

IP address blocking and throttling are common challenges encountered while web scraping and the most common solution to this is proxy use. However, proxies can be very expensive so are there any free alternatives?
In this article, we'll explore web scraping using Tor proxy network which is free and accessible to anyone. For this, we'll setup our scrapers to use Tor as a proxy server. This will change the IP address randomly for each scraping request - let's get started!
Key Takeaways
Configure tor proxy for web scraping using SOCKS5 and HTTP connections to rotate IP addresses and bypass geo-restrictions. Learn to set up Tor as a proxy server and implement IP rotation for anonymous data collection.
- Configure Tor as SOCKS5 proxy on port 9150 or HTTP proxy on port 9080 for web scraping
- Enable HTTP tunneling by adding HTTPTunnelPort 9080 to torrc configuration file
- Use rotating Tor proxy solutions like docker-multi-tor for multiple concurrent connections
- Implement proper timeout settings and connection handling for Tor's slower network performance
- Handle Tor's low IP reputation and increased blocking chances with fallback strategies
- Use specialized tools like ScrapFly for automated Tor proxy management with anti-blocking features
What is Tor?
Tor (The Onion Router) is a free and open-source tool and a network that's most commonly implemented through Firefox. It allows for anonymous internet browsing by:
- Blocking third-party trackers such as ads by clearing cookies and browsing history.
- Preventing connection monitoring and knowing the visited websites.
- Resist fingerprinting by making all Tor users look the same.
- Allowing access to restricted domains on the local network.
- Masking the real identity to a different IP address.
Tor also allows access to .onion domains exclusively. These domains have increased anonymity, and their visitors can almost hide their identities completely.
Although Tor is a web browser, other clients, such as web scrapers can use its network through a proxy.
How Does Tor Work?
Tor data is transmitted over a network called the Onion Router. This network consists of thousands of volunteer-based servers known as Tor relays.
To remain anonymous, requests sent over the Tor network go through three nodes: entry, middle, and exist. All requests sent over this network are encrypted, and they get decrypted through the following process:
- Entry Node This node knows the sender but doesn't know the destination. It peels the first encryption layer and passes it to the middle nodes.
- Middle Nodes Multiple layers of middle nodes that don't know the sender or the destination. They peel the more encryption layers except for the inner one and pass it to the exit node.
- Exit Node This node removes the last encryption layer and then sends the request to its final destination. It knows the destination but doesn't know the request sender.

How to Install Tor?
Installing Tor is very straightforward. Simply go the Tor download page and select the executable for your operating system:

After installing the downloaded file, run the Tor browser and connect to the network. You will get the following tab page:

Note that the Tor browser has to be opened for web scrapers to connect to its network. Next, let's explore using Tor for web scraping.
Using Tor as A Proxy Server
Since Tor routes the requests to different nodes on remote servers, the request's IP address gets rotated. Hence, we can use Tor as a proxy server for web scraping.
Web scraping using Tor distributes the requesting traffic across multiple IP addresses. This makes it harder for websites and antibots to detect the requests' origin, preventing IP address blocking.
SOCKS5
By default, Tor can be used as a proxy server by connecting to the 9150 port on localhost using the SOCKS5 protocol. Go to the http://127.0.0.1:9150/ localhost URL, and you will get the following page:
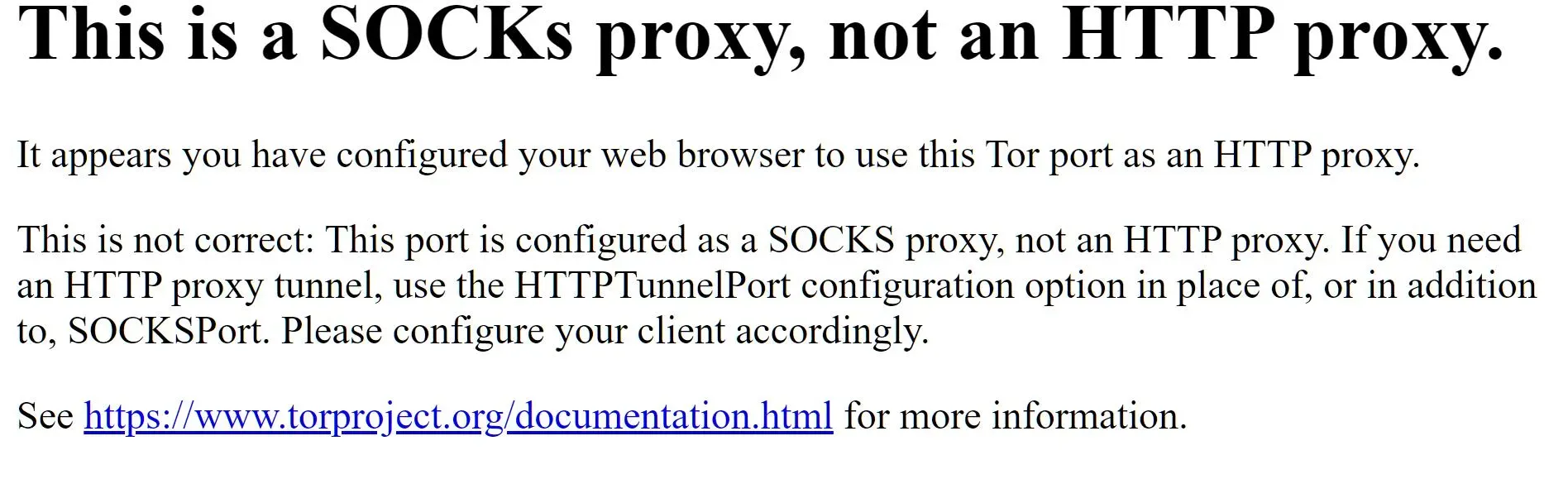
The above image warns about connecting to Tor as an HTTP proxy instead of SOCKS5, as it was requested using the browser.
Let's attempt to use Tor as a proxy server for simple HTTP requests:
import httpx
client = httpx.Client(proxy="socks5://127.0.0.1:9150/")
resp = client.get("https://httpbin.dev/ip")
print(resp.text)
"{'origin': '185.243.218.61'}"Here, we use the URL socks5://127.0.0.1:9150/ as a proxy server for How to Web Scrape with HTTPX and Python using Tor. The same URL can also be used with other web scraping clients to connect to Tor:
We have successfully used Tor as a SOCKS5 proxy server. However, we can enable HTTP proxies with Tor using a simple configuration option!
HTTP
To use Tor as an HTTP proxy, we'll use HTTP tunneling:
- Open the
torrcfile that can be found at:- Windows and Linux:
~/Browser/Browser/TorBrowser/Data/Tor/torrc - Mac:
~/Library/Application Support/TorBrowser-Data/torrc
- Windows and Linux:
- Add this line:
HTTPTunnelPort 9080to thetorrcfile and save it.
If we go to port 9080 on localhost, we'll find that Tor can now be used as an HTTP proxy:
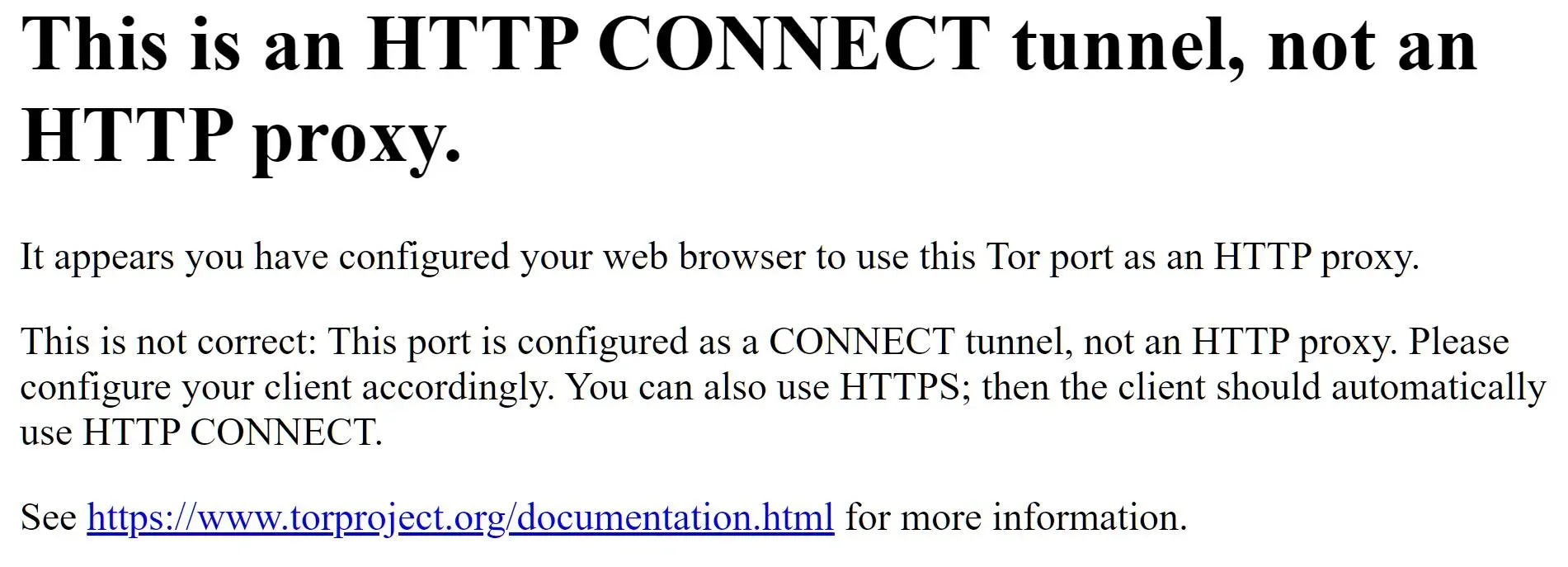
Just like what we did earlier with SOCKS5. We can use Tor HTTP proxy for web scraping:
import httpx
client = httpx.Client(proxy="http://127.0.0.1:9080/")
resp = client.get("https://httpbin.dev/ip")
print(resp.text)
"{'origin': '104.244.72.115'}"Here, we use http://127.0.0.1:9080/ as our Tor HTTP proxy URL. It can also be used with other web scraping clients, including headless browsers such as Web Scraping with Selenium and Python, Web Scraping Dynamic Websites With Scrapy Playwright, and How to Web Scrape with Puppeteer and NodeJS in 2026.
Rotate Proxies With Tor
When using Tor for web scraping as a proxy, we are limited to one IP address for each connection bridge. To get a new IP address, we have to restart Tor to re-initiate the connection bridge, which isn't practical to do while scraping.
There are community solutions that allow using Tor as a rotating proxy server by connecting to multiple Tor networks. Let's explore a few of these solutions.
- rotating-tor-http-proxy
A Docker image with many concurrently running network tunnels. It provides one HTTP endpoint to retrieve the network IPs as a proxy pool using HAProxy as a middleware.
- rotating-proxy
It does exactly what the above tool does, but it uses Polipo as a proxy adapter from SOCKS5 to HTTP.
- docker-multi-tor A lightweight Docker image, wrapping Tor and Polipo using Linux Alpine.
For further details on proxy rotation, refer to our dedicated guide.

Web Scraping With Tor Limitations
Tor can be used as a proxy server to change the IP address. However, using Tor for web scraping can have some limitations, including:
- Low connection speed
Requests sent over the Tor network must go through multiple routers to decrypt the data, significantly decreasing the connection speed.
- Low IP address reputation
IP addresses on the onion network can be shared across multiple users. This can decrease the IP address's reputation, leading to more request challenges and CAPTCHAs.
- Increased blocking chances Traffic data sent from the Tor exit node is public and decrypted. Websites and antibots can detect Tor usage from this node and block the requests.
For example, let's attempt to scrape data with Tor and observe its execution time:
import time
import httpx
client = httpx.Client(proxy="http://127.0.0.1:9080/", timeout=5000) # client with the Tor proxies
start_time = time.time()
for page_number in range(1, 6):
client.get(f"https://web-scraping.dev/products?page={page_number}")
total_execution_time = time.time() - start_time
print(f"Requests with Tor proxy execution time: {total_execution_time:.2f} seconds")
client = httpx.Client() # regular client without Tor
start_time = time.time()
for page_number in range(1, 6):
client.get(f"https://web-scraping.dev/products?page={page_number}")
total_execution_time = time.time() - start_time
print(f"Regular requests execution time: {total_execution_time:.2f} seconds")
"""
Requests with Tor proxy execution time: 19.93 seconds
Regular requests execution time: 10.36 seconds
"""From the above results, we can see that the Tor web crawler took almost double the time of normal requests. In a real-life scraping scenario, it can even be slower.
We can conclude that web scraping using Tor is suitable for small and medium-sized scales. However, it's not reliable for effective and scalable web scrapers. To effectively change the IP address while web scraping. It's advised to use high-quality residential and mobile proxies. Let's have a look!

Proxies with ScrapFly
Proxies and TOR network can be powerful but often still not enough to scale up web scraping operations and this is where Scrapfly can lend a hand!

Here's how we can web scrape with proxies using ScrapFly Python SDK. All we have to do is select a proxy pool and country while enabling the asp parameter to bypass scraping blocking:
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
proxy_pool="public_residential_pool", # select the residential proxy pool
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']FAQ
Can I use Tor for web scraping as a proxy server?
Yes. The Tor browser accepts a SOCKS5 proxy connection at the URL 127.0.0.1:9150 by default, which can be used with HTTP clients or headless browsers.
How to use Tor as an HTTP proxy?
To accept HTTP proxy connections with Tor, open the torrc file in the Tor browser directory. Then, add the line HTTPTunnelPort 9080 and save the file. Tor will then operate as an HTTP proxy at the URL 127.0.0.1:9080.
Can I rotate proxies with Tor?
Yes. rotating-tor-http-proxy and rotating-proxy are open-source tools that initiate multiple Tor connections using Docker, which is used as a rotating proxy server with dynamic proxy IPs.
How does Tor compare to residential proxies for web scraping?
Tor is free but significantly slower than residential proxies due to multi-hop routing. It also has a limited pool of exit nodes that many websites already block. Residential proxies offer faster speeds, larger IP pools, and better geographic targeting. For high-volume scraping, residential proxies are generally more reliable.
Summary
In this guide, we explained how to use Tor for web scraping. We started by defining what Tor is, how it works, and how to install it.
We went through a step-by-step guide on using Tor as a SOCKS and HTTP proxy server and explored a few open-source tools that allow using Tor as a rotating proxy server. Finally, we explored the limitations of web scraping using Tor:
- Slow connection speed due to traffic routing.
- High likelihood of being blocked by anti-bot services.
- Low proxy IP address reputation.


