

Ever wondered why your TikTok scraper gets blocked after just a few requests, even when you're only accessing public data? You successfully scrape a few profiles then suddenly, you're hit with 403 errors or CAPTCHAs, while your regular browser can still navigate TikTok just fine.
TikTok now employs some of the most advanced anti-scraping measures in social media, combining encrypted headers, behavioral detection, and real-time fraud scoring to permanently target bots and automated scripts.
In this guide, you'll learn how TikTok blocks scrapers and how ScrapFly's tools bypass those blocks, with step-by-step Python code for scraping profiles, channels, comments, post and search data.
Let's break through TikTok's walls safely, efficiently, and at scale.
Quick Start
For developers seeking immediate implementation, ScrapFly provides a production-ready TikTok scraper available via GitHub:
git clone https://github.com/scrapfly/scrapfly-scrapers.git
cd scrapfly-scrapers/tiktok-scraperWhy Scrape TikTok?
TikTok data offers unique insights that power data-driven marketing and social intelligence. By understanding and leveraging this data, organizations can refine their strategies, stay ahead of trends, and make more informed business decisions.
With effective access to TikTok data, you can:
Influencer Marketing: Find the right micro-influencers, study their audience demographics, and track competitor growth to identify collaboration opportunities.
Content Strategy: Uncover trending topics, measure hashtag performance, and monitor the characteristics of viral content to guide your creative direction.
Brand Monitoring: Keep track of brand mentions, assess campaign impact, and analyze audience sentiment to strengthen brand reputation.
Market Research: Explore trending content, identify rising creators, and gain insights into TikTok’s fast-changing platform dynamics.
While much of TikTok’s data is publicly visible, it’s also heavily guarded. The real challenge isn’t finding the data, it’s collecting it at scale without triggering detection systems. In the next section, we’ll examine the main defenses that make large-scale TikTok scraping difficult.
Why TikTok Scraping Fails Without Proper Tools
TikTok employs advanced security systems to prevent automated scraping of its publicly visible data. The platform actively monitors traffic patterns and enforces layers of defenses that make large-scale data collection challenging without the right infrastructure.
Similar to other major social platforms, TikTok combines behavioral analysis, device fingerprinting, and request validation to detect and block scraping attempts. Each incoming request is evaluated based on its IP reputation, browser behavior, and session consistency to determine whether it comes from a real user or an automated process.
Understanding these mechanisms is key before implementing any large-scale data extraction strategy. Below are TikTok’s primary defenses that often cause scrapers to fail.
1. Authentication and Rate Limits
TikTok allows casual browsing of profiles and videos without an account, but this access is tightly rate-limited. After a few requests, anonymous visitors often encounter “Rate Limit Exceeded” or “Access Denied” errors.
In some regions or content types such as user comments, likes, or analytics, TikTok enforces authentication requirements. Attempting to scrape this data without proper handling of cookies or session tokens can quickly result in blocked requests or incomplete data retrieval.
Scraping while logged in is technically possible but risky. TikTok accounts can be flagged or permanently banned if unusual traffic patterns are detected, such as rapid page requests or non-human navigation behavior.
2. Behavioral Detection
TikTok continuously analyzes visitor behavior to identify automation. Genuine users browse unpredictably scrolling through videos, watching content for varying durations, and interacting through likes or comments.
Behavioral detection systems evaluate:
- Request timing: Bots send requests too quickly or too consistently.
- Navigation patterns: Humans scroll, click, and pause; scrapers jump directly to URLs.
- Engagement signals: Lack of mouse movement, media playback, or interaction events raises red flags.
Without realistic human-like browsing patterns, scraping sessions will be detected and blocked within minutes.
3. Request Fingerprinting
Beyond behavior, TikTok inspects the technical fingerprint of every request. These low-level signals are nearly impossible to fake with simple HTTP scripts.
Key fingerprinting checks include:
- IP reputation: TikTok identifies datacenter and proxy IPs commonly used for scraping. Residential or mobile IPs are considered more trustworthy.
- TLS fingerprints: During the HTTPS handshake, each client produces a unique cryptographic signature. TikTok compares these against known browser fingerprints to spot automation tools.
- Headers and cookies: Requests missing realistic browser headers or valid cookie chains are quickly flagged.
- Device characteristics: TikTok checks user-agent metadata, operating system versions, and browser capabilities to confirm authenticity.
By combining these factors, TikTok builds a “trust profile” for each session. Once that profile deviates from normal human behavior, access is restricted or blocked entirely.
How TikTok Data is Loaded and How to Scrape it?
TikTok is a single-page application that delivers most content via a small set of backend endpoints and client-side rendering. Our TikTok scraper combines several techniques to collect data reliably.
Below we will briefly explain each approach, show what happens under the hood, demonstrate how to inspect the traffic and payloads in your browser’s developer tools, and provide practical code examples for extracting the data.
Rendering an HTML Template
This is the simplest and most traditional way a website delivers content. In this method, the server sends a complete HTML page that already includes all the data a user needs to see. When your browser opens the page, it simply renders that pre-built HTML without requiring additional background requests.
While TikTok primarily relies on dynamic rendering, some public pages like basic profile overviews or fallback pages still contain structured HTML data. This makes it possible to scrape certain elements directly without running JavaScript.
To extract data from pages like these on TikTok, the process is straightforward:
- Send a request to the TikTok page URL and wait for the full HTML response.
- Read the response body, which includes the pre-rendered HTML structure.
- Parse the HTML and extract key information using CSS selectors, XPath, or an HTML parsing library like BeautifulSoup.
This approach is efficient because the data is already embedded in the HTML, requiring no JavaScript execution or network inspection.
Hydrating the Page Using Script Tags
Many modern websites, including TikTok, embed structured data inside <script> tags rather than directly rendering it into the HTML. This approach is common in applications that rely on server-side or client-side rendering to improve loading speed and user experience.
When you open a TikTok profile or video page, the HTML often includes one or more <script> tags that store JSON data representing the page’s content such as user details, video metadata, or engagement statistics. The browser later uses this JSON to “hydrate” the page and display it dynamically.
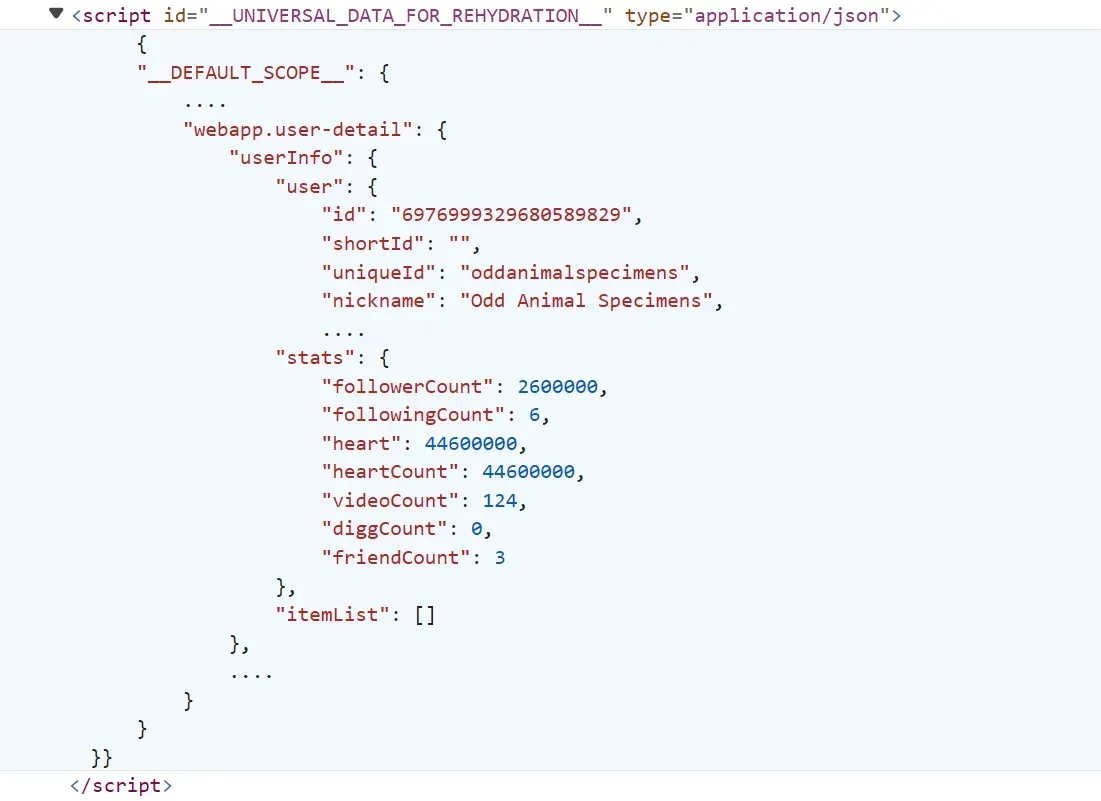
To extract TikTok data from these pages, you can follow this process:
- Request the page URL and retrieve the full HTML response.
- Parse the HTML and locate the
<script>tag that holds the embedded JSON. - Extract and decode that JSON data into a structured object for analysis or storage.
This method is known as hidden data scraping because the valuable data is concealed inside script tags that typical scrapers overlook. It’s a lightweight and reliable technique for accessing TikTok data without needing full browser automation.
Loading Data from XHR Calls
Modern web applications, including TikTok, don’t load all their data at once. Instead, they use background requests commonly known as XHR calls or fetch requests to retrieve additional content as the user interacts with the page.
For example, when you open a TikTok profile, the page first loads its basic layout, then quietly sends several XHR requests to fetch the user’s videos, stats, and recommendations in JSON format. Once the responses arrive, the browser dynamically updates the page to display the new content.
To collect this type of data, follow these steps:
- Start a headless browser such as Playwright or Puppeteer.
- Open the TikTok page and monitor its network activity.
- Wait for or trigger the XHR requests that fetch the data.
- Capture and inspect the JSON responses from the browser’s network logs.
These XHR requests are often referred to as hidden APIs because they operate silently in the background.
ScrapFly's Solution
We know that managing TikTok scraping can be a real overhead. That's why we've built ScrapFly's TikTok-scraper an open source tool ready to use! It's configured to leverage ScrapFly's web scraping API, which manages:

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input, and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
Learn more about ScrapFly's anti-bot capabilities on our Web Scraping API page.
For pricing details, visit our pricing page.
What TikTok Data Can You Scrape?
Web scraping is about collecting raw web data, avoiding detection, and transforming it into structured, ready-to-use datasets. Our TikTok-scraper automates this entire process from fetching and rendering pages to parsing and cleaning the results and outputs clean JSON data you can use immediately.
With ScrapFly, you can extract a wide range of TikTok data, including:
- Profiles: Username, follower and following counts, bio, interests, demographics, verification status, and profile picture URLs.
- Posts: Video URLs, captions, hashtags, sound metadata, view counts, likes, shares, and upload timestamps.
- Comments: Comment text, posting time, likes, replies, and user information.
- Search results: Trending videos, hashtag analytics, user discovery results, and content relevance metrics.
- Channels: Topic-based or brand-focused feeds that group related videos, often used for trend tracking and audience analysis.
Scraping TikTok data with ScrapFly is both efficient and reliable. Here’s an example in Python:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR_API_KEY")
result = client.scrape(ScrapeConfig(
"https://tiktok.com/@username",
asp=True, # Enable anti-scraping protection
render_js=True, # Handle dynamic content
country="US"
))This setup takes care of the complex parts such as JavaScript rendering, location targeting, and anti-bot protection, so you can focus on analyzing the data instead of fighting detection systems.
TikTok Scraping Code Examples
So far, we have covered all the essential details needed to scrape TikTok data. Now it is time to move on to some practical examples. In the following sections, we will show ready-to-use Python code snippets for extracting data from different parts of TikTok.
These examples use ScrapFly's Python SDK, which takes care of all the complex parts for you. If you prefer using libraries like HTTPX or requests directly, you will need to manage proxy rotation, fingerprint randomization, and session handling on your own.
To follow along with the examples, install the ScrapFly SDK with this command:
$ pip install scrapfly-sdkScraping TikTok Profile Data
Let's start building the first parts of our TikTok scraper by scraping profile pages. Profile pages can include two types of data:
- Main profile data, such as the name, ID followers and likes count.
- Channel data, if the profile has any posts. It includes data about each video, such as the name, description and view statistics.
Let's begin by scraping the profile data, which can be found under JavaScript script tags. To view this tag, follow the below steps:
- Go to any profile page on TikTok.
- Open the browser developer tools by pressing the
F12key. - Look for the
scripttag that starts with the `UNIVERSAL_DATA`__ ID.
The identified tag contains a comprehensive JSON dataset about the web app, browser and localization details. However, the profile data can be found under the webapp.user-detail key:
The above data is commonly referred to as hidden web data. It's the same data on the page but before getting rendered into the HTML.

So, to scrape the profile data, we'll request the TikTok profile page, select the script tag with the data and parse it:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def parse_profile(response: Response):
"""parse profile data from hidden scripts on the HTML"""
assert response.status_code == 200, "request is blocked, use the ScrapFly codetabs"
selector = Selector(response.text)
data = selector.xpath("//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()").get()
profile_data = json.loads(data)["__DEFAULT_SCOPE__"]["webapp.user-detail"]["userInfo"]
return profile_data
async def scrape_profiles(urls: List[str]) -> List[Dict]:
"""scrape tiktok profiles data from their URLs"""
to_scrape = [client.get(url) for url in urls]
data = []
# scrape the URLs concurrently
for response in asyncio.as_completed(to_scrape):
response = await response
profile_data = parse_profile(response)
data.append(profile_data)
log.success(f"scraped {len(data)} profiles from profile pages")
return dataimport asyncio
import json
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_profile(response: ScrapeApiResponse):
"""parse profile data from hidden scripts on the HTML"""
selector = response.selector
data = selector.xpath("//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()").get()
profile_data = json.loads(data)["__DEFAULT_SCOPE__"]["webapp.user-detail"]["userInfo"]
return profile_data
async def scrape_profiles(urls: List[str]) -> List[Dict]:
"""scrape tiktok profiles data from their URLs"""
to_scrape = [ScrapeConfig(url, asp=True, country="US") for url in urls]
data = []
# scrape the URLs concurrently
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
profile_data = parse_profile(response)
data.append(profile_data)
log.success(f"scraped {len(data)} profiles from profile pages")
return dataRun the code
async def run():
profile_data = await scrape_profiles(
urls=[
"https://www.tiktok.com/@oddanimalspecimens"
]
)
# save the result to a JSON file
with open("profile_data.json", "w", encoding="utf-8") as file:
json.dump(profile_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())The code works as follows:
- Create an async
httpxwith basic browser headers to avoid blocking. - Define a
parse_profilesfunction to select the script tag and parse the profile data. - Define a
scrape_profilesfunction to request the profile URLs concurrently while parsing the data from each page.
Running the above TikTok scraper will create a JSON file named profile_data. The output looks like this:
Output
[
{
"user": {
"id": "6976999329680589829",
"shortId": "",
"uniqueId": "oddanimalspecimens",
"nickname": "Odd Animal Specimens",
"avatarLarger": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_1080x1080.jpeg?lk3s=a5d48078&x-expires=1709280000&x-signature=1rRtT4jX0Tk5hK6cpSsDcqeU7cM%3D",
"avatarMedium": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_720x720.jpeg?lk3s=a5d48078&x-expires=1709280000&x-signature=WXYAMT%2BIs9YV52R6jrg%2F1ccwdcE%3D",
"avatarThumb": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_100x100.jpeg?lk3s=a5d48078&x-expires=1709280000&x-signature=rURTqWGfKNEiwl42nGtc8ufRIOw%3D",
"signature": "YOUTUBE: Odd Animal Specimens\nCONTACT: OddAnimalSpecimens@whalartalent.com",
"createTime": 0,
"verified": false,
"secUid": "MS4wLjABAAAAmiTQjtyN2Q_JQji6RgtgX2fKqOA-gcAAUU4SF9c7ktL3uPoWu0nLpBfqixgacB8u",
"ftc": false,
"relation": 0,
"openFavorite": false,
"bioLink": {
"link": "linktr.ee/oddanimalspecimens",
"risk": 0
},
"commentSetting": 0,
"commerceUserInfo": {
"commerceUser": false
},
"duetSetting": 0,
"stitchSetting": 0,
"privateAccount": false,
"secret": false,
"isADVirtual": false,
"roomId": "",
"uniqueIdModifyTime": 0,
"ttSeller": false,
"region": "US",
"profileTab": {
"showMusicTab": false,
"showQuestionTab": true,
"showPlayListTab": true
},
"followingVisibility": 1,
"recommendReason": "",
"nowInvitationCardUrl": "",
"nickNameModifyTime": 0,
"isEmbedBanned": false,
"canExpPlaylist": true,
"profileEmbedPermission": 1,
"language": "en",
"eventList": [],
"suggestAccountBind": false
},
"stats": {
"followerCount": 2600000,
"followingCount": 6,
"heart": 44600000,
"heartCount": 44600000,
"videoCount": 124,
"diggCount": 0,
"friendCount": 3
},
"itemList": []
}
]We can successfully scrape TikTok for profile data. However, we are missing the profile's video data. Let's extract it!
For the full retrieved JSON output, you can view the example onour example dataset on ScrapFly's TikTok scraper.
Next, let's explore how to scrape channels data!
Scraping TikTok Channel Data
In this section, we'll scrape channel posts. The data we'll scrape are video data, which are only found in profiles with posts. Hence, this profile type is referred to as a channel.
The channel video data are loaded dynamically through JavaScript, where scrolling loads more data.
The above background XHR calls are loaded while scrolling down the page. These calls were sent to the endpoint /api/post/item_list/, which returns the channel video data through batches.
To scrape channel data, we can request the /post/item_list/ API endpoint directly. However, this endpoint requires many different parameters, which can be challenging to maintain. Therefore, we'll extract the data from the XHR calls.

TikTok allows non-logged-in users to view the profile pages. However, it restricts any actions unless you are logged in, meaning that we can't scroll down with the mouse actions. Therefore, we'll scroll down using JavaScript code that gets executed upon sending a request:
function scrollToEnd(i) {
// check if already at the bottom and stop if there aren't more scrolls
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
console.log("Reached the bottom.");
return;
}
// scroll down
window.scrollTo(0, document.body.scrollHeight);
// set a maximum of 15 iterations
if (i < 15) {
setTimeout(() => scrollToEnd(i + 1), 3000);
} else {
console.log("Reached the end of iterations.");
}
}
scrollToEnd(0);Here, we create a JavaScript function to scroll down and wait between each scroll iteration for the XHR requests to finish loading. It has a maximum of 15 scrolls, which is sufficient for most profiles.
Let's use the above JavaScript code to scrape TikTok channel data from XHR calls:
import jmespath
import asyncio
import json
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly APi key")
js_scroll_function = """
function scrollToEnd(i) {
// check if already at the bottom and stop if there aren't more scrolls
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
console.log("Reached the bottom.");
return;
}
// scroll down
window.scrollTo(0, document.body.scrollHeight);
// set a maximum of 15 iterations
if (i < 15) {
setTimeout(() => scrollToEnd(i + 1), 3000);
} else {
console.log("Reached the end of iterations.");
}
}
scrollToEnd(0);
"""
def parse_channel(response: ScrapeApiResponse):
"""parse channel video data from XHR calls"""
# extract the xhr calls and extract the ones for videos
_xhr_calls = response.scrape_result["browser_data"]["xhr_call"]
post_calls = [c for c in _xhr_calls if "/api/post/item_list/" in c["url"]]
post_data = []
for post_call in post_calls:
try:
data = json.loads(post_call["response"]["body"])["itemList"]
except Exception:
raise Exception("Post data couldn't load")
post_data.extend(data)
# parse all the data using jmespath
parsed_data = []
for post in post_data:
result = jmespath.search(
"""{
createTime: createTime,
desc: desc,
id: id,
stats: stats,
contents: contents[].{desc: desc, textExtra: textExtra[].{hashtagName: hashtagName}},
video: video
}""",
post
)
parsed_data.append(result)
return parsed_data
async def scrape_channel(url: str) -> List[Dict]:
"""scrape video data from a channel (profile with videos)"""
log.info(f"scraping channel page with the URL {url} for post data")
response = await SCRAPFLY.async_scrape(
ScrapeConfig(
url,
asp=True,
country="AU",
render_js=True,
rendering_wait=5000,
js=js_scroll_function,
wait_for_selector="//div[@id='main-content-video_detail']",
)
)
data = parse_channel(response)
log.success(f"scraped {len(data)} posts data")
return dataRun the code
async def run():
channel_data = await scrape_channel(
url="https://www.tiktok.com/@oddanimalspecimens"
)
# save the result to a JSON file
with open("channel_data.json", "w", encoding="utf-8") as file:
json.dump(channel_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())Let's break down the execution flow of the above TikTok web scraping code:
- A request with a headless browser is sent to the profile page.
- The JavaScript scroll function gets executed.
- More channel video data are loaded through background XHR calls.
- The
parse_channelfunction iterates over the responses of all the XHR calls and saves the video data into thepost_dataarray. - The channel data are refined using Quick Intro to Parsing JSON with JMESPath in Python to exclude the unnecessary details.
We have extracted a small portion of each video data from the responses we got. However, the full response includes further details that might be useful. Here is a sample output for the results we got:
Sample output
[
{
"createTime": 1675963028,
"desc": "Mouse to Whale Vertebrae - What bone should I do next? How big is a mouse vertebra? How big is a whale vertebrae? A lot bigger, but all vertebrae share the same shape. Specimen use made possible by the University of Michigan Museum of Zoology. #animals #science #learnontiktok ",
"id": "7198206283571285294",
"stats": {
"collectCount": 92400,
"commentCount": 5464,
"diggCount": 1500000,
"playCount": 14000000,
"shareCount": 11800
},
"contents": [
{
"desc": "Mouse to Whale Vertebrae - What bone should I do next? How big is a mouse vertebra? How big is a whale vertebrae? A lot bigger, but all vertebrae share the same shape. Specimen use made possible by the University of Michigan Museum of Zoology. #animals #science #learnontiktok ",
"textExtra": [
{
"hashtagName": "animals"
},
{
"hashtagName": "science"
},
{
"hashtagName": "learnontiktok"
}
]
}
],
"video": {
"bitrate": 441356,
"bitrateInfo": [
....
],
"codecType": "h264",
"cover": "https://p16-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028?x-expires=1709287200&x-signature=Iv3PLyTi3PIWT4QUewp6MPnRU9c%3D",
"definition": "540p",
"downloadAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/ed00b2ad6b9b4248ab0a4dd8494b9cfc/?a=1988&ch=0&cr=3&dr=0&lr=tiktok_m&cd=0%7C0%7C1%7C&cv=1&br=932&bt=466&bti=ODszNWYuMDE6&cs=0&ds=3&ft=4fUEKMvt8Zmo0K4Mi94jVhstrpWrKsd.&mime_type=video_mp4&qs=0&rc=ZTs1ZTw8aTZmZzU8ZGdpNkBpanFrZWk6ZmlsaTMzZzczNEBgLmJgYTQ0NjQxYDQuXi81YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709138858&l=20240228104720CEC3E63CBB78C407D3AE&ply_type=2&policy=2&signature=b86d518a02194c8bd389986d95b546a8&tk=tt_chain_token",
"duration": 16,
"dynamicCover": "https://p19-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/348b414f005f4e49877e6c5ebe620832_1675963029?x-expires=1709287200&x-signature=xJyE12Y5TPj2IYQJF6zJ6%2FALwVw%3D",
"encodeUserTag": "",
"encodedType": "normal",
"format": "mp4",
"height": 1024,
"id": "7198206283571285294",
"originCover": "https://p16-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/3f677464b38a4457959a7b329002defe_1675963028?x-expires=1709287200&x-signature=KX5gLesyY80rGeHg6ywZnKVOUnY%3D",
"playAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/e9748ee135d04a7da145838ad43daa8e/?a=1988&ch=0&cr=3&dr=0&lr=unwatermarked&cd=0%7C0%7C0%7C&cv=1&br=862&bt=431&bti=ODszNWYuMDE6&cs=0&ds=6&ft=4fUEKMvt8Zmo0K4Mi94jVhstrpWrKsd.&mime_type=video_mp4&qs=0&rc=OzRlNzNnPDtlOTxpZjMzNkBpanFrZWk6ZmlsaTMzZzczNEAzYzI0MC1gNl8xMzUxXmE2YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709138858&l=20240228104720CEC3E63CBB78C407D3AE&ply_type=2&policy=2&signature=21ea870dc90edb60928080a6bdbfd23a&tk=tt_chain_token",
"ratio": "540p",
"subtitleInfos": [
....
],
"videoQuality": "normal",
"volumeInfo": {
"Loudness": -15.3,
"Peak": 0.79433
},
"width": 576,
"zoomCover": {
"240": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:240:240.avif?x-expires=1709287200&x-signature=UV1mNc2EHUy6rf9eRQvkS%2FX%2BuL8%3D",
"480": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:480:480.avif?x-expires=1709287200&x-signature=PT%2BCf4%2F4MC70e2VWHJC40TNv%2Fbc%3D",
"720": "https://p19-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:720:720.avif?x-expires=1709287200&x-signature=3t7Dxca4pBoNYtzoYzui8ZWdALM%3D",
"960": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:960:960.avif?x-expires=1709287200&x-signature=aKcJ0jxPTQx3YMV5lPLRlLMrkso%3D"
}
}
},
....
]The above code extracted over a hundred video data with a few lines of code in less than a minute. That's pretty powerful!
Scraping TikTok Posts?
Let's continue with our TikTok scraping project. In this section, we'll scrape video data, which represents TikTok posts. Similar to profile pages, post data can be found as hidden data under script tags.
Go to any video on TikTok, inspect the page and search for the following selector, which we have used earlier:
//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()The post data in the above script tag looks like this:
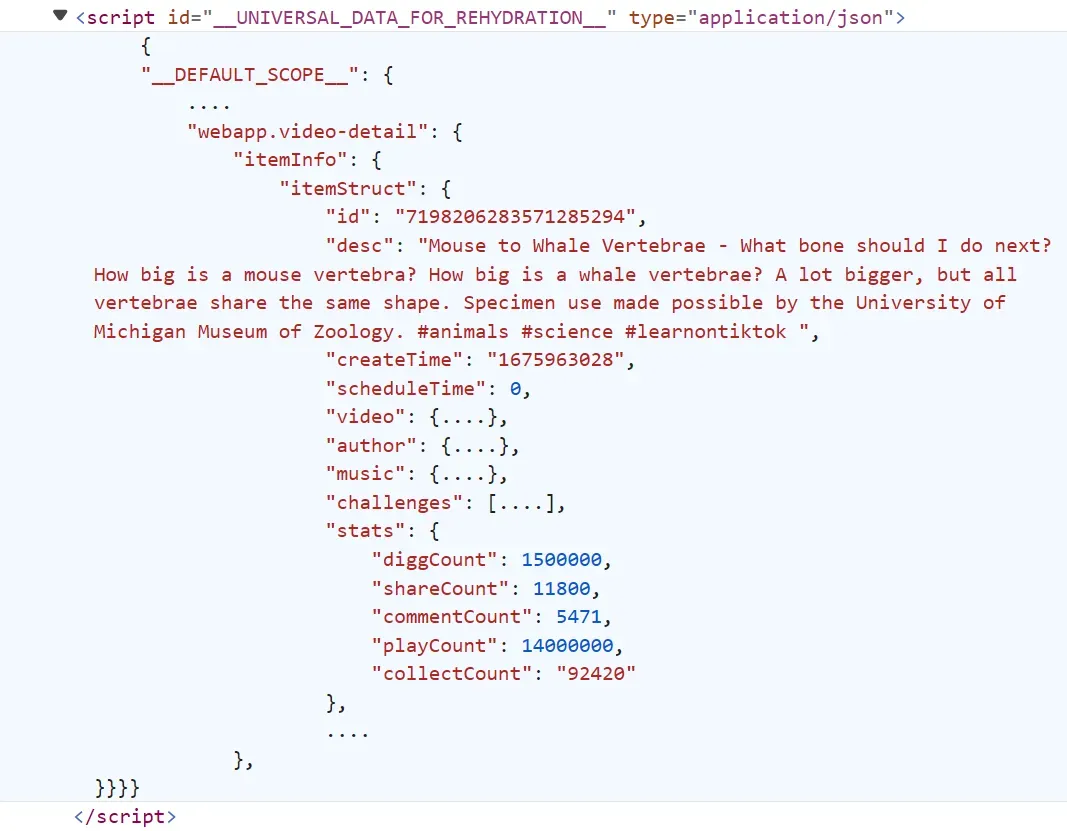
Let's scrape TikTok posts by extracting and parsing the above data:
import jmespath
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def parse_post(response: Response) -> Dict:
"""parse hidden post data from HTML"""
assert response.status_code == 200, "request is blocked, use the ScrapFly codetabs"
selector = Selector(response.text)
data = selector.xpath("//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()").get()
post_data = json.loads(data)["__DEFAULT_SCOPE__"]["webapp.video-detail"]["itemInfo"]["itemStruct"]
parsed_post_data = jmespath.search(
"""{
id: id,
desc: desc,
createTime: createTime,
video: video.{duration: duration, ratio: ratio, cover: cover, playAddr: playAddr, downloadAddr: downloadAddr, bitrate: bitrate},
author: author.{id: id, uniqueId: uniqueId, nickname: nickname, avatarLarger: avatarLarger, signature: signature, verified: verified},
stats: stats,
locationCreated: locationCreated,
diversificationLabels: diversificationLabels,
suggestedWords: suggestedWords,
contents: contents[].{textExtra: textExtra[].{hashtagName: hashtagName}}
}""",
post_data
)
return parsed_post_data
async def scrape_posts(urls: List[str]) -> List[Dict]:
"""scrape tiktok posts data from their URLs"""
to_scrape = [client.get(url) for url in urls]
data = []
for response in asyncio.as_completed(to_scrape):
response = await response
post_data = parse_post(response)
data.append(post_data)
log.success(f"scraped {len(data)} posts from post pages")
return dataimport jmespath
import asyncio
import json
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_post(response: ScrapeApiResponse) -> Dict:
"""parse hidden post data from HTML"""
selector = response.selector
data = selector.xpath("//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()").get()
post_data = json.loads(data)["__DEFAULT_SCOPE__"]["webapp.video-detail"]["itemInfo"]["itemStruct"]
parsed_post_data = jmespath.search(
"""{
id: id,
desc: desc,
createTime: createTime,
video: video.{duration: duration, ratio: ratio, cover: cover, playAddr: playAddr, downloadAddr: downloadAddr, bitrate: bitrate},
author: author.{id: id, uniqueId: uniqueId, nickname: nickname, avatarLarger: avatarLarger, signature: signature, verified: verified},
stats: stats,
locationCreated: locationCreated,
diversificationLabels: diversificationLabels,
suggestedWords: suggestedWords,
contents: contents[].{textExtra: textExtra[].{hashtagName: hashtagName}}
}""",
post_data
)
return parsed_post_data
async def scrape_posts(urls: List[str]) -> List[Dict]:
"""scrape tiktok posts data from their URLs"""
to_scrape = [ScrapeConfig(url, country="US", asp=True) for url in urls]
data = []
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
post_data = parse_post(response)
data.append(post_data)
log.success(f"scraped {len(data)} posts from post pages")
return dataRun the code
async def run():
post_data = await scrape_posts(
urls=[
"https://www.tiktok.com/@oddanimalspecimens/video/7198206283571285294"
]
)
# save the result to a JSON file
with open("post_data.json", "w", encoding="utf-8") as file:
json.dump(post_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())In the above code, we define two functions. Let's break them down:
parse_post: For parsing the post data from the script tag and refining it with JMESPath to extract the useful details only.scrape_posts: For scraping multiple post pages concurrently by adding the URLs to a scraping list and requesting them concurrently.
Here is what the created post_data file should look like:
Output
[
{
"id": "7198206283571285294",
"desc": "Mouse to Whale Vertebrae - What bone should I do next? How big is a mouse vertebra? How big is a whale vertebrae? A lot bigger, but all vertebrae share the same shape. Specimen use made possible by the University of Michigan Museum of Zoology. #animals #science #learnontiktok ",
"createTime": "1675963028",
"video": {
"duration": 16,
"ratio": "540p",
"cover": "https://p16-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028?x-expires=1709290800&x-signature=YP7J1o2kv1dLnyjv3hqwBBk487g%3D",
"playAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/e9748ee135d04a7da145838ad43daa8e/?a=1988&ch=0&cr=3&dr=0&lr=unwatermarked&cd=0%7C0%7C0%7C&cv=1&br=862&bt=431&bti=ODszNWYuMDE6&cs=0&ds=6&ft=4fUEKMUj8Zmo0Qnqi94jVZgzZpWrKsd.&mime_type=video_mp4&qs=0&rc=OzRlNzNnPDtlOTxpZjMzNkBpanFrZWk6ZmlsaTMzZzczNEAzYzI0MC1gNl8xMzUxXmE2YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709142489&l=202402281147513D9DCF4EE8518C173598&ply_type=2&policy=2&signature=c0c4220f863ca89053ec2a71b180f226&tk=tt_chain_token",
"downloadAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/ed00b2ad6b9b4248ab0a4dd8494b9cfc/?a=1988&ch=0&cr=3&dr=0&lr=tiktok_m&cd=0%7C0%7C1%7C&cv=1&br=932&bt=466&bti=ODszNWYuMDE6&cs=0&ds=3&ft=4fUEKMUj8Zmo0Qnqi94jVZgzZpWrKsd.&mime_type=video_mp4&qs=0&rc=ZTs1ZTw8aTZmZzU8ZGdpNkBpanFrZWk6ZmlsaTMzZzczNEBgLmJgYTQ0NjQxYDQuXi81YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709142489&l=202402281147513D9DCF4EE8518C173598&ply_type=2&policy=2&signature=779a4044a0768f870abed13e1401608f&tk=tt_chain_token",
"bitrate": 441356
},
"author": {
"id": "6976999329680589829",
"uniqueId": "oddanimalspecimens",
"nickname": "Odd Animal Specimens",
"avatarLarger": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_1080x1080.jpeg?lk3s=a5d48078&x-expires=1709290800&x-signature=F8hu8G4VOFyd%2F0TN7QEZcGLNmW0%3D",
"signature": "YOUTUBE: Odd Animal Specimens\nCONTACT: OddAnimalSpecimens@whalartalent.com",
"verified": false
},
"stats": {
"diggCount": 1500000,
"shareCount": 11800,
"commentCount": 5471,
"playCount": 14000000,
"collectCount": "92420"
},
"locationCreated": "US",
"diversificationLabels": [
"Science",
"Education",
"Culture & Education & Technology"
],
"suggestedWords": [],
"contents": [
{
"textExtra": [
{
"hashtagName": "animals"
},
{
"hashtagName": "science"
},
{
"hashtagName": "learnontiktok"
}
]
}
]
}
]The above TikTok scraping code has successfully extracted the video data from its page. However, the comments are missing! Let's scrape it in the following section!
Scraping TikTok Comments?
The comment data on a post aren't found on hidden parts of the HTML. Instead, it's loaded dynamically through hidden APIs, which get activated through scroll actions.
Since the comments on a post can exceed thousands, scraping them through scrolling isn't a practical approach. Therefore, we'll scrape them using the hidden comments API itself.

To locate the comments hidden API, follow the below steps:
- Open the browser developer tools and select the
networktab. - Go to any video page on TikTok.
- Load more comments by scrolling down.
After following the above steps, you will find the API calls used for loading more comments logged:
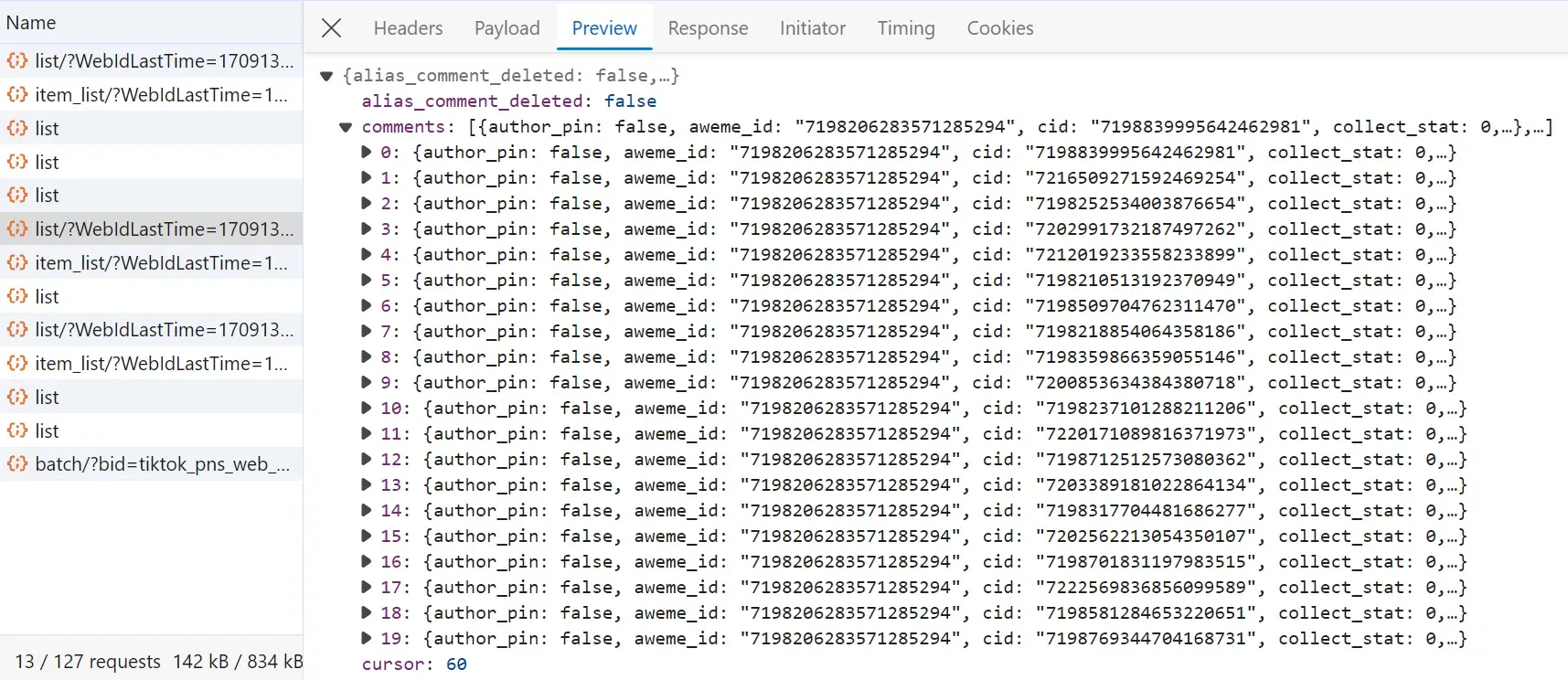
The API request was sent to the endpoint https://www.tiktok.com/api/comment/list/ with many different API parameters. However, a few of them are required:
{
"aweme_id": 7198206283571285294, # the post ID
"count": 20, # number of comments to retrieve in each API call
"cursor": 0 # the index to start retrieving from
}We'll request the comments API endpoint to the comment data directly in JSON and use the cursor parameter to crawl over comment pages:
import jmespath
import asyncio
import json
from urllib.parse import urlencode, urlparse, parse_qs
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
BASE_CONFIG = {
# bypass tiktok.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "AU",
}
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_comments(response: ScrapeApiResponse) -> List[Dict]:
"""parse comments data from the API response"""
data = json.loads(response.scrape_result["content"])
comments_data = data["comments"]
total_comments = data["total"]
parsed_comments = []
# refine the comments with JMESPath
for comment in comments_data:
result = jmespath.search(
"""{
text: text,
comment_language: comment_language,
digg_count: digg_count,
reply_comment_total: reply_comment_total,
author_pin: author_pin,
create_time: create_time,
cid: cid,
nickname: user.nickname,
unique_id: user.unique_id,
aweme_id: aweme_id
}""",
comment
)
parsed_comments.append(result)
return {"comments": parsed_comments, "total_comments": total_comments}
async def retrieve_comment_params(post_url: str) -> Dict:
"""retrieve query parameters for the comments API"""
response = await SCRAPFLY.async_scrape(
ScrapeConfig(
post_url, **BASE_CONFIG, render_js=True,
rendering_wait=5000, wait_for_selector="//div[@id='main-content-video_detail']"
)
)
_xhr_calls = response.scrape_result["browser_data"]["xhr_call"]
for i in _xhr_calls:
if "api/comment/list" not in i["url"]:
continue
url = urlparse(i["url"])
qs = parse_qs(url.query)
# remove the params we'll override
for key in ["count", "cursor"]:
_ = qs.pop(key, None)
api_params = {key: value[0] for key, value in qs.items()}
return api_params
async def scrape_comments(post_url: str, comments_count: int = 20, max_comments: int = None) -> List[Dict]:
"""scrape comments from tiktok posts using hidden APIs"""
post_id = post_url.split("/video/")[1].split("?")[0]
api_params = await retrieve_comment_params(post_url)
def form_api_url(cursor: int):
"""form the reviews API URL and its pagination values"""
base_url = "https://www.tiktok.com/api/comment/list/?"
params = {"count": comments_count, "cursor": cursor, **api_params} # the index to start from
return base_url + urlencode(params)
log.info("scraping the first comments batch")
first_page = await SCRAPFLY.async_scrape(
ScrapeConfig(form_api_url(cursor=0), **BASE_CONFIG, headers={"content-type": "application/json"})
)
data = parse_comments(first_page)
comments_data = data["comments"]
total_comments = data["total_comments"]
# get the maximum number of comments to scrape
if max_comments and max_comments < total_comments:
total_comments = max_comments
# scrape the remaining comments concurrently
log.info(f"scraping comments pagination, remaining {total_comments // comments_count - 1} more pages")
_other_pages = [
ScrapeConfig(form_api_url(cursor=cursor), **BASE_CONFIG, headers={"content-type": "application/json"})
for cursor in range(comments_count, total_comments + comments_count, comments_count)
]
async for response in SCRAPFLY.concurrent_scrape(_other_pages):
data = parse_comments(response)["comments"]
comments_data.extend(data)
log.success(f"scraped {len(comments_data)} from the comments API from the post with the ID {post_id}")
return comments_dataRun the code
async def run():
comment_data = await scrape_comments(
# the post/video URL containing the comments
post_url="https://www.tiktok.com/@oddanimalspecimens/video/7198206283571285294",
# total comments to scrape, omitting it will scrape all the avilable comments
max_comments=24,
# default is 20, it can be overriden to scrape more comments in each call but it can't be > the total comments on the post
comments_count=20
)
# save the result to a JSON file
with open("comment_data.json", "w", encoding="utf-8") as file:
json.dump(comment_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())The above code scrapes TikTok comments data using two main functions:
scrape_comments: To create the comments API URL with the desired offset and request it to get the comment data in JSON.parse_comments: This is used to parse the comments API responses and extract the useful data using JMESPath.
Here is a sample output of the comment data we got:
Sample output
[
{
"text": "Dude give ‘em back",
"comment_language": "en",
"digg_count": 72009,
"reply_comment_total": 131,
"author_pin": false,
"create_time": 1675963633,
"cid": "7198208855277060910",
"nickname": "GrandMoffJames",
"unique_id": "grandmoffjames",
"aweme_id": "7198206283571285294"
},
{
"text": "Dudes got everyone’s back",
"comment_language": "en",
"digg_count": 36982,
"reply_comment_total": 100,
"author_pin": false,
"create_time": 1675966520,
"cid": "7198221275168719662",
"nickname": "Scott",
"unique_id": "troutfishmanjr",
"aweme_id": "7198206283571285294"
},
{
"text": "do human backbone",
"comment_language": "en",
"digg_count": 18286,
"reply_comment_total": 99,
"author_pin": false,
"create_time": 1676553505,
"cid": "7200742421726216987",
"nickname": "www",
"unique_id": "ksjekwjkdbw",
"aweme_id": "7198206283571285294"
},
{
"text": "casually has a backbone in his inventory",
"comment_language": "en",
"digg_count": 20627,
"reply_comment_total": 9,
"author_pin": false,
"create_time": 1676106562,
"cid": "7198822535374734126",
"nickname": "*",
"unique_id": "angelonextdoor",
"aweme_id": "7198206283571285294"
},
{
"text": "😧",
"comment_language": "",
"digg_count": 7274,
"reply_comment_total": 20,
"author_pin": false,
"create_time": 1675963217,
"cid": "7198207091995132698",
"nickname": "Son Bi’",
"unique_id": "son_bisss",
"aweme_id": "7198206283571285294"
},
....
]The above TikTok scraper code can scrape tens of comments in mere seconds. That's because utilizing the TikTok hidden APIs for web scraping is much faster than parsing data from HTML.
How To Scrape TikTok Search?
In this section, we'll proceed with the last piece of our TikTok web scraping code: search pages. The search data are loaded through a hidden API, which we'll utilize for web scraping. Alternatively, data on search pages can be scraped from background XHR calls, similar to how we scraped the channel data.
To capture the search API, follow the below steps:
- Open the
networktab of the browser developer tools. - Use the search box to search for any keyword.
- Scroll down to load more search results.
After following the above steps, you will find the search API requests logged:
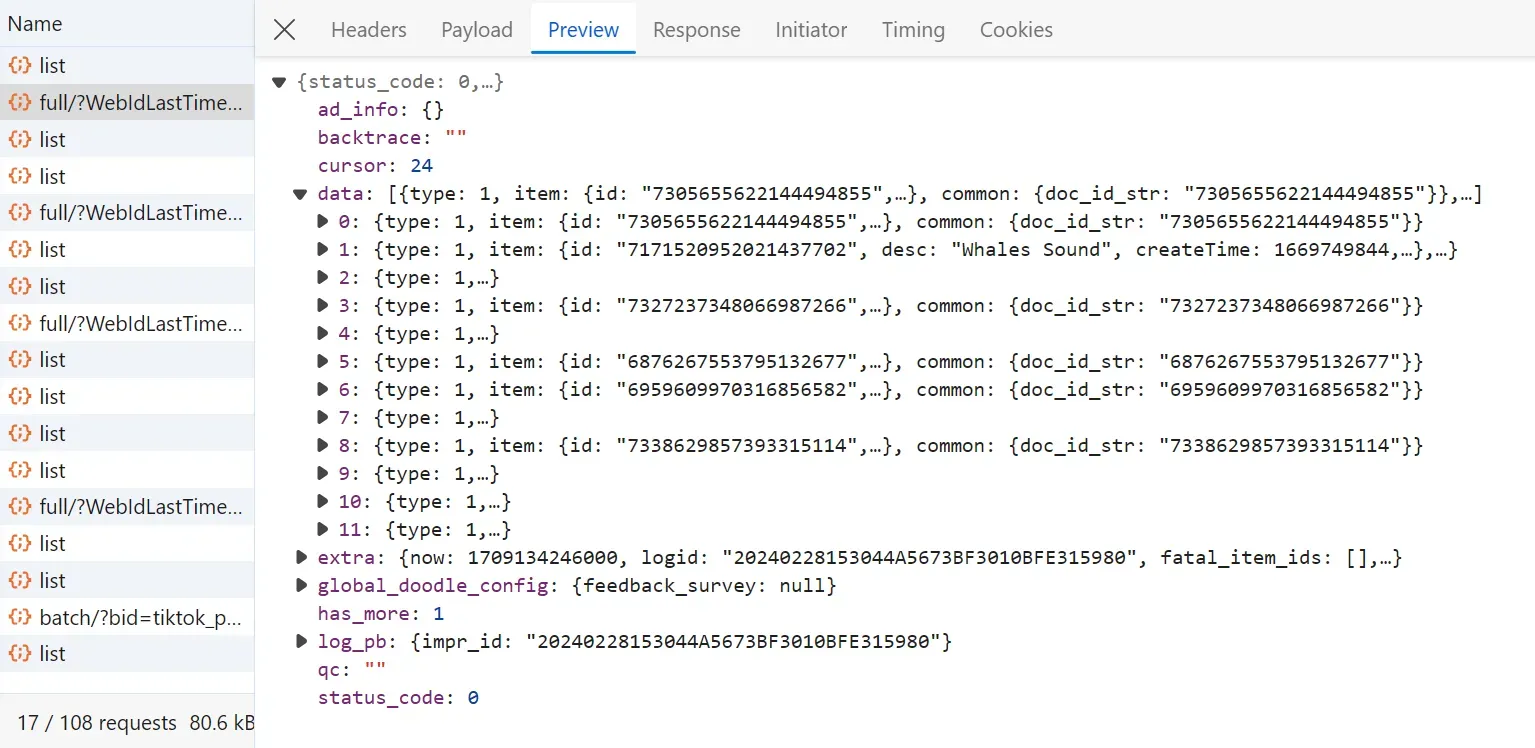
The above API request was sent to the following endpoint with these parameters:
search_api_url = "https://www.tiktok.com/api/search/general/full/?"
parameters = {
"keyword": "whales", # the keyword of the search query
"offset": cursor, # the index to start from
"search_id": "2024022710453229C796B3BF936930E248" # timestamp with random ID
}The above parameters are essential for the search query. However, this endpoint requires certain How to Handle Cookies in Web Scraping values to authorize the requests, which can be challenging to maintain. Therefore, we'll utilize the ScrapFly sessions feature to obtain a cookie and reuse it with the search API requests:
import datetime
import secrets
import asyncio
import json
import jmespath
from typing import Dict, List
from urllib.parse import urlencode, quote
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your Scrapfly API key key")
def parse_search(response: ScrapeApiResponse) -> List[Dict]:
"""parse search data from the API response"""
data = json.loads(response.scrape_result["content"])
search_data = data["data"]
parsed_search = []
for item in search_data:
if item["type"] == 1: # get the item if it was item only
result = jmespath.search(
"""{
id: id,
desc: desc,
createTime: createTime,
video: video,
author: author,
stats: stats,
authorStats: authorStats
}""",
item["item"]
)
result["type"] = item["type"]
parsed_search.append(result)
# wheter there is more search results: 0 or 1. There is no max searches available
has_more = data["has_more"]
return parsed_search
async def obtain_session(url: str) -> str:
"""create a session to save the cookies and authorize the search API"""
session_id="tiktok_search_session"
await SCRAPFLY.async_scrape(ScrapeConfig(
url, asp=True, country="US", render_js=True, session=session_id
))
return session_id
async def scrape_search(keyword: str, max_search: int, search_count: int = 12) -> List[Dict]:
"""scrape tiktok search data from the search API"""
def generate_search_id():
# get the current datetime and format it as YYYYMMDDHHMMSS
timestamp = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
# calculate the length of the random hex required for the total length (32)
random_hex_length = (32 - len(timestamp)) // 2 # calculate bytes needed
random_hex = secrets.token_hex(random_hex_length).upper()
random_id = timestamp + random_hex
return random_id
def form_api_url(cursor: int):
"""form the reviews API URL and its pagination values"""
base_url = "https://www.tiktok.com/api/search/general/full/?"
params = {
"keyword": quote(keyword),
"offset": cursor, # the index to start from
"search_id": generate_search_id()
}
return base_url + urlencode(params)
log.info("obtaining a session for the search API")
session_id = await obtain_session(url="https://www.tiktok.com/search?q=" + quote(keyword))
log.info("scraping the first search batch")
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(
form_api_url(cursor=0), asp=True, country="US", session=session_id
))
search_data = parse_search(first_page)
# scrape the remaining comments concurrently
log.info(f"scraping search pagination, remaining {max_search // search_count} more pages")
_other_pages = [
ScrapeConfig(form_api_url(cursor=cursor), asp=True, country="US", session=session_id
)
for cursor in range(search_count, max_search + search_count, search_count)
]
async for response in SCRAPFLY.concurrent_scrape(_other_pages):
data = parse_search(response)
search_data.extend(data)
log.success(f"scraped {len(search_data)} from the search API from the keyword {keyword}")
return search_dataRun the code
async def run():
search_data = await scrape_search(
keyword="whales",
max_search=18
)
# save the result to a JSON file
with open("search_data.json", "w", encoding="utf-8") as file:
json.dump(search_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())Let's break down the execution flow of the above TikTok scraping code:
- A request is sent to the regular search page to obtain the cookie values through the
obtain_sessionfunction. - A random search ID is created using the
generate_search_idto use it with the requests sent to the search API. - The first search API URL is created with the
form_api_urlfunction. - A request is sent to the search API with the session key containing the cookies.
- The JSON response of the search API is parsed using the
parse_search. It also filters the response data to only include the video data.
🙋 The above code requests the `/search/general/full/` endpoint, which retrieves search results for both profile and video data. This endpoint is limited to a low cursor value. To effectiely manage its pagination, you can use filters to narrow down the results.
Here is a sample output of results we got:
Sample output
[
{
"id": "7192262480066825515",
"desc": "Replying to @julsss1324 their songs are described as hauntingly beautiful. Do you find them scary or beautiful? For me it’s peaceful. They remind me of elephants. 🐋🎶💙 @kaimanaoceansafari #whalesounds #whalesong #hawaii #ocean #deepwater #deepsea #thalassophobia #whales #humpbackwhales ",
"createTime": 1674579130,
"video": {
"id": "7192262480066825515",
"height": 1024,
"width": 576,
"duration": 25,
"ratio": "540p",
"cover": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/e438558728954c74a761132383865d97_1674579131~tplv-dmt-logom:tos-useast5-i-0068-tx/0bb4cf51c9f445c9a46dc8d5aab20545.image?x-expires=1709215200&x-signature=Xl1W9ELtZ5%2FP4oTEpjqOYsGQcx8%3D",
"originCover": "https://p19-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/2061429a4535477686769d5f2faeb4f0_1674579131?x-expires=1709215200&x-signature=OJW%2BJnqnYt4L2G2pCryrfh52URI%3D",
"dynamicCover": "https://p19-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/88b455ffcbc6421999f47ebeb31b962b_1674579131?x-expires=1709215200&x-signature=hDBbwIe0Z8HRVFxLe%2F2JZoeHopU%3D",
"playAddr": "https://v16-webapp-prime.us.tiktok.com/video/tos/useast5/tos-useast5-pve-0068-tx/809fca40201048c78299afef3b627627/?a=1988&ch=0&cr=3&dr=0&lr=unwatermarked&cd=0%7C0%7C0%7C&cv=1&br=3412&bt=1706&bti=NDU3ZjAwOg%3D%3D&cs=0&ds=6&ft=4KJMyMzm8Zmo0apOi94jV94rdpWrKsd.&mime_type=video_mp4&qs=0&rc=NDU3PDc0PDw7ZGg7ODg0O0BpM2xycGk6ZnYzaTMzZzczNEBgNl4tLjFiNjMxNTVgYjReYSNucGwzcjQwajVgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709216449&l=202402271420230081AD419FAC9913AB63&ply_type=2&policy=2&signature=1d44696fa49eb5fa609f6b6871445f77&tk=tt_chain_token",
"downloadAddr": "https://v16-webapp-prime.us.tiktok.com/video/tos/useast5/tos-useast5-pve-0068-tx/c7196f98798e4520834a64666d253cb6/?a=1988&ch=0&cr=3&dr=0&lr=tiktok_m&cd=0%7C0%7C1%7C&cv=1&br=3514&bt=1757&bti=NDU3ZjAwOg%3D%3D&cs=0&ds=3&ft=4KJMyMzm8Zmo0apOi94jV94rdpWrKsd.&mime_type=video_mp4&qs=0&rc=ZTw5Njg0NDo3Njo7PGllOkBpM2xycGk6ZnYzaTMzZzczNEBhYjFiLjA1NmAxMS8uMDIuYSNucGwzcjQwajVgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709216449&l=202402271420230081AD419FAC9913AB63&ply_type=2&policy=2&signature=1443d976720e418204704f43af4ff0f5&tk=tt_chain_token",
"shareCover": [
"",
"https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/2061429a4535477686769d5f2faeb4f0_1674579131~tplv-photomode-tiktok-play.jpeg?x-expires=1709647200&x-signature=%2B4dufwEEFxPJU0NX4K4Mm%2FPET6E%3D",
"https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/2061429a4535477686769d5f2faeb4f0_1674579131~tplv-photomode-share-play.jpeg?x-expires=1709647200&x-signature=XCorhFJUTCahS8crANfC%2BDSrTbU%3D"
],
"reflowCover": "https://p19-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/e438558728954c74a761132383865d97_1674579131~tplv-photomode-video-cover:480:480.jpeg?x-expires=1709215200&x-signature=%2BFN9Vq7TxNLLCtJCsMxZIrgjMis%3D",
"bitrate": 1747435,
"encodedType": "normal",
"format": "mp4",
"videoQuality": "normal",
"encodeUserTag": ""
},
"author": {
"id": "6763395919847523333",
"uniqueId": "mermaid.kayleigh",
"nickname": "mermaid.kayleigh",
"avatarThumb": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7310953622576037894~c5_100x100.jpeg?lk3s=a5d48078&x-expires=1709215200&x-signature=0tw66iTdRDhPA4pTHM8e4gjIsNo%3D",
"avatarMedium": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7310953622576037894~c5_720x720.jpeg?lk3s=a5d48078&x-expires=1709215200&x-signature=IkaoB24EJoHdsHCinXmaazAWDYo%3D",
"avatarLarger": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7310953622576037894~c5_1080x1080.jpeg?lk3s=a5d48078&x-expires=1709215200&x-signature=38KCawETqF%2FdyMX%2FAZg32edHnc4%3D",
"signature": "Love the ocean with me 💙\nOwner @KaimanaOceanSafari 🤿\nCome dive with me👇🏼",
"verified": true,
"secUid": "MS4wLjABAAAAhIICwHiwEKwUg07akDeU_cnM0uE1LAGO-kEQdw3AZ_Rd-zcb-qOR0-1SeZ5D2Che",
"secret": false,
"ftc": false,
"relation": 0,
"openFavorite": false,
"commentSetting": 0,
"duetSetting": 0,
"stitchSetting": 0,
"privateAccount": false,
"downloadSetting": 0
},
"stats": {
"diggCount": 10000000,
"shareCount": 390800,
"commentCount": 72100,
"playCount": 89100000,
"collectCount": 663400
},
"authorStats": {
"followingCount": 313,
"followerCount": 2000000,
"heartCount": 105400000,
"videoCount": 1283,
"diggCount": 40800,
"heart": 105400000
},
"type": 1
},
....
]With this last feature, our TikTok scraper is complete. It can scrape profiles, channels, posts, comments and search data!
Bypass TikTok Scraping Blocking With ScrapFly
We can successfully scrape TikTok data from various pages. However, scaling our scraping rate will lead TikTok to block the IP address used. Moreover, it can challenge the requests with 5 Proven Ways to Bypass CAPTCHA in Python if the traffic is suspected:
Scrapfly can help resolve TikTok scraper blocking.
Here's how to avoid TikTok web scraping blocking using ScrapFly. Replace the HTTP client with the ScrapFly client and enable the asp parameter:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some tiktok.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']FAQ
How long before TikTok detects and bans scraping attempts?
TikTok continuously monitors user behavior, including request timing, scrolling activity, TLS fingerprints, and IP reputation. Its detection models are trained on millions of real user sessions, so avoiding detection requires mimicking human-like interaction, not just rotating proxies.
Can I scrape TikTok without an account?
You can scrape limited public data such as basic profiles and video metadata, but access usually stops after a few page views. Search results and comments require more complex handling, while most video data is only partially visible. In short, unauthenticated scraping is very limited.
Why do TikTok scrapers get blocked?
TikTok blocks scrapers that show automated or unnatural behavior, such as making requests too quickly, using uniform request patterns, using datacenter IPs, or missing required headers. Once flagged, blocks are persistent and require sophisticated bypass techniques.
Is scraping TikTok legal?
Scraping publicly accessible data has strong legal precedents. However, TikTok's Terms of Service prohibit automated access. While scraping public data carries minimal legal risk, it can still lead to IP or account bans. Always seek legal advice for commercial projects.
How much does ScrapFly cost for TikTok scraping?
Pricing depends on your request volume. As a general estimate: 1,000 profiles usually cost between $15 and $30. 10,000 videos cost around $80 to $150.
You can check ScrapFly's pricing page for the most up-to-date rates. Most users find it far more cost-effective than maintaining their own proxy or infrastructure.
How often does TikTok change its structure?
TikTok's internal APIs and frontend code change frequently. API endpoints update every four to eight weeks, while frontend elements change every two to four weeks. JSON structures usually remain stable for several months. ScrapFly's monitoring system detects these changes and updates its TikTok scrapers within 48 hours.
Why can't I just use Puppeteer/Playwright for TikTok?
While Puppeteer and Playwright can render TikTok pages, they lack the full anti-detection setup required. You would still need to handle residential proxy rotation, header generation, session persistence, human-like browsing patterns, and browser fingerprint rotation. ScrapFly manages all of this automatically, making scraping much more reliable.
Can I scrape TikTok private accounts?
Private account data is only visible to logged-in users. Scraping this data would require authentication, which breaches TikTok's Terms of Service. However, public account information can still be accessed safely using ScrapFly.
Can I scrape TikTok video download URLs?
TikTok video URLs are available in the page's hidden JSON data, but they are time-limited and signed with authentication tokens that expire quickly. For reliable video metadata extraction, use ScrapFly's maintained TikTok scraper which handles token refresh automatically. For scraping other social media platforms with similar challenges, see our guides on scraping Instagram and scraping Threads.
Summary
TikTok protects social media data through multi-layered blocking: encrypted headers, behavioral tracking, and request fingerprinting. DIY scraping requires managing session persistence, residential proxy rotation, TLS fingerprint randomization, and behavior emulation - a very time consuming maintenance burden!
ScrapFly eliminates this complexity:
- Automated anti-bot bypass: Handles fingerprinting, behavioral tracking, and fraud score evasion
- Maintained scrapers: Updated within 48 hours when TikTok changes structure
- Production-ready code: Extract profiles, videos, comments, and search results without managing infrastructure
- Residential proxy pools: Rotate IPs automatically to prevent detection
When TikTok updates its defenses, ScrapFly updates the scraper. You focus on data, not anti-bot engineering.
Ready to start?
git clone https://github.com/scrapfly/scrapfly-scrapers.git
cd scrapfly-scrapers/tiktok-scraperLegal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


