

StockX is an online marketplace for buying and selling authentic sneakers, streetwear, watches, and designer handbags. The most interesting part about StockX is that it treats apparel items as a commodity and tracks their value over time. This makes StockX a prime target for web scraping as tracking market movement and product data is a great way to build a data-driven business.
In this web scraping tutorial, we'll be taking a look at how to scrape StockX using Python. We'll be scraping StockX's hidden web data which is an incredibly easy way to scrape e-commerce websites with just a few lines of code.
We'll start with a quick Python environment setup and tool overview, then scrape some products and product search pages. Let's dive in!
Key Takeaways
Master stockx scraper development with Python to extract fashion and sneaker market data using hidden web data extraction techniques for tracking product prices and market trends.
- Use hidden JSON data embedded in HTML to extract comprehensive StockX product and market information
- Parse StockX's commodity-style pricing data including bids, asks, and historical price movements
- Handle StockX's anti-scraping measures with proper headers and request spacing for fashion data extraction
- Extract structured product data including sneaker details, market performance, and trading statistics
- Implement efficient data extraction from JavaScript variables without browser automation requirements
- Use market data for competitive analysis and data-driven business decisions in fashion e-commerce
Why scrape StockX?
Just like most e-commerce targets StockX public data provides an important overview of the market. So, scraping StockX is a great way to get a competitive advantage through data-driven decision-making.
Additionally, since StockX treats its products as commodities by scraping the data we can perform various data analysis tasks to keep on top with market trends outbidding and outmaneuvering our competitors.
StockX Dataset Preview
Since we'll be using hidden web data scraping we'll be extracting the whole product datasets which contain fields like:
- Product data like descriptions, images, sizes, ids, traits and everything visible on the page.
- Product market performance like sale numbers, prices, asks and bids.
Example Product Dataset
{
"id": "7cfe0c22-7e77-4e54-89ca-c03007ecbfd1",
"listingType": "STANDARD",
"deleted": false,
"merchandising": {
"title": "StockX Verified Sneakers",
"subtitle": "We Verify Every Item. Every Time.",
"image": {
"alt": null,
"url": "https: //images-cs.stockx.com/v3/assets/blt818b0c67cf450811/bltc3258254704231c0/62a8faa88f6a4950536d049f/Merchandising_Modules_EN_-_Image_02.jpg"
},
"body": "",
"trackingEvent": "06-08-22 Verified Authentic Sneakers",
"link": {
"title": "StockX Verified Sneakers",
"url": "https://stockx.com/about/verification/",
"urlType": "EXTERNAL"
}
},
"productCategory": "sneakers",
"urlKey": "nike-air-max-90-se-running-club",
"market": {
"bidAskData": {
"lowestAsk": 114,
"numberOfAsks": 130,
"highestBid": 128,
"numberOfBids": 79
},
"statistics": {
"lastSale": {
"amount": 204,
"changePercentage": 0.211539,
"changeValue": 36,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 204,
"salesLast72Hours": 3
}
},
"variants": [
{
"id": "1f07d59f-988e-48ac-8c44-24efa4543118",
"market": {
"bidAskData": {
"lowestAsk": 237,
"numberOfAsks": 1,
"highestBid": 70,
"numberOfBids": 2
},
"statistics": {
"lastSale": {
"amount": 278,
"changePercentage": 0.456539,
"changeValue": 88,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 278,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "6"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087411"
}
],
"sizeChart": {
"baseSize": "6",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 6",
"type": "us m"
},
{
"size": "UK 5.5",
"type": "uk"
},
{
"size": "JP 24 (US M 6)",
"type": "jp"
},
{
"size": "KR 240 (US M 6)",
"type": "kr"
},
{
"size": "EU 38.5",
"type": "eu"
},
{
"size": "US W 7.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "80701fe2-0488-4c57-9d38-9ac15988b87b",
"market": {
"bidAskData": {
"lowestAsk": 173,
"numberOfAsks": 4,
"highestBid": 57,
"numberOfBids": 2
},
"statistics": {
"lastSale": {
"amount": 189,
"changePercentage": 0.35,
"changeValue": 49,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 189,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "6.5"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087428"
}
],
"sizeChart": {
"baseSize": "6.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 6.5",
"type": "us m"
},
{
"size": "UK 6 (EU 39)",
"type": "uk"
},
{
"size": "JP 24.5",
"type": "jp"
},
{
"size": "KR 245",
"type": "kr"
},
{
"size": "EU 39",
"type": "eu"
},
{
"size": "US W 8",
"type": "us w"
}
]
},
"group": null
},
{
"id": "72f405a3-2788-470d-9258-bad6cd56ad7e",
"market": {
"bidAskData": {
"lowestAsk": 164,
"numberOfAsks": 3,
"highestBid": 20,
"numberOfBids": 1
},
"statistics": {
"lastSale": {
"amount": 204,
"changePercentage": 0.505296,
"changeValue": 69,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 204,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "7"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087435"
}
],
"sizeChart": {
"baseSize": "7",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 7",
"type": "us m"
},
{
"size": "UK 6 (EU 40)",
"type": "uk"
},
{
"size": "JP 25",
"type": "jp"
},
{
"size": "KR 250",
"type": "kr"
},
{
"size": "EU 40",
"type": "eu"
},
{
"size": "US W 8.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "7fa2dc2e-de81-4c3b-95c2-14fd020c5377",
"market": {
"bidAskData": {
"lowestAsk": 126,
"numberOfAsks": 8,
"highestBid": 40,
"numberOfBids": 3
},
"statistics": {
"lastSale": {
"amount": 120,
"changePercentage": 0.00175,
"changeValue": 1,
"sameFees": true
}
},
"salesInformation": {
"lastSale": 120,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "7.5"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087442"
}
],
"sizeChart": {
"baseSize": "7.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 7.5",
"type": "us m"
},
{
"size": "UK 6.5",
"type": "uk"
},
{
"size": "JP 25.5",
"type": "jp"
},
{
"size": "KR 255",
"type": "kr"
},
{
"size": "EU 40.5",
"type": "eu"
},
{
"size": "US W 9",
"type": "us w"
}
]
},
"group": null
},
{
"id": "bed7428d-31f9-46b3-9a5b-18e5e4fbe6d1",
"market": {
"bidAskData": {
"lowestAsk": 117,
"numberOfAsks": 10,
"highestBid": 63,
"numberOfBids": 10
},
"statistics": {
"lastSale": {
"amount": 168,
"changePercentage": 0.084122,
"changeValue": 14,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 168,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "8"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087459"
}
],
"sizeChart": {
"baseSize": "8",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 8",
"type": "us m"
},
{
"size": "UK 7",
"type": "uk"
},
{
"size": "JP 26",
"type": "jp"
},
{
"size": "KR 260",
"type": "kr"
},
{
"size": "EU 41",
"type": "eu"
},
{
"size": "US W 9.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "674e5c93-a8f6-41f7-a9a0-beabb7788c5a",
"market": {
"bidAskData": {
"lowestAsk": 120,
"numberOfAsks": 6,
"highestBid": 79,
"numberOfBids": 12
},
"statistics": {
"lastSale": {
"amount": 118,
"changePercentage": -0.077334,
"changeValue": -9,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 118,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "8.5"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087466"
},
{
"type": "EAN-13",
"identifier": "2460002040899"
}
],
"sizeChart": {
"baseSize": "8.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 8.5",
"type": "us m"
},
{
"size": "UK 7.5",
"type": "uk"
},
{
"size": "JP 26.5",
"type": "jp"
},
{
"size": "KR 265",
"type": "kr"
},
{
"size": "EU 42",
"type": "eu"
},
{
"size": "US W 10",
"type": "us w"
}
]
},
"group": null
},
{
"id": "fe862238-749b-47ff-8913-b8f299beb9c4",
"market": {
"bidAskData": {
"lowestAsk": 114,
"numberOfAsks": 15,
"highestBid": 79,
"numberOfBids": 4
},
"statistics": {
"lastSale": {
"amount": 160,
"changePercentage": 0.873659,
"changeValue": 75,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 160,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "9"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087473"
}
],
"sizeChart": {
"baseSize": "9",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 9",
"type": "us m"
},
{
"size": "UK 8",
"type": "uk"
},
{
"size": "JP 27",
"type": "jp"
},
{
"size": "KR 270",
"type": "kr"
},
{
"size": "EU 42.5",
"type": "eu"
},
{
"size": "US W 10.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "9f02d4df-bd2f-4c60-a79b-df087d597bb4",
"market": {
"bidAskData": {
"lowestAsk": 119,
"numberOfAsks": 13,
"highestBid": 78,
"numberOfBids": 6
},
"statistics": {
"lastSale": {
"amount": 168,
"changePercentage": 0.430113,
"changeValue": 51,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 168,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "9.5"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087480"
}
],
"sizeChart": {
"baseSize": "9.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 9.5",
"type": "us m"
},
{
"size": "UK 8.5",
"type": "uk"
},
{
"size": "JP 27.5",
"type": "jp"
},
{
"size": "KR 275",
"type": "kr"
},
{
"size": "EU 43",
"type": "eu"
},
{
"size": "US W 11",
"type": "us w"
}
]
},
"group": null
},
{
"id": "79baa849-a2b7-487c-8468-6fa3314028ca",
"market": {
"bidAskData": {
"lowestAsk": 117,
"numberOfAsks": 11,
"highestBid": 92,
"numberOfBids": 6
},
"statistics": {
"lastSale": {
"amount": 156,
"changePercentage": -0.035684,
"changeValue": -5,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 156,
"salesLast72Hours": 1
}
},
"hidden": false,
"traits": {
"size": "10"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087497"
},
{
"type": "EAN-13",
"identifier": "2460002040929"
}
],
"sizeChart": {
"baseSize": "10",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 10",
"type": "us m"
},
{
"size": "UK 9",
"type": "uk"
},
{
"size": "JP 28",
"type": "jp"
},
{
"size": "KR 280",
"type": "kr"
},
{
"size": "EU 44",
"type": "eu"
},
{
"size": "US W 11.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "dbdbfc90-07fa-4574-be5c-8a53502fedd5",
"market": {
"bidAskData": {
"lowestAsk": 125,
"numberOfAsks": 12,
"highestBid": 45,
"numberOfBids": 3
},
"statistics": {
"lastSale": {
"amount": 124,
"changePercentage": 0.24,
"changeValue": 24,
"sameFees": true
}
},
"salesInformation": {
"lastSale": 124,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "10.5"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087503"
}
],
"sizeChart": {
"baseSize": "10.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 10.5",
"type": "us m"
},
{
"size": "UK 9.5",
"type": "uk"
},
{
"size": "JP 28.5",
"type": "jp"
},
{
"size": "KR 285",
"type": "kr"
},
{
"size": "EU 44.5",
"type": "eu"
},
{
"size": "US W 12",
"type": "us w"
}
]
},
"group": null
},
{
"id": "6f9daafc-3309-42a0-8cdb-4ffb0a60a8ba",
"market": {
"bidAskData": {
"lowestAsk": 149,
"numberOfAsks": 7,
"highestBid": 90,
"numberOfBids": 5
},
"statistics": {
"lastSale": {
"amount": 218,
"changePercentage": 0.439591,
"changeValue": 67,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 218,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "11"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087510"
}
],
"sizeChart": {
"baseSize": "11",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 11",
"type": "us m"
},
{
"size": "UK 10",
"type": "uk"
},
{
"size": "JP 29",
"type": "jp"
},
{
"size": "KR 290",
"type": "kr"
},
{
"size": "EU 45",
"type": "eu"
},
{
"size": "US W 12.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "40f04b53-43aa-4dd2-983b-64f1e2f14642",
"market": {
"bidAskData": {
"lowestAsk": 146,
"numberOfAsks": 9,
"highestBid": 99,
"numberOfBids": 5
},
"statistics": {
"lastSale": {
"amount": 163,
"changePercentage": 0,
"changeValue": 0,
"sameFees": true
}
},
"salesInformation": {
"lastSale": 163,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "11.5"
},
"gtins": [
{
"type": "EAN-13",
"identifier": "2460002040950"
},
{
"type": "UPC",
"identifier": "195242087527"
}
],
"sizeChart": {
"baseSize": "11.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 11.5",
"type": "us m"
},
{
"size": "UK 10.5",
"type": "uk"
},
{
"size": "JP 29.5",
"type": "jp"
},
{
"size": "KR 295",
"type": "kr"
},
{
"size": "EU 45.5",
"type": "eu"
},
{
"size": "US W 13",
"type": "us w"
}
]
},
"group": null
},
{
"id": "c9a34e69-96c5-4880-aa14-93d2d7cd1b11",
"market": {
"bidAskData": {
"lowestAsk": 169,
"numberOfAsks": 12,
"highestBid": 51,
"numberOfBids": 3
},
"statistics": {
"lastSale": {
"amount": 190,
"changePercentage": 0.292037,
"changeValue": 43,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 190,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "12"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087534"
},
{
"type": "EAN-13",
"identifier": "2000216738184"
}
],
"sizeChart": {
"baseSize": "12",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 12",
"type": "us m"
},
{
"size": "UK 11",
"type": "uk"
},
{
"size": "JP 30",
"type": "jp"
},
{
"size": "KR 300",
"type": "kr"
},
{
"size": "EU 46",
"type": "eu"
},
{
"size": "US W 13.5",
"type": "us w"
}
]
},
"group": null
},
{
"id": "2a080f4a-8d04-434a-9c20-46f015256bfa",
"market": {
"bidAskData": {
"lowestAsk": 214,
"numberOfAsks": 4,
"highestBid": 128,
"numberOfBids": 5
},
"statistics": {
"lastSale": {
"amount": 187,
"changePercentage": 0.680219,
"changeValue": 76,
"sameFees": false
}
},
"salesInformation": {
"lastSale": 187,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "12.5"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087541"
}
],
"sizeChart": {
"baseSize": "12.5",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 12.5",
"type": "us m"
},
{
"size": "UK 11.5",
"type": "uk"
},
{
"size": "JP 30.5",
"type": "jp"
},
{
"size": "KR 305",
"type": "kr"
},
{
"size": "EU 47",
"type": "eu"
},
{
"size": "US W 14",
"type": "us w"
}
]
},
"group": null
},
{
"id": "6286188c-47ff-4ac5-bad6-898ea136fdeb",
"market": {
"bidAskData": {
"lowestAsk": 164,
"numberOfAsks": 10,
"highestBid": 95,
"numberOfBids": 6
},
"statistics": {
"lastSale": {
"amount": 160,
"changePercentage": 0.006289,
"changeValue": 1,
"sameFees": true
}
},
"salesInformation": {
"lastSale": 160,
"salesLast72Hours": 0
}
},
"hidden": false,
"traits": {
"size": "13"
},
"gtins": [
{
"type": "UPC",
"identifier": "195242087558"
}
],
"sizeChart": {
"baseSize": "13",
"baseType": "us m",
"displayOptions": [
{
"size": "US M 13",
"type": "us m"
},
{
"size": "UK 12",
"type": "uk"
},
{
"size": "JP 31",For parsing these json datasets to something smaller see our Quick Intro to Parsing JSON with JMESPath in Python and Introduction to Parsing JSON with Python JSONPath tool introductions.
Project Setup
In this web scraping tutorial, we'll be using Python with three popular libraries:
- httpx - HTTP client library which we'll use to retrieve StockX's web pages.
- parsel - HTML parsing library which we'll use to find
<script>elements containing hidden web data. - nested_lookup - Allows to extract nested values from a dictionary by key. Since StockX's datasets are huge and nested this library will help us find the product data quickly and reliably.
These packages can be easily installed via the pip install command:
$ pip install httpx parsel nested_lookupAlternatively, feel free to swap httpx out with any other HTTP client package such as requests as we'll only need basic HTTP functions which are almost interchangeable in every library. As for, parsel, another great alternative is the How to Parse Web Data with Python and Beautifulsoup package.
Next, let's start by taking a look at how to scrape StockX's single product data.
Scraping StockX Product Data
To scrape single product data we'll be using hidden web data technique.
StockX is powered by React and Next.js technologies so we'll be looking for hidden data in the <script> elements. In particular, hidden web data is usually available in one of these two places:
<script id="__NEXT_DATA__" type="application/json">{...}</script>
<!-- or -->
<script data-name="query">window.__REACT_QUERY_STATE__ = {...};</script>To parse this HTML for these hidden datasets we can use Parsing HTML with Xpath or CSS Selectors:
import json
from parsel import Selector
def parse_hidden_Data(html: str) -> dict:
"""extract nextjs cache from page"""
selector = Selector(html)
data = selector.css("script#__NEXT_DATA__::text").get()
if not data:
data = selector.css("script[data-name=query]::text").get()
data = data.split("=", 1)[-1].strip().strip(';')
data = json.loads(data)
return dataHere we're building a parsel.Selector and looking up <script> elements based on CSS selectors.
Next, let's add HTTP capabilities to complete our product scraper and let's take it for a spin:
import asyncio
import json
import httpx
from nested_lookup import nested_lookup
from parsel import Selector
# create HTTPX client with headers that resemble a web browser
client = httpx.AsyncClient(
http2=True,
follow_redirects=True,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
},
)
def parse_nextjs(html: str) -> dict:
"""extract nextjs cache from page"""
selector = Selector(html)
data = selector.css("script#__NEXT_DATA__::text").get()
if not data:
data = selector.css("script[data-name=query]::text").get()
data = data.split("=", 1)[-1].strip().strip(";")
data = json.loads(data)
return data
async def scrape_product(url: str) -> dict:
"""scrape a single stockx product page for product data"""
response = await client.get(url)
assert response.status_code == 200
data = parse_nextjs(response.text)
# extract all products datasets from page cache
products = nested_lookup("product", data)
# find the current product dataset
try:
product = next(p for p in products if p.get("urlKey") in str(response.url))
except StopIteration:
raise ValueError("Could not find product dataset in page cache", response)
return product
# example use:
url = "https://stockx.com/nike-air-max-90-se-running-club"
print(asyncio.run(scrape_product(url)))
import asyncio
import json
from nested_lookup import nested_lookup
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="YOUR SCRAPFLY API KEY", max_concurrency=10)
def parse_nextjs(result: ScrapeApiResponse) -> dict:
"""extract nextjs cache from page"""
data = result.selector.css("script#__NEXT_DATA__::text").get()
if not data:
data = result.selector.css("script[data-name=query]::text").get()
data = data.split("=", 1)[-1].strip().strip(";")
data = json.loads(data)
return data
async def scrape_product(url: str) -> dict:
"""scrape a single stockx product page for product data"""
result = await scrapfly.async_scrape(
ScrapeConfig(
url=url,
render_js: True,
proxy_pool: "public_residential_pool",
country="US",
asp=True,
)
)
data = parse_nextjs(result)
# extract all products datasets from page cache
products = nested_lookup("product", data)
# find the current product dataset
try:
product = next(p for p in products if p.get("urlKey") in result.context["url"])
except StopIteration:
raise ValueError("Could not find product dataset in page cache", result.context)
return product
# example use:
url = "https://stockx.com/nike-air-max-90-se-running-club"
print(asyncio.run(scrape_product(url)))Above, in just a few lines of code, we've scraped the entire product's dataset available on StockX's website.
Now that we can scrape a single item, let's take a look at how to find products on StockX to scrape all data or just select categories.
Scraping Product Prices
In the above section, we were able to scrape StockX product pages successfully. The extracted data includes various details about its specifications and variants. However, it's missing an essential detail: pricing!
The product details we extracted earlier were rendered on the server side. Hence, it was accessible upon requesting the product page URL. On the other hand, pricing data are loaded through a GraphQL endpoint that's dynamically sent using JavaSciprt. Therefore, pricing data aren't accessible in the script tag extracted earlier.
To view the GraphQL endpoint for retrieving price data, follow the below steps:
Open the browser developer tools by clicking the F12 key.
- Head over to the network tab and filter by
Fetch/XHRrequests. - Hard reload the product web page.
Upon following the above steps, you will find the below XHR call captured:
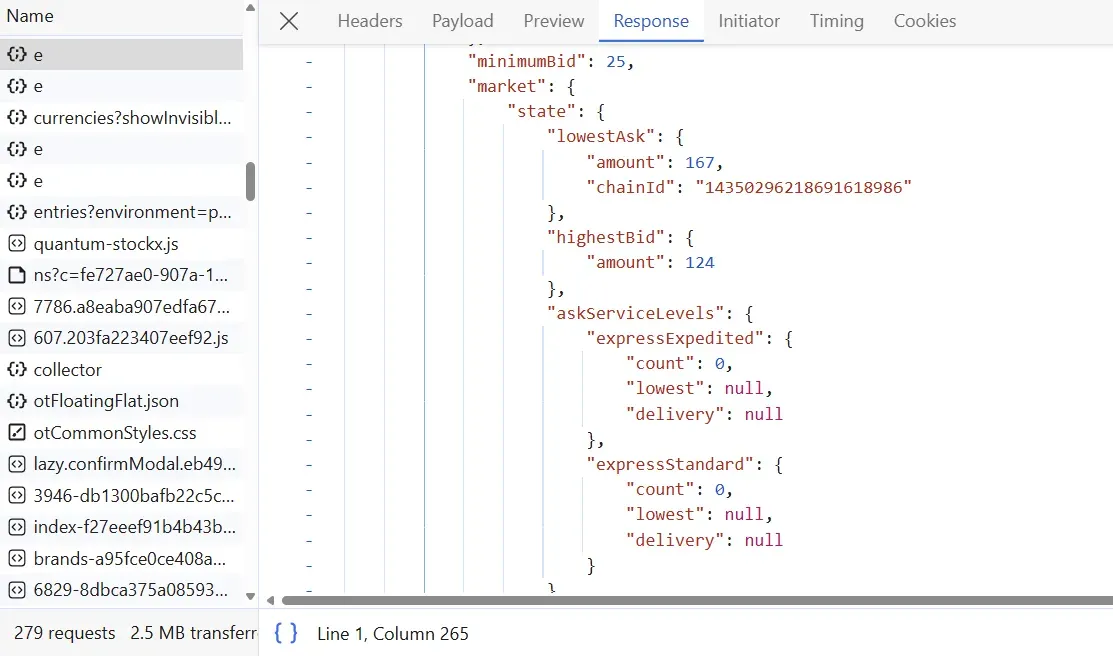
To scrape StockX product pricing data, we'll extract the above XHR response:
import json
import asyncio
from typing import Dict
from nested_lookup import nested_lookup
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
def parse_pricing(result: ScrapeApiResponse, sku: str = None) -> Dict:
"""extractproduct data from xhr responses"""
_xhr_calls = result.scrape_result["browser_data"]["xhr_call"]
json_calls = []
for xhr in _xhr_calls:
if xhr["response"]["body"] is None:
continue
try:
data = json.loads(xhr["response"]["body"])
except json.JSONDecodeError:
continue
json_calls.append(data)
for xhr in json_calls:
if (
"data" not in xhr
or "product" not in xhr["data"]
or "uuid" not in xhr["data"]["product"]
):
continue
if sku == xhr["data"]["product"]["uuid"]:
data = xhr["data"]["product"]
return {
"minimumBid": data["minimumBid"],
"market": data["market"],
"variants": data["variants"],
}
return None
async def scrape_product(url: str) -> dict:
"""scrape a single stockx product page for product data"""
result = await scrapfly.async_scrape(
ScrapeConfig(
url=url,
render_js=True,
proxy_pool="public_residential_pool",
country="US",
asp=True,
rendering_wait=5000,
wait_for_selector="//h2[@data-testid='trade-box-buy-amount']",
)
)
# previous product parsing logic
data = parse_nextjs(result)
products = nested_lookup("product", data)
product = next(p for p in products if p.get("urlKey") in result.context["url"])
# extract product price
product["pricing"] = parse_pricing(result, product["id"])
return product["pricing"]Run the code
if __name__ == "__main__":
pricing = asyncio.run(
scrape_product("https://stockx.com/nike-air-max-90-se-running-club")
)
print("extracted pricing details")
with open("pricing.json", "w") as f:
json.dump(pricing, f, indent=2, ensure_ascii=False)Above, we request the product page with JavaScript rendering after ensuring the pricing details have loaded correctly. Then, we use the parse_pricing to parse the XHR response.
Here's an example output of the results extracted:
Example output
{
"minimumBid": 25,
"market": {
"state": {
"lowestAsk": {
"amount": 179,
"chainId": "14484651581140458078"
},
"highestBid": {
"amount": 124
},
"askServiceLevels": {
"expressExpedited": {
"count": 0,
"lowest": null,
"delivery": null
},
"expressStandard": {
"count": 0,
"lowest": null,
"delivery": null
}
},
"numberOfAsks": 34,
"numberOfBids": 40
},
"salesInformation": {
"lastSale": 169,
"salesLast72Hours": 0
},
"statistics": {
"lastSale": {
"amount": 183,
"changePercentage": 0.4022,
"changeValue": 74,
"sameFees": null
}
}
},
"variants": [
{
"id": "1f07d59f-988e-48ac-8c44-24efa4543118",
"market": {
"state": {
"lowestAsk": null,
"highestBid": {
"amount": 25
},
"askServiceLevels": {
"expressExpedited": {
"count": 0,
"lowest": null,
"delivery": null
},
"expressStandard": {
"count": 0,
"lowest": null,
"delivery": null
}
},
"numberOfAsks": 0,
"numberOfBids": 1
},
"salesInformation": {
"lastSale": 110,
"salesLast72Hours": 0
},
"statistics": {
"lastSale": {
"amount": 110,
"changePercentage": -1.4817,
"changeValue": -162,
"sameFees": null
}
}
}
},
.....
]
}Note that the above approach is available using headless browsers. For more, refer to our guide on web scraping background requests.
Scraping Stockx Search
To discover products we have two choices: sitemaps and search.
Sitemaps are ideal for discovering all products and they can usually be found by inspecting /robots.txt URL. For example, StockX's robots.txt indicates this:
Sitemap: https://stockx.com/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/it-it/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/de-de/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/fr-fr/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/ja-jp/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/zh-cn/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/en-gb/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/ko-kr/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/es-es/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/es-mx/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/es-us/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/zh-tw/sitemap/sitemap-index.xml
Sitemap: https://stockx.com/fr-ca/sitemap/sitemap-index.xmlSo we could scrape /sitemap/sitemap-index.xml where every product URL is located. However, if we want to narrow down our scope and scrape specific items then we can scrape StockX's search pages. Let's take a look how can we do that.
To start, we can see that StockX's search is capable of searching by product category and query:
Each of these search pages can be further refined and sorted which results in a unique URL.
For this example, let's take the top sold apparel items that match the query "indigo":
Which takes us to the final url stockx.com/search/apparel?s=indigo
To scrape this we'll be using the same hidden web data approach as before. The hidden data is located in the same place so we can reuse our parse_hidden_data() function though this time around it only contains product preview data rather than the whole datasets.
import asyncio
import json
import math
from typing import Dict, List
import httpx
from nested_lookup import nested_lookup
from parsel import Selector
# create HTTPX client with headers that resemble a web browser
client = httpx.AsyncClient(
http2=True,
follow_redirects=True,
limits=httpx.Limits(max_connections=3), # keep this low to avoid being blocked
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
},
)
# From previous chapter:
def parse_nextjs(html: str) -> dict:
"""extract nextjs cache from page"""
selector = Selector(html)
data = selector.css("script#__NEXT_DATA__::text").get()
if not data:
data = selector.css("script[data-name=query]::text").get()
data = data.split("=", 1)[-1].strip().strip(";")
data = json.loads(data)
return data
async def scrape_search(url: str, max_pages: int = 25) -> List[Dict]:
"""Scrape StockX search"""
print(f"scraping first search page: {url}")
first_page = await client.get(url)
assert first_page.status_code == 200, "scrape was blocked" # this should be retried, handled etc.
# parse first page for product search data and total amount of pages:
data = parse_nextjs(first_page.text)
_first_page_results = nested_lookup("results", data)[0]
_paging_info = _first_page_results["pageInfo"]
total_pages = _paging_info["pageCount"] or math.ceil(_paging_info["total"] / _paging_info["limit"]) # note: pageCount can be missing but we can calculate it ourselves
if max_pages < total_pages:
total_pages = max_pages
product_previews = [edge["node"] for edge in _first_page_results["edges"]]
# then scrape other pages concurrently:
print(f" scraping remaining {total_pages - 1} search pages")
_other_pages = [ # create GET task for each page url
asyncio.create_task(client.get(f"{first_page.url}&page={page}"))
for page in range(2, total_pages + 1)
]
for response in asyncio.as_completed(_other_pages): # run all tasks concurrently
response = await response
data = parse_nextjs(response.text)
_page_results = nested_lookup("results", data)[0]
product_previews.extend([edge["node"] for edge in _page_results["edges"]])
return product_previews
# example run
result = asyncio.run(scrape_search("https://stockx.com/search?s=nike", max_pages=2))
print(json.dumps(result, indent=2))import asyncio
import json
import math
from typing import Dict, List
from nested_lookup import nested_lookup
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="YOUR SCRAPFLY KEY", max_concurrency=10)
def parse_nextjs(result: ScrapeApiResponse) -> dict:
"""extract nextjs cache from page"""
data = result.selector.css("script#__NEXT_DATA__::text").get()
if not data:
data = result.selector.css("script[data-name=query]::text").get()
data = data.split("=", 1)[-1].strip().strip(";")
data = json.loads(data)
return data
async def scrape_search(url: str, max_pages: int = 25) -> List[Dict]:
"""Scrape StockX search"""
print(f"scraping first search page: {url}")
first_page = await scrapfly.async_scrape(
ScrapeConfig(
url=url,
country="US",
render_js: True,
proxy_pool: "public_residential_pool",
asp=True,
)
)
# parse first page for product search data and total amount of pages:
data = parse_nextjs(first_page)
_first_page_results = nested_lookup("results", data)[0]
_paging_info = _first_page_results["pageInfo"]
total_pages = _paging_info["pageCount"] or math.ceil(_paging_info["total"] / _paging_info["limit"])
if max_pages < total_pages:
total_pages = max_pages
product_previews = [edge["node"] for edge in _first_page_results["edges"]]
# then scrape other pages concurrently:
print(f" scraping remaining {total_pages - 1} search pages")
_other_pages = [
ScrapeConfig(
url=f"{first_page.context['url']}&page={page}",
render_js: True,
proxy_pool: "public_residential_pool",
country="US",
asp=True,
)
for page in range(2, total_pages + 1)
]
async for result in scrapfly.concurrent_scrape(_other_pages):
data = parse_nextjs(result)
_page_results = nested_lookup("results", data)[0]
product_previews.extend([edge["node"] for edge in _page_results["edges"]])
return product_previews
# example run
result = asyncio.run(scrape_search("https://stockx.com/search?s=nike"))
print(json.dumps(result, indent=2))While this product preview data offers a lot of data we might want to scrape the entire product dataset using the product scraper we wrote in the previous chapter. See the urlKey field for the full product URL.
Bypass StockX Blocking with Scrapfly
StockX is a popular website and it's not uncommon for them to block scraping attempts. To scale up our scraper and bypass blocking we can use Scrapfly's web scraping API which fortifies scrapers against blocking and much more!

For more, explore web scraping API and its documentation.
Using Python-SDK we can easily integrate Scrapfly into our Python scrapers:
from scrapfly import ScrapflyClient, ScrapeConfig
scrapfly = ScrapflyClient(key="YOUR SCRAPFLY KEY")
result = scrapfly.scrape(ScrapeConfig(
"https://stockx.com/search/apparel/top-selling?s=indigo",
# anti scraping protection bypass
asp=True,
# proxy country selection
country="US",
# we can enable features like:
# cloud headless browser use
render_js=True,
# screenshot taking
screenshots={"all": "fullpage"},
))
# full result data
print(result.content) # html body
print(result.selector.css("h1")) # CSS selector and XPath parser built-inFor more see the complete stockx scraper code using Scrapfly on our Github repository:
FAQ
Is it legal to scrape StockX.com?
Yes, it is legal to scrape StockX.com. StockX e-commerce data is publically available and as long as the scraper doesn't inflict damages to the website it's perfectly legal to scrape.
Can StockX.com be crawled?
Yes, StockX.com can be crawled. Crawling is an alternative web scraping approach where the scraper is capable of discovering pages on its own. StockX offers sitemaps and recommended product areas that can be used to develop crawling logic. For more see our Crawling With Python introduction.
StockX Scraping Summary
In this guide, we've learned how to scrape StockX.com using Python and a few community packages. For this, we've used the hidden web data scraping technique where instead of traditional HTML parsing we retrieve the product HTML pages and extracted Javascript cache data.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.
With just a few lines of Python code, we've extracted the entire product dataset from StockX.com.
We've also taken a look at how to discover StockX product pages using sitemaps or search pages.
To scale up our scraper we've also taken a look at Scrapfly API which fortifies scrapers against blocking and much more - try it out for free!


