

Imagine having a huge repository of scholarly articles, theses, books, and conference papers at your fingertips all accessible through a single, user-friendly platform. Whether you're a researcher, student, or academic enthusiast, Google Scholar is an indispensable tool that streamlines your quest for knowledge.
In this article, we'll explore how Google Scholar works, why there's no official API, and how to extract data using web scraping techniques.
Key Takeaways
Build google scholar api alternatives using Scholarly library, undetected-chromedriver, and web scraping techniques. Learn to extract academic data, handle CAPTCHAs, and implement citation analysis for research automation without official API access.
- Use Scholarly library with scholarly.search_pubs() method to extract academic data from Google Scholar
- Implement undetected-chromedriver with Chrome options to bypass anti-bot detection and handle CAPTCHAs
- Configure XPath selectors for h3.gs_rt elements to extract paper titles and academic metadata
- Handle Google Scholar's blocking mechanisms with proxy rotation and fingerprint management
- Use ScrapFly's extraction_model for automated academic data collection with anti-blocking features
- Parse academic metadata including titles, authors, citations, and publication sources from search results
What is Google Scholar?
Google Scholar is a freely accessible web search engine that indexes the full text or metadata of scholarly literature across various formats and disciplines.
Launched by Google, it serves as a comprehensive gateway to academic resources, allowing users to search for digital or physical copies of articles available online or in libraries.
Let's try a search for "optimizing rag" on Google Scholar and see what is displayed.
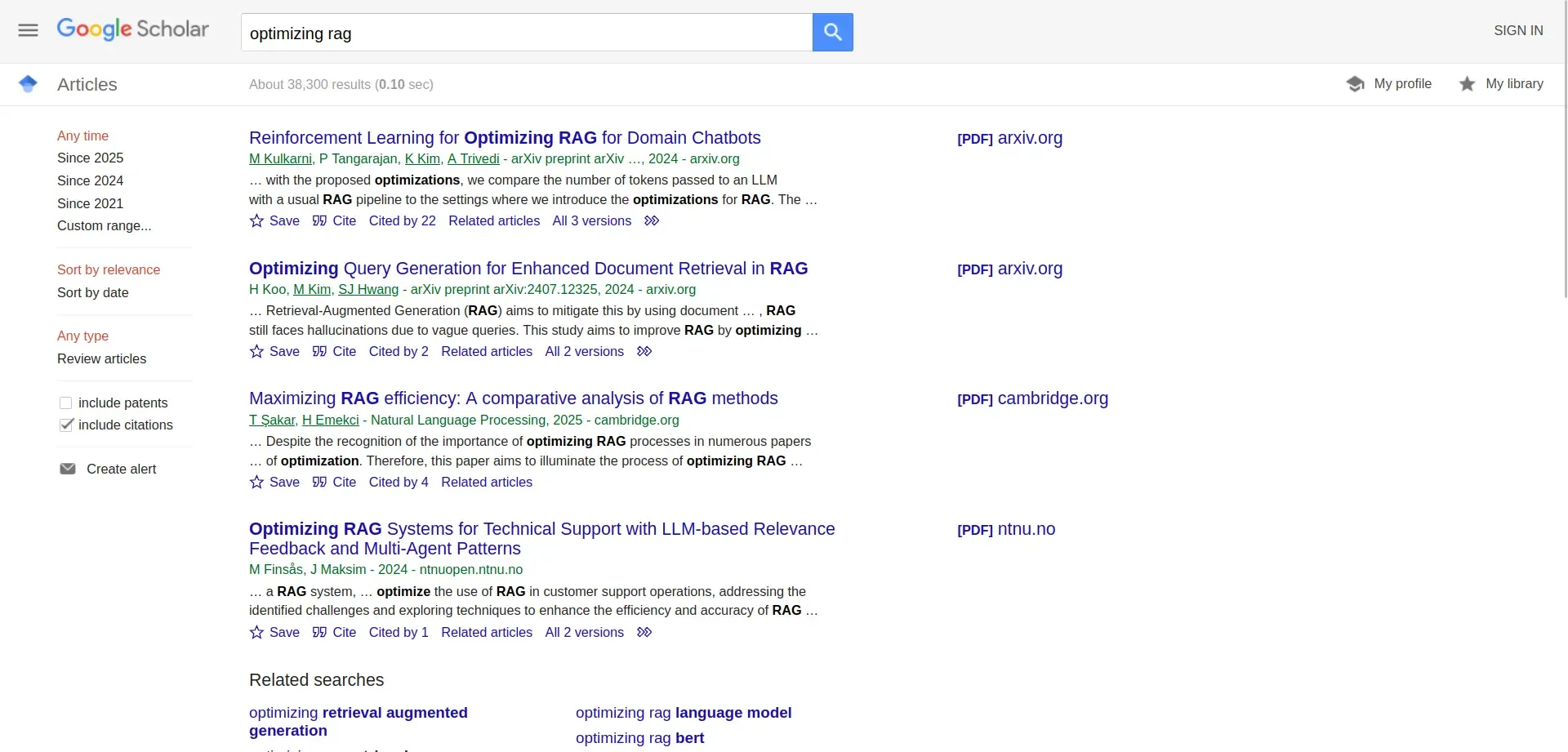
A search for "optimizing rag" on Google Scholar yields numerous results, each providing essential information such as the title, authors, publication source, and a snippet of the abstract. For those interested in data extraction, various elements can be scraped from these search results, including:
- Title of the paper: The main heading of the scholarly work.
- Authors: Names of the individuals who contributed to the research.
- Publication source: The journal, conference, or platform where the work was published.
- Publication year: The year the work was made publicly available.
- Abstract snippet: A brief overview or summary of the research.
- Citations count: The number of times the work has been cited by other scholarly articles.
- Related articles link: References to similar or related research works.
- Versions link: Different versions or editions of the paper available online.
Since Google Scholar provides such a huge amount of academic data, you might wonder why there isn’t an official API to access it directly. Let’s explore the reasons behind this limitation.
Why is There No Official Google Scholar API?
One reason there isn't an official Google Scholar API is the complexities with data licensing and varying terms. The service relies on contributions from diverse sources (such as university repositories and academic publishers) which all have different rules about how their content can be used, making it challenging to create a reliable and respectful API that complies with everyone's requirements.
Despite the lack of an official API, there are alternative ways to extract data from Google Scholar one of the most effective being web scraping. Let’s explore how this works.
Web Scraping Google Scholar
While there isn't a traditional API for accessing Google Scholar data, web scraping can be an effective way to extract the information you need. Several tools and libraries can help with this process:
Scholary
Scholary is a Python package that provides a simple and easy-to-use interface for scraping Google Scholar data. It's an excellent option if you're already familiar with Python.
from scholarly import scholarly
# Search for papers on the topic "optimizing rag"
query = 'optimizing rag'
# Perform the search
search_results = scholarly.search_pubs(query)
scholarly.pprint(next(search_results))Example Output
{
"container_type": "Publication",
"source": "PUBLICATION_SEARCH_SNIPPET",
"bib": {
"title": "Reinforcement Learning for Optimizing RAG for Domain Chatbots",
"author": [
"M Kulkarni",
"P Tangarajan",
"K Kim",
"A Trivedi"
],
"pub_year": "2024",
"venue": "arXiv preprint arXiv …",
"abstract": "with the proposed optimizations, we compare the number of tokens passed to an LLM with a usual RAG pipeline to the settings where we introduce the optimizations for RAG. The"
},
"filled": false,
"gsrank": 1,
"pub_url": "https://arxiv.org/abs/2401.06800",
"author_id": [
"rFG8dYIAAAAJ",
"",
"2X9BwYoAAAAJ",
"hr3rNbcAAAAJ"
],
"url_scholarbib": "/scholar?hl=en&q=info:TolcQhKMH7QJ:scholar.google.com/&output=cite&scirp=0&hl=en",
"url_add_sclib": "/citations?hl=en&xsrf=&continue=/scholar%3Fq%3Doptimizing%2Brag%26hl%3Den%26as_sdt%3D0,33&citilm=1&update_op=library_add&info=TolcQhKMH7QJ&ei=AvW2Z_S0BdaIieoPz8qJuAc&json=",
"num_citations": 22,
"citedby_url": "/scholar?cites=12979246661155719502&as_sdt=5,33&sciodt=0,33&hl=en",
"url_related_articles": "/scholar?q=related:TolcQhKMH7QJ:scholar.google.com/&scioq=optimizing+rag&hl=en&as_sdt=0,33",
"eprint_url": "https://arxiv.org/pdf/2401.06800"
}
This script initiates a search for publications matching the query "optimizing rag" and prints the details of the first result. The output includes information such as the title, authors, publication source, and a snippet of the abstract.
While Scholarly is convenient, it has limitations: Google Scholar blocks automated requests after just a few queries, making it impractical for large-scale data collection without additional measures.
Now let's explore a more robust alternative using Undetected Chromedriver, which helps bypass Google's anti-bot measures.
Undetected Chromedriver
Undetected Chromedriver is an advanced tool built on top of Web Scraping with Selenium and Python, designed to bypass anti-bot mechanisms and improve browser automation. It is particularly useful for scraping complex web pages, handling CAPTCHAs, and avoiding detection.
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# Initialize the undetected Chrome browser
options = uc.ChromeOptions()
options.headless = True # Run in headless mode
browser = uc.Chrome(options=options)
with browser:
browser.get('https://scholar.google.com/')
# Locate the search input field
search_box = browser.find_element(By.NAME, 'q')
# Enter the search query
search_query = 'optimizing rag'
search_box.send_keys(search_query)
search_box.send_keys(Keys.RETURN)
# Allow time for search results to load
time.sleep(2)
# Retrieve and print the titles of the search results
titles = browser.find_elements(By.CSS_SELECTOR, 'h3.gs_rt')
for index, title in enumerate(titles, start=1):
print(f"{index}. {title.text}")
browser.quit()Example Output
1. Reinforcement Learning for Optimizing RAG for Domain Chatbots
2. Optimizing Query Generation for Enhanced Document Retrieval in RAG
3. Maximizing RAG efficiency: A comparative analysis of RAG methods
4. Optimizing RAG Systems for Technical Support with LLM-based Relevance Feedback and Multi-Agent Patterns
5. Advanced RAG Models with Graph Structures: Optimizing Complex Knowledge Reasoning and Text Generation
6. Stochastic rag: End-to-end retrieval-augmented generation through expected utility maximization
7. Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
8. PA-RAG: RAG Alignment via Multi-Perspective Preference Optimization
9. Optimizing RAG Techniques for Automotive Industry PDF Chatbots: A Case Study with Locally Deployed Ollama Models
10. Towards understanding retrieval accuracy and prompt quality in rag systems
The code above uses the undetected_chromedriver library to initialize an undetected Chrome browser in headless mode. The browser navigates to Google Scholar and searches for papers on the topic "optimizing rag". The search results are then retrieved and printed to the console.
For more details about Undetected Chromedriver, refer to our dedicated article:

Seemless Scraping with Scrapfly
ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass: scrape web pages without blocking!
- Rotating residential proxies: prevent IP address and geographic blocks.
- JavaScript rendering: scrape dynamic web pages through cloud browsers.
- Full browser automation: control browsers to scroll, input, and click on objects.
- Format conversion: scrape as HTML, JSON, Text, or Markdown.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.

Here's an example of how to scrape Google Scholar with the Scrapfly web scraping API and extract results using AI and LLM models:
import os
from scrapfly import ScrapflyClient, ScrapeConfig, ScrapeApiResponse
scrapfly = ScrapflyClient(key=os.getenv("SCRAPFLY_KEY"))
result: ScrapeApiResponse = scrapfly.scrape(ScrapeConfig(
url="https://scholar.google.com/scholar?q=optimizing+rag",
# select what to extract, see https://scrapfly.io/docs/extraction-api/automatic-ai#models
extraction_model="search_engine_results",
# enable automatic blocking bypass
asp=True,
# enable cloud web browsers
render_js=True,
))
print(result.scrape_result['extracted_data']['data'])Example Output
{
"ads": null,
"associatedSearches": null,
"geolocationWidget": null,
"informationWidget": null,
"nextPage": {
"nextUrl": "https://scholar.google.com/scholar?start=10&q=optimizing+rag&hl=da&as_sdt=0,5"
},
"pages": [
{
"pageNumber": 2,
"pageUrl": "https://scholar.google.com/scholar?start=10&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 3,
"pageUrl": "https://scholar.google.com/scholar?start=20&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 4,
"pageUrl": "https://scholar.google.com/scholar?start=30&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 5,
"pageUrl": "https://scholar.google.com/scholar?start=40&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 6,
"pageUrl": "https://scholar.google.com/scholar?start=50&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 7,
"pageUrl": "https://scholar.google.com/scholar?start=60&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 8,
"pageUrl": "https://scholar.google.com/scholar?start=70&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 9,
"pageUrl": "https://scholar.google.com/scholar?start=80&q=optimizing+rag&hl=da&as_sdt=0,5"
},
{
"pageNumber": 10,
"pageUrl": "https://scholar.google.com/scholar?start=90&q=optimizing+rag&hl=da&as_sdt=0,5"
}
],
"query": "optimizing rag",
"results": [
{
"displayUrl": "arxiv.org",
"publishDate": "2024-01-01 00:00:00",
"richSnippet": null,
"snippet": "… with the proposed optimizations , we compare the number of tokens passed to an LLM with a usual RAG pipeline to the settings where we introduce the optimizations for RAG . The …",
"title": "Reinforcement learning for optimizing rag for domain chatbots",
"url": "https://arxiv.org/pdf/2401.06800"
},
{
"displayUrl": "arxiv.org",
"publishDate": "2024-07-12 00:00:00",
"richSnippet": null,
"snippet": "… Retrieval-Augmented Generation ( RAG ) aims to mitigate this by using document … , RAG still faces hallucinations due to vague queries. This study aims to improve RAG by optimizing …",
"title": "Optimizing Query Generation for Enhanced Document Retrieval in RAG",
"url": "https://arxiv.org/pdf/2407.12325"
},
{
"displayUrl": "cambridge.org",
"publishDate": "2025-01-01 00:00:00",
"richSnippet": null,
"snippet": "… Despite the recognition of the importance of optimizingRAG processes in numerous papers … of optimization . Therefore, this paper aims to illuminate the process of optimizingRAG …",
"title": "Maximizing RAG efficiency: A comparative analysis of RAG methods",
"url": "https://www.cambridge.org/core/services/aop-cambridge-core/content/view/D7B259BCD35586E04358DF06006E0A85/S2977042424000530a.pdf/div-class-title-maximizing-rag-efficiency-a-comparative-analysis-of-rag-methods-div.pdf"
},
{
"displayUrl": "ntnuopen.ntnu.no",
"publishDate": "2024-01-01 00:00:00",
"richSnippet": null,
"snippet": "… a RAG system, … optimize the use of RAG in customer support operations, addressing the identified challenges and exploring techniques to enhance the efficiency and accuracy of RAG …",
"title": "Optimizing RAG Systems for Technical Support with LLM-based Relevance Feedback and Multi-Agent Patterns",
"url": "https://ntnuopen.ntnu.no/ntnu-xmlui/bitstream/handle/11250/3160478/no.ntnu%3Ainspera%3A187264004%3A47043521.pdf?sequence=1"
},
{
"displayUrl": "ieeexplore.ieee.org",
"publishDate": "2024-01-01 00:00:00",
"richSnippet": null,
"snippet": "… The retrieval-augmented generation model ( RAG ) based on graph structure optimization proposed in this study introduces graph neural network (GNN) to process structured graph data…",
"title": "Advanced RAG Models with Graph Structures: Optimizing Complex Knowledge Reasoning and Text Generation",
"url": "https://arxiv.org/pdf/2411.03572"
},
{
"displayUrl": "dl.acm.org",
"publishDate": "2024-01-01 00:00:00",
"richSnippet": null,
"snippet": "… for RAG –a novel framework for end-to-end RAGoptimization by … A major challenge in end-to-end optimization of RAG … descent-based methods for optimization . We address this issue …",
"title": "Stochastic rag : End-to-end retrieval-augmented generation through expected utility maximization",
"url": "https://dl.acm.org/doi/pdf/10.1145/3626772.3657923"
},
{
"displayUrl": "arxiv.org",
"publishDate": "2024-10-21 00:00:00",
"richSnippet": null,
"snippet": "… RAG be optimized for … RAG systems using a set of 100 domain-specific questions. Additionally, we explore various retrieval methods to optimize the performance of the multimodal RAG …",
"title": "Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications",
"url": "https://arxiv.org/pdf/2410.21943"
},
{
"displayUrl": "arxiv.org",
"publishDate": "2024-01-01 00:00:00",
"richSnippet": null,
"snippet": "… In this work, we propose PA- RAG , a method for optimizing the generator of RAG systems to align with specific RAG requirements comprehensively. The training process includes …",
"title": "PA- RAG : RAG Alignment via Multi-Perspective Preference Optimization",
"url": "https://arxiv.org/pdf/2412.14510"
},
{
"displayUrl": "arxiv.org",
"publishDate": "2024-01-01 00:00:00",
"richSnippet": null,
"snippet": "… day a new technique to improve RAG appears, making it … to implement, optimize , and evaluate RAG for the Brazilian … Finally, we present the complete architecture of the RAG with …",
"title": "The chronicles of rag : The retriever, the chunk and the generator",
"url": "https://arxiv.org/pdf/2401.07883"
},
{
"displayUrl": "arxiv.org",
"publishDate": "2024-08-05 00:00:00",
"richSnippet": null,
"snippet": "… We compared our optimizedRAG model and self- RAG agent against a naive RAG baseline across three … Our optimization scheme provides an effective solution for deploying local …",
"title": "Optimizing RAG Techniques for Automotive Industry PDF Chatbots: A Case Study with Locally Deployed Ollama Models",
"url": "https://arxiv.org/pdf/2408.05933"
}
],
"socialAccounts": null,
"totalResults": 35900
}Or freeform extract anything using your own LLM prompts:
import os
from scrapfly import ScrapflyClient, ScrapeConfig, ScrapeApiResponse
scrapfly = ScrapflyClient(key=os.getenv("SCRAPFLY_KEY"))
result: ScrapeApiResponse = scrapfly.scrape(ScrapeConfig(
url="https://arxiv.org/abs/2401.06800",
# use any LLM prompt:
extraction_prompt="Explain thhe abstract of this paper like I'm 10",
# enable automatic blocking bypass
asp=True,
# enable cloud web browsers
render_js=True,
))
print(result.scrape_result['extracted_data']['data'])
{
"content_type": "text/plain",
"data": "Okay, imagine you have a super smart robot that can answer questions \
about a specific topic, like a video game or a type of animal. \
This paper is about making that robot even better!\n\nSometimes, \
these robots use a special trick called RAG. RAG is like giving the \
robot a cheat sheet with facts and information, so it can answer \
questions more accurately.\n\nThe people who wrote this paper found \
a way to make the robot save energy, like when you turn off the lights to save electricity.\
They taught the robot to decide when it really needs to look at the cheat sheet and \
when it already knows the answer.\n\nThey used something called \"Reinforcement Learning,\" \
which is like training a dog with treats. If the robot makes a good decision, \
it gets a reward! This helps the robot learn to be more efficient and save energy, \
while still answering questions correctly."
}Alternatives to Google Scholar
Google scholar is not the only indexing service for scholarly literature. Here are some alternatives:
- Scopus: subscription-based curated database of peer-reviewed literature. Often offers higher quality, structured data with more accurate citations.
- BASE (Bielefeld Academic Search Engine): search engine for academic open access web resources. Offers a large index of open access papers.
- Lens.org: open access platform for scholarly literature, patents, and other research outputs.
- JSTOR: digital library for curated academic journals, books, and primary sources. Requires a subscription.
As well a some indirect alternatives for scholarly research:
- Scispace - AI powered research assistant with a large index of scientific papers as well. Limited free access.
- Semantic Scholar: AI-powered search engine for academic literature. Offers structured data and citation information.
- ResearchGate: social networking site for researchers to share papers, ask questions, and find collaborators.
All of these can be automated using Scrapfly's web scraping API!
FAQ
Can I use Google Scholar for free?
Yes, Google Scholar is free to use. However, some articles may be behind paywalls, requiring access through a university, library, or paid subscription.
Can I scrape full articles on Google Scholar?
Yes, if the article is publicly available, scraping and collecting it is legal in most countries. However, since Google Scholar indexes many different sources, it's important to verify the terms of each one. For more details, see our page on web scraping legality.
Can I set up alerts for new research on Google Scholar?
Yes! Google Scholar allows you to create alerts for specific keywords so you can be notified when new research papers are published in your area of interest. You can set up alerts by visiting scholar alerts and adding the keywords you want to track.
Summary
Google Scholar is an invaluable resource for accessing a vast array of scholarly literature and due to copyright complexities doesn't offer an official API.
However, it can still be automated using Scholarly or web scraping with relative ease allowing for search for papers, authors, and more. We've taken a look at some Python examples as well as some alternatives to Google Scholar for academic research.


