

Booking.com is the biggest travel reservation service out there, and it contains public data on thousands of hotels, resorts, airbnbs and so on. In 2026, Booking.com continues to rely on dynamic content loading and anti-bot measures, making HTTP/2 support and proper request headers essential for successful scraping.
In this tutorial, we'll take a look at how to scrape booking.com in Python programming language.
We'll start with a quick overview of booking.com's website functions. Then, we'll replicate its behavior in our python scraper to scrape hotel information and price data.
Finally, we'll wrap everything up by taking a look at some tips and tricks and frequently encountered challenges when web scraping booking.com. So, let's dive in!
Key Takeaways
Learn to scrape Booking.com hotel data and pricing using Python with httpx and parsel, handling dynamic content, anti-bot measures, and geographic restrictions for comprehensive travel data extraction.
- Reverse engineer Booking.com's search API endpoints by intercepting browser network requests
- Handle dynamic content loading with proper request headers and HTTP/2 support for anti-blocking
- Parse hotel data including names, prices, ratings, and availability from search results and detail pages
- Implement geographic targeting and language preferences to access region-specific hotel data
- Bypass Booking.com's anti-scraping measures with realistic headers, rate limiting, and proxy rotation
- Extract structured pricing data including currency conversion and seasonal rate variations
Latest Booking.com Scraper Code
Project Setup
In this tutorial, we'll be using Python with Scrapfly's Python SDK.
It can be easily installed using the below pip command:
$ pip install scrapfly-sdkFinding Booking Hotels
Our first step is to figure out how we can discover hotel pages, so we can start scraping their data. On Booking.com platform, we have several ways to achieve that.
Using Sitemaps
Booking.com is easily accessible through its vast sitemap system. Sitemaps are compressed XML files that contain all URLs available on the websites categorized by subject.
To find sitemaps, we first must visit the /robots.txt page, and here we can find Sitemap links:
Sitemap: https://www.booking.com/sitembk-airport-index.xml
Sitemap: https://www.booking.com/sitembk-articles-index.xml
Sitemap: https://www.booking.com/sitembk-attractions-index.xml
Sitemap: https://www.booking.com/sitembk-beaches-index.xml
Sitemap: https://www.booking.com/sitembk-beach-holidays-index.xml
Sitemap: https://www.booking.com/sitembk-cars-index.xml
Sitemap: https://www.booking.com/sitembk-city-index.xml
Sitemap: https://www.booking.com/sitembk-country-index.xml
Sitemap: https://www.booking.com/sitembk-district-index.xml
Sitemap: https://www.booking.com/sitembk-hotel-index.xml
Sitemap: https://www.booking.com/sitembk-landmark-index.xml
Sitemap: https://www.booking.com/sitembk-region-index.xml
Sitemap: https://www.booking.com/sitembk-tourism-index.xml
Sitemap: https://www.booking.com/sitembk-themed-city-villas-index.xml
Sitemap: https://www.booking.com/sitembk-themed-country-golf-index.xml
Sitemap: https://www.booking.com/sitembk-themed-region-budget-index.xmlHere, we can see URLs categorized by cities, landmarks or even themes. For example, if we take a look at the /sitembk-hotel-index.xml we can see that it splits into another set of sitemaps as a single sitemap is only allowed to contain 50 000 results:
<sitemapindex xmlns="http://www.google.com/schemas/sitemap/0.9">
<sitemap>
<loc>https://www.booking.com/sitembk-hotel-zh-tw.0037.xml.gz</loc>
<lastmod>2022-05-17</lastmod>
</sitemap>
<sitemap>
<loc>https://www.booking.com/sitembk-hotel-zh-tw.0036.xml.gz</loc>
<lastmod>2022-05-17</lastmod>
</sitemap>
...Here, we have 1710 sitemaps - meaning 85 million links to various hotel pages. Of course, not all are unique hotel pages (some are duplicates), but that's the easiest and most efficient way to discover hotel listing pages on booking.com.
Using sitemaps is an efficient and easy way to find hotels, but it's not a flexible discovery method. Usually, when we scrape this type of data we have specific areas or categories in mind.
To scrape hotels available in a specific area or containing certain features, we need to scrape Booking.com's search system instead. So, let's take a look at how to do that.
Scraping Booking.com Search
Alternatively, we can take advantage of the search system running on booking.com just like a human user would.
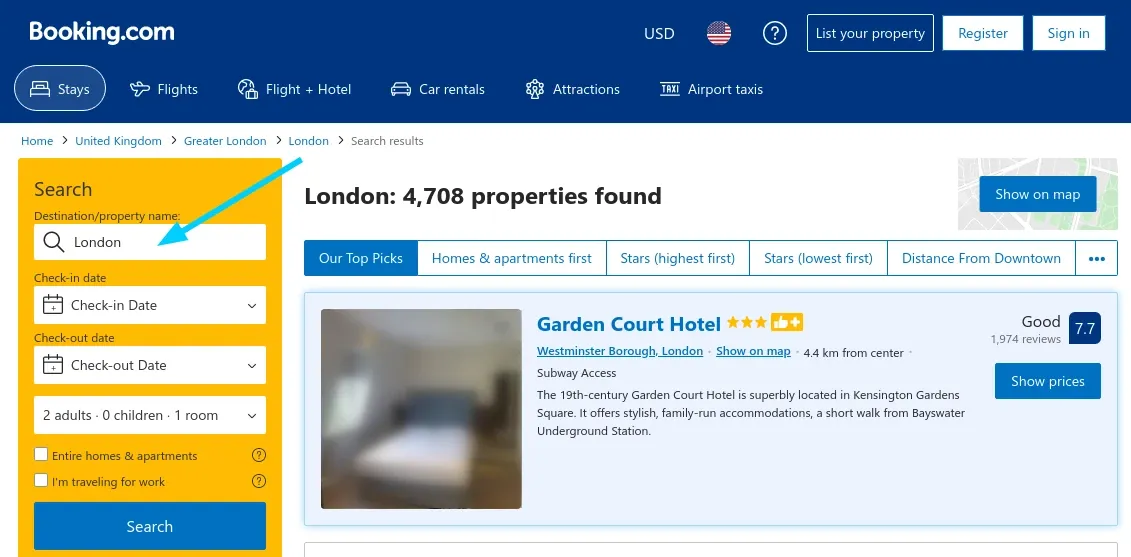
Booking's search might appear to be complex at first because of long URLs, but if we dig a bit deeper, we can see that it's rather simple, as most URL parameters are optional. For example, let's take a look at this query of "Hotels in London":
https://www.booking.com/searchresults.html?label=gen173nr-1DCAEoggI46AdIM1gEaN0BiAEBmAExuAEKyAEF2AED6AEB-AECiAIBqAIDuAK-u5eUBsACAdICJGRlN2VhYzYyLTJiYzItNDE0MS1iYmY4LWYwZjkxNTc0OGY4ONgCBOACAQ
&sid=51b2c8cd7b3c8377e83692903e6f19ca
&sb=1
&sb_lp=1
&src=index
&src_elem=sb
&error_url=https%3A%2F%2Fwww.booking.com%2Findex.html%3Flabel%3Dgen173nr-1DCAEoggI46AdIM1gEaN0BiAEBmAExuAEKyAEF2AED6AEB-AECiAIBqAIDuAK-u5eUBsACAdICJGRlN2VhYzYyLTJiYzItNDE0MS1iYmY4LWYwZjkxNTc0OGY4ONgCBOACAQ%26sid%3D51b2c8cd7b3c8377e83692903e6f19ca%26sb_price_type%3Dtotal%26%26
&ss=London%2C+Greater+London%2C+United+Kingdom
&is_ski_area=
&ssne=London
&ssne_untouched=London
&checkin_year=2022
&checkin_month=6
&checkin_monthday=9
&checkout_year=2022
&checkout_month=6
&checkout_monthday=11
&group_adults=2
&group_children=0
&no_rooms=1
&b_h4u_keep_filters=
&from_sf=1
&search_pageview_id=f25c2a9ee3630134
&ac_suggestion_list_length=5
&ac_suggestion_theme_list_length=0
&ac_position=0
&ac_langcode=en
&ac_click_type=b
&dest_id=-2601889
&dest_type=city
&iata=LON
&place_id_lat=51.507393
&place_id_lon=-0.127634
&search_pageview_id=f25c2a9ee3630134
&search_selected=true
&ss_raw=LondonLots of scary parameters! Fortunately, we can distill it to a few mandatory ones in our Python web scraper! Now that we are fimilar with the available query paremeters on search pages, let's jump into the exciting part about data extraction!
Search pages use dynamic scroll actions to load more results. Simulating scroll actions using headless browser automation to load more results is possible, but it's not recommended. Since search pages can include thousands of results, it makes it unrealistic to scroll tens of pages in a single session.
Alternatively, we'll scrape the hidden APIs responsible for fetching search results while scrolling. To capture this API, follow the below steps:
- Open the browser developer tools by pressing the
F12key. - Select the network tab and filter by
Fetch/XHRrequests. - Scroll down the page to load more data.
After following the above steps, you will find the a request sent to the booking.com/dml/graphql captured:

The above request represents a Web Scraping Graphql with Python call. In order to scrape it, we have to fetch the required request body from the search HTML page:
First, we define our scrape_search() function which loops through our previously defined search_page() function to scrape all pages instead of just the first one. We do this by taking advantage of a common web scraping idiom for scraping known size pagination -- we scrape the first page, find the number of results and scrape the rest of the pages concurrently.
Another key parameter here is offset which controls the search result paging. Providing offset tells that we want 25 results to start from the X point of the result set. So, let's use it to implement full paging and hotel preview data parsing.
In addition, we define three functions, let's break them down:
generate_graphql_request: To create a request object with the required body, offset, and headers. It represents the main search API calls for the search data.retrieve_graphql_body: To parse the GraphQL request body from the HTML. Note that the body uses aqueryobject, which can be retreived the browser XHR calls.parse_graphql_response: To parse the response of the search API requests.

Here's a sample output of the results we got:
Example output:
[
{
"bookerExperienceContentUIComponentProps": [],
"matchingUnitConfigurations": null,
"location": {
"publicTransportDistanceDescription": "Bethnal Green station is within 150 metres",
"__typename": "SearchResultsPropertyLocation",
"beachDistance": null,
"nearbyBeachNames": [],
"geoDistanceMeters": null,
"beachWalkingTime": null,
"displayLocation": "Tower Hamlets, London",
"mainDistance": "5.5 km from centre",
"skiLiftDistance": null
},
"showAdLabel": false,
"relocationMode": null,
"mlBookingHomeTags": [],
"priceDisplayInfoIrene": null,
"basicPropertyData": {
"isTestProperty": false,
"ufi": -2601889,
"externalReviewScore": null,
"id": 3788761,
"isClosed": false,
"pageName": "yotel-london-shoreditch",
"photos": {},
"paymentConfig": null,
"accommodationTypeId": 204,
"__typename": "BasicPropertyData",
"starRating": {
"value": 3,
"caption": {
"translation": "This star rating is provided to Booking.com by the property, and is usually determined by an official hotel rating organisation or another third party. ",
"__typename": "TranslationTag"
},
"tocLink": {
"__typename": "TranslationTag",
"translation": "Learn more on the \"How we work\" page"
},
"showAdditionalInfoIcon": false,
"__typename": "StarRating",
"symbol": "STARS"
},
"location": {
"address": "309 - 317 Cambridge Heath Road Bethnal Green",
"countryCode": "gb",
"city": "London",
"__typename": "Location"
},
"reviewScore": {
"showScore": true,
"score": 7.6,
"secondaryTextTag": {
"__typename": "TranslationTag",
"translation": null
},
"showSecondaryScore": false,
"secondaryScore": 0,
"totalScoreTextTag": {
"translation": "Good",
"__typename": "TranslationTag"
},
"__typename": "Reviews",
"reviewCount": 4116
}
},
....
]We've successfully scraped booking.com's search page to discover hotels located in London. Furthermore, we got some valuable metadata and URL to the hotel page itself so next, we can scrape detailed hotel data and pricing!
Scraping Booking.com Hotel Data
Now that we have a scraper that can scrape booking.com's hotel preview data we can further collect remaining hotel data like description, address, feature list etc. by scraping each individual hotel URL.
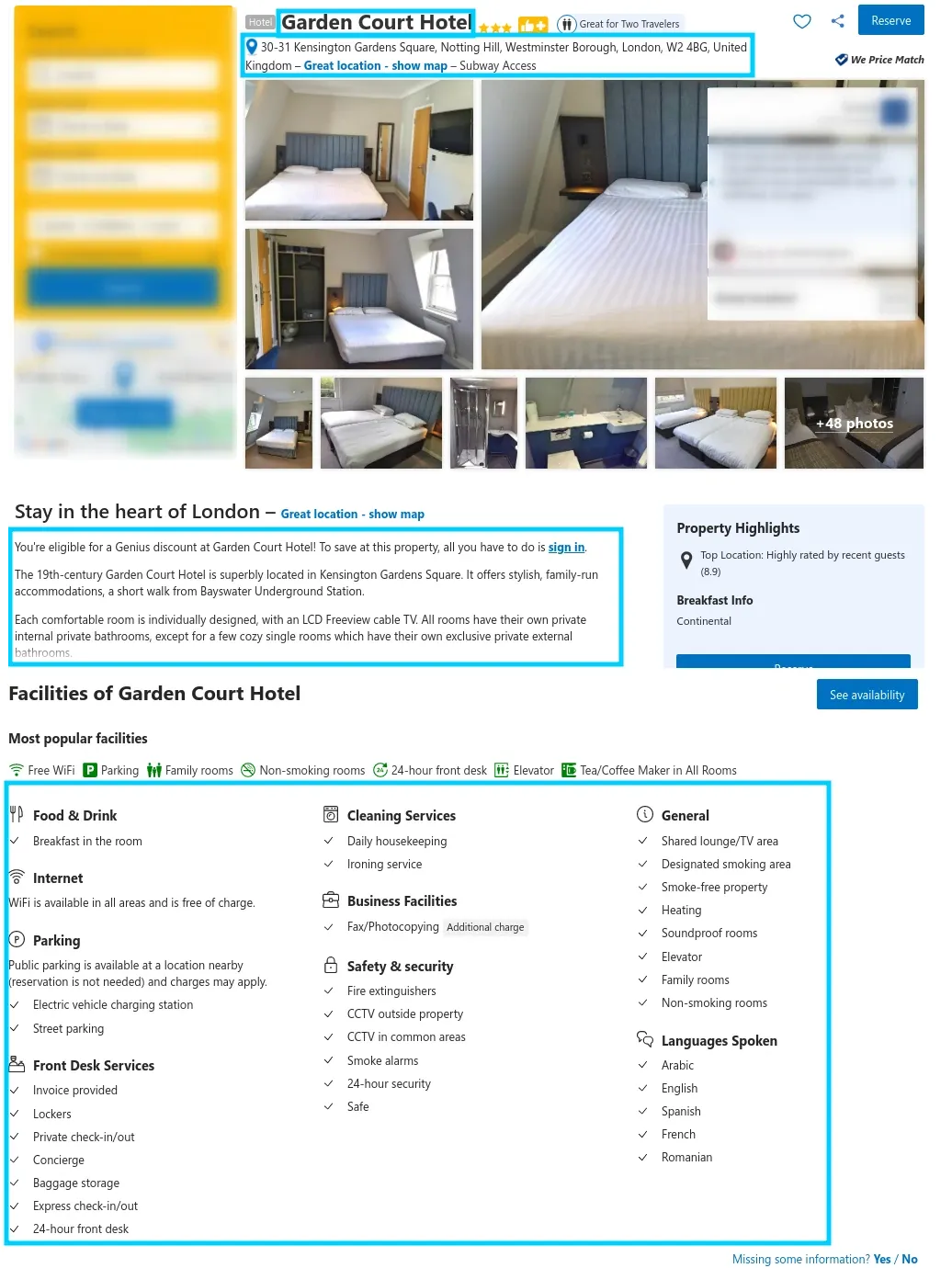
To scrape Booking hotel data, we'll directly parse the HTML using CSS and XPath selectors:
Here, we define our hotel page scraping logic. Our scrape_hotel function takes a list of hotel urls which we scrape via simple GET requests for the HTML data. We then use our HTML parsing library to extract hotel information using selectors.
Example output:
[
{
"title": "Garden Court Hotel",
"description": "You're eligible for a Genius discount at Garden Court Hotel! To save at this property, all you have to do is \nsign in\n.\n\n\nThe 19th-century Garden Court Hotel is ...",
"address": "30-31 Kensington Gardens Square, Notting Hill, Westminster Borough, London, W2 4BG, United Kingdom",
"lat": "51.51431706",
"lng": "-0.19066349",
"features": {
"Food & Drink": [
"Breakfast in the room"
],
"Internet": [],
"Parking": [ "Electric vehicle charging station", "Street parking" ],
"Front Desk Services": [ "Invoice provided", ""],
"Cleaning Services": [ "Daily housekeeping", "Ironing service" ],
"Business Facilities": [ "Fax/Photocopying" ],
"Safety & security": [ "Fire extinguishers", "..."],
"General": [ "Shared lounge/TV area", "..." ],
"Languages Spoken": [ "Arabic", "English", "Spanish", "French", "Romanian" ]
},
"id": "102764",
"url": "https://www.booking.com/hotel/gb/gardencourthotel.html?cur_currency=usd",
"price": [
{
"available": true,
"__typename": "AvailabilityCalendarDay",
"checkin": "2023-07-05",
"minLengthOfStay": 1,
"avgPriceFormatted": "386"
},
{
"available": true,
"__typename": "AvailabilityCalendarDay",
"avgPriceFormatted": "623",
"minLengthOfStay": 1,
"checkin": "2023-07-07"
},
...
]
},
....
]There's significantly more data available on the page but to keep this tutorial brief we only focused on a few example fields.
Scraping Booking.com Hotel Reviews
To scrape booking.com hotel reviews let's take a look at what happens when we explore the reviews page. Let's click 2nd page and observe what happens in our browsers web inspector (F12 in major browsers):
Similar to the product search, product reviews can be extracted from the graphql endpoint:
In our scraper code above, we're using what we learned before: we collect the first page to extract a total number of pages and then scrape the rest of the pages concurrently.
Here's what the retrieved Booking hotel review data should look like:
Example output:
[
{
"isTranslatable": false,
"editUrl": null,
"helpfulVotesCount": 0,
"guestDetails": {
"__typename": "GuestDetails",
"username": "Marco",
"avatarColor": null,
"showCountryFlag": true,
"anonymous": false,
"guestTypeTranslation": "Couple",
"countryName": "Italy",
"countryCode": "it",
"avatarUrl": "https://xx.bstatic.com/static/img/review/avatars/ava-m.png"
},
"isApproved": true,
"reviewUrl": "8895d10df583649c",
"negativeHighlights": null,
"photos": null,
"__typename": "ReviewCard",
"reviewScore": 8.0,
"textDetails": {
"title": null,
"negativeText": "In my opinion, the breakfast could be improved; there is not enough choice.",
"textTrivialFlag": 0,
"__typename": "TextDetails",
"positiveText": "excellent location and beautiful room",
"lang": "en"
},
"positiveHighlights": null,
"partnerReply": {
"reply": "Dear Marco,\n\nThank you very much for the feedback. We are happy you have enjoyed the location and room :)\nWe also appreciate the remarks regarding breakfast.\n\nWarm Regards,\nJessica",
"__typename": "PropertyReplyData"
},
"reviewedDate": 1760961260,
"bookingDetails": {
"roomId": 60181,
"checkinDate": "2025-09-18",
"checkoutDate": "2025-09-23",
"customerType": "COUPLES",
"__typename": "BookingDetails",
"roomType": {
"name": "Double Room",
"__typename": "RoomTranslation",
"id": "60181"
},
"numNights": 5,
"stayStatus": "stayed"
}
},
....
]published_at: 2022-01-01
Finally - our scraper can discover hotels, extract hotel preview data and then scrape each hotel page for hotel information, pricing data and reviews! However, to adopt this scraper at scale we need one final thing - web scraper blocking avoidance.
Bypass Blocking and Captchas with ScrapFly
We looked at how to Scrape Booking.com though unfortunately when scraping at scale it's very likely that Booking will start to either block us or start serving us captchas, which will hinder or completely disable our web scraper.

For this, we'll be using scrapfly-sdk python package. First, let's install scrapfly-sdk using pip:
$ pip install scrapfly-sdkTo take advantage of ScrapFly's API in our Booking web scraper all we need to do is change our httpx session code with scrapfly-sdk client requests. For more see the latest scraper code on github:
FAQ
Is web scraping booking.com legal?
Yes. Booking hotel data is publicly available; we're not extracting anything personal or private. Scraping booking.com at slow, respectful rates would fall under the ethical scraping definition. See our Is Web Scraping Legal? article for more.
How to change currency when scraping booking.com?
Booking.com automatically chooses currency based on client IP's geographical location. The easiest approach is to use a proxy of a specific location; for example, in ScrapFly we can use country=US argument in our request to receive USD prices.
Alternatively, we can manually change the currency for our scraping session via GET request with the selected_currency parameter.
import httpx
with httpx.Client() as session:
currency = 'USD'
url = f"https://www.booking.com/?change_currency=1;selected_currency={currency};top_currency=1"
response = session.get(url)This request will return currency cookies which we can reuse to retrieve any other page in this currency. Note that this has to be done every time we start a new HTTP session.
How to scrape more than 1000 booking.com hotels?
Like many result paging systems, Booking.com's search returns a limited amount of results. In this case, 1000 results per query might not be enough to cover some broader queries fully.
The best approach here, is to split the query into several smaller queries. For example, instead of searching "London", we can split the search by scraping each of London's neighborhoods:
[%img src=./neighborhood-split.webp alt="illustration of booking.com search split" width=400 height=425 %]
Booking.com Scraping Summary
In this web scraping tutorial, we built a small Booking.com scraper that uses search to discover hotel listing previews and then scrapes hotel data and pricing information.
For this we've used Python with httpx and parsel packages and to avoid being blocked we used ScrapFly's API which smartly configures every web scraper connection to avoid being blocked. For more on ScrapFly see our documentation and try it out for free!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


