

In this article, we'll explain how to scrape BestBuy, one of the most popular retail stores for electronic stores in the United States. We'll scrape different data types from product, search, review, and sitemap pages. Additionally, we'll employ a wide range of web scraping tricks, such as hidden JSON data, hidden APIs, HTML, and XML parsing. So, this guide serves as a comprehensive web scraping introduction!
Key Takeaways
Learn to scrape best buy scraper data, reviews, and search results using Python with httpx and parsel, accessing hidden APIs and parsing JSON data embedded in HTML pages.
- Use BestBuy's hidden API endpoints to access product data and review information without JavaScript rendering
- Parse embedded JSON data from HTML script tags to extract comprehensive product and pricing information
- Handle BestBuy's anti-scraping measures with realistic headers, user agents, and request spacing
- Extract structured product data including specifications, pricing, availability, and customer reviews
- Implement XML sitemap parsing to discover all product URLs for comprehensive data collection
- Use ScrapFly SDK for automated BestBuy scraping with anti-blocking and geographic targeting features
Latest BestBuy Scraper Code
Why Scrape BestBuy?
The amount of data that web scraping BestBuy can allow is numerous. It can empower both businesses and retail buyers in different ways:
- Competitive Analysis
The market dynamics are aggressive and fast-changing, making it challenging for businesses to remain competitive. Scraping BestBuy allows businesses to compare their competitors' pricing, sales, and reviews. This provides a better understanding of the current trends and interests to remain up-to-date and attract new customers.
- Customer Sentiment Analysis
BestBuy includes thousands of review data for different products. Web scraping BestBuy's reviews can be used to run sentiment analysis research, which provides useful insights into the customers' satisfaction, preferences, and feedback.
- Empowered Navigation
Manually browsing the excessive number of similar products on BestBuy can be tedious. On the other hand, retailers can web scrape BestBuy to compare many products quickly, allowing them to identify niche markets and undervalued products.
For further details, refer to our introduction on web scraping use cases.
Setup
In this tutorial we'll be using Python with Scrapfly's Python SDK.
It can be easily installed via the below pip command:
$ pip install scrapfly-sdk
How To Discover BestBuy Pages?
Scraping sitemaps is an efficient way to discover thousands of organized URLs. They are provided for search engine crawlers to index the pages, which we can use to discover web scraping targets on a website.
BestBuy's sitemaps can be found at bestbuy.com/robots.txt. It's a text file that provides crawling instructions along with the website's sitemap directory:
Sitemap: https://sitemaps.bestbuy.com/sitemaps_discover_learn.xml
Sitemap: https://sitemaps.bestbuy.com/sitemaps_pdp.xml
Sitemap: https://sitemaps.bestbuy.com/sitemaps_promos.xml
Sitemap: https://sitemaps.bestbuy.com/sitemaps_qna.xml
Sitemap: https://sitemaps.bestbuy.com/sitemaps_rnr.xml
Sitemap: https://sitemaps.bestbuy.com/sitemaps_search_plps.xml
Sitemap: https://sitemaps.bestbuy.com/sitemaps_standalone_qa.xml
Sitemap: https://www.bestbuy.com/sitemap.xml
Each of the above sitemaps represents a group of related page URLs found under an XML file that's compressed to a gzip file to reduce its size:
<?xml version="1.0" encoding="UTF-8"?>
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap><loc>https://sitemaps.bestbuy.com/sitemaps_pdp.0000.xml.gz</loc><lastmod>2024-03-08T10:16:14.901109+00:00</lastmod></sitemap>
<sitemap><loc>https://sitemaps.bestbuy.com/sitemaps_pdp.0001.xml.gz</loc><lastmod>2024-03-08T10:16:14.901109+00:00</lastmod></sitemap>
</sitemapindex>
The above gz file looks like the following after extracting:
<?xml version='1.0' encoding='utf-8'?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml"><url><loc>https://www.bestbuy.com/site/aventon-aventure-step-over-ebike-w-45-mile-max-operating-range-and-28-mph-max-speed-medium-fire-black/6487149.p?skuId=6487149</loc></url>
<url><loc>https://www.bestbuy.com/site/detective-story-1951/34804554.p?skuId=34804554</loc></url>
<url><loc>https://www.bestbuy.com/site/flowers-lp-vinyl/35944053.p?skuId=35944053</loc></url>
<url><loc>https://www.bestbuy.com/site/apple-iphone-15-pro-max-1tb-natural-titanium-verizon/6525500.p?skuId=6525500</loc></url>
<url><loc>https://www.bestbuy.com/site/geeni-dual-outlet-outdoor-wi-fi-smart-plug-gray/6388590.p?skuId=6388590</loc></url>
<url><loc>https://www.bestbuy.com/site/dynasty-the-sixth-season-vol-1-4-discs-dvd/20139655.p?skuId=20139655</loc></url>
To scrape BestBuy's sitemaps, we'll request the compressed XML file, decode it, and parse it for the URLs. For this example, we'll use the promotions sitemap:
In the above code, we define two functions, let's break them down:
scrape_sitemaps: To request the sitemap URL using the definedhttpxclient.parse_sitemaps: To decode thegzfile into its XML content and then parse the XML for the URLs using the XPath selector.
Here is a sample output of the results we got:
[
"https://www.bestbuy.com/site/promo/4k-capable-memory-cards",
"https://www.bestbuy.com/site/promo/all-total-by-verizon",
"https://www.bestbuy.com/site/promo/shop-featured-intel-evo",
"https://www.bestbuy.com/site/promo/laser-heat-therapy",
"https://www.bestbuy.com/site/promo/save-on-select-grills",
....
]
For further details on scraping and discovering sitemaps, refer to our dedicated guide:

How To Scrape BestBuy Search Pages?
Let's start with the first part of our BestBuy scraper code: search pages. Search for any product on the website, like the "macbook" keyword, and you will get a page that looks the following:
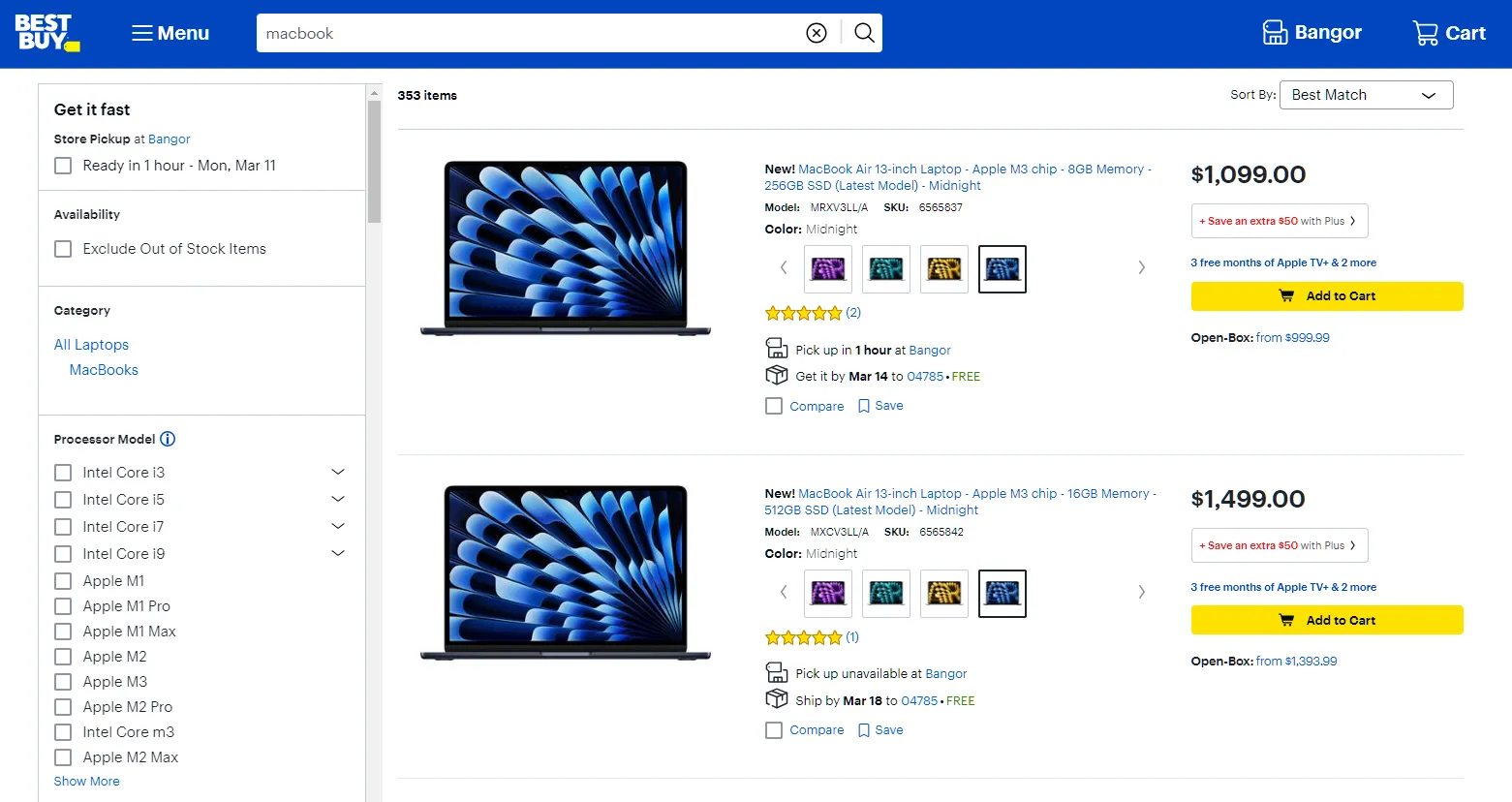
To scrape BestBuy search pages, we'll request the search page URL and then parse the HTML:
Let's break down the execution flow of the above scrape_search function:
- Form a search URL based on the search keyword, sorting option, and page number.
- Request the search URL and parse it with the
parse_searchfunction. - Get the number of pagination pages to scrape using the
max_pagesparameter. - Add the remaining pagination URLs to a list and request them concurrently.
The above BestBuy scraping code will extract product data from three search pages by parsing the data using parse_search function, which does the following:
- Iterates over the product boxes on the HTML.
- Parses each product's data, such as the name, price, link, etc.
- Gets the total number of search pages available and returns the search data.
Here is what the results should look like:
[
{
"name": "Apple - MacBook Air 13-inch Laptop - Apple M4 chip Built for Apple Intelligence - 16GB Memory - 256GB SSD - Midnight",
"link": "https://www.bestbuy.com/product/apple-macbook-air-13-inch-laptop-apple-m4-chip-built-for-apple-intelligence-16gb-memory-256gb-ssd-midnight/JJGCQ8RH7G",
"images": [
"https://pisces.bbystatic.com/image2/BestBuy_US/images/products/317b99e1-058d-4162-88c9-051faf76b924.jpg;maxHeight=256;maxWidth=384?format=webp 1x, https://pisces.bbystatic.com/image2/BestBuy_US/images/products/317b99e1-058d-4162-88c9-051faf76b924.jpg;maxHeight=427;maxWidth=640?format=webp 2x"
],
"sku": "6565862",
"price": "749.00",
"original_price": "999.00",
"rating": "4.9",
"rating_count": 5482
},
....
]
The above code can scrape the product data that is visible on the search pages. However, it can be extended with crawling logic to scrape the full details of each product from its respective URL. For further details on crawling while scraping, refer to our dedicated guide.

How To Scrape BestBuy Product Pages?
Let's add support for scraping product pages to our BestBuy scraper. Before we start, let's have a look at what product pages look like. Go to any product page on the website, like this one, and you will get a page similar to this:
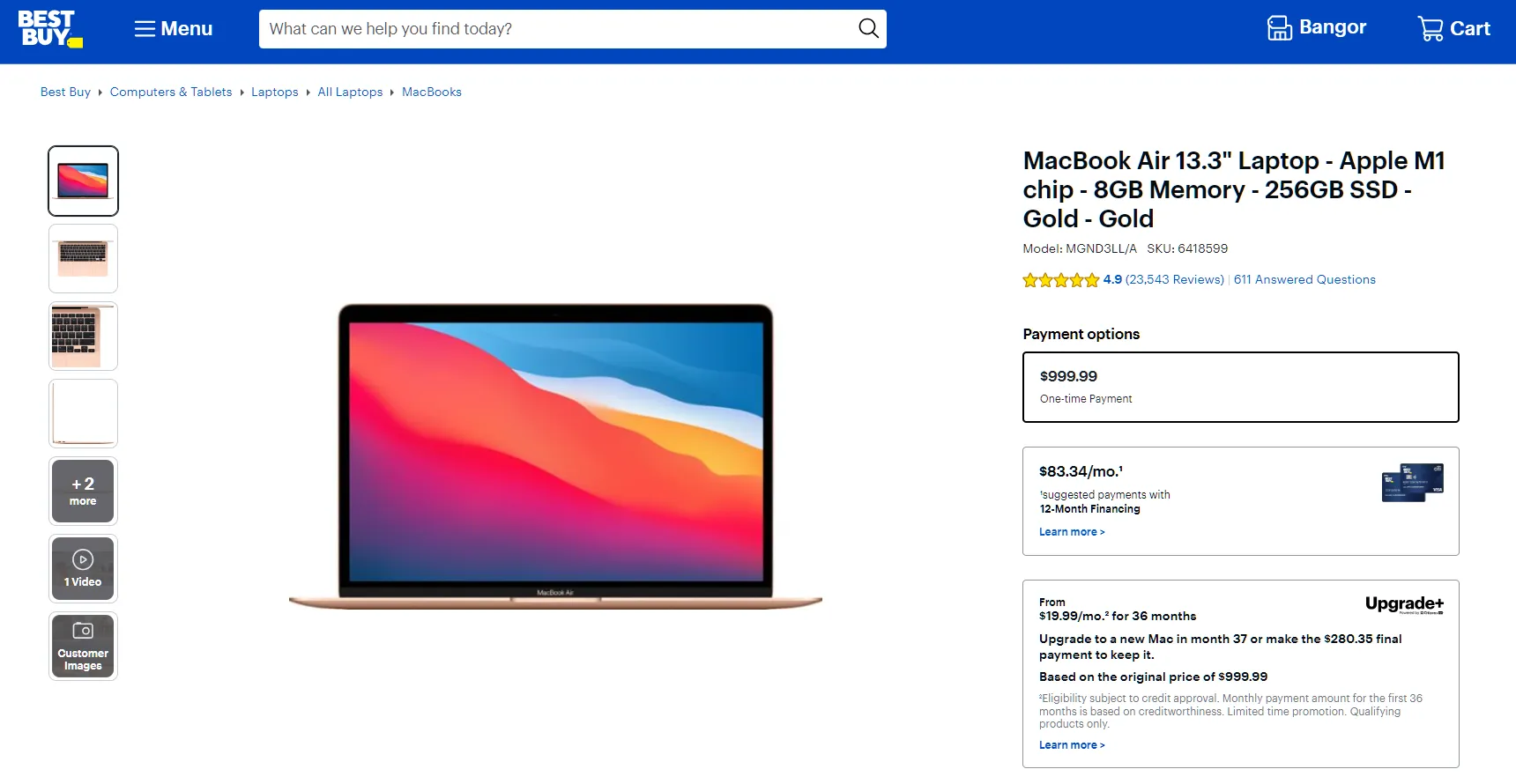
Data on product pages is comprehensive, and it's scattered across the page. Therefore, it's challenging to scrape it using selectors. Instead, we'll scrape them as JSON datasets from script tags. To locate these script tags, follow the below steps:
- Open the browser developer tools by pressing the
F12key. - Search for the script tags using the selector
//script[@type='application/json'].
After following the above steps, you will find several script tags that include JSON data. However, we are only interested in a few of them:

The above JSON data are the same on the page but before getting rendered into the HTML, which is often known as hidden web data.

To scrape the product data, we will select the script tags containing the JSON data and parse them:
Let's break down the above BestBuy scraping code:
refine_product: It refines the product JSON datasets with JMESPath to exclude the unnecessary and keep the useful ones.parse_product: To parse the product hidden JSON data from the HTML with XPath.scrape_products: To request the product page URLs concurrently and parse the HTML output with theparse_productfunction.
The output is a comprehensive JSON dataset that looks like the following:
Sample output
[
{
"specifications": [
{
"displayName": "Key Specs",
"specifications": [
{
"displayName": "Screen Size",
"value": "13.3 inches",
"definition": "Size of the screen, measured diagonally from corner to corner.",
"id": "TQqJBgOyVv"
}
....
]
},
....
],
"pricing": {
"skuId": "6418599",
"regularPrice": 999.99,
"currentPrice": 999.99,
"priceEventType": "regular",
"totalSavings": 0,
"totalSavingsPercent": 0,
"totalPaidMemberSavings": 0,
"totalNonPaidMemberSavings": 0,
"customerPrice": 999.99,
"isMAP": false,
"isPriceMatchGuarantee": true,
"offerQualifiers": [
{
"offerId": "634974",
"offerName": "Apple - Apple Music 3 Month Trial GWP",
"offerVersion": 662398,
"offerDiscountType": "Free",
"id": 634974002,
"comOfferType": "FREEITEM",
"comRuleType": "10",
"instanceId": 5,
"offerRevocableOnReturns": true,
"excludeFromBundleBreakage": false
},
....
],
"giftSkus": [
{
"skuId": "6484511",
"quantity": 1,
"offerId": "465099",
"savings": 0,
"isRequiredWithOffer": false
},
....
],
"totalGiftSavings": 0,
"gspUnitPrice": 999.99,
"financeOption": {
"offerId": "384913",
"financeCodeName": "12-Month Financing",
"financeCode": 7,
"rank": 8,
"financeTerm": 12,
"monthlyPayment": 83.34,
"monthlyPaymentIncludingTax": 83.34,
"defaultPlan": true,
"priority": 1,
"planType": "Deferred",
"rate": 0,
"totalCost": 999.99,
"termsAndConditions": "NO INTEREST IF PAID IN FULL WITHIN 12 MONTHS. If the deferred interest balance is not paid in full by the end of the promotional period, interest will be charged from the purchase date at rates otherwise applicable under your Card Agreement. Min. payments required. See Card Agreement for details.",
"totalCostIncludingTax": 999.99,
"financeCodeDescLong": "No interest if paid in full within 12 months (no points)"
},
"financeOptions": [
{
"offerId": "384913",
"financeCodeName": "12-Month Financing",
"financeCode": 7,
"rank": 8,
"financeTerm": 12,
"monthlyPayment": 83.34,
"monthlyPaymentIncludingTax": 83.34,
"defaultPlan": true,
"priority": 1,
"planType": "Deferred",
"rate": 0,
"totalCost": 999.99,
"termsAndConditions": "NO INTEREST IF PAID IN FULL WITHIN 12 MONTHS. If the deferred interest balance is not paid in full by the end of the promotional period, interest will be charged from the purchase date at rates otherwise applicable under your Card Agreement. Min. payments required. See Card Agreement for details.",
"totalCostIncludingTax": 999.99,
"financeCodeDescLong": "No interest if paid in full within 12 months (no points)"
}
],
....
},
"ratings": {
"featureRatings": [
{
"attribute": "BatteryLife",
"attributeLabel": "Battery Life",
"avg": 4.856636035826451,
"count": 17194
},
....
],
"positiveFeatures": [
{
"name": "Speed",
"score": 4,
"totalReviewCount": 2386
},
....
],
"negativeFeatures": [
{
"name": "Touch screen",
"score": 16,
"totalReviewCount": 168
},
....
]
},
"faqs": [
{
"sku": "6418599",
"questionTitle": "Does this MacBook have a built-in HDMI port?",
"answersForQuestion": [
"No. It has 2 Thunderbolt 3 ports that you can get an adapter for to give you HDMI.",
"No. However, you can connect your MacBook Air to HDMI using the a USB-C Digital AV Multiport Adapter. (sold separately)",
"I am afraid not for Mac book air and pro m1 2020 it has only the thunderbolts 2 points"
]
},
....
]
}
]
🙋 Note that the HTML structure of the BestBuy product pages differs based on product type and category. Therefore, the above product parsing logic should be adjusted for other product types.
Cool! The above BestBuy scraping code can extract the full details of each product. However, it lacks the product reviews - let's scrape them in the next section!
How to Scrape BestBuy Review Pages?
Reviews on BestBuy can be found on each product page:
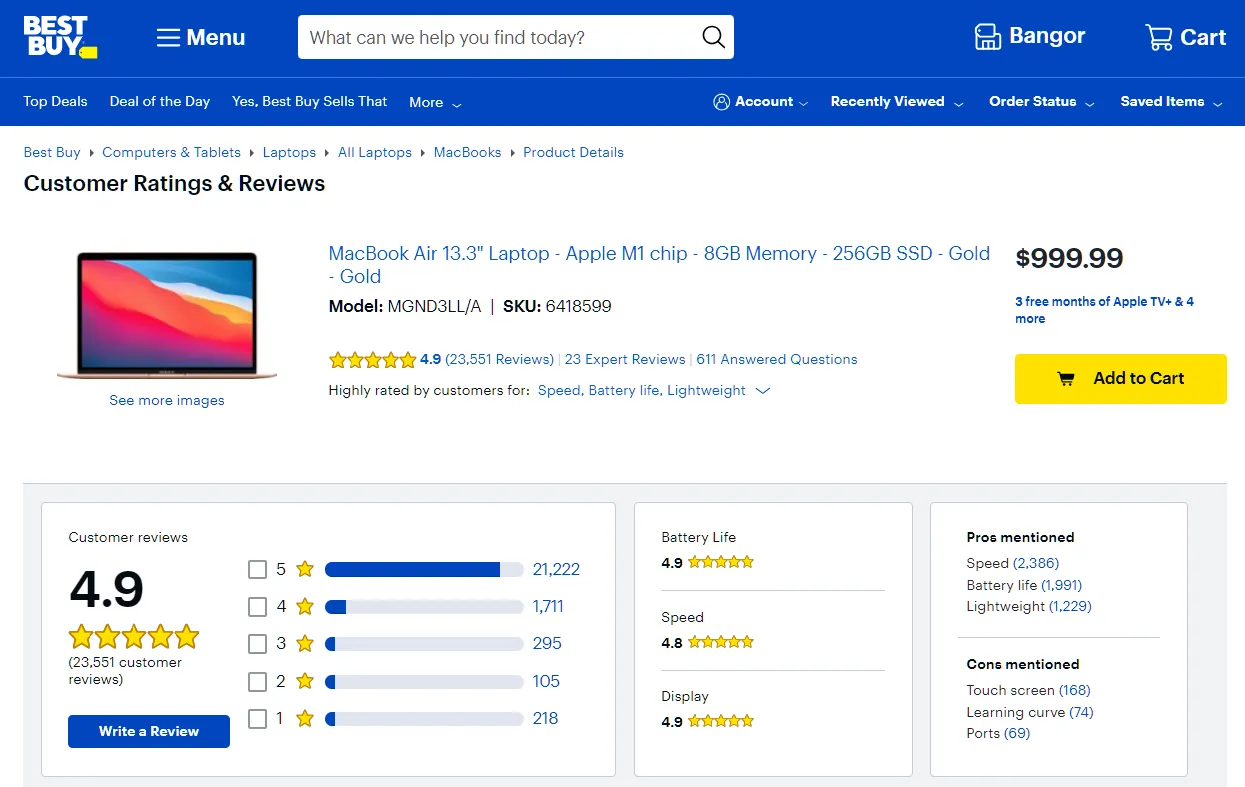
The above review data are split into two categories:
Product ratings
Review and rating data into each product's specification, which we scraped earlier from the product page itself.User reviews
Detailed user reviews of the product, which we'll scrape in this section.
To scrape BestBuy reviews, we'll utilize the hidden reviews API. To locate this API, follow the below steps:
- Open the browser developer tools by pressing the
F12key. - Select the
networktab and filter byFetch/XHRrequests. - Filter the review using the sort option or click on the next review page.
After following the above steps, you will find the reviews API recorded on the browser:
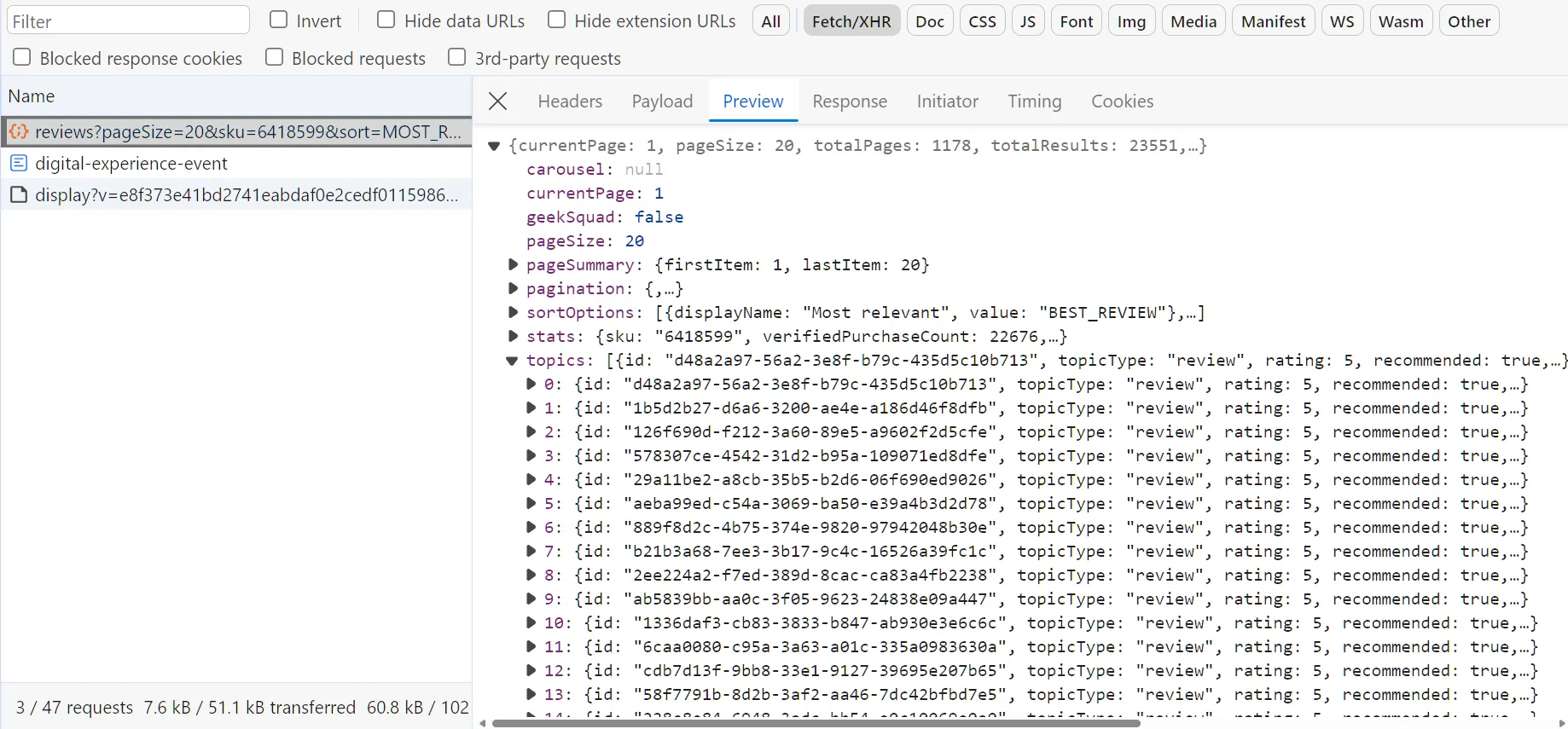
The API above is called in the background using the browser and then rendered into HTML. The request can be copied as a cURL and imported into HTTP clients like Postman.

To scrape the product reviews, we'll request the above API and paginate it:
The above part of our BestBuy scraper is fairly straightforward. We only use two functions:
scrape_reviews: For requesting the reviews API, which accepts product skuID, sorting option, and page number. It starts by requesting the first page and then adding the remaining API URLs to a scraping list to request them concurrently.parse_reviews: For parsing the JSON response of the reviews API. The response contains various review data types, but the function only parses the user reviews.
Here is a sample output of the above BestBuy scraping code:
Sample output
[
{
"id": "6b88383f-3830-3c78-915c-d3cf9f16596d",
"topicType": "review",
"rating": 5,
"recommended": true,
"title": "Amazing!",
"text": "An absolutly amazing console very fast and smooth.",
"author": "CocaNoot",
"positiveFeedbackCount": 0,
"negativeFeedbackCount": 0,
"commentCount": 0,
"writeCommentUrl": "/site/reviews/submission/6565065/review/337294210?campaignid=RR_&return=",
"submissionTime": "2024-03-02T10:52:07.000-06:00",
"brandResponses": [],
"badges": [
{
"badgeCode": "Incentivized",
"badgeDescription": "This reviewer received promo considerations or sweepstakes entry for writing a review.",
"badgeName": "Incentivized",
"badgeType": "Custom",
"fileName": null,
"iconText": null,
"iconPath": null,
"index": 90900
},
....
],
"photos": [
{
"photoId": "008b1a1e-ba1b-38ea-b86e-effb7c0ca162",
"caption": null,
"normalUrl": "https://photos-us.bazaarvoice.com/photo/2/cGhvdG86YmVzdGJ1eQ/e79a5ff1-e891-57fa-ae03-e9f52bb4d7c4",
"piscesUrl": "https://pisces.bbystatic.com/image2/BestBuy_US/ugc/photos/thumbnail/8db68b60f7a60bcea8f6cd1470938da9.jpg",
"thumbnailUrl": "https://photos-us.bazaarvoice.com/photo/2/cGhvdG86YmVzdGJ1eQ/bd287ee8-1c8b-52ae-9c12-4a379d7ecb24",
"reviewId": "6b88383f-3830-3c78-915c-d3cf9f16596d"
}
],
"qualityRating": null,
"valueRating": null,
"easeOfUseRating": null,
"daysOfOwnership": 70,
"pros": null,
"cons": null,
"secondaryRatings": [
{
"attribute": "Performance",
"value": 5,
"attributeLabel": "Performance",
"valueLabel": "Excellent"
},
....
]
},
....
]
With this last feature, our BestBuy scraper is complete. It can scrape sitemaps, search, product, and review data.
Avoid BestBuy Scraping Blocking
We have successfully scraped BestBuy data from various pages. However, attempting to scale our scraping rate will lead the website to block the IP address.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
Here is how we can scrape without getting blocked with ScrapFly. All we have to do is replace the HTTP client with the ScrapFly client, enable the asp parameter, and select a proxy country:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some bestbuy.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']
FAQ
To wrap up this guide on web scraping BestBuy, let's have a look at some frequently asked questions.
Are there public APIs for BestBuy?
Yes, BestBuy offers APIs for developers. We have scraped review data from hidden BestBuy APIs. The same approach can be utilized to scrape other data sources on the website.
Are there alternatives for scraping BestBuy?
Yes, other popular e-commerce platforms include Amazon and Walmart. We have covered scraping Amazon and Walmart in previous tutorials. For more guides on similar scraping targets, refer to our #scrapeguide blog tag.
Summary
In this guide, we have explained how to scrape BestBuy. We went through a step-by-step guide on scraping BestBuy with Python for different pages on the website, which are:
- Sitemaps for BestBuy page URLs.
- Search pages for product data on search results.
- Product pages for various details, including specifications, pricing, and ratings.
- Review pages for user reviews on products.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.




