

In this tutorial, we'll take a look at how to scrape ZoomInfo for public company data. In 2026, ZoomInfo stores most visible data in hidden JSON blocks within <script type="application/json"> tags, making direct JSON extraction more reliable than parsing volatile CSS selectors.
We'll start with an overview on how Zoominfo.com works so we can find all public company pages. Then we'll scrape company data using Python with a few community packages.
Key Takeaways
Learn zoominfo scraper techniques using Python with Playwright for JavaScript-heavy interfaces and embedded JSON data extraction from company profiles.
- Use Playwright for browser automation to handle ZoomInfo's JavaScript-heavy interface and dynamic loading
- Parse HTML with parsel to extract company profiles, financial data, and employee information
- Handle ZoomInfo's anti-scraping measures with proper browser automation and realistic user behavior
- Extract comprehensive company data including credentials, contact details, and business intelligence
- Implement proper session management and cookie handling for sustained data collection
- Use specialized tools like ScrapFly for automated ZoomInfo scraping with anti-blocking features
Latest Zoominfo.com Scraper Code
Why Scrape Zoominfo?
Zoominfo.com hosts millions of public company profiles that contain company credentials, financial data and contacts. Company overview data can be used in business intelligence and market analysis. Company contact and employee details can be used in lead generation and the employment market.
For more on scraping use cases see our extensive web scraping use case article
Project Setup
In this tutorial we'll be using Python and a couple of popular community packages:
- httpx - an HTTP client library that will let us communicate with amazon.com's servers
- parsel - an HTML parsing library though we'll be doing very little HTML parsing in this tutorial and will be mostly working with JSON data directly instead.
- Playwright - a headless browser we'll use to scrape dynamically loaded content on Zoominfo.
These packages can be easily installed via pip command:
$ pip install httpx parsel playwrightAlternatively, feel free to swap httpx out with any other HTTP client package such as requests as we'll only need basic HTTP functions which are almost interchangeable in every library. As for, parsel, another great alternative is beautifulsoup package.
How to Scrape Zoominfo Company Data
To scrape a company profile listed on Zoominfo first let's take a look at the company page itself. For example, let's see this page for Tesla Inc. zoominfo.com/c/tesla-inc/104333869
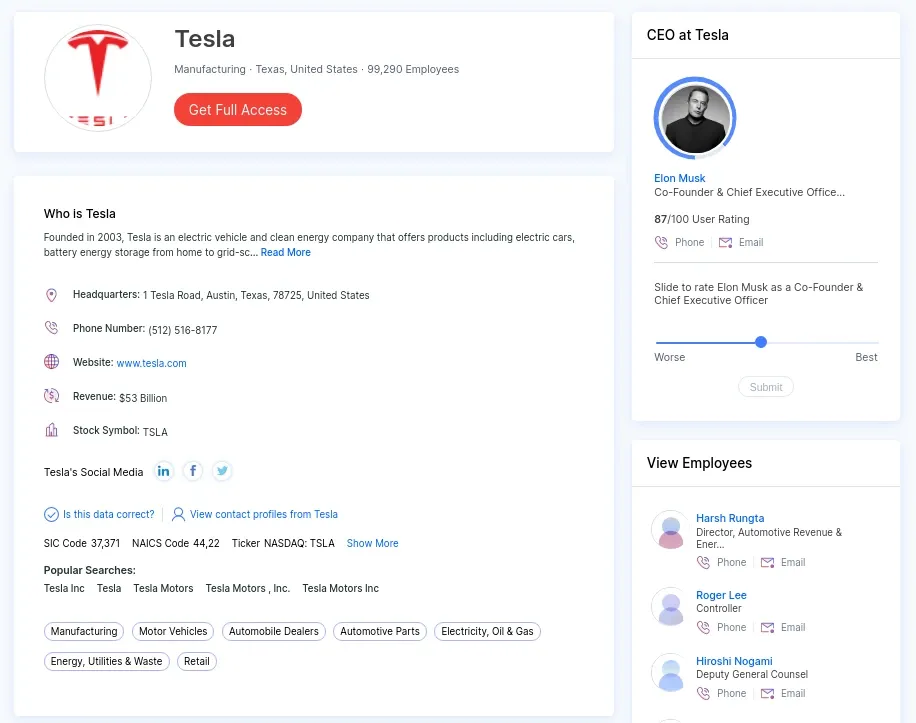
The visible HTML is packed with data, however, instead of parsing it directly we can take a look at the page source of the web page and we can see that the data is embedded as a quoted or raw JSON file:

So, instead of parsing the HTML let's pick up this JSON file directly:
import asyncio
import json
from pathlib import Path
import httpx
from parsel import Selector
def parse_company(selector: Selector):
"""parse Zoominfo company page for company data"""
data = selector.css("script#ng-state::text").get()
data = json.loads(data)["pageData"]
return data
async def scrape_company(url:str, session: httpx.AsyncClient) -> dict:
"""scrape zoominfo company page"""
response = await session.get(url)
assert response.status_code == 200, "request was blocked, see the avoid blocking section for more info"
return parse_company(Selector(text=response.text, base_url=response.url))import asyncio
import json
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
# base config for ScrapFly requests
BASE_CONFIG = {
"asp": True, # avoid Zoominfo scraping blocking
"country": "US" # set the proxy location to US
}
def parse_company(response: ScrapeApiResponse):
"""parse Zoominfo company page for company data"""
data = response.selector.css("script#app-root-state::text").get()
data = selector.css("script#ng-state::text").get()
data = json.loads(data)["pageData"]
return data
async def scrape_company(url: str) -> dict:
"""scrape zoominfo company page"""
response = await scrapfly.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
return parse_company(response)
async def run():
data = await scrape_company(
url="https://www.zoominfo.com/c/tesla-inc/104333869"
)
print(json.dumps(data, indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(run())Run code and example output
async def run():
BASE_HEADERS = {
"accept-language": "en-US,en;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
}
async with httpx.AsyncClient(
limits=httpx.Limits(max_connections=5), timeout=httpx.Timeout(15.0), headers=BASE_HEADERS, http2=True
) as session:
data = await scrape_company("https://www.zoominfo.com/c/tesla-inc/104333869", session=session)
print(json.dumps(data, indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(run()){
"companyId": "104333869",
"url": "www.tesla.com",
"foundingYear": "2003",
"totalFundingAmount": "13763790",
"isPublic": "Public",
"name": "Tesla",
"names": [
"Tesla Inc",
"..."
],
"logo": "https://res.cloudinary.com/zoominfo-com/image/upload/w_70,h_70,c_fit/tesla.com",
"ticker": "NASDAQ: TSLA",
"website": "//www.tesla.com",
"displayLink": "www.tesla.com",
"revenue": "53823001",
"numberOfEmployees": "99290",
"fullName": "Tesla, Inc.",
"companyIds": [
"104333869",
"..."
],
"industries": [
{
"name": "Manufacturing",
"link": "/companies-search/industry-manufacturing",
"primary": true
},
"..."
],
"socialNetworkUrls": [
{
"socialNetworkType": "LINKED_IN",
"socialNetworkUrl": "https://www.linkedin.com/company/tesla-motors/"
},
"..."
],
"address": {
"street": "1 Tesla Road",
"city": "Austin",
"state": "Texas",
"country": "United States",
"zip": "78725"
},
"phone": "(512) 516-8177",
"techUsed": [
{
"id": 92112,
"name": "Microsoft SQL Server Reporting",
"logo": "https://storage.googleapis.com/datanyze-data//technologies/17480e9fd49bbff12f7c482210d0060cf8f97713.png",
"vendorFullName": "Microsoft Corporation",
"vendorDisplayName": "Microsoft",
"vendorId": 24904409
},
"..."
],
"techOwned": [],
"description": "Founded in 2003, Tesla is an electric vehicle and clean energy company that offers products including electric cars, battery energy storage from home to grid-scale, solar panels, solar roof tiles, and other related products and services.",
"competitors": [
{
"id": "407578600",
"name": "NIO",
"employees": 9834,
"revenue": "720117",
"logo": "https://res.cloudinary.com/zoominfo-com/image/upload/w_70,h_70,c_fit/nio.com",
"index": 0
},
"..."
],
"fundings": [
{
"amount": "2000000",
"date": "Feb 13, 2020",
"type": "Stock Issuance/Offering",
"investors": [
"Elon Musk",
"Larry Ellison"
]
},
"..."
],
"acquisitions": [],
"claimed": false,
"sic": [
"37",
"..."
],
"naics": [
"44",
"..."
],
"success": true,
"chartData": {
"chartEmployeeData": [
{
"date": "'21 - Q1",
"value": 45000000
},
"..."
],
"chartRevenueData": [
{
"date": "'21 - Q1",
"value": 24578000000
},
"..."
],
"twitter": [],
"facebook": []
},
"executives": {
"CEO": {
"personId": "3201848920",
"fullName": "Elon Musk",
"title": "Co-Founder & Chief Executive Officer",
"picture": "https://n.com.do/wp-content/uploads/2019/08/elon-musk-neuralink-portrait.jpg",
"personUrl": "/p/Elon-Musk/3201848920",
"orgChartTier": 1
},
"CFO": {
"personId": "3744260195",
"fullName": "Zachary Kirkhorn",
"title": "Master of Coin & Chief Financial Officer",
"picture": "https://img.etimg.com/thumb/msid-80476199,width-1200,height-900,imgsize-287780,overlay-economictimes/photo.jpg",
"personUrl": "/p/Zachary-Kirkhorn/3744260195",
"orgChartTier": 2
}
},
"orgChart": {
"title": "Tesla's Org Chart",
"btnContent": "See Full Org Chart",
"personCardActions": {
"nameAction": "OrgChartContact",
"imageAction": "OrgChartContact",
"emailAction": "OrgChartContactInfo",
"phoneAction": "OrgChartContactInfo"
},
"firstTier": {
"personId": "3201848920",
"fullName": "Elon Musk",
"title": "Co-Founder & Chief Executive Officer",
"picture": "https://n.com.do/wp-content/uploads/2019/08/elon-musk-neuralink-portrait.jpg",
"personUrl": "/p/Elon-Musk/3201848920",
"orgChartTier": 1
},
"secondTier": [
{
"personId": "3744260195",
"fullName": "Zachary Kirkhorn",
"title": "Master of Coin & Chief Financial Officer",
"picture": "https://img.etimg.com/thumb/msid-80476199,width-1200,height-900,imgsize-287780,overlay-economictimes/photo.jpg",
"personUrl": "/p/Zachary-Kirkhorn/3744260195",
"orgChartTier": 2
},
"..."
]
},
"pic": [
{
"personId": "-2033294111",
"fullName": "Emmanuelle Stewart",
"title": "Deputy General Counsel",
"picture": "",
"personUrl": "/p/Emmanuelle-Stewart/-2033294111",
"orgChartTier": 3
},
"..."
],
"ceo": {
"personId": "3201848920",
"fullName": "Elon Musk",
"title": "Co-Founder & Chief Executive Officer",
"picture": "https://n.com.do/wp-content/uploads/2019/08/elon-musk-neuralink-portrait.jpg",
"personUrl": "/p/Elon-Musk/3201848920",
"orgChartTier": 1,
"rating": {
"great": 18,
"good": 1,
"ok": 1,
"bad": 2
},
"company": {
"name": "Tesla",
"id": "104333869",
"country": "US",
"logo": "https://res.cloudinary.com/zoominfo-com/image/upload/w_70,h_70,c_fit/tesla.com",
"fullName": "Tesla, Inc.",
"claimed": false,
"domain": "www.tesla.com",
"numberOfEmployees": "99290",
"industries": [
{
"name": "Manufacturing",
"link": "/companies-search/industry-manufacturing",
"primary": true
},
"..."
],
"address": {
"street": "1 Tesla Road",
"city": "Austin",
"state": "Texas",
"country": "United States",
"zip": "78725"
}
}
},
"newsFeed": [
{
"url": "https://www.inferse.com/152631/tesla-issues-another-over-the-air-recall-on-a-small-number-of-cars-in-the-us-electrek/",
"title": "Tesla issues another over-the-air recall on a small number of cars in the US - Inferse.com",
"content": "March 25 Fred Lambert - Mar. 25th 2022 11:23 am PT",
"date": "2022-07-18T02:09:11Z",
"domain": "www.inferse.com",
"isComparablyNews": false
},
"..."
],
"user": {
"country": "US"
},
"emailPatterns": [
{
"value": "tesla.com",
"rank": 0,
"rawpatternstring": "0:tesla.com:0.61:0.61:0.98:25574",
"sampleemail": "JSmith@tesla.com",
"usagePercentage": 59.8,
"format": "first initials + last"
},
"..."
]
}
🤖 Zoominfo is known for its high blocking rate. If you are blocked, run the ScrapFly code tabs to avoid Zoominfo scraping blocking.
We can see, how incredibly short, efficient and simple our Zoominfo scraper is using this approach!
Now that we know how to scrape a single company's page let's take a look at how to find company page URLs so we can collect all of the public company data from Zoominfo.
Finding Zoominfo Company Pages
Unfortunately, Zoominfo doesn't provide a publicly accessible sitemap directory as many other websites do. So, we either need to explore directories by location/industry or search companies by name. Let's take a look two of these discovery techniques.
How to Scrape Zoominfo Direcotries
Zoominfo.com has public company directory pages for many locations or industry types. However, these directories are limited to 100 results (5 pages) per query. For example, to find "software companies in Los Angeles" we could use this directory page:
zoominfo.com/companies-search/location-usa--california--los-angeles-industry-software
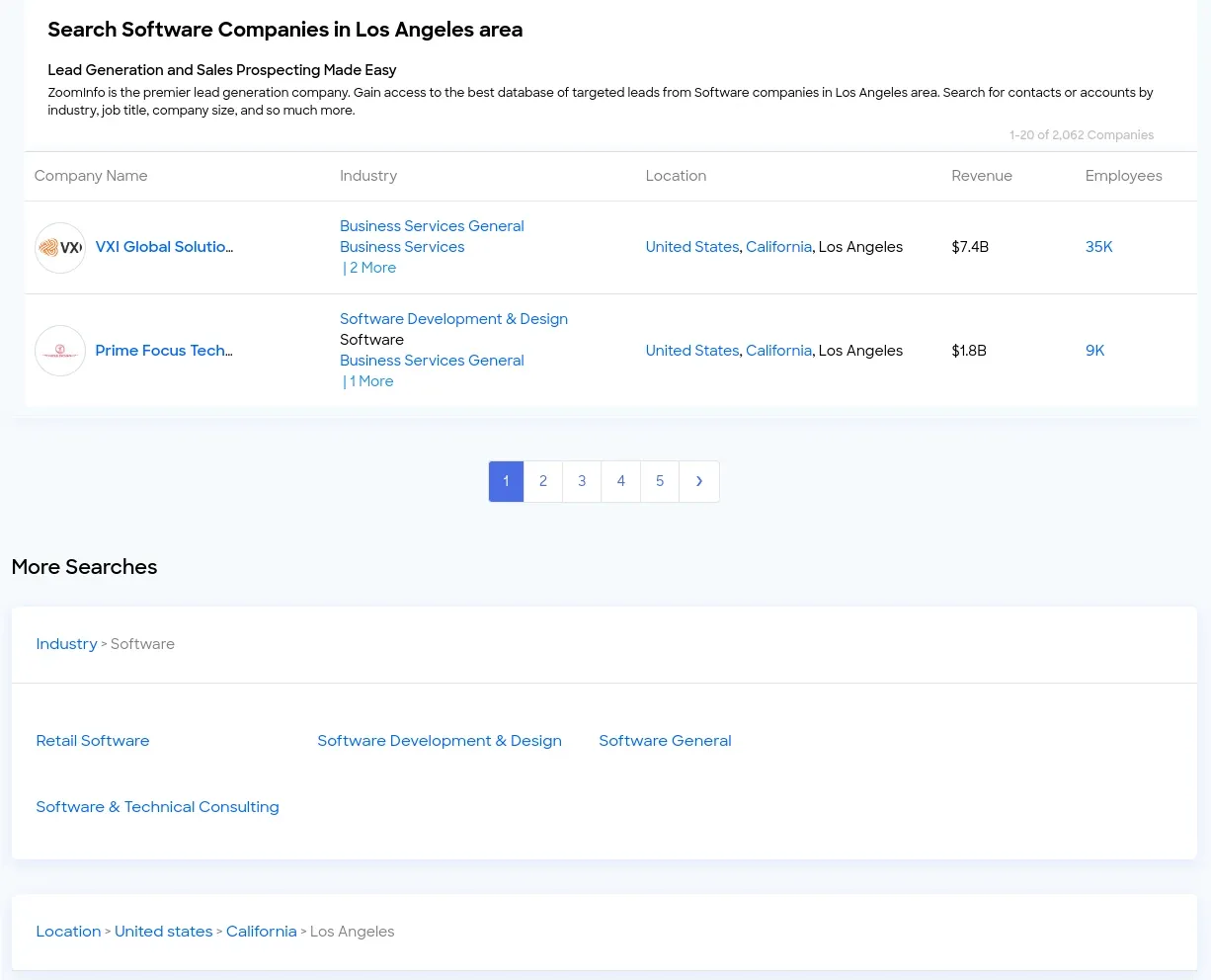
Picking up first 100 results from each directory page can give us a good amount of results and it's an easy scrape:
import httpx
import json
from parsel import Selector
from typing import List
def scrape_directory(url: str, scrape_pagination=True) -> List[str]:
"""Scrape Zoominfo directory page"""
response = httpx.get(url)
assert response.status_code == 200 # check whether we're blocked
# parse first page of the results
selector = Selector(text=response.text, base_url=url)
companies = selector.css("a.company-name.link::attr(href)").getall()
# parse other pages of the results
base_url = "https://www.zoominfo.com/"
if scrape_pagination:
other_pages = selector.css('a.page-link::attr(href)').getall()
for page_url in other_pages:
companies.extend(scrape_directory(base_url + page_url, scrape_pagination=False))
return companies
data = scrape_directory(
url="https://www.zoominfo.com/companies-search/location-usa--california--los-angeles-industry-software"
)
print(json.dumps(data, indent=2, ensure_ascii=False))import json
from typing import List
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
# base config for ScrapFly requests
BASE_CONFIG = {
"asp": True, # avoid Zoominfo scraping blocking
"country": "US" # set the proxy location to US
}
def scrape_directory(url: str, scrape_pagination=True) -> List[str]:
"""Scrape Zoominfo directory page"""
response = scrapfly.scrape(ScrapeConfig(url=url, **BASE_CONFIG))
# parse first page of the results
selector = response.selector
companies = selector.css("a.company-name.link::attr(href)").getall()
# parse other pages of the results
base_url = "https://www.zoominfo.com/"
if scrape_pagination:
other_pages = selector.css("a.page-link::attr(href)").getall()
for page_url in other_pages[:2]:
companies.extend(scrape_directory(base_url + page_url, scrape_pagination=False))
return companies
data = scrape_directory(
url="https://www.zoominfo.com/companies-search/location-usa--california--los-angeles-industry-software"
)
print(json.dumps(data, indent=2, ensure_ascii=False))In our short scraper above, we pick up all 5 pages of our directory page. To extend this, we can employ a crawling technique by exploring related companies in each company we scrape. If we take a look at the dataset we scraped before we can see that each company page contains a list of up to six competing companies:
"competitors": [
{
"id": "407578600",
"name": "NIO",
"employees": 9834,
"revenue": "720117",
"logo": "https://res.cloudinary.com/zoominfo-com/image/upload/w_70,h_70,c_fit/nio.com",
"index": 0
},
"..."
],So, by all companies available in the directories and their competitors we can reach pretty high coverage rates. This approach is generally referred to as crawling. We have a starting point of a single or few URLs by scraping those we acquire more URLs to follow.
Our Zoominfo crawler has a decent discovery coverage by combining these two techniques, even with paging restrictions of 5 pages per directory.

Next, let's add an additional feature to our Zoominfo scraper. We'll scrape FAQ data on company pages.
How to Scrape Zoominfo Company FAQs
Zoominfo also offers a FAQ section on each company page, which includes valuable data about the company found as questions and answers:
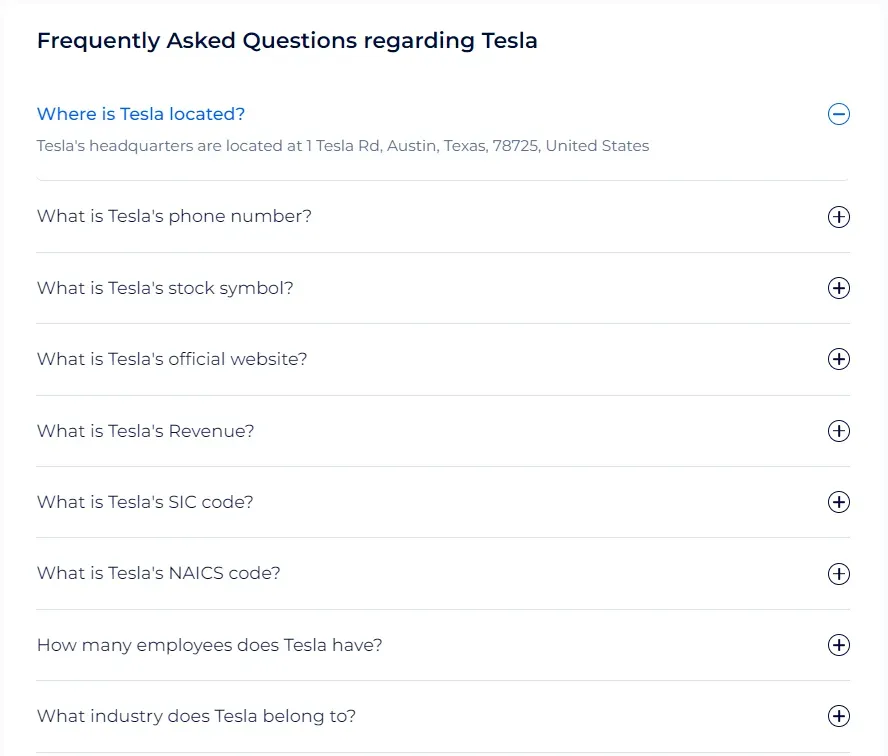
However, this section is found at the bottom of the page, and it requires JavaScript to be fully loaded. Therefore, we'll use Web Scraping with Playwright and Python to scrape this section:
import json
from typing import List, Dict
from parsel import Selector
from playwright.sync_api import sync_playwright
def parse_faqs(html) -> List[Dict]:
"""parse faqs from Zoominfo company pages"""
selector = Selector(html)
faqs = []
for faq in selector.xpath("//div[@class='faqs']/zi-directories-faqs-item"):
question = faq.css("span.question::text").get()
answer = faq.css("span.answer::text").get()
if not answer:
answer = faq.css("span.answer > p::text").get()
faqs.append({
"question": question,
"answer": answer
})
return faqs
def scrape_faqs(url: str) -> List[Dict]:
"""scrape faqs from Zoominfo company pages"""
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# go the page URL
page.goto(url)
# wait for the FAQ section to load
page.wait_for_selector("div.faqs")
# scroll down the page
page.keyboard.down("End")
# get the page HTML
html = page.content()
# parse the FAQs data
faqs = parse_faqs(html)
return faqs
data = scrape_faqs(url="https://www.zoominfo.com/c/tesla-inc/104333869")
print(json.dumps(data, indent=2))import json
from typing import List, Dict
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
# base config for ScrapFly requests
BASE_CONFIG = {
"asp": True, # avoid Zoominfo scraping blocking
"country": "US", # set the proxy location to US
"render_js": True, # faq section requeries JS rendering
"auto_scroll": True, # scroll down the page
"wait_for_selector": "div.faqs" # wait for the FAQs section to load
}
def parse_faqs(response: ScrapeApiResponse) -> List[Dict]:
"""parse faqs from Zoominfo company pages"""
selector = response.selector
faqs = []
for faq in selector.xpath("//div[@class='faqs']/zi-directories-faqs-item"):
question = faq.css("span.question::text").get()
answer = faq.css("span.answer::text").get()
if not answer:
answer = faq.css("span.answer > p::text").get()
faqs.append({
"question": question,
"answer": answer
})
return faqs
def scrape_faqs(url: str) -> List[Dict]:
"""scrape faqs from Zoominfo company pages"""
response = scrapfly.scrape(ScrapeConfig(url=url, **BASE_CONFIG, ))
faqs = parse_faqs(response)
return faqs
data = scrape_faqs(url="https://www.zoominfo.com/c/tesla-inc/104333869")
print(json.dumps(data, indent=2))In the above code, we start by initializing a Playwright instance in the headless mode. Next, we go to the page URL on Zoominfo, scroll down to the bottom of the page and wait for the FAQs section to load. Next, we iterate over the questions and answers to parse their data. Here is the result we got:
Example output
[
{
"question": " Where is Tesla located? ",
"answer": "Tesla's headquarters are located at 1 Tesla Rd, Austin, Texas, 78725, United States"
},
{
"question": " What is Tesla's phone number? ",
"answer": "Tesla's phone number is (512) 516-8177"
},
{
"question": " What is Tesla's stock symbol? ",
"answer": "Tesla's stock symbol is TSLA"
},
{
"question": " What is Tesla's official website? ",
"answer": "Tesla's official website is www.tesla.com"
},
{
"question": " What is Tesla's Revenue? ",
"answer": "Tesla's revenue is $74.9 Billion"
},
{
"question": " What is Tesla's SIC code? ",
"answer": "Tesla's SIC: 75,753"
},
{
"question": " What is Tesla's NAICS code? ",
"answer": "Tesla's NAICS: 22,221"
},
{
"question": " How many employees does Tesla have? ",
"answer": "Tesla has 127,855 employees"
},
{
"question": " What industry does Tesla belong to? ",
"answer": "Tesla is in the industry of: "
},
{
"question": " What is Tesla competition? ",
"answer": "Tesla top competitors include: "
},
{
"question": " What technology does Tesla use? ",
"answer": "Some of the popular technologies that Tesla uses are: Connectifier, OWASP, Bing Universal Event Tracking, Jira Service Desk"
},
{
"question": " Who is the CFO of Tesla? ",
"answer": "Tesla's CFO is "
},
{
"question": " How do I contact Tesla? ",
"answer": "Tesla contact info:\nPhone number: (512) 516-8177\nWebsite: www.tesla.com"
},
{
"question": " What does Tesla do? ",
"answer": "Tesla, Inc. designs, develops, manufactures, and sells electric vehicles and energy storage products in the United States, China, Norway, and internationally. The company operates in two segments, Automotive, and Energy Generation and Storage. It primarily offers sedans and sport utility vehicles. The company also provides electric vehicle powertra... "
},
{
"question": " What are Tesla social media links? ",
"answer": "Tesla "
},
{
"question": " How much funding has Tesla raised to date? ",
"answer": "Tesla has raised $13.8 Billion in 27 funding rounds"
},
{
"question": " When was the last funding round for Tesla? ",
"answer": "Tesla closed its last funding round on Feb 13, 2020 with the amount of $2 Billion"
},
{
"question": " Who invested in Tesla? ",
"answer": "Tesla has 53 investors including Marc Tarpenning, Martin Eberhard, Elon Musk and Elon Musk."
},
{
"question": " Is Tesla a public company? ",
"answer": "Yes, Tesla is a public company and is traded under the symbol TSLA"
}
]With this last feature, our Zoominfo scraper can get the full company details, from financial and managerial information to competitors and FAQs data.
Easy Zoominfo Scraping with Scrapfly
We looked at how to scrape Zoominfo.com. It's known for using multiple anti web scraping technologies, such as How to Bypass Cloudflare When Web Scraping in 2026 to block web scrapers from collecting public data and this is where Scrapfly can help out!

For more, explore web scraping API and its documentation.
For example, we'll be using scrapfly-sdk python package. To start, let's install scrapfly-sdk using pip:
$ pip install scrapfly-sdkTo take advantage of ScrapFly's API in our Zoominfo web scraper all we need to do is change our httpx session code with scrapfly-sdk client requests.
For scraping Zoominfo we'll be using Anti Scraping Protection Bypass feature which can be enabled via asp=True argument.
For example, let's take a look how can we use ScrapFly to scrape a single company page:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key='YOUR_SCRAPFLY_KEY')
result = client.scrape(ScrapeConfig(
url="https://www.zoominfo.com/c/tesla-inc/104333869",
# we need to enable Anti Scraping Protection bypass with a keyword argument:
asp=True,
))FAQ
Is it legal to scrape Zoominfo.com ?
Yes. Data displayed on Zoominfo is publicly available, and we're not extracting anything private. Scraping Zoominfo.com at slow, respectful rates would fall under the ethical scraping definition. That being said, attention should be paid to GDRP compliance in the EU when scraping personal data such as people's data. For more, see our Is Web Scraping Legal? article.
Is there a public API for Zoominfo?
At the time of writing, Zoominfo doesn't offer APIs for public use. However, scraping Zoominfo is straightforward, and you can use it to create your own web scraping API.
Are there alternatives for Zoominfo?
Yes, Crunchbase is another popular website for company data. We have previously covered how to scrape Crunchbase.
Zoominfo Scraping Summary
In this tutorial, we built an Zoominfo.com company data scraper. We've taken a look at how to scrape company pages by extracting embedded state data rather than parsing HTML files. We also took a look at how to find company pages using either Zoominfo directory pages or its search system.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.
For this, we used Python with a few community packages like httpx and to prevent being blocked we used ScrapFly's API which smartly configures every web scraper connection to avoid being blocked. For more on ScrapFly see our documentation and try it out for free!


