

Have you wondered how businesses seem to have an endless list of email contacts? Email scraping can do that!
In this article, we'll explore how to scrape emails from websites with Python. We'll also cover the most common email scraping challenges and how to overcome them. Let's dig in!
Key Takeaways
Learn to scrape email addresses from websites using Python with regex patterns, HTML parsing, and obfuscation handling techniques for contact data extraction.
- Extract emails from mailto links and plain text using regex patterns and HTML parsing
- Handle email obfuscation techniques including JavaScript encoding and HTML entities
- Use BeautifulSoup and httpx for parsing HTML and extracting email addresses
- Implement regex patterns to match various email formats including modern TLDs
- Add error handling and validation to ensure robust email scraping
- Validate and clean extracted email addresses for data quality assurance
How Websites Store Emails in HTML?
The most common way of storing emails in HTML is using mailto links. Which is a clickable link that opens the default email-sending client and adds the recipient's email automatically. These email links can be found in the HTML under a tags:
<a href="mailto:email@example.com">Send Email</a>Websites can also store emails in HTML as plain text:
<p>Email: email@example.com</p>It can be straightforward to scrape emails from the above HTML sources. However, some websites use obfuscation techniques to prevent scrapers from accessing emails as a fear of email spam.
We'll cover these obfuscation techniques in a dedicated section. But before that, let's take a look at the tools we'll use in this tutorial.
Setup
In this email scraping guide, we'll use this page on Yellowpages as our scraping target:
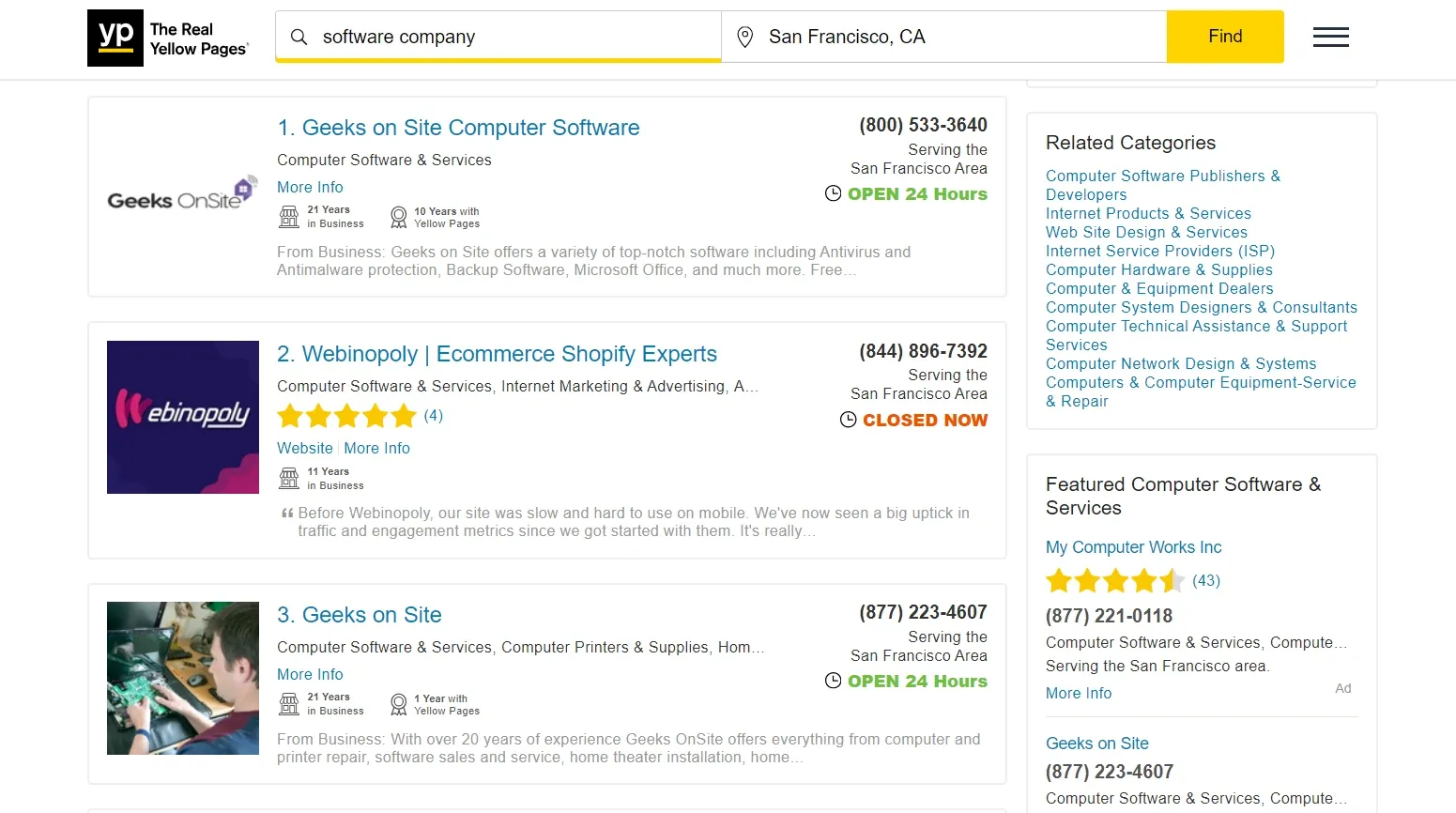
We have covered scraping Yellowpages in detail before. In this guide, we'll use it to scrape emails.

To scrape emails, we'll use httpx for sending requests and BeautifulSoup for HTML parsing. These libraries can be installed using the pip command:
pip install httpx bs4How to Scrape a Website For Email Addresses?
To scrape emails from websites we really need to focus on HTML parsing techniques. Since all emails follow a predictable structure like something@something.something the easiest way to find emails in an HTML page is to use regex.
Note: While regex is convenient for email extraction, it has some limitations. It may occasionally match strings that look like emails but aren't (false positives like image@2x.png), or miss unconventional but valid email formats. For production use, combine regex matching with validation as we'll demonstrate later in this guide.
These regex patterns can match against the full email structure or against a specific criteria like mailto links:
# Matching against the email structure:
email_pattern = re.compile(r'([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})')
email_matches = re.findall(email_pattern, page_html)
# Matching against emails links with mailto: text
email_matches = soup.findAll("a", attrs={"href": re.compile("^mailto:")})The first method is suitable for scraping emails when they are found as plain text. However, it can be time-consuming as the script will search through all the HTML.
Now let's apply email regex matching to our target website. It has multiple company pages, each page stores emails as links under a tags with a mailto text:
We'll use httpx and BeautifulSoup to get all page links. Then, we'll scrape emails from all pages using each page link:
import httpx
from bs4 import BeautifulSoup
import re
import json
def scrape_yellowpages_search(main_url: str):
links = []
response = httpx.get(url=main_url)
soup = BeautifulSoup(response.text, "html.parser")
# Loop through all page boxes in the search result page
for link_box in soup.select("div.info-section.info-primary"):
# Extract the link of each page and add it to the main website URL
link = "https://www.yellowpages.com" + link_box.select_one("a").attrs["href"]
links.append(link)
return links
def scrape_emails(links: list):
emails = {}
for link in links:
try:
# Send a GET request to each company page with timeout
page_response = httpx.get(url=link, timeout=10.0)
page_response.raise_for_status()
soup = BeautifulSoup(page_response.text, "html.parser")
# Extract the company name from the HTML with null check
company_element = soup.select_one("h1.dockable.business-name")
if not company_element:
continue
company_name = company_element.text
# Find all a tags with href that contain (mailto:) text
for email_link in soup.findAll("a", attrs={"href": re.compile("^mailto:")}):
# Extract the email address from the href attribute
email = email_link.get("href").replace("mailto:", "")
# Check if the company name exists in the emails dictionary and add it if not
if company_name not in emails:
emails[company_name] = []
emails[company_name].append(email)
except httpx.HTTPError as e:
print(f"Error scraping {link}: {e}")
continue
return emails
# Scrape all links and save it to a list
links = scrape_yellowpages_search("https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco%2C+CA")
# Scrape all emails from each page link
emails = scrape_emails(links)
# Print the result in JSON format
print(json.dumps(emails, indent=4))from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
import json
scrapfly = ScrapflyClient(key="Your API key")
def scrape_yellowpages_search(main_url: str):
links = []
api_response: ScrapeApiResponse = scrapfly.scrape(
scrape_config=ScrapeConfig(
url=main_url
)
)
# Use the built in selector in the api_response
selector = api_response.selector
# Loop through all page boxes in the search result page
for link_box in selector.css("div.info-section.info-primary"):
link = "https://www.yellowpages.com" + link_box.css("a").attrib["href"]
links.append(link)
return links
def scrape_emails(links: list):
emails = {}
for link in links:
try:
# Scrape each company page
api_response: ScrapeApiResponse = scrapfly.scrape(scrape_config=ScrapeConfig(url=link))
selector = api_response.selector
# Extract the company name from the HTML with null check
company_name = selector.css("h1.dockable.business-name::text").get()
if not company_name:
continue
# Find all a tags with href that contain (mailto:) text
email_links = selector.css('a[href^="mailto:"]')
for email_link in email_links:
email = email_link.attrib['href'].replace("mailto:", "")
if company_name not in emails:
emails[company_name] = []
emails[company_name].append(email)
except Exception as e:
print(f"Error scraping {link}: {e}")
continue
return emails
# Scrape all links and save it to a list
links = scrape_yellowpages_search("https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco%2C+CA")
# Scrape all emails from each page link
emails = scrape_emails(links)
# Print the result in JSON format
print(json.dumps(emails, indent=4))The above code is split into two main functions. The scrape_yellowpages_search is used to scrape all page links in the main search page and append them to the links array.
Next, we use scrape_emails to send a request to each page link and get the page HTML. Then, we use the findAll method to get all a tags and use the regex compile method to only select a tags with the mailto text. Finally, we append all emails on the page to each company_name variable and print the final emails dictionary.
Here are the emails we scraped:
Output
{
"Webinopoly | Ecommerce Shopify Experts": [
"hello@webinopoly.com"
],
"My Computer Works Inc": [
"larrybuckmiller1@google.com"
],
"Geeks on Site": [
"vborja@ottepolo.com"
],
"Playfirst Inc": [
"mmeunier@madsenstaffing.com"
],
"Piston Cloud Computing, Inc.": [
"info@pistoncloud.com"
],
"Ecairn Inc": [
"conversation+sale@ecairn.com"
],
"Revel Systems iPad POS": [
"info@revelsystems.com"
],
"Forecross Corp": [
"business-development@forecross.com"
],
"Appstem": [
"info@appstem.com"
],
"Sliderocket": [
"sliderocket@clearslide.com"
],
"Wiser": [
"info@wiser.com"
],
"Cider": [
"ilya.lipovich@getcider.com",
"info@getcider.com"
],
"Cygent Inc.": [
"hostmaster@cygent.com"
],
"Lecco Technology Inc": [
"kinchan@rll.com"
],
"Tapjoy": [
"jdrobick@ebay.com",
"accountpayable@tapjoy.com",
"bbb-hotline@tapjoy.com",
"brett.nicholson@tapjoy.com",
"dan.bellig@tapjoy.com",
"escalations@tapjoy.com",
"jinah.haytko@tapjoy.com",
"sherry.zarabi@tapjoy.com",
"info@tapjoy.com"
],
"Splunk Inc": [
"parvesh.jain@splunk.com",
"DMCA@splunk.com",
"splunkbr@splunk.com"
],
"Centaur Multimedia": [
"sales@1focus-medical-billing.com"
],
"Cloud Admin Solution": [
"benny@cloudadminsolution.com"
],
"VFIX Onsite Computer Service": [
"nikan@myvfix.com"
],
"Kylie.ai": [
"admin@kylie.ai"
],
"Trash Warrior": [
"support@trashwarrior.com",
"raymond@trashwarrior.com"
],
"TechDaddy": [
"info@techdaddy.net"
],
"DSIDEX": [
"office@dsidex.com",
"sales@dsidex.com",
"info@dsidex.com"
],
"RT Dynamic": [
"katy@rtdynamic.com"
]
}So to scrape emails from a website we:
- Retrieve the HTML pages using
httpx - Parse the HTML using
BeautifulSoup - Found all emails using a simple regex pattern
^mailto:
Our email scraper got all the emails it could find in the HTML for every yellowpages business page.
However, due to the email obfuscation techniques, scraping emails isn't always this easy. Let's take a look at some of challenges when it comes to creating a perfect free email scraper tool.
How to Scrape Emails With Obfuscation Challenges?
While the above approach works well for straightforward HTML, many websites actively try to prevent email scraping to avoid spam and protect user privacy. According to various web scraping studies, approximately 30-40% of websites with contact information use some form of email obfuscation. This means that as you scale your email scraping operations, you'll inevitably encounter these protection mechanisms.
The goal of email obfuscation challenges is to prevent automated tools like web scrapers from finding emails. The implementation of most challenges is very similar - render emails into HTML using JavaScript. This works against bots as most bots don't support JavaScript as that requires a real web browser automation which is much more expensive.
There are different types of obfuscation challenges. Here's a list of the most popular ones:
-
Encoding email links. Which requires clicking buttons to decode the link and reveal the real email address:
html<a href="mailto:%65%6d%61%69%6c%40%65%78%61%6d%70%6c%65%2e%63%6f%6d">email</a> -
Concatenating email addresses. Which requires running JavaScript code to write the full email in the HTML:
html<script>document.write('<a href="mailto:'+'e'+'m'+'a'+'i'+'l'+'@'+'e'+'x'+'a'+'m'+'p'+'l'+'e'+'.'+'c'+'o'+'m'+'">email</a>');</script> -
Encrypting email addresses. which requires enabling JavaScript to decrypt email tokens or reverse engineering and replicating the decryption algorithm:
html<a class="email" href="7179757d7854716c75796478713a777b79" rel="nofollow, noindex">email</a> <script src="js/decrypt_email.js" defer></script> -
Storing emails in images. Which requires image downloading and OCR to extract the email:
html<img src="images/email.jpg" width="216" height="18" alt="email address"> -
CAPTCHA challenges. Some websites require bypassing captcha challenges to reveal emails.
For example, let's take a look at this localized Yellowpages website for Egypt :
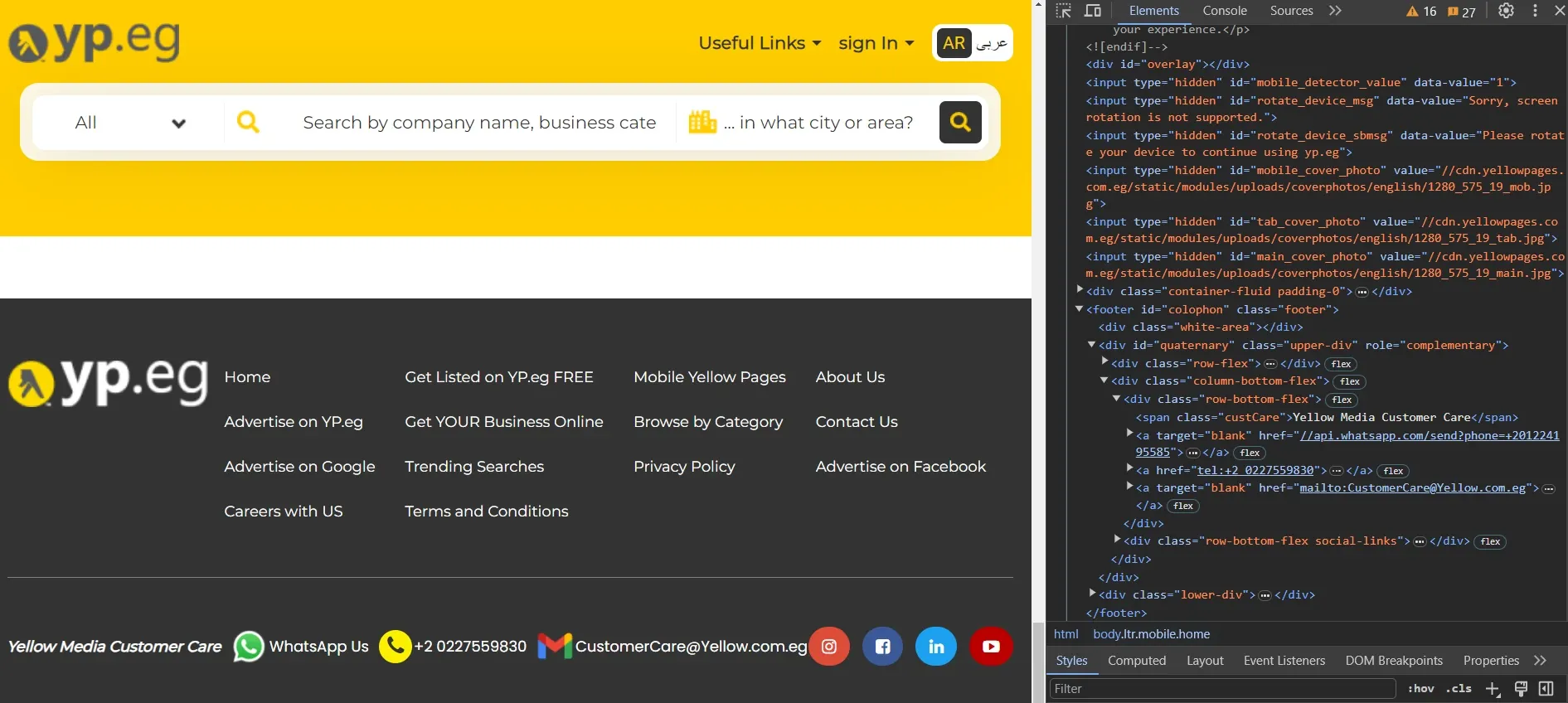
We can see the email address on the web page and the HTML code. Let's try to scrape it:
import httpx
from bs4 import BeautifulSoup
url = "https://yellowpages.com.eg/en"
r = httpx.get(url)
soup = BeautifulSoup(r.text, "html.parser")
email = soup.select("div.row-bottom-flex")[0].select("a")[2].select_one("span")
print(email)This website uses Cloudflare email obfuscation which basically uses javaScript to decode email tokens on page load. Since we sent a request with a client that doesn't run JavaScript, we can only see the encoded email token:
<span class="__cf_email__" data-cfemail="a9eadcdaddc6c4ccdbeac8dbcce9f0ccc5c5c6de87cac6c487ccce">[email protected]</span>To de-obfuscate Cloudflare emails, we can use a simple Python algorithm:
def DecodeEmail(encodedString):
r = int(encodedString[:2],16)
email = ''.join([chr(int(encodedString[i:i+2], 16) ^ r) for i in range(2, len(encodedString), 2)])
return email
print (DecodeEmail('a9eadcdaddc6c4ccdbeac8dbcce9f0ccc5c5c6de87cac6c487ccce'))
# CustomerCare@Yellow.com.egEmail decoding and deobfuscation is not always this easy. Many custom methods can be surprisingly complex to reverse engineer so sometimes running a real web browser using a a headless browser for web scraping is a more robust solution.
That being said, running headless browsers really slow and consume a lot of resources. Let's take a look at a better solution with Scrapfly's cloud browsers!
Validating and Cleaning Scraped Emails
After scraping emails from websites, it's important to validate and clean the data to ensure quality. Not all strings that match email patterns are valid emails - they could be false positives, malformed addresses, or non-email file extensions.
Here's a practical email validation function that filters out common issues:
import re
def validate_email(email: str) -> bool:
"""Validate email format and filter common false positives"""
# Remove whitespace
email = email.strip()
# Basic format check
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
if not re.match(pattern, email):
return False
# Filter out common false positives (file extensions mistaken as emails)
invalid_extensions = ['.png', '.jpg', '.jpeg', '.gif', '.css', '.js', '.svg', '.pdf']
if any(email.lower().endswith(ext) for ext in invalid_extensions):
return False
# Check for suspicious patterns
if email.count('@') != 1 or email.count('..') > 0:
return False
return True
def clean_emails(emails_dict: dict) -> dict:
"""Remove duplicates and invalid emails from scraped data"""
cleaned = {}
for company, email_list in emails_dict.items():
# Validate and remove duplicates
valid_emails = list(set([
email for email in email_list
if validate_email(email)
]))
if valid_emails: # Only add if there are valid emails
cleaned[company] = valid_emails
return cleaned
# Example usage with our scraped emails
emails = scrape_emails(links)
cleaned_emails = clean_emails(emails)
print(json.dumps(cleaned_emails, indent=4))This validation approach helps ensure that your scraped email data is clean and usable for further processing or analysis.
Scrape Emails with ScrapFly
Scraping emails is not particularly challenging but scaling up operations like this can quickly introduce new unforseen challenges like blocking and this is where Scrapfly can be of assistance.

For example, by using the ScrapFly render_js feature with the previous example. We can easily enable JavaScript and scrape emails without facing obfuscation challenges:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="YOUR SCRAPFLY KEY")
api_response: ScrapeApiResponse = scrapfly.scrape(
ScrapeConfig(
url="https://www.yellowpages.com/mill-valley-ca/mip/buckeye-roadhouse-4193022",
# Activate the render_js feature to scrape dynamically loaded content
render_js=True,
# Bypass anti scraping protections
asp=True,
# Set any geographical country
country="US",
)
)
email = api_response.selector.css(".email-business::attr(href)").get()
print(email.split('mailto:')[-1])
# buckeyeroadhouse@comcast.netFAQ
Is email scraping legal?
It's perfectly legal to scrape emails for non-commercial use as long as you respect the website's terms of service. However, in some regions like the European Union, email scraping may violate the protection of the individuals' personal data - known as the GDPR.
What's the best regex pattern for email scraping?
For finding emails in text: [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,} (without anchors to match emails within text). For validating email format: ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ (with anchors). For HTML mailto links: "mailto:.+?" which captures addresses that implement the mailto: protocol. Use re.compile() for better performance when processing multiple pages.
How do I validate and clean scraped email addresses?
Use email validation libraries (like email-validator in Python), check for common typos, remove duplicates, and verify email format compliance. Consider using email verification services for production use.
How do I handle email obfuscation and JavaScript-encoded emails?
Use headless browsers (Selenium, Playwright) to execute JavaScript and reveal obfuscated emails. For Cloudflare obfuscation, use decoding algorithms. For complex obfuscation, consider OCR for image-based emails or reverse-engineer the decryption logic.
How do I avoid getting blocked when scraping emails at scale?
Use rotating proxies, implement request delays (1-3 seconds), rotate user-agents, respect robots.txt, and consider using anti-bot bypass services. Distribute requests across multiple IP addresses and time periods.
Summary
In this article, we created an email scraping tool using nothing but Python. To start, we used httpx to crawl pages that might contain email addresses. Then, we used HTML parsing tool beautifulsoup4 to find emails using CSS selectors and email regex patterns.
We also explained the most common obfuscation challenges that's used to block email scraping by rendering emails using JavaScript. In a nutshell, these challenges include:
- Encoding email links.
- Concatenating emails using JavaScript.
- Encrypting emails.
- Storing emails in images.
- CAPTCHA challenges.


