

In this web scraping tutorial, we'll be taking a look at how to scrape Zoopla - a popular UK real estate property marketplace.
We'll be scraping real estate data such as pricing info, addresses, photos and phone numbers displayed on Zoopla's property pages.
To scrape Zoopla properties we'll be using hidden web data scraping method as this website is powered by Next.js. We'll also take a look at how to find real estate properties using Zoopla's search and sitemap system to collect all real estate property data available.
Finally, we'll also cover property tracking by continuously scraping for newly listed properties - giving us an edge in real estate market awareness. We'll be using Python with a few community libraries - Let's dive in!
Key Takeaways
Learn to scrape Zoopla.com UK real estate property data using Python with hidden web data techniques, extracting property listings, pricing, and market information from Next.js powered pages.
- Use hidden web data scraping to extract Zoopla's Next.js embedded JSON data without browser automation
- Parse JavaScript-embedded data structures to access comprehensive UK property information and pricing
- Handle Zoopla's anti-scraping measures with proper headers and request spacing for real estate data collection
- Extract structured property data including addresses, photos, phone numbers, and listing specifications
- Implement search and sitemap systems to discover and track all available property listings
- Use property tracking for newly listed properties to gain competitive advantages in UK real estate market

Latest Zoopla.com Scraper Code
Why Scrape Zoopla.com?
Zoopla.com is one of the biggest real estate websites in the United States making it the biggest public real estate dataset out there. Containing fields like real estate prices, listing locations and sale dates and general property information.
This is valuable information for market analytics, the study of the housing industry, and a general competitor overview.
For more on scraping use cases see our extensive write-up Scraping Use Cases

Available Zoopla Data Fields
We can scrape data from Zoopla for several popular real estate data fields and targets:
- Properties for sale
- Properties for rent
- Real estate agent info
In this guide, we'll cover focus on scraping real estate property (rent and sale) data for popular data fields like:
- Prices
- Photos
- Agent contact details
- Property features
- Proprety meta data and performance
For more, see the example scraper dataset for all fields we'll be scraping in this guide:
Example Scraper Output
{
"id": 63422316,
"title": "3 bed maisonette for sale",
"description": "Internal:<br><br>Entrance - Access is made via its own rear entrance door from the private outdoor terrace, opening to the first floor hall.<br><br>Hall - With solid wood flooring, the carpeted staircase leading up to the second floor landing and doors to the lounge, the kitchen, bedroom three and the bathroom.<br><br>Lounge - Offering generous space for furniture with a double glazed window with wooden shutters, solid wood flooring and a feature period fireplace with a decorative surround, mantelpiece and hearth.<br><br>Kitchen/Diner - Fitted with a range of modern black wall and base units with complementing wood worktops over, two double glazed windows and tiled flooring and splashbacks. Inset one and a half stainless steel sink basin with a drainer and mixer tap and an integrated fridge-freezer and an electric oven with a countertop gas hob and overhead extractor hood, with space for further appliances and for a dining table and chairs.<br><br>Bedroom Three - Can be used as a double size bedroom or as an additional reception room or study, with a double glazed window with wooden shutters, solid wood flooring and a closed corner fireplace.<br><br>Bathroom - Modern white suite comprising a push-button WC, a wash hand basin and a panelled bath with an overhead shower and glass screen. Obscure double glazed window, tiled flooring and partly tiled walls.<br><br>Second Floor Landing - With a Velux window, carpeted flooring, a storage cupboard, eaves storage and doors to bedrooms one and two.<br><br>Bedroom One - Large bedroom providing ample space for furniture, with a double glazed window, carpeted flooring, a closed fireplace and a storage cupboard.<br><br>Bedroom Two - Double size bedroom with a double glazed window with wooden shutters, carpeted flooring and a storage cupboard.<br><br>External:<br><br>The property benefits from a spacious and low-maintenance private terrace to the rear first floor.<br><br>Additional information:<br><br>Council Tax Band: B<br><br>Local Authority: Sutton<br><br>Lease: 125 years from 25 March 1988<br><br>Annual Ground Rent: £50 per<br><br>This information is to be confirmed by the vendor's solicitor.<br><br>Early viewing is highly recommended due to the property being realistically priced.<br><br>Disclaimer:<br><br>These particulars, whilst believed to be accurate are set out as a general guideline and do not constitute any part of an offer or contract. Intending Purchasers should not rely on them as statements of representation of fact, but must satisfy themselves by inspection or otherwise as to their accuracy. Please note that we have not tested any apparatus, equipment, fixtures, fittings or services including gas central heating and so cannot verify they are in working order or fit for their purpose. Furthermore, Solicitors should confirm moveable items described in the sales particulars and, in fact, included in the sale since circumstances do change during the marketing or negotiations. Although we try to ensure accuracy, if measurements are used in this listing, they may be approximate. Therefore if intending Purchasers need accurate measurements to order carpeting or to ensure existing furniture will fit, they should take such measurements themselves. Photographs are reproduced general information and it must not be inferred that any item is included for sale with the property.<br><strong>Tenure<br></strong><br><br>To be confirmed by the Vendor’s Solicitors<br><strong>Possession<br></strong><br><br>Vacant possession upon completion<br><strong>Viewing<br></strong><br><br>Viewing strictly by appointment through The Express Estate Agency",
"url": "/for-sale/details/63422316/",
"price": "£220,000",
"type": "maisonette",
"date": "2022-12-08T02:28:04",
"category": "residential",
"section": "for-sale",
"features": [
"*Guide Price £220,000 - £240,000*",
"**cash buyers only**",
"Duplex Maisonette With Private Entrance",
"Vacant with No Onward Chain",
"Three Double Size Bedrooms",
"Spacious Lounge with Feature Fireplace",
"Modern Kitchen/Diner with Appliances",
"Modern Bathroom Suite",
"Private Rear Terrace & Entrance Door",
"Ideal Rental Investment"
],
"floor_plan": { "filename": null, "caption": null },
"nearby": [
{ "title": "Malmesbury Primary School", "distance": 0.3 },
"etc. (reduced for blog)"
],
"coordinates": {
"lat": 51.383345,
"lng": -0.190118
},
"photos": [
{
"filename": "5f2cbcd9866478e716b32aa9af78e59a2c3645ce.jpg",
"caption": null
},
"etc. (reduced for blog)"
],
"details": {
"__typename": "ListingAnalyticsTaxonomy",
"location": "Sutton",
"regionName": "London",
"section": "for-sale",
"acorn": 36,
"acornType": 36,
"areaName": "Sutton",
"bedsMax": 3,
"bedsMin": 3,
"branchId": 15566,
"branchLogoUrl": "https://st.zoocdn.com/zoopla_static_agent_logo_(654815).png",
"branchName": "Express Estate Agency",
"brandName": "Express Estate Agency",
"chainFree": true,
"companyId": 18887,
"countryCode": "gb",
"countyAreaName": "London",
"currencyCode": "GBP",
"displayAddress": "Rosehill, Sutton SM1",
"furnishedState": "",
"groupId": null,
"hasEpc": true,
"hasFloorplan": true,
"incode": "3HE",
"isRetirementHome": false,
"isSharedOwnership": false,
"listingCondition": "pre-owned",
"listingId": 63422316,
"listingsCategory": "residential",
"listingStatus": "for_sale",
"memberType": "agent",
"numBaths": 1,
"numBeds": 3,
"numImages": 14,
"numRecepts": 1,
"outcode": "SM1",
"postalArea": "SM",
"postTownName": "Sutton",
"priceActual": 220000,
"price": 220000,
"priceMax": 220000,
"priceMin": 220000,
"priceQualifier": "guide_price",
"propertyHighlight": "",
"propertyType": "maisonette",
"sizeSqFeet": "",
"tenure": "leasehold",
"zindex": 255069
},
"agency": {
"__typename": "AgentBranch",
"branchDetailsUri": "/find-agents/branch/express-estate-agency-manchester-15566/",
"branchId": "15566",
"branchResultsUri": "/for-sale/branch/express-estate-agency-manchester-15566/",
"logoUrl": "https://st.zoocdn.com/zoopla_static_agent_logo_(654815).png",
"phone": "0333 016 5458",
"name": "Express Estate Agency",
"memberType": "agent",
"address": "St George's House, 56 Peter Street, Manchester",
"postcode": "M2 3NQ"
}
}
Project Setup
In this tutorial, we'll be using Python with three community packages:
- httpx - HTTP client library which will let us communicate with Zoopla.com's servers
- parsel - HTML parsing library which will help us to parse our web scraped HTML data using CSS selectors or Xpath.
- jmespath - JSON parsing library. Allows writing XPath like rules for JSON.
These packages can be easily installed via the pip install command:
$ pip install httpx parsel jmespath
Alternatively, feel free to swap httpx out with any other HTTP client package such as requests as we'll only need basic HTTP functions which are almost interchangeable in every library. As for, parsel, another great alternative is the beautifulsoup package.
Scraping Zoopla Property Data
Let's start by taking a look at how to scrape property data from a single listing page.
Let's start by picking a random property listing as our test target. To extract its data, we'll parse its HTML documents using prsel.
import asyncio
import json
from typing import List
from httpx import AsyncClient, Response
from parsel import Selector
session = AsyncClient(
headers={
# use same headers as a popular web browser (Chrome on Windows in this case)
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "en-US,en;q=0.9",
}
)
def parse_property(response: Response) -> Optional[PropertyResult]:
"""refine property data using JMESPath"""
selector = Selector(response.text)
url = selector.xpath("//meta[@property='og:url']/@content").get()
price = selector.xpath("//p[contains(text(),'£')]/text()").get()
receptions = selector.xpath("//p[contains(text(),'reception')]/text()").get()
baths = selector.xpath("//p[contains(text(),'bath')]/text()").get()
beds = selector.xpath("//p[contains(text(),'bed')]/text()").get()
gmap_source = selector.xpath("(//section[@aria-labelledby='local-area']//picture/source/@srcset)[last()]").get()
coordinates = gmap_source.split("/static/")[1].split("/")[0] if gmap_source else None
agent_path = selector.xpath("//section[@aria-label='Contact agent']//a/@href").get()
info = []
for i in selector.xpath("//section[h2[@id='key-info']]/ul/li"):
info.append(
{
"title": i.xpath(".//p/text()").get(),
"value": i.xpath(".//div/p/text()").get(),
}
)
nearby = []
for i in selector.xpath("//div[section[contains(@aria-label,'Travel')]]/section[3]//li/div"):
distance = i.xpath(".//p[2]/text()").get()
nearby.append(
{
"title": i.xpath(".//p[1]/text()").get(),
"distance": float(distance.split(" ")[0]) if distance else None,
"unit": distance.split(" ")[1] if distance else None,
}
)
result = {
"id": int(url.split("details/")[-1].split("/")[0]) if url else None,
"url": url,
"title": selector.xpath("//title/text()").get(),
"address": selector.xpath("//address/text()").get(),
"price": {
"amount": int(price.replace("£", "").replace(",", "")) if price else None,
"currency": "£",
},
"gallery": selector.xpath("//li[contains(@data-key,'gallery')]/picture/source[last()]/@srcset").getall(),
"epcRating": selector.xpath("//p[contains(text(),'EPC')]/text()").get(),
"floorArea": selector.xpath("//p[contains(text(),'ft')]/text()").get(),
"numOfReceptions": int(receptions.split(" ")[0]) if receptions else None,
"numOfBathrooms": int(baths.split(" ")[0]) if baths else None,
"numOfBedrooms": int(beds.split(" ")[0]) if beds else None,
"propertyTags": selector.xpath("(//section/ul)[1]/li/p/text()").getall(),
"propertyInfo": info,
"propertyDescription": selector.xpath("//section[@aria-labelledby='about']/ul/li/p/span/text()").getall(),
"coordinates": {
"googleMapeSource": gmap_source,
"latitude": float(coordinates.split(",")[0]) if coordinates else None,
"longitude": float(coordinates.split(",")[1]) if coordinates else None,
},
"nearby": nearby,
"agent": {
"name": selector.xpath("//section[@aria-label='Contact agent']//p/text()").get(),
"logo": selector.xpath("//section[@aria-label='Contact agent']//img/@src").get(),
"url": "https://www.zoopla.co.uk" + agent_path if agent_path else None,
}
}
return result
async def scrape_properties(urls: List[str]):
to_scrape = [session.get(url) for url in urls]
properties = []
for response in asyncio.as_completed(to_scrape):
properties.append(parse_property(await response))
return properties
import asyncio
import json
from typing import List
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
def parse_property(response: ScrapeApiResponse) -> Optional[PropertyResult]:
"""refine property data using JMESPath"""
selector = response.selector
url = selector.xpath("//meta[@property='og:url']/@content").get()
price = selector.xpath("//p[contains(text(),'£')]/text()").get()
receptions = selector.xpath("//p[contains(text(),'reception')]/text()").get()
baths = selector.xpath("//p[contains(text(),'bath')]/text()").get()
beds = selector.xpath("//p[contains(text(),'bed')]/text()").get()
gmap_source = selector.xpath("(//section[@aria-labelledby='local-area']//picture/source/@srcset)[last()]").get()
coordinates = gmap_source.split("/static/")[1].split("/")[0] if gmap_source else None
agent_path = selector.xpath("//section[@aria-label='Contact agent']//a/@href").get()
info = []
for i in selector.xpath("//section[h2[@id='key-info']]/ul/li"):
info.append(
{
"title": i.xpath(".//p/text()").get(),
"value": i.xpath(".//div/p/text()").get(),
}
)
nearby = []
for i in selector.xpath("//div[section[contains(@aria-label,'Travel')]]/section[3]//li/div"):
distance = i.xpath(".//p[2]/text()").get()
nearby.append(
{
"title": i.xpath(".//p[1]/text()").get(),
"distance": float(distance.split(" ")[0]) if distance else None,
"unit": distance.split(" ")[1] if distance else None,
}
)
result = {
"id": int(url.split("details/")[-1].split("/")[0]) if url else None,
"url": url,
"title": selector.xpath("//title/text()").get(),
"address": selector.xpath("//address/text()").get(),
"price": {
"amount": int(price.replace("£", "").replace(",", "")) if price else None,
"currency": "£",
},
"gallery": selector.xpath("//li[contains(@data-key,'gallery')]/picture/source[last()]/@srcset").getall(),
"epcRating": selector.xpath("//p[contains(text(),'EPC')]/text()").get(),
"floorArea": selector.xpath("//p[contains(text(),'ft')]/text()").get(),
"numOfReceptions": int(receptions.split(" ")[0]) if receptions else None,
"numOfBathrooms": int(baths.split(" ")[0]) if baths else None,
"numOfBedrooms": int(beds.split(" ")[0]) if beds else None,
"propertyTags": selector.xpath("(//section/ul)[1]/li/p/text()").getall(),
"propertyInfo": info,
"propertyDescription": selector.xpath("//section[@aria-labelledby='about']/ul/li/p/span/text()").getall(),
"coordinates": {
"googleMapeSource": gmap_source,
"latitude": float(coordinates.split(",")[0]) if coordinates else None,
"longitude": float(coordinates.split(",")[1]) if coordinates else None,
},
"nearby": nearby,
"agent": {
"name": selector.xpath("//section[@aria-label='Contact agent']//p/text()").get(),
"logo": selector.xpath("//section[@aria-label='Contact agent']//img/@src").get(),
"url": "https://www.zoopla.co.uk" + agent_path if agent_path else None,
}
}
return result
async def scrape_properties(urls: List[str]):
to_scrape = [ScrapeConfig(url, asp=True, country="GB", proxy_pool="public_residential_pool") for url in urls]
properties = []
async for response in scrapfly.concurrent_scrape(to_scrape):
try:
properties.append(parse_property(response))
except:
# retry failed requests
pass
return properties
🧙 If you are experiencing errors while running the Python code tabs, it may be due to getting blocked. To bypass blocking, use the ScrapFly code tabs instead.
Run Code
if __name__ == "__main__":
urls = [
"https://www.zoopla.co.uk/new-homes/details/67644732/",
"https://www.zoopla.co.uk/new-homes/details/66702316/",
"https://www.zoopla.co.uk/new-homes/details/67644753/"
]
data = asyncio.run(scrape_properties(urls))
print (json.dumps(data, indent=2))
Above, we wrote a small web scraper for Zoopla properties. Let's take a look at the key points of what we're doing here.
First, we establish a httpx session with browser-like default headers to avoid blocking. Then, we use the parsel.Selector object to parse the HTML document uisng the XPath selector and return the results as JSON.
Here's an example output of the results we got.
Example Output
{
"id": 67644753,
"url": "https://www.zoopla.co.uk/new-homes/details/67644753/",
"title": "New home, 3 bed detached house for sale in Felix Road, London W13, £1,035,000 - Zoopla",
"address": "Felix Road, London W13",
"price": {
"amount": 1035000,
"currency": "£"
},
"gallery": [
"https://lid.zoocdn.com/u/480/360/cee041957b1bbd98dbb317243c4b76d59c8b3a1a.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/0de7dfeccbe2264a687f3dd1fdf90d79a2deca11.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/80d0ee78df11be9387319f990487eced88ccb53d.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/57bc46a30ec256c98d1c93b9611f908c69e912d7.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/75c4f7ad2e1cebff34369905413a367892026e2c.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/9e19bcd66502cb47a3c79ba8e075e68e2d9d7b7f.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/c5648825650cbf0b2e17a2492222f176fceee66f.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/51bc8188bc04139307380c5bb18ec575e62ac69c.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/4000560b2deade585081311295d671aedd8efcca.jpg:p 480w",
"https://lid.zoocdn.com/u/480/360/0ce7cc46c667e90220bf429298383cc313e4e731.jpg:p 480w"
],
"epcRating": null,
"floorArea": "1,301 sq. ft",
"numOfReceptions": null,
"numOfBathrooms": 2,
"numOfBedrooms": 3,
"propertyTags": [
"New home",
"Freehold"
],
"propertyInfo": [
{
"title": "Tenure",
"value": "Freehold"
},
{
"title": "Council tax band",
"value": "The Council Tax Band of the Property is currently unknown."
}
],
"propertyDescription": [
"Close to Train Station",
"Home of the Week",
"Separate kitchen/dining and living room space",
"Luxury kitchen with breakfast bar",
"Fully fitted Siemens appliances and Caesarstone worktops",
"Private landscaped rear garden",
"Three-storey townhouse designed by Conran & Partners",
"Built in wardrobes to master and second bedrooms",
"En-suites to the master and guest bedrooms",
"Private front garden with storage space",
"Located on a quiet residential tree-lined road",
"Five minute walk to West Ealing station over the footbridge opposite"
],
"coordinates": {
"googleMapeSource": "https://maps.googleapis.com/maps/api/staticmap?size=400x200&format=jpg&scale=2¢er=51.512324,-0.326186&maptype=roadmap&zoom=13&channel=Lex-LDP&style=feature:poi.business%7Cvisibility:on&client=gme-zooplapropertygroup&sensor=false&markers=scale:2%7Cicon:https://r.zoocdn.com/assets/map-static-pin-purple-76.png%7C51.512324,-0.326186&signature=5i9XXbGOvsa242keMp10Bj0VZFU= 400w",
"latitude": 51.512324,
"longitude": -0.326186
},
"nearby": [
{
"title": "West Ealing",
"distance": 0.3,
"unit": "miles"
},
{
"title": "Drayton Green",
"distance": 0.3,
"unit": "miles"
},
{
"title": "Hanwell",
"distance": 0.5,
"unit": "miles"
},
{
"title": "Castle Bar Park",
"distance": 0.8,
"unit": "miles"
},
{
"title": "St John's Primary School",
"distance": 0.09,
"unit": "miles"
},
{
"title": "Drayton Green Primary School",
"distance": 0.2,
"unit": "miles"
},
{
"title": "Insights Independent School",
"distance": 0.3,
"unit": "miles"
},
{
"title": "Springhallow School",
"distance": 0.4,
"unit": "miles"
}
],
"agent": {
"name": "Hamptons - London New Homes",
"logo": "https://st.zoocdn.com/zoopla_static_agent_logo_(707660).png",
"url": "https://www.zoopla.co.uk/new-homes/developers/branch/hamptons-london-new-homes-london-16196/"
}
}
Here, we've updated our Python Zoopla web scraper with JSON parsing logic by defining parsing path using JMESPath.
Finding Zoopla Properties
To find property listings on Zoopla we have two options: scrape sitemaps to find all listed properties or use Zoopla's search system to scrape listings by location.
Scraping Zoopla Search
Zoopla is powered by a robust search system that allows easy navigation to the website. Before we scrape Zoopla's search, let's have a look at what it looks like. Upon submitting a search request with a keyword, like "Islington, London", you will get a similar page:
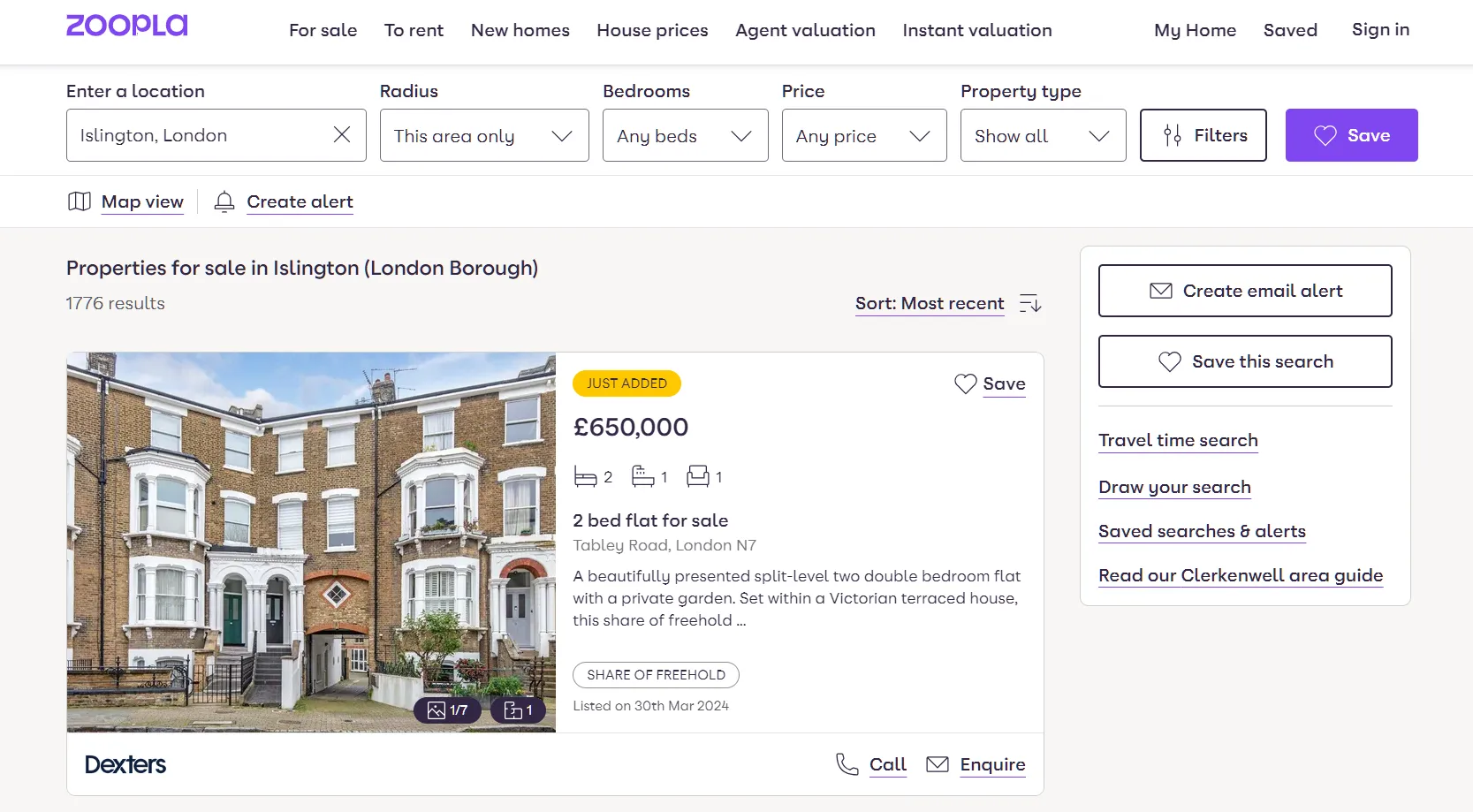
Zoopla search pages are dynamic, requiring JavaScript to be enabled in order for the search results to load. Hence, headless browsers like Selenium, Playwright, or Puppeteer. In this Zoopla scraper, we'll use ScrapFly to enable JavaScript rendering using a simple render_js parameter:
import json
import asyncio
import urllib.parse
from typing import List, Dict, Literal
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_search(response: ScrapeApiResponse):
"""parse property data from Zoopla search pages"""
selector = response.selector
data = []
total_results = int(
json.loads(selector.xpath("//script[@id='__ZAD_TARGETING__']/text()").get())["search_results_count"]
)
boxes = selector.xpath("//div[@data-testid='regular-listings']/div")
_results_count = len(boxes)
total_pages = total_results // _results_count
for box in boxes:
url = box.xpath(".//a/@href").get()
if not url:
continue
price = box.xpath(".//p[@data-testid='listing-price']/text()").get()
sq_ft = box.xpath(".//span[contains(text(),'sq. ft')]/text()").get()
sq_ft = int(sq_ft.split(" ")[0]) if sq_ft else None
listed_on = box.xpath(".//li[contains(text(), 'Listed on')]/text()").get()
listed_on = listed_on.split("on")[-1].strip() if listed_on else None
bathrooms = box.xpath(".//span[(contains(text(), 'bath'))]/text()").get()
bedrooms = box.xpath(".//span[(contains(text(), 'bed'))]/text()").get()
livingrooms = box.xpath(".//span[(contains(text(), 'reception'))]/text()").get()
image = box.xpath(".//picture/source/@srcset").get()
agency = box.xpath(".//div[a[@data-testid='listing-card-content']]/div")
item = {
"price": int(price.split(" ")[0].replace("£", "").replace(",", "")) if price else None,
"priceCurrency": "Sterling pound £",
"url": "https://www.zoopla.co.uk" + url.split("?")[0] if url else None,
"image": image.split(":p")[0] if image else None,
"address": box.xpath(".//address/text()").get(),
"squareFt": sq_ft,
"numBathrooms": int(bathrooms.split(" ")[0]) if bathrooms else None,
"numBedrooms": int(bedrooms.split(" ")[0]) if bedrooms else None,
"numLivingRoom": int(livingrooms.split(" ")[0]) if livingrooms else None,
"description": box.xpath(".//a[address]/p/text()").get(),
"justAdded": bool(box.xpath(".//div[text()='Just added']/text()").get()),
"agency": agency.xpath(".//img/@alt").get() or agency.xpath(".//p/text()").get(),
}
data.append(item)
return {"search_data": data, "total_pages": total_pages}
async def scrape_search(
scrape_all_pages: bool,
location_slug: str,
max_scrape_pages: int = 10,
query_type: Literal["for-sale", "to-rent"] = "for-sale",
) -> List[Dict]:
"""scrape zoopla search pages for roperty listings"""
# scrape the first search page first
first_page = await SCRAPFLY.async_scrape(
ScrapeConfig(
url = f"https://www.zoopla.co.uk/{query_type}/property/{location_slug}",
asp=True,
country="GB",
render_js=True,
auto_scroll=True,
rendering_wait=5000,
wait_for_selector="//p[@data-testid='total-results']"
)
)
data = parse_search(first_page)
# extract property listings
search_data = data["search_data"]
# get the number of the available search pages
max_search_pages = data["total_pages"]
# scrape all available pages in the search if scrape_all_pages = True or max_search_pages > max_scrape_pages
if scrape_all_pages == False and max_scrape_pages < max_search_pages:
total_pages_to_scrape = max_scrape_pages
else:
total_pages_to_scrape = max_search_pages
print(f"scraping search page {first_page.context['url']} remaining ({total_pages_to_scrape - 1} more pages)")
# add the remaining search pages to a scraping list
_other_pages = [
ScrapeConfig(f"{first_page.context['url']}&pn={page}", asp=True, country="GB", render_js=True)
for page in range(2, total_pages_to_scrape + 1)
]
# scrape the remaining search page concurrently
async for result in SCRAPFLY.concurrent_scrape(_other_pages):
page_data = parse_search(result)["search_data"]
search_data.extend(page_data)
print(f"scraped {len(search_data)} search listings from {first_page.context['url']}")
return search_data
Run Code
async def run():
search_data = await scrape_search(
scrape_all_pages=False,
max_scrape_pages=2,
# add further query parameters if needed
query="Islington, London",
query_type="for-sale"
)
# save the data to a JSON file
with open("data.json", "w", encoding="utf-8") as file:
json.dump(search_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
In the above Zoopla scraping code, we define two functions. Let's break them down:
parse_search: To parse the property data on Zoopla search pages and retrieve the total search pages available. It iterates over the search boxes to parse and refine each element using XPath selectors.scrape_search: To define the search URL using the search query parameter, including the search keyword. It requests the first page to retrieve the total pages available and request them concurrently.
Here's a sample output of the above Zoopla scraper code:
Example output
[
{
"price": 6934,
"priceCurrency": "Sterling pound £",
"url": "https://www.zoopla.co.uk/to-rent/details/68763704/",
"image": "https://lid.zoocdn.com/645/430/7c989cc5c58e5a99f08af9552fb9e27774998c8f.jpg",
"address": "New Wharf Road, Angel, London N1",
"squareFt": 634,
"numBathrooms": 1,
"numBedrooms": 2,
"numLivingRoom": 1,
"description": " Short let. Situated in a striking gated canal-side development this stylish 2 bedroom flat features a spacious reception room ...",
"justAdded": true,
"agency": "Foxtons - Islington"
},
]
The above code can be extended with crawling logic. Instead of parsing the search data results directly, the script can request the dedicated property page URL and then the full property data.
Next, let's take a look at a different discovery approach which can be used to find all properties on Zoopla - the sitemaps.
Scraping Zoopla Sitemaps
Sitemaps are collections of files that contain URLs to various web pages - be it property listings, blog articles or individual pages.
For our Zoopla scraper in Python, to find all properties using the sitemap collection, we first must find the sitemap itself. For that, we can check the /robots.txt endpoint which contains various instructions for web scrapers:
Sitemap: https://www.zoopla.co.uk/xmlsitemap/sitemap/index.xml.gz
This central sitemap acts as a hub for all other sitemaps that are categorized by a topic:
<sitemap>
<loc>https://www.zoopla.co.uk/xmlsitemap/sitemap/for_sale_details_001.xml.gz</loc>
<lastmod>2022-12-08T09:25:08+00:00</lastmod>
</sitemap>
<sitemap>
<loc>https://www.zoopla.co.uk/xmlsitemap/sitemap/to_rent_details_001.xml.gz</loc>
<lastmod>2022-12-08T09:25:08+00:00</lastmod>
</sitemap>
<sitemap>
<loc>https://www.zoopla.co.uk/xmlsitemap/sitemap/for_sale_flats_001.xml.gz</loc>
<lastmod>2022-12-08T09:25:08+00:00</lastmod>
</sitemap>
...
🧙♂️ each sitemap is limited to 50_000 URLs - that's why they are split into several parts.
For example, to scrape all properties for rent we could find all URLs by scraping the to_rent_ sitemaps.
Let's take a quick look at how to scrape sitemap files using Python:
import gzip
import asyncio
from httpx import AsyncClient
from parsel import Selector
session = AsyncClient()
async def scrape_feed(url):
response = await session.get(url)
decoded_gzip = gzip.decompress(response.text.read()).decode('utf-8')
selector = Selector(decoded_gzip)
results = []
for url in selector.xpath("//loc/text()").getall():
results.append(url)
return results
# example run
if __name__ == "__main__":
results = asyncio.run(scrape_feed("https://www.zoopla.co.uk/xmlsitemap/sitemap/to_rent_details_001.xml.gz"))
print(results)
import asyncio
import gzip
from scrapfly import ScrapeConfig, ScrapflyClient
from parsel import Selector
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
async def scrape_feed(url):
response = await scrapfly.async_scrape(ScrapeConfig(url, asp=True, country="GB"))
decoded_gzip = gzip.decompress(response.scrape_result['content'].read()).decode('utf-8')
selector = Selector(decoded_gzip)
results = []
for url in selector.xpath("//loc/text()").getall():
results.append(url)
return results
# example run
if __name__ == "__main__":
results = asyncio.run(scrape_feed("https://www.zoopla.co.uk/xmlsitemap/sitemap/to_rent_details_001.xml.gz"))
print(results)
🧙♂️ sometimes sitemap files can be gzip encoded. Use gzip.decode() function to decode the contents before passing them to the Selector.
Since sitemaps are XML files we can parse them with the same tools we use to parse HTML. In the example above we retrieve the sitemap page and extract URLs using parsel and XPath selectors.
Tracking New Zoopla Listings
We know how to find property listings, so now we can also track Zoopla for new property listings either by scraping the search or sitemaps.
If we want to keep our whole listing dataset up to date we can track the new_home_details_x sitemaps found in the Zooplas we covered earlier.
Though, these sitemaps are being updated only once per day - what if we want to know about new listings ASAP? For that, we can scrape search queries and sort them by "Most Recent" which is exactly how we coded our search scraper to behave.
Bypass Zoopla Blocking with Scrapfly
Web scraping Zoopla is very straight forward, however when scaling up our scraper beyond a few property scrapes we might start to run into scraper blocking and captchas.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
For this, we'll be using the scrapfly-sdk python package and the Anti Scraping Protection Bypass feature. To start, let's install scrapfly-sdk using pip:
$ pip install scrapfly-sdk
To take advantage of ScrapFly's API in our Zoopla web scraper all we need to do is change our httpx session code with scrapfly-sdk client requests:
import httpx
response = httpx.get("some redfin.com url")
# in ScrapFly SDK becomes
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient("YOUR SCRAPFLY KEY")
result = client.scrape(ScrapeConfig(
# some zoopla URL
"https://www.zoopla.co.uk/for-sale/details/63412743/",
# we can select specific proxy country
country="GB",
# and enable anti scraping protection bypass:
asp=True,
))
For more on how to scrape Zoopla.com using ScrapFly, see the Full Scraper Code section.
FAQ
To wrap this guide up, let's take a look at some frequently asked questions regarding how to scrape data from Zoopla:
Is it legal to scrape Zoopla.com?
Yes. Zoopla's data is publically available - scraping Zoopla at slow, respectful rates would fall under the ethical scraping definition.
That being said, be aware of GDRP compliance in the EU when storing personal data such as agent's personal details like names, phone numbers. For more, see our Is Web Scraping Legal? article.
Is there a Zoopla API?
Yes, though it's private and is limited to a specific set of data fields (e.g. contains no agent contact details). Fortunately, as covered in this article, we can scrape Zoopla using Python.
How to crawl Zoopla.com?
To web crawl Zoopla we can adapt the scraping techniques covered in this article. Particularly, the recommended/similar properties data field can be used to develop crawling logic. That being said, with Zoopla's extensive sitemap system crawling is unnecessary as we can scrape all properties directly.
Zoopla Scraping Summary
In this guide, we wrote a Zoopla scraper for real estate property data using nothing but Python with a few community packages: httpx, parsel and jmespath.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.
To scrape property data we used parsel to extract data hidden in an HTML script element. We then cleaned it up and parsed the most important fields using JMESPath parsing language.
To find properties to scrape we also explored how to scrape Zoopla's sitemap and search systems. We've also covered how search scraping can be used to track when new properties are being listed.
Finally, to avoid being blocked we used ScrapFly's API which smartly configures every web scraper connection to avoid being blocked. For more about ScrapFly, see our documentation and try it out for FREE!





