

SimilarWeb is a leading platform specializing in web analytics, acting as a directory for worldwide website traffic. Imagine the insights and SEO impact would scraping SimilarWeb allow for!
In this guide, we'll explain how to scrape SimilarWeb through a step-by-step guide. We'll scrape comprehensive domain traffic insights, websites comparing data, sitemaps, and trending industry domains. Let's get started!
Key Takeaways
Master similarweb scraper techniques using Python with httpx and parsel, extracting domain insights, competitor data, and SEO rankings for comprehensive market analysis.
- Implement similarweb scraper solutions with advanced anti-detection techniques and proxy rotation
- Use specialized tools like ScrapFly for automated SimilarWeb data extraction with anti-blocking features
- Configure proper headers, user agents, and request patterns to avoid detection
- Apply rate limiting and request delays to prevent blocking and maintain access
- Use residential proxies and IP rotation for reliable SimilarWeb data collection
- Implement error handling and retry mechanisms for robust scraping operations
Latest SimilarWeb Scraper Code
Why Scrape SimilarWeb?
Web scraping SimilarWeb provides us with detailed valuable insights into websites' traffic, which can be valuable across different aspects.
- Competitor Analysis
One of the key features of web analytics is analyzing the industry peers and benchmarking against their traffic. Scraping SimilarWeb enables such data retrieval, allowing business to fine-tune their strategies to meet their competitors and gain a competitive edge.
- SEO and Keyword Analysis
Search Engine Optimization (SEO) is crucial for driving traffic into the domains. SimilarWeb data extraction provides comprehensive insights into the SEO keywords and search engine rankings, allowing for better online presence and visibility.
- Data-Driven Decision Making The search trends are aggressive and fast-changing. Therefore, utilizing scraping SimilarWeb for data-based insights is crucial for supporting decision-making and defining strategies.
Have a look at our comprehensive guide on web scraping use cases for further details.

Setup
To web scrape SimilarWeb, we'll use Python with a few community packages.
- httpx: To request SimilarWeb pages and get the data as HTML. Feel free to replace How to Web Scrape with HTTPX and Python with any other HTTP client, such as requests.
- parsel: To parse the HTML retrieved using web selectors, such as Parsing HTML with Xpath and Parsing HTML with CSS Selectors.
- Quick Intro to Parsing JSON with JMESPath in Python: To refine the JSON datasets we get and remove the unnecessary details.
- asyncio: To increase our SimilarWeb scraper speed by running it asynchronously.
- loguru: Optional prerequisite to monitor our code through colored terminal outputs.
Since asyncio comes pre-installed in Python, we'll only have to install the other packages using the following pip command:
pip install httpx parsel jmespath loguruHow to Discover SimilarWeb Pages?
How to Crawl the Web with Python sitemaps is a great way to discover and navigate pages on a website. Since they direct search engines for organized indexing, we can use them for scraping, too!
The SimilarWeb sitemaps can be found at similarweb.com/robots.txt, which looks like this:
User-agent: *
Disallow: */search/
Disallow: */adult/*
Disallow: /corp/*.pdf$
Disallow: /corp/solution/
Disallow: /corp/lps/
Disallow: /corp/get-data/
Disallow: /silent-login/
Disallow: /signin-oidc/
Disallow: /signout-oidc/
Sitemap: https://www.similarweb.com/corp/sitemap_index.xml
Sitemap: https://www.similarweb.com/blog/sitemap_index.xml
Sitemap: https://www.similarweb.com/sitemaps/sitemap_index.xml.gz
#
# sMMMMMMMMs
# MNdmMh+-``.:ohNM
# MNy/ .sMd- `/yNM
# MNo` sMo .oNM
# Md - sMo -dM
# 'MM+ -dMm+. yMM'
# MN` `:yNMd/ .NM
# MN- `-hMy :MM
# MMN- sMd` -NM
# Md:` `sh`` .sMM
# Mdms+-.```-hmMds
# oMMMMMMMMo
#
# OFFICIAL MEASURE OF THE DIGITAL WORLD
#Each of the above sitemap indexes represents a group of related sitemaps. Let's explore the latest sitemap /sitemaps/sitemap_index.xml.gz. It's a gz compressed file to save bandwidth, which looks like this after extracting:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
....
<sitemap>
<loc>https://www.similarweb.com/sitemaps/top-websites-trending/part-00000.gz</loc>
<lastmod>2023-08-17</lastmod>
</sitemap>
<sitemap>
<loc>https://www.similarweb.com/sitemaps/website/part-00000.gz</loc>
<lastmod>2023-08-17</lastmod>
</sitemap>
<sitemap>
<loc>https://www.similarweb.com/sitemaps/website_competitors/part-00000.gz</loc>
<lastmod>2023-08-17</lastmod>
</sitemap>
</sitemapindex>We have reached another sitemap index for several website insight pages. Each sitemap located in a loc element provides further scraping targets:
[
"https://www.similarweb.com/top-websites/food-and-drink/groceries/trending/",
"https://www.similarweb.com/top-websites/gambling/bingo/trending/",
"https://www.similarweb.com/top-websites/travel-and-tourism/transportation-and-excursions/trending/",
"https://www.similarweb.com/top-websites/health/health-conditions-and-concerns/trending/",
"https://www.similarweb.com/top-websites/finance/investing/trending/",
....
]
The above URLs represent website ranking pages for different industries. Let's scrape them next!How to Scrape SimilarWeb Trending Websites?
The trending website pages on SimilarWeb represent two related insights:
- Trending: The month's trending websites and their traffic changes.
- Ranking: The industry's overall website rankings with essential traffic insights.
Let's scrape the trending website section. Go to any industry trending page, such as the one for software, and you will get a similar web page:
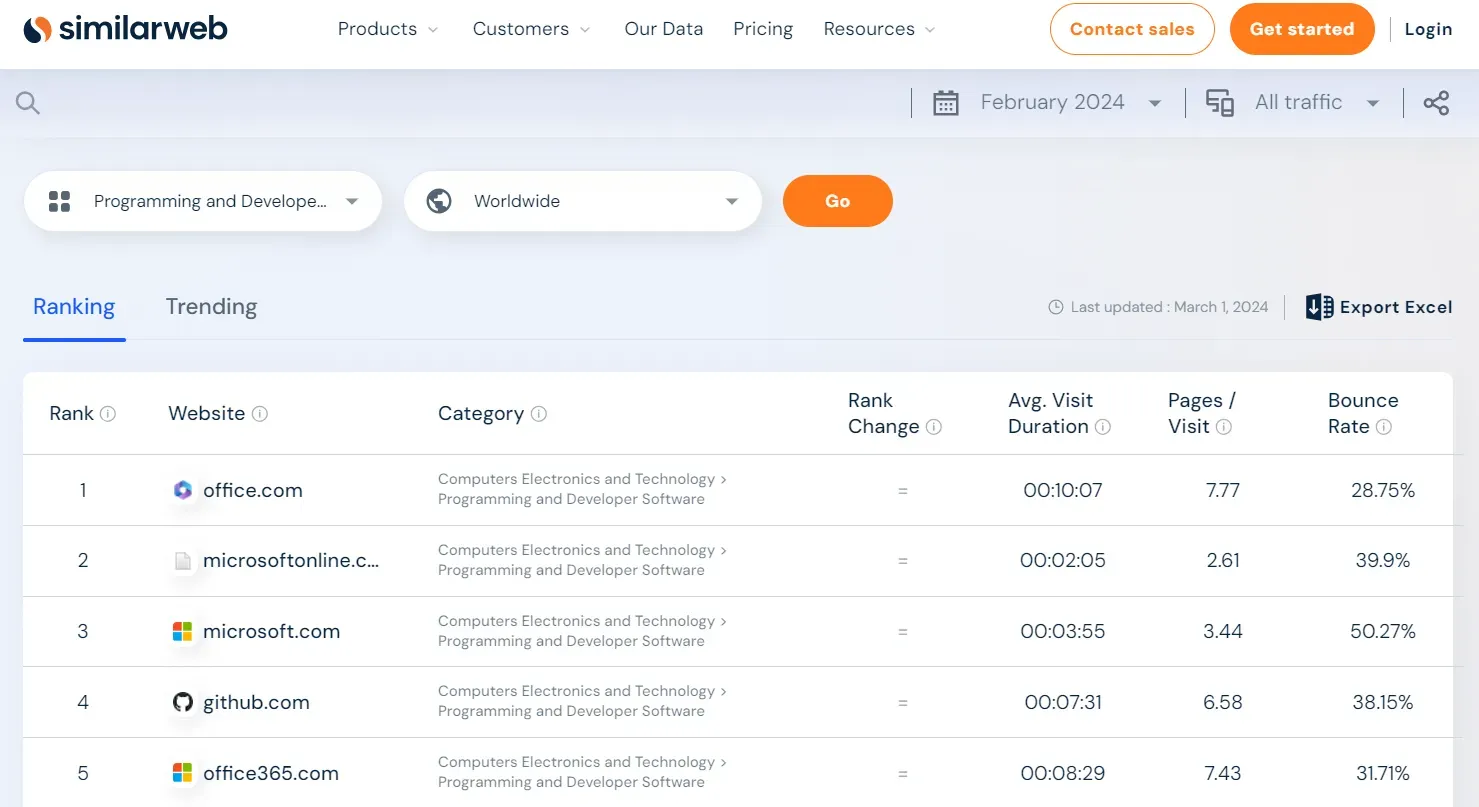
We can parse the above SimilarWeb page using selectors to scrape it. However, there is a better approach: hidden web data.

To locate the website ranking hidden web data, follow the below steps:
- Open the browser developer tools by clicking the
F12key. - Search for the XPath selector:
//script[@id='dataset-json-ld'].
After following the above steps, you will find the below data:

The above data is the same on the web page but before getting rendered into the HTML. To scrape it, we'll select its associated script tag and then parse it:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br"
},
)
def parse_trending_data(response: Response) -> List[Dict]:
"""parse hidden trending JSON data from script tags"""
selector = Selector(response.text)
json_data = json.loads(selector.xpath("//script[@id='dataset-json-ld']/text()").get())["mainEntity"]
data = {}
data["name"] = json_data["name"]
data["url"] = str(response.url)
data["list"] = json_data["itemListElement"]
return data
async def scrape_trendings(urls: List[str]) -> List[Dict]:
"""parse trending websites data"""
to_scrape = [client.get(url) for url in urls]
data = []
for response in asyncio.as_completed(to_scrape):
response = await response
category_data = parse_trending_data(response)
data.append(category_data)
log.success(f"scraped {len(data)} trneding categories from similarweb")
return dataimport asyncio
import json
from typing import List, Dict
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_trending_data(response: ScrapeApiResponse) -> List[Dict]:
"""parse hidden trending JSON data from script tags"""
selector = response.selector
json_data = json.loads(selector.xpath("//script[@id='dataset-json-ld']/text()").get())["mainEntity"]
data = {}
data["name"] = json_data["name"]
data["url"] = response.scrape_result["url"]
data["list"] = json_data["itemListElement"]
return data
async def scrape_trendings(urls: List[str]) -> List[Dict]:
"""parse trending websites data"""
to_scrape = [ScrapeConfig(url, asp=True, country="US") for url in urls]
data = []
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
category_data = parse_trending_data(response)
data.append(category_data)
log.success(f"scraped {len(data)} trneding categories from similarweb")
return data Run the code
async def run():
data = await scrape_trendings(
urls=[
"https://www.similarweb.com/top-websites/computers-electronics-and-technology/programming-and-developer-software/",
"https://www.similarweb.com/top-websites/computers-electronics-and-technology/social-networks-and-online-communities/",
"https://www.similarweb.com/top-websites/finance/investing/"
]
)
# save the data to a JSON file
with open("trendings.json", "w", encoding="utf-8") as file:
json.dump(data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())We use the previously defined httpx client and define additional functions:
parse_trending_data: For extracting the page JSON data from the hiddenscripttag, organizing the data by removing the JSON schema details and adding the URL.scrape_trendings: For adding the page URLs to a list and requesting them concurrently.
Here is a sample output of the above SimilarWeb scraping code:
[
{
"name": "Most Visited Social Media Networks Websites",
"url": "https://www.similarweb.com/top-websites/computers-electronics-and-technology/social-networks-and-online-communities/",
"list": [
{
"@type": "ListItem",
"position": 1,
"item": {
"@type": "WebSite",
"name": "facebook.com",
"url": "https://www.similarweb.com/website/facebook.com/"
}
},
....
]
},
....
]Next, let's explore the exciting part of our SimilarWeb scraper: website analytics! But before this, we must solve a SimilarWeb scraping blocking issue: validation challenge.
How to Avoid SimilarWeb Validation Challenge?
The SimilarWeb validation challenge is a web scraping blocking mechanism that blocks HTTP requests from clients without JavaScript support. It's a JavaScript challenge that's automatically bypassed after 5 seconds when requesting the domain for the first time:
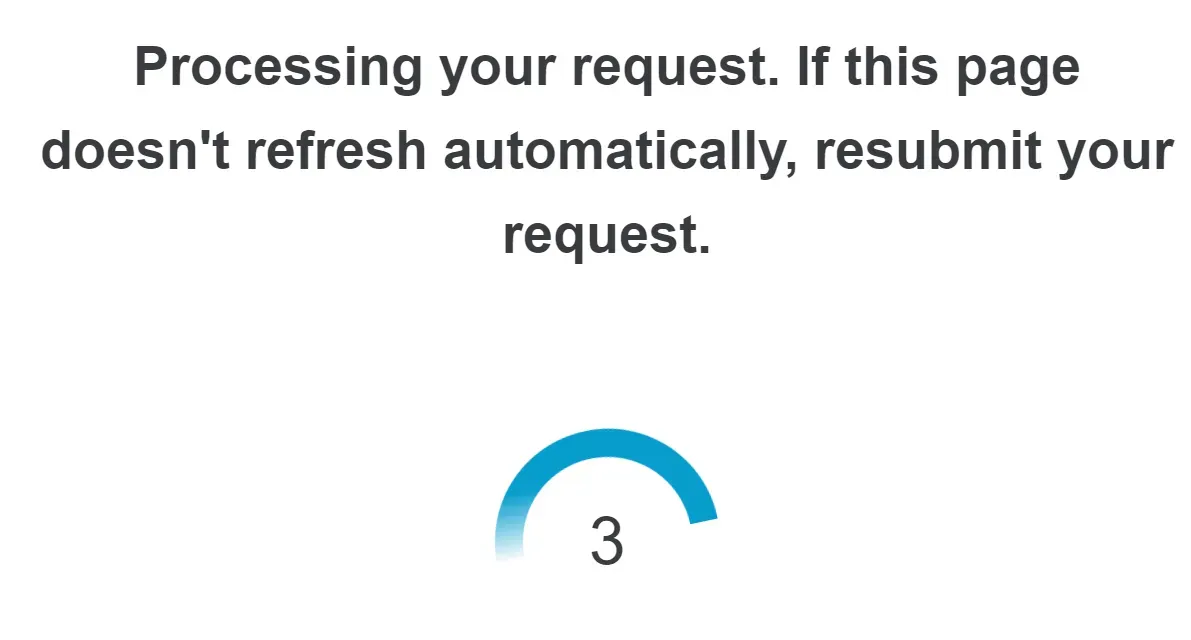
Since we scrape SimilarWeb with an HTTP client that doesn't support JavaScript (httpx), requests sent to pages with this challenge will be blocked due to not evaluating it:
from httpx import Client
client = Client(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
response = client.get("https://www.similarweb.com/website/google.com/")
print(response.text)
"""
<!DOCTYPE html><html><head><meta charset="utf-8">
<title>Challenge Validation</title>
<script type="text/javascript">function cp_clge_done(){location.reload(true);}</script>
<script src="/_sec/cp_challenge/sec-cpt-int-4-3.js" async defer></script>
<script type="text/javascript">sessionStorage.setItem('data-duration', 5);</script>
</html>
"""To avoid the SimilarWeb validation challenge, we can use a headless browser to complete the challenge automatically using JavaScript. However, there's a trick we can use to bypass the challenge without JavaScript: cookies!
When the validation challenge is solved, the website cookies are updated with the challenge state, so it's not triggered again.
We can make use of cookies for web scraping to bypass the validation challenge automatically! To do this, we have to get the cookie value:
- Go to any protected SimilarWeb page with the challenge.
- Open the browser developer tools by pressing the
F12key. - Select the
Applicationtab and choose cookies. - Copy the
_abckcookie value, which is responsible for the challenge.
After following the above steps, you will find the SimilarWeb saved cookies:
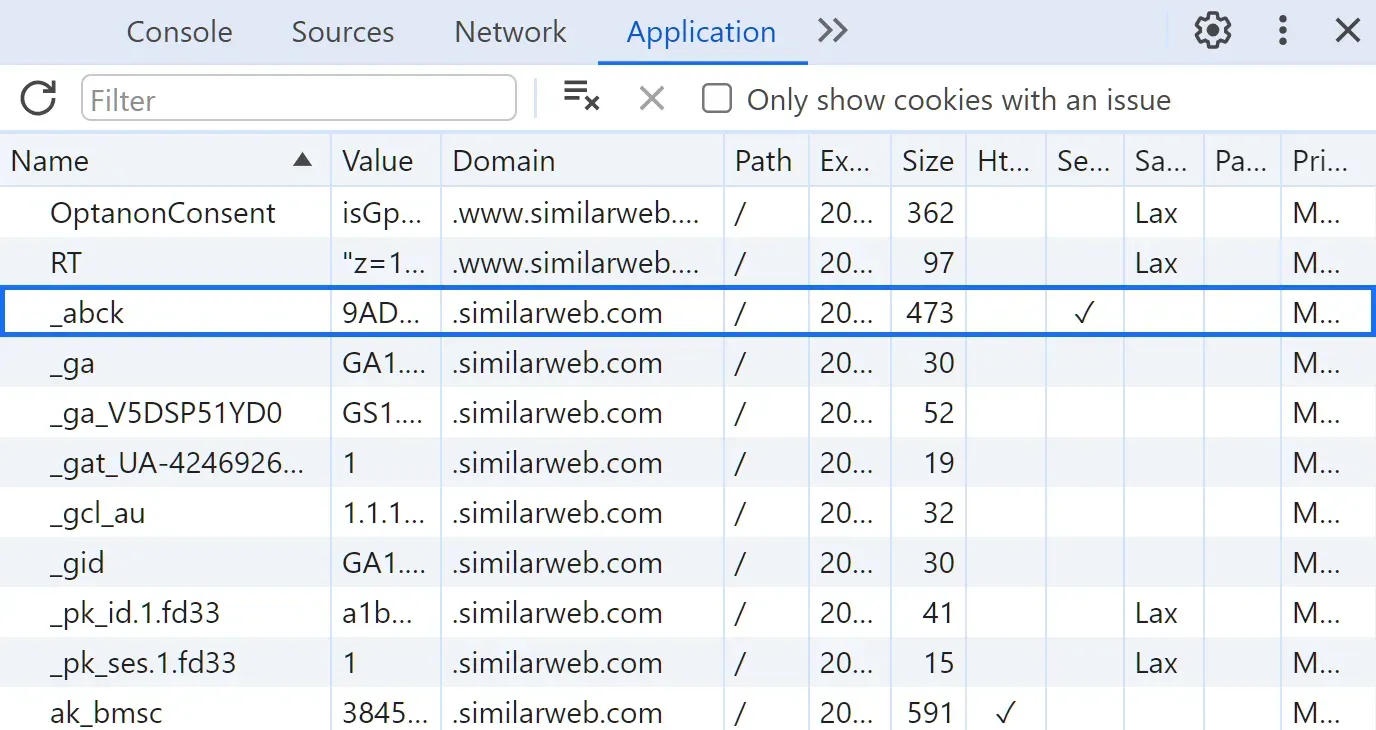
Adding the _abck cookie to the requests will authorize them against the challenge:
from httpx import Client
client = Client(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Cookie": "_abck=85E72C5791B36ED327B311F1DC7461A6~0~YAAQHPR6XIavCzyOAQAANeDuYgs83VF+IZs6MdB2WGsdsp5d89AWqe1hI+IskJ6V24OYvokUZSIn2Om9PATl5rqminoOTHQYZAMWO5Om8bcXlT3q2D9axmG+YQkS/77h/7O98vFFDrFX8Jns/upO+RbomHm7SxQ0IGk0yS80GGbWBQoSkxN+770ltBb9vdyT/7ShUBl3eKz/iLfyMSe4SyOxymE0pQL0pch0FJhvCiC2CD4asMBXGBNMQv2qvA553uO9bwz4Yr1X/7zLPOm6Vn2bz242O7rephGPmVud25Yc3Khs0oEqiQ4pgMvCy/NGIXTlVKN8anBc5QlnqGw7dq8kLqDrID9HqzbqusS9p5gkNUd4A2QJXDj80pjB9k4SWitpn1zRhsUNUYzrfvHMeGiDZhNuTYSq3sMcYg==~-1~-1~-1"
},
)
response = client.get("https://www.similarweb.com/website/google.com/")
print(response.text) # full HTML responseWe can successfully bypass the validation challenge. However, the cookie value has to be roated as it can expire. The rotation logic can also be automated with a headless browser for better rotation efficiency.
How to Scrape SimilarWeb Website Analytics?
The SimilarWeb website analytics pages is a powerful feature that includes comprehensive insights about the domain, including:
- Ranking: The domain's category, country, and global rank.
- Traffic: Engagement analysis including total visits, bounce rate, and visit duration.
- Geography: The domain's traffic by top countries.
- Demographics: The visitors' composition distribution by age and gender.
- Interests: The visitors' interests by categories and topics.
- Competitors: The domain's competitors and alternatives and their similarities.
- Traffic sources: The domain's traffic by its source, such as search, direct, or Web Scraping Emails using Python.
- Keywords: Top keywords visitors use to search the domain.
First, let's look at what the website analysis page on our target website looks like by targeting a specific domain: How to Scrape Google Search Results in 2026. Go to the domain page SimilarWeb, and you will get a page similar to this:
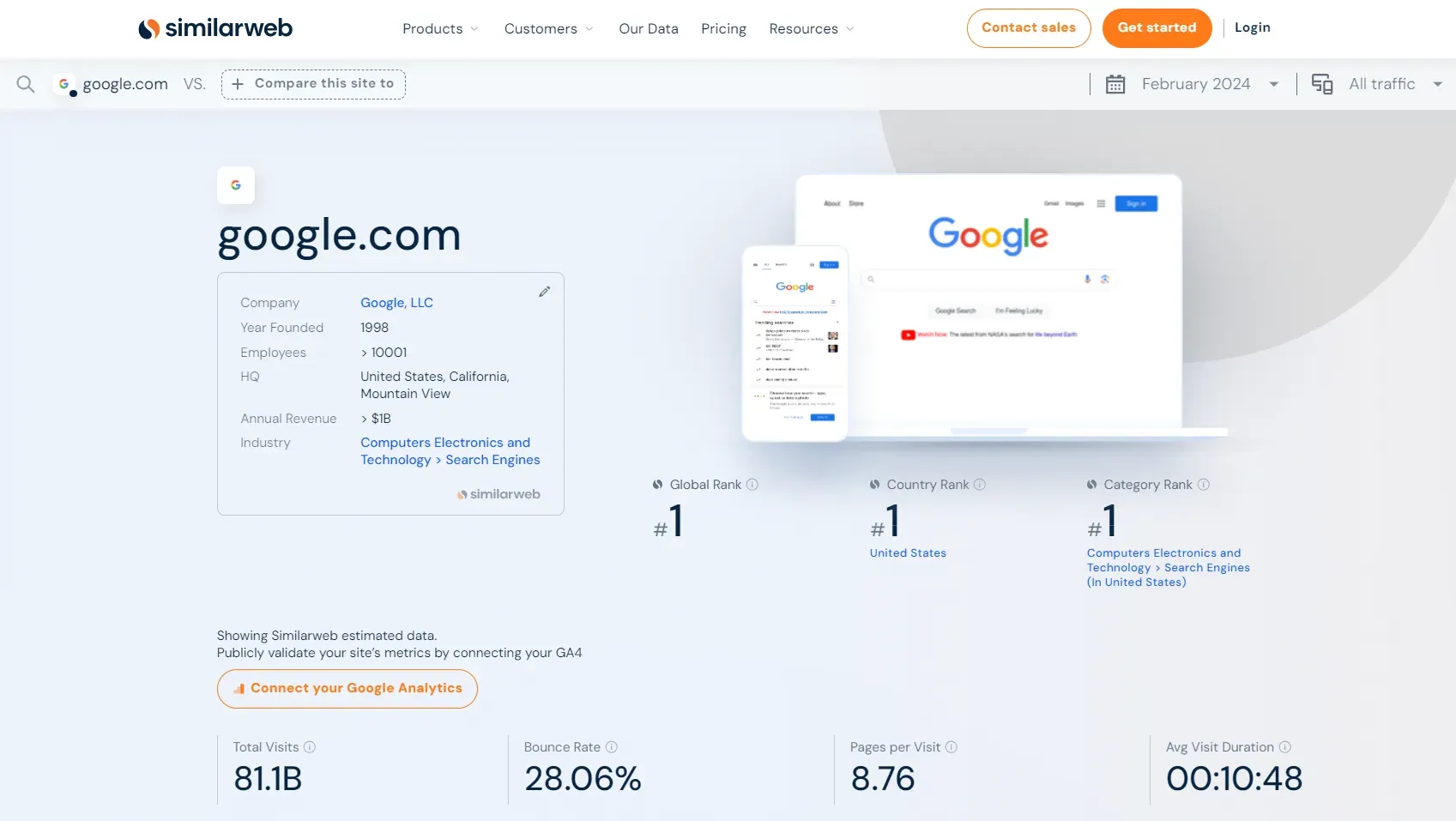
The above page data are challenging to scrape using selectors, as they are mostly located in charts and graphs. Therefore, we'll use the hidden web data approach.
Search through the HTML using the following XPath selector:
//script[contains(text(), 'window.__APP_DATA__')]. The script tag found contains a comprehensive JSON dataset with the domain analysis data:

To scrape SimilarWeb traffic analytics pages, we'll select this script tag and parse the inside JOSN data:
import re
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Cookie": "_abck=D2F915DBAC628EA7C01A23D7AA5DF495~0~YAAQLvR6XFLvH1uOAQAAJcI+ZgtcRlotheILrapRd0arqRZwbP71KUNMK6iefMI++unozW0X7uJgFea3Mf8UpSnjpJInm2rq0py0kfC+q1GLY+nKzeWBFDD7Td11X75fPFdC33UV8JHNmS+ET0pODvTs/lDzog84RKY65BBrMI5rpnImb+GIdpddmBYnw1ZMBOHdn7o1bBSQONMFqJXfIbXXEfhgkOO9c+DIRuiiiJ+y24ubNN0IhWu7XTrcJ6MrD4EPmeX6mFWUKoe/XLiLf1Hw71iP+e0+pUOCbQq1HXwV4uyYOeiawtCcsedRYDcyBM22ixz/6VYC8W5lSVPAve9dabqVQv6cqNBaaCM2unTt5Vy+xY3TCt1s8a0srhH6qdAFdCf9m7xRuRsi6OarPvDYjyp94oDlKc0SowI=~-1~-1~-1"
},
)
def parse_hidden_data(response: Response) -> List[Dict]:
"""parse website insights from hidden script tags"""
selector = Selector(response.text)
script = selector.xpath("//script[contains(text(), 'window.__APP_DATA__')]/text()").get()
data = json.loads(re.findall(r"(\{.*?)(?=window\.__APP_META__)", script, re.DOTALL)[0])
return data
async def scrape_website(domains: List[str]) -> List[Dict]:
"""scrape website inights from website pages"""
# define a list of similarweb URLs for website pages
urls = [f"https://www.similarweb.com/website/{domain}/" for domain in domains]
to_scrape = [client.get(url) for url in urls]
data = []
for response in asyncio.as_completed(to_scrape):
response = await response
website_data = parse_hidden_data(response)["layout"]["data"]
data.append(website_data)
log.success(f"scraped {len(data)} website insights from similarweb website pages")
return dataimport re
import asyncio
import json
from typing import List, Dict
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_hidden_data(response: ScrapeApiResponse) -> List[Dict]:
"""parse website insights from hidden script tags"""
selector = response.selector
script = selector.xpath("//script[contains(text(), 'window.__APP_DATA__')]/text()").get()
data = json.loads(re.findall(r"(\{.*?)(?=window\.__APP_META__)", script, re.DOTALL)[0])
return data
async def scrape_website(domains: List[str]) -> List[Dict]:
"""scrape website inights from website pages"""
# define a list of similarweb URLs for website pages
urls = [f"https://www.similarweb.com/website/{domain}/" for domain in domains]
to_scrape = [ScrapeConfig(url, asp=True, country="US") for url in urls]
data = []
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
website_data = parse_hidden_data(response)["layout"]["data"]
data.append(website_data)
log.success(f"scraped {len(data)} website insights from similarweb website pages")
return dataRun the code
async def run():
data = await scrape_website(
domains=["google.com", "twitter.com", "instagram.com"]
)
# save the data to a JSON file
with open("websites.json", "w", encoding="utf-8") as file:
json.dump(data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())[% info "🤖 Update the "_abck" cookie before running the above code, as it may expire, to avoid challenge validation blocking or use the ScrapFly code tab instead." %]
Let's break down the above SimilarWeb scraping code:
parse_hidden_data: For selecting thescripttag that contains the domain analysis data and then parsing the JSON data using regex to execute the HTML tags.scrape_website: For creating the domain analytics page URLs on SimilarWeb and then requesting them concurrently while utilizing the parsing logic.
Here's an example output of the results we got:
Example output
[
{
"interests": {
"interestedWebsitesTotalCount": 10,
"topInterestedWebsites": [
{
"domain": "facebook.com",
"icon": "https://site-images.similarcdn.com/image?url=facebook.com&t=2&s=1&h=be773d6b77aa3d59b6a671c5c27ad729b1ae77400e89776e2f749cce6b926c4b"
},
....
],
"topInterestedTopics": [
"news",
"software",
"online",
"games",
"porn"
],
"topInterestedCategories": [
"games/video_games_consoles_and_accessories",
"adult",
"computers_electronics_and_technology/computers_electronics_and_technology",
"computers_electronics_and_technology/programming_and_developer_software",
"news_and_media"
]
},
"competitors": {
"topSimilarityCompetitors": [
{
"domain": "twitter.com",
"icon": "https://site-images.similarcdn.com/image?url=twitter.com&t=2&s=1&h=05438debe431144d9c727828570d1754a25bd9286bc14f3aa65a4f05b9057e25",
"visitsTotalCount": 5761605539,
"categoryId": "computers_electronics_and_technology/social_networks_and_online_communities",
"categoryRank": 3,
"affinity": 1,
"isDataFromGa": false
},
....
]
},
"searchesSource": {
"organicSearchShare": 0.9975672362655021,
"paidSearchShare": 0.002432763734497856,
"keywordsTotalCount": 17947,
"topKeywords": [
{
"name": "instagram",
"estimatedValue": 32674904.69996643,
"volume": 101034090,
"cpc": 0.204557390625
},
....
]
},
"incomingReferrals": {
"referralSitesTotalCount": 915,
"topReferralSites": [
{
"domain": "",
"icon": "",
"visitsShare": 0.12224650345933631,
"isLocked": true,
"isAvailable": true
},
....
],
"topIncomingCategories": [
{
"category": "News_and_Media",
"visitsShare": 0.15784273881871516
},
....
]
},
"adsSource": {
"adsSitesTotalCount": 455,
"adsNetworksTotalCount": 67,
"topAdsSites": [
{
"domain": "",
"icon": "",
"visitsShare": 0.1853011237551163,
"isLocked": true,
"isAvailable": true
},
....
]
},
"socialNetworksSource": {
"topSocialNetworks": [
{
"name": "Facebook",
"visitsShare": 0.43057689186747783,
"icon": "https://site-images.similarcdn.com/image?url=facebook.com&t=2&s=1&h=be773d6b77aa3d59b6a671c5c27ad729b1ae77400e89776e2f749cce6b926c4b"
},
....
],
"socialNetworksTotalCount": 79
},
"outgoingReferrals": {
"outgoingSitesTotalCount": 0,
"topOutgoingSites": [],
"topOutgoingCategories": []
},
"compareCompetitor": null,
"technologies": {
"categories": [
{
"categoryId": "advertising",
"topTechName": "PubMatic",
"topTechIconUrl": "https://s3.amazonaws.com/s3-static-us-east-1.similarweb.com/technographics/id=331",
"technologiesTotalCount": 4
},
....
],
"categoriesTotalCount": 9,
"technologiesTotalCount": 21
},
"recentAds": {
"recentAds": [
{
"creativeId": "a30a51acfa0ff47a40c41c4fe0ef4fd05d00_10d040f2",
"preview": "https://sw-df-ads-scraping-creatives-production.s3.amazonaws.com/creatives/a30a51acfa0ff47a40c41c4fe0ef4fd05d00_10d040f2.jpeg?AWSAccessKeyId=AKIAIIYZKCNDR6FJZFPQ&Expires=1711717983&Signature=FgE0EitrZtikuKOvpLIdENTpxVU%3D",
"height": 90,
"width": 970,
"activeDays": 1311
},
....
],
"isMoreAds": true
},
"snapshotDate": "2024-02-01T00:00:00+00:00",
"domain": "instagram.com",
"icon": "https://site-images.similarcdn.com/image?url=instagram.com&t=2&s=1&h=acbe9ff09f263f0114ce8473b3d3e401bfdc360d5aff845e04182e8d2335ba49",
"previewDesktop": "https://site-images.similarcdn.com/image?url=instagram.com&t=1&s=1&h=acbe9ff09f263f0114ce8473b3d3e401bfdc360d5aff845e04182e8d2335ba49",
"previewMobile": "https://site-images.similarcdn.com/image?url=instagram.com&t=4&s=1&h=acbe9ff09f263f0114ce8473b3d3e401bfdc360d5aff845e04182e8d2335ba49",
"isInvalidTrafficData": false,
"domainGaStatus": 0,
"isDataFromGaHighlyDiscrepant": false,
"isDataFromGa": false,
"categoryId": "computers_electronics_and_technology/social_networks_and_online_communities",
"overview": {
"description": "create an account or log in to instagram - a simple, fun & creative way to capture, edit & share photos, videos & messages with friends & family.",
"globalRank": 4,
"globalRankChange": 0,
"countryAlpha2Code": "US",
"countryUrlCode": "united-states",
"countryRank": 5,
"countryRankChange": 1,
"categoryRank": 2,
"categoryRankChange": 0,
"visitsTotalCount": 6559108584,
"bounceRate": 0.35884756897538095,
"pagesPerVisit": 11.602903725123301,
"visitsAvgDurationFormatted": "00:08:22",
"companyFeedbackRecaptcha": "6LfEq1gUAAAAACEE4w7Zek8GEmBooXMMWDpBjI6r",
"companyName": "Instagram, Inc.",
"companyYearFounded": 2010,
"companyHeadquarterCountryCode": "US",
"companyHeadquarterStateCode": 8406,
"companyHeadquarterCity": "Menlo Park",
"companyEmployeesMin": 10001,
"companyEmployeesMax": null,
"companyRevenueMin": 1000000000,
"companyRevenueMax": null,
"companyCategoryId": "computers_electronics_and_technology/social_networks_and_online_communities",
"companyRevenueCurrency": null,
"companyParentDomain": "instagram.com"
},
"traffic": {
"visitsTotalCount": 6559108584,
"visitsTotalCountChange": -0.06445071465341932,
"bounceRate": 0.35884756897538095,
"pagesPerVisit": 11.602903725123301,
"visitsAvgDurationFormatted": "00:08:22",
"history": [
{
"date": "2023-12-01T00:00:00",
"visits": 6877387705
},
....
],
"competitors": [
{
"domain": "instagram.com",
"icon": "https://site-images.similarcdn.com/image?url=instagram.com&t=2&s=1&h=acbe9ff09f263f0114ce8473b3d3e401bfdc360d5aff845e04182e8d2335ba49",
"isDataFromGa": false,
"visits": 6559108584
},
....
]
},
"trafficSources": {
"directVisitsShare": 0.7225718475171395,
"referralVisitsShare": 0.03671589976432921,
"organicSearchVisitsShare": 0.1715834983688537,
"paidSearchVisitsShare": 0.00041844007811711777,
"socialNetworksVisitsShare": 0.0641981602879241,
"mailVisitsShare": 0.004222807581810079,
"adsVisitsShare": 0.0002893464018264397,
"topCompetitorInsight": {
"domain": "twitter.com",
"source": "DirectVisitsShare",
"share": 0.8029530189588602,
"icon": "https://site-images.similarcdn.com/image?url=twitter.com&t=2&s=1&h=05438debe431144d9c727828570d1754a25bd9286bc14f3aa65a4f05b9057e25"
}
},
"ranking": {
"globalRankCompetitors": [
{
"rank": 2,
"domain": "youtube.com",
"icon": "https://site-images.similarcdn.com/image?url=youtube.com&t=2&s=1&h=e117fb09ba0a34dee9830863bf927d29fc864e342583a36a667bf12346e88e20"
},
....
],
"globalRankHistory": [
{
"date": "2023-12-01T00:00:00+00:00",
"rank": 4
},
....
],
"countryRankCompetitors": [
{
"rank": 3,
"domain": "facebook.com",
"icon": "https://site-images.similarcdn.com/image?url=facebook.com&t=2&s=1&h=be773d6b77aa3d59b6a671c5c27ad729b1ae77400e89776e2f749cce6b926c4b"
},
....
],
"countryRankHistory": [
{
"date": "2023-12-01T00:00:00+00:00",
"rank": 6
},
....
],
"categoryRankCompetitors": [
{
"rank": 1,
"domain": "facebook.com",
"icon": "https://site-images.similarcdn.com/image?url=facebook.com&t=2&s=1&h=be773d6b77aa3d59b6a671c5c27ad729b1ae77400e89776e2f749cce6b926c4b"
},
....
],
"categoryRankHistory": [
{
"date": "2023-12-01T00:00:00+00:00",
"rank": 2
},
....
],
"globalRank": 4,
"globalRankPrev": 4,
"globalRankChange": 0,
"categoryRank": 2,
"categoryRankPrev": 2,
"categoryRankChange": 0,
"countryRank": 5,
"countryRankPrev": 6,
"countryRankChange": 1,
"countryAlpha2Code": "US",
"countryUrlCode": "united-states"
},
"demographics": {
"ageDistribution": [
{
"minAge": 25,
"maxAge": 34,
"value": 0.31120395140296164
},
....
],
"genderDistribution": {
"male": 0.5417371572698492,
"female": 0.45826284273015083
}
},
"geography": {
"countriesTotalCount": 161,
"topCountriesTraffics": [
{
"countryAlpha2Code": "US",
"countryUrlCode": "united-states",
"visitsShare": 0.19436890376964308,
"visitsShareChange": -0.061281447749603424
},
....
]
}
},
...
]The above web scraping SimilarWeb results are the raw analytics data. We can use it for further analysis ourselves!
How to Scrape SimilarWeb Website Comparing Pages?
The SimilarWeb comparing pages are similar to the dedicated pages for website analytics. They include traffic insights for two compared domains.
For example, let's compare How to Scrape X.com (Twitter) in 2026 and How to Scrape Instagram in 2026 using our target website. Go to the compare page on SimilarWeb, and you will get a similar page:
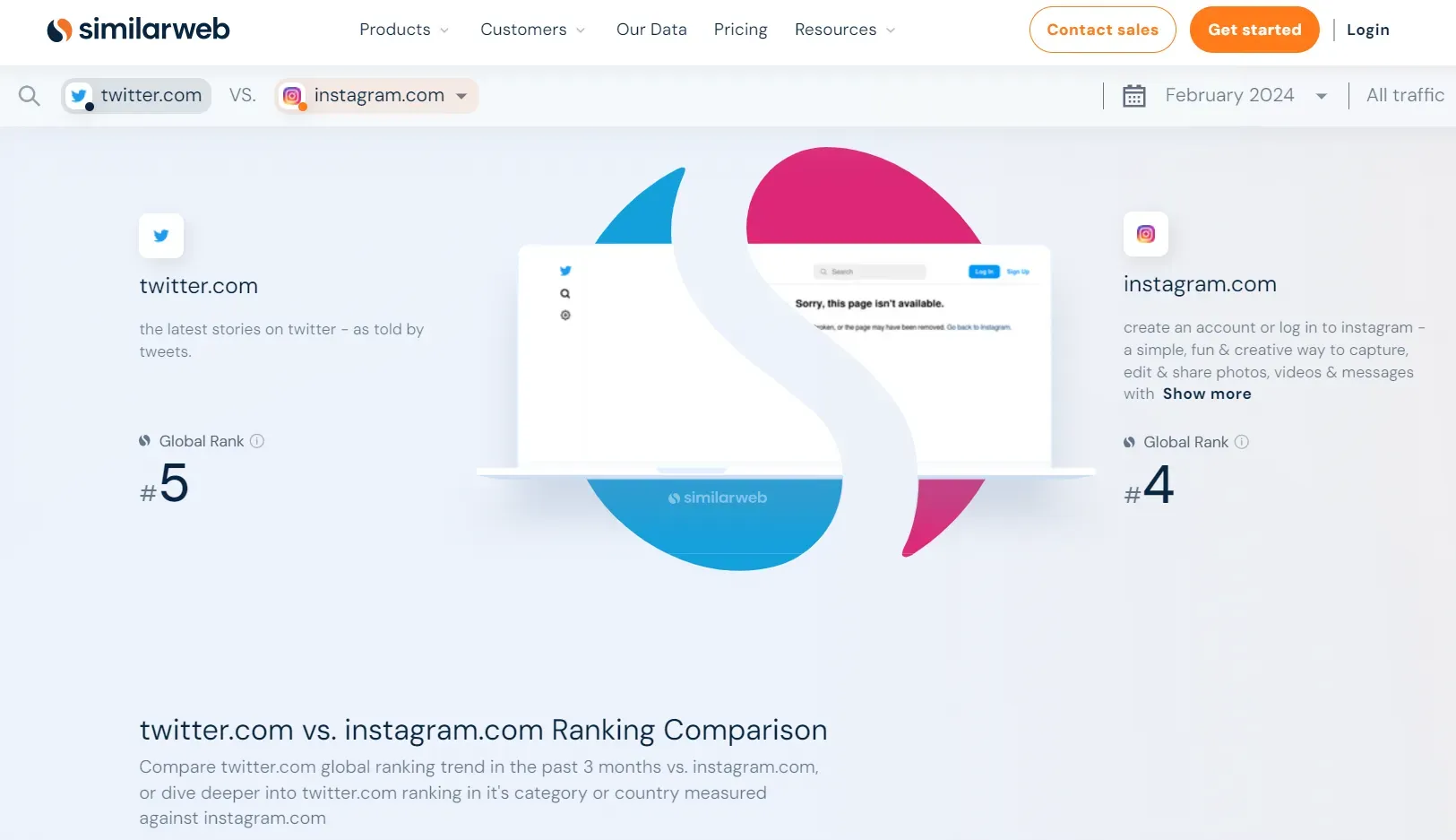
To scrape the above data, we'll use the hidden data approach again using the previously used selector //script[contains(text(), 'window.__APP_DATA__')]. The data inside the script tag looks like the following:

Similar to our previous SimilarWeb scraping code, we'll select the script tag and parse the inside data:
import jmespath
import re
import asyncio
import json
from typing import List, Dict, Optional
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Cookie": "_abck=D2F915DBAC628EA7C01A23D7AA5DF495~0~YAAQLvR6XFLvH1uOAQAAJcI+ZgtcRlotheILrapRd0arqRZwbP71KUNMK6iefMI++unozW0X7uJgFea3Mf8UpSnjpJInm2rq0py0kfC+q1GLY+nKzeWBFDD7Td11X75fPFdC33UV8JHNmS+ET0pODvTs/lDzog84RKY65BBrMI5rpnImb+GIdpddmBYnw1ZMBOHdn7o1bBSQONMFqJXfIbXXEfhgkOO9c+DIRuiiiJ+y24ubNN0IhWu7XTrcJ6MrD4EPmeX6mFWUKoe/XLiLf1Hw71iP+e0+pUOCbQq1HXwV4uyYOeiawtCcsedRYDcyBM22ixz/6VYC8W5lSVPAve9dabqVQv6cqNBaaCM2unTt5Vy+xY3TCt1s8a0srhH6qdAFdCf9m7xRuRsi6OarPvDYjyp94oDlKc0SowI=~-1~-1~-1"
},
)
def parse_hidden_data(response: Response) -> List[Dict]:
"""parse website insights from hidden script tags"""
selector = Selector(response.text)
script = selector.xpath("//script[contains(text(), 'window.__APP_DATA__')]/text()").get()
data = json.loads(re.findall(r"(\{.*?)(?=window\.__APP_META__)", script, re.DOTALL)[0])
return data
def parse_website_compare(response: Response, first_domain: str, second_domain: str) -> Dict:
"""parse website comparings inights between two domains"""
def parse_domain_insights(data: Dict, second_domain: Optional[bool]=None) -> Dict:
"""parse each website data and add it to each domain"""
data_key = data["layout"]["data"]
if second_domain:
data_key = data_key["compareCompetitor"] # the 2nd website compare key is nested
parsed_data = jmespath.search(
"""{
overview: overview,
traffic: traffic,
trafficSources: trafficSources,
ranking: ranking,
demographics: geography
}""",
data_key
)
return parsed_data
script_data = parse_hidden_data(response)
data = {}
data[first_domain] = parse_domain_insights(data=script_data)
data[second_domain] = parse_domain_insights(data=script_data, second_domain=True)
return data
async def scrape_website_compare(first_domain: str, second_domain: str) -> Dict:
"""parse website comparing data from similarweb comparing pages"""
url = f"https://www.similarweb.com/website/{first_domain}/vs/{second_domain}/"
response = await client.get(url)
data = parse_website_compare(response, first_domain, second_domain)
f"scraped comparing insights between {first_domain} and {second_domain}"
log.success(f"scraped comparing insights between {first_domain} and {second_domain}")
return dataimport jmespath
import re
import asyncio
import json
from typing import List, Dict, Optional
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_hidden_data(response: ScrapeApiResponse) -> List[Dict]:
"""parse website insights from hidden script tags"""
selector = response.selector
script = selector.xpath("//script[contains(text(), 'window.__APP_DATA__')]/text()").get()
data = json.loads(re.findall(r"(\{.*?)(?=window\.__APP_META__)", script, re.DOTALL)[0])
return data
def parse_website_compare(response: ScrapeApiResponse, first_domain: str, second_domain: str) -> Dict:
"""parse website comparings inights between two domains"""
def parse_domain_insights(data: Dict, second_domain: Optional[bool]=None) -> Dict:
"""parse each website data and add it to each domain"""
data_key = data["layout"]["data"]
if second_domain:
data_key = data_key["compareCompetitor"] # the 2nd website compare key is nested
parsed_data = jmespath.search(
"""{
overview: overview,
traffic: traffic,
trafficSources: trafficSources,
ranking: ranking,
demographics: geography
}""",
data_key
)
return parsed_data
script_data = parse_hidden_data(response)
data = {}
data[first_domain] = parse_domain_insights(data=script_data)
data[second_domain] = parse_domain_insights(data=script_data, second_domain=True)
return data
async def scrape_website_compare(first_domain: str, second_domain: str) -> Dict:
"""parse website comparing data from similarweb comparing pages"""
url = f"https://www.similarweb.com/website/{first_domain}/vs/{second_domain}/"
response = await SCRAPFLY.async_scrape(ScrapeConfig(url, country="US", asp=True))
data = parse_website_compare(response, first_domain, second_domain)
f"scraped comparing insights between {first_domain} and {second_domain}"
log.success(f"scraped comparing insights between {first_domain} and {second_domain}")
return dataRun the code
async def run():
comparing_data = await scrape_website_compare(
first_domain="twitter.com",
second_domain="instagram.com"
)
# save the data to a JSON file
with open("websites_compare.json", "w", encoding="utf-8") as file:
json.dump(comparing_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())In the above code, we use the previously defined parse_hidden_data to parse data from the page and define two additional functions:
parse_website_compare: For organizing the JSON data and parsing it to exclude unnecessary details with JMESPath.scrape_website_compare: For defining the SimilarWeb comparing URL and requesting it, while utilizing the parsing logic.
Here is a sample output of the results we got:
Example output
{
"twitter.com": {
"overview": {
"description": "the latest stories on twitter - as told by tweets.",
"globalRank": 5,
"globalRankChange": 0,
"countryAlpha2Code": "US",
"countryUrlCode": "united-states",
"countryRank": 7,
"countryRankChange": 0,
"categoryRank": 3,
"categoryRankChange": 0,
"visitsTotalCount": 5761605539,
"bounceRate": 0.31973927509903083,
"pagesPerVisit": 10.723622448514728,
"visitsAvgDurationFormatted": "00:11:03",
"companyFeedbackRecaptcha": "6LfEq1gUAAAAACEE4w7Zek8GEmBooXMMWDpBjI6r",
"companyName": null,
"companyYearFounded": null,
"companyHeadquarterCountryCode": null,
"companyHeadquarterStateCode": null,
"companyHeadquarterCity": null,
"companyEmployeesMin": null,
"companyEmployeesMax": null,
"companyRevenueMin": null,
"companyRevenueMax": null,
"companyCategoryId": "",
"companyRevenueCurrency": null,
"companyParentDomain": null
},
"traffic": {
"visitsTotalCount": 5761605539,
"visitsTotalCountChange": -0.08130202734065403,
"bounceRate": 0.31973927509903083,
"pagesPerVisit": 10.723622448514728,
"visitsAvgDurationFormatted": "00:11:03",
"history": [
{
"date": "2023-12-01T00:00:00",
"visits": 6237810432
},
....
],
"competitors": [
{
"domain": "twitter.com",
"icon": "https://site-images.similarcdn.com/image?url=twitter.com&t=2&s=1&h=05438debe431144d9c727828570d1754a25bd9286bc14f3aa65a4f05b9057e25",
"isDataFromGa": false,
"visits": 5761605539
}
]
},
"trafficSources": {
"directVisitsShare": 0.8029530189588602,
"referralVisitsShare": 0.04303306407258124,
"organicSearchVisitsShare": 0.11258429980814376,
"paidSearchVisitsShare": 2.3072165238041076e-05,
"socialNetworksVisitsShare": 0.03595580708833726,
"mailVisitsShare": 0.005194380408304638,
"adsVisitsShare": 0.0002563574985346188,
"topCompetitorInsight": {
"domain": "",
"source": "",
"share": 0,
"icon": ""
}
},
"ranking": {
"globalRankCompetitors": [],
"globalRankHistory": [
{
"date": "2023-12-01T00:00:00+00:00",
"rank": 5
},
....
],
"countryRankCompetitors": [],
"countryRankHistory": [
{
"date": "2023-12-01T00:00:00+00:00",
"rank": 7
},
....
],
"categoryRankCompetitors": [],
"categoryRankHistory": [
{
"date": "2023-12-01T00:00:00+00:00",
"rank": 3
},
....
],
"globalRank": 5,
"globalRankPrev": 5,
"globalRankChange": 0,
"categoryRank": 3,
"categoryRankPrev": 3,
"categoryRankChange": 0,
"countryRank": 7,
"countryRankPrev": 7,
"countryRankChange": 0,
"countryAlpha2Code": "US",
"countryUrlCode": "united-states"
},
"demographics": {
"countriesTotalCount": null,
"topCountriesTraffics": [
{
"countryAlpha2Code": "US",
"countryUrlCode": "united-states",
"visitsShare": 0.5658495543788219,
"visitsShareChange": null
},
....
]
}
},
"instagram.com": {
// The same previous data schema
....
}
}For further details on JMESPath, refer to our dedicated guide.

With this last feature, our SimilarWeb scraper is complete. It can scrape tons of website traffic data from sitemaps, trending, domain, and comparing pages. However, our scraper will soon encounter a major challenge: scraping blocking!
Bypass SimilarWeb Web Scraping Blocking
We can successfully scrape SimilarWeb for a limited amount of requests. However, attempting to scale our scraper will lead SimilarWeb to block the IP address or request us to log in:
This is where Scrapfly can lend a hand for scraping Similarweb without getting blocked.

For example, with scrapfly all we have to do is enable the asp parameter and select a proxy country:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some similarweb.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
proxy_pool="public_residential_pool", # select the residential proxy pool
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']Learn more about Web Scraping API and how it works.
FAQ
Are there public APIs for SimilarWeb?
SimilarWeb offers a subscription-based API. However, extracting data from SimilarWeb is straightforward, and you can use it to create your own scraper API.
Are there alternatives for scraping SimilarWeb?
Yes, you can scrape Google Trends and SEO keywords for similar web traffic insights. For more website scraping tutorials, refer to our #scrapeguide blog tag.
Summary
In this guide, we explained how to scrape SimilarWeb with Python. We started by exploring and navigating the website by scraping sitemaps. Then, we went through a step-by-step guide on scraping several SimilarWeb pages for traffic, rankings, trending, and comparing data.
We have also explored bypassing web scraping SimilarWeb without getting blocked using ScrapFly and avoiding its validation challenges.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


