

Phone number scraping is one of the most common scraping use cases for lead generation. However, extracting phone numbers from websites is not always an easy task.
In this article, we'll explain how to crawl web pages to discover leads and how to successfully scrape phone numbers. We'll also cover the most common challenges involved with phone number scraping and how to overcome them using Python. Let's dive in!
Key Takeaways
Learn phone number scraping techniques using Python regex patterns, BeautifulSoup parsing, and Playwright for JavaScript-powered websites.
- Implement phone number extraction using regex patterns and BeautifulSoup for structured data parsing from HTML pages
- Configure headless browser automation with Playwright for JavaScript-powered websites and dynamic content
- Implement data validation and phone number formatting for consistent lead generation workflows
- Configure proxy rotation and fingerprint management to avoid detection and rate limiting
- Use specialized tools like ScrapFly for automated phone number scraping with anti-blocking features
- Implement data cleaning and deduplication for reliable contact information extraction and lead management
Why Scrape Phone Numbers?
Phone numbers are a crucial contact method for lead generation which helps organizations and businesses in several ways by allowing for:
- Growing customer base by connecting with new customers.
- Marketing reach by promoting new products and services.
- Market analytics by using phone numbers as identifiers.
- Customer engagement and emergency contact.
That being said, manually extracting phone numbers from web pages can be tedious. This is where scraping phone numbers comes in handy!
With the modern capabilities of HTML parsing and data extraction techniques, we can easily scrape phone numbers from complex HTML pages. Before we jump into the details of web scraping phone numbers, let's look at the tools we'll use.
Setup
In this scraping phone numbers guide, we'll scrape phone numbers from this search page on Yellowpages:
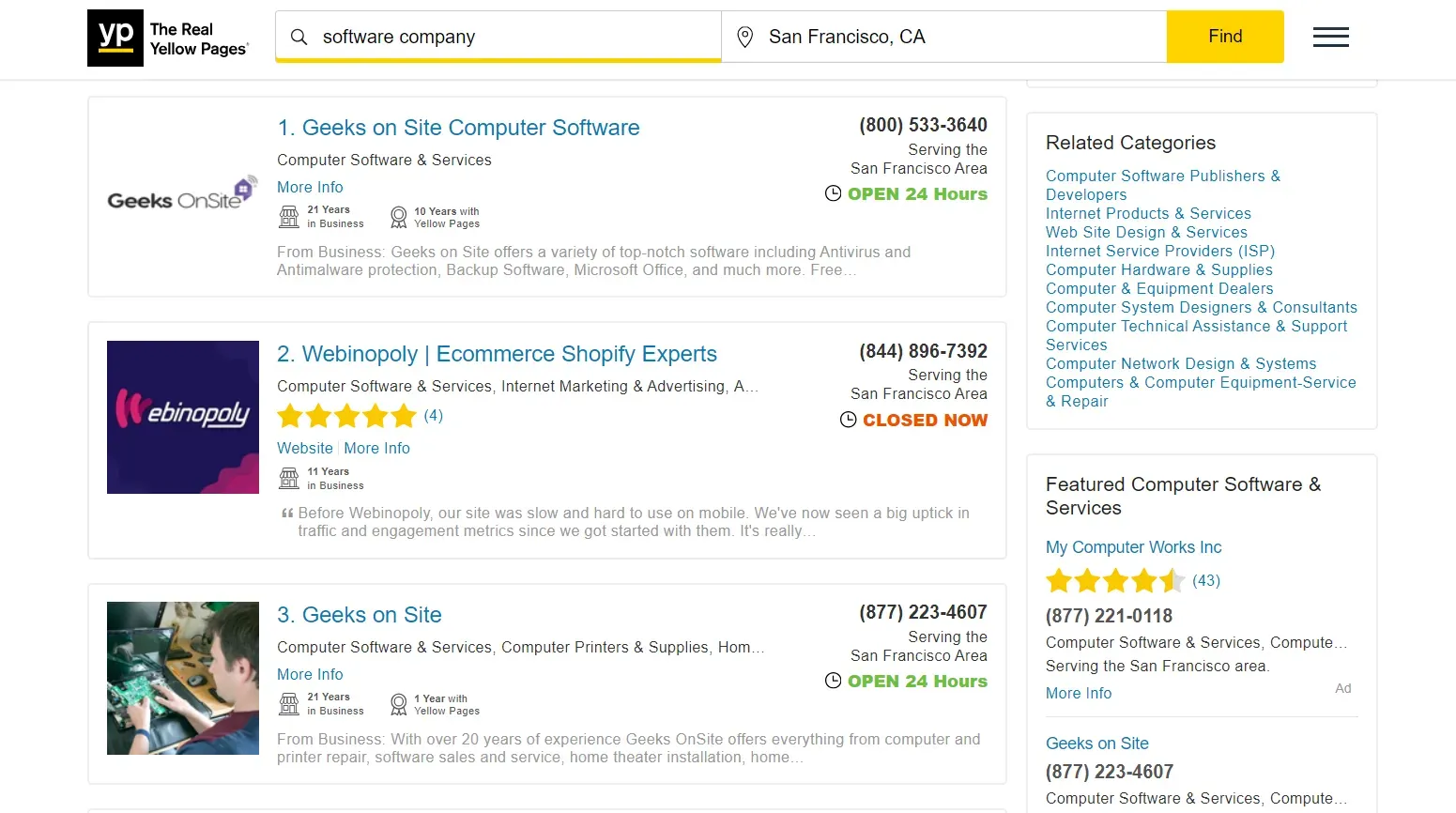
We have previously covered scraping data from Yellowpages, including scraping phone numbers. Today, we'll use it to scrape phone numbers.
We'll also explain some web scraping concepts, including running headless browsers, sending requests and HTML parsing. For that, we'll use multiple Python packages:
- httpx: for sending HTTP requests.
- beautifulsoup4: for parsing HTML using CSS selectors.
- plawyright: for scraping javascript-powered websites using headless browsers.
These libraries can be installed using pip terminal command:
pip install httpx playwright bs4How to Discover and Crawl Web Pages
Web scraping is the process of extracting data from HTML using parsing tools. Therefore, we need to get the HTML content by sending requests. This can be done using two different approaches:
- Using Headless browsers
Headless browsers are real web browsers without visible GUI which can be scripted and controlled through programming. Most commonly headless browsers are used for scraping of dynamic web pages. - Using HTTP clients
HTTP clients are libraries that implement HTTP protocol which allows to retrieve HTML or JSON web pages.
🧙 Want to scrape dynamic pages but worried about running headless browsers? Try out the ScrapFly render_js feature and let ScrapFly run headless browsers in the cloud for you!
Although headless browsers aren't required in our case, we'll use it with our target website to explain the concept. It has multiple search results and each result has its own page.
We'll use Web Scraping with Playwright and Python and CSS selectors to get all page links in the search result:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
def scrape_yellowpages_search(url):
# Intitialize a playwright instance
with sync_playwright() as playwight:
# Launch a chrome headless browser
browser = playwight.chromium.launch(headless=True)
# Create a new page inside the browser
page = browser.new_page()
# Go to the page URL
page.goto(url)
# Get the page HTML content
page_content = page.content()
# Create a BeautifulSoup object
soup = BeautifulSoup(page_content, "html.parser")
links = []
# Loop through all result boxes in the search result
for link_box in soup.select("div.info-section.info-primary"):
# Extract the page link
link = "https://www.yellowpages.com" + link_box.select_one("a").attrs["href"]
links.append(link)
return links
links = scrape_yellowpages_search("https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco%2C+CA")
print(links)Expected Output
[
"https://www.yellowpages.com/nationwide/mip/geeks-on-site-computer-software-481555550?lid=1002155016513",
"https://www.yellowpages.com/nationwide/mip/geeks-on-site-computer-software-481555550?lid=1002155016513",
"https://www.yellowpages.com/nationwide/mip/webinopoly-ecommerce-shopify-experts-572587975?lid=1002146350495",
"https://www.yellowpages.com/nationwide/mip/my-computer-works-inc-533468437?lid=1002102412573",
"https://www.yellowpages.com/coral-gables-fl/mip/geeks-on-site-531845374?lid=1002149559489",
"https://www.yellowpages.com/san-francisco-ca/mip/playfirst-inc-464839866",
"https://www.yellowpages.com/san-francisco-ca/mip/piston-cloud-computing-inc-475559034",
"https://www.yellowpages.com/san-francisco-ca/mip/ecairn-inc-489225124",
"https://www.yellowpages.com/san-francisco-ca/mip/zynga-31058290",
"https://www.yellowpages.com/san-francisco-ca/mip/revel-systems-ipad-pos-475970888",
"https://www.yellowpages.com/san-francisco-ca/mip/forecross-corp-12862715",
"https://www.yellowpages.com/san-francisco-ca/mip/appstem-473692217",
"https://www.yellowpages.com/san-francisco-ca/mip/sliderocket-13664752",
"https://www.yellowpages.com/san-francisco-ca/mip/wiser-503952773",
"https://www.yellowpages.com/san-francisco-ca/mip/cider-553283867",
"https://www.yellowpages.com/san-francisco-ca/mip/cygent-inc-460168183",
"https://www.yellowpages.com/san-francisco-ca/mip/lecco-technology-inc-467326369",
"https://www.yellowpages.com/san-francisco-ca/mip/lightbend-inc-473002030",
"https://www.yellowpages.com/san-francisco-ca/mip/tapjoy-460697613",
"https://www.yellowpages.com/san-francisco-ca/mip/uncountable-inc-572984550",
"https://www.yellowpages.com/san-francisco-ca/mip/splunk-inc-4420913",
"https://www.yellowpages.com/san-francisco-ca/mip/centaur-multimedia-458738778",
"https://www.yellowpages.com/san-francisco-ca/mip/cloud-admin-solution-543052113",
"https://www.yellowpages.com/san-francisco-ca/mip/vfix-onsite-computer-service-525720353",
"https://www.yellowpages.com/san-francisco-ca/mip/the-com-10739601",
"https://www.yellowpages.com/san-francisco-ca/mip/kylie-ai-538621154",
"https://www.yellowpages.com/san-francisco-ca/mip/trash-warrior-562133707",
"https://www.yellowpages.com/san-francisco-ca/mip/kyte-455118689",
"https://www.yellowpages.com/san-francisco-ca/mip/techdaddy-496310685",
"https://www.yellowpages.com/san-francisco-ca/mip/dsidex-523480897",
"https://www.yellowpages.com/san-francisco-ca/mip/rt-dynamic-550755997",
]Here, we initialize a playwright instance and launch a new headless browser. Next, we send a request to the search page URL and turn the page HTML into a BeautifulSoup object. Finally, using our HTML soup we extract the business page links from each page.
Now that we have all the page links, we'll use them to scrape phone numbers from each page.
How to Scrape Phone Numbers From Websites
We can scrape phone numbers using selectors like in the previous section. However, web pages often contain multiple phone numbers and it can be challenging to create selectors for each number in the HTML. Therefore, it's easier to scrape phone numbers using regex.
Regex is a special pattern recognition language for text. It's primarily used to validate if the string follows a known pattern but we can also use it to find patterns in text. For example, the following regex pattern is used to capture phone numbers:
[+]*[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s\.\0-9]*(?=[^0-9])Let's break down this regex pattern:
- *`[+]
**: Matches the+` sign character with any number of occurrences. [(]{0,1}: Matches an opening parenthesis(character with zero or one occurrence.[0-9]{1,4}: Matches any digit from 0 to 9 with one to four consecutive digits.[)]{0,1}: Matches a closing parenthesis)character with zero or one occurrence.- *`[-\s.\0-9]`**: Matches any characters or numbers in the list with any number of occurrences.
(?=[^0-9]): Prevent the following characters from being detected as part of the phone number.
🙋 The above regex pattern can detect the format of phone numbers on our target website. However, it may need adjustments to capture different phone number formats
Now let's scrape numbers by applying the above regex pattern to our target website. We'll iterate over the links we got earlier and send a request to each link to get the page HTML. Then, we'll search for phone numbers in each HTML page:
from playwright.sync_api import sync_playwright
import httpx
from bs4 import BeautifulSoup
import re
import json
# Scrape links function we created earlier
def scrape_yellowpages_search(url):
with sync_playwright() as playwight:
browser = playwight.chromium.launch(headless=True)
page = browser.new_page()
page.goto(url)
page_content = page.content()
soup = BeautifulSoup(page_content, "html.parser")
links = []
for link_box in soup.select("div.info-section.info-primary"):
link = "https://www.yellowpages.com" + link_box.select_one("a").attrs["href"]
links.append(link)
return links
def scrape_phone_numbers(links: list):
# Empty object to save the data into
data = {}
for link in links:
page_response = httpx.get(url=link)
# Get a BeautifulSoup for each page HTML
soup = BeautifulSoup(page_response.text, "html.parser")
# Scrape the company name
company_name = parse_business(soup)
# Scrape phone numbers in the HTML
phone_numbers = parse_phone_numbers(soup)
# Check if we go phone numbers and company name doesn't exist in the data object
if len(phone_numbers) > 0 and company_name not in data:
data[company_name] = phone_numbers
return data
def parse_business(soup):
company_name = soup.select_one("h1.dockable.business-name").text
return company_name
def parse_phone_numbers(soup):
# Regex pattern used to search for numbers
phone_number_pattern = r"[+]*[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s\.\0-9]*(?=[^0-9])"
# Get all text in the HTML page
all_text = soup.get_text()
phone_numbers = []
# Loop through all phone numbers found the text
for phone_number in re.findall(phone_number_pattern, all_text):
# Check if this is a valid phone number by checking the length
if len(phone_number.strip()) > 12:
phone_numbers.append(phone_number)
return phone_numbers
# Get all page links in the main search page
links = scrape_yellowpages_search("https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco%2C+CA")
# Scrape phone numbers data from all links
data = scrape_phone_numbers(links)
# Print the result in JSON format
print(json.dumps(data, indent=4))Here, we use the scrape_pages function to iterate over all links to get a BeautifulSoup object for each page. Then, we use the scrape_business function to get the company name from each company page. Next, using the regex pattern, we use the scrape_phone_numbers to find all phone numbers on the page. Finally, we append all phone numbers on each page to the data object.
Here is the phone number scraping result:
Output
{
"Geeks on Site Computer Software": [
"(800) 533-3640"
],
"Webinopoly | Ecommerce Shopify Experts": [
"(844) 896-7392"
],
"Geeks on Site": [
"(877) 223-4607"
],
"My Computer Works Inc": [
"(877) 221-0118",
"1-877-301-0214 "
],
"Playfirst Inc": [
"(415) 391-4020",
"(415) 362-0133",
"(415) 738-4600"
],
"Piston Cloud Computing, Inc.": [
"(650) 242-5683"
],
"Ecairn Inc": [
"(650) 388-8962"
],
"Zynga": [
"(800) 762-2530",
"(415) 252-9555"
],
"Revel Systems iPad POS": [
"(415) 754-5355",
"(855) 738-3555"
],
"Forecross Corp": [
"(415) 543-1515"
],
"Appstem": [
"(415) 956-7400"
],
"Sliderocket": [
"(415) 436-9134",
"(415) 512-9135"
],
"Wiser": [
"(415) 326-7603"
],
"Cider": [
"(415) 741-5504"
],
"Cygent Inc.": [
"(415) 913-3000",
"(415) 913-3001"
],
"Lecco Technology Inc": [
"(415) 901-8228"
],
"Lightbend, Inc.": [
"(877) 989-7372"
],
"Tapjoy": [
"(415) 766-6905",
"(510) 257-5613",
"(415) 296-9007",
"(415) 989-1215",
"(415) 766-6900"
],
"Uncountable Inc.": [
"(650) 208-5949"
],
"Splunk Inc": [
"(415) 848-8400",
"(415) 615-0396",
"(415) 568-4200",
"(415) 738-5456",
"(866) 438-7758",
"(888) 249-3263"
],
"Centaur Multimedia": [
"(415) 775-3020",
"(888) 775-3020",
"(800) 775-3008"
],
"Cloud Admin Solution": [
"(415) 940-0020"
],
"VFIX Onsite Computer Service": [
"(855) 955-8349"
],
"The.com": [
"(303) 536-1077",
"(386) 453-6280"
],
"Kylie.ai": [
"(415) 463-7870",
"1-415-463-7870."
],
"Trash Warrior": [
"(415) 340-7182",
"(415) 304-8171"
],
"Kyte": [
"(415) 340-4850",
"(415) 480-6800"
],
"TechDaddy": [
"(415) 937-0622"
],
"DSIDEX": [
"(415) 854-5671"
],
"RT Dynamic": [
"(310) 492-5564"
]
}We successfully scraped all phone numbers on all pages. However, it may be harder to scrape phone numbers due to the phone number obfuscation challenges. Let's take a look at some examples!
Phone Number Scraping Challenges
Many websites use obfuscation techniques to prevent bots from accessing phone numbers. This often happens by rendering phone numbers using JavaScript. And since bots don't support JavaScript, this prevents bots from accessing phone numbers while allowing regular web browsers. Some of these challenges are:
- Concatenating phone numbers.
Which requires running JavaScript code to write the full email in the HTML:html<script>document.write('<a href="tel:'+'+'+'1'+'-'+'2'+'3'+'4'+'-'+'5'+'6'+'7'+'-'+'8'+'9'+'1'+'0''">Phone Number</a>');</script> - Encoding phone numbers.
Which requires enabling JavaScript to decode phone numbers in the HTML:html<a class="phone" href="KzEtMjM0LTU2Ny04OTEw" rel="nofollow, noindex">Phone Number</a> <script src="js/decode_number.js" defer></script> - Storing phone numbers in images.
Which requires enabling JavaScript or downloading images:html<img src="images/phone_number.jpg" width="216" height="18" alt="phone number"> - Revealing phone numbers using buttons.
Which requires custom JavaScript code to click buttonshtml<li data-phone="phone-number"><strong>Phone Number:</strong> <a href="#">Click to reveal</a></li>
We can avoid these challenges by allowing JavaScript. However, running headless browsers is slow and consumes a lot of resources. Let's take a better phone number scraping solution!
Scrape Phone Numbers With ScrapFly
Scraping phone numbers is surprisingly straight forward but can be challenging when scaling up. This is where Scrapfly can help out!

For example, by using the ScrapFly render_js feature. We can easily enable JavaScript and scrape phone numbers without facing obfuscation challenges:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
import json
from bs4 import BeautifulSoup
import re
scrapfly = ScrapflyClient(key="Your API key")
def scrape_business(soup):
company_name = soup.select_one("h1.dockable.business-name").text
return company_name
def scrape_phone_numbers(soup):
phone_number_pattern = r"[+]*[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s\.\0-9]*(?=[^0-9])"
all_text = soup.get_text()
phone_numbers = []
for phone_number in re.findall(phone_number_pattern, all_text):
if len(phone_number.strip()) > 12:
phone_numbers.append(phone_number)
return phone_numbers
def scrape_pages(links: list):
data = {}
for link in links:
api_response: ScrapeApiResponse = scrapfly.scrape(
scrape_config=ScrapeConfig(
url=link,
# Activate the render_js feature to dynamic JavaScript content
render_js=True,
# Activate the anti scraping protection bypass to scrape without getting blocked
asp=True,
# Set the proxies location to the US to avoid Yellowpages regional blocking
country="US",
)
)
soup = BeautifulSoup(api_response.scrape_result["content"], "html.parser")
company_name = scrape_business(soup)
phone_numbers = scrape_phone_numbers(soup)
if len(phone_numbers) > 0 and company_name not in data:
data[company_name] = phone_numbers
return data
data = scrape_pages(
["https://www.yellowpages.com/san-francisco-ca/mip/splunk-inc-4420913"]
)
# Print the result in JSON format
print(json.dumps(data, indent=4))
# {
# "Splunk Inc": [
# "(415) 848-8400",
# "(415) 615-0396",
# "(415) 568-4200",
# "(415) 738-5456",
# "(866) 438-7758",
# "(888) 249-3263",
# "(415) 848-8400"
# ]
# }FAQ
What's the best regex pattern for scraping phone numbers from different countries?
Use country-specific patterns or a universal pattern like [+]*[(]{0,1}[0-9]{1,4}[)]{0,1}[-\s\.\0-9]*(?=[^0-9]). For specific countries, create targeted patterns (e.g., US: \d{3}-\d{3}-\d{4}, UK: \d{4}\s\d{3}\s\d{3}).
How do I handle phone number obfuscation techniques like JavaScript encoding?
Use headless browsers (Playwright, Selenium) to execute JavaScript and reveal obfuscated numbers. Alternatively, reverse engineer the JavaScript to understand the encoding/decoding process and implement it in your scraper.
Can I scrape phone numbers from social media platforms like LinkedIn or Facebook?
Yes, but be cautious about terms of service and privacy laws. Use headless browsers for JavaScript-heavy platforms, implement realistic delays, and respect rate limits. Consider using official APIs when available.
What's the difference between scraping phone numbers with regex vs CSS selectors?
Regex is better for finding phone numbers in text content, while CSS selectors are better for structured HTML elements. Use regex for general text scraping and CSS selectors for specific HTML elements containing phone numbers.
How do I validate and clean scraped phone numbers?
Remove formatting characters, validate length and format, check for duplicates, and use phone number validation libraries like phonenumbers in Python. Consider normalizing numbers to international format.
Is it legal to scrape phone numbers?
It's perfectly legal to scrape phone numbers. However, using the collected phone number data for further projects can get complicated, especially in the European Union. Consult a lawyer before using scraped phone numbers for commercial use.
Is it possible to scrape phone numbers without JavaScript?
Yes, however for that some website reverse engineering skills are often needed to find out how Javascript is used for phone number storage. For that see Browser Developer Tools introduction.
What are the different ways to scrape phone numbers?
Scraping phone numbers is all about crawling HTML page data and finding the phone numbers in HTML. In this article we used regex but often Parsing HTML with Xpath and CSS Selectors can be a better choice.
How do I handle phone numbers in different international formats?
International phone numbers vary widely in format (e.g., +1-555-1234, 0044 20 7946 0958). Use the Python phonenumbers library to parse and normalize numbers into a standard E.164 format. This ensures consistent data regardless of how numbers appear on the page.
Scrape Phone Numbers Summary
This article explained how to crawl web pages to scrape phone numbers. Which works by parsing the HTML to extract phone numbers using selectors or regular expressions.
We also went through the most common challenges used to block phone number scraping by rendering phone numbers using JavaScript. In a nutshell, these challenges include:
- Encoding phone numbers.
- Concatenating phone numbers using JavaScript.
- Storing phone numbers in images.
- Revealing phone numbers by clicking buttons.
Phone number scraping can be a great way to collect powerful leads and it can be done for free using Python given the right preparation and knowledge.


