

In web development, data formats play a crucial role in how information is transferred and understood across different systems. Two of the most common formats are JSON and XML.
JSON, known for its lightweight and flexible structure, has become the leading format for web APIs and modern development practices. However, XML still maintains a presence, especially in legacy systems and scenarios requiring strict data validation.
This article will explore both formats, compare their advantages, and delve into how they're used, parsed, and converted in web development today.
Key Takeaways
Learn the key differences between JSON and XML data formats, their parsing methods, and when to use each for web development and data exchange.
- Use JSON for modern web APIs and lightweight data exchange with faster parsing and smaller size
- Choose XML for legacy systems and applications requiring strict data validation and schemas
- Parse JSON with native language support for simpler data extraction and manipulation
- Handle XML with specialized parsers like lxml or BeautifulSoup for complex document structures
- Consider JSON for mobile and web applications where bandwidth and performance matter
- Implement proper error handling for both formats to manage malformed data gracefully
What is JSON?
JSON (JavaScript Object Notation) is a lightweight data-interchange format that's easy for both humans and machines to read and write. Originally derived from JavaScript, JSON is language-agnostic and is now widely adopted across many programming environments.
JSON's structure is based on key-value pairs, where the key is string enclosed by double quotes and the value is one of a set of defined data types, including:
- Strings: Represent text data, enclosed in double quotes.
- Numbers: Used to represent numeric values, including integers and decimals.
- Booleans: Represent
trueorfalse. - Arrays: Ordered lists of values, which can contain any JSON value types.
- Objects: Unordered collections of key-value pairs.
- Null: Represents an empty or non-existent value.
This syntax makes it easy to serialize and deserialize JSON data, which is why it has become the preferred choice for data transmission in web APIs.
Example JSON object:
{
"name": "John Doe",
"age": 30,
"isEmployed": true,
"skills": ["JavaScript", "Python", "Node.js"],
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"phoneNumber": null
}JSON is commonly used for:
- Web APIs: JSON is the standard format for transferring data between a server and a client, making it ideal for RESTful APIs.
- Configuration Files: Many modern applications use JSON for storing settings, as it is simple to understand and modify.
- Data Serialization: JSON’s format makes it easy to serialize and send structured data between systems or store it in a file for later use.
What is XML?
XML (eXtensible Markup Language) is a data format used to define rules for defining data and encoding documents. It uses tags to differentiate between data attributes and the actual data.
XML is known for its hierarchical structure as well as its flexibility. It allows the use of attributes, comments, and custom tags which allows it to represent complex, rich, and descriptive data relationships.
ℹ️ **XML** and **HTML** are both markup languages that use tags to structure data, but they serve different purposes. HTML is designed to define the structure and presentation of web pages, focusing on how content is displayed in a browser. In contrast, XML is used to store and transport data in a flexible, hierarchical format, allowing developers to define their own tags.
Though it's more verbose compared to JSON, XML is often used in scenarios that require strict data validation or compatibility with legacy systems.
Example XML document:
<!-- This is a comment explaining the XML structure -->
<person id="123">
<name>John Doe</name>
<age>30</age>
<city>New York</city>
<contact phone="123-456-7890" email="john.doe@example.com" />
</person>XML is commonly used for:
- Web Services: SOAP (Simple Object Access Protocol) services often use XML as the primary data format to ensure standardized communication between different systems.
- Document-Based Data Exchange: XML is extensively used in industries like healthcare and finance for exchanging structured documents, as it ensures data accuracy through the use of well-defined schemas.
- Configuration Files: Some enterprise applications use XML configuration files to manage settings, especially where a more robust, structured approach is needed.
Key Difference Between JSON and XML
Although JSON and XML are both popular data formats used in web development, but they have fundamental differences in their design and applications.
JSON is primarily a data format focused on simplicity and efficiency for transmitting data. On the other hand, XML is a markup language designed to describe and structure documents with a focus on data integrity and extensibility.
While XML offers more powerful features, such as attributes, schemas, and custom tags, it also tends to be more verbose and complex compared to JSON.
Let’s take a look at a detailed comparison of these two formats.
| Aspect | JSON | XML |
|---|---|---|
| Type | Data Format | Markup Language |
| Syntax | Lightweight, easy-to-read key-value pairs | Verbose markup with opening and closing tags |
| Readability | Compact, human-readable, and easy to understand | Can be harder to read due to extensive tagging |
| Data Handling | Uses arrays and objects for a straightforward structure | Allows attributes, nested elements, and mixed content for more complex data representation |
| Schema Validation | No built-in schema support | Supports schemas through XSD for data validation |
| Flexibility | Ideal for simple data structures | Highly flexible for describing complex relationships |
| Parsing | Easy to parse using native methods in most programming languages | Requires XML parsers which can be more complex |
| Type Casting | Automatically infers types like strings, numbers, booleans, etc. | All data is treated as text and requires manual type conversion based on schema definitions |
| Use Cases | Web APIs, configuration files, client-server data exchange | Document-based data exchange, industry-specific standards, data validation |
| Extensibility | Limited extensibility | Highly extensible with user-defined tags |
| Data Size | Smaller, compact | Larger due to verbose tags (insignificant when compression is used) |
| Comment Support | No native support for comments | Supports comments using <!-- Comment --> syntax |
| Character Escapes | Limited escape sequences (e.g., \", \\, \n) |
Rich set of character escapes for special characters (e.g., <, >, &) |
| Common Pitfalls | - Trailing commas can cause parsing errors. - Precision loss in numbers due to floating-point representation. |
- Unclosed or mismatched tags can break parsing. - Whitespace preservation can be inconsistent. - Advanced features like namespaces and XSD schema can be confusing |
While JSON excels in simplicity, efficiency, and ease of use, XML shines in scenarios requiring complex data structures and strict validation.
So, when it comes to XML vs JSON it often depends on the project requirements: whether you need an efficient data exchange format or a feature-rich language for data validation and document handling.
Conversion between JSON and XML
Conversion between JSON and XML can be beneficial in situations where you need compatibility between systems using different data formats. Tools and libraries exist in most programming languages to perform these conversions.
Let's look at some Python and Node.js examples of coverting JSON to XML and vice versa. For a deeper dive into XML processing, see our guide to parsing XML.
Convert JSON to XML
To convert JSON to XML, you can use libraries like dicttoxml in Python and js2xmlparser in JavaScript (like Node.js):
import dicttoxml
json_data = {
"name": "John Doe",
"age": 30,
"city": "New York"
}
xml_data = dicttoxml.dicttoxml(json_data)
print(xml_data.decode())
const js2xmlparser = require("js2xmlparser");
const jsonData = {
name: "John Doe",
age: 30,
city: "New York"
};
const xmlData = js2xmlparser.parse("person", jsonData);
console.log("XML Output:");
console.log(xmlData);
Convert XML to JSON
To convert XML to JSON, you can use libraries like xmltodict in Python and xml2js in JavaScript (like Node.js):
import xmltodict
import json
xml_data = """
<person>
<name>John Doe</name>
<age>30</age>
<city>New York</city>
</person>
"""
dict_data = xmltodict.parse(xml_data)
json_data = json.dumps(dict_data)
print(json_data)const xml2js = require("xml2js");
const xmlData = `
<person>
<name>John Doe</name>
<age>30</age>
<city>New York</city>
</person>
`;
xml2js.parseString(xmlData, { explicitArray: false }, (err, jsonResult) => {
if (err) {
console.error("Error parsing XML:", err);
return;
}
console.log("JSON Output:");
console.log(jsonResult);
});Using AI with JSON and XML
Both JSON and XML play big roles in new LLM and AI technologies in many different ways. So, let's take a look at XML vs JSON in the context of rising AI and LLM applications next.
Parsing and Manipulation
In the realm of data processing, AI has become a powerful tool for parsing and manipulating JSON and XML data. These formats are widely used for data interchange, and AI can significantly enhance the efficiency and accuracy of working with them.
AI can generate instructions for querying and manipulating JSON and XML data. By analyzing the structure and content of the data, AI can suggest appropriate queries or transformations. This can save time and reduce errors, especially when dealing with complex data structures.
For instance, AI can generate Quick Intro to Parsing JSON with JMESPath in Python or Introduction to Parsing JSON with Python JSONPath queries based on the user's requirements, or it can suggest XPath or CSS selectors for extracting specific elements from an XML document. This capability is particularly useful for developers and data analysts who need to work with large and complex datasets.
Check out our guide on using ChatGPT to faciliate JSON parsing.
{
"store": {
"book": [
{ "category": "fiction", "title": "The Great Gatsby" },
{ "category": "non-fiction", "title": "Sapiens" }
]
}
}Using JMESPath, you can extract all book titles with the following query:
store.book[*].titleFor XML, XPath and CSS selectors are used to navigate and extract data from XML documents. XPath provides a way to query XML documents using path expressions, while CSS selectors allow you to select elements based on their attributes and hierarchy.
For more details about XML parsing, you can check out our guide on XML parsing which explores different XML parsing techniques in depth.
<store>
<book category="fiction">
<title>The Great Gatsby</title>
</book>
<book category="non-fiction">
<title>Sapiens</title>
</book>
</store>Using XPath, you can extract all book titles with the following query:
//book/titleAI can also assist in reshaping JSON and XML data to fit specific requirements. This involves transforming the structure of the data to make it more suitable for a particular application or analysis. For JSON, this might involve flattening nested structures or aggregating data. For XML, it could mean converting hierarchical data into a more flat structure or vice versa.
For example, consider the following JSON data:
{
"name": "John Doe",
"address": {
"street": "123 Main St",
"city": "New York"
}
}You can reshape this data to a flat structure using a transformation tool:
{
"name": "John Doe",
"street": "123 Main St",
"city": "New York"
}Similarly, XML data can be reshaped to fit different schemas or formats, making it easier to integrate with other systems or applications.
In summary, AI enhances the ability to parse, manipulate, and reshape JSON and XML data, making it easier to extract valuable insights and integrate data across different systems. Whether you're working with web APIs, configuration files, or document-based data, AI can streamline your workflow and improve the accuracy of your data processing tasks.
Data Extraction
Extracting structured data from unstructured text is one of the most powerful applications of modern AI models. Today, with the advancement of Large Language Models (LLMs), extracting structured outputs has become more efficient, accessible, and precise.
Popular LLM APIs like GPT, Gemini, and Claude now provide specialized tools to transform complex, freeform text into structured data formats such as JSON, making them a go-to solution for developers working with unstructured data.
We can demonstarte a simple example of extracting JSON product data from an HTML page using a product from web-scraping.dev and OpenAI's chat completions API with the structured output feature.
We need to get the basic information of this product in JSON format.
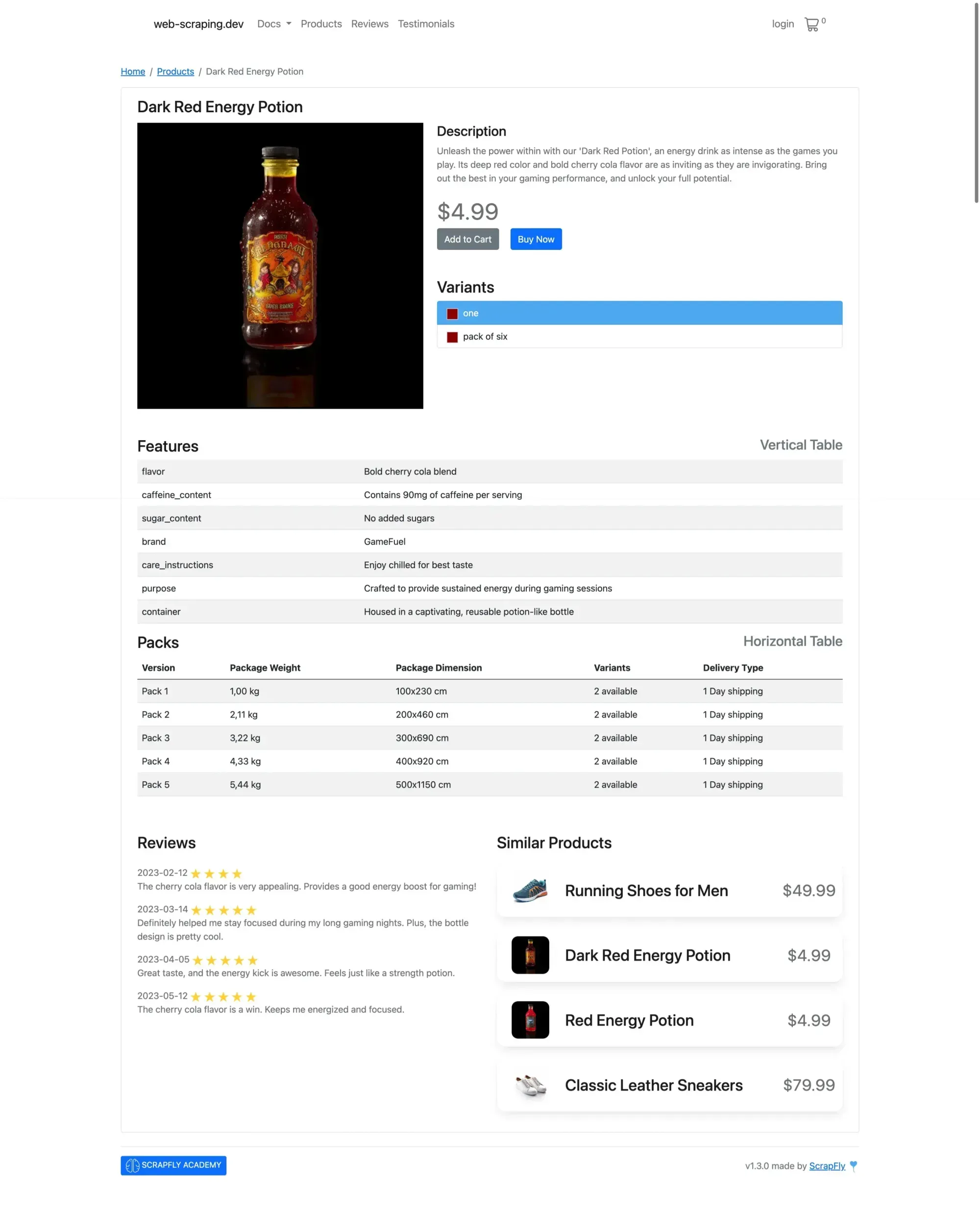
We can create a JSON schema that we will pass to OpenAI's API so that the model will make sure to respond with a JSON object that validate this schema.
{
name: "product",
strict: true,
schema: {
type: "object",
properties: {
name: {
type: "string",
description: "The name of the product.",
},
description: {
type: "string",
description: "A brief description of the product.",
},
price: {
type: "number",
description: "The price of the product.",
},
features: {
type: "array",
description: "List of features of the product.",
items: {
type: "object",
properties: {
name: {
type: "string",
description: "The feature name.",
},
details: {
type: "string",
description: "The feature details",
},
},
required: ["name", "details"],
additionalProperties: false,
},
},
reviews: {
type: "array",
description: "List of reviews for the product.",
items: {
type: "object",
properties: {
date: {
type: "string",
description: "The review date.",
},
rating: {
type: "number",
description: "The rating given by the reviewer.",
},
comment: {
type: "string",
description: "The review comment.",
},
},
required: ["date", "rating", "comment"],
additionalProperties: false,
},
},
},
required: ["name", "description", "price", "features", "reviews"],
additionalProperties: false,
},
}We will use Node.js to fetch the product page's HTML content and pass it to the API call where we also provide the above JSON schema in the response_format parameter.
import OpenAI from "openai";
const openai = new OpenAI({
apiKey:
"YOUR_API_KEY",
});
const htmlResponse = await fetch(
"https://web-scraping.dev/product/2?variant=one"
);
const html = await htmlResponse.text();
const completion = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: "Extract the product information from the HTML page",
},
{
role: "user",
content: html,
},
],
response_format: {
type: "json_schema",
json_schema: // The JSON schema goes here
},
});
const product = JSON.parse(completion.choices[0].message.content);
console.log(product);The API successfully responds with the following JSON data:
{
name: 'Dark Red Energy Potion',
description: "Unleash the power within with our 'Dark Red Potion', an energy drink as intense as the games you play. Its deep red color and bold cherry cola flavor are as inviting as they are invigorating. Bring out the best in your gaming performance, and unlock your full potential.",
price: 4.99,
features: [
{ name: "flavor", details: "Bold cherry cola blend" },
{
name: "caffeine_content",
details: "Contains 90mg of caffeine per serving"
},
{ name: "sugar_content", details: "No added sugars" },
{ name: "brand", details: "GameFuel" },
{
name: "care_instructions",
details: "Enjoy chilled for best taste"
},
{
name: "purpose",
details: "Crafted to provide sustained energy during gaming sessions"
},
{
name: "container",
details: "Housed in a captivating, reusable potion-like bottle"
}
],
reviews: [
{
date: "2023-02-12",
rating: 4,
comment: "The cherry cola flavor is very appealing. Provides a good energy boost for gaming!"
},
{
date: "2023-03-14",
rating: 5,
comment: "Definitely helped me stay focused during my long gaming nights. Plus, the bottle design is pretty cool."
},
{
date: "2023-04-05",
rating: 5,
comment: "Great taste, and the energy kick is awesome. Feels just like a strength potion."
},
{
date: "2023-05-12",
rating: 5,
comment: "The cherry cola flavor is a win. Keeps me energized and focused."
}
]
}The ability to extract structured data from unstructured sources is a game-changer in data processing. With the advanced features offered by LLM APIs like GPT, Gemini, and Claude, developers can efficiently transform raw data into valuable insights. This not only enhances data analysis but also opens up new possibilities for automation and innovation across various industries.
Using XML for LLM Prompting
XML is a powerful tool for structuring data, and it can be effectively used for prompting Large Language Models (LLMs). By using XML tags, you can create well-defined prompts that guide the LLM to generate more accurate and relevant responses. Here are some key aspects of using XML for LLM prompting:
1. Structuring Prompts with XML Tags
XML tags can be used to define the structure and content of prompts. This helps in organizing the information and making it clear for the LLM to understand the context and requirements. For example, you can use tags to specify different parts of the prompt, such as instructions, examples, and expected outputs.
<prompt>
<instruction>Generate a summary of the following text:</instruction>
<text>
<paragraph>Artificial Intelligence (AI) is a rapidly evolving field...</paragraph>
</text>
<output>Summary:</output>
</prompt>In this example, the <instruction> tag provides the task, the <text> tag contains the input data, and the <output> tag indicates where the LLM should generate the response.
2. Enhancing Clarity and Precision
Using XML tags can enhance the clarity and precision of prompts by explicitly defining the roles of different elements. This reduces ambiguity and helps the LLM to focus on the specific task. For instance, you can use tags to highlight key points, questions, or constraints.
<prompt>
<question>What are the benefits of using AI in healthcare?</question>
<constraints>
<constraint>Focus on patient outcomes</constraint>
<constraint>Mention cost-effectiveness</constraint>
</constraints>
</prompt>Here, the <question> tag specifies the query, and the <constraints> tag lists the conditions that the LLM should consider while generating the response.
3. Defensive Measures with XML Tagging
XML tagging can also be used as a defensive measure to prevent prompt injection attacks and ensure the integrity of the prompts. By defining strict XML schemas, you can validate the structure and content of the prompts before they are processed by the LLM. This helps in maintaining the security and reliability of the system.
<prompt>
<instruction>Translate the following sentence to French:</instruction>
<sentence>Hello, how are you?</sentence>
</prompt>By validating the prompt against a predefined XML schema, you can ensure that only well-formed and authorized prompts are used.
In summary, using XML for LLM prompting provides a structured and clear way to define tasks and guide the model's responses. It enhances the precision and reliability of the prompts, making it a valuable tool for developers and data analysts working with large language models.
For more detailed information, you can refer to the Anthropic documentation and the Learn Prompting guide.
Power Up with Scrapfly Extraction API
Scrapfly's advanced Extraction API simplifies the data parsing process for any data format be it JSON or XML by utilizing machine learning and LLM models.

Learn more about Web Scraping API and how it works.
Scrapfly's Extraction API includes a number of predefined models that can automatically extract common objects like products, reviews, articles etc.
For example, let's use the product model to extract the product data from the same page used in the example above:
from scrapfly import ScrapflyClient, ScrapeConfig, ExtractionConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
# First retrieve your html or scrape it using web scraping API
html = client.scrape(ScrapeConfig(url="https://web-scraping.dev/product/2?variant=one")).content
# Then, extract data using extraction_model parameter:
api_result = client.extract(
ExtractionConfig(
body=html,
content_type="text/html",
extraction_model="product",
)
)
print(api_result.result)FAQ
What are the primary differences between JSON and XML?
The primary differences between JSON and XML lie in their structure and syntax. JSON is a lightweight data format that uses key-value pairs, making it easy to read and write. In contrast, XML utilizes a more verbose syntax with tags to represent data, which can add complexity. While JSON is primarily used for data interchange in web APIs, XML excels in data representation requiring strict validation and better compatibility with legacy systems.
Can I convert data between XML and JSON?
Yes, data can be converted between XML and JSON using various tools and libraries available in most programming languages like xmltodict and dicttoxml in python and xml2js and js2xmlparser in node.js. There are also numerous online converters that can quickly transform XML data to JSON format and vice versa.
How is JSON used in web APIs?
JSON is extensively used in web APIs because of its lightweight nature and ease of parsing. It serves as a standard format for data exchange between a client and a server, enabling seamless communication in RESTful APIs.
JSON's simplicity allows developers to facilitate quick data serialization and deserialization, making it ideal for modern web applications that require efficient data interchange.
Which format is better for web scraping responses?
JSON is generally preferred for web scraping. Most modern web APIs return JSON, and it parses faster with native support in every major language. XML is still common in legacy SOAP APIs and RSS feeds. For scraping JSON from APIs, check our guide to parsing JSON in Python.
Summary
In this JSON vs XML overview, we explored the differences and unique features of JSON and XML: two popular data formats widely used in web development:
- What is JSON and XML?: JSON is a lightweight data format used for data interchange, while XML is a flexible markup language used to define and structure documents.
- Key Differences: We compared JSON and XML across multiple aspects like readability, data validation, type handling, comment support, and common pitfalls.
- Data Conversion Examples: We demonstrated how to convert between JSON and XML using Python and Node.js, highlighting tools that make the process seamless.
- Using AI with JSON and XML: We discussed how LLMs like GPT, Gemini, and Claude bring new uses to both JSON and XML
Whether you need simple data handling with JSON or more complex document structuring with XML, choosing the right tool depends on the project requirements.


