

Homegate.ch is one of the most popular websites for real estate ads in Switzerland, which includes thousands of various property listings.
In this article, we'll explore how to scrape homegate.ch search and property pages. We'll explore how to avoid homegate.ch web scraping blocking. Let's dig in!
Key Takeaways
Extract Swiss real estate data from Homegate.ch using hidden web data techniques and JSON parsing for comprehensive property market analysis.
- Use browser developer tools to identify and extract data from
window.__INITIAL_STATE__script tags containing structured JSON - Parse property listings from both individual property pages and search result pages using XPath selectors
- Implement concurrent scraping with asyncio to handle multiple property URLs simultaneously for faster data collection
- Configure proper headers and user agents to mimic real browser behavior and avoid detection
- Handle pagination by extracting total page counts and scraping all search result pages systematically
- Use ScrapFly SDK with anti-scraping protection and Swiss proxy locations for reliable large-scale scraping
Latest Homegate.ch Scraper Code
Why Scrape Homegate.ch?
Homegate.com offers access to a comprehensive overview of the real estate market in Switzerland, including exploring different property types, price trends, and geographical variations.
Manually exploring these property listings can be time-consuming. Web scraping homegate.com automates this process, allowing for retrieving data quickly and reliably.
Scraping homegate.com can also help investors and buyers with market research and analysis. Where they can identify market trends and evaluate property values, allowing for better decision-making.
Project Setup
In this guide about homegate.com web scraping, we'll use a few Python libraries:
httpx: HTTP client used for sending requests.parsel: HTML parsing library for selecting elements using Parsing HTML with Xpath and Parsing HTML with CSS Selectors selectors.scrapfly-sdk: A Python SDK for a web scraping API that allows for scraping at scale without blocking.asyncio: A library used for running asynchronous code, resulting in increasing web scraping speed.
Note that asyncio is already pre-installed in Python. Install the other libraries using the following pip command:
pip install httpx parsel scrapfly-sdkHow to Scrape Homegate.ch Property Pages?
Let's begin by scraping homegate.ch pages. Go to any property listing page and you will get a page similar to this:
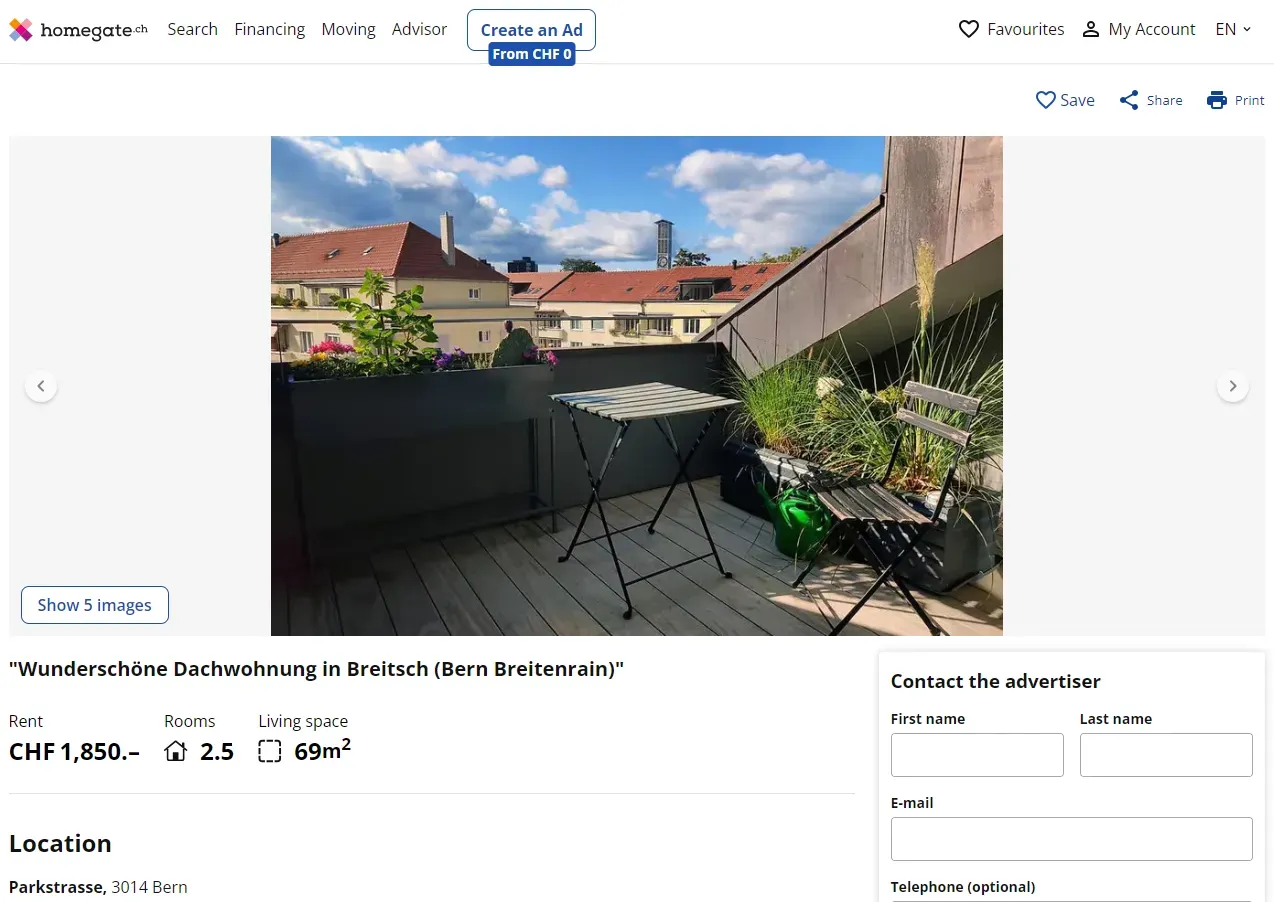
Instead of selecting each data point from the HTML using selectors, we will extract all the data directly from script tags in JSON. This data is the same on the HTML but before getting rendered, which is often known as hidden web data.
To view this data on the property page, click the F12 key to open developer tools and scroll down to the script tag that looks like the following HTML:

We can see all the property data in this script as JSON dataset. Let's select and parse it within our scraper:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
client = AsyncClient(
headers={
# use same headers as a popular web browser (Chrome on Windows in this case)
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "en-US,en;q=0.9",
}
)
def parse_next_data(response: Response) -> Dict:
"""parse listing data from homegate search"""
selector = Selector(response.text)
# extract data in JSON from script tags
next_data = selector.xpath("//script[contains(text(),'window.__INITIAL_STATE__')]/text()").get()
if not next_data:
return
# remove the non-json data and load the data into a JSON object
next_data_json = json.loads(next_data.strip("window.__INITIAL_STATE__="))
return next_data_json
async def scrape_properties(urls: List[str]) -> List[Dict]:
"""scrape listing data from homegate proeprty pages"""
# add the property pages in a scraping list
to_scrape = [client.get(url) for url in urls]
properties = []
# scrape all property pages concurrently
for response in asyncio.as_completed(to_scrape):
data = parse_next_data(await response)
# handle expired property pages
try:
properties.append(data["listing"]["listing"])
except:
print("expired propery page")
pass
return properties import asyncio
import json
from typing import List, Dict
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
def parse_next_data(response: ScrapeApiResponse) -> Dict:
"""parse data from script tags"""
selector = response.selector
# extract data in JSON from script tags
next_data = selector.xpath("//script[contains(text(),'window.__INITIAL_STATE__')]/text()").get()
if not next_data:
return
next_data_json = json.loads(next_data.strip("window.__INITIAL_STATE__="))
return next_data_json
async def scrape_properties(urls: List[str]) -> List[Dict]:
"""scrape listing data from homegate proeprty pages"""
# add the property pages in a scraping list
to_scrape = [ScrapeConfig(url, asp=True, country="CH") for url in urls]
properties = []
# scrape all property pages concurrently
async for response in scrapfly.concurrent_scrape(to_scrape):
data = parse_next_data(response)
# handle expired property pages
try:
properties.append(data["listing"]["listing"])
except:
print("expired propery page")
pass
return properties Run the code
if __name__ == "__main__":
properties_data = asyncio.run(scrape_properties(
urls = [
"https://www.homegate.ch/derent/4000269209"
"https://www.homegate.ch/derent/4000249686",
"https://www.homegate.ch/derent/4000228352",
"https://www.homegate.ch/derent/4000205406",
"https://www.homegate.ch/derent/4000184236",
"https://www.homegate.ch/derent/4000161842",
"https://www.homegate.ch/derent/4000269199",
"https://www.homegate.ch/derent/3003548501",
"https://www.homegate.ch/derent/3003536052",
"https://www.homegate.ch/derent/3003528174"
]
))
print(json.dumps(properties_data, indent=2))First, we initialize an async httpx client and create two functions:
parse_next_data(), which we use to extract the property data fromscripttag.scrape_properties(), to iterate over property page URLs to scrape each page data.
Finally, we append the results to the properties array and run the code using asyncio.
The result is a list containing the property listing data of each page:
Example output
[
{
"localization": {
"de": {
"urls": [],
"text": {
"title": "Wundersch\u00f6ne Studio nah an der Aare",
"description": "Hier gibt es eine Wundersch\u00f6ne Wohnung f\u00fcr 6 Monaten zum Untermieten. Die Wohnung liegt 5 Minuten zu Fuss von der Zytggloge entfernt. Das Quartiert ist sehr ruhig und die Aare ist sehr nah. Die Wohnung steht im EG mit einem grossen Garten. Die Wohnung ist M\u00f6bliert. <br />Mietzeit: Von 0 1.0 1.2024 - 3 1.06.2024 oder nach Vereinbarung."
},
"attachments": [
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/tuttifill/4000269209/image/dc9c3db6460f3c1457add5a42f67e347.jpg",
"file": "tutti_bf80186656b1c2e9b931bf405c3452d2.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/tuttifill/4000269209/image/aeacf7d7d7fabbb498b57a96907f5b29.jpg",
"file": "tutti_cef7bf8df7cb17b21bbbdb6b3a0c7d9e.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/tuttifill/4000269209/image/a384ca98f8d3181a928a165481b0d98d.jpg",
"file": "tutti_4a7f4d82fb342ff362a0ba890bbe7c03.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/tuttifill/4000269209/image/5efc934fd15635182b050454a939b8a7.jpg",
"file": "tutti_2b1003d25abe397283e57d227f951c44.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/tuttifill/4000269209/image/cf1a0b2375c1d92181bd6111e090b41d.jpg",
"file": "tutti_24273421432273f7c15abf603c5b9468.jpg"
}
]
},
"primary": "de"
},
"lister": {
"legalName": "Vasudeva",
"website": {
"value": "https://www.tutti.ch"
},
"id": "tuttifill",
"contacts": {
"inquiry": {},
"viewing": {}
},
"allowToContact": false
},
"characteristics": {
"livingSpace": 41,
"numberOfRooms": 1
},
"address": {
"country": "CH",
"geoDistances": [
{
"distance": -10388.31841047525,
"geoTag": "geo-canton-bern"
},
{
"distance": -1630.4206584556755,
"geoTag": "geo-city-bern"
},
{
"distance": -25.65459540747564,
"geoTag": "geo-citydistrict-spitalacker"
},
{
"distance": -381.384373064381,
"geoTag": "geo-cityregion-breitenrain-lorraine"
},
{
"distance": -49071.31884307248,
"geoTag": "geo-country-switzerland"
},
{
"distance": -1630.4206584556755,
"geoTag": "geo-region-bern"
},
{
"distance": -6713.433647590513,
"geoTag": "geo-region-bern-mittelland"
},
{
"distance": -1630.4206584556755,
"geoTag": "geo-zipcode-3000"
},
{
"distance": -332.83439266090625,
"geoTag": "geo-zipcode-3013"
}
],
"geoTags": [
"geo-canton-bern",
"geo-city-bern",
"geo-citydistrict-spitalacker",
"geo-cityregion-breitenrain-lorraine",
"geo-country-switzerland",
"geo-region-bern",
"geo-region-bern-mittelland",
"geo-zipcode-3000",
"geo-zipcode-3013"
],
"street": "Altenberg",
"postalCode": "3013",
"locality": "Bern",
"geoCoordinates": {
"accuracy": "HIGH",
"manual": false,
"latitude": 46.955141562119,
"longitude": 7.446921501257
}
},
"externalIds": {
"internalReferenceId": "tuttifill#63014477##",
"displayReferenceId": "63014477",
"refObject": "63014477",
"displayPropertyReferenceId": "63014477",
"propertyReferenceId": "tuttifill#63014477##"
},
"contactForm": {
"size": "NO_ADDRESS",
"deliveryFormat": "NORMAL"
},
"version": 1,
"platforms": [
"homegate",
"alleimmobilien",
"home",
"immostreet"
],
"offerType": "RENT",
"meta": {
"createdAt": "2023-10-26T07:17:48.108Z",
"updatedAt": "2023-10-27T07:16:58.050Z",
"source": "FILSINGER"
},
"id": "4000269209",
"categories": [
"APARTMENT",
"FLAT"
],
"prices": {
"rent": {
"area": "ALL",
"interval": "MONTH",
"gross": 1520
},
"currency": "CHF"
},
"valueAddedServices": {
"isTenantPlusListing": true
}
}
]Now that our code can scrape homagate.ch property pages, let's scrape search pages to discover the desired property listings.
How to Scrape Homegate.ch Search Pages?
In this section, we'll create a homegate.ch scraper to scrape search pages of any search query. We'll also integrate pagination support. The pagination is controlled through the ep url parameter, so the first page for properties in Bern, Switzerland looks like this:
https://www.homegate.ch/derent/real-estate/city-bern/matching-list?ep=1As for the data itself, just like in property pages, the search page data can be found in a script tag as well as a JSON dataset:
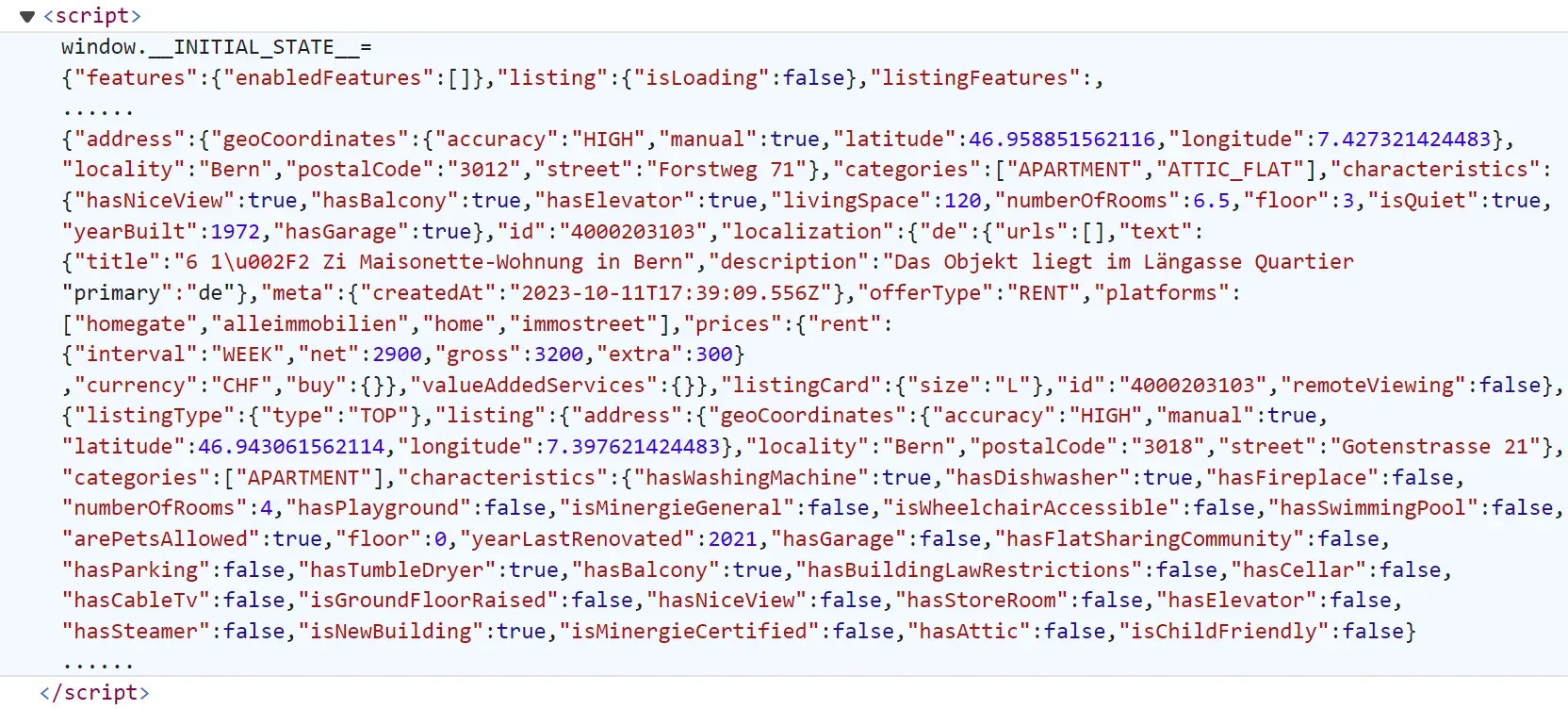
To scrape search pages, we'll use a code similar to the homegate.ch scraper we wrote earlier:
import asyncio
import json
from typing import List, Dict, Literal
from httpx import AsyncClient, Response
from parsel import Selector
client = AsyncClient(
headers={
# use same headers as a popular web browser (Chrome on Windows in this case)
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "en-US,en;q=0.9",
}
)
def parse_next_data(response: Response) -> Dict:
"""parse listing data from homegate search"""
selector = Selector(response.text)
# extract data in JSON from script tags
next_data = selector.xpath("//script[contains(text(),'window.__INITIAL_STATE__')]/text()").get()
if not next_data:
return
next_data_json = json.loads(next_data.strip("window.__INITIAL_STATE__="))
return next_data_json
async def scrape_search(query_type: Literal["rent", "buy"] = "rent") -> List[Dict]:
"""scrape listing data from homegate search pages"""
# change the below URL to the desired search but validate it in the browser first
url = f"https://www.homegate.ch/de{query_type}/real-estate/city-bern/matching-list"
# scrape the first search page first
first_page = await client.get(url)
data = parse_next_data(first_page)["resultList"]["search"]["fullSearch"]["result"]
search_data = data["listings"]
# get the number of maximum search pages available
max_search_pages = data["pageCount"]
print(f"scraped first search page, remaining ({max_search_pages} search pages)")
# add the remaining search pages in a scraping list
other_pages = [client.get(url=str(first_page.url) + f"?ep={page}") for page in range(2, max_search_pages + 1)]
# scrape the remaining search pages concurrently
for response in asyncio.as_completed(other_pages):
data = parse_next_data(await response)
search_data.extend(data["resultList"]["search"]["fullSearch"]["result"]["listings"])
print(f"scraped {len(search_data)} property listings from search")
return search_dataimport asyncio
import json
from typing import List, Dict, Literal
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
def parse_next_data(response: ScrapeApiResponse) -> Dict:
"""parse data from script tags"""
selector = response.selector
# extract data in JSON from script tags
next_data = selector.xpath("//script[contains(text(),'window.__INITIAL_STATE__')]/text()").get()
if not next_data:
return
next_data_json = json.loads(next_data.strip("window.__INITIAL_STATE__="))
return next_data_json
async def scrape_search(query_type: Literal["rent", "buy"] = "rent") -> List[Dict]:
"""scrape listing data from homegate search pages"""
# change the below URL to the desired search but validate it in the browser first
url = f"https://www.homegate.ch/de{query_type}/real-estate/city-bern/matching-list"
# scrape the first search page first
first_page = await scrapfly.async_scrape(ScrapeConfig(url, asp=True, country="CH"))
data = parse_next_data(first_page)["resultList"]["search"]["fullSearch"]["result"]
search_data = data["listings"]
# get the number of maximum search pages available
max_search_pages = data["pageCount"]
print(f"scraped first search page, remaining ({max_search_pages} search pages)")
# add the remaining search pages in a scraping list
other_pages = [
ScrapeConfig(first_page.context['url']+ f"?ep={page}", asp=True, country="CH")
for page in range(2, max_search_pages + 1)
]
# scrape the remaining search pages concurrently
async for response in scrapfly.concurrent_scrape(other_pages):
data = parse_next_data(response)
search_data.extend(data["resultList"]["search"]["fullSearch"]["result"]["listings"])
return search_data Run the code
if __name__ == "__main__":
search_data = asyncio.run(scrape_search(
query_type = "rent",
))
print(json.dumps(search_data, indent=2))Here, we use the scrape_search() function to scrape the first search page data by extracting it from the script tag. Then, we extract the total number of search pages available to scrape. Next, we add the remaining search pages to a scraping list and scrape them concurrently for faster scraping.
The result is a list containing all property listings on the search pages, similar to this:
Example output
[
{
"listingType": {
"type": "PREMIUM"
},
"listing": {
"address": {
"geoCoordinates": {
"accuracy": "HIGH",
"manual": true,
"latitude": 46.958851562115,
"longitude": 7.427321501252
},
"locality": "Bern",
"postalCode": "3012",
"street": "Forstweg 71"
},
"categories": [
"APARTMENT",
"ATTIC_FLAT"
],
"characteristics": {
"hasNiceView": true,
"hasBalcony": true,
"hasElevator": true,
"livingSpace": 150,
"numberOfRooms": 5.5,
"floor": 3,
"isQuiet": true,
"yearBuilt": 1972,
"hasGarage": true
},
"id": "4000203103",
"localization": {
"de": {
"urls": [],
"text": {
"title": "6 1/2 Zi Maisonette-Wohnung in Bern",
"description": "Das Objekt liegt im L\u00e4ngasse Quartier (Endstation Bus) mit wunderbarer Sicht auf die Bergen. Die Gallerie mit Chemin\u00e9e oder das grosse Wohnzimmer laden zum verweilen ein. Grosser Balkon sowie Estrich und Keller vorhanden. Wunderbare heimelige originale \"Fonduestube\". Der Bahnhof und \u00d6V-Anbindungen (Bus) wie auch diverse Einkaufsm\u00f6glichkeiten liegen in attraktiver Entfernung. Schulen und Bremgartenwald liegen in unmittelbarer Umgebung (2-3 Min zu Fuss). Einstellhallenplatz auf Wunsch ebenfalls verf\u00fcgbar."
},
"attachments": [
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/hgonif/4000203103/image/035b210b03b055ffc83b819da5b7f165.jpg",
"file": "43e1277268.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/hgonif/4000203103/image/9fcec0c69d5a40a9bc0bd8c4752aaa15.jpg",
"file": "f3b8f6eb43.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/hgonif/4000203103/image/3c7e560405524a99035e78113c12061d.jpg",
"file": "3be62e1182.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/hgonif/4000203103/image/a903b777eaf5971c791d800f7a138bf1.jpg",
"file": "cff94726e1.jpg"
},
{
"type": "IMAGE",
"url": "https://media2.homegate.ch/listings/v2/hgonif/4000203103/image/dd57c261a15084abcb0305c7a0bfde6d.jpg",
"file": "ee01538c86.jpg"
}
]
},
"primary": "de"
},
"meta": {
"createdAt": "2023-10-11T17:39:09.556Z"
},
"offerType": "RENT",
"platforms": [
"homegate",
"alleimmobilien",
"home",
"immostreet"
],
"prices": {
"rent": {
"interval": "WEEK",
"gross": 4240
},
"currency": "CHF",
"buy": {}
},
"valueAddedServices": {}
},
"listingCard": {
"size": "L"
},
"id": "4000203103",
"remoteViewing": false
}
]We can successfully scrape homegate.ch property and search pages. However, after sending a few requests, our homegate.ch scraper will likely get blocked. Let's take a look at a solution!
How to Avoid Homegate.ch Web Scraping Blocking?
To scale up homegate.ch scraping check out Scrapfly!

For more, explore web scraping API and its documentation.
For example, here is how we can use the asp feature with the ScrapFly Python SDK to avoid homegate.ch web scraping blocking:
import httpx
from parsel import Selector
response = httpx.get("some homegate.ch url")
selector = Selector(response.text)
# in ScrapFly SDK becomes
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly_client = ScrapflyClient("Your ScrapFly API key")
result: ScrapeApiResponse = scrapfly_client.scrape(ScrapeConfig(
# some homegate.ch URL
"https://www.homegate.ch/derent/4000269209",
# we can select specific proxy country
country="CH",
# and enable anti scraping protection bypass:
asp=True,
# allows JavaScript rendering similar to headless browsers
render_js=True
))
# use the built-in parsel selector
selector = result.selectorSign-up now for FREE to get your ScrapFly API key!
FAQ
How do I extract property images and their URLs from Homegate.ch?
Inspect the HTML for <img> tags within property listings. Image URLs are typically in the src or data-src attributes. For high-resolution images, you might need to find a larger version linked within the property details.
What's the best way to handle Homegate.ch's pagination when scraping search results?
Identify the URL pattern for subsequent pages (e.g., ?ep=2). If it's infinite scrolling, use a headless browser to simulate scrolling down to load more content, then extract the newly revealed data.
Can I scrape Homegate.ch's property history and price changes?
Yes, property history and price changes are usually part of the public HTML. Locate the HTML elements containing this data using CSS selectors or XPath. Be mindful of the volume and potential copyright of user-generated content.
How do I handle Homegate.ch's anti-bot protection when scraping at scale?
Use rotating residential or mobile proxies, implement realistic request delays (2-5 seconds), rotate user-agents and headers, use headless browsers for JavaScript rendering, and consider using anti-bot bypass services like ScrapFly.
Why does Homegate.ch return empty JSON data when scraping property pages?
Homegate.ch likely uses anti-bot measures that detect automated requests. They might return empty or obfuscated data to scrapers. Use rotating proxies, realistic headers, and potentially headless browsers to bypass these protections.
Is it legal to scrape homegate.ch?
Yes, all data on homegate.ch are publicly available, so it's legal to scrape homegate.ch as long as you keep your scraping rate reasonable. However, using scraped personal data (like private real estate agent details) from homegate.ch commercially may violate GDRP requirements in EU countries. For more information, refer to our previous article on web scraping legality.
Is there a public API for homegate.ch?
There is no public API for homegate.ch. However, scraping homegate.ch is straightforward using Python as descirbed in this article. Further, the scrapers can be easily turned into APIs using fastapi and real time scraping.
How to avoid homegate.ch web scraping blocking?
There are a lot of factors that contribute to web scraping blocking, including IP addresses, security handshakes, cookies and headers. To avoid homegate.ch scraping blocking, you need to consider these factors. For more information, refer to our previous guide on avoiding web scraping blocking.
Can I scrape other Swiss real estate platforms with this approach?
Yes, Swiss real estate platforms like ImmoScout24.ch share similar page structures using hidden JSON data in script tags.
Web Scraping Homegate.ch Summary
In this article, we wrote a short Homegate scraper using Python. We looked into scraping Homegate properties as well as search pages to discover property datasets.
For that, we focused on hidden web data scraping and extracted property JSON datasets directly from hidden HTML source. Finally, we've taken a look at how to bypass Homegate scraper blocking using ScrapFly.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


