

In this web scraping tutorial, we'll be taking a look at how to scrape Realtor.com - the biggest real estate marketplace in the United States.
In this guide, we'll be scraping real estate data such as pricing info, addresses, photos and phone numbers displayed on Realtor.com property pages.
Realtor.com is easy to scrape and in this guide, we'll be taking advantage of its hidden web data systems to quickly scrape entire property datasets. We'll also take a look at how to use the search system to find all property listings in specific areas.
Finally, we'll also cover tracking to scrape newly listed or sold properties or properties that have updated their pricing - giving us an upper hand in real estate bidding!
We'll be using Python with a few community packages that'll make this web scraper a breeze. Let's dive in!
Key Takeaways
Master realtor.com scraping with advanced Python techniques, hidden data extraction, and anti-blocking strategies for comprehensive real estate data collection.
- Extract hidden JSON data from Realtor.com's NEXT_DATA script tags using XPath selectors for complete property datasets
- Reverse engineer search API endpoints by analyzing browser network requests to discover pagination and filtering parameters
- Implement concurrent scraping with asyncio for efficient property data collection across multiple pages
- Parse structured property data including prices, addresses, photos, and metadata from embedded JSON responses
- Configure realistic headers and user agents to bypass anti-scraping measures and avoid detection
- Use specialized tools like ScrapFly for automated realtor.com scraping with anti-blocking features
Latest Realtor.com Scraper Code
Why Scrape Realtor.com?
Realtor.com is one of the biggest real estate websites in the United States making it the biggest public real estate dataset out there. Containing fields like real estate prices, listing locations and sale dates and general property information.
This is valuable information for market analytics, the study of the housing industry, and a general competitor overview.
For more on scraping use cases see our extensive write-up Scraping Use Cases
Project Setup
In this tutorial, we'll be using Python with two community packages:
- httpx - HTTP client library which will let us communicate with Realtor.com's servers
- parsel - HTML parsing library which will help us to parse our web scraped HTML files.
These packages can be easily installed via the pip install command:
$ pip install httpx parsel
Alternatively, feel free to swap httpx out with any other HTTP client package such as requests as we'll only need basic HTTP functions which are almost interchangeable in every library. As for, parsel, another great alternative is the beautifulsoup package.

Scraping Property Data
Let's dive right in and see how can we scrape data of a single property listed on realtor.com. Then, we'll also take a look at how to find these properties and scale up our scraper.
For example, let's start by taking a look at the listing page and where is all of the information stored on it. Let's pick a random property listing, like:
realtor.com/realestateandhomes-detail/149-3rd-Ave_San-Francisco_CA_94118_M16017-14990We can see that this page contains a lot of data and parsing everything using CSS selectors or XPath selectors would be a lot of work. Instead, let's take a look at the page source of this page.
If we look up some unique identifier (like the realtor's phone number or address) in the page source we can see that this page contains hidden web data which holds the whole property dataset:

Let's see how can we scrape it using Python. We'll retrieve the property HTML page, find the <script> containing the hidden web data and parse it as a JSON document:
import asyncio
import json
from typing import List
import httpx
from parsel import Selector
from typing_extensions import TypedDict
# First, we sneed to establish a persisten HTTPX session
# with browser-like headers to avoid instant blocking
BASE_HEADERS = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
}
session = httpx.AsyncClient(headers=BASE_HEADERS)
# type hints fo expected results - property listing has a lot of data!
class PropertyResult(TypedDict):
property_id: str
listing_id: str
href: str
status: str
list_price: int
list_date: str
... # and much more!
def parse_property(response: httpx.Response) -> PropertyResult:
"""parse Realtor.com property page"""
# load response's HTML tree for parsing:
selector = Selector(text=response.text)
# find <script id="__NEXT_DATA__"> node and select it's text:
data = selector.css("script#__NEXT_DATA__::text").get()
if not data:
print(f"page {response.url} is not a property listing page")
return
# load JSON as python dictionary and select property value:
data = json.loads(data)
return data["props"]["pageProps"]["initialReduxState"]
async def scrape_properties(urls: List[str]) -> List[PropertyResult]:
"""Scrape Realtor.com properties"""
properties = []
to_scrape = [session.get(url) for url in urls]
# tip: asyncio.as_completed allows concurrent scraping - super fast!
for response in asyncio.as_completed(to_scrape):
response = await response
if response.status_code != 200:
print(f"can't scrape property: {response.url}")
continue
properties.append(parse_property(response))
return properties
Run Code & Example Output
async def run():
# some realtor.com property urls
urls = [
"https://www.realtor.com/realestateandhomes-detail/12355-Attlee-Dr_Houston_TX_77077_M70330-35605"
]
results = await scrape_properties(urls)
print(json.dumps(results, indent=2))
if __name__ == "__main__":
asyncio.run(run())
The resulting dataset is too big to embed into this article so download the JSON dataset using this link.
We can see that our simple scraper received an extensive property dataset containing everything we see on the page like property price, address, photos and realtor's phone number as well as meta information fields that are not visible on the page.

Now that we know how to scrape a single property, let's take a look at how can we find properties to scrape next!
Finding Realtor.com Properties
There are several ways to find properties on Realtor.com however the easiest and most reliable way is to use their search system. Let's take a look at how Realtor.com's search works and how can we scrape it.
If we type in a location into the Realtor's search bar we can see a few important bits of information:
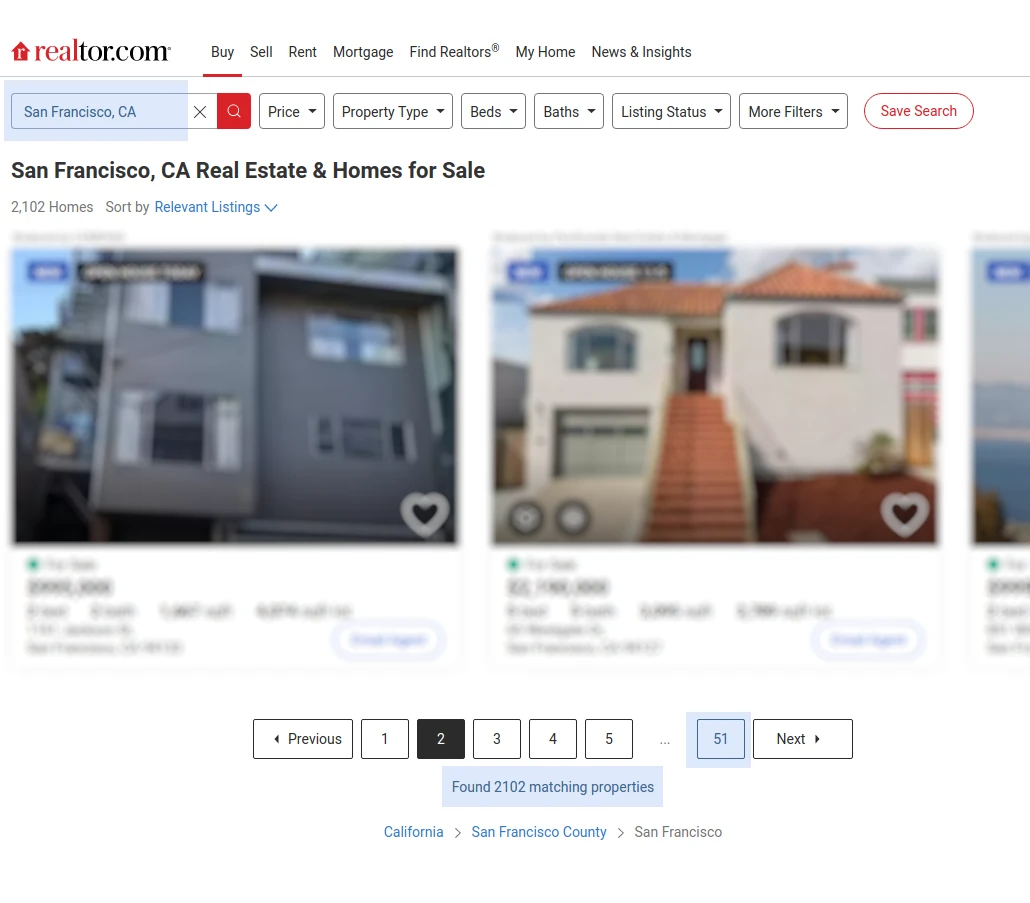
The search automatically redirects us to the results URL which contains property listings and pagination metadata (how many listings are available in this area). If we further click on the second page we can see a clear URL pattern that we can use in our scraper:
realtor.com/realestateandhomes-search/<CITY>_<STATE>/pg-<PAGE>
Knowing this we can write our scraper that scrapes all property listings from a given geographical location variables - city and state:
import asyncio
import json
import math
from typing import List, Optional
import httpx
from parsel import Selector
from typing_extensions import TypedDict
# 1. Establish persisten HTTPX session with browser-like headers to avoid blocking
BASE_HEADERS = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
}
session = httpx.AsyncClient(headers=BASE_HEADERS, follow_redirects=True)
...
# Type hints for search results
# note: the property preview contains a lot of data though not the whole dataset
class PropertyPreviewResult(TypedDict):
property_id: str
listing_id: str
permalink: str
list_price: int
price_reduces_amount: Optional[int]
description: dict
location: dict
photos: List[dict]
list_date: str
last_update_date: str
tags: List[str]
... # and more
# Type hint for search results of a single page
class SearchResults(TypedDict):
count: int # results on this page
total: int # total results for all pages
results: List[PropertyPreviewResult]
def parse_search(response: httpx.Response) -> SearchResults:
"""Parse Realtor.com search for hidden search result data"""
selector = Selector(text=response.text)
data = selector.css("script#__NEXT_DATA__::text").get()
if not data:
print(f"page {response.url} is not a property listing page")
return
data = json.loads(data)["props"]["pageProps"]
if not data.get('properties'): # a|b testing, sometimes it's in a different location
data['properties'] = data["searchResults"]["home_search"]["results"]
if not data.get('totalProperties'):
data['totalProperties'] = data['searchResults']['home_search']['total']
return data
async def find_properties(state: str, city: str):
"""Scrape Realtor.com search for property preview data"""
print(f"scraping first result page for {city}, {state}")
first_page = f"https://www.realtor.com/realestateandhomes-search/{city}_{state.upper()}/pg-1"
first_result = await session.get(first_page)
first_data = parse_search(first_result)
results = first_data["properties"]
total_pages = math.ceil(first_data["totalProperties"] / len(results))
print(f"found {total_pages} total pages")
to_scrape = []
for page in range(1, total_pages + 1):
assert "pg-1" in str(first_result.url) # make sure we don't accidently scrape duplicate pages
page_url = str(first_result.url).replace("pg-1", f"pg-{page}")
to_scrape.append(session.get(page_url))
for response in asyncio.as_completed(to_scrape):
parsed = parse_search(await response)
results.extend(parsed["properties"])
print(f"scraped search of {len(results)} results for {city}, {state}")
return results
Run Code & Example Output
async def run():
results_search = await find_properties("CA", "San-Francisco")
print(json.dumps(results_search, indent=2))
if __name__ == "__main__":
asyncio.run(run())
Will results in a list of property preview items:
[
{
"property_id": "1601714990",
"list_price": 4780000,
"primary": true,
"primary_photo": { "href": "https://ap.rdcpix.com/3cbf77fa7d09fc28cc037c55ddbfe875l-m4228927009s.jpg" },
"source": { "id": "SFCA", "agents": [ { "office_name": null } ], "type": "mls", "spec_id": null, "plan_id": null },
"community": null,
"products": { "brand_name": "basic_opt_in", "products": [ "co_broke" ] },
"listing_id": "2949512103",
"matterport": false,
"virtual_tours": null,
"status": "for_sale",
"permalink": "149-3rd-Ave_San-Francisco_CA_94118_M16017-14990",
"price_reduced_amount": null,
"other_listings": { "rdc": [ { "listing_id": "2949512103", "status": "for_sale", "listing_key": null, "primary": true } ] },
"description": {
"beds": 4,
"baths": 5,
"baths_full": 4,
"baths_half": 1,
"baths_1qtr": null,
"baths_3qtr": null,
"garage": null,
"stories": null,
"type": "single_family",
"sub_type": null,
"lot_sqft": 3000,
"sqft": 2748,
"year_built": 1902,
"sold_price": 1825000,
"sold_date": "2021-03-29",
"name": null
},
"location": {
"street_view_url": "https://maps.googleapis.com/maps/api/streetview?channel=rdc-streetview&client=gme-movesalesinc&location=149%203rd%20Ave%2C%20San%20Francisco%2C%20CA%2094118&size=640x480&source=outdoor&signature=dNdLpEruVEeKaMpLA7nwKV7lm2o=",
"address": {
"line": "149 3rd Ave",
"postal_code": "94118",
"state": "California",
"state_code": "CA",
"city": "San Francisco",
"coordinate": {
"lat": 37.785838,
"lon": -122.461732
}
},
"county": { "name": "San Francisco", "fips_code": "06075" }
},
"tax_record": { "public_record_id": "5121F94BD44030C02787624D7249A34D" },
"lead_attributes": { "show_contact_an_agent": true, "opcity_lead_attributes": { "cashback_enabled": false, "flip_the_market_enabled": false }, "lead_type": "co_broke", "ready_connect_mortgage": { "show_contact_a_lender": true, "show_veterans_united": true }, "flip_the_market_enabled": false }, "open_houses": null,
"flags": {
"is_coming_soon": null,
"is_pending": null,
"is_foreclosure": null,
"is_contingent": null,
"is_new_construction": null,
"is_new_listing": true,
"is_price_reduced": null,
"is_plan": null,
"is_subdivision": null
},
"list_date": "2022-11-03T07:10:44Z",
"last_update_date": "2022-11-03T00:09:33Z",
"coming_soon_date": null,
"photos": [
{
"href": "https://ap.rdcpix.com/3cbf77fa7d09fc28cc037c55ddbfe875l-m4228927009s.jpg"
},
{
"href": "https://ap.rdcpix.com/3cbf77fa7d09fc28cc037c55ddbfe875l-m3453981500s.jpg"
}
],
"tags": [
"central_air",
"dishwasher",
"family_room",
"fireplace",
"hardwood_floors",
"laundry_room",
"garage_1_or_more",
"basement",
"two_or_more_stories",
"big_yard",
"open_floor_plan",
"floor_plan",
"wine_cellar",
"ensuite",
"lake"
],
"branding": [ { "type": "Office", "photo": null, "name": "Marcus & Millichap" }
],
"home_photos": {
"collection": [
{
"href": "https://ap.rdcpix.com/3cbf77fa7d09fc28cc037c55ddbfe875l-m4228927009s.jpg"
},
{
"href": "https://ap.rdcpix.com/3cbf77fa7d09fc28cc037c55ddbfe875l-m3453981500s.jpg"
}
],
"count": 2
}
},
...
]
Above, our scraper first scrapes the first page for results and how many pages are there in total in this query. Then, it scrapes the remaining pages concurrently returning a list of property URLs.
Following Realtor.com Listing Changes
Realtor.com offers several RSS feeds that announce listed property changes such as:
- Price Change Feed - announces when properties change price.
- Open House Feed - announces open house events.
- Sold Property Feed - announces when properties are being sold.
- New Property Feed - announces when new properties are being listed.
These are great resources if we want to follow to track events in the real estate market. We can observe property price changes, new listings and sales in real-time!
Let's take a look at how can we write a tracker scraper for these feeds that will keep scraping them periodically.
Each of these feeds is split by US state and it's a simple RSS XML file that contains announcements and dates. For example, let's take a look at Price Change Feed for California:
<?xml version="1.0" encoding="utf-8"?>
<rss xmlns:atom="http://www.w3.org/2005/Atom" version="2.0">
<channel>
<title>Price Changed</title>
<link>https://www.realtor.com</link>
<description/>
<atom:link href="https://pubsubhubbub.appspot.com/" rel="hub"/>
<atom:link href="https://www.realtor.com/realestateandhomes-detail/sitemap-rss-price/rss-price-ca.xml" rel="self"/>
<item>
<link>https://www.realtor.com/realestateandhomes-detail/1801-Wedemeyer-St_San-Francisco_CA_94129_M94599-53650</link>
<pubDate>Fri, 04 Nov 2022 08:54:48</pubDate>
</item>
<item>
<link>https://www.realtor.com/realestateandhomes-detail/24650-Amador-St_Hayward_CA_94544_M96649-53504</link>
<pubDate>Fri, 04 Nov 2022 08:55:03</pubDate>
</item>
...
We can see it contains links to properties and dates when the price has changed. So, to write our tracker scraper all we have to do is:
- Scrape the feed every X seconds
- Parse
<link>elements for property URLs - Use our property scraper to collect the datasets
- Save the data (to database or file) and repeat #1
Let's take a look at how would this look in Python. We'll be scraping this feed every 5 minutes and appending results to a JSON-list file (1 JSON object per line):
import asyncio
import json
import math
from datetime import datetime
from pathlib import Path
from typing import Dict, List, Optional
from typing_extensions import TypedDict
import httpx
from parsel import Selector
... # NOTE: include code from property scraping section
async def scrape_feed(url) -> Dict[str, datetime]:
"""scrapes atom RSS feed and returns all entries in "url:publish date" format"""
response = await session.get(url)
selector = Selector(text=response.text, type="xml")
results = {}
for item in selector.xpath("//item"):
url = item.xpath("link/text()").get()
pub_date = item.xpath("pubDate/text()").get()
results[url] = datetime.strptime(pub_date, "%a, %d %b %Y %H:%M:%S")
return results
async def track_feed(url: str, output: Path, interval: int = 60):
"""Track Realtor.com feed, scrape new listings and append them as JSON to the output file"""
# to prevent duplicates let's keep a set of property IDs we already scraped
seen = set()
output.touch(exist_ok=True) # create file if it doesn't exist
try:
while True:
# scrape feed for listings
listings = await scrape_feed(url=url)
# remove listings we scraped in previous loops
listings = {k: v for k, v in listings.items() if f"{k}:{v}" not in seen}
if listings:
# scrape properties and save to file - 1 property as JSON per line
properties = await scrape_properties(list(listings.keys()))
with output.open("a") as f:
f.write("\n".join(json.dumps(property) for property in properties))
# add seen to deduplication filter
for k, v in listings.items():
seen.add(f"{k}:{v}")
print(f"scraped {len(properties)} properties; waiting {interval} seconds")
await asyncio.sleep(interval)
except KeyboardInterrupt: # Note: CTRL+C will gracefully stop our scraper
print("stopping price tracking")
Run Code & Example Output
async def run():
# for example price feed for California
feed_url = f"https://www.realtor.com/realestateandhomes-detail/sitemap-rss-price/rss-price-ca.xml"
# or
await track_feed(feed_url, Path("track-pricing.jsonl"))
if __name__ == "__main__":
asyncio.run(run())
In the example above, we wrote an RSS feed scraper that scrapes Realtor.com announcements. Then we wrote an endless loop scraper, which scrapes this feed and the full property dataset to a JSON-list file.
Bypass Realtor.com Blocking with ScrapFly
Scraping Realtor.com seems to be easy though when scraping at scale we're very likely to be blocked or asked to solve captchas. This is where Scrapfly can lend a hand!

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
For example, using the scrapfly-sdk python package and the Anti Scraping Protection Bypass feature we can replicate our Realtor scraper easily. First, let's install scrapfly-sdk using pip:
$ pip install scrapfly-sdk
To take advantage of ScrapFly's API in our Realtor.com web scraper all we need to do is change our httpx session code with scrapfly-sdk client requests:
import httpx
response = httpx.get("some realtor.com url")
# in ScrapFly SDK becomes
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient("YOUR SCRAPFLY KEY")
result = client.scrape(ScrapeConfig(
"some Realtor.ocm url",
# we can select specific proxy country
country="US",
# and enable anti scraping protection bypass:
asp=True
))
For more on how to scrape Realtor.com using ScrapFly, see the Full Scraper Code section.
FAQ
To wrap this guide up, let's take a look at some frequently asked questions about web scraping Realtor.com data:
Is it legal to scrape Realtor.com?
Yes. Realtor.com's data is publicly available; we're not extracting anything personal or private. Scraping Realtor.com at slow, respectful rates would fall under the ethical scraping definition.
That being said, attention should be paid to GDRP compliance in the EU when scraping personal data of non-agent listings (seller's name, phone number etc). For more, see our Is Web Scraping Legal? article.
Does Realtor.com have an API?
No, realtor.com doesn't offer a public API for property data. However, as seen in this guide, it's really easy to scrape property data and track property changes using Realtro.com's official RSS feeds.
How to crawl Realtor.com?
Like scraping we can also crawl realtor.com by following related rental pages listed on every property page. For that see relatedRentals field in datasets scraped in the Scraping Property Data section
Are there alternatives to Realtor.com?
Yes, besides Realtor.com, Zillow and Redfin are major US real estate platforms. For UK real estate data, consider RightMove and Zoopla.
Realtor.com Scraping Summary
In this tutorial, we built a Realtor.com scraper in Python. We started by taking a look at how to scrape a single property page by extracting hidden web data.
Then, we've taken a look at how to find properties using Realtor.com's search system. We build a search URL from the given parameters and scraped all of the listings listed in the query pagination.
Finally, we've taken a look at how to track changes on realtor.com like price changes, sales and new listing announcements by scraping the official RSS feed.
For all of this, we used Python with httpx and parsel packages and to avoid being blocked we used ScrapFly's API that smartly configures every web scraper connection to avoid being blocked.
For more about ScrapFly, see our documentation and try it out for FREE!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.





