

In this article about web scraping Etsy, we'll scrape items and review data from product, shop and search pages. Moreover, we'll explore to avoid Etsy scraping blocking. Let's get started!
Key Takeaways
Master etsy scraper development with Python to extract product data, reviews, and shop information while bypassing anti-scraping measures for comprehensive e-commerce analysis.
- Reverse engineer Etsy's hidden JSON data embedded in script tags for product details and variants
- Extract structured review data including ratings, comments, and reviewer information from product pages
- Handle Etsy's anti-scraping measures with realistic headers, user agents, and request spacing
- Parse dynamic search results and pagination to collect comprehensive product listings
- Implement error handling and retry logic for rate limiting and temporary blocking scenarios
- Use ScrapFly SDK for automated Etsy scraping with built-in anti-blocking protection
Latest Etsy.com Scraper Code
Why Scrape Etsy.com?
If you are a buyer looking to buy certain items, manually exploring thousands of ad listings to figure out the best deal can be tedious and time-consuming. With etsy.com scraping, we can retrieve thousands of listings and compare them in no time, allowing for better decision-making.
Web scraping etsy.com also allows businesses and sellers to understand and analyze market trends to get insights into consumer behavior.
Furthermore, scraping sellers' and shops' data from Etsy allows business owners to analyze their competitors' and market peers' items, stocks and prices. Leading to taking strategic moves and gaining a competitive edge.
Project Setup
To scrape etsy.com, we'll use a few Python libraries.
scrapfly-sdkfor bypassing etsy.com web scraping blocking using ScrapFly's web scraping API.asynciofor running our code in an asynchronous fashion, increasing our web scraping speed.
As asyncio comes included with Python, so we only have to install scrapfly-sdk using the following pip command:
pip install scrapfly-sdk
How to Scrape Etsy Listings
Let's start by scraping Etsy.com listing pages. Go to any listing page on the website and you will get a page similar to this:
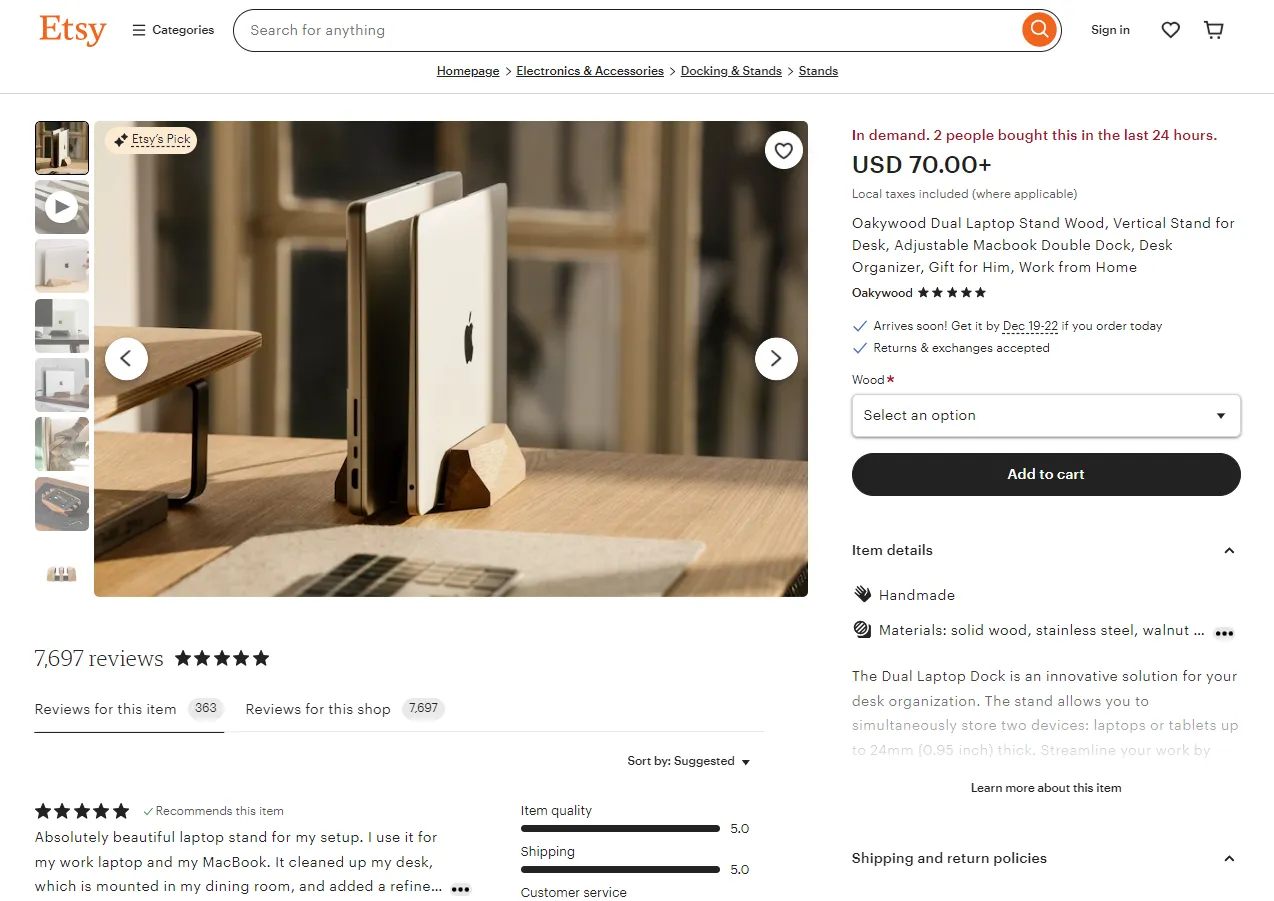
To scrape listing pages' data, we'll extract all the data directly in JSON rather than parsing each data point from the HTML.
To view the hidden listing data, open the browser developer tools (by pressing the F12 key) to view the page HTML. Then, scroll down till you find the script tag with the application/ld+json type. The data inside this tag looks like this:
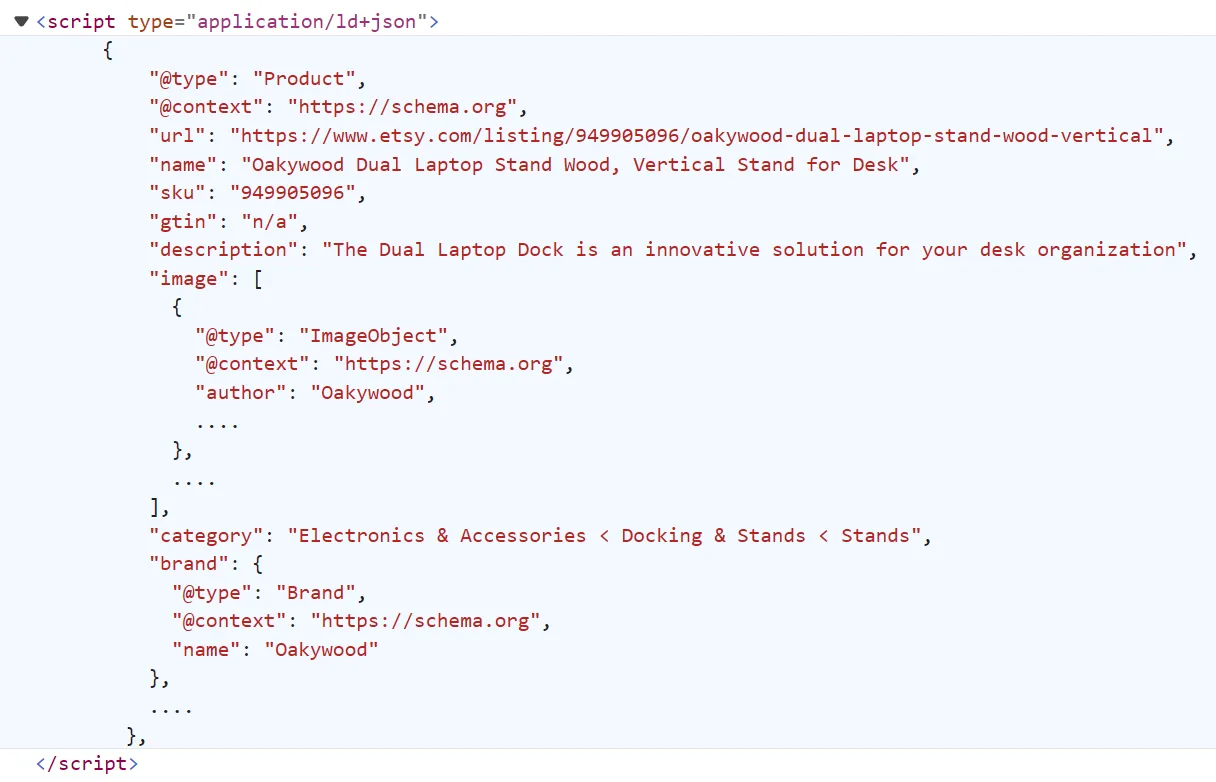
This data is the same on the web page but before getting rendered into the HTML, usually known as hidden web data. To scrape etsy.com listing pages, we'll select this script tag and extract the inside data as JSON directly:
Here, we initialize an httpx client with basic browser headers and define two functions:
parse_product_page()for parsing the HTML and selecting the JSON data inside the script tag.scrape_product()for scraping the product pages by adding the page URLs to a scraping list and scraping them concurrently.
Here is a sample output of the result we got:
Example output
[
{
"@type": "Product",
"@context": "https://schema.org",
"url": "https://www.etsy.com/listing/949905096/oakywood-dual-laptop-stand-wood-vertical",
"name": "Oakywood Dual Laptop Stand Wood, Vertical Stand for Desk, Adjustable Macbook Double Dock, Desk Organizer, Gift for Him, Work from Home",
"sku": "949905096",
"gtin": "n/a",
"description": "The Dual Laptop Dock is an innovative solution for your desk organization. The stand allows you to simultaneously store two devices: laptops or tablets up to 24mm (0.95 inch) thick. Streamline your work by securely storing your gadgets, organizing your desk space, and smoothly switching between the two devices.\n\nWant it PERSONALIZED? Add this - https://www.etsy.com/listing/662276951\n\nF E A T U R E S:\n• supports two devices up to 24mm (0.94 inch) thick and offers adjustable width for a secure fit\n• hand-polished solid oak or walnut wood\n• solid aluminum base - stable & safe\n• one-hand operation - micro-suction tape technology\n• soft wool felt and flock on the inside protects your devices\n• unique geometric design\n\nMake your desk organized and comfortable - choose a multifunctional dual vertical stand, which allows you to store all of your favorite devices! Handcrafted in solid walnut or oak wood, polished by true woodworking enthusiasts.\n\n1 PRODUCT = 1 TREE\nYes! It's that simple! You buy 1 product from us, and we plant 1 tree! You can do something good for the environment while buying products for yourself. Isn’t that great?!\n\nADDITIONAL INFORMATION:\n• Length x Width: 18 x 11.3 cm (7" x 4.45")\n• Height: 4 cm (1.6")\n• Wood is a natural material, thus each individual product may slightly vary in color\n• Handcrafted in Poland, EU\n\nASK US!\nIf you have any other questions about this phone case, please click the "Ask a Question" button next to the price and we’ll get right back to you!\nThank you for shopping at Oakywood!",
"image": [
{
"@type": "ImageObject",
"@context": "https://schema.org",
"author": "Oakywood",
"contentURL": "https://i.etsystatic.com/13285848/r/il/ea7b26/4369079578/il_fullxfull.4369079578_p74k.jpg",
"description": null,
"thumbnail": "https://i.etsystatic.com/13285848/c/1452/1154/149/0/il/ea7b26/4369079578/il_340x270.4369079578_p74k.jpg"
},
....
],
"category": "Electronics & Accessories < Docking & Stands < Stands",
"brand": {
"@type": "Brand",
"@context": "https://schema.org",
"name": "Oakywood"
},
"logo": "https://i.etsystatic.com/isla/7cfa3d/58081234/isla_fullxfull.58081234_fqvaz995.jpg?version=0",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.9",
"reviewCount": 7695
},
"offers": {
"@type": "AggregateOffer",
"offerCount": 2959,
"lowPrice": "70.00",
"highPrice": "80.00",
"priceCurrency": "USD",
"availability": "https://schema.org/InStock"
},
"review": [
{
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": 5,
"bestRating": 5
},
"datePublished": "2023-11-30",
"reviewBody": "Absolutely beautiful laptop stand for my setup. I use it for my work laptop and my MacBook. It cleaned up my desk, which is mounted in my dining room, and added a refined look. The walnut almost perfectly matches the wood of my desk (differences in finishes aside; I can't expect the seller to use tung oil). The included woolen strips help to make each slot perfect for my laptops, both my chunky government one and my thin MBP. The stand hasn't moved, so whatever they put on the bottom to keep it in place is great. Highly recommend this.",
"author": {
"@type": "Person",
"name": "JC Palmer"
}
},
....
],
"material": "Solid Wood/Stainless Steel/Walnut Wood"
},
]
Pretty straightforward! Our Etsy scraper got all the product data and a few reviews with just a few lines of code. Next, we'll scrape shop data!
How to Scrape Etsy Shops
Shop pages on etsy.com include data about the products sold by a shop alongside the shop reviews. Similar to product listing pages, shop page data are also found under script tags:
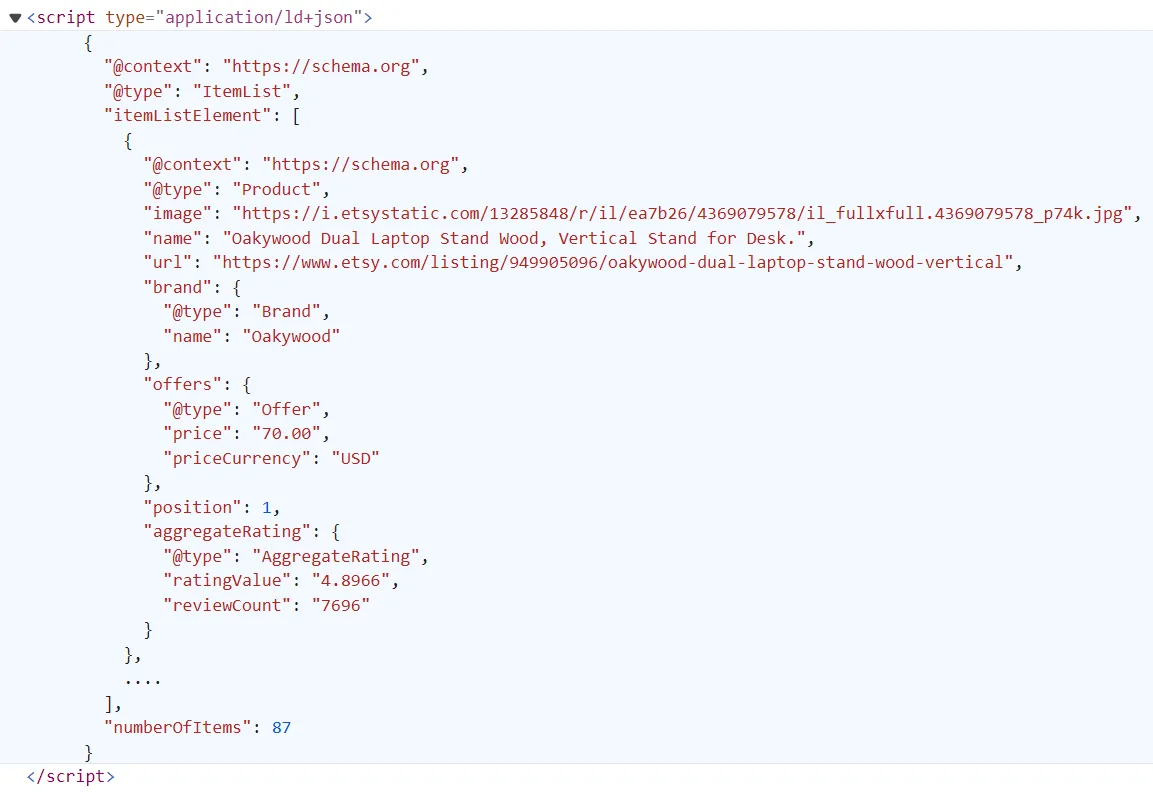
Just like in the previous section, we'll scrape etsy.com shop pages by extracting the data directly from the above script tag:
The above code is the same as the Etsy scraper we wrote earlier. We have only changed the naming and the XPath selector.
Here is a sample output of the result we got:
Sample output
[
{
"@context": "https://schema.org",
"@type": "ItemList",
"itemListElement": [
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/18986650/r/il/42281b/3427680022/il_fullxfull.3427680022_busp.jpg",
"name": "Custom Recipe Journal Anniversary gift Christmas gift, Recipe book For Mom, Leather Bound Cook book, Cookbook Wooden Cover Notebook",
"url": "https://www.etsy.com/listing/1096283182/custom-recipe-journal-anniversary-gift",
"brand": {
"@type": "Brand",
"name": "JoshuaHouseCrafts"
},
"offers": {
"@type": "Offer",
"price": "90.69",
"priceCurrency": "USD"
},
"position": 1
},
....
],
"numberOfItems": 36
}
]
Cool! We are able to scrape product and shop pages from etsy.com. The last piece of our Etsy scraper is the search pages. Let's jump into it!
How to Scrape Etsy Search
In this section, we'll scrape item listing data from search pages. But first, let's look at what the search pages on etsy.com look like. Search for any product on the website and you will get a page similar to this:
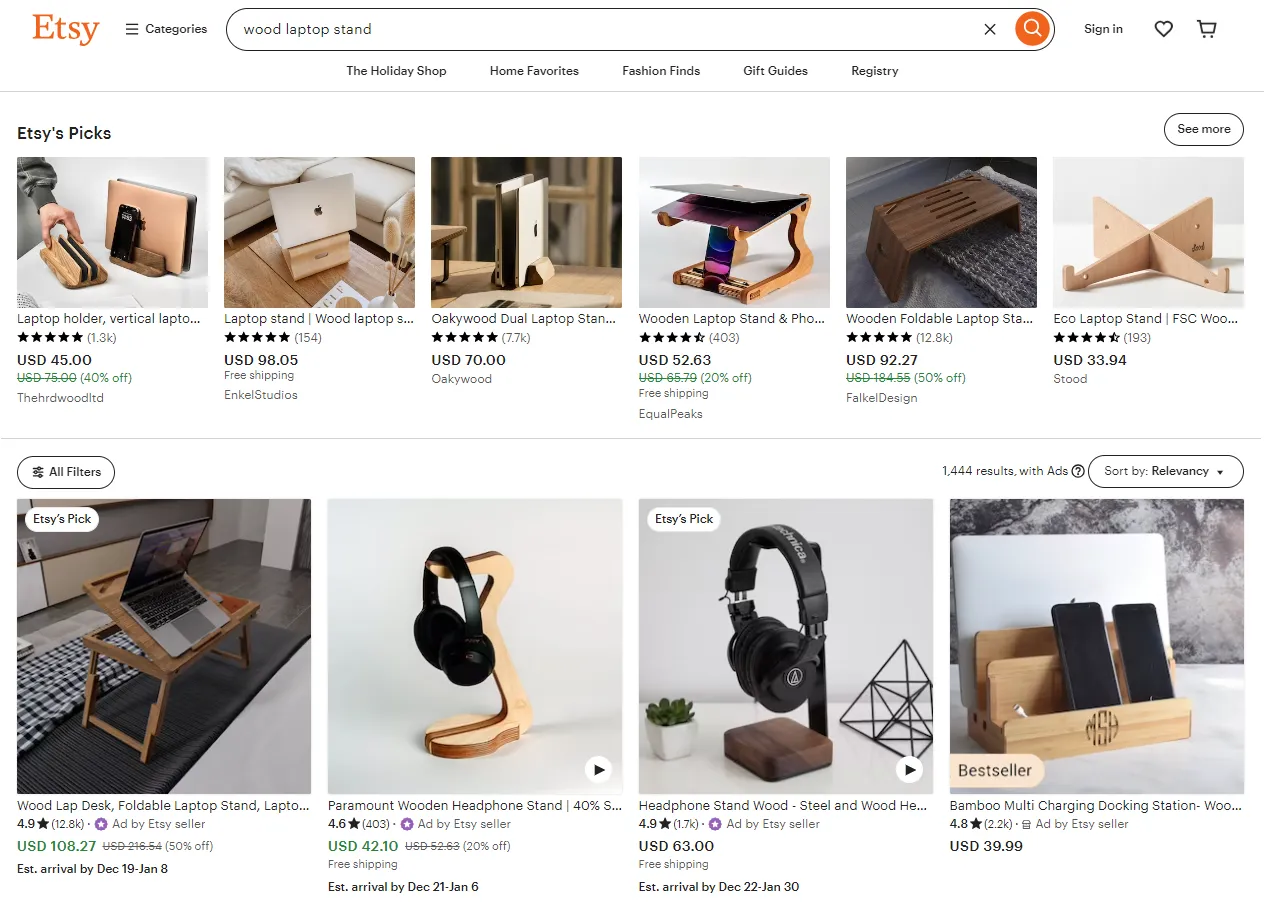
Unlike the product and shop pages, hidden data on search pages don't provide all the search data. For example, here is hidden data on a search page. It contains 8 product listings, but the actual page contains 64 product listings:
Hidden data on a search page
{
"@context": "https://schema.org",
"@type": "ItemList",
"itemListElement": [
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/26507191/r/il/5e963e/3991311170/il_fullxfull.3991311170_1zyv.jpg",
"name": "Wood Laptop Stand for Desk Wooden Computer Laptop Stand Portable Office Desk Accessories",
"url": "https://www.etsy.com/listing/1575517454/wood-laptop-stand-for-desk-wooden",
"brand": {
"@type": "Brand",
"name": "YiYoYo"
},
"offers": {
"@type": "Offer",
"price": "39.20",
"priceCurrency": "USD"
},
"position": 1,
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8875",
"reviewCount": "501"
}
},
....
],
"numberOfItems": 1447
}
So, to scrape Etsy.com search pages, we have to parse each listing data from the HTML. Let's start with that.
Here, we define a scrape_search() function to crawl over the search pages by scraping the first search page and then iterating over the desired number of search pages.
The above etsy.com scraping code should scrape three search pages with a total number of 192 product listings. Here is what the scraped data should look like:
Sample output
[
{
"productLink": "https://www.etsy.com/listing/1584493903",
"productTitle": "Wood Monitor Stand. Wooden Monitor Stand. Laptop Stand. Monitor Riser. Desk Accessories. Speaker Stand. Desk Shelf.",
"productImage": "https://i.etsystatic.com/46053372/c/1688/1688/654/0/il/b98b88/5716635451/il_300x300.5716635451_iyzl.jpg",
"seller": "unfnshed",
"listingType": "Free listing",
"productRate": 4.9,
"numberOfReviews": 87,
"freeShipping": "Yes",
"productPrice": 69.0,
"priceCurrency": "$",
"originalPrice": "No discount",
"discount": "No discount"
},
{
"productLink": "https://www.etsy.com/listing/1572117648",
"productTitle": "Monitor Stand - Monitor Riser, Wood Monitor Stand, Solid Wood Stand, Desk Shelf, Laptop Stand, Speaker Stand, Desk Accessories, Wooden Stand",
"productImage": "https://i.etsystatic.com/46053372/c/1688/1688/654/0/il/b98b88/5716635451/il_300x300.5716635451_iyzl.jpg",
"seller": "KeelanScott",
"listingType": "Free listing",
"productRate": 4.9,
"numberOfReviews": 310,
"freeShipping": "Yes",
"productPrice": 89.99,
"priceCurrency": "$",
"originalPrice": 149.99,
"discount": "(40% off)"
},
{
"productLink": "https://www.etsy.com/listing/1353251909",
"productTitle": "Wood Monitor Stand, Monitor Stand with Drawers, Computer Monitor Riser, Computer Stand, Wood Laptop Stand, Adjustable Desk, Monitor Riser",
"productImage": "https://i.etsystatic.com/46053372/c/1688/1688/654/0/il/b98b88/5716635451/il_300x300.5716635451_iyzl.jpg",
"seller": "woodandscienceteam",
"listingType": "Free listing",
"productRate": 5.0,
"numberOfReviews": 160,
"freeShipping": "Yes",
"productPrice": 69.0,
"priceCurrency": "$",
"originalPrice": 138.0,
"discount": "(50% off)"
},
....
]
Our scraping code is finally complete, which can scrape product, shop and search pages. However, our Etsy scraper will likely get blocked after sending additional requests to the website. Let's take a look at a solution!
Avoid Esty.com Scraping Blocking
Etsy.com is a highly protected website that can detect and block bots such as web scrapers. For example, let's attempt to request a search page on etsy.com with a headless browser to minimize the chances of getting blocked:
from playwright.sync_api import sync_playwright
with sync_playwright() as playwight:
# Lanuch a chrome browser
browser = playwight.chromium.launch(headless=False)
page = browser.new_page()
# Go to leboncoin.fr
page.goto("https://www.etsy.com/search?q=personalized+gifts")
# Take a screenshot
page.screenshot(path="screenshot.png")
Our request has been detected as a bot and we got required to a CAPTCHA challenge before proceeding to the web page:
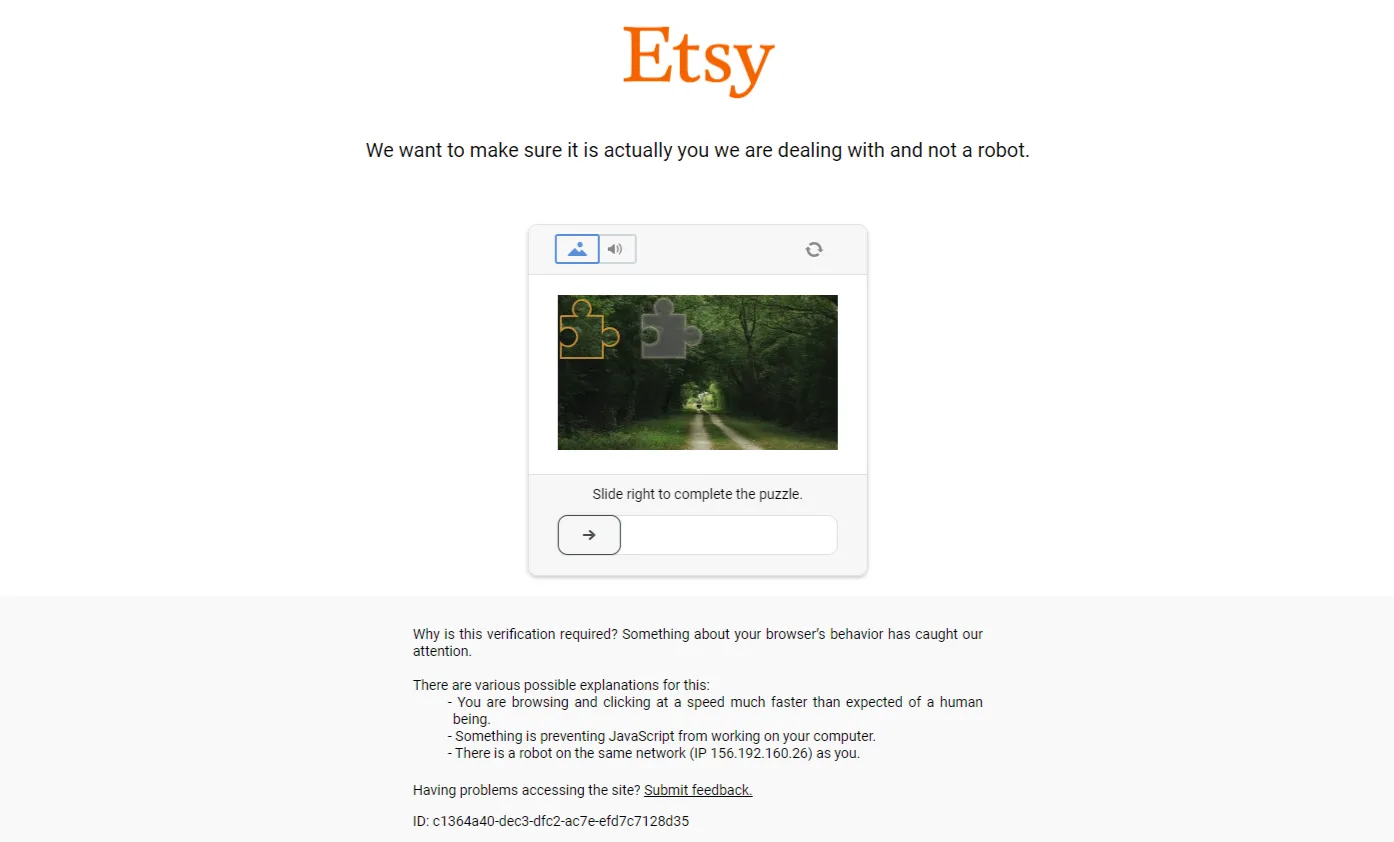
To avoid etsy.com scraping blocking, we'll use ScrapFly.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
For Scrapfly example, all we should do is replace our HTTP client with the ScrapFly client:
import httpx
from parsel import Selector
response = httpx.get("some etsy.com url")
selector = Selector(response.text)
# in ScrapFly SDK becomes
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly_client = ScrapflyClient("Your ScrapFly API key")
result: ScrapeApiResponse = scrapfly_client.scrape(ScrapeConfig(
# some homegate.ch URL
"https://www.etsy.com/search?q=personalized+gifts",
# we can select specific proxy country
country="US",
# and enable anti scraping protection bypass
asp=True,
# allows JavaScript rendering similar to headless browsers
render_js=True
))
# get the HTML content
html = result.scrape_result['content']
# use the built-in parsel selector
selector = result.selector
FAQ
To wrap up this guide on etsy.com web scraping, let's take a look at some frequently asked questions.
Is scraping etsy.com legal?
All the data on etsy.com are publicly available and it's legal to scrape them as long as you don't affect the website performance by keeping your scraping rate reasonable. However, you should pay attention to the GDPR compliance in the EU, which stands against scraping personal data, such as scraping sellers' personal data on Etsy. Refer to our previous guide on web scraping legality for more details.
Is there a public API for etsy.com?
There are no public Etsy API endpoints available however it's Etsy.com is easy and legal to scrape. You can use the scraper code described in this tutorial to create your own web scraping API.
Are there alternatives for etsy.com?
Yes, for more scrape guides about websites similar to Etsy, refer to our #scrapeguide blog tag.
Web Scraping Etsy.com - Summary
In this article, we explained how to scrape etsy.com, a popular website for hand-crafted and gift products.
We went through a step-by-step process on how to scrape product and review data from Etsy products, shop and search pages using Python. We have seen that etsy.com can detect and block web scrapers. And for that, we have used ScrapFly to avoid Etsy web scraping blocking.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.




