

In this web scraping tutorial, we'll be taking a look at how to scrape Redfin.com - a popular real estate listing website.
We'll be scraping real estate data such as pricing info, addresses and photos displayed on Redfin property pages.
To scrape Redfin properties we'll be using the hidden API scraping method. We'll also cover property tracking by continuously scraping for newly listed or updated - giving us an upper hand in real estate bidding. We'll be using Python with a few community libraries - Let's dive in!
Key Takeaways
Learn to scrape Redfin.com real estate property data using Python with hidden redfin api techniques, extracting pricing, addresses, and property details for market analysis.
- Use Redfin's hidden API endpoints to access property listings and pricing data without JavaScript rendering
- Parse JSON responses to extract comprehensive real estate information including prices, addresses, and photos
- Handle Redfin's anti-scraping measures with proper headers and request spacing for real estate data collection
- Extract structured property data including listing details, sale history, and market performance metrics
- Implement property tracking systems for newly listed or updated properties to gain competitive advantages
- Use specialized tools like ScrapFly for automated Redfin scraping with anti-blocking features
Why Scrape Redfin.com?
Redfin.com is one of the biggest real estate websites in the United States making it the biggest public real estate dataset out there. Containing fields like real estate prices, listing locations and sale dates and general property information.
This is valuable information for market analytics, the study of the housing industry, and a general competitor overview. By web scraping Redfin we can easily have access to a major real estate dataset.
See our Scraping Use Cases guide for more.
Available Redfind Data Fields
We can scrape Redfin for several popular real estate data fields and targets:
- Property search pages
- Properties for sale
- Properties for rent
- Land for sale
- Open house events
- Real estate agent info
In this guide, we'll focus on scraping real estate property rent, sale and search pages, though everything we'll learn can be easily applied to other pages.
Project Setup
In this tutorial, we'll be using Python with a few community packages:
- httpx - HTTP client library which will let us communicate with Redfin.com's servers
- parsel - HTML parsing library which will help us to parse our web scraped HTML files.
- ScrapFly-SDK - Python SDK for ScrapFly. Allows for web scraping at scale without getting blocked.
These packages can be easily installed via the pip install command:
$ pip install httpx parsel scrapfly-sdkAlternatively, feel free to swap httpx out with any other HTTP client package such as requests as we'll only need basic HTTP functions which are almost interchangeable in every library. As for, parsel, another great alternative is the How to Parse Web Data with Python and Beautifulsoup package.
How to Scrape Redfin Property Pages
To start, let's take a look at how to scrape property data from a single listing page. Property pages on redfin.com differ based on whether this property is for sale or rent. Let's begin with scraping redfin.com property pages for rent.
Scraping Redfin Property Pages for Rent
Properties for rent data on redfin.com comes from a private API. To see this API in action, follow these steps:
- Go to any property page for rent like this property page on redfin.com.
- Open browser developer tools by clicking the
F12key and head over to theNetworktab. - Filter requests by
Fetch/XHRrequests. - Reload the page.
By following the above steps, you will see all the requests sent from the browser to the server while reloading the page:
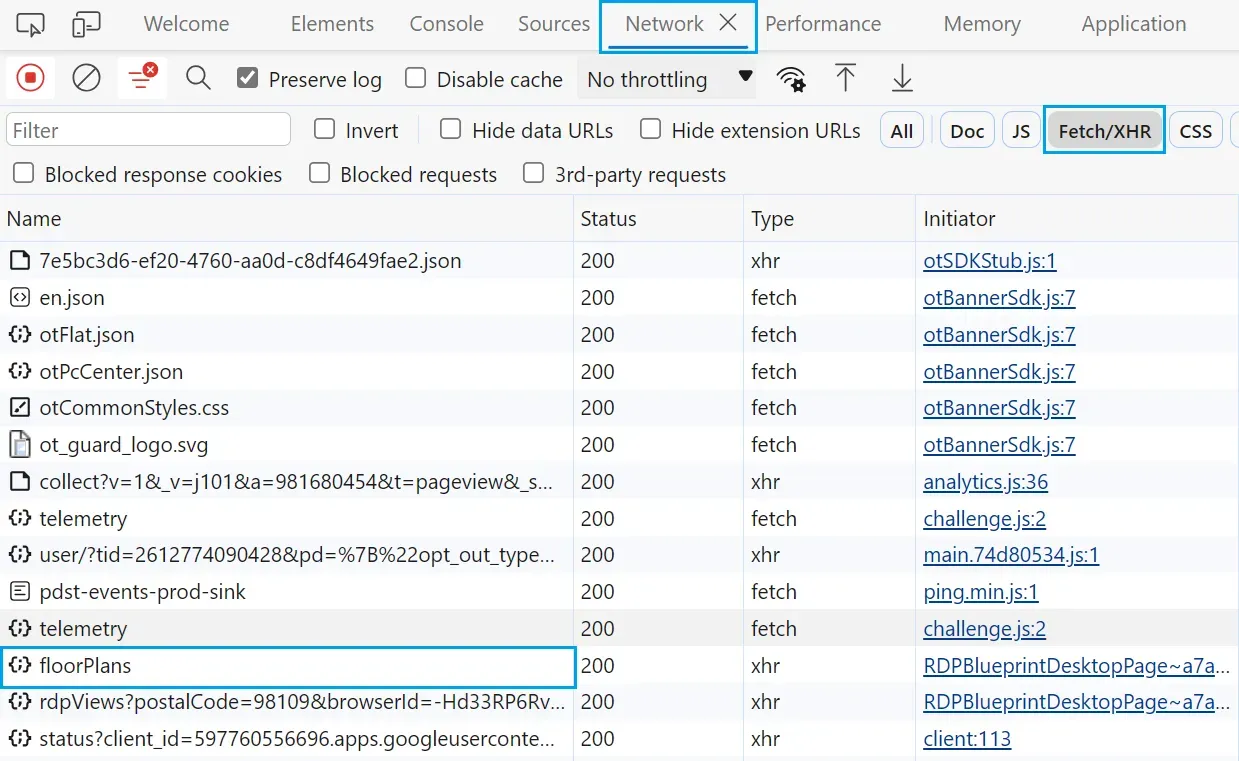
We can see different requests, though we are only interested in the floorPlans request, which includes the actual property data:
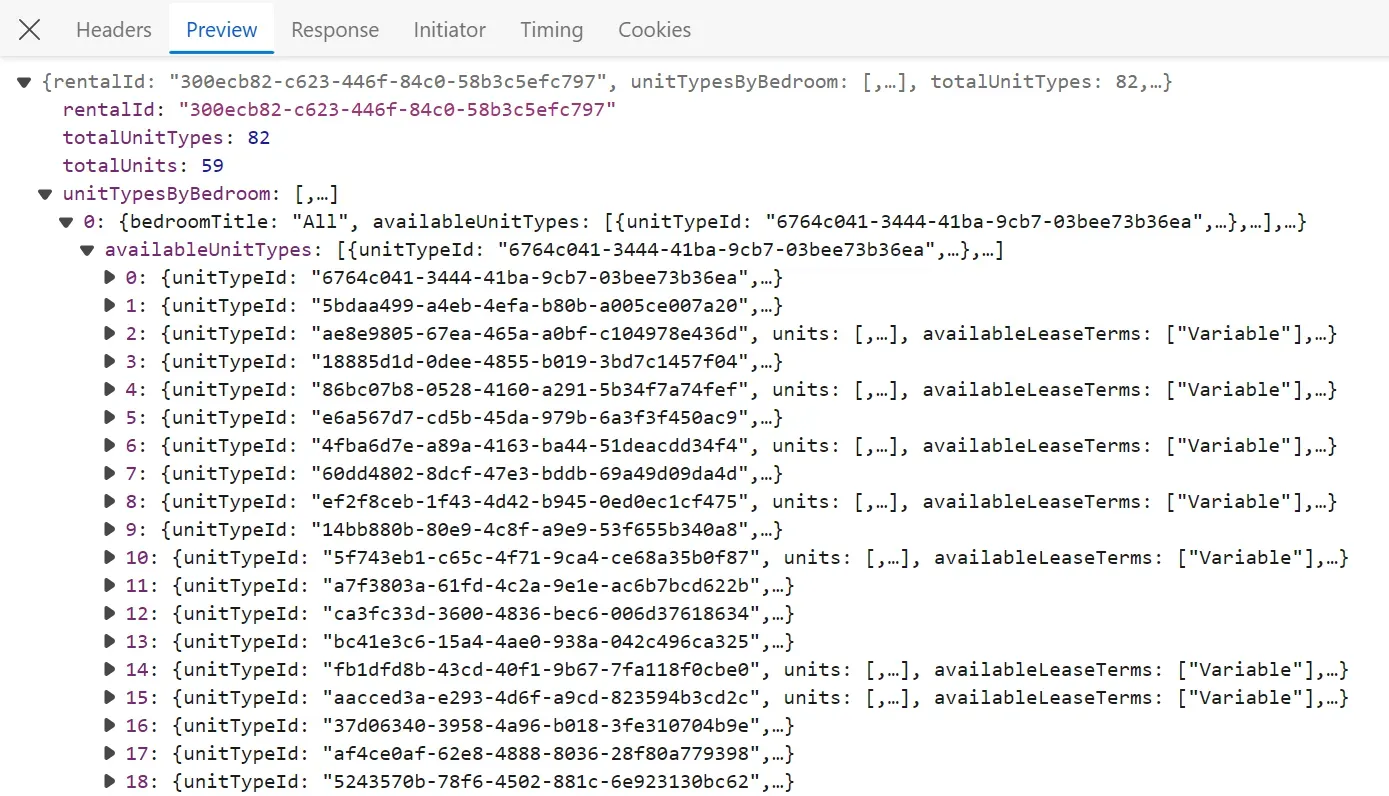
This request was sent to the following API URL:
https://www.redfin.com/stingray/api/v1/rentals/300ecb82-c623-446f-84c0-58b3c5efc797/floorPlansThe id that follows the /rentals route represents the rentalId of the property. To scrape this this data within our scraper, we'll mimic this API request by getting the rentalId from the page HTML and then sending a request to the API:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
# 1. establish HTTP client with browser-like headers to avoid being blocked
client = AsyncClient(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
},
follow_redirects=True,
http2=True, # enable http2 to reduce block chance
timeout=30,
)
def parse_property_for_rent(response: Response):
"""get the rental ID from the HTML to use it in the API"""
selector = Selector(response.text)
data = selector.xpath("//meta[@property='og:image']").attrib["content"]
print(data)
try:
rental_id = data.split("rent/")[1].split("/")[0]
# validate the rentalId
assert len(rental_id) == 36
return rental_id
except:
print("proeprty isn't for rent")
return None
async def scrape_property_for_rent(urls: List[str]) -> list[Dict]:
"""scrape properties for rent from the API"""
api_urls = []
properties = []
for url in urls:
response_html = await client.get(url)
rental_id = parse_property_for_rent(response_html)
if rental_id:
api_urls.append(
f"https://www.redfin.com/stingray/api/v1/rentals/{rental_id}/floorPlans"
)
# add the property pages API URLs to a scraping list
to_scrape = [client.get(url) for url in api_urls]
for response in asyncio.as_completed(to_scrape):
response = await response
properties.append(json.loads(response.text))
print(f"scraped {len(properties)} property listings for rent")
return propertiesimport asyncio
import json
from typing import List, Dict
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_property_for_rent(response: ScrapeApiResponse):
"""get the rental ID from the HTML to use it in the API"""
selector = response.selector
data = selector.xpath("//meta[@property='og:image']").attrib["content"]
try:
rental_id = data.split("rent/")[1].split("/")[0]
# validate the rentalId
assert len(rental_id) == 36
return rental_id
except:
print("proeprty isn't for rent")
return None
async def scrape_property_for_rent(urls: List[str]) -> list[Dict]:
"""scrape properties for rent from the API"""
api_urls = []
properties = []
for url in urls:
response_html = await SCRAPFLY.async_scrape(ScrapeConfig(url, asp=True, country="US"))
rental_id = parse_property_for_rent(response_html)
if rental_id:
api_urls.append(
f"https://www.redfin.com/stingray/api/v1/rentals/{rental_id}/floorPlans"
)
# add the property pages API URLs to a scraping list
to_scrape = [ScrapeConfig(url, country="US") for url in api_urls]
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
properties.append(json.loads(response.content))
print(f"scraped {len(properties)} property listings for rent")
return propertiesRun the code
async def run():
data = await scrape_property_for_rent([
"https://www.redfin.com/WA/Seattle/Onni-South-Lake-Union/apartment/147020546",
"https://www.redfin.com/WA/Seattle/The-Ivey-on-Boren/apartment/146904423",
"https://www.redfin.com/WA/Seattle/Broadstone-Strata/apartment/178439949",
])
print(json.dumps(data, indent=2))
if __name__ == "__main__":
asyncio.run(run()) 🧙 If you get errors running the Python code tabs, this is due to getting blocked. Run the ScrapFly code tabs instead to avoid redfin.com scraping blocking.
First, we send a request to the property page URL to extract the rentalId from the HTML. Next, we use this ID to define the API URL of each property page. Finally, we send requests to the API URLs we defined to get each property data in JSON.
Here is a sample output of the result we got:
Sample output
[
{
"rentalId": "2316e47c-b1f1-4975-8e4e-806c6d5e0023",
"unitTypesByBedroom": [
{
"bedroomTitle": "All",
"availableUnitTypes": [
{
"unitTypeId": "8e312346-0ace-4464-9fd8-6af3aa663bfa",
"units": [
{
"unitId": "2a508775-aa6c-431a-9575-f72a456cfea7",
"bedrooms": 0,
"depositCurrency": "USD",
"fullBaths": 1,
"halfBaths": 0,
"name": "E627",
"rentCurrency": "USD",
"rentPrice": 2395,
"sqft": 525,
"status": "available"
},
{
"unitId": "01993cd5-cd22-4f52-b237-16a0cb03fdb3",
"bedrooms": 0,
"depositCurrency": "USD",
"fullBaths": 1,
"halfBaths": 0,
"name": "E525",
"rentCurrency": "USD",
"rentPrice": 2385,
"sqft": 525,
"status": "available"
},
{
"unitId": "19e003a9-a3b4-4497-80c4-592938c6ab54",
"bedrooms": 0,
"depositCurrency": "USD",
"fullBaths": 1,
"halfBaths": 0,
"name": "E628",
"rentCurrency": "USD",
"rentPrice": 2416,
"sqft": 525,
"status": "available"
}
],
"availableLeaseTerms": [
"Variable"
],
"availablePhotos": [
{
"startPos": 0,
"endPos": 0,
"version": "3"
}
],
"availableUnits": 3,
"bedrooms": 0,
"fullBaths": 1,
"halfBaths": 0,
"name": "Studio A",
"rentPriceMax": 2416,
"rentPriceMin": 2385,
"sqftMax": 525,
"sqftMin": 525,
"status": "available",
"style": "Studio A",
"totalUnits": 3
}
]
}
]
}
]Now that we can scrape property pages for rent, let's scrape the ones for sale.
Scraping Redfin Property Pages for Sale
Unlike the previous property pages, property pages for sale don't use an API to fetch the data. Hence, we'll scrape them using Parsing HTML with Xpath and Parsing HTML with CSS Selectors selectors.
def parse_property_for_sale(response: Response) -> List[Dict]:
"""parse property data from the HTML"""
selector = Selector(response.text)
price = selector.xpath("//div[@data-rf-test-id='abp-price']/div/text()").get()
estimated_monthly_price = "".join(selector.xpath("//span[@class='est-monthly-payment']/text()").getall())
address = (
"".join(selector.xpath("//div[contains(@class, 'street-address')]/text()").getall())
+ " " + "".join(selector.xpath("//div[contains(@class, 'cityStateZip')]/text()").getall())
)
description = selector.xpath("//div[@id='marketing-remarks-scroll']/p/span/text()").get()
images = [
image.attrib["src"]
for image in selector.xpath("//img[contains(@class, 'widenPhoto')]")
]
details = [
"".join(text_content.getall())
for text_content in selector.css("div .keyDetails-value::text")
]
features_data = {}
for feature_block in selector.css(".amenity-group ul div.title"):
label = feature_block.css("::text").get()
features = feature_block.xpath("following-sibling::li/span")
features_data[label] = [
"".join(feat.xpath(".//text()").getall()).strip() for feat in features
]
return {
"address": address,
"description": description,
"price": price,
"estimatedMonthlyPrice": estimated_monthly_price,
"propertyUrl": str(response.context["url"]),
"attachments": images,
"details": details,
"features": features_data,
}def parse_property_for_sale(response: ScrapeApiResponse) -> List[Dict]:
"""parse property data from the HTML"""
selector = response.selector
price = selector.xpath("//div[@data-rf-test-id='abp-price']/div/text()").get()
estimated_monthly_price = "".join(selector.xpath("//span[@class='est-monthly-payment']/text()").getall())
address = (
"".join(selector.xpath("//div[contains(@class, 'street-address')]/text()").getall())
+ " " + "".join(selector.xpath("//div[contains(@class, 'cityStateZip')]/text()").getall())
)
description = selector.xpath("//div[@id='marketing-remarks-scroll']/p/span/text()").get()
images = [
image.attrib["src"]
for image in selector.xpath("//img[contains(@class, 'widenPhoto')]")
]
details = [
"".join(text_content.getall())
for text_content in selector.css("div .keyDetails-value::text")
]
features_data = {}
for feature_block in selector.css(".amenity-group ul div.title"):
label = feature_block.css("::text").get()
features = feature_block.xpath("following-sibling::li/span")
features_data[label] = [
"".join(feat.xpath(".//text()").getall()).strip() for feat in features
]
return {
"address": address,
"description": description,
"price": price,
"estimatedMonthlyPrice": estimated_monthly_price,
"propertyUrl": str(response.context["url"]),
"attachments": images,
"details": details,
"features": features_data,
}Here, we define a parse_property_for_sale function. Which parses the property page data from the HTML using XPath and CSS selectors and returns the data as a JSON object. Next, we'll use this function with httpx to scrape the property pages:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
# 1. establish HTTP client with browser-like headers to avoid being blocked
client = AsyncClient(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
},
follow_redirects=True,
http2=True, # enable http2 to reduce block chance
timeout=30,
)
def parse_property_for_sale(response: Response) -> List[Dict]:
"""parse property data from the HTML"""
# Rest of the function logic
async def scrape_property_for_sale(urls: List[str]) -> list[Dict]:
"""scrape properties for sale data from HTML"""
properties = []
# add the property pages API URLs to a scraping list
to_scrape = [client.get(url) for url in urls]
for response in asyncio.as_completed(to_scrape):
response = await response
properties.append(parse_property_for_sale(response))
print(f"scraped {len(properties)} property listings for sale")
return propertiesimport asyncio
import json
from typing import List, Dict
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_property_for_sale(response: ScrapeApiResponse) -> List[Dict]:
"""parse property data from the HTML"""
# Rest of the function logic
async def scrape_property_for_sale(urls: List[str]) -> List[Dict]:
"""scrape properties for sale data from HTML"""
# add the property pages to a scraping list
to_scrape = [ScrapeConfig(url, asp=True, country="US") for url in urls]
properties = []
# scrape all property pages concurrently
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
data = parse_property_for_sale(response)
properties.append(data)
print(f"scraped {len(properties)} property listings for sale")
return propertiesRun the code
async def run():
data = await scrape_property_for_sale([
"https://www.redfin.com/WA/Seattle/506-E-Howell-St-98122/unit-W303/home/46456",
"https://www.redfin.com/WA/Seattle/1105-Spring-St-98104/unit-405/home/12305595",
"https://www.redfin.com/WA/Seattle/10116-Myers-Way-S-98168/home/186647",
])
print(json.dumps(data, indent=2))
if __name__ == "__main__":
asyncio.run(run()) Here, we add the property page URLs to a scraping list and scrape them concurrently. Then, we extract the property data using the parse_property_for_sale function we defined earlier.
The result is a list with the data of each property page:
Sample output
[
{
"address": "10116 Myers Way S, Seattle, WA 98168",
"description": "Let's introduce you to the home of your turnkey dreams! This stunning 4 bed, 1.75 bath rambler was extensively remodeled in 2020 with all the bells and whistles. Enjoy a functional, open concept floorpan and gleaming oak hardwood floors that span the kitchen and main living area. The impressive chef's kitchen boasts quartz slab countertops, ss appliances and ample storage. The expansive primary bedroom speaks for itself with 2 walk-in closets, and an ensuite bath w/double-sink vanity. Enjoy the privacy of your 7,600sqft+ lot with multiple raised garden beds, outdoor shed and fully fenced backyard. Convenient access to 509 - just a short commute to Downtown Seattle and everywhere else in-between! ",
"price": "$649,950",
"estimatedMonthlyPrice": "Est. $4,556/mo",
"propertyUrl": "https://www.redfin.com/WA/Seattle/10116-Myers-Way-S-98168/home/186647",
"attachments": [
"https://ssl.cdn-redfin.com/photo/1/bigphoto/848/2178848_0.jpg",
"https://ssl.cdn-redfin.com/photo/1/bigphoto/848/2178848_6_0.jpg",
"https://ssl.cdn-redfin.com/photo/1/bigphoto/848/2178848_20_0.jpg"
],
"details": [
"Single-family",
"Built in 1960, renovated in 2020",
"7,616 sq ft lot",
"$475 per sq ft",
"1 parking space",
"In-unit laundry (washer and dryer)"
],
"features": {
"Parking Information": [
"Parking Features: Driveway, Off Street"
],
"Bedroom Information": [
"# of Bedrooms: 4",
"# of Bedrooms Main: 4"
],
"Bathroom Information": [
"# of Full Baths (Total): 1",
"# of Three Quarter Baths (Total): 1"
],
"Room 1 Information": [
"Room Type: Entry Hall",
"Room Level: Main"
],
"Room 2 Information": [
"Room Type: Living Room",
"Room Level: Main"
],
"Room 3 Information": [
"Room Type: Primary Bedroom",
"Room Level: Main"
],
"Room 4 Information": [
"Room Type: Bedroom",
"Room Level: Main"
],
"Room 5 Information": [
"Room Type: Bedroom",
"Room Level: Main"
],
"Room 6 Information": [
"Room Type: Bedroom",
"Room Level: Main"
],
"Room 7 Information": [
"Room Type: Bathroom Full",
"Room Level: Main"
],
"Room 8 Information": [
"Room Type: Bathroom Three Quarter",
"Room Level: Main"
],
"Room 9 Information": [
"Room Type: Utility Room",
"Room Level: Main"
],
"Room 10 Information": [
"Room Type: Dining Room",
"Room Level: Main"
],
"Room 11 Information": [
"Room Type: Kitchen With Eating Space",
"Room Level: Main"
],
"Basement Information": [
"Basement Features: None"
],
"Fireplace Information": [
"Has Fireplace",
"# of Fireplaces: 1"
],
"Heating & Cooling": [
"Has Heating",
"Heating Information: Wall Unit(s)"
],
"Interior Features": [
"Interior Features: Ceramic Tile, Hardwood, Wall to Wall Carpet, Dining Room, Walk-in Closet(s), Fireplace, Water Heater",
"Appliances: Dishwasher, Dryer, Disposal, Microwave, Refrigerator, Washer"
],
"Building Information": [
"Building Information: Built On Lot",
"Roof: Composition"
],
"Exterior Features": [
"Exterior Features: Wood, Wood Products"
],
"Property Information": [
"Energy Source: Electric",
"Sq. Ft. Finished: 1,368"
],
"Land Information": [
"Vegetation: Fruit Trees, Garden Space"
],
"Lot Information": [
"MLS Lot Size Source: Public Records",
"Site Features: Fenced-Fully,Outbuildings,Patio"
],
"Tax Information": [
"Tax Annual Amount: $7,660",
"Tax Year: 2023"
],
"Financial Information": [
"Listing Terms: Cash Out, Conventional, FHA, VA Loan"
],
"Utility Information": [
"Water Source: Public",
"Water Company: District 20"
],
"School Information": [
"High School District: Highline"
],
"Location Information": [
"Directions: Head down 1st Ave S. Stay on the right to Myers Way S. Home is on your Right."
],
"Community Information": [
"Senior Exemption: false"
],
"Listing Information": [
"Selling Agency Compensation: 3",
"Mls Status: Active"
],
"Listing Date Information": [
"On Market Date: Thursday, November 9, 2023",
"Cumulative Days On Market: 6"
],
"Green Information": [
"Direction Faces: West",
"Power Production Type: Electric"
],
"Home Information": [
"Living Area: 1,368",
"Living Area Units: Square Feet"
]
}
}
]Our redfin scraper can scrape property pages. Let's scrape search pages.
How to Scrape Redfin Search Pages
To scrape redfin.com search pages, we'll use the private search API to get the data directly in JSON. To view this API, follow the below steps:
- Go to any search page on redfin.com.
- Open the browser developer tools by clicking the
F12key to view the page HTML. - Use the draw feature to mark a search area on the map.
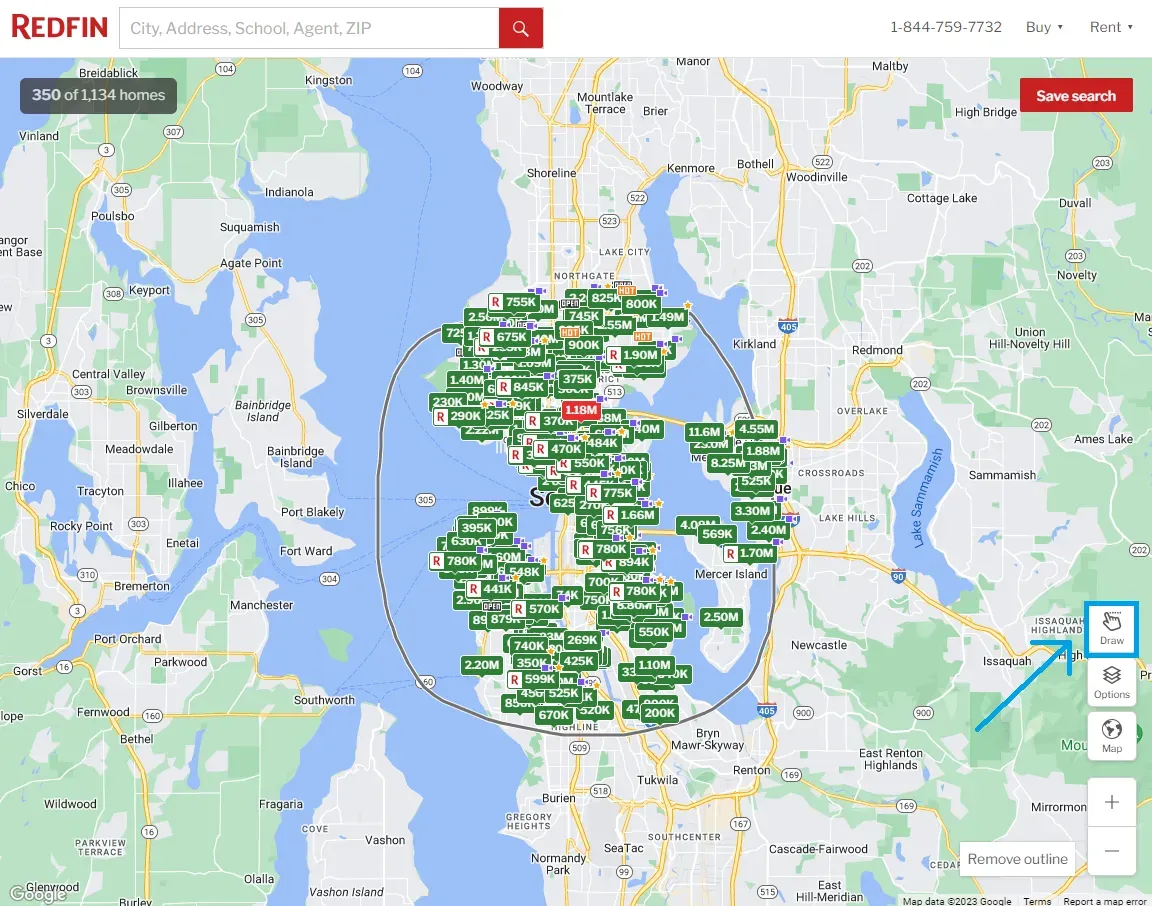
By following the above steps, the browser will record the API request used for fetching this area data. To view this API, open the network tab and filter by Fetch/XHR requests:
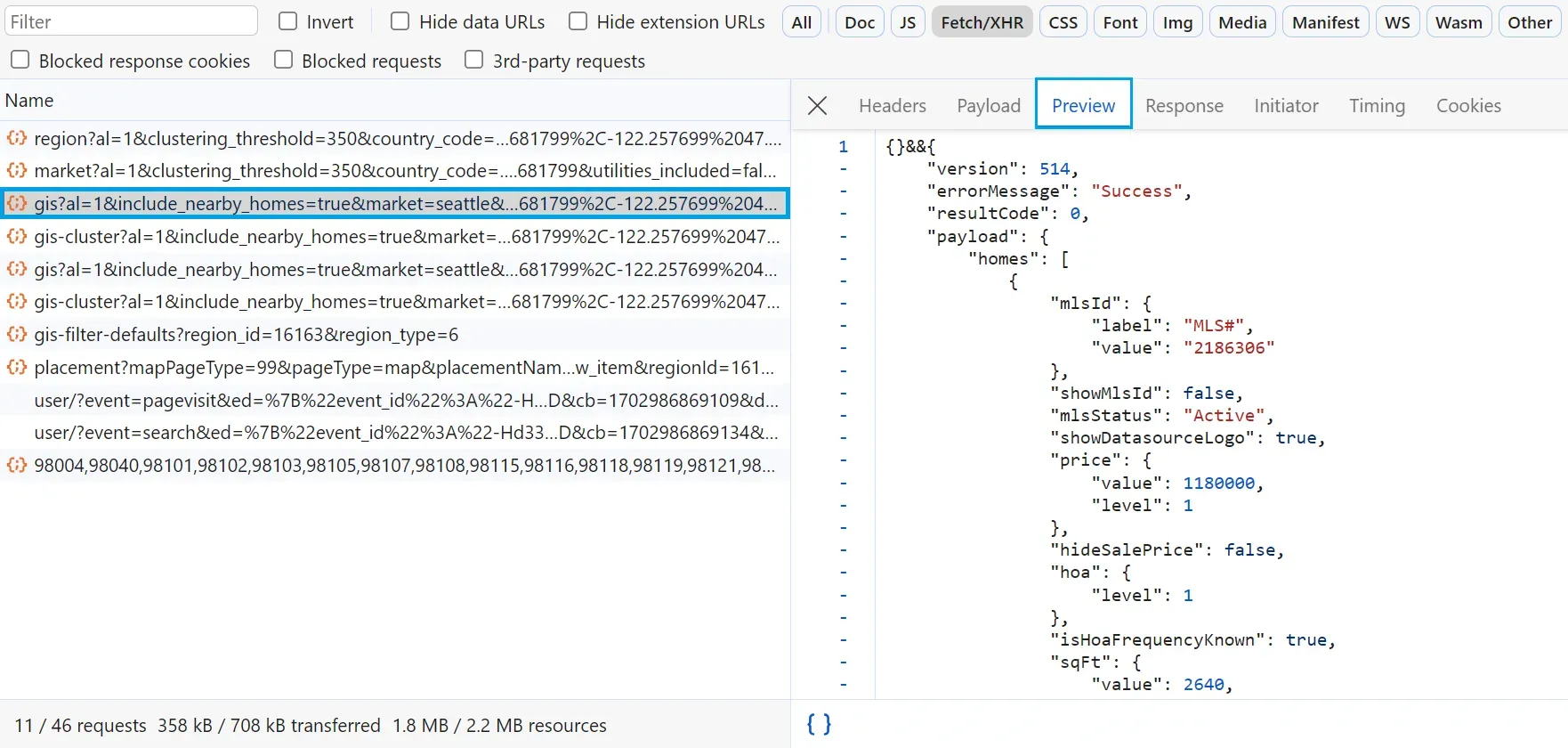
To scrape redfin.com search, we'll copy this API URL and use it to get all the search data in JSON:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
# 1. establish HTTP client with browser-like headers to avoid being blocked
client = AsyncClient(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
},
follow_redirects=True,
http2=True, # enable http2 to reduce block chance
timeout=30,
)
def parse_search_api(response: Response) -> List[Dict]:
"""parse JSON data from the search API"""
return json.loads(response.text.replace("{}&&", ""))["payload"]["homes"]
async def scrape_search(url: str) -> List[Dict]:
"""scrape search data from the searh API"""
# send a request to the search API
search_api_response = await client.get(url)
search_data = parse_search_api(search_api_response)
print(f"scraped ({len(search_data)}) search results from the search API")
return search_dataimport asyncio
import json
from typing import List, Dict
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
def parse_search_api(response: ScrapeApiResponse) -> List[Dict]:
"""parse JSON data from the search API"""
return json.loads(response.content.replace("{}&&", ""))["payload"]["homes"]
async def scrape_search(url: str) -> List[Dict]:
"""scrape search data from the searh API"""
# send a request to the search API
search_api_response = await SCRAPFLY.async_scrape(
ScrapeConfig(url, country="US")
)
search_data = parse_search_api(search_api_response)
print(f"scraped ({len(search_data)}) search results from the search API")
return search_dataRun the code
async def run():
data = await scrape_search(
url="https://www.redfin.com/stingray/api/gis?al=1&include_nearby_homes=true&market=seattle&num_homes=350&ord=redfin-recommended-asc&page_number=1&poly=-122.54472%2047.44109%2C-122.11144%2047.44109%2C-122.11144%2047.78363%2C-122.54472%2047.78363%2C-122.54472%2047.44109&sf=1,2,3,5,6,7&start=0&status=1&uipt=1,2,3,4,5,6,7,8&user_poly=-122.278298%2047.739783%2C-122.278985%2047.739783%2C-122.279671%2047.739783%2C-122.325677%2047.743015%2C-122.330483%2047.743015%2C-122.335290%2047.743015%2C-122.346276%2047.742554%2C-122.351769%2047.742092%2C-122.357262%2047.741168%2C-122.362756%2047.740245%2C-122.368249%2047.739321%2C-122.373742%2047.737936%2C-122.378548%2047.736551%2C-122.383355%2047.735165%2C-122.388161%2047.733780%2C-122.392968%2047.732856%2C-122.397088%2047.731471%2C-122.401208%2047.730085%2C-122.404641%2047.728238%2C-122.407388%2047.726390%2C-122.410134%2047.724081%2C-122.412194%2047.721771%2C-122.414254%2047.718999%2C-122.416314%2047.716228%2C-122.418374%2047.712532%2C-122.421120%2047.708835%2C-122.423867%2047.704677%2C-122.426614%2047.700056%2C-122.429360%2047.695434%2C-122.432107%2047.690813%2C-122.434853%2047.686190%2C-122.437600%2047.681568%2C-122.439660%2047.676945%2C-122.441033%2047.671859%2C-122.442406%2047.666310%2C-122.444466%2047.660298%2C-122.446526%2047.653823%2C-122.447900%2047.646885%2C-122.449960%2047.639946%2C-122.451333%2047.632543%2C-122.452020%2047.625139%2C-122.452020%2047.619122%2C-122.452020%2047.613105%2C-122.452020%2047.607087%2C-122.452020%2047.601994%2C-122.452020%2047.596438%2C-122.451333%2047.590881%2C-122.449960%2047.586250%2C-122.448586%2047.581619%2C-122.447213%2047.576987%2C-122.445153%2047.572818%2C-122.443093%2047.568648%2C-122.441033%2047.564942%2C-122.438973%2047.561235%2C-122.436227%2047.557992%2C-122.433480%2047.554748%2C-122.430734%2047.551967%2C-122.428674%2047.549187%2C-122.426614%2047.546869%2C-122.423867%2047.544552%2C-122.421120%2047.541771%2C-122.418374%2047.539453%2C-122.415627%2047.537136%2C-122.412881%2047.534818%2C-122.410134%2047.532500%2C-122.406014%2047.530182%2C-122.401894%2047.527864%2C-122.397775%2047.525545%2C-122.392968%2047.523691%2C-122.388161%2047.521372%2C-122.383355%2047.519517%2C-122.378548%2047.517662%2C-122.373055%2047.515807%2C-122.368249%2047.513952%2C-122.362756%2047.512561%2C-122.357262%2047.511170%2C-122.351769%2047.509314%2C-122.345589%2047.507923%2C-122.339410%2047.506995%2C-122.332543%2047.506068%2C-122.325677%2047.505140%2C-122.318810%2047.504212%2C-122.312630%2047.503285%2C-122.307137%2047.502821%2C-122.302331%2047.502357%2C-122.298211%2047.502357%2C-122.294091%2047.502357%2C-122.289285%2047.502821%2C-122.285165%2047.503748%2C-122.281045%2047.504676%2C-122.276925%2047.505604%2C-122.272805%2047.506532%2C-122.267999%2047.507923%2C-122.263192%2047.508851%2C-122.258385%2047.509314%2C-122.253579%2047.509778%2C-122.248772%2047.510242%2C-122.245339%2047.510242%2C-122.240533%2047.510706%2C-122.237099%2047.511170%2C-122.233666%2047.511633%2C-122.231606%2047.512561%2C-122.229546%2047.513025%2C-122.228173%2047.513952%2C-122.226800%2047.515344%2C-122.226113%2047.517199%2C-122.225426%2047.519517%2C-122.224053%2047.522299%2C-122.222680%2047.526009%2C-122.221993%2047.529718%2C-122.220620%2047.533427%2C-122.219247%2047.537136%2C-122.218560%2047.540844%2C-122.217187%2047.545016%2C-122.216500%2047.549650%2C-122.215127%2047.554748%2C-122.213067%2047.561235%2C-122.212380%2047.568648%2C-122.211694%2047.576524%2C-122.211694%2047.584861%2C-122.211694%2047.593660%2C-122.211694%2047.602920%2C-122.211694%2047.611716%2C-122.211694%2047.620048%2C-122.211694%2047.627452%2C-122.211694%2047.634856%2C-122.211694%2047.641796%2C-122.212380%2047.648735%2C-122.213754%2047.655211%2C-122.215127%2047.661223%2C-122.216500%2047.667235%2C-122.218560%2047.673246%2C-122.220620%2047.679256%2C-122.223367%2047.684341%2C-122.226113%2047.688964%2C-122.228173%2047.692661%2C-122.230233%2047.695897%2C-122.232293%2047.699132%2C-122.235040%2047.701904%2C-122.237099%2047.704677%2C-122.239846%2047.707449%2C-122.242593%2047.710221%2C-122.244653%2047.712994%2C-122.246713%2047.715304%2C-122.248772%2047.717613%2C-122.250832%2047.719923%2C-122.252206%2047.721771%2C-122.253579%2047.723619%2C-122.254952%2047.725004%2C-122.256326%2047.726390%2C-122.257699%2047.727314%2C-122.258385%2047.728238%2C-122.259072%2047.729161%2C-122.259759%2047.730085%2C-122.260445%2047.730547%2C-122.261132%2047.731471%2C-122.261819%2047.731932%2C-122.262505%2047.732394%2C-122.263192%2047.733318%2C-122.263879%2047.733780%2C-122.264565%2047.734242%2C-122.265252%2047.734703%2C-122.265939%2047.735165%2C-122.266625%2047.735627%2C-122.267312%2047.736089%2C-122.267999%2047.736551%2C-122.268685%2047.737012%2C-122.270058%2047.737936%2C-122.270745%2047.738859%2C-122.271432%2047.739783%2C-122.272118%2047.740245%2C-122.272805%2047.740707%2C-122.273492%2047.741168%2C-122.274178%2047.741168%2C-122.274865%2047.741630%2C-122.275552%2047.741630%2C-122.278298%2047.739783&v=8&zoomLevel=11"
)
print(json.dumps(data, indent=2))
if __name__ == "__main__":
asyncio.run(run()) Here, we use the scrape_search function tp send a request to the search API and and use the parse_search_api function to load the data into a JSON object.
By running this code, we get all the property data found in all the search pagination pages:
Sample output
[
{
"mlsId": {
"label": "MLS#",
"value": "2180345"
},
"showMlsId": false,
"mlsStatus": "Active",
"showDatasourceLogo": true,
"price": {
"value": 360000,
"level": 1
},
"hideSalePrice": false,
"hoa": {
"value": 427,
"level": 1
},
"isHoaFrequencyKnown": true,
"sqFt": {
"value": 566,
"level": 1
},
"pricePerSqFt": {
"value": 636,
"level": 1
},
"lotSize": {
"level": 1
},
"beds": 1,
"baths": 1.0,
"fullBaths": 1,
"location": {
"value": "Broadway",
"level": 1
},
"stories": 1.0,
"latLong": {
"value": {
"latitude": 47.6180415,
"longitude": -122.3249551
},
"level": 1
},
"streetLine": {
"value": "506 E Howell St Unit W303",
"level": 1
},
"unitNumber": {
"value": "Unit W303",
"level": 1
},
"city": "Seattle",
"state": "WA",
"zip": "98122",
"postalCode": {
"value": "98122",
"level": 1
},
"countryCode": "US",
"showAddressOnMap": true,
"soldDate": 1130745600000,
"searchStatus": 1,
"propertyType": 3,
"uiPropertyType": 2,
"listingType": 1,
"propertyId": 46456,
"listingId": 178262671,
"dataSourceId": 1,
"marketId": 1,
"yearBuilt": {
"value": 1992,
"level": 1
},
"dom": {
"value": 1,
"level": 1
},
"timeOnRedfin": {
"value": 49046118,
"level": 1
},
"originalTimeOnRedfin": {
"value": 49046168,
"level": 1
},
"timeZone": "US/Pacific",
"primaryPhotoDisplayLevel": 1,
"photos": {
"value": "0-21:0",
"level": 1
},
"alternatePhotosInfo": {
"mediaListType": "1",
"mediaListIndex": 0,
"groupCode": "871959_JPG",
"positionSpec": [
...
],
"type": 1
},
"additionalPhotosInfo": [],
"scanUrl": "https://my.matterport.com/show/?m=vQYUhauLS8E",
"posterFrameUrl": "https://my.matterport.com/api/v2/player/models/vQYUhauLS8E/thumb",
"listingBroker": {
"name": "Redfin",
"isRedfin": true
},
"sellingBroker": {
"isRedfin": false
},
"listingAgent": {
"name": "Earnest Watts",
"redfinAgentId": 502
},
"url": "/WA/Seattle/506-E-Howell-St-98122/unit-W303/home/46456",
"hasInsight": false,
"sashes": [
{
"sashType": 7,
"sashTypeId": 7,
"sashTypeName": "New",
"sashTypeColor": "#2E7E36",
"isRedfin": true,
"timeOnRedfin": 49046118,
"openHouseText": "",
"lastSaleDate": "",
"lastSalePrice": ""
},
{
"sashType": 31,
"sashTypeId": 31,
"sashTypeName": "3D Walkthrough",
"sashTypeColor": "#7556F2",
"isRedfin": false,
"openHouseText": "",
"lastSaleDate": "",
"lastSalePrice": ""
}
],
"isHot": false,
"hasVirtualTour": true,
"hasVideoTour": false,
"has3DTour": true,
"newConstructionCommunityInfo": {},
"isRedfin": true,
"isNewConstruction": false,
"listingRemarks": "Welcome home to this stunning light-filled unit in the sought after Ambassador community. Gated entry to a welcoming courtyard. Conveniently located in the heart of Capitol Hill blocks from shopping/restaurant districts, parks, the Light Rail, SLU, downtown, and freeways. This unit showcases panoramic views of the Seattle City skyline and endless sunsets. The inviting living room features a cozy gas fireplace and private balcony perfect for entertaining. The open kitchen layout offers concrete countertops with stainless steel appliances and ample storage. Large bedroom also with awesome views! One secure garage parking spot, storage unit, in-unit laundry, and community exercise room and bik",
"remarksAccessLevel": 1,
"servicePolicyId": 14,
"businessMarketId": 1,
"isShortlisted": false,
"isViewedListing": false
}
]Cool! We can almost scrape all the data on redfin.com with a few lines of code. But what continuously web scraping redfin.com for recently added listings!
Following Redfin Listing Changes
To keep track of new Redfin listings, we can use sitemap feeds for the newest and updated listings:
- newest which signals when new listings are being posted.
- latest which siganls when listings are being updated or changed.
To find new listings and updates, we'll be scraping these two sitemaps which provide a listing URL and timestamp when it was listed or updated:
<url>
<loc>https://www.redfin.com/NH/Boscawen/1-Sherman-Dr-03303/home/96531826</loc>
<lastmod>2022-12-01T00:53:20.426-08:00</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>⌚ Note that this sitemap is using UTC-8 timezone. It's indicated by the last number of the datetime string: -08.00.
To scrape these Redfin feeds in Python we'll be using httpx and parsel libraries we've used before:
import asyncio
import arrow # for handling datetime: pip install arrow
from datetime import datetime
from parsel import Selector
from typing import Dict
from httpx import AsyncClient
client = AsyncClient(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
}
)
async def scrape_feed(url) -> Dict[str, datetime]:
"""scrape Redfin sitemap and return url:datetime dictionary"""
result = await client.get(url)
selector = Selector(result.text)
results = {}
for item in selector.xpath("//url"):
url = item.xpath(".//loc/text()").get()
pub_date = item.xpath(".//lastmod/text()").get()
results[url] = arrow.get(pub_date).datetime
return resultsimport asyncio
import arrow # for handling datetime: pip install arrow
from datetime import datetime
from typing import Dict
from scrapfly import ScrapeConfig, ScrapflyClient
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
async def scrape_feed(url) -> Dict[str, datetime]:
"""scrape Redfin sitemap and return url:datetime dictionary"""
result = await SCRAPFLY.async_scrape(ScrapeConfig(url, asp=True, country="US"))
selector = result.selector
results = {}
for item in selector.xpath("//url"):
url = item.xpath(".//loc/text()").get()
pub_date = item.xpath(".//lastmod/text()").get()
results[url] = arrow.get(pub_date).datetime
return resultsRun the code
async def run():
data = await scrape_feed("https://www.redfin.com/newest_listings.xml")
print(data)
if __name__ == "__main__":
asyncio.run(run())By running the above code, we'll get the URLs and dates of the recently added property listings on redfin.com:
{
'https://www.redfin.com/TN/Elizabethton/121-Williams-Ave-37643/home/116345480': datetime.datetime(2023, 11, 19, 18, 54, 56, 277000, tzinfo=tzoffset(None, -28800)),
'https://www.redfin.com/IL/Bensenville/4N650-Ridgewood-Ave-60106/home/12559393': datetime.datetime(2023, 11, 19, 9, 26, 19, 968000, tzinfo=tzoffset(None, -28800)),
'https://www.redfin.com/WI/Oak-Creek/10405-S-Willow-Creek-Dr-53154/home/57853736': datetime.datetime(2023, 11, 18, 14, 48, 58, 829000, tzinfo=tzoffset(None, -28800)),
'https://www.redfin.com/FL/Davenport/511-Hatteras-Rd-33837/home/182909751': datetime.datetime(2023, 11, 19, 23, 52, 20, 650000, tzinfo=tzoffset(None, -28800)),
'https://www.redfin.com/FL/Miramar/Undisclosed-address-33025/home/188607448': datetime.datetime(2023, 11, 18, 3, 59, 37, 511000, tzinfo=tzoffset(None, -28800))
}We can then use the Python Redfin scraper we wrote earlier to scrape these URLs for property datasets.
Bypass Redfin Blocking with ScrapFly
Scraping Redfin.com seems very straight-forward though, when scraping at scale our scrapers are very likely to be blocked or asked to solve captchas. This is where Scrapfly can lend you a hand!

For example, we can use the scrapfly-sdk python package and the Anti Scraping Protection Bypass feature.
To take advantage of ScrapFly's API in our Redfin.com web scraper all we need to do is change our httpx session code with scrapfly-sdk client requests:
import httpx
from parsel import Selector
response = httpx.get("some redfin.com url")
selector = Selector(response.text)
# in ScrapFly SDK becomes
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient("Your ScrapFly API key")
result = client.scrape(ScrapeConfig(
"some Redfin.com url",
# we can select specific proxy country
country="US",
# and enable anti scraping protection bypass:
asp=True
))
selector = result.selectorLearn more about Web Scraping API and how it works.
FAQ
Is it legal to scrape Redfin.com?
Yes. Redfin.com's data is available publically; we're not collecting anything private. Scraping Redfin at slow, respectful rates would fall under the ethical scraping definition.
That being said, attention should be paid to GDRP compliance in the EU when storing personal data such as seller's name, phone number etc. For more, see our Is Web Scraping Legal? article.
Does Redfin.com have an API?
Currently, redfin.com doesn't have a public API. However, we have seen that we can use redfin's private APIs to get property listing data. Redfin also publishes market summary datasets in their data-center section.
How to crawl Redfin.com?
Like scraping, we can also crawl redfin.com by following related rental pages listed on every property page. To write a Redfin crawler, see the related properties field in datasets scraped in this tutorial.
Are there alternatives to Redfin?
Yes, besides Redfin, Zillow and Realtor.com are major US real estate platforms. For UK real estate data, consider RightMove and Zoopla.
Redfin Scraping Summary
In this tutorial, we built a Redfin scraper in Python with a few free community packages. We started by taking a look at how to scrape property pages using redfin's private API and HTML selectors. We also explained how to scrape redfin.com search pages using the search API. Finally, we explained how to find property listings and track new/updated properties on redfin's sitemap system.
For this Redfin data scraper we used Python with httpx and parsel packages. To avoid being blocked, we used ScrapFly's API, which smartly configures every web scraper connection to avoid being blocked.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


