

In this web scraping tutorial, we'll take a look at how to scrape Algolia search using Python. We'll take a look at a real-life example of alternativeto.net - a web database of software metadata and recommendations. Through this example, we'll see how Algolia works and how we can write a generic web scraper to scrape data from any Algolia-powered website.
Key Takeaways
Master algolia scraper development with hidden API techniques, concurrent request handling, and cross-platform scraping strategies for comprehensive search data extraction.
- Extract API keys from frontend JavaScript code using regex patterns to identify 10-character application IDs and 32-character API keys
- Replicate Algolia search requests directly by analyzing network traffic and reconstructing POST requests with proper headers
- Implement concurrent scraping with asyncio to maximize efficiency when processing multiple search pages simultaneously
- Configure proper Content-Type headers and Algolia-specific authentication for successful API communication
- Apply generic scraping logic across different Algolia-powered websites using consistent API patterns and endpoints
- Use specialized tools like ScrapFly for automated algolia scraping with anti-blocking features
Project Setup
We'll be using a couple of Python packages for web scraping:
Both of which can be installed through pip console command:
$ pip install httpx parsel
What is Algolia?
Algolia offers a search indexing API service, so any website can implement a search system with very little back-end effort.It's excellent for web scraping as we can write a generic scraper that applies to any website using Algolia. In this tutorial, we'll do just that!
Creating Search Engine for any Website using Web Scraping
Guide for creating a search engine for any website using web scraping in Python. How to crawl data, index it and display it via js powered GUI.

Understanding and Scraping Algolia Search
To write our scraper, we need to understand how Algolia works. For this, let's start with our real-life example alternativeto.net.
If we go to this website and type something into the search box, we can see a backend request is being sent to Algolia's API:
The first thing we notice is the URL itself - it contains a few secret keys like the application name and the API token, as well as sends JSON document with our query details:
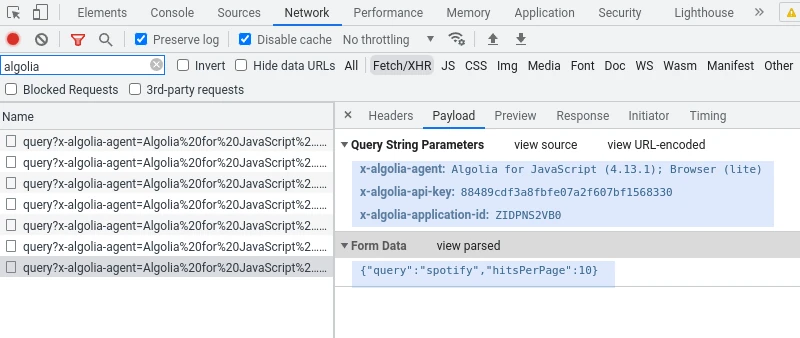
Now that we know this, we can replicate this behavior in Python rather easily:
from urllib.parse import urlencode
import httpx
params = {
"x-algolia-agent": "Algolia for JavaScript (4.13.1); Browser (lite)",
"x-algolia-api-key": "88489cdf3a8fbfe07a2f607bf1568330",
"x-algolia-application-id": "ZIDPNS2VB0",
}
search_url = "https://zidpns2vb0-dsn.algolia.net/1/indexes/fullitems/query?" + urlencode(params)
search_data = {
# for more see: https://www.algolia.com/doc/api-reference/search-api-parameters/
"query": "Spotify",
"page": 1,
"distinct": True,
"hitsPerPage": 20,
}
response = httpx.post(search_url, json=search_data)
print(response.json())
We got the first page of the results as well as pagination metadata which we can use to retrieve the remaining pages concurrently. For this, let's use asynchronous programming to download all of the pages concurrently at blazing fast speeds:
import asyncio
import json
from typing import List
from urllib.parse import urlencode
import httpx
params = {
"x-algolia-agent": "Algolia for JavaScript (4.13.1); Browser (lite)",
"x-algolia-api-key": "88489cdf3a8fbfe07a2f607bf1568330",
"x-algolia-application-id": "ZIDPNS2VB0",
}
search_url = "https://zidpns2vb0-dsn.algolia.net/1/indexes/fullitems/query?" + urlencode(params)
async def scrape_search(query: str) -> List[dict]:
search_data = {
# for more see: https://www.algolia.com/doc/api-reference/search-api-parameters/
"query": query,
"page": 1,
"distinct": True,
"hitsPerPage": 20,
}
async with httpx.AsyncClient(timeout=httpx.Timeout(30.0)) as session:
# scrape first page for total number of pages
response_first_page = await session.post(search_url, json=search_data)
data_first_page = response_first_page.json()
results = data_first_page["hits"]
total_pages = data_first_page["nbPages"]
# scrape remaining pages concurrently
other_pages = [
session.post(search_url, json={**search_data, "page": i})
for i in range(2, total_pages + 1)
]
for response_page in asyncio.as_completed(other_pages):
page_data = (await response_page).json()
results.extend(page_data["hits"])
return results
print(asyncio.run(scrape_search("spotify")))
This short scraper we wrote above will work with any Algolia-powered search system! To test this out, you can practice on some popular Algolia-powered websites:
Bonus: Finding Tokens
In our scraper, we simply hardcoded Algolia API and web app keys we found in our network inspector and while they are unlikely to change often, we might want to discover them programmatically if we're building a high uptime real-time web scraper.
Since Algolia is a front-end plugin, all of the required keys can be found somewhere in the HTML or javascript body. For example, the keys could be placed in hidden <input> nodes or in javascript resources as variables.
With a little bit of parsing magic and pattern matching, we can try to extract these keys:
import re
from urllib.parse import urljoin
import httpx
from parsel import Selector
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
}
def search_keyword_variables(html: str):
"""Look for Algolia keys in javascript keyword variables"""
variables = re.findall(r'(\w*algolia\w*?):"(.+?)"', html, re.I)
api_key = None
app_id = None
for key, value in variables:
key = key.lower()
if len(value) == 32 and re.search("search_api_key|search_key|searchkey", key):
api_key = value
if len(value) == 10 and re.search("application_id|appid|app_id", key):
app_id = value
if api_key and app_id:
print(f"found algolia details: {app_id=}, {api_key=}")
return app_id, api_key
def search_positional_variables(html: str):
"""Look for Algolia keys in javascript position variables"""
found = re.findall(r'"(\w{10}|\w{32})"\s*,\s*"(\w{10}|\w{32})"', html)
return sorted(found[0], reverse=True) if found else None
def find_algolia_keys(url):
"""Scrapes url and embedded javascript resources and scans for Algolia APP id and API key"""
response = httpx.get(url, headers=HEADERS)
sel = Selector(response.text)
# 1. Search in input fields:
app_id = sel.css("input[name*=search_api_key]::attr(value)").get()
search_key = sel.css("input[name*=search_app_id]::attr(value)").get()
if app_id and search_key:
print(f"found algolia details in hidden inputs {app_id=} {search_key=}")
return {
"x-algolia-application-id": app_id,
"x-algolia-api-key": search_key,
}
# 2. Search in website scripts:
scripts = sel.xpath("//script/@src").getall()
# prioritize scripts with keywords such as "app-" which are more likely to contain environment keys:
_script_priorities = ["app", "settings"]
scripts = sorted(scripts, key=lambda script: any(key in script for key in _script_priorities), reverse=True)
print(f"found {len(scripts)} script files that could contain algolia details")
for script in scripts:
print("looking for algolia details in script: {script}", script=script)
resp = httpx.get(urljoin(url, script), headers=HEADERS)
if found := search_keyword_variables(resp.text):
return {
"x-algolia-application-id": found[0],
"x-algolia-api-key": found[1],
}
if found := search_positional_variables(resp.text):
return {
"x-algolia-application-id": found[0],
"x-algolia-api-key": found[1],
}
print(f"could not find algolia keys in {len(scripts)} script details")
## input
find_algolia_keys("https://www.heroku.com/search")
## kw variables
find_algolia_keys("https://incidentdatabase.ai/apps/discover/")
find_algolia_keys("https://fontawesome.com/search")
## positional variables
find_algolia_keys("https://alternativeto.net/")
In the scraping algorithm above, we are scanning the main page for Algolia API keys which might be located in:
- Javascript keyword variables in script files used by the website.
- Positional javascript variables as we know that Algolia web ids are 10 characters long and API keys are 32 character long.
- Input forms that are hidden in the page HTML.
This algorithm should be a good start for finding Algolia keys without hands-on effort!
Avoiding Blocking with ScrapFly
While Algolia is easy to scrape, the websites that implement Algolia search often block web scrapers.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - scrape web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- JavaScript rendering - scrape dynamic web pages through cloud browsers.
- Full browser automation - control browsers to scroll, input and click on objects.
- Format conversion - scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
Let's take a look at what our alternativeto.net scraper would look like using Scrapfly SDK, which can be installed through pip console command:
$ pip install scrapfly-sdk
For our code, all we have to do is replace the httpx bits with ScrapFly-SDK:
import asyncio
import json
from typing import List
from urllib.parse import urlencode
from scrapfly import ScrapflyClient, ScrapeConfig
params = {
"x-algolia-agent": "Algolia for JavaScript (4.13.1); Browser (lite)",
"x-algolia-api-key": "88489cdf3a8fbfe07a2f607bf1568330",
"x-algolia-application-id": "ZIDPNS2VB0",
}
search_url = "https://zidpns2vb0-dsn.algolia.net/1/indexes/fullitems/query?" + urlencode(params)
async def scrape_search(query: str) -> List[dict]:
search_data = {
# for more see: https://www.algolia.com/doc/api-reference/search-api-parameters/
"query": query,
"page": 1,
"distinct": True,
"hitsPerPage": 20,
}
with ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=2) as client:
# scrape first page for total number of pages
first_page = client.scrape(
ScrapeConfig(
url=search_url,
method="POST",
data=search_data,
headers={"Content-Type": "application/json"},
# note we can enalb optional features like:
asp=True, # enable Anti Scraping Proteciton Bypass
country="US", # we can select any country for our IP address
)
)
data_first_page = json.loads(first_page.content)
results = data_first_page["hits"]
total_pages = data_first_page["nbPages"]
# scrape remaining pages concurrently
async for result in client.concurrent_scrape(
[
ScrapeConfig(
url=search_url,
data={**search_data, "page": i},
method="POST",
headers={"Content-Type": "application/json"}
# note we can enalb optional features like:
asp=True, # enable Anti Scraping Proteciton Bypass
country="US", # we can select any country for our IP address
)
for i in range(2, total_pages + 1)
]
):
data = json.loads(result.content)
results.extend(data["hits"])
return results
print(asyncio.run(scrape_search("spotify")))
By replacing httpx with scrapfly SDK we can scrape all of the pages without being blcoked or throttled.
FAQs
How do I find Algolia API keys and application IDs for scraping?
Use browser developer tools (F12) to inspect network requests when searching. Look for requests to algolia.net domains and check the request headers for x-algolia-api-key and x-algolia-application-id. These can also be found in page source code or JavaScript files.
What's the difference between scraping Algolia vs regular HTML parsing?
Algolia scraping uses direct API calls to get structured JSON data, which is faster and more reliable than HTML parsing. It bypasses HTML rendering and provides cleaner data, but requires finding the correct API endpoints and parameters.
How do I handle rate limiting when scraping Algolia-powered websites?
Implement request delays (1-2 seconds between requests), use rotating proxies, and respect the website's rate limits. Algolia itself has generous limits, but the implementing websites may have their own restrictions.
Can I scrape Algolia search results without knowing the API keys?
Yes, you can reverse engineer the keys by inspecting the website's JavaScript code, network requests, or HTML source. Look for patterns like 32-character API keys and 10-character application IDs in script tags or hidden form fields.
What are the most common Algolia scraping challenges?
Common challenges include: finding the correct API endpoints and parameters, handling authentication tokens, dealing with rate limiting, and adapting to changes in the website's Algolia implementation.
Is web scraping Algolia legal?
Yes. Algolia search index is publicly available, and we're not extracting anything personal or private. Scraping Algolia search at slow, respectful rates would fall under the ethical scraping definition. See our Is Web Scraping Legal? article for more.
What causes "Expecting value (near 1:1)" error?
This error is cause when our POST request's search body is incorrectly formatted (should be a valid json) or the Content-Type header is missing or incorrect when it should be set to application/json.
What causes "{"message":"indexName is not valid","status":400}" error?
Some websites use multiple indexes, and the queried one needs to be specified explicitly through the request body's "IndexName" keyword argument. Just like other details, we can see it in our devtools network inspector (F12 key). This value is unlikely to change, so we can code it into your web scraper.
Summary
In this brief tutorial, we've taken a look at scraping Algolia embedded search systems. We wrote a quick scraper for alternativeto.net that scraped all search results concurrently. We wrapped our tutorial up by taking a look at basic token scanning to find those Algolia API keys and how to avoid being blocked with ScrapFly SDK.




