

JavaScript rendering is often required to scrape dynamic websites that load data using JavaScript. To handle this in web scraping a common approach is to use headless browsers. However, this approach can be difficult and complex and hard to pair with scraping frameworks like Scrapy. In cases like this, a self-hosted headless browser service like Splash is a perfect fit!
In this article, we'll explore how to web scrape with Scrapy Splash. A headless browser tool specially crafted for Scrapy which allows to scrape dynamic web pages. We'll start by defining what Splash is, how to install and navigate it. Then, we'll go over a step-by-step guide on using Scrapy Splash for web scraping. Let's get started!
Key Takeaways
Combine Scrapy's crawling framework with Splash JavaScript rendering for scraping dynamic web pages that require browser automation and custom interactions.
- Deploy Splash via Docker for consistent JavaScript rendering environment across different systems and platforms
- Write Lua scripts to execute custom JavaScript, handle scrolling, and interact with dynamic elements on pages
- Configure resource filtering to disable images and block unnecessary domains for faster processing and reduced bandwidth
- Use parallel processing to handle multiple pages simultaneously and improve scraping efficiency with concurrent requests
- Integrate with Scrapy middleware to automatically route requests through Splash for JavaScript rendering
- Use ScrapFly as an alternative to Splash for easier JavaScript rendering with built-in anti-blocking features
What is Scrapy Splash?
As the name suggests, Scrapy Splash is an integration between Scrapy and Splash. Scrapy is an HTTP-based web crawling framework with built-in tools for common web scraping utilities, such as middlewares, runners and parsers. However, the biggest advantage of Scrapy lies in its non-blocking networking infrastructure that makes requesting web pages more efficient.
Splash is a JavaScript rendering service that operates over APIs. Unlike regular headless browsers, Splash uses lightweight Webkit or Chromium engines, making rendering dynamic web pages fast. However, it allows for advanced features, such as:
- Processing multiple web pages in parallel.
- Taking screenshots.
- Turning off image rendering or blocking requests from specific domains.
- Executing custom JavaScript and Lua scripts.
- Getting detailed rendering info in the HAR format.

How to Install Scrapy Splash?
To use Scrapy Splash for web scraping, we'll have to install scrapy, splash and scrapy-splash.
To start, Splash can be installed using Docker. If you don't have Docker installed, refer to the official installation page.
Create a docker-compose.yml file and add the following code:
version: '3'
services:
splash:
image: scrapinghub/splash
ports:
- "8050:8050"The above command pulls the splash image and maps the splash port to localhost:8050. Then, spin up the splash server using the following command:
docker-compose up --buildTo verify your Splash installation, head over to the Splash server on localhost:8050. You will get the following page:
Next, install the scrapy-splash integration and Scrapy using the following pip command:
pip install scrapy scrapy-splashBasic Spash Navigation
Splash itself is a server that communicates over HTTP. This means that we can perform web scraping with Splash using any HTTP client, such as How to Web Scrape with HTTPX and Python. So, before we use it with Scrapy, let's explore a few of its core features.
Render.html
The /render.html endpoint provides most of the Splash functionalities for rendering web pages and returns rendered HTML. You can try it with curl in your terminal:
curl --location 'http://localhost:8050/render.html' \
--header 'content-type: application/json' \
--data '{"url": "https://web-scraping.dev/products"}'Here, we specify the URL of the Splash instance on localhost and pass the page URL to render through the url parameter in the request body.
To web scrape with Splash, we have to capture the HTML we got from each request sent. So, let's send the above request using Python requests instead of CURL:
import requests
import json
url = "http://localhost:8050/render.html"
payload = json.dumps({
"url": "https://web-scraping.dev/products" # page URL to render
})
headers = {
'content-type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
"""
<!DOCTYPE html><html lang="en"><head>
<meta charset="utf-8">
<title>web-scraping.dev product page 1</title>
"""Splash has rendered the page with JavaScript and returned the final page HTML.
However, there are a few more important rendering parameters - let's explore some of this endpoint's options we can utilize while web scraping:
import requests
import json
url = "http://localhost:8050/render.html"
payload = json.dumps({
"url": "https://web-scraping.dev/products", # page URL to render
"timeout": 20, # timout for the request
"wait": 5, # rendering wait
"images": 0, # disable image rendering
"html5_media": 1, # enable HTML5 media
"http2": 1, # enable HTTP2
"engine": "webkit" # use the webkit as rendering engine
})
headers = {
'content-type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)In the above code, we provide Splash with additional parameters for controlling the request. Let's break them down:
| Parameter | Description | Default |
|---|---|---|
timeout |
Time interval in seconds, in which splash timeouts after | 30 seconds. The max is 90, but it can overridden. |
wait |
Time to wait after the page loads in seconds. | 0 seconds |
images |
Whether to enable or disable image rendering. | 1 (enabled) |
html5_media |
Whether to render HTML5, such as videos. | 0 (disabled) |
http2 |
Whether to use HTTP2 with the requests. | 0 (disabled) |
engine |
Rendering engine to use, either Webkit or Chromium. | webkit |
The above requests are sent of the GET method. However, Splash also supports sending POST requests with custom headers and body:
import requests
import json
url = "http://localhost:8050/render.html"
payload = json.dumps({
"url": "https://httpbin.dev/anything",
"headers": {"key1": "value1", "key2": "value2"},
"body": "This is a request body",
"http_method": "POST"
})
headers = {
'content-type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Here, we override the http_method parameter to POST and add custom request How Headers Are Used to Block Web Scrapers and How to Fix It and body.
Render.png
The /render.png endpoint renders web pages and instead of HTML returns screenshots in the png format. It accepts all the render parameters in addition to a few more parameters for adjusting the screenshot:
import requests
import json
url = "http://localhost:8050/render.png"
payload = json.dumps({
"url": "https://web-scraping.dev/products",
"width": 1280, # adjust the image width
"height": 720, # adjust the image height
## alternatively, screenshot the whole page (with scrools)
# "wait": 5,
# "render_all": 1
})
headers = {
'content-type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
# create an image file
with open("screenshot.png", "wb") as f:
f.write(response.content)Above, we use the render.png endpoint to screenshot the page and adjust the image width and height. The response contains the binary data of the image. To save it, we use the Python write method to write it into a png file.
Splash also provides a /render.jpeg endpoint for taking screenshots in the jpeg format. It uses the same /render.png parameter with an additional quality parameter for compressing the image quality.
Other Splash Endpoints
The other endpoints aren't as common in web scraping but also offer additional powerful functions:
- Render.har Returns information about the Splash interaction with the web page in the HAR format. It includes details about the requests, responses, headers, and timings, similar to the networking tab in the browser developer tools.
- Render.json Returns JSON-based data about the requested web page based on the used parameters, including the HTML and screenshots.
- Execute Supports all the previous endpoint functionalities in addition to writing custom scripts for Splash in Lua.
- Run
Same as
/execute, but it wraps the passed Lua scripts in a different structure.
Web Scraping With Scrapy Splash
Now that we have an overview of what Splash is. Let's explore using it with Scrapy Splash for web scraping. We'll also explore executing custom JavaScript code while scraping, such as scrolling, clicking buttons and filling forms!
In this Scrapy Splash tutorial, we'll only cover the basics of Scrapy. For more details on navigating Scrapy, including managing spiders, crawling and parsing logic, refer to our previous guide on web scraping with Scrapy.

Setting Up Scrapy Splash
To scrape with Scrapy Splash, we'll have to explicitly instruct Scrapy to use Splash. First, let's start a new Scrapy project using the startproject command:
scrapy startproject reviewscan reviewscan-scraperThe abode command will create a Scrapy project in the reviewscan-scraper folder:
$ cd reviewscan-scraper
$ tail
.
├── reviewscan
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
└── scrapy.cfgNext, let's configure the created Scrapy project with Splash by adding these settings to settings.py configuration file:
# the splash instance URL on localhost
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'Now that the Scrapy project can use our Splash instance. Let's start scraping with scrapy-splash by creating scrapy spider!
Creating Scraping Spider
In this article, we'll scrape testominal data from web-scraping.dev:
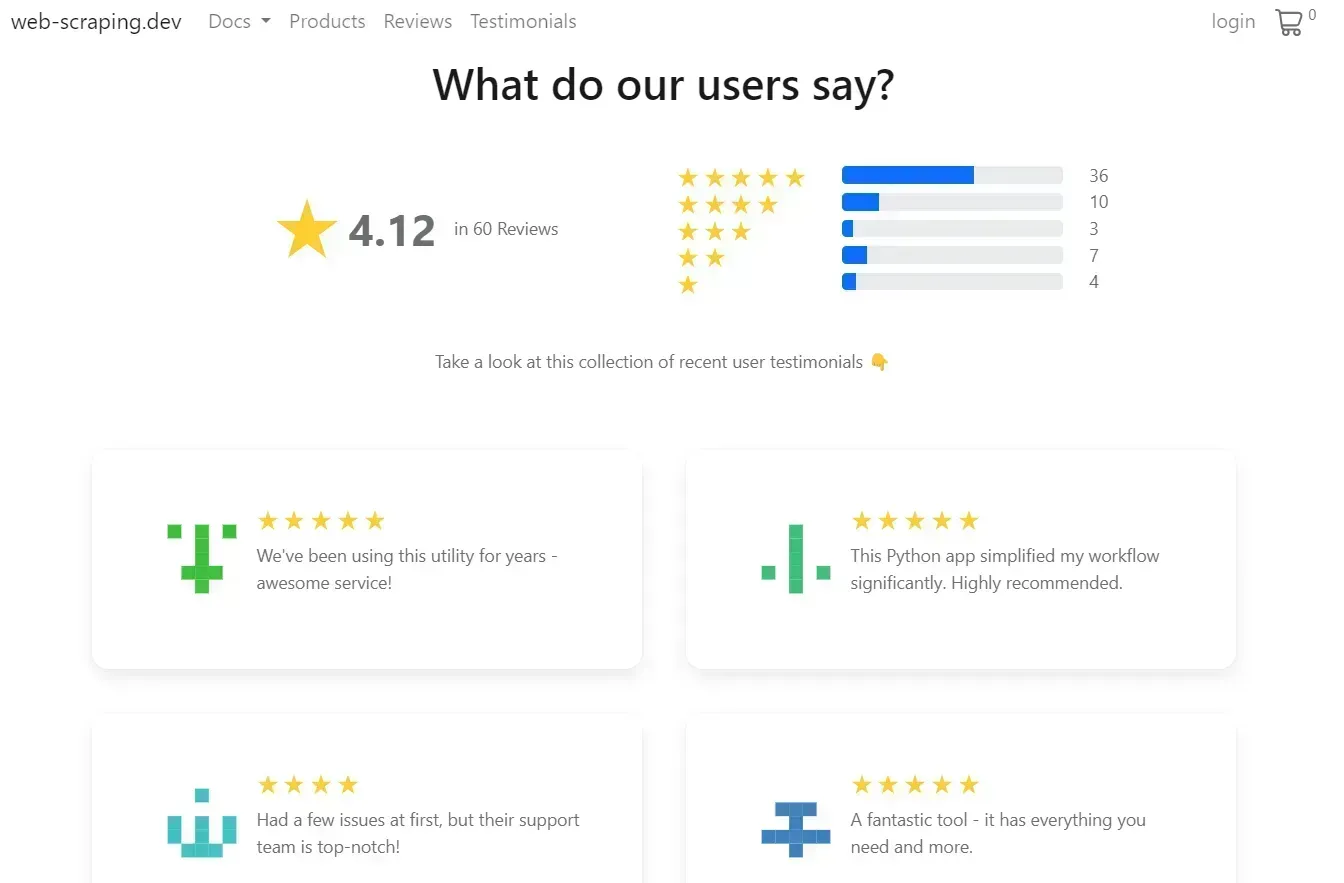
To extract this review data, let's create a Scrapy spider in our project using the genspider command:
$ scrapy genspider reviews web-scraping.dev
# ^ name ^ host to scrapeThe above command will create a boilerplate spider named reviews.py:
import scrapy
class ReviewsSpider(scrapy.Spider):
name = "reviews"
allowed_domains = ["web-scraping.dev"]
start_urls = ["https://web-scraping.dev"]
def parse(self, response):
passLet's break down the above code:
nameis the spider id for Scrapy commands to run, such asscrapy crawl reviews.allowed_domainsis a safety feature that restricts the spider to only crawl the specified domain.start_urlsis a list of URLs where the spider will start crawling from.
The above code is designed for crawling purposes to scrape data from nested pages. However, our desired data lies under the main page. Therefore, we'll replace the starts_urls with a start_requests() function and add parsing logic to iterate and parse the reviews on the page. We'll also add Splash metadata to redirect the request into the Splash instance:
import scrapy
class ReviewsSpider(scrapy.Spider):
name = "reviews"
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield scrapy.Request(url=url, callback=self.parse, meta={
"splash": {
"args": {
"html": 1,
"png": 1
}
}
})
def parse(self, response):
print(response.data.keys())
"dict_keys(['png', 'url', 'requestedUrl', 'geometry', 'title', 'html'])"
reviews = response.css("div.testimonial")
for review in reviews:
yield {
"rate": len(review.css("span.rating > svg").getall()),
"text": review.css("p.text::text").get()
}The above code is the same as the regular Scrapy code. We only add a meta key to add a few Splash metadata:
htmlto set to one to save the HTML with the Splash response.pngto set to one to save a png screenshot with the Splash response.
After the request is sent, Scrapy passes the response to the parse function. The actual response contains the HTML and regular Scrapy parsers. However, the response.data contains the full Splash response.
The rest of the code is parsing logic. We use the CSS selectors to iterate over all the reviews on the page and then extract the rate and text from each one.
Let's run this review spider and save the results to a JSON file:
scrapy crawl reviews --output results.jsonHere are the results we got:
[
{"rate": 5, "text": "We've been using this utility for years - awesome service!"},
{"rate": 4, "text": "This Python app simplified my workflow significantly. Highly recommended."},
{"rate": 3, "text": "Had a few issues at first, but their support team is top-notch!"},
{"rate": 5, "text": "A fantastic tool - it has everything you need and more."},
{"rate": 2, "text": "The interface could be a little more user-friendly."},
{"rate": 5, "text": "Been a fan of this app since day one. It just keeps getting better!"},
{"rate": 4, "text": "The recent updates really improved the overall experience."},
{"rate": 3, "text": "A decent web app. There's room for improvement though."},
{"rate": 5, "text": "The app is reliable and efficient. I can't imagine my day without it now."},
{"rate": 1, "text": "Encountered some bugs. Hope they fix it soon."}
]The above request is sent over the Splash /render.json endpoint by default. However, we can configure the endpoint and parameters for Splash to use:
def start_requests(self):
url = "https://web-scraping.dev/testimonials"
yield scrapy.Request(url=url, callback=self.parse, meta={
"splash": {
"args": {
"html": 1,
"png": 1,
"width": 1280,
"height": 720,
# screenshot the whole page instead
"wait": 5,
"render_all": 1
# 'url' is prefilled from request url
# 'http_method' is set to 'POST' for POST requests
# 'body' is set to request body for POST requests
},
# optional parameters
'endpoint': 'render.json', # use another Splash endpoint, default is render.json
'splash_url': '<url>', # override the Splash URL un the senttings.py file
}
})Here, we enable the png parameter to capture a screenshot of the page and specify the driver dimensions. We can also enable the render_all parameter to screenshot the whole page instead.
Just with default values Splash can get us pretty far when it comes to dynamic data scraping. To take this even further let's take a brief look at browser scripting with Scrapy Splash and Lua scripting language.
Executing Lua Scripts With Scrapy Splash
Splash allows executing custom JavaScript either by passing it through the js_source parameter or defining it in a Lua script, which then gets executed by Splash.
Note that the js_source approach is limiting and doesn't offer a great developing experience so it's best to stick with Lua scripting feature.
Let's start with writing a Lua script for scrolling while scraping using Scrapy Splash.
Handling Infinite Scrolling With Scrapy Splash
Splash itself doesn't have built-in functionalities for scrolling like Selenium or other headless browsers. So, scrolling in Scrapy Splash can only be achieved through JavaScript execution.
We'll simulate a scroll action through a JavaScript function and pass it through a Lua script for execution:
import scrapy
import base64
lua_script = """
function main(splash, args)
splash:go(args.url)
local scroll = splash:jsfunc([[
function scrollWithDelay() {
for (let i = 0; i < 5; i++) {
setTimeout(() => window.scrollTo(0, document.body.scrollHeight), i * 2000);
}
}
]])
scroll()
splash:wait(5.0)
return {
html = splash:html(),
png = splash:png(),
}
end
"""
class ReviewsSpider(scrapy.Spider):
name = "reviews"
def start_requests(self):
url = "https://scrapfly.io/"
yield scrapy.Request(url=url, callback=self.parse, meta={
"splash": {
"args": {
"html": 1,
"png": 1,
"lua_source": lua_script,
"wait": 5
},
"endpoint": "execute",
}
})
def parse(self, response):
print(response.data.keys())
# "dict_keys(['html', 'png'])"
image_binary = base64.b64decode(response.data["png"])
with open("screenshot.png", "wb") as f:
f.write(image_binary)Above, we define the JavaScript scrollWithDelay() function within a local Lua function named scroll. Then, we execute the scroll function, wait for 5 seconds and return the page HTML and a screenshot.
Lua scripting in splash not only gives us access to splash functions but also the full javascript execution environment of the browser. Let's take a look at some other common browser automation tasks next.
Filling Forms and Clicking Buttons With Scrapy Splash
We'll use Scrapy Splash to login into web-scraping.dev/login using JavaScript.
Let's start with JavaScript code. It will accept the Cookie policy on the page, fill in the login credentials and then click submit:
function scrollPage() {
// Set an interval to scroll every 500 milliseconds (adjust as needed)
setInterval(function () {
window.scrollBy(0, window.innerHeight);
// Check if you have reached the bottom of the page
if (window.innerHeight + window.scrollY >= document.body.offsetHeight) {
clearInterval(scrollInterval);
}
}, 500); // Adjust the interval time as needed
}Now that we have the JavaScript code ready. Let's create a Scrapy spider and integrate it with a Lua script for Splash for execution:
import scrapy
lua_script = """
function main(splash, args)
splash:go(args.url)
local navigation_delay = 5.0
local handleLogin = splash:jsfunc([[
function () {
// accept the Cookie policy
document.querySelector("button#cookie-ok").click();
// fill-in the credentials
document.querySelector("input[name='username']").value="user123";
document.querySelector("input[name='password']").value="password";
// click submit
document.querySelector("button[type='submit']").click();
}
]])
handleLogin()
splash:wait(navigation_delay)
return {
html = splash:html(),
}
end
"""
class LoginSpider(scrapy.Spider):
name = "login"
def start_requests(self):
url = "https://web-scraping.dev/login"
yield scrapy.Request(url=url, callback=self.parse, meta={
"splash": {
"args": {
"html": 1,
"lua_source": lua_script
},
"endpoint": "execute"
}
})
def parse(self, response):
print(f"The secret message is {response.css('div#secret-message::text').get()}")
"The secret message is 🤫"
passAbove, we create a Lua script to request the login page and execute JavaScript function that performs the login action. Then, after executing the login function, we wait for 5 seconds explicitly to ensure the login flow completes and returns the HTML.
published_at: 2022-01-01
Through javascript execution, Splash can do a lot but it can be easily detected as browser actions are not natural. Let's take a look at an alternative to Splash that can help us with this next.
ScrapFly: Scrapy Splash Alternative
The scrapy-splash integration can enable JavaScript rendering with Scrapy. However, Splash has a steep learning curve and doesn't provide pre-built utilities for controlling the rendering engine while scraping. Moreover, scaling Scapy Splash can be challenging due to the websites' protection, which leads to web scraping blocking.
ScrapFly is a web scraping API that supports JavaScript rendering using cloud headless browsers. It allows for executing native JavaScript code with every scraping request or controlling the headless browsers using JavaScript scenarios, such as waiting for elements, clicking buttons and filling forms.
ScrapFly also allows for scraping at scale by providing:
- Anti-scraping protection - For scraping any website without getting blocked.
- Residential proxies from over 50 countries - For avoiding IP throttling and blocking while also allowing for scraping from almost any geographical location.
- Straightforward Python and Typescript SDKs, as well as Scrapy integration.
- And much more!

Here is how we can use ScrapFly integration with Scrapy to control the headless browser, as in the previous example. First, add the following lines to the settings.py in the Scrapy project:
SCRAPFLY_API_KEY = "Your ScrapFly API key"
CONCURRENT_REQUESTS = 2 # Adjust according to your plan limit rate and your needsAll we have to do is replace the scrapy.Spider with ScrapflySpider, declare the JavaScript scenario steps and enable the asp parameter to bypass any scraping blocking:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
ScrapeConfig(
# target website URL
url="https://web-scraping.dev/login",
# bypass anti scraping protection
asp=True,
# set the proxy location to a specific country
country="US",
# enable the cookies policy
headers={"cookie": "cookiesAccepted=true"},
# enable JavaScript rendering
render_js=True,
# scroll down the page automatically
auto_scroll=True,
# add JavaScript scenarios
js_scenario=[
{"fill": {"selector": "input[name='username']","clear": True,"value": "user123"}},
{"fill": {"selector": "input[name='password']","clear": True,"value": "password"}},
{"click": {"selector": "form > button[type='submit']"}},
{"wait_for_navigation": {"timeout": 5000}}
],
# take a screenshot
screenshots={"logged_in_screen": "fullpage"}
)
)
# get the HTML from the response
html = api_response.scrape_result['content']
# use the built-in Parsel selector
selector = api_response.selector
print(f"The secret message is {selector.css('div#secret-message::text').get()}")
"The secret message is 🤫"from scrapfly import ScrapeConfig
from scrapfly.scrapy import ScrapflyScrapyRequest, ScrapflySpider, ScrapflyScrapyResponse
class LoginSpider(ScrapflySpider):
name = 'login'
allowed_domains = ['web-scraping.dev']
def start_requests(self):
yield ScrapflyScrapyRequest(
scrape_config=ScrapeConfig(
# target website URL
url="https://web-scraping.dev/login",
# bypass anti scraping protection
asp=True,
# set the proxy location to a specific country
country="US",
# enable the cookies policy
headers={"cookie": "cookiesAccepted=true"},
# enable JavaScript rendering
render_js=True,
# scroll down the page automatically
auto_scroll=True,
# add JavaScript scenarios
js_scenario=[
{"fill": {"selector": "input[name='username']","clear": True,"value": "user123"}},
{"fill": {"selector": "input[name='password']","clear": True,"value": "password"}},
{"click": {"selector": "form > button[type='submit']"}},
{"wait_for_navigation": {"timeout": 5000}}
],
# take a screenshot
screenshots={"logged_in_screen": "fullpage"}
),
callback=self.parse
)
def parse(self, response: ScrapflyScrapyResponse):
print(f"The secret message is {response.css('div#secret-message::text').get()}")
passFAQ
What is the difference between Scrapy Splash and headless browsers?
Scrapy Splash is an integration between Scrapy and Splash that enables JavaScript rendering with Scrapy by redirecting the requests to Splash. On the other hand, headless browsers are fully controllable web browsers that can scrape dynamic web pages through popular libraries like Web Scraping with Selenium and Python, Web Scraping with Playwright and Python and How to Web Scrape with Puppeteer and NodeJS in 2026.
Can I scrape dynamic JavaScript web pages with Scrapy?
Yes, Splash is a server-based service that renders JavaScript-loaded pages using the Webkit engine. Splash can be integrated with Scrapy using the scrapy-splash middleware, allowing Scrapy to scrape dynamic web pages.
Can I avoid scraper blocking using Scrapy Splash?
No. Scrapy splash doesn't implement any extra scraper-blocking bypass features and is unlikely to help with scraping scraper-hostile targets that don't want to be scraped.
Scrapy Splash Summary
In this guide, we have explained how to scrape dynamic web pages using Scrapy Splash. We started by explaining what Splash is, how to install it and how to use its core API endpoints.
We also went through a step-by-step guide on web scraping with Scrapy Splash to extract data from dynamic web pages using the scrapy-splash middleware. We have seen that it's possible to inject and execute JavaScript code with Splash using Lua scripts for various actions, such as scrolling, filling forms, and clicking buttons.


