browser
if user_agent.browser == "Chrome":
weight += 100
if user_agent.browser == "Firefox" or "Edge":
weight += 50
if user_agent.browser == "Chrome Mobile" or "Firefox Mobile":
weight += 0
# Add higher weight for higher browser versions
if user_agent.browser_version:
weight += user_agent.browser_version * 10
# Add higher weight based on the OS type
if user_agent.os == "Windows":
weight += 150
if user_agent.os == "Mac OS X":
weight += 100
if user_agent.os == "Linux" or "Ubuntu":
weight -= 50
if user_agent.os == "Android":
weight -= 100
return weight
def get(self):
# Weigh all User-Agents
user_agent_weights = [
self.weigh_user_agent(user_agent) for user_agent in self.user_agents
]
# Select a random User-Agent
user_agent = random.choices(
self.user_agents,
weights=user_agent_weights,
k=1,
)[0]
# Update the last used time when selecting a User-Agent
user_agent.last_used = time()
return user_agentLet’s break down the above code.
First, the User-Agent strings are passed to the UserAgent class to extract its properties using the ua_parser module. Then, we create Rotator object which can select a random UserAgent from the pool based on the weights we defined.
Let’s mock a thousand requests with user-agent rotation to see how it works:
from collections import Counter
# Some user agents from the list we created earlier
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35",
"Mozilla/5.0 (Windows NT 6.1; rv:109.0) Gecko/20100101 Firefox/113.0",
"Mozilla/5.0 (Android 12; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0",
]
# The rotator class we created
rotator = Rotator(user_agents)
# Counter to track the most used user agents
counter = Counter()
for i in range(1000):
# Choose a random User-Agent in each iteration
user_agent = rotator.get()
counter[user_agent] += 1
# Show the most used User-Agents
for user_agent, used_count in counter.most_common():
print(f"{user_agent} was used {used_count} times")We create an instance to the Rotator class to rotate user agents in the list and use the Counter module to track the most used ones. Here is the result we got:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35 was used 188 times
Mozilla/5.0 (Windows NT 6.1; rv:109.0) Gecko/20100101 Firefox/113.0 was used 184 times
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35 was used 169 times
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0 was used 163 times
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35 was used 149 times
Mozilla/5.0 (Android 12; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0 was used 147 timesCool! We successfully rotated user agents for thousands of requests using weighted randomization which would distribute our scraper traffic through multiple user agent identifiers and prevent blocking.
How to Add User-Agents to Web Scrapers
A User-Agent string is just a request header, so configuring it in a web scraping client is straightforward: you simply need to set the User-Agent header in your HTTP requests.
import httpx
url = "https://httpbin.dev/user-agent"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
}
request = httpx.get(url, headers=headers)
user_agents = []
print(request.text)
# {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"}from playwright.sync_api import sync_playwright
# Intitialize a playwright instance
with sync_playwright() as playwight:
# Launch a chrome headless browser
browser = playwight.chromium.launch(headless=True)
# Create an independent browser session
context = browser.new_context()
context.set_extra_http_headers(
{
# Add User-Agent header
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36",
}
)
page = context.new_page()
page.goto("https://httpbin.dev/user-agent")
page_content = page.content()
browser.close()
print(page_content)
# {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"}from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
scrape_config=ScrapeConfig(
url="https://httpbin.dev/user-agent",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36",
},
)
)
page_content = api_response.scrape_result["content"]
print(page_content)
# {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"}In each case above, we simply added or changed the User-Agent header in the request. Once set, the HTTP response from httpbin.dev confirms the header value we used.
We have seen that we can manually generate and rotate user agents for web scraping. However, this process (maintaining a user agent list and writing rotation logic) can be quite complex and time-consuming. Next, let's look at an easier solution.
Automatic User-Agents using ScrapFly
User Agents can be quite straight forward when it comes to web scraping but still not enough to scale up some web scraping operations and this is where Scrapfly can lend a hand!

Instead of manually configuring user agents for web scraping ourselves, ScrapFly will automatically manage User-Agent headers and proxies to ensure the highest scraping success rate.
Here's an example of a scraping request with automated user-agent rotation and Scrapfly Python SDK:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
# Send a request to this URL, which returns the used User-Agent header
scrape_config=ScrapeConfig(url="https://httpbin.dev/user-agent")
)
page_content = api_response.scrape_result["content"]
print(page_content)
# {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}Instead of worrying about rotating User-Agent headers, let ScrapFly SDK do the heavy lifting for you. Sign-up now for free!
FAQ
What is the User-Agent header?
The User-Agent is a request header that represents the client device or application making the request. It typically includes information about the device, operating system, and web browser.
How to rotate user agents for web scraping?
The best way to rotate user agent strings in web scraping is to use weighted randomization. As user agent strings vary in quality in web scraping, we can assign weight modifications to each user agent string features like operating system, browser name or version. See this example in python.
What are the most common user agents?
The most common user agents are the ones that represent the most popular web browsers, their versions and operating systems. So, given these 3 details and user-agent pattern we can generate all possible popular user-agent headers!
Why do we need user agents for web scraping?
The User-Agent header adds metadata to the request that servers use to infer if the client is a regular browser or a script. Many websites will block or challenge requests that lack a realistic User-Agent. Therefore, including a proper User-Agent string with each request helps avoid scraping blocks.
How can I get a list of user agents for web scraping?
There are multiple online databases that provide lists of user agent strings. These databases can be scraped (as we demonstrated above) to generate your own user-agent pool. Some sources even provide ready-made lists (e.g., a "user agent list txt" file) that you can download and use directly as well.
Is just changing the User-Agent enough to avoid blocking?
No. While User-Agent rotation is essential, modern anti-bot systems check many other signals including TLS fingerprints, browser fingerprints, and request patterns. A comprehensive anti-detection strategy should combine User-Agent rotation with proxy rotation, proper headers, and realistic request timing.
Summary
In this article, we've looked at the User-Agent header and how it's used in web scraping. In short, the User-Agent provides metadata about the request sender's device and software, and by including appropriate User-Agent strings in your web scraping requests, you can drastically reduce the chances of your scraper being blocked.
We've also covered how to rotate user agents for web scraping. We've scraped our own user agent string pool from useragentstrings.net and used weighted randomization to rotate user agents in python. Finally, we've covered how to add these user agents to web scraping clients like httpx, playwright and Scrapfly Python SDK.


