

In this article, we'll explore how to scrape trustpilot.com using Python through a step-by-step guide. We'll scrape several data fields, such as company details, rates and reviews. We'll also explain how to bypass Trustpilot web scraping blocking to scrape at scale. Let's get started!
Key Takeaways
Build a Trustpilot scraper using Python to extract business reviews and company data from hidden API endpoints, handling anti-bot measures for comprehensive review analysis.
- Use Trustpilot's hidden API endpoints to access review data and company information without JavaScript rendering
- Parse JSON responses with proper headers to extract structured review and rating information
- Handle Trustpilot's anti-scraping measures with realistic user agents and request spacing
- Extract comprehensive company data including ratings, review counts, and detailed customer feedback
- Implement proper error handling and retry logic for rate limiting and temporary blocking
- Use ScrapFly SDK for automated Trustpilot scraping with anti-blocking features
Latest Trustpilot.com Scraper Code
Why Scrape Trustpilot.com
Trustpilot contains review data for thousands of companies. Scraping this data can help analyze competitors' strengths and weaknesses, evaluate business sentiment which leads to better business decision-making.
Scraping Trustpilot's reviews can also be a good resource for developing Machine Learning models. Companies can analyze reviews through sentiment analysis to gain insights into specific companies or markets as a whole.
Furthermore, manually exploring reviews from websites can be tedious and time-consuming. Therefore, web scraping trustpilot.com can save a lot of manual effort by quickly retrieving thousands of reviews.
Project Setup
To scrape trustpilot.com, we'll use a few Python libraries:
httpxfor sending HTTP requests to the website.parselfor parsing the HTML using XPath and CSS selectors.logurufor logging and monitoring our scraper.scrapfly-sdkfor bypassing trustpilot.com web scraping blocking.asynciofor running our scraping code asynchronously, increasing our web scraping speed.
Since asyncio comes pre-installed in Python, you will only have to install the other libraries using the following pip command:
pip install httpx parsel loguru scrapfly-sdk
How to Scrape Trustpilot.com Search Pages
Let's start our guide by scraping trustpilot.com search pages. Search for any company or go to any companies category on the website, and you will get a page similar to this:
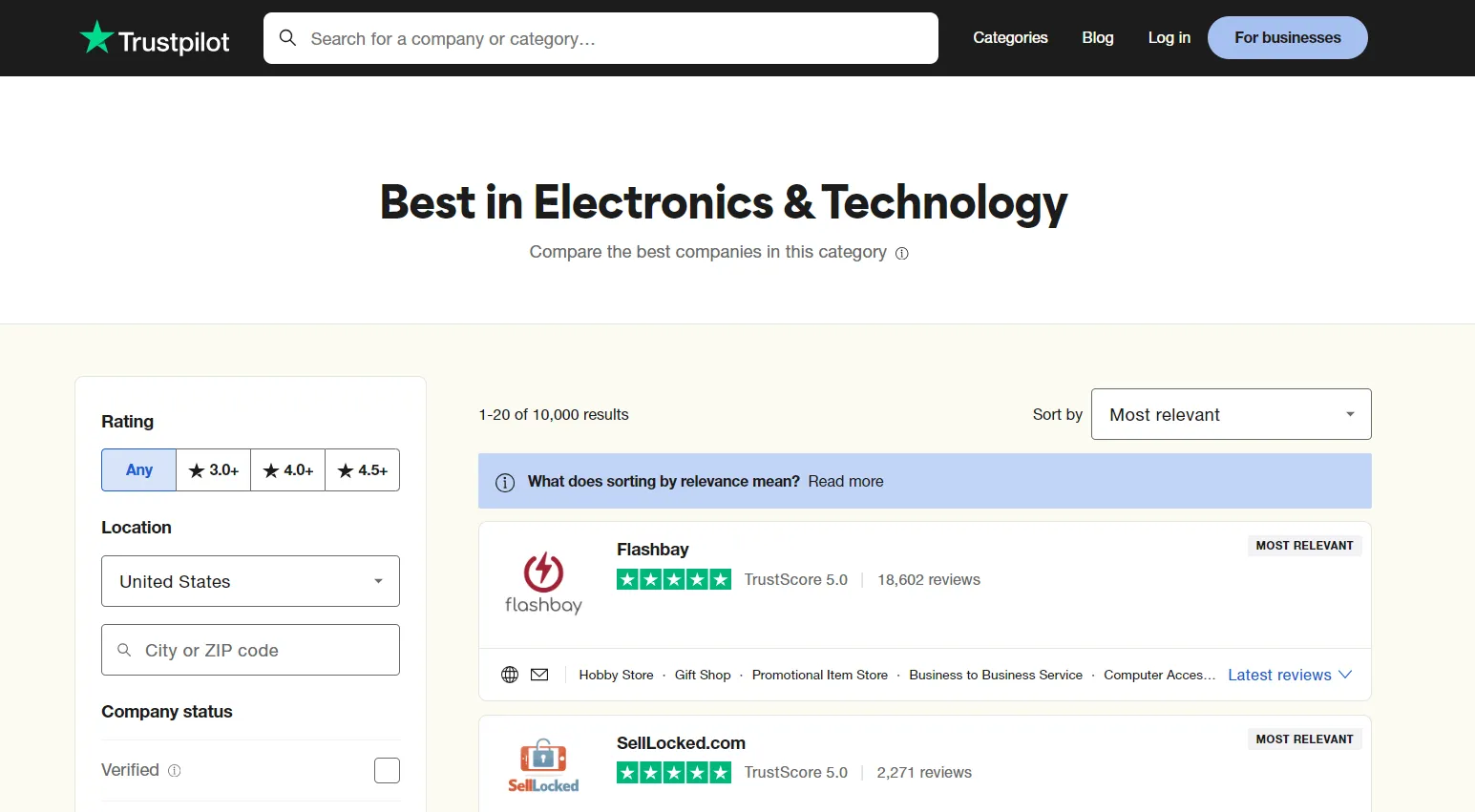
To scrape the search page data, we'll extract all the companies' data directly in JSON from script tags. To view this data, open the browser developer tools by pressing the F12 key and scroll down in the HTML till you find the script tag with the __NEXT_DATA__ id:
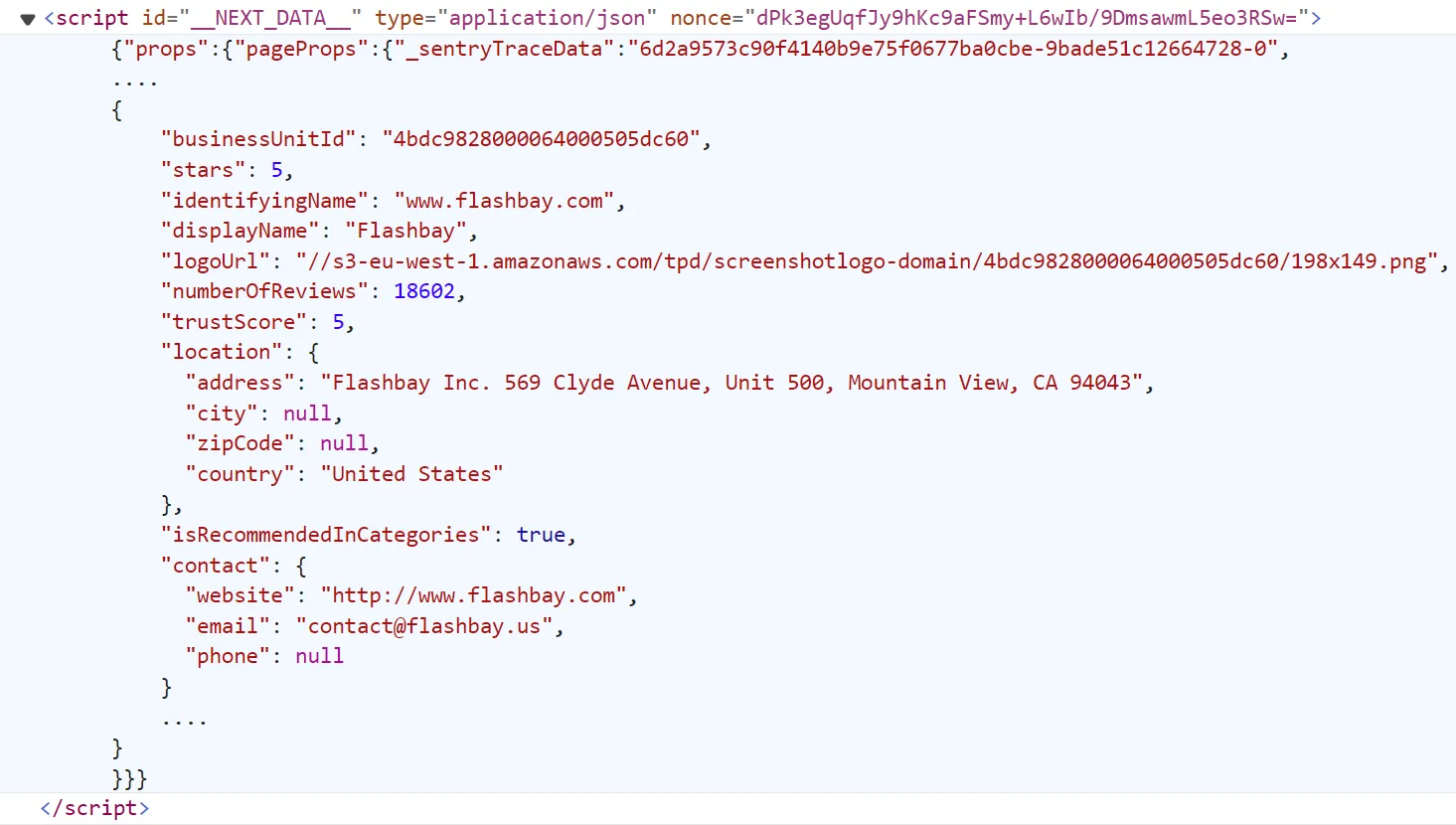
This data is the same on the web page but before getting rendered into the HTML, often known as hidden web data.
To extract this data, we'll select this script tag and parse the inside JSON data. And to crawl over search pages, we'll repeat the same process for the desired number of pagination pages:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initializing a async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"accept-language": "en-US,en;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
},
)
def parse_hidden_data(response: Response) -> Dict:
"""parse JSON data from script tags"""
selector = Selector(response.text)
script = selector.xpath("//script[@id='__NEXT_DATA__']/text()").get()
data = json.loads(script)
return data
async def scrape_search(url: str, max_pages: int = 5) -> List[Dict]:
"""scrape trustpilot search pages"""
# scrape the first search page first
log.info("scraping the first search page")
first_page = await client.get(url)
data = parse_hidden_data(first_page)["props"]["pageProps"]["businessUnits"]
search_data = data["businesses"]
# get the number of pages to scrape
total_pages = data["totalPages"]
if max_pages and max_pages < total_pages:
total_pages = max_pages
log.info(f"scraping search pagination ({total_pages - 1} more pages)")
# add the remaining search pages in a scraping list
other_pages = [
client.get(url + f"?page={page_number}")
for page_number in range(2, total_pages + 1)
]
# scrape the remaining search pages concurrently
for response in asyncio.as_completed(other_pages):
response = await response
assert response.status_code == 200, "request has been blocked"
data = parse_hidden_data(response)["props"]["pageProps"]["businessUnits"][
"businesses"
]
search_data.extend(data)
log.success(f"scraped {len(search_data)} company details from search")
return search_data
import asyncio
import json
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
from typing import Dict, List
from loguru import logger as log
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
# config for ScrapFly requests
BASE_CONFIG = {
# bypass trustpilot web scraping blocking
"asp": True,
# set the poxy location to US
"country": "US",
}
def parse_hidden_data(response: ScrapeApiResponse):
"""parse JSON data from script tags"""
selector = response.selector
script = selector.xpath("//script[@id='__NEXT_DATA__']/text()").get()
data = json.loads(script)
return data
async def scrape_search(url: str, max_pages: int = 5) -> List[Dict]:
"""scrape trustpilot search pages"""
# scrape the first search page first
log.info("scraping the first search page")
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
data = parse_hidden_data(first_page)["props"]["pageProps"]["businessUnits"]
search_data = data["businesses"]
# get the number of pages to scrape
total_pages = data["totalPages"]
if max_pages and max_pages < total_pages:
total_pages = max_pages
log.info(f"scraping search pagination ({total_pages - 1} more pages)")
# add the remaining search pages in a scraping list
other_pages = [
ScrapeConfig(url + f"?page={page_number}", **BASE_CONFIG)
for page_number in range(2, total_pages + 1)
]
# scrape the remaining search pages concurrently
async for response in SCRAPFLY.concurrent_scrape(other_pages):
data = parse_hidden_data(response)["props"]["pageProps"]["businessUnits"][
"businesses"
]
search_data.extend(data)
log.success(f"scraped {len(search_data)} company listings from search")
return search_data
Run the code
async def run():
search_data = await scrape_search(
# search page URL
url="https://www.trustpilot.com/categories/electronics_technology",
# max search pages to scrape
max_pages=3,
)
# save the data into JSON file
with open("search.json", "w", encoding="utf-8") as file:
json.dump(search_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
Let's break down the above code. First, we create an async httpx client with basic HTTP headers that mimic a web browser and define two functions:
parse_hidden_data()for selecting the hidden datascripttag from the HTML.scrape_search()for scraping the search pages by requesting the search page first, then iterating over the remaining search pages and requesting them concurrently.
Here is a sample output of the result we got:
Run the code
[
{
"businessUnitId": "5cf53562e0d5ad0001e78aed",
"stars": 5,
"identifyingName": "bloomaudio.com",
"displayName": "Bloom Audio",
"logoUrl": "//s3-eu-west-1.amazonaws.com/tpd/screenshotlogo-domain/5cf53562e0d5ad0001e78aed/198x149.png",
"numberOfReviews": 1660,
"trustScore": 5,
"location": {
"address": "59 N Lakeview Dr",
"city": "Gibbsboro",
"zipCode": "08026",
"country": "United States"
},
"isRecommendedInCategories": true,
"contact": {
"website": "http://bloomaudio.com",
"email": "hello@bloomaudio.com",
"phone": "8562000681"
},
"categories": [
{
"categoryId": "electronics_store",
"displayName": "Electronics Store",
"isPredicted": false
},
{
"categoryId": "hi-fi_shop",
"displayName": "Hi-fi shop",
"isPredicted": false
}
]
}
]
Our Trustpilot scraper can successfully get company's data from search pages. However, the actual review data can be found on the company profile pages. Let's scrape them!
How to Scrape Trustpilot.com Company Pages
Before we start scraping company pages, let's see how they look and function. Go to any company page and you will get a page similar to this:
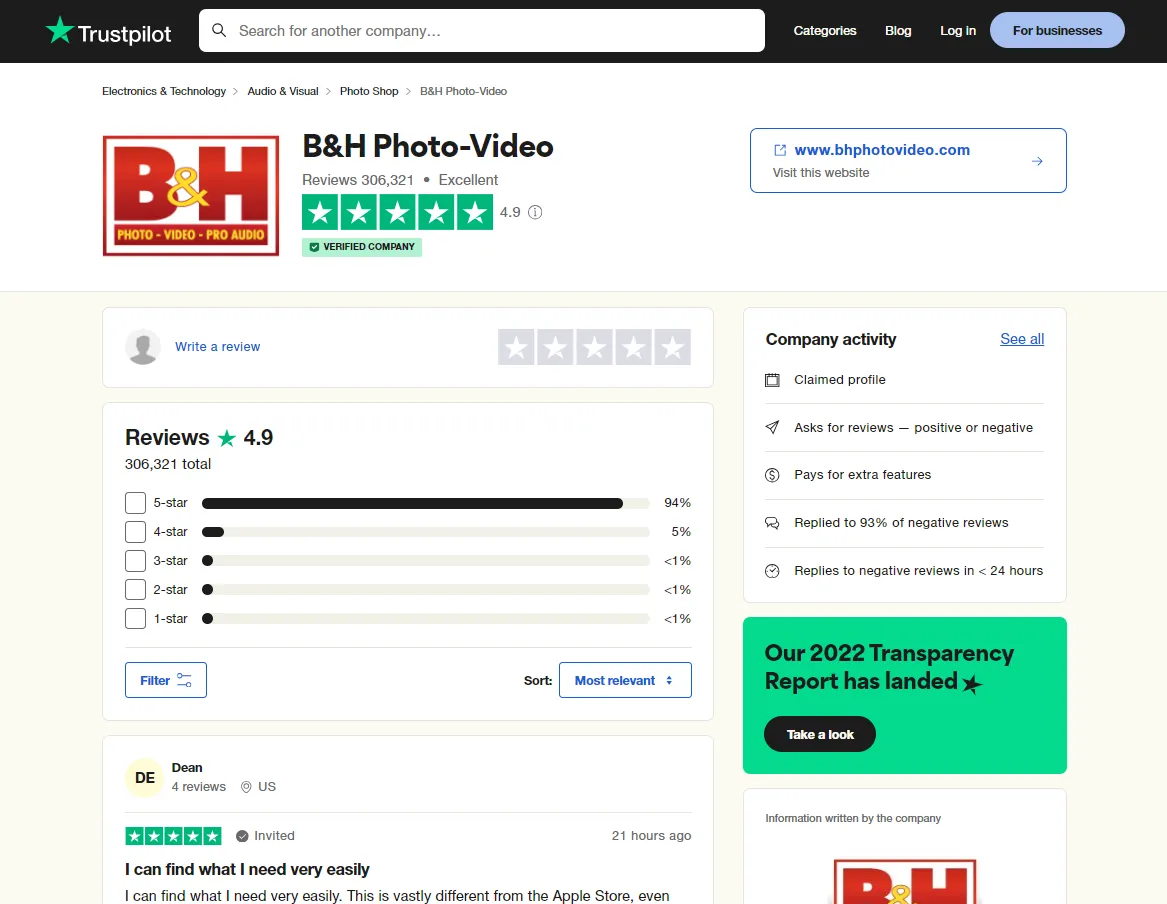
Similar to search pages, company page dataset can be found under script tags hidden in the HTML body:
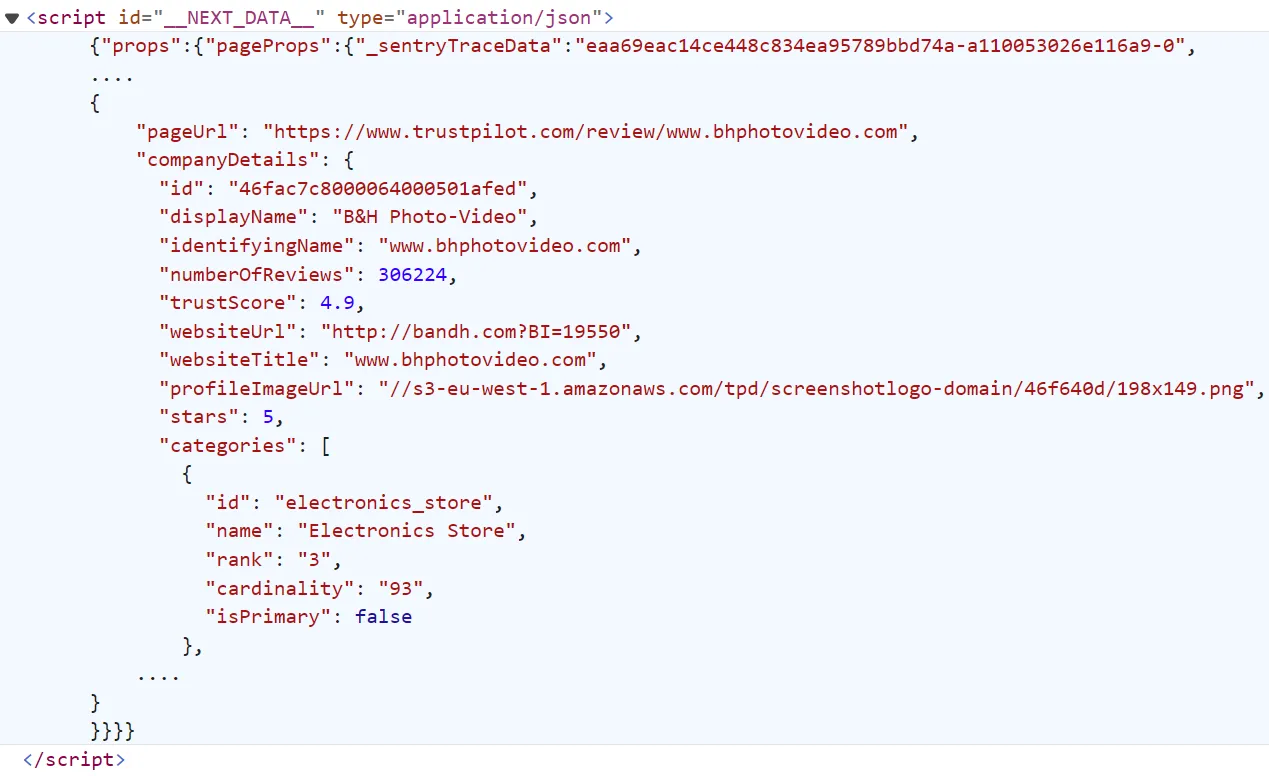
Let's scrape this data by extracting this hidden dataset:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initializing a async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"accept-language": "en-US,en;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
},
)
def parse_hidden_data(response: Response) -> Dict:
"""parse JSON data from script tags"""
selector = Selector(response.text)
script = selector.xpath("//script[@id='__NEXT_DATA__']/text()").get()
data = json.loads(script)
return data
def parse_company_data(data: Dict) -> Dict:
"""parse company data from JSON and execlude the web app details"""
data = data["props"]["pageProps"]
return{
"pageUrl": data["pageUrl"],
"companyDetails": data["businessUnit"],
"reviews": data["reviews"]
}
async def scrape_company(urls: List[str]) -> List[Dict]:
"""scrape trustpilot company pages"""
# add the company pages to a scraping list
to_scrape = [client.get(url) for url in urls]
companies = []
# scrape all the company pages concurrently
for response in asyncio.as_completed(to_scrape):
response = await response
assert response.status_code == 200, "request has been blocked"
data = parse_hidden_data(response)
data = parse_company_data(data)
companies.append(data)
log.success(f"scraped {len(companies)} company listings from company pages")
return companies
import asyncio
import json
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
from typing import Dict, List
from loguru import logger as log
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
# config for ScrapFly requests
BASE_CONFIG = {
# bypass trustpilot web scraping blocking
"asp": True,
# set the poxy location to US
"country": "US",
}
def parse_hidden_data(response: ScrapeApiResponse):
"""parse JSON data from script tags"""
selector = response.selector
script = selector.xpath("//script[@id='__NEXT_DATA__']/text()").get()
data = json.loads(script)
return data
def parse_company_data(data: Dict) -> Dict:
"""parse company data from JSON and execlude the web app details"""
data = data["props"]["pageProps"]
return {
"pageUrl": data["pageUrl"],
"companyDetails": data["businessUnit"],
"reviews": data["reviews"],
}
async def scrape_company(urls: List[str]) -> List[Dict]:
"""scrape trustpilot company pages"""
companies = []
# add the company pages to a scraping list
to_scrape = [ScrapeConfig(url, **BASE_CONFIG) for url in urls]
# scrape all the company pages concurrently
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
data = parse_hidden_data(response)
data = parse_company_data(data)
companies.append(data)
log.success(f"scraped {len(companies)} company listings from company pages")
return companies
Run the code
async def run():
companies_data = await scrape_company(
# company page URLs
urls = [
"https://www.trustpilot.com/review/www.bhphotovideo.com",
"https://www.trustpilot.com/review/www.flashbay.com",
"https://www.trustpilot.com/review/iggm.com",
]
)
# save the data into a JSON file
with open("companies.json", "w", encoding="utf-8") as file:
json.dump(companies_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
Here, we use the same code we used earlier and define two additional functions:
parse_company_data()for selecting the actual company data and excluding any data related to the website itself.scrape_company()for scraping the company pages by adding the page URLs to a scraping list and scraping them concurrently.
Here is a sample output of the result we got:
Sample output
[
{
"pageUrl": "https://www.trustpilot.com/review/iggm.com",
"companyDetails": {
"id": "5daac6198b173d0001fbdd53",
"displayName": "IGGM",
"identifyingName": "iggm.com",
"numberOfReviews": 27721,
"trustScore": 4.9,
"websiteUrl": "https://www.iggm.com/",
"websiteTitle": "iggm.com",
"profileImageUrl": "//s3-eu-west-1.amazonaws.com/tpd/logos/5daac6198b173d0001fbdd53/0x0.png",
"stars": 5,
"categories": [
{
"id": "internet_shop",
"name": "Internet Shop",
"rank": "1",
"cardinality": "12",
"isPrimary": false
},
{
"id": "video_game_store",
"name": "Video Game Store",
"rank": "2",
"cardinality": "39",
"isPrimary": false
},
{
"id": "gaming_service_provider",
"name": "Gaming service Provider",
"rank": "4",
"cardinality": "78",
"isPrimary": true
},
{
"id": "computer_accessories_store",
"name": "Computer Accessories Store",
"rank": "3",
"cardinality": "70",
"isPrimary": false
},
{
"id": "game_store",
"name": "Game Store",
"rank": "3",
"cardinality": "41",
"isPrimary": false
}
],
"breadcrumb": {
"topLevelId": "events_entertainment",
"topLevelDisplayName": "Events & Entertainment",
"midLevelId": "gaming",
"midLevelDisplayName": "Gaming",
"bottomLevelId": "gaming_service_provider",
"bottomLevelDisplayName": "Gaming service Provider"
},
"isClaimed": true,
"isClosed": false,
"isTemporarilyClosed": false,
"locationsCount": 0,
"isCollectingReviews": true,
"verification": {
"verifiedByGoogle": false,
"verifiedBusiness": false,
"verifiedPaymentMethod": true,
"verifiedUserIdentity": false
},
"hasCollectedIncentivisedReviews": false,
"consumerAlert": null,
"isMerged": false,
"contactInfo": {
"email": "support@iggm.com",
"address": "",
"city": "",
"country": "US",
"phone": "",
"zipCode": ""
},
"activity": {
"isUsingPaidFeatures": true,
"hasSubscription": true,
"isAskingForReviews": true,
"claimedDate": "2019-10-19T08:17:02.000Z",
"isClaimed": true,
"previouslyClaimed": true,
"replyBehavior": {
"averageDaysToReply": 0.36,
"lastReplyToNegativeReview": "2023-12-06 03:20:02 UTC",
"negativeReviewsWithRepliesCount": 169,
"replyPercentage": 99.41176470588235,
"totalNegativeReviewsCount": 170
},
"verification": {
"verifiedByGoogle": false,
"verifiedBusiness": false,
"verifiedPaymentMethod": true,
"verifiedUserIdentity": false
},
"hasBusinessUnitMergeHistory": false,
"basiclinkRate": 36,
"hideBasicLinkAlert": false
}
},
"reviews": [
{
"id": "657186ba9722066aa0570362",
"filtered": false,
"pending": false,
"text": "Other than a delayed delivery 2hours wait - had to log out and Got the morning after - it was a good experience. Quick reply on hotline. \n\nIf You accidently cancel order with Products in basket You Will get an e-mail which was confusing because i completed another purchase.",
"rating": 4,
"labels": {
"merged": null,
"verification": {
"isVerified": true,
"createdDateTime": "2023-12-07T10:47:54.000Z",
"reviewSourceName": "AFSv2",
"verificationSource": "invitation",
"verificationLevel": "verified",
"hasDachExclusion": false
}
},
"title": "Trustworthy",
"likes": 0,
"dates": {
"experiencedDate": "2023-12-07T00:00:00.000Z",
"publishedDate": "2023-12-07T10:47:54.000Z",
"updatedDate": null
},
"report": null,
"hasUnhandledReports": false,
"consumer": {
"id": "51afadbd00006400013e95a4",
"displayName": "Jens",
"imageUrl": "",
"numberOfReviews": 16,
"countryCode": "DK",
"hasImage": false,
"isVerified": false
},
"reply": null,
"consumersReviewCountOnSameDomain": 1,
"consumersReviewCountOnSameLocation": null,
"productReviews": [],
"language": "en",
"location": null
},
....
]
}
]
Our Trustpilot scraper got the company details alongside some review data. However, this is only the first review page. So for our next task - let's explore how we can scrape more reviews!
Scraping Trustpilot.com Reviews
To scrape the company reviews, we'll use the Trustpilot private API to get the data directly in JSON.

To view this API, follow the steps below:
- Open the browser developer tools by pressing the
F12key. - Head over to the
Networkand filter byFetch/XHRrequests. - Load more reviews by clicking on the next reviews page.
By following these steps, you will find the API responsible for fetching the new reviews:
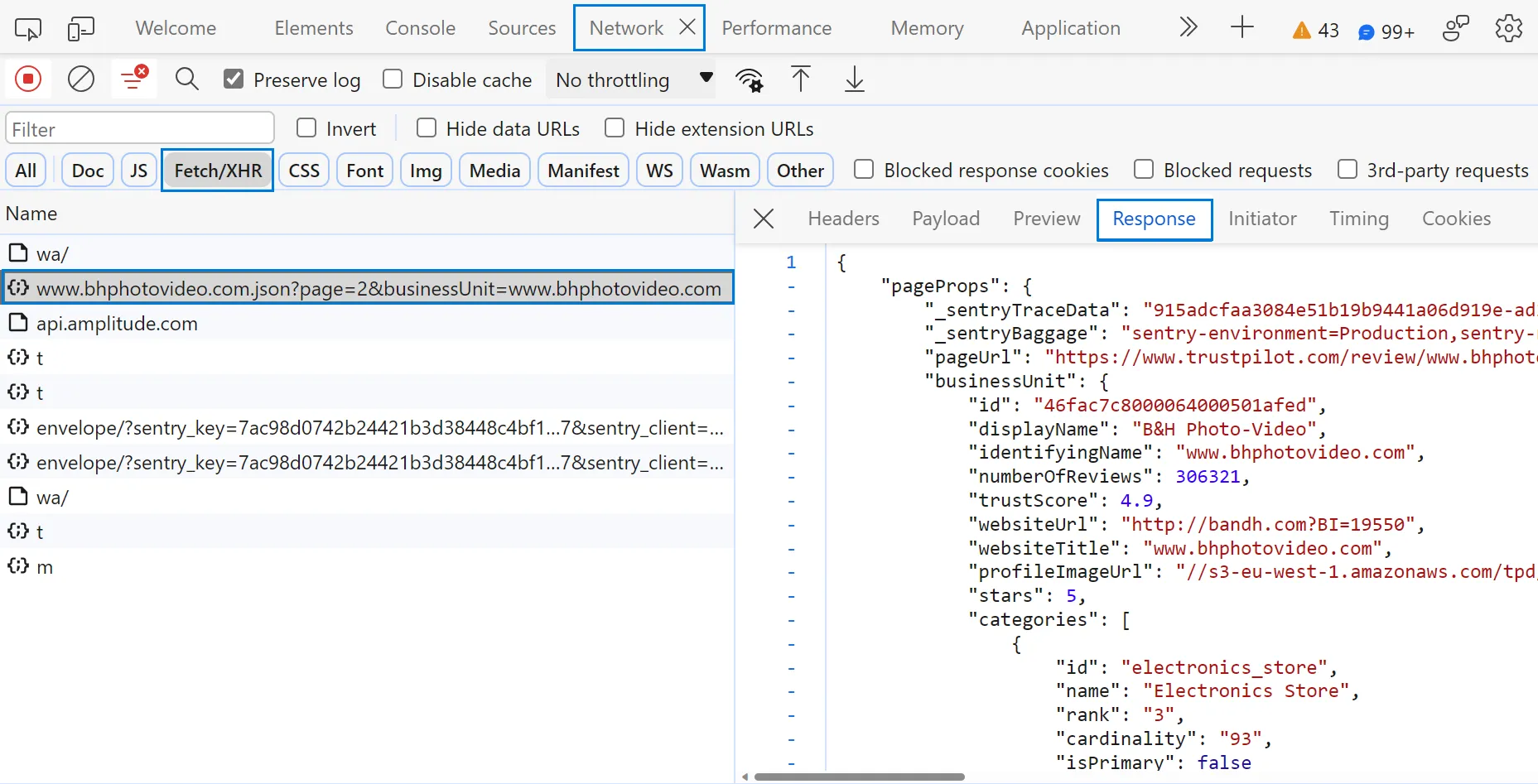
As we can see, this API supports pagination for loading more reviews. It also supports filtering, as the reviews filters on the web page get applied to the API too. So, let's web scrape trustpilot.com reviews by requesting this API:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient
from parsel import Selector
from loguru import logger as log
# initializing a async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"accept-language": "en-US,en;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
},
)
async def get_reviews_api_url(url: str) -> str:
"""scrape the API version from the HTML and create the reviews API"""
response = await client.get(url)
selector = Selector(response.text)
buildId = json.loads(selector.xpath("//script[@id='__NEXT_DATA__']/text()").get())["buildId"]
business_unit = url.split("review/")[-1]
return f"https://www.trustpilot.com/_next/data/{buildId}/review/{business_unit}.json?sort=recency&businessUnit={business_unit}"
async def scrape_reviews(url: str, max_pages: int = 5) -> List[Dict]:
"""parse review data from the API"""
# create the reviews API url
log.info(f"getting the reviews API for the URL {url}")
api_url = await get_reviews_api_url(url)
# send a POST request to the first review page and get the result directly in JSON
log.info("scraping the first review page")
first_page = await client.post(api_url)
data = json.loads(first_page.text)["pageProps"]
reviews_data = data["reviews"]
# get the number of review pages to scrape
total_pages = data["filters"]["pagination"]["totalPages"]
if max_pages and max_pages < total_pages:
total_pages = max_pages
log.info(f"scraping reviews pagination ({total_pages - 1} more pages)")
# add the remaining search pages in a scraping list
other_pages = [client.post(api_url + f"&page={page_number}") for page_number in range(2, total_pages + 1)]
# scrape the remaining search pages concurrently
for response in asyncio.as_completed(other_pages):
response = await response
assert response.status_code == 200, "request has been blocked"
data = json.loads(response.text)["pageProps"]["reviews"]
reviews_data.extend(data)
log.success(f"scraped {len(reviews_data)} company reviews")
return reviews_data
import asyncio
import json
from scrapfly import ScrapeConfig, ScrapflyClient
from typing import Dict, List
from loguru import logger as log
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass trustpilot web scraping blocking
"asp": True,
# set the poxy location to US
"country": "US",
}
async def get_reviews_api_url(url: str) -> str:
"""scrape the API version from the HTML and create the reviews API"""
response = await SCRAPFLY.async_scrape(
ScrapeConfig(url, **BASE_CONFIG)
)
buildId = json.loads(response.selector.xpath("//script[@id='__NEXT_DATA__']/text()").get())["buildId"]
business_unit = url.split("review/")[-1]
return f"https://www.trustpilot.com/_next/data/{buildId}/review/{business_unit}.json?sort=recency&businessUnit={business_unit}"
async def scrape_reviews(url: str, max_pages: int = 5) -> List[Dict]:
"""parse review data from the API"""
# create the reviews API url
log.info(f"getting the reviews API for the URL {url}")
api_url = await get_reviews_api_url(url)
log.info("scraping the first review page")
# send a POST request to the first review page and get the result directly in JSON
first_page = await SCRAPFLY.async_scrape(
ScrapeConfig(api_url, method="POST", **BASE_CONFIG)
)
data = json.loads(first_page.scrape_result["content"])["pageProps"]
reviews_data = data["reviews"]
# get the number of review pages to scrape
total_pages = data["filters"]["pagination"]["totalPages"]
if max_pages and max_pages < total_pages:
total_pages = max_pages
log.info(f"scraping reviews pagination ({total_pages - 1} more pages)")
# add the remaining search pages in a scraping list
other_pages = [
ScrapeConfig(api_url + f"&page={page_number}", method="POST", **BASE_CONFIG)
for page_number in range(2, total_pages + 1)
]
# scrape the remaining search pages concurrently
async for response in SCRAPFLY.concurrent_scrape(other_pages):
data = json.loads(response.scrape_result["content"])["pageProps"]["reviews"]
reviews_data.extend(data)
log.success(f"scraped {len(reviews_data)} company reviews")
return reviews_data
Run the code
async def run():
reviews_data = await scrape_reviews(
url="https://www.trustpilot.com/review/www.bhphotovideo.com",
# max pages of reviews, each page contains 20 reviews
max_pages=3
)
# save the data into a JSON file
with open("reviews.json", "w", encoding="utf-8") as file:
json.dump(reviews_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())
The above code is fairly straightforward. We only send a POST request to the reviews API, parse the JSON response to extract only the actual review data and repeat the same process for the desired review pages.
Here is a sample of the result we got:
Sample output
[
{
"id": "6572b76637ebeb8c76d42271",
"filtered": false,
"pending": false,
"text": "Easy to order and everything clear",
"rating": 5,
"labels": {
"merged": null,
"verification": {
"isVerified": true,
"createdDateTime": "2023-12-08T08:27:51.000Z",
"reviewSourceName": "InvitationLinkApi",
"verificationSource": "invitation",
"verificationLevel": "invited",
"hasDachExclusion": false
}
},
"title": "Easy to order and everything clear",
"likes": 0,
"dates": {
"experiencedDate": "2023-12-08T00:00:00.000Z",
"publishedDate": "2023-12-08T08:27:51.000Z",
"updatedDate": null
},
"report": null,
"hasUnhandledReports": false,
"consumer": {
"id": "64eb2060c235c30012c9c1c9",
"displayName": "Moushir Rizk",
"imageUrl": "",
"numberOfReviews": 2,
"countryCode": "AE",
"hasImage": false,
"isVerified": false
},
"reply": null,
"consumersReviewCountOnSameDomain": 1,
"consumersReviewCountOnSameLocation": null,
"productReviews": [],
"language": "en",
"location": null
}
]
Cool! We built a Trustpilot scraper with a few lines of python code to scrape search, company and review pages. However, our scraper is likely to get blocked once we scale up. Let's look at a solution!
Avoid Trustpilot.com Web Scraping Blocking
To scrape without getting blocked, we should pay attention to various details. Including IP addresses, TLS handshakes, cookies and headers. This can be tough and this is where Scrapfly can lend a hand!

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
For example, to bypass Trustpilot scraping blocking, we'll only have to replace our httpx client with the ScrapFly client:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some trustpilot.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="some trustpilot.com URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript(like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']
FAQ
To wrap up this guide on web scraping trustpilot.com, let's look at some frequently asked questions.
Is it legal to scrape trustpilot.com?
Yes, all the data on trustpilot.com is publicly available and scraping it at a reasonable rate is perfectly legal and ethical. However, attention should be paid to GDPR compliance in the EU countries where there are limitations, such as commercializing personal data. For more details, see our previous guide - is web scraping legal?
Is there a public API for trustpilot.com?
Currently, there's no Trustpilot API available publicly. However, Trustpilot can be easily scraped using Python and hidden APIs as described in this guide.
Are there alternatives for trustpilot.com?
Yes, Yellowpages and Yelp are other popular websites for business reviews. We have covered how to scrape Yellowpages and Yelp in previous articles.
Web Scraping Trustpilot.com - Summary
In this guide, we explained how to scrape trustpilot.com - a popular website for business reviews.
We went through a step-by-step guide on creating a Trustpilot scraper to scrape company details and review data from search and company pages. We have seen that we can use the trustpilot.com private API to scrape review data without HTML parsing. Furthermore, we explained how to avoid trustpilot.com scraping blocking using ScrapFly.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.




