

Web scraping blocking can happen for different reasons, requiring attention to various details. But what about about simple tools that can avoid web scraping blocking?
In this article, we'll explain the Undetected ChromeDriver and how to use it to avoid web scraping blocking. Let's dive in!
Key Takeaways
Master undetected chromedriver for web scraping by bypassing anti-bot protection with stealth browser automation and realistic user behavior simulation.
- Use undetected ChromeDriver to bypass Cloudflare, Imperva, and Datadome anti-bot protection
- Configure randomized User-Agent strings and behavioral simulation for natural browsing patterns
- Implement mouse movement and click simulation for human-like interaction patterns
- Configure proxy integration and session management for enhanced anonymity
- Use specialized tools like ScrapFly for automated undetected ChromeDriver management with anti-blocking features
- Implement proper error handling and retry logic for reliable anti-detection workflows
What is the Undetected ChromeDriver?
The Undetected ChromeDriver is a modified Web Driver for Web Scraping with Selenium and Python. It mimics regular browsers' behavior by various techniques, such as:
- Changing Selenium's variable names to appear as normal web browsers.
- Randomizing User-Agent strings.
- Adding randomized delays between sending requests or executing actions.
- Maintaining cookies and sessions correctly while browsing a website.
- Simulating mouse clicks and moves, which makes browsing behavior appear natural.
- Allowing for adding proxies, which prevents IP blocking and rate limiting.
The Undetected ChromeDriver uses the above techniques to avoid specific anti-scraping challenges, such as How to Bypass Cloudflare When Web Scraping in 2026, How to Bypass Imperva Incapsula when Web Scraping in 2026 and How to Bypass Datadome Anti Scraping in 2026.
Before proceeding to web scraping with Undetected ChromeDriver, let's install it.
Setup
In this Undetected ChromeDriver for web scraping guide, we'll use nowsecure.nl as our target website. Which uses Cloudflare to detect web scrapers. We'll use the Undetected ChromeDriver to bypass this protection. It can be installed using the pip terminal command:
pip install undetected-chromedriverThe above command will also install Selenium as it's used by the undetected-chromedriver under the hood.
How to Avoid Blocking using Undetected ChromeDriver?
Undetected ChromeDriver is a modified version of the web driver used by Selenium, which can avoid web scraping detection - let's take a look at it.
Comparing with Selenium
To confirm its capabilities, let's try our target website with standard Selenium code. For this, we'll use common selenium installation:
$ pip install selenium webdriver-managerThen, let's scrape a secured web page that uses Cloudflare to detect web scrapers:
# pip install webdriver-manager
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
import time
# Add selenium option
options = Options()
options.headless = False
# Configure Selenium options and download the default web driver automatically
driver = webdriver.Chrome(options=options, service=ChromeService(ChromeDriverManager().install()))
# Maximize the browser widnows size
driver.maximize_window()
# Go the target website
driver.get("https://nowsecure.nl/")
# Wait for security check
time.sleep(4)
# Take screenshot
driver.save_screenshot('screenshot.png')
# Close the driver
driver.close()Here, we intialize a Selenium headless browser with the default web driver that's installed using the web-driver-manager. Then, we send a request to the target website and take a screenshot. Here is what we got:
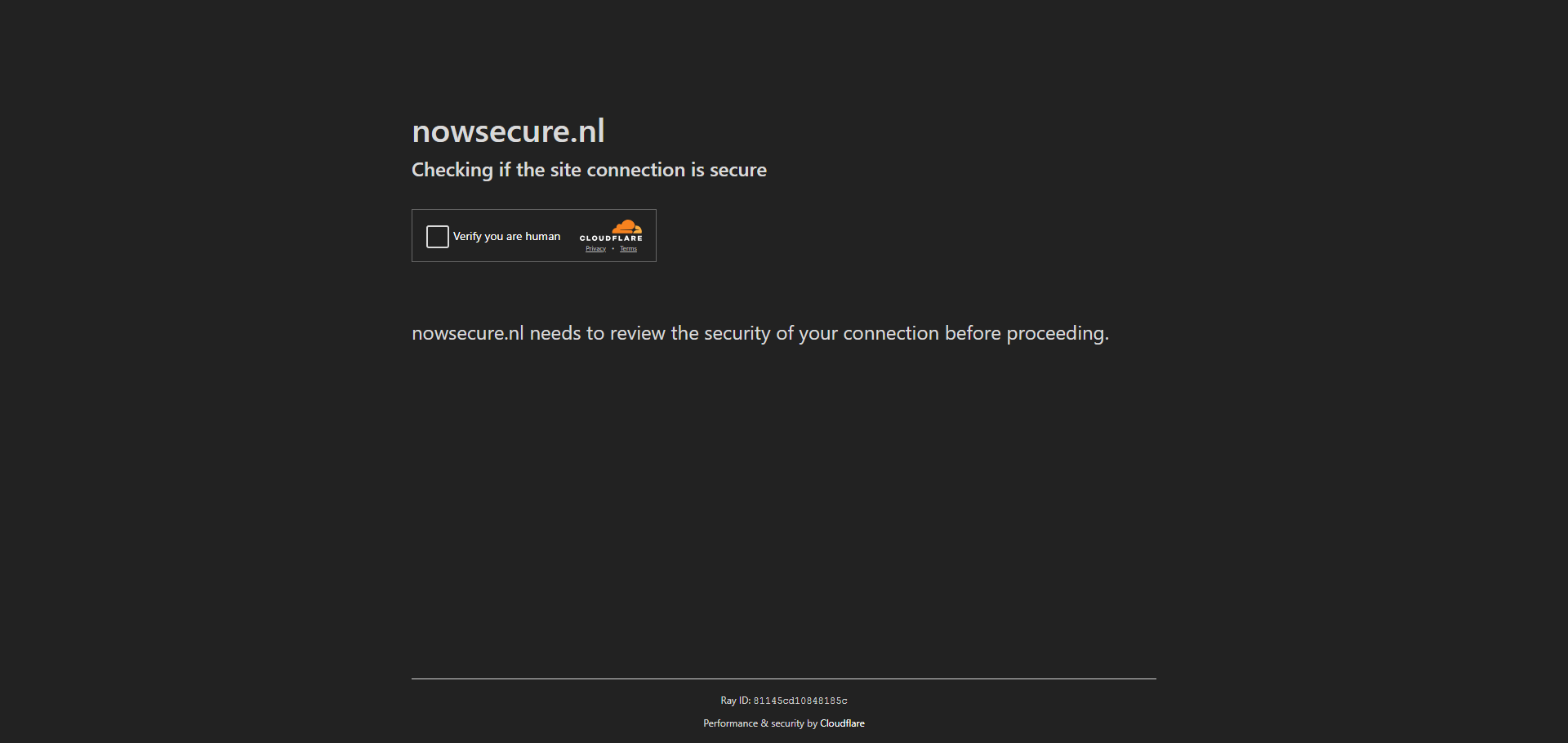
We can see that the website detected us and requested a Cloudflare challenge to solve before proceeding to the website.
Bypass with Undetected Chromedriver
Now, that we know what failure looks like let's bypass this challenge using the Undetected ChromeDriver:
import undetected_chromedriver as uc
import time
# Add the driver options
options = uc.ChromeOptions()
options.headless = False
# Configure the undetected_chromedriver options
driver = uc.Chrome(options=options)
with driver:
# Go to the target website
driver.get("https://nowsecure.nl/")
# Wait for security check
time.sleep(4)
# Take a screenshot
driver.save_screenshot('screenshot.png')
# Close the browsers
driver.quit()We initialize an undetected_chromedriver object, go to the target website and take a screenshot. Here is the screenshot we got:
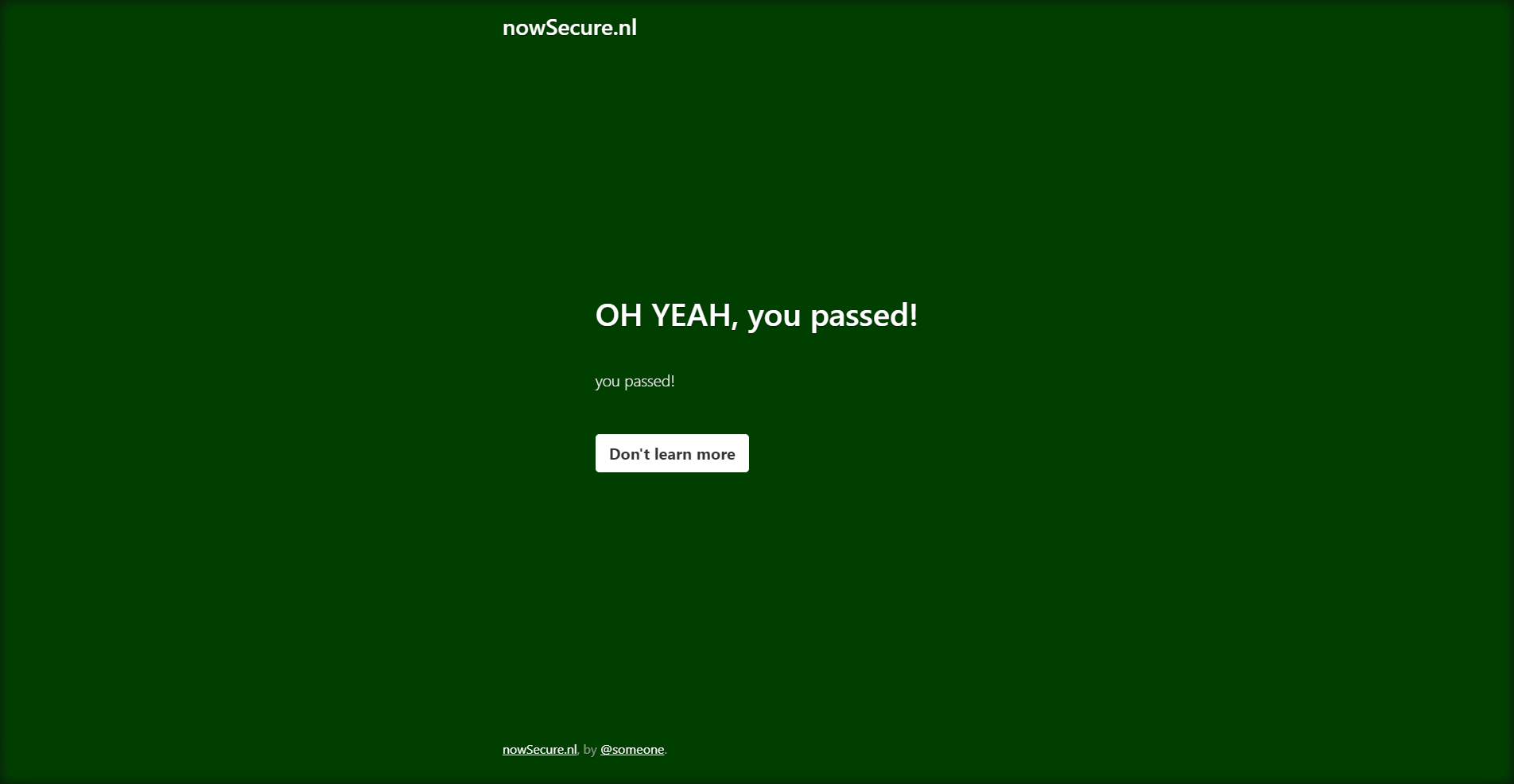
Shortcomings
We successfully avoided web scraping detection using the Undetected ChromeDriver for Cloudflare. However, it can still struggle against more advanced anti-bot systems.
For example, let's try bypass Opensea.io protection:
import undetected_chromedriver as uc
import time
# Add the driver options
options = uc.ChromeOptions()
options.headless = False
# Configure that driver options
driver = uc.Chrome(options=options)
with driver:
# Go to the target website
driver.get("https://opensea.io/")
# Wait for security check
time.sleep(4)
# Take a screenshot
driver.save_screenshot('opensea.png')
# Close the browsers
driver.quit()In this example, OpenSea instantly detects and blocks our scraper:
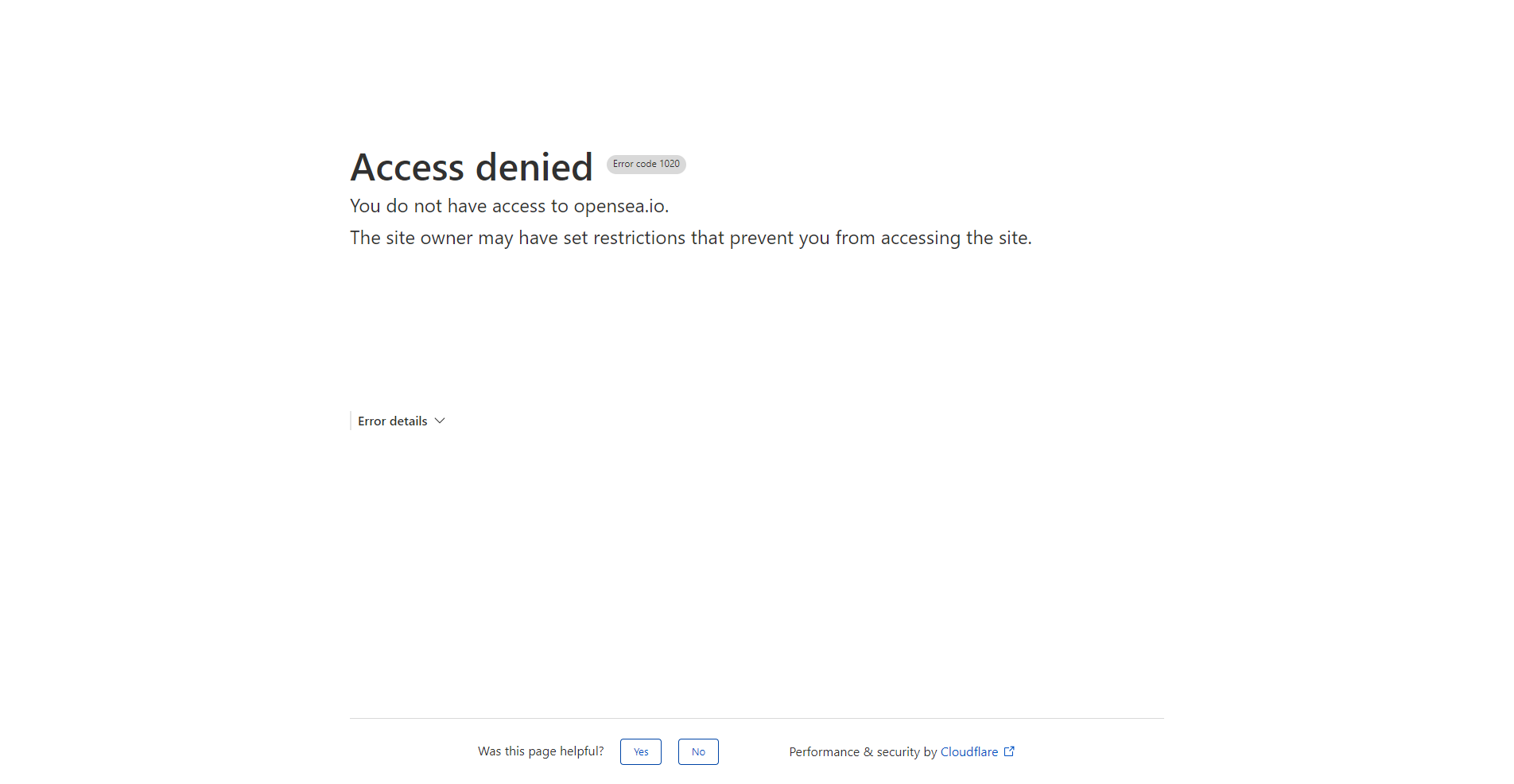
There are a few more things we can do to empower our use Undetected ChromeDriver for web scraping. Let's take a look at them next!
How to Add Proxies to Undetected ChromeDriver?
Proxies are essential for avoiding IP blocking while scraping by splitting the traffic between multiple IP addresses. Here is how you can add proxies to the Undetected ChromeDriver:
import undetected_chromedriver as uc
# Add the driver options
options = uc.ChromeOptions()
options.headless = False
# For proxies without authentication
options.add_argument(f'--proxy-server=https://proxy_ip:port')
# For proxies with authentication
options.add_argument(f'--proxy-server=https://proxy_username:proxy_password@proxy_ip:proxy_port')
# Configure that driver options
driver = uc.Chrome(options=options) Although you can add proxies to the undetected chrome driver, there is no direct implementation for proxy rotation.

We have seen that the Undetected ChromeDriver can't avoid advanced anti-scraping challenges and can't rotate proxies by itself. Let's look at a better solution!
Powering Up with ScrapFly
Undetected Chromedriver is a powerful tool though it doesn't solve all web scraping issues and this is where Scrapfly can fill in the rest!

For example, by using the ScrapFly asp feature, we can easily scrape websites without getting blocked:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
scrape_config=ScrapeConfig(
url="https://opensea.io",
# Activate the JavaScript rendering feature to render images
render_js=True,
# Enable the asp to bypass anti scraping protections
asp=True,
# Take a screenshot
screenshots={"opensea": "fullpage"},
)
)
# Save the screenshot
scrapfly.save_screenshot(api_response=api_response, name="opensea")
# Use the built-in selector to parse the HTML
selector = api_response.selector
# Empty array to save the data into
data = []
# Loop through the trending NFT names
for nft_title in selector.xpath("//span[@data-id='TextBody']/div/div[1]/text()"):
data.append(nft_title.get())
print(data)
# ['Akumu Dragonz', 'Nakamigos-CLOAKS', 'RTFKT x Nike Dunk Genesis CRYPTOKICKS', 'Skyborne - Genesis Immortals', 'Arbitrum Odyssey NFT', 'Parallel Alpha', 'Skyborne - Nexian Gems', 'Milady Maker', 'Otherside Vessels', 'BlockGames Dice']Common Errors
Using Chromedriver with undetectable patches can introduce new errors. Here are some common errors and how to fix them.
ModuleNotFoundError: No module named 'undetected_chromedriver'
This error means something went wrong with unedetected_chromedriver installation. This usually happens when pip install installs the package to a different python environment. So, ensure that python and pip point to the same Python environment.
Alternatively, use package manager like poetry:
# create a project
$ mkdir my_project && cd my_project
$ poetry init --Dependency undetected_chromedriver
$ touch myscript.py # create your python script
$ poetry run python myscript.pyThis will ensure that undetected_chromedriver is installed in the same environment as your script.
This version of ChromeDriver only supports Chrome version X
Another common error is related to the browser version availability.
Message: unknown error: cannot connect to chrome at 127.0.0.1:33505
from session not created: This version of ChromeDriver only supports Chrome version 118
Current browser version is 117.0.5938.149This error means available chrome browser on the current machine is too old for undetectable chrome driver to work. To fix this, simply update your Chrome browser to the newer version. Alternatively, if you have multiple chrome browser version available (such as beta) you can specify one using the browser_executable_path parameter:
import undetected_chromedriver as uc
driver = uc.Chrome(
browser_executable_path="/usr/bin/google-chrome-beta"
)FAQ
Are there alternatives to the Undetected ChromeDriver?
Yes, Puppeteer Stealth is a library that can bypass anti-scraping challenges similar to the Undetected ChromeDriver. However, it's based on Node.js and unavailable in Python yet. For a Python-native alternative, SeleniumBase UC Mode offers similar stealth capabilities built on top of undetected-chromedriver with additional fixes and improvements.
Does Undetected ChromeDriver work in headless mode?
Undetected ChromeDriver supports headless mode, but it can reduce stealth effectiveness. Some anti-bot systems detect headless browsers through JavaScript property checks and rendering differences. For the best results, run in headed mode when possible, or use the --headless=new flag in Chrome 112+ which provides a more complete browser environment that's harder to detect.
How to avoid web scraping blocking?
There are multiple factors that lead to web scraping blocking including headers, IP addresses, security handshakes and javascript execution. To scrape without getting blocked, you must pay attention to these details. For more information, refer to our dedicated article on scraping without getting blocked.
Summary on Undetected Chromedriver use for Scraping
In this article, we explained how to use the Undetected ChromeDriverr to scrape without getting blocked. Which works by mimicking normal web browsers configurations to appear natural.
We have seen that the Undetected ChromeDriver can avoid specific anti-scraping challenges like Cloudflare. However, it can be detected by advanced anti-bot systems.


