

Extracting price data from websites is a popular web scraping use-case, especially in e-commerce businesses. However, there is one major issue - web scraping data becomes obsolete. But what about a scraper that keeps this data up-to-date?
In this article, we'll explain how to create a price scraper using Python. It will crawl over pages, extract product data and record historical price changes. Let's get started!
Key Takeaways
Build price tracker python applications using httpx, parsel, and pandas for automated price monitoring. Learn to scrape product data, track price changes, and implement scheduling for e-commerce price analysis and competitor monitoring.
- Use httpx.AsyncClient with asyncio for concurrent price data extraction from multiple product pages
- Implement pandas DataFrame operations for CSV storage and historical price comparison
- Configure desktop_notifier with DesktopNotifier.send() for automated price change alerts
- Use parsel Selector with XPath selectors for product data extraction from HTML elements
- Implement price change calculation with percentage formulas and timestamp tracking
- Use ScrapFly's concurrent_scrape() for automated price tracking with anti-blocking features
Why Track Prices?
Market dynamics and trends tend to move aggressively, leading prices to change accordingly. Therefore, tracking prices is a key factor towards keeping up with these changes, which allows for making better decisions.
Businesses can benefit from price monitoring by tracking their competitors' prices. Allowing for better pricing adjustments and strategies to stay competitive and retain customers.
Tracking prices also allows buyers and investors to make wise purchasing decisions and catch investment opportunities by detecting underpriced products.
For further details, refer to our previous article on web scraping user cases.
Project Steup
In this guide on scraping product prices, we'll use a few Python libraries:
httpxfor sending HTTP requests to the web pages and getting the HTML.parselfor parsing the HTML and extracting data using web selectors, such as Parsing HTML with Xpath and Parsing HTML with CSS Selectors.pandasto convert the data type between CSV and JSON formats.desktop_notifierfor creating a simple scraping alerting system.asynciofor increasing our web scraping speed by running our code asynchronously and scheduling our script.
Note that asyncio comes pre-installed in Python. So, you will only have to install the other packages using the following pip command:
$ pip install httpx parsel pandas desktop_notifierCreate a Price Tracker Tool
In a previous article, we created a similar price monitoring tool for monitoring e-commerce website trends by visualizing product insights.

In this one, we'll create a web scraping tool for price tracking and it will be divided into three parts:
- Product scraper, to scrape essential product data and save it to a CSV file.
- Price comparator, to compare the previous product prices and their changes.
- Scheduler, to create a simple cron job that schedules the previous steps.
First, let's start with the core part: price scraping!
Scraping Price Data
In this guide, we'll scrape price data from product pages on web-scraping.dev:
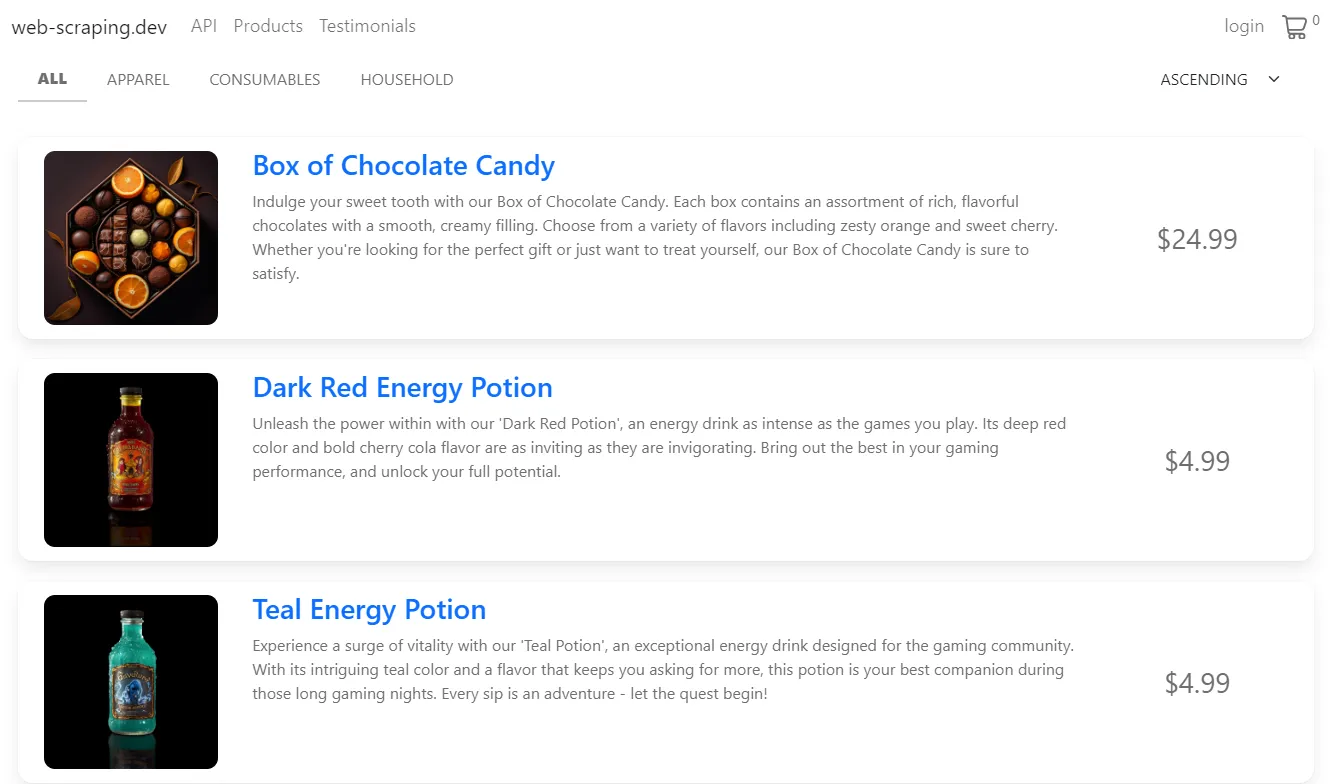
Although our scraping target is a mock website, the concept in this guide can be applied to any e-commerce app.
Let's begin with the parsing logic. We'll iterate over product cards and extract each product's details:
def parse_products(response: Response) -> List[Dict]:
"""parse products from HTML"""
selector = Selector(response.text)
data = []
for product in selector.xpath("//div[@class='row product']"):
name = product.xpath(".//div[contains(@class, description)]/h3/a/text()").get()
link = product.xpath(".//div[contains(@class, description)]/h3/a/@href").get()
product_id = link.split("/product/")[-1]
price = float(product.xpath(".//div[@class='price']/text()").get())
data.append({
"product_id": int(product_id),
"name": name,
"link": link,
"price": price,
"latest_change": strftime("%Y-%m-%d %H:%M", gmtime()),
"price_change": "N/A"
})
return datadef parse_products(response: ScrapeApiResponse) -> List[Dict]:
"""parse products from HTML"""
selector = response.selector
data = []
for product in selector.xpath("//div[@class='row product']"):
name = product.xpath(".//div[contains(@class, description)]/h3/a/text()").get()
link = product.xpath(".//div[contains(@class, description)]/h3/a/@href").get()
product_id = link.split("/product/")[-1]
price = float(product.xpath(".//div[@class='price']/text()").get())
data.append({
"product_id": int(product_id),
"name": name,
"link": link,
"price": price,
"latest_change": strftime("%Y-%m-%d %H:%M", gmtime()),
"price_change": "N/A"
})
return dataHere, we use the XPath selector to extract basic product details, such as the name, price, link and ID. We also add additional fields, latest_change() and price_change(). We'll update them later when we get new data.
Next, we'll utilize the parsing logic while sending requests to scrape the product page for these data:
import asyncio
import json
from httpx import AsyncClient, Response
from parsel import Selector
from typing import List, Dict
from time import gmtime, strftime
# initializing a async httpx client
client = AsyncClient(
headers = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
)
def parse_products(response: Response) -> List[Dict]:
"""parse products from HTML"""
# rest of the function code
async def scrape_products(url: str) -> List[Dict]:
"""scrape product pages"""
# scrape the first product page first
first_page = await client.get(url)
products_data = parse_products(first_page)
# add the remaining product pages to a scraping list
other_pages = [
client.get(url + f"?page={page_number}")
# the maximum available pages are 5
for page_number in range(2, 5 + 1)
]
for response in asyncio.as_completed(other_pages):
response = await response
data = parse_products(response)
# extend the first page data with new ones
products_data.extend(data)
print(f"scraped {len(products_data)} products")
return products_dataimport asyncio
import json
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
from typing import List, Dict
from time import gmtime, strftime
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
def parse_products(response: ScrapeApiResponse) -> List[Dict]:
"""parse products from HTML"""
# rest of the function code
async def scrape_products(url: str) -> List[Dict]:
"""scrape product pages"""
# scrape the first product page first
first_page = await scrapfly.async_scrape(ScrapeConfig(url, asp=True, country="US"))
products_data = parse_products(first_page)
# add the remaining product pages to a scraping list
other_pages = [
ScrapeConfig(url + f"?page={page_number}", asp=True, country="US")
# the maximum available pages are 5
for page_number in range(2, 5 + 1)
]
async for response in scrapfly.concurrent_scrape(other_pages):
data = parse_products(response)
# extend the first page data with new ones
products_data.extend(data)
print(f"scraped {len(products_data)} products")
return products_dataRun the code
async def track_prices():
data = await scrape_products(url="https://web-scraping.dev/products")
print(json.dumps(data, indent=2))
if __name__ == "__main__":
asyncio.run((track_prices()))In the above code, we initialize an asynchronous httpx client and define a scrape_products function. It scrapes the product pages by scraping the first page first and then the remaining page concurrently.
Here are the products we scraped:
Sample output
[
{
"product_id": 1,
"name": "Box of Chocolate Candy",
"link": "https://web-scraping.dev/product/1",
"price": 24.99,
"latest_change": "2023-12-29 13:13",
"price_change": "N/A"
},
{
"product_id": 2,
"name": "Dark Red Energy Potion",
"link": "https://web-scraping.dev/product/2",
"price": 4.99,
"latest_change": "2023-12-29 13:13",
"price_change": "N/A"
},
{
"product_id": 3,
"name": "Teal Energy Potion",
"link": "https://web-scraping.dev/product/3",
"price": 4.99,
"latest_change": "2023-12-29 13:13",
"price_change": "N/A"
},
{
"product_id": 4,
"name": "Red Energy Potion",
"link": "https://web-scraping.dev/product/4",
"price": 4.99,
"latest_change": "2023-12-29 13:13",
"price_change": "N/A"
},
{
"product_id": 5,
"name": "Blue Energy Potion",
"link": "https://web-scraping.dev/product/5",
"price": 4.99,
"latest_change": "2023-12-29 13:13",
"price_change": "N/A"
},
....
]Our script can successfully scrape product data. In the following section, we'll update it to track prices.
Tracking Price Data
To track price changes while scraping, we need to compare the old or existing data with the new ones. To do that, we'll save the results each time we run the script and then compare the new data with the existing file:
import pandas as pd
# same import statements
client = AsyncClient(
headers = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
)
def parse_products(response: Response) -> List[Dict]:
"""parse products from HTML"""
# function from previous section
async def scrape_products(url: str) -> List[Dict]:
"""scrape product pages"""
# function from previous section
def write_to_csv(data, filename):
"""save the data into csv"""
df = pd.DataFrame(data)
df.to_csv(f"./{filename}.csv", index=False)
def compare_data(new_data, filename):
"""compare old and new price data"""
# check if there is existing data and compare of them
try:
df = pd.read_csv(f"./{filename}.csv")
print("found existing data, comparing the new results with old ones")
except:
print("results doesn't exist, creating a CSV file for the first time")
return new_data
# convert the data in the CSV file
old_data = df.to_dict(orient='records')
for new_product in new_data:
for old_product in old_data:
# match two products from old and new data
if old_product["product_id"] == new_product["product_id"]:
# track the price change if the two prices aren't the same
if old_product["price"] != new_product["price"]:
# get the change percentage
change_percentage = round((new_product['price'] - old_product['price']) / old_product['price'] * 100)
change_case = "+" if new_product['price'] - old_product['price'] > 1 else ""
new_product["price_change"] = f"{change_case}{change_percentage}%"
# set the latest change to the previous one if the price hasn't changed
else:
new_product["latest_change"] = old_product["latest_change"]
return new_data
async def track_prices():
# scrape the data
data = await scrape_products(url="https://web-scraping.dev/products")
# compare the data and save the final results
data = compare_data(data, filename="prices")
write_to_csv(data, filename="prices")
if __name__ == "__main__":
asyncio.run((track_prices()))In the above code, we use the parse_products() and scrape_products() functions we defined earlier and define two additional functions. Let's break them down:
write_to_csv()for saving the data after comparing it to a CSV file.compare_data()for comparing the price data with the existing ones and tracking the change rate.
Since the product prices on our target website don't change, we'll use this fake data as previous scraping data to see the results in action:
# .....
async def track_prices():
# scrape the data
data = await scrape_products(url="https://web-scraping.dev/products")
# compare the data and save the final results
data = compare_data(data, filename="fake")
write_to_csv(data, filename="prices")Here is what the CSV file we got looks like:
From the above image, we can see that the products with updated prices include details about the latest change time and price percentage change. However, our price tracker can't track historical prices. Meaning that it can only save the latest change. So, let's update our scraper to save the product prices each time we execute the script:
# ...
def save_hsitorical(new_data):
try:
with open("./histocial.json", 'r') as file:
existing_data = json.load(file)
except FileNotFoundError:
# if the file doesn't exist yet, initialize with an empty list
existing_data = []
# extract timestamp from the first record
timestamp = new_data[0]["latest_change"]
new_data = [
{
"timestamp": timestamp,
"data": [
{
"product_id": item["product_id"],
"price": item["price"]
}
for item in new_data
]
}
]
existing_data.extend(new_data)
with open("./histocial.json", 'w') as file:
json.dump(existing_data, file, indent=2)
async def track_prices():
# scrape the data
data = await scrape_products(url="https://web-scraping.dev/products")
# compare the data and save the final results
save_hsitorical(data) # use the reccently created function
data = compare_data(data, filename="fake")
write_to_csv(data, filename="prices") 🙋♂️if you find this code snippet confusing, look for the final code in the full code section.
We define a save_historical() function to save all the historic product prices. It creates a JSON file if the script is executed for the first time and appends new data to the file each time we run the script. The historical price data should look like this:
Sample output
[
{
"timestamp": "2023-12-29 09:01",
"data": [
{
"product_id": 1,
"price": 24.99
},
{
"product_id": 2,
"price": 4.99
},
....
]
},
{
"timestamp": "2023-12-29 09:06",
"data": [
{
"product_id": 1,
"price": 24.99
},
{
"product_id": 2,
"price": 4.99
},
....
]
},
{
"timestamp": "2023-12-29 09:11",
"data": [
{
"product_id": 1,
"price": 24.99
},
{
"product_id": 2,
"price": 4.99
},
....
]
]Our price tracker can scrape price data, monitor and track their historical changes. The last step is scheduling this script to execute it every certain amount of time.
Web Scraping Scheduling
In this section, we'll create a simple notification alert using desktop_notifier to notify us of the results whenever they are ready. We'll also use asyncio to run this function as a cron job:
# ...
notifier = DesktopNotifier()
# send a desktop notification
async def send_notification():
await notifier.send(
title="Price tracking tool",
message="Your web scraping results are ready!",
buttons=[
Button(
title="Mark as read",
),
],
)
async def track_prices():
print("======= price tracker has started =======")
data = await scrape_products(url="https://web-scraping.dev/products")
save_hsitorical(data)
data = compare_data(data, filename="prices")
write_to_csv(data, filename="prices")
await send_notification()
print("======= price tracker has finished =======")
async def main():
while True:
# Run the script every 3 hours
await track_prices()
await asyncio.sleep(5 * 60 * 60)
if __name__ == "__main__":
asyncio.run(main()) Here, we define a send_notification function to send alerts whenever the scraping results are ready. Then, we use all the previously defined functions in the track_prices function and run it every 3 hours using asyncio.
Full Price Tracker Code
Here is what the full price tracking code should look like:
import asyncio
import json
import pandas as pd
from httpx import AsyncClient, Response
from desktop_notifier import DesktopNotifier, Button
from parsel import Selector
from typing import List, Dict
from time import gmtime, strftime
# initialize an async httpx client
client = AsyncClient(
headers = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
)
def parse_products(response: Response) -> List[Dict]:
"""parse products from HTML"""
selector = Selector(response.text)
data = []
for product in selector.xpath("//div[@class='row product']"):
name = product.xpath(".//div[contains(@class, description)]/h3/a/text()").get()
link = product.xpath(".//div[contains(@class, description)]/h3/a/@href").get()
product_id = link.split("/product/")[-1]
price = float(product.xpath(".//div[@class='price']/text()").get())
data.append({
"product_id": int(product_id),
"name": name,
"link": link,
"price": price,
"latest_change": strftime("%Y-%m-%d %H:%M", gmtime()),
"price_change": "N/A"
})
return data
async def scrape_products(url: str) -> List[Dict]:
"""scrape product page"""
# scrape the first prouct page first
response = await client.get(url)
products_data = parse_products(response)
# add the remaining product pages to a scraping list
other_pages = [
client.get(url + f"?page={page_number}")
# the maximum available pages are 5
for page_number in range(2, 5 + 1)
]
for response in asyncio.as_completed(other_pages):
response = await response
data = parse_products(response)
# extend the first page data with new ones
products_data.extend(data)
print(f"scraped {len(products_data)} products")
return products_data
def write_to_csv(data, filename):
"""save the data into csv"""
df = pd.DataFrame(data)
df.to_csv(f"./{filename}.csv", index=False)
def compare_data(new_data, filename):
try:
df = pd.read_csv(f"./{filename}.csv")
except:
print("OOps")
return new_data
old_data = df.to_dict(orient='records')
for new_product in new_data:
for old_product in old_data:
if old_product["product_id"] == new_product["product_id"]:
if old_product["price"] != new_product["price"]:
change_percentage = round((new_product['price'] - old_product['price']) / old_product['price'] * 100)
change_case = "+" if new_product['price'] - old_product['price'] > 1 else ""
new_product["price_change"] = f"{change_case}{change_percentage}%"
else:
new_product["latest_change"] = old_product["latest_change"]
return new_data
def save_hsitorical(new_data):
try:
with open("./histocial.json", 'r') as file:
existing_data = json.load(file)
except FileNotFoundError:
# if the file doesn't exist yet, initialize with an empty list
existing_data = []
# extract timestamp from the first record
timestamp = new_data[0]["latest_change"]
new_data = [
{
"timestamp": timestamp,
"data": [
{
"product_id": item["product_id"],
"price": item["price"]
}
for item in new_data
]
}
]
existing_data.extend(new_data)
with open("./histocial.json", 'w') as file:
json.dump(existing_data, file, indent=2)
notifier = DesktopNotifier()
# send a desktop notification
async def send_notification():
await notifier.send(
title="Price tracking tool",
message="Your web scraping results are ready!",
buttons=[
Button(
title="Mark as read",
),
],
)
async def track_prices():
print("======= price tracker has started =======")
data = await scrape_products(url="https://web-scraping.dev/products")
save_hsitorical(data)
data = compare_data(data, filename="prices")
write_to_csv(data, filename="prices")
await send_notification()
print("======= price tracker has finished =======")
async def main():
while True:
# Run the script every 3 hours
await track_prices()
await asyncio.sleep(3 * 60 * 60)
if __name__ == "__main__":
asyncio.run(main())import asyncio
import json
import pandas as pd
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
from desktop_notifier import DesktopNotifier, Button
from typing import List, Dict
from time import gmtime, strftime
# initialize an async httpx client
client = AsyncClient(
headers = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
)
def parse_products(response: ScrapeApiResponse) -> List[Dict]:
"""parse products from HTML"""
selector = response.selector
data = []
for product in selector.xpath("//div[@class='row product']"):
name = product.xpath(".//div[contains(@class, description)]/h3/a/text()").get()
link = product.xpath(".//div[contains(@class, description)]/h3/a/@href").get()
product_id = link.split("/product/")[-1]
price = float(product.xpath(".//div[@class='price']/text()").get())
data.append({
"product_id": int(product_id),
"name": name,
"link": link,
"price": price,
"latest_change": strftime("%Y-%m-%d %H:%M", gmtime()),
"price_change": "N/A"
})
return data
async def scrape_products(url: str) -> List[Dict]:
"""scrape product page"""
# scrape the first product page first
first_page = await scrapfly.async_scrape(ScrapeConfig(url, asp=True, country="US"))
products_data = parse_products(first_page)
# add the remaining product pages to a scraping list
other_pages = [
ScrapeConfig(url + f"?page={page_number}", asp=True, country="US")
# the maximum available pages are 5
for page_number in range(2, 5 + 1)
]
async for response in scrapfly.concurrent_scrape(other_pages):
data = parse_products(response)
# extend the first page data with new ones
products_data.extend(data)
print(f"scraped {len(products_data)} products")
return products_data
def write_to_csv(data, filename):
"""save the data into csv"""
df = pd.DataFrame(data)
df.to_csv(f"./{filename}.csv", index=False)
def compare_data(new_data, filename):
try:
df = pd.read_csv(f"./{filename}.csv")
except:
print("OOps")
return new_data
old_data = df.to_dict(orient='records')
for new_product in new_data:
for old_product in old_data:
if old_product["product_id"] == new_product["product_id"]:
if old_product["price"] != new_product["price"]:
change_percentage = round((new_product['price'] - old_product['price']) / old_product['price'] * 100)
change_case = "+" if new_product['price'] - old_product['price'] > 1 else ""
new_product["price_change"] = f"{change_case}{change_percentage}%"
else:
new_product["latest_change"] = old_product["latest_change"]
return new_data
def save_hsitorical(new_data):
try:
with open("./histocial.json", 'r') as file:
existing_data = json.load(file)
except FileNotFoundError:
# if the file doesn't exist yet, initialize with an empty list
existing_data = []
# extract timestamp from the first record
timestamp = new_data[0]["latest_change"]
new_data = [
{
"timestamp": timestamp,
"data": [
{
"product_id": item["product_id"],
"price": item["price"]
}
for item in new_data
]
}
]
existing_data.extend(new_data)
with open("./histocial.json", 'w') as file:
json.dump(existing_data, file, indent=2)
notifier = DesktopNotifier()
# send a desktop notification
async def send_notification():
await notifier.send(
title="Price tracking tool",
message="Your web scraping results are ready!",
buttons=[
Button(
title="Mark as read",
),
],
)
async def track_prices():
print("======= price tracker has started =======")
data = await scrape_products(url="https://web-scraping.dev/products")
save_hsitorical(data)
data = compare_data(data, filename="prices")
write_to_csv(data, filename="prices")
await send_notification()
print("======= price tracker has finished =======")
async def main():
while True:
# Run the script every 3 hours
await track_prices()
await asyncio.sleep(1)
if __name__ == "__main__":
asyncio.run(main())Powering up with ScrapFly
Our price scraper can run smoothly without issues on our target website. However, we'll likely get blocked when scraping a real e-commerce app.

Using ScrapFly for scraping price data at scale is straightforward. All we have to do is replace our HTTP client with the ScrapFly client:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some website URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML contentFAQ
Is it possible to track prices on e-commerce apps?
Yes, by applying the concepts described in this article, we can use the same method to track prices on real websites. For detailed scrape guides on popular e-commerce websites, see our guides on scraping How to Scrape Amazon.com Product Data and Reviews, How to Scrape Walmart.com Product Data (2026 Update), How to Scrape Aliexpress.com (2026 Update), How to Scrape Etsy.com Product, Shop and Search Data, and How to Scrape BestBuy Product, Offer and Review Data. For travel and accommodation pricing, see our guide on scraping Booking.com.
Can I track product prices in a different currency and language?
Yes, you can change the web scraping localization to another language or currency by using different approaches, such as changing headers or proxy locations.
Summary
In this article, we went through a step-by-step on how to create a price tracker using Python. We started by scraping product prices from HTML pages using httpx and XPath selectors. Then, we compared the new product prices with the old data. Finally, we scheduled the price scraper to run it every certain amount of time.


