Data on a web page can be found in different forms, including HTML and JavaScript. When data is located in JavaScript, it’s often found in script tags or JavaScript variables. This form of data is commonly known as hidden web data.
To scrape hidden data we have two choices:
- Use a headless browser to render it to the HTML essentially unhiding it.
- Find it directly using text parsing techniques.
In this article, we'll be taking a look at the second option and how we can use ChatGPT to scrape hidden data. We'll start with a quick overview of this technique and explore some real-life examples. Let's dive in!
Key Takeaways
Master ChatGPT hidden data extraction with advanced prompt engineering, JSON parsing, and text analysis techniques for comprehensive web scraping workflows.
- Use ChatGPT for intelligent hidden data extraction from JavaScript variables and script tags without browser automation
- Implement advanced prompt engineering to guide ChatGPT in identifying and parsing complex data structures
- Apply JSON parsing and data validation techniques for reliable extraction of structured hidden content
- Configure text analysis and pattern recognition for extracting data from various JavaScript formats
- Use specialized tools like ScrapFly for automated hidden data extraction with anti-blocking features
- Implement proper error handling and data validation for reliable ChatGPT-based parsing workflows
What is Hidden Web Data?
Dynamic web pages use JavaScript functions to manage the state of the HTML. These functions isolate the actual HTML from the data logic. This means that a website may have an empty HTML structure and data gets rendered into the HTML on page load by Javascript.
As the usual web scraping tools like BeautifulSoup don't support JavaScript, this data doesn’t appear in the HTML and is therefore hidden from HTML parsing.
For example, on this this mock product page we can see this review data in our browser:
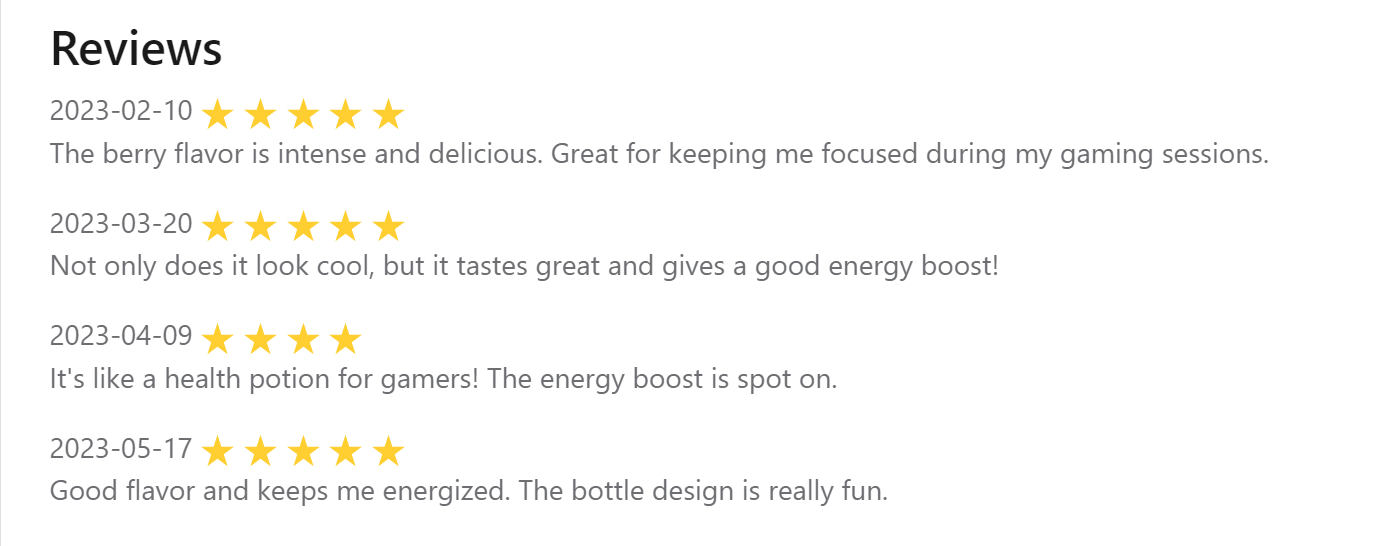
Furhter, if we inspect the page in our browser, we can see that this data is present in the HTML:
<div id="reviews" data-page="1">
<div class="review review-red-potion-1">
<span>2023-02-10</span>
<p>The berry flavor is intense and delicious. Great for keeping me focused during my gaming sessions.</p>
</div>
<div class="review review-red-potion-2">
<span>2023-03-20</span>
<p>Not only does it look cool, but it tastes great and gives a good energy boost!</p>
</div>
<div class="review review-red-potion-3">..</div>
<div class="review review-red-potion-4">..</div>
</div>
However, if we run a simple BeautifulSoup scraper code we can see that
there's no review data in the HTML:
from bs4 import BeautifulSoup
import requests
r = requests.get('https://web-scraping.dev/product/4?variant=one')
soup = BeautifulSoup(r.content, 'html.parser')
print (soup)
"""
<h3 class="box-title mt-5">Reviews</h3>
<div data-page="1" id="reviews">
</div>
</div>
</div>
</div>
</div>
</div>
<input name="csrf-token" type="hidden" value="secret-csrf-token-123"/>
<script id="reviews-data" type="application/json">[{"date": "2023-02-10", "id": "red-potion-1", "rating": 5, "text": "The berry flavor is intense and delicious. Great for keeping me focused during my gaming sessions."}..]</script>
<script id="reviews-template" type="nunjucks">
"""
The div tags that store the data are empty now and the data seems to be hidden.
If we take a closer look we can see that this hidden data is now in JSON format found in the <script id="reviews-data"> tag.
This data should have been rendered into the HTML. But since we used a web scraper that doesn’t support JavaScript, this couldn’t happen.
So to summarize, we can see that HTML web scrapers can’t scrape hidden web data directly. Let’s figure out how we can do it!
How to scrape hidden web data?
We have a few solutions that can scrape hidden web data:
We can use Headless browsers like Selenium, Playwright and Puppeteer.
These headless browsers enable you to mimic and control a real web browser. Which we can use to
render hidden data to HTML DOM and then parse it as usual with BeautifulSoup.
However, this approach allows rendering hidden data to HTML, but this comes at a cost. Headless browsers consume a lot of time and resources, as we have to run a whole web browser and wait for things to load.
Alternatively, we can find the data directly in the web page using Regex and JSON finding algorithms.
This approach allows browserless scrapers to scrape hidden data though we need to provide clear instructions where to find it. This is where ChatGPT comes in.
We can use ChatGPT to program that hidden data lookup for us. This works by passing an HTML code to the chat prompt, ChatGPT will then identify and extract hidden data from the page data.
We've covered a similar approach for finding web elements with ChatGPT previously but now we'll use it for non-HTML entities. Let's take a look at how we can make ChatGPT scrape hidden data.
Setup
Before we start finding hidden web data with chatgpt, let’s take a look at our target website.
In this example, we we’ll be using web-scraping.dev/product/4 page:
To pass this page into ChatGPT’s chat prompt, we need to copy the HTML first which can be saved directly from the browser (CTRL+s) or scraped using python:
import requests
response = requests.get("https://web-scraping.dev/product/4")
print(response.text)
🙋 if you have a very long HTML file, you can split the HTML code into smaller chunks and pass them to the chat prompt as chatgpt has a character limit.
Scrape hidden web data with chatgpt
Now that we got the HTML code, let’s the find hidden web data using chatgpt.
We’ll paste the code in the chat prompt and ask for hidden data:

ChatGPT will scan the HTML document and find the hidden data elements for us:
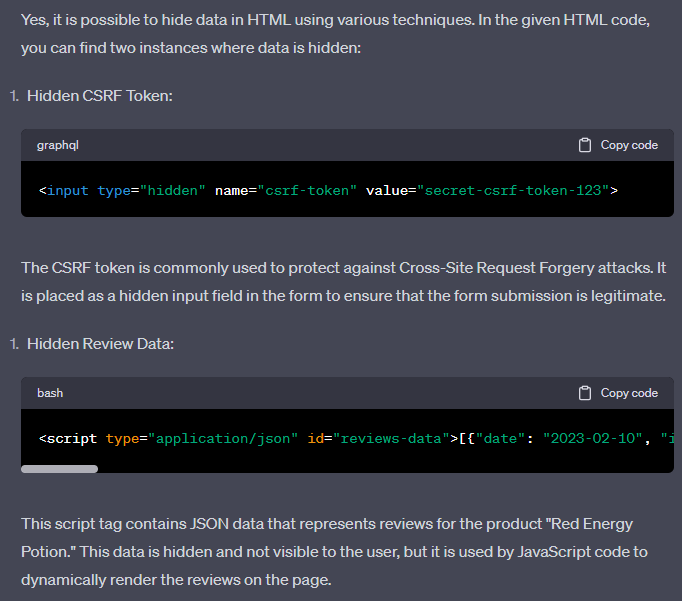
We can see it did a great job finding scripts that contain the review data. Next, we can ask it to cleanup and format the result:
Can you clean the review data and format it in JSON?
ChatGPT output data
[
{
"date": "2023-02-10",
"id": "red-potion-1",
"rating": 5,
"text": "The berry flavor is intense and delicious. Great for keeping me focused during my gaming sessions."
},
{
"date": "2023-03-20",
"id": "red-potion-2",
"rating": 5,
"text": "Not only does it look cool, but it tastes great and gives a good energy boost!"
},
{
"date": "2023-04-09",
"id": "red-potion-3",
"rating": 4,
"text": "It's like a health potion for gamers! The energy boost is spot on."
},
{
"date": "2023-05-17",
"id": "red-potion-4",
"rating": 5,
"text": "Good flavor and keeps me energized. The bottle design is really fun."
}
]
ChatGPT is smart enough to find and present this data. We can ask it to produce parsing code for us by further requesting with prompts like "
ChatGPT Character Limit
While we can scrape hidden web data with chatgpt, complex websites with longer HTML files can’t fit into the chat prompt.
For example, this Glassdoor page has some hidden data:
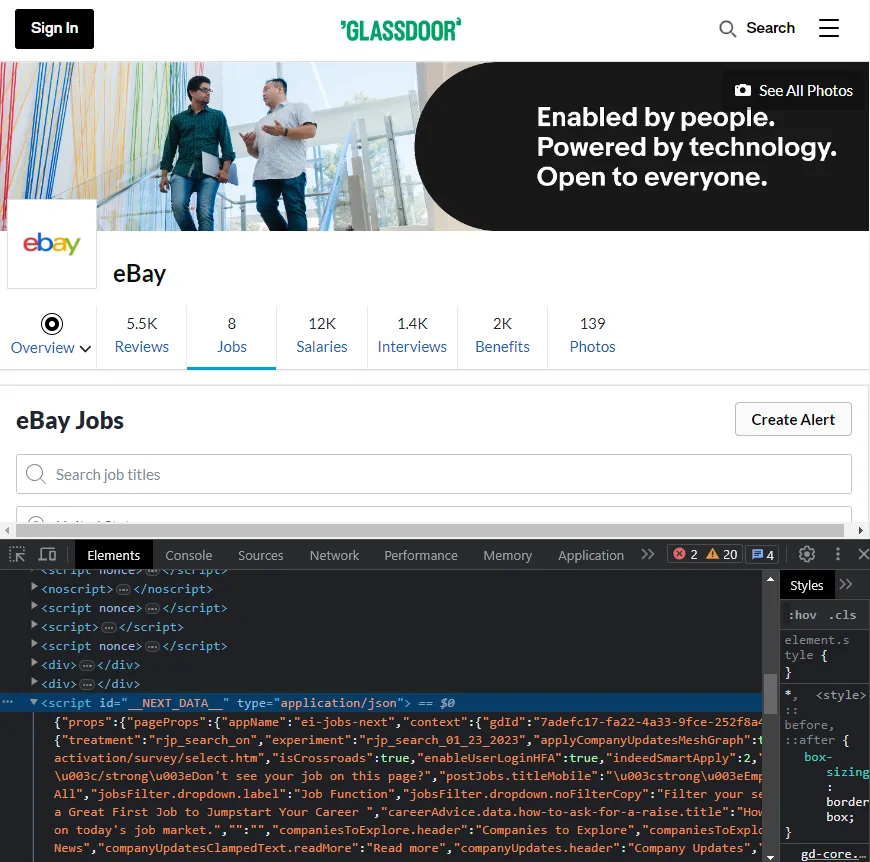
Unfortunately, the giant HTML pages of Glassdoor couldn't fit into the chat prompt for us to take advantage of chatgpt here.
For this, the new chatgpt code interpreter feature comes in handy which allows to upload files directly. We've covered this approach in crafting a chatgpt web scraper using the code interpreter article for more but basically, we'd attach the HTML file directly instead of pasting it into the chat prompt.
How to Scrape Glassdoor (2025 update)
In this web scraping tutorial we'll take a look at Glassdoor - a major resource for company review, job listings and salary data.

We can see what a great assistant chatGPT can be when it comes to web scraper development though we can take this even further by taking advantage of Scrapfly's web scraping API. Let’s take a quick look!
Scrape Hidden Data with ScrapFly
While hidden web data is often easy to handle and scrape scaling up these type of scrapers can be a challenge and Scrapfly can simplify this process.

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale.
- Anti-bot protection bypass - extract web pages without blocking!
- Rotating residential proxies - prevent IP address and geographic blocks.
- LLM prompts - extract data or ask questions using LLMs
- Extraction models - automatically find objects like products, articles, jobs, and more.
- Extraction templates - extract data using your own specification.
- Python and Typescript SDKs, as well as Scrapy and no-code tool integrations.
Here's how we'd use Scrapfly to scrape Glassdoor page using ScrapFly Python SDK:
from scrapfly import ScrapeConfig, ScrapflyClient
client = ScrapflyClient(key="Your ScrapFly API key")
result = client.scrape(ScrapeConfig(
url="https://www.glassdoor.com/Jobs/eBay-Jobs-E7853.htm?filter.countryId=1",
# enable headless browser use and evaluate javascript script
render_js=True,
# we can tell the headless browser to wait 2 seconds for the content to load:
rendering_wait=2_000,
# we can set specific proxy country:s
country="CA",
# we can also take screenshots to see what our browser is doing:
screenshots={"fullpage": "fullpage"}
))
# we can find hidden web data:
data = result.selector.css("script#__NEXT_DATA__::text").get()
print(data)
# OR since we used a headless browser we can scrape the HTML directly
for job in result.selector.css('.job-title::text'):
print(job.get())
Using Scrapfly we can scrape hidden web data from any website without being worried about anti-scraping protection or getting blocked. Scrapfly's headless browsers also significantly simplify the scraping process and is an easy way to handle hidden web data.
FAQs
Can I scrape hidden web data with BeautifulSoup?
Yes, but since BeautifulSoup doesn't support JavaScript, you won't be able to find hidden data in the HTML. You have to parse it from JavaScript script tags using Regex or JSON finding algorithms.
How do I extract JSON-LD structured data from script tags using ChatGPT?
Pass the HTML containing <script type="application/ld+json"> tags to ChatGPT and ask it to extract the structured data. ChatGPT can identify and parse JSON-LD, microdata, and other structured formats from script tags.
When should I use ChatGPT instead of BeautifulSoup or Selenium for hidden data?
Use ChatGPT when you need quick data extraction from complex HTML, want to avoid setting up browser automation, or need to parse data from large HTML files. Use BeautifulSoup for simple HTML parsing and Selenium for dynamic content that requires JavaScript execution.
What are the limitations of using ChatGPT for web scraping hidden data?
ChatGPT has character limits for input, can't execute JavaScript, requires manual HTML copying, and may not handle very large or complex HTML structures. It's best for one-off extractions rather than automated scraping.
Is it legal to use ChatGPT to scrape hidden data from websites?
Yes, using ChatGPT to analyze publicly available HTML data is legal. However, always respect website terms of service, robots.txt, and applicable data protection laws when scraping any data.
How do I handle obfuscated or minified JavaScript when using ChatGPT to find hidden data?
ChatGPT can often parse obfuscated JavaScript and extract meaningful data. For heavily minified code, ask ChatGPT to "beautify" or "format" the JavaScript first, then extract the relevant data structures.
Scrape hidden data with ChatGPT Summary
In summary, hidden web data is data saved into script tags or JavaScript variables, which is rendered to HTML by running JavaScript in the browser. We can scrape hidden web data in multiple ways, including headless browsers, parsing JSON from script tags and ChatGPT.
We have seen that it's possible to find and scrape hidden data with chatgpt. However, you need to be careful while using the chat prompt. Clear prompt instructions and short HTML code are the keys to getting decent ChatGPT web scraping results.