

In this tutorial, we'll look at how to scrape from Amazon - the biggest e-commerce website in the world!
Amazon contains millions of products and operates in many different countries making it a great target for public market analytics data.
To scrape Amazon product data, prices and reviews, we'll be using Python with a few community packages and common Amazon web scraping idioms. So, let's dive in!
Key Takeaways
Learn to scrape Amazon product data and reviews using Python with httpx and parsel libraries, handling dynamic content and avoiding blocking through proper headers and rate limiting.
- Use Amazon's search API endpoints to bypass JavaScript rendering for faster data collection
- Implement concurrent scraping with asyncio to handle multiple product pages simultaneously
- Parse dynamic JSON data embedded in HTML using XPath selectors for product details and pricing
- Handle Amazon's anti-bot measures through realistic headers, user agents, and request spacing
- Extract structured product data including titles, prices, ratings, and review counts from search results
- Build robust error handling for rate limiting and temporary blocking scenarios
Why Scrape Amazon.com?
Amazon contains loads of valuable e-commerce data: product details, prices and reviews. It's a leading e-commerce platform in many regions around the world. This makes Amazon's public data ideal for market analytics, business intelligence and many niches of data science.
Amazon is often used by companies to track the performance of their products sold by 3rd party resellers. So, needless to say, there are almost countless ways to make use of this public data! For more on scraping use cases see our extensive web scraping use case article
Project Setup
In this tutorial we'll be using Python with Scrapfly's Python SDK.
It can be easily installed via the below pip command:
$ pip install scrapfly-sdkThis guide heavily relies on HTML parsing using CSS selectors. If you aren't familiar, please refer to our dedicated guide below 👇
Finding Amazon Products
There are several ways of finding products on Amazon though, the most flexible and powerful one is amazon's search system.
We can see when we type our search term amazon redirects us to search page https://www.amazon.com/s?k=<search query> which we can use in our scraper.
When scraping Amazon search pages, we want to crawl over pagination pages to extract all the product preview data related to the used keyword. For this, we'll use the crawling approach illustrated below:

Let's translate the above crawling mechanism into Python scraping code:
Here, in our search function we collect the first results page of a given query. Then, we find total pages this query contains and scrape the rest of the pages concurrently using asynchronous web scraping. This is a common pagination scraping idiom for when we can find total amount of pages which allows us to take advantage of concurrent web scraping. Note: This scraper uses both CSS and XPath selectors for parsing - XPath offers powerful tree navigation for complex HTML patterns.
We are using Parsel's CSS and XPath selectors to select product preview containers and iterate through each one of them:
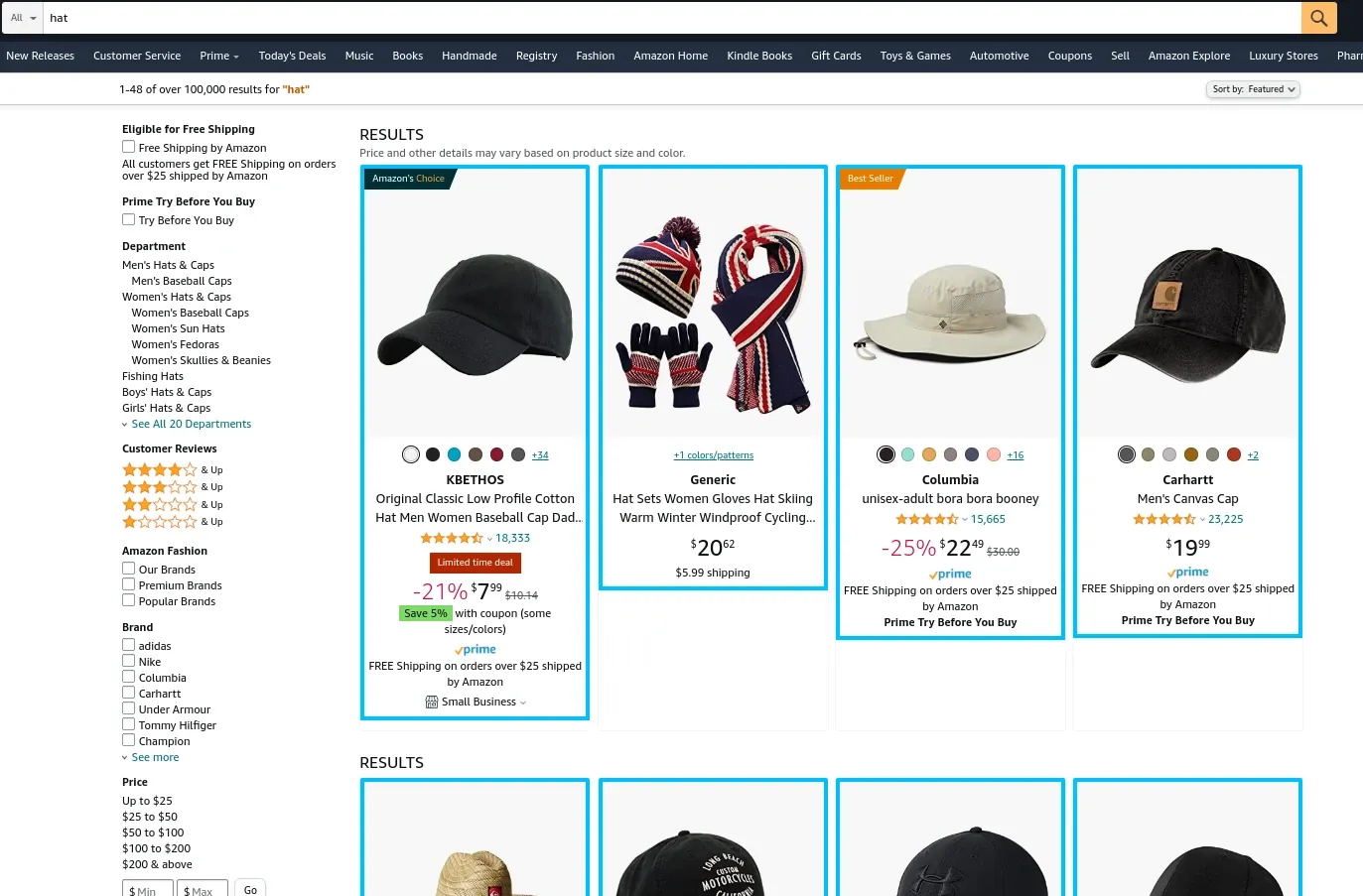
Each container contains preview information of the product that we can extract using a few relative CSS and XPath selectors. Here's what the retrieved data should look like after running the above Amazon scraper:
Example output:
[
{
"url": "https://www.amazon.com/Amazon-Kindle/dp/B0CNVCQZG1/ref=sr_1_1",
"title": "Kindle 16 GB (newest model) - Lightest and most compact Kindle, now with faster page turns, and higher contrast ratio, for an enhanced reading experience - Matcha",
"price": "$89.99",
"real_price": "$118.79",
"rating": 4.6,
"rating_count": 11772
},
{
"url": "https://www.amazon.com/All-new-Amazon-Kindle-Paperwhite-glare-free/dp/B0CFPJYX7P/ref=sr_1_2",
"title": "Kindle Paperwhite 16GB (newest model) – 20% faster, with new 7\" glare-free display and weeks of battery life – Black",
"price": "$134.99",
"real_price": "$118.79",
"rating": 4.6,
"rating_count": 11772
},
....
]
Now that we can effectively find products, let's take a look at how we can scrape Amazon product data itself.
Scraping Amazon Products
To scrape product data, we'll retrieve each product's HTML page and parse it using our XPath selectors.
To retrieve product data we mostly just need the ASIN (Amazon Standard Identification Number) code. This unique 10-character identifier is assigned to every product and product variant on Amazon. We can usually extract it from product URL like:

This also means that we can find the URL of any product as long as we know its ASIN code!
But before jumping into code, let's have a look at an important aspect when it comes to scraping Amazon products: variants!
Product Variants and Prices
Every product on Amazon can have multiple variants. For example, let's take a look at this product:
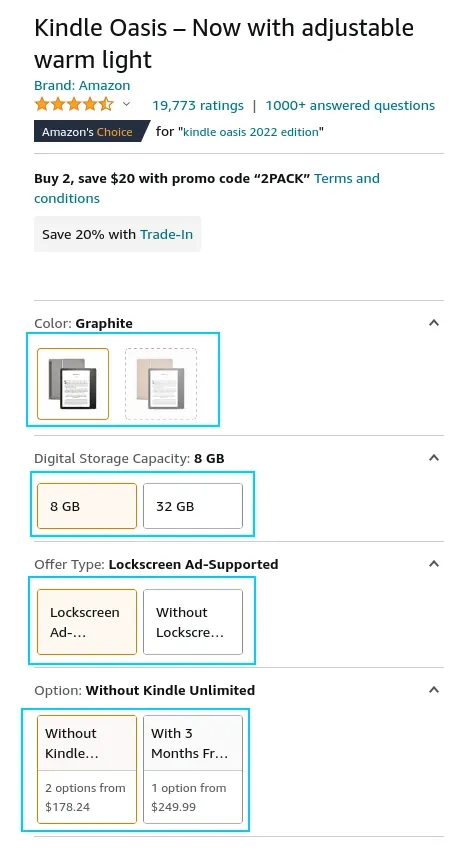
We can see that this product is customizable by several options. Each of these option combos is represented by its own ASIN identifier. So, if we take a look at the page source and find all identifiers of this product we can see multiple ASIN codes:

We can see that variant ASIN codes and descriptions are present in a javascript variable hidden in the HTML source of the page. To be more exact, it's in dimensionValuesDisplayData field of a dataToReturn variable. We can easily extract this using a small regular expressions pattern:
Now that we know how to retrieve the product variant ASIN identifiers, let's put it all together:
The interesting thing to note here is that not every product has multiple variants but every product has at least 1 variant. Let's take this scraper for a spin and see the product data retrieved:
Example output:
async def run(): limits = httpx.Limits(max_connections=5) async with httpx.AsyncClient(limits=limits, timeout=httpx.Timeout(15.0), headers=BASE_HEADERS) as session: data = await scrape_product("B07L5G6M1Q", session=session, reviews=True) print(json.dumps(data, indent=2))
if name == "main": asyncio.run(run())
```JSON
[
{
"name": "PlayStation 5 Console (PS5)",
"asin": "B0BCNKKZ91",
"style": "",
"description": "The PS5 console unleashes new gaming possibilities that you never anticipated. Experience lightning fast loading with an ultra-high speed SSD, deeper immersion with support for haptic feedback, adaptive triggers, and 3D Audio, and an all-new generation of incredible PlayStation games.",
"stars": "4.7 out of 5 stars",
"rating_count": "9,079 global ratings",
"features": [
"Model Number CFI-1215A01X.",
"Stunning Games - Marvel at incredible graphics and experience new PS5 features.",
"Breathtaking Immersion - Discover a deeper gaming experience with support for haptic feedback, adaptive triggers, and 3D Audio technology.",
"Lightning Speed - Harness the power of a custom CPU, GPU, and SSD with Integrated I/O that rewrite the rules of what a PlayStation console can do."
],
"images": [
"https://m.media-amazon.com/images/I/51VHiQ+LrsL.jpg"
],
"info_table": {
"ASIN": "B0BCNKKZ91",
"Release date": "October 1, 2022",
"Customer Reviews": "4.7 out of 5 stars",
"Best Sellers Rank": "#13,846 in Video Games ( See Top 100 in Video Games ) #57 in PlayStation 5 Consoles",
"Product Dimensions": "19 x 17 x 8 inches; 10 Pounds",
"Type of item": "Video Game",
"Language": "Multilingual",
"Item model number": "CFI-1215",
"Item Weight": "9.98 pounds",
"Manufacturer": "Sony Interactive Entertainment",
"Batteries": "1 Lithium Ion batteries required. (included)",
"Date First Available": "October 1, 2022"
}
},
{
"name": "PlayStation 5 Console (PS5)",
"asin": "B0BCNKKZ91",
"style": "",
"description": "The PS5 console unleashes new gaming possibilities that you never anticipated. Experience lightning fast loading with an ultra-high speed SSD, deeper immersion with support for haptic feedback, adaptive triggers, and 3D Audio, and an all-new generation of incredible PlayStation games.",
"stars": "4.7 out of 5 stars",
"rating_count": "9,079 global ratings",
"features": [
"Model Number CFI-1215A01X.",
"Stunning Games - Marvel at incredible graphics and experience new PS5 features.",
"Breathtaking Immersion - Discover a deeper gaming experience with support for haptic feedback, adaptive triggers, and 3D Audio technology.",
"Lightning Speed - Harness the power of a custom CPU, GPU, and SSD with Integrated I/O that rewrite the rules of what a PlayStation console can do."
],
"images": [
"https://m.media-amazon.com/images/I/51VHiQ+LrsL.jpg"
],
"info_table": {
"ASIN": "B0BCNKKZ91",
"Release date": "October 1, 2022",
"Customer Reviews": "4.7 out of 5 stars",
"Best Sellers Rank": "#13,846 in Video Games ( See Top 100 in Video Games ) #57 in PlayStation 5 Consoles",
"Product Dimensions": "19 x 17 x 8 inches; 10 Pounds",
"Type of item": "Video Game",
"Language": "Multilingual",
"Item model number": "CFI-1215",
"Item Weight": "9.98 pounds",
"Manufacturer": "Sony Interactive Entertainment",
"Batteries": "1 Lithium Ion batteries required. (included)",
"Date First Available": "October 1, 2022"
}
}
]We can see that now our scraper generates product information and a list of variant data points where each contains price and its own ASIN identifier.
The only detail we're missing now is product reviews, so next, let's take a look at how to scrape Amazon product reviews.
Scraping Amazon Reviews
Amazon product reviews exist on the very botton of the product page:
To scrape Amazon product reviews, let's take a look at where we can find them. If we scroll to the bottom of the page, we can see a link that says "See All Reviews" and if we click it, we can see that we are taken to a new location that follows this URL format:
We can see that just like for product information, all we need is the ASIN identifier to find the review page of a product. Let's add this logic to our scraper:
The above Amazon is fairly straightforward, we request the product page and then parse the review data using CSS selectors. Let's see the output generated:
Example output:
[
{
"text": "Great, never used the disc drive since I got it, never had any issues years later",
"title": "Great",
"location_and_date": "Reviewed in the United States on December 17, 2025",
"verified": true,
"rating": 5.0
},
{
"text": "Great PS5! It has lasted me for 2 years and still works! It is great gaming, I HIGHLY recommend!!",
"title": "Great quality, perfect packaging!",
"location_and_date": "Reviewed in the United States on October 25, 2025",
"verified": true,
"rating": 5.0
},
....
]By this point, we've learned how to find products on Amazon and scrape their description, pricing and review data. However, to scrape Amazon at scale we have to fortify our scraper from being blocked. For general techniques on how to avoid web scraping blocking, check out our complete guide. Now let's use ScrapFly web scraping API to handle this!
Bypass Blocking and Captchas with ScrapFly
We looked at how to Scrape Amazon.com though unfortunately when scraping at scale it's very likely that Amazon will start to either block us or start serving us captchas, which will hinder or completely disable our web scraper.

Check out Scrapfly's web scraping API for all the details.
For this, we'll be using scrapfly-sdk python package. First, let's install scrapfly-sdk using pip:
$ pip install scrapfly-sdkTo take advantage of ScrapFly's API in our Amazon web scraper all we need to do is change our httpx session code with scrapfly-sdk client requests. For more see the latest scraper code on github:
FAQ
Is it legal to scrape Amazon.com?
Yes. Amazon's data is publicly available, and we're not extracting anything personal or private. Scraping Amazon.com at slow, respectful rates would fall under the ethical scraping definition.
That being said, attention should be paid to GDRP compliance in the EU when scraping personal data such as personal people's data from the reviews section. For more, see our Is Web Scraping Legal? article.
How to crawl Amazon.com?
It's easy to crawl Amazon products because of the extensive related product and recommendation system featured on every page. In other words, we can write a crawler that takes in a seed of amazon product URLs, scrapes them, extracts more product URLs from the related product section - and loops this on. For more on crawling see How to Crawl the Web with Python.
Summary
In this tutorial, we built an Amazon product scraper by understanding how the website functions so we could replicate its functionality in our web scraper. First, we replicated the search function to find products, then we scraped product information and variant data and finally, we scraped all of the reviews of each product.
We can see that web scraping amazon in Python is pretty easy thanks to brilliant community tools like httpx and parsel.
To prevent being blocked, we used ScrapFly's API which smartly configures every web scraper connection to avoid being blocked. For more on ScrapFly see our documentation and try it out for free!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


