

One of the most common challenges encountered when web scraping is scaling. For this, using proxies in web scraping is crucial! Having a set of quality proxies can prevent web scraping blocking. But what makes a quality proxy for web scraping, and what are the different proxies are there?
In this guide, we'll take an extensive guide to using proxies for web scraping. We'll explain the different types of proxies, how they compare, their challenges, and their best practices for using them in web scraping. Let's get started!
Key Takeaways
Master proxy usage in web scraping by understanding residential vs datacenter proxies, IP rotation techniques, and anti-detection methods for large-scale data extraction.
- Use residential proxies over datacenter proxies for better trust scores and reduced blocking
- Implement IP rotation and geographic targeting to distribute requests across multiple IPs
- Choose proxy providers based on success rates, bandwidth limits, and anti-detection capabilities
- Handle IPv4 vs IPv6 considerations and website compatibility for optimal proxy selection
- Implement exponential backoff retry logic with 403 status code detection for rate limiting
- Use specialized tools like ScrapFly for automated proxy management and anti-blocking features
What Is a Proxy?
A proxy server is a middleware that lies between a client and a host. There are different usages for proxies, such as connection optimization. However, the most common usage of web scraping proxies is masking or hiding the client.
This IP masking is beneficial for two main purposes:
- Accessing geographically blocked websites by changing the IP location.
- Splitting the requests' traffic across multiple IP addresses.
In the web scraping context, proxy servers are used to prevent IP address blocking, as a high number of requests sent from the same IP address can cause the connection to be identified as non-human.
To further explore the usage of proxies for web scraping, let's have a look at the IP address types.
IP Protocol Versions

Currently, the internet runs on two types of IP addresses: IPv4 and IPv6. The key differences between these two protocols are the following:
- Address quantity The IPv4 address pool is limited to around 4 billion addresses. This might seem like a lot, but the internet is a big place, and technically, we ran out of free addresses already! (see IPv4 address exhaustion)
- Adoption Most websites still only support IP addresses with IPv4 connections, meaning we can't use IPv6 proxies unless we explicitly know our target website supports it.
How does the IP address type affect web scraping?
Since IPv6 is supported by very few target websites, we are limited to using IPv4 proxy servers, which are more expensive (3-10 times on average) as they are limited. That being said, some major websites do support IPv6, which can be checked on various IPv6 accessibility test tools like https://ipv6-test.com/validate.php. So, if your target website supports IPv6, the web scraping proxy pool budget can be significantly reduced!
Proxy Protocols
There are two major proxy protocols used these days: HTTP and SOCKS (latest SOCKS5). In the context of web scraping proxies, there isn't much practical difference between these two protocols. Proxy servers with the SOCKS protocol tend to be a bit faster, more stable, and more secure. On the other hand, HTTP proxies are more widely adopted by web scraping proxy providers and the HTTP client libraries.
Proxy Types
The proxy type is the most important aspect when choosing a web scraping proxy provider or creating a proxy pool. There are four types of proxy IP addresses:
- Datacenter
- Residential
- Static Residential (aka ISP)
- Mobile.
The key differences between the above proxy server types are the following:
- Price
- Reliability, such as speed or the automatic proxy rotation
- Stealth score, the likelihood of getting blocked, which is low for the anonymous proxies.
Let's have a deeper look into the value and details of each web scraping proxies.
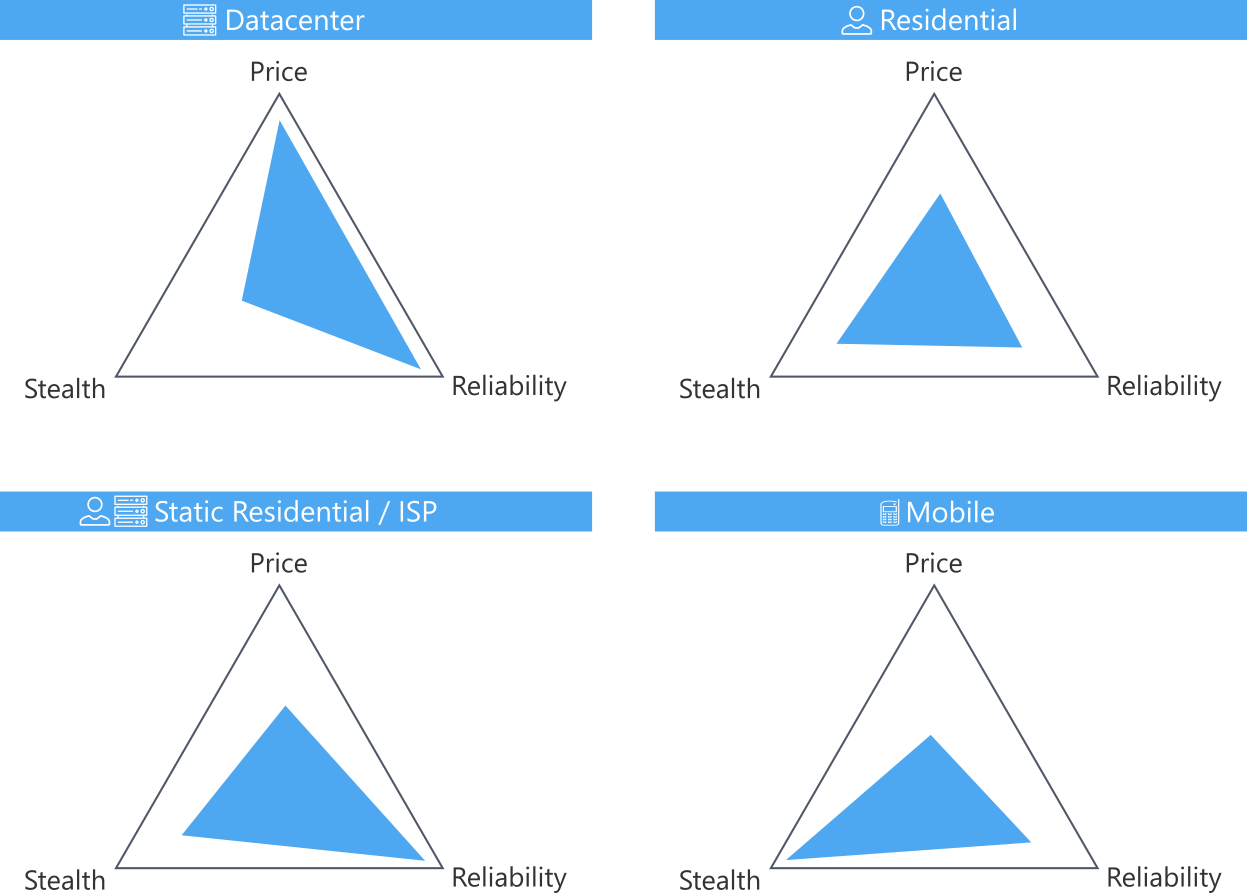
Datacenter Proxies
Datacenter IPs are commercially assigned to proxy services through cloud servers, and they aren't affiliated with internet service providers (ISPs). This web scraping proxy type is often flagged as high-risk (with a high chance of being automated). They can be provided as dedicated proxies or shared between multiple users, which increases the flagging risk in the last case.
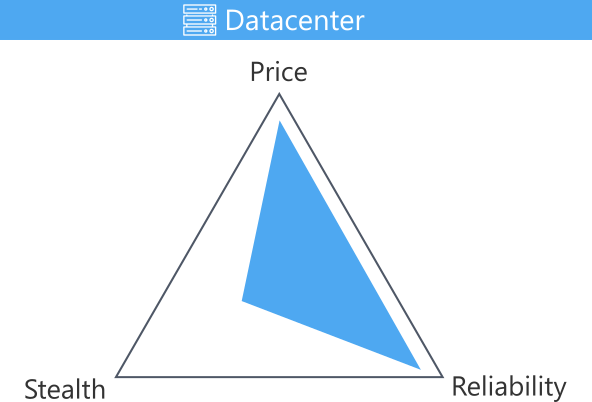
On the bright side, datacenter proxies are widely accessible, reliable, and cheap! A proxy pool of this type is recommended for teams with reliable engineering resources to reverse engineer the target websites. This can be utilized to create a proxy manager for rotating proxies depending on the blocking rate.
Residential Proxies
Residential IPs are assigned by ISPs and have a lower risk of being flagged, as they are assigned to home networks. Residential IPs make a reliable web scraping proxy as they are used by real humans!
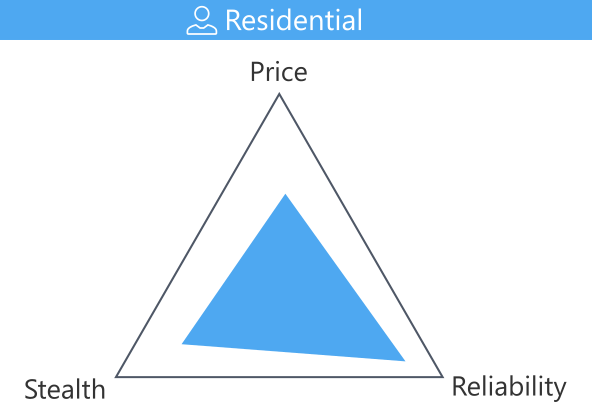
That being said, proxy services with residential IP addresses are much pricier than the datacenter ones. Additionally, this proxy type can have session persistency issues with maintaining the same IP address for long periods. Hence, they are often referred to as "Rotating Residential Proxies".
Therefore, residential proxies can be problematic with specific target websites, as they require the same IP address to be maintained for the whole connection session. For example, if we are scraping web data at the end of a long process, the proxy manager can change the IP address before we reach the end.
A proxy service with residential IPs requires minimal engineering efforts, as they have a high trust score and are relatively affordable.
Static Residential / ISP Proxies
Residential IPs have a great trust score but are unreliable as they aren't powered by a reliable datacenter infrastructure. What if we combine the best of both worlds: the reliability of the datacenter proxies and the stealth of the residential proxies?
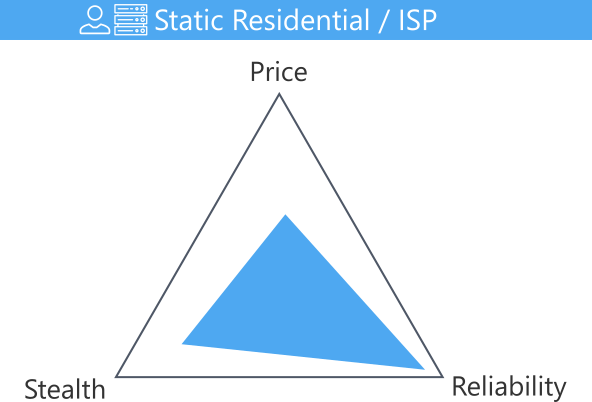
ISP proxies "Static Residential proxies" are a mixed version of residential and datacenter proxies. They combine the high score of residential IPs with the high proxy network quality of the datacenter infrastructure!
The static residential proxies are best suited for web scrapers, as they can benefit from the high trust score and the persistent connection sessions.
Mobile Proxies
Mobile IPs are assigned by mobile network towers. They have a dynamic IP address that gets rotated automatically. This means that they have a high trust score and are unlikely to get blocked or faced with 5 Proven Ways to Bypass CAPTCHA in Python challenges.
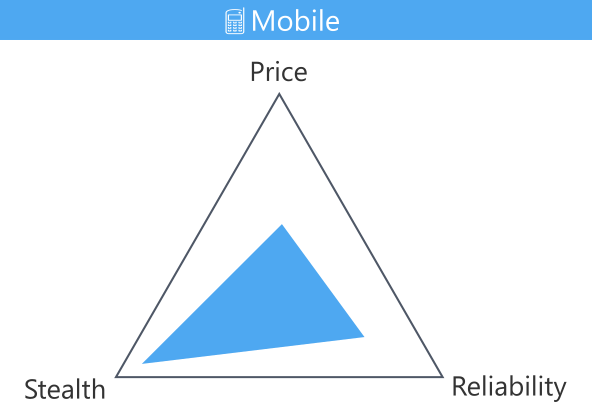
Mobile proxies are an extreme version of residential proxies: maintaining the same IP might be more challenging, and they are even more expensive. This proxy type tends to be slower and less reliable. However, they are getting improved by web scraping proxy providers lately.
Mobile proxies don't require much engineering resources, as they solve most of their connection blocking by themselves!
Other Proxy Types
We've covered four proxy types. However, masking the IP address isn't only accessible through regular proxy providers. Let's quickly explore the other types.
Virtual Private Network (VPN)
VPNs are proxies with a more complex tunneling protocol. The IPs of a VPN are shared across many users. This means that the VPN IPs have low trust scores, and they are likely to get blocked or challenged with CAPTCHAs. Additionally, most of the VPNs don't provide access to their HTTP or SOCKS5 servers. However, they can be accessed for web scraping using a bot of technical knowledge.
The Onion Router (TOR)
Tor is an open-source software that provides anonymous proxies using volunteer-driven network layers. The IPs of Tor have a very low success rate. Tor connections are also slow and unreliable, making them ineffective for web scraping.
Which Web Scraping Proxy Provider to Choose?
Choosing the right proxy solution depends on your specific scraping scenario. Here are four common situations and what works best for each:
Scenario 1: Scraping Protected Sites (E-commerce, Social Media)
Target sites like Amazon, LinkedIn, or Instagram use anti-bot systems that detect automation through fingerprinting, TLS analysis, and behavioral patterns.
Solution: You need residential or ISP proxies combined with anti-fingerprinting and JavaScript rendering. Scrapfly handles this automatically by combining residential proxies with browser fingerprint management and CAPTCHA solving. The alternative is managing your own residential proxy pools, browser stealth libraries, and constant adaptation to blocking changes.
Scenario 2: Scraping Public Data at Scale (News, Blogs, Forums)
Public content sites like news portals, forums, or directories typically have basic rate limiting but don't use advanced anti-bot systems.
Solution: Datacenter proxies work well here since these sites don't actively fingerprint IP reputation. Scrapfly's datacenter tier provides reliable performance at lower cost with automatic rotation and retry logic built-in.
Scenario 3: Geolocation-Specific Scraping (Local Search, Regional Pricing)
Projects requiring location-specific results like Google local search, regional e-commerce pricing, or geo-restricted content.
Solution: You need geo-targeting with residential or ISP proxies in specific countries/cities. Scrapfly offers 50+ countries with city-level targeting. Managing this yourself requires sourcing and maintaining residential proxies across multiple geographies.
Scenario 4: Unpredictable Bandwidth Usage (Image-Heavy Sites)
Scraping product catalogs with images, real estate sites, or any content where page size varies dramatically.
Solution: Bandwidth-based pricing becomes unpredictable when page sizes vary. Scrapfly's credit-based pricing gives predictable costs regardless of page size, unlike traditional proxy providers charging per GB where costs can spike 10x when scraping image-heavy pages.
Why Scrapfly's Approach Works Better
When evaluating proxy solutions, the pricing model matters as much as proxy quality. Traditional proxy providers charge per bandwidth, which creates unpredictable costs and leaves you managing complexity.
Credit-Based vs Bandwidth-Based Pricing
Traditional bandwidth-based pricing charges per gigabyte transferred. This creates problems:
- Unpredictable costs when scraping image-heavy sites (Amazon product pages: 200kb vs 2-4MB with images)
- Price spikes when target sites add media or redesign with heavier assets
- Expensive when using browser automation which downloads fonts, stylesheets, and images
- Forces you to focus on bandwidth rather than results
Scrapfly's credit-based pricing charges per successful request regardless of page size. This model gives predictable costs whether scraping text pages or image catalogs. You pay for successful results, not bandwidth consumed.
All-in-One vs DIY Proxy Management
Traditional proxy-only approach requires:
- Sourcing and maintaining proxy pools
- Building rotation and retry logic
- Managing anti-fingerprinting separately
- Handling CAPTCHAs through third-party services
- Monitoring success rates and replacing failed proxies
- Adapting to blocking changes manually
Scrapfly includes everything:
- 50+ countries with city-level targeting
- Automatic proxy rotation and retry logic
- Browser fingerprint management built-in
- CAPTCHA solving integration
- Real-time adaptation to blocking changes
- Single API call replaces entire proxy infrastructure
Cost Reality
Starting prices may seem similar, but total cost differs:
- Traditional proxies: $50-500/month + engineering time (10-40 hours/month) + separate anti-bot tools
- Scrapfly: $20-100/month with proxies, anti-bot, and infrastructure included
For detailed provider comparisons, see our best proxy providers guide.
Bandwidth Budget
When shopping around for the best web scraping proxies, we'll first notice that most proxies are priced by proxy count and bandwidth. Bandwidth can quickly become a huge budget sink for some web scraping scenarios, so evaluating bandwidth consumption is important before choosing dedicated proxies or a web scraping API.
It's easy to overlook bandwidth usage and end up with a huge proxy bill, so let's take a look at some examples:
| target | avg document page size | pages per 1GB | avg browser page size | pages per 1GB |
|---|---|---|---|---|
| Walmart.com | 16kb | 1k - 60k | 1 - 4 MB | 200 - 2,000 |
| Indeed.com | 20kb | 1k - 50k | 0.5 - 1 MB | 1,000 - 2,000 |
| LinkedIn.com | 35kb | 300 - 30k | 1 - 2 MB | 500 - 1,000 |
| Airbnb.com | 35kb | 30k | 0.5 - 4 MB | 250 - 2,000 |
| Target.com | 50kb | 20k | 0.5 - 1 MB | 1,000 - 2,000 |
| Crunchbase.com | 50kb | 20k | 0.5 - 1 MB | 1,000 - 2,000 |
| G2.com | 100kb | 10k | 1 - 2 MB | 500 - 2,000 |
| Amazon.com | 200kb | 5k | 2 - 4 MB | 250 - 500 |
In the table above, we see the average bandwidth usage by various targets. If we look closely, we can see some patterns emerge: big, heavy HTML websites (like How to Scrape Amazon.com Product Data and Reviews) use a lot of bandwidth compared to dynamic websites that use background requests to populate their pages (like How to Scrape Walmart.com Product Data (2026 Update)).
Another example of a bandwidth sink is using browser automation tools like How to Web Scrape with Puppeteer and NodeJS in 2026, Web Scraping Dynamic Web Pages With Scrapy Selenium, or Web Scraping with Playwright and Python. Since web browsers are less precise in their connections they often download a lot of unnecessary data like images, fonts and so on.
Therefore, it's essential to configure browser automation setups with resource blocking rules and proper caching rules to prevent bandwidth overhead, but generally expect browser traffic to be much more expensive bandwidth-wise.
Common Proxy Issues
Proxy scraping is having a middleman between your client and the server, which can introduce many issues.
Probably the biggest issue is the support of HTTP2/3 traffic. The newer HTTP protocols are typically preferred in web scraping to avoid blocking. Unfortunately, lots of HTTP proxies struggle with this sort of traffic, so when choosing a web scraping proxy provider, we advise testing HTTP2 quality first!
Another common proxy provider issue is connection concurrency. Typically, proxy services have a limit on concurrent proxy connections, which might be too small for powerful web scrapers. Hence, it's recommended to do research on concurrent connection limits and throttling scrapers a bit below that limit to prevent proxy-related connection crashes.
Finally, proxies introduce a lot of additional complexity to a web scraping project. So, when using a proxy server for scraping, we recommend investing additional engineering effort in retry and error-handling logic.
Free vs Paid Proxies: The Real Cost Analysis
Free proxy lists are tempting but rarely worth the engineering overhead. Here's the real comparison:
Free Proxies
What you get:
- Public proxy lists from GitHub, forums, or free proxy sites
- No direct monetary cost
- Datacenter IPs only
What you actually pay:
- Extremely low success rates (5-15% of proxies work at any given time)
- Constant monitoring required to detect dead proxies and find replacements
- High blocking rates as IPs are shared across thousands of users
- Security risks as free proxies may log traffic or inject malware
- No geographic targeting or specific location support
Engineering cost: A developer spending 10 hours/month maintaining free proxy lists costs more than paid proxies when factoring in salary.
Paid Proxies
What you get:
- 95%+ uptime and success rates
- Geographic targeting (country/city-level)
- Dedicated support and SLAs
- Choice of residential, datacenter, or ISP proxies
- HTTP2/3 support and proper infrastructure
Real cost comparison:
- Budget datacenter proxies: $50-100/month for 10-50 IPs
- Residential proxy services: $80-500/month depending on bandwidth
- All-in-one solutions like Scrapfly: $20-100/month including proxies + anti-bot features
When Free Proxies Make Sense
Free proxies are only viable when:
- You're running proof-of-concept tests (not production scraping)
- Your team has excess engineering capacity for proxy maintenance
- Target sites have zero anti-bot protection
- Scraping volume is very low (under 1,000 requests/day)
For any production scraping, paid proxies or managed services provide better ROI when factoring in engineering time and success rates.
Proxies at ScrapFly
Proxies can be a very powerful tool in web scraping but still not enough for scaling up some web scraping projects and this is where Scrapfly can assist!

ScrapFly is a web scraping API that offers a request middleware service, which ensures that outgoing requests result in successful responses. This is done by a combination of unique ScrapFly features such as a smart proxy selection algorithm, anti-web scraping protection solver, and browser-based rendering.
ScrapFly uses credit-based pricing model, which is much easier to predict and scale than bandwidth-based pricing. This allows flexible pricing based on used features rather than arbitrary measurements such as bandwidth, meaning our users aren't locked into a single solution and can adjust their scrapers on the fly!
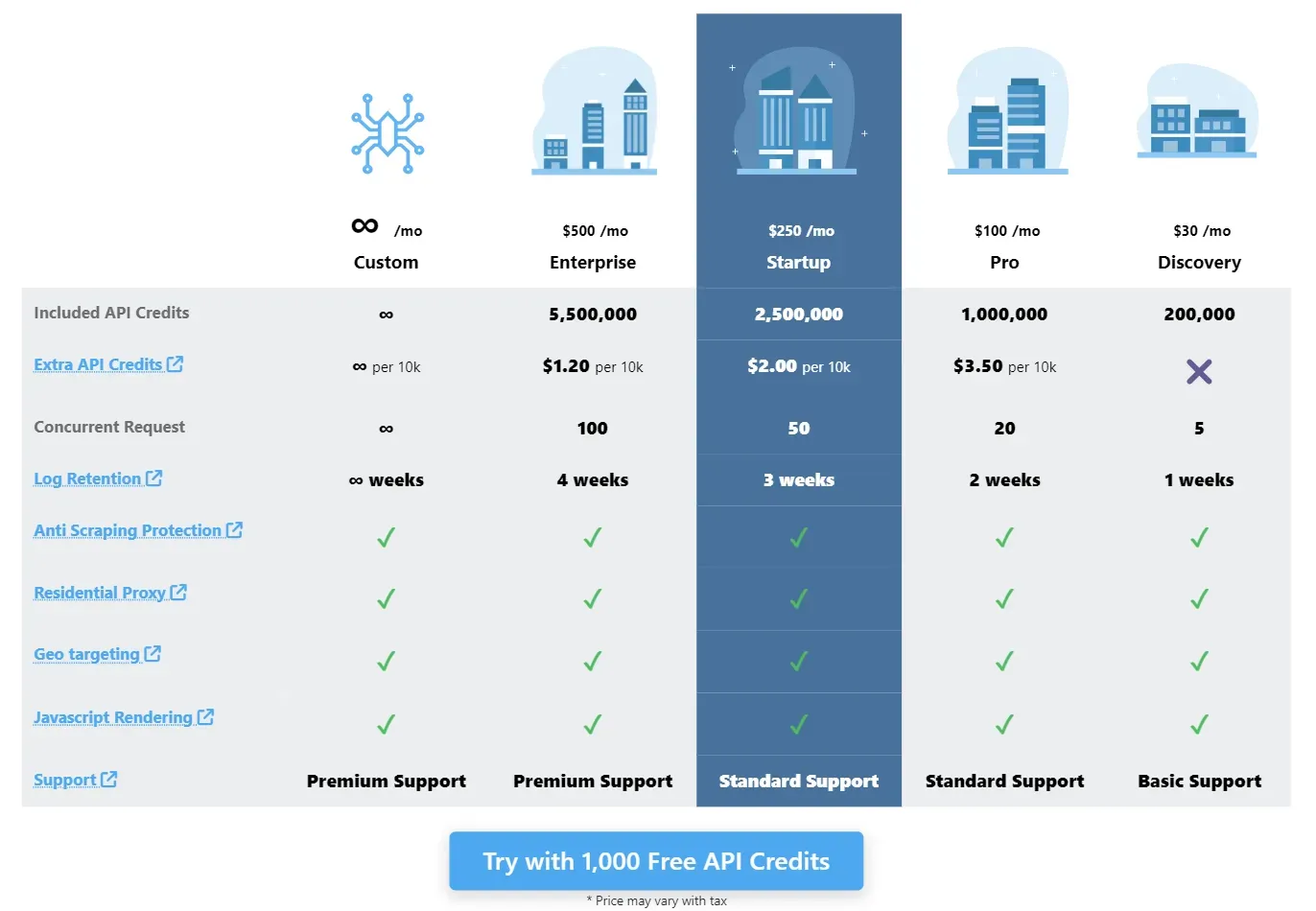
For example, the most popular $100/Month tier can yield up to 1,000,000 target responses based on enabled features:
- Anti-scraping protection bypass - For scraping any website without getting blocked.
- Millions of residential and datacenter proxies in over 50 countries - For scraping from almost any geographical location while also avoiding IP address blocking using an automatic proxy rotation.
- JavaScript rendering - For scraping dynamically loaded content using cloud headless browsers.
- Easy to use Python and Typescript SDKs.
To explore these and other offered features see our full documentation!
FAQ
What's the difference between datacenter, residential, and mobile proxies for web scraping?
Datacenter proxies are cheap and fast but easily detected. Residential proxies use real home IPs, are harder to detect but more expensive. Mobile proxies use mobile network IPs, are hardest to detect but most expensive and least reliable.
How do I choose the right proxy type for my web scraping project?
Start with datacenter proxies for simple projects and rate limiting. Use residential proxies for anti-bot protection bypass. Choose mobile proxies for highly protected targets. Consider your budget, target website's protection level, and required reliability.
What are the bandwidth costs when using proxies for web scraping?
Bandwidth costs vary by target website complexity. Simple pages (16-50kb) allow 20k-60k requests per 1GB. Heavy pages with images/JavaScript (1-4MB) allow only 250-2,000 requests per 1GB. Browser automation significantly increases bandwidth usage.
How much do web scraping proxies cost?
Datacenter proxies: $1-3 per IP per month, or $50-150 for pools of 50-100 IPs. Residential proxies: $5-15 per GB bandwidth. ISP proxies: $2-5 per IP per month. Mobile proxies: $10-20 per GB or $50-200 per IP monthly. API solutions like Scrapfly use credit-based pricing starting at $20/month, avoiding bandwidth unpredictability. Hidden cost warning: bandwidth charges can explode 10x when scraping image-heavy sites versus text pages.
Using Proxies For Web Scraping Summary
In this guide, we've learned a lot about proxies. We compared IPv4 vs IPv6 internet protocols and HTTP vs SOCKS proxy protocols. Then, we explored the different proxy types and how they differ in web scraping blocking. Finally, we wrapped everything up by looking at common proxy challenges like bandwidth-based pricing, HTTP2 support, and proxy stability issues.
Proxies are complicated and can be hard to work with, so try out our flat-priced ScrapFly solution for free!


