

Glassdoor is mostly known for company reviews from past and current employees though it contains much more data like company metadata, salary information and reviews. In 2026, Glassdoor's JavaScript-heavy interface requires browser automation tools like Playwright to fully render content before extraction. This makes Glassdoor a great public data target for web scraping!
In this hands-on web scraping tutorial, we'll be taking a look at glassdoor.com and how can we scrape company information, job listings and reviews. We'll do this in Python using a few popular community packages, so let's dive in.
Key Takeaways
Learn to scrape Glassdoor company data, job listings, and reviews using Python with httpx and parsel, handling dynamic content and anti-bot measures for employment data extraction.
- Reverse engineer Glassdoor's search API endpoints by intercepting browser network requests
- Parse dynamic JSON data embedded in HTML using XPath selectors for job details and company information
- Bypass Glassdoor's anti-scraping measures with realistic headers, user agents, and request spacing
- Extract structured employment data including job titles, salaries, company reviews, and ratings
- Implement exponential backoff retry logic with 403 status code detection for rate limiting
- Use specialized tools like ScrapFly for automated Glassdoor scraping with anti-blocking features
Project Setup
In this tutorial, we'll be using Python and a couple of popular community packages:
- httpx - an HTTP client library that will let us communicate with amazon.com's servers
- parsel - an HTML parsing library though we'll be doing very little HTML parsing in this tutorial and will be mostly working with JSON data directly instead.
These packages can be easily installed via pip command:
$ pip install httpx parsel Alternatively, feel free to swap httpx out with any other HTTP client package such as requests as we'll only need basic HTTP functions which are almost interchangeable in every library. As for, parsel, another great alternative is beautifulsoup package.
How to Remove Glassdoor Overlay
When browsing Glassdoor we are sure to encounter an overlay that requests users to log in:
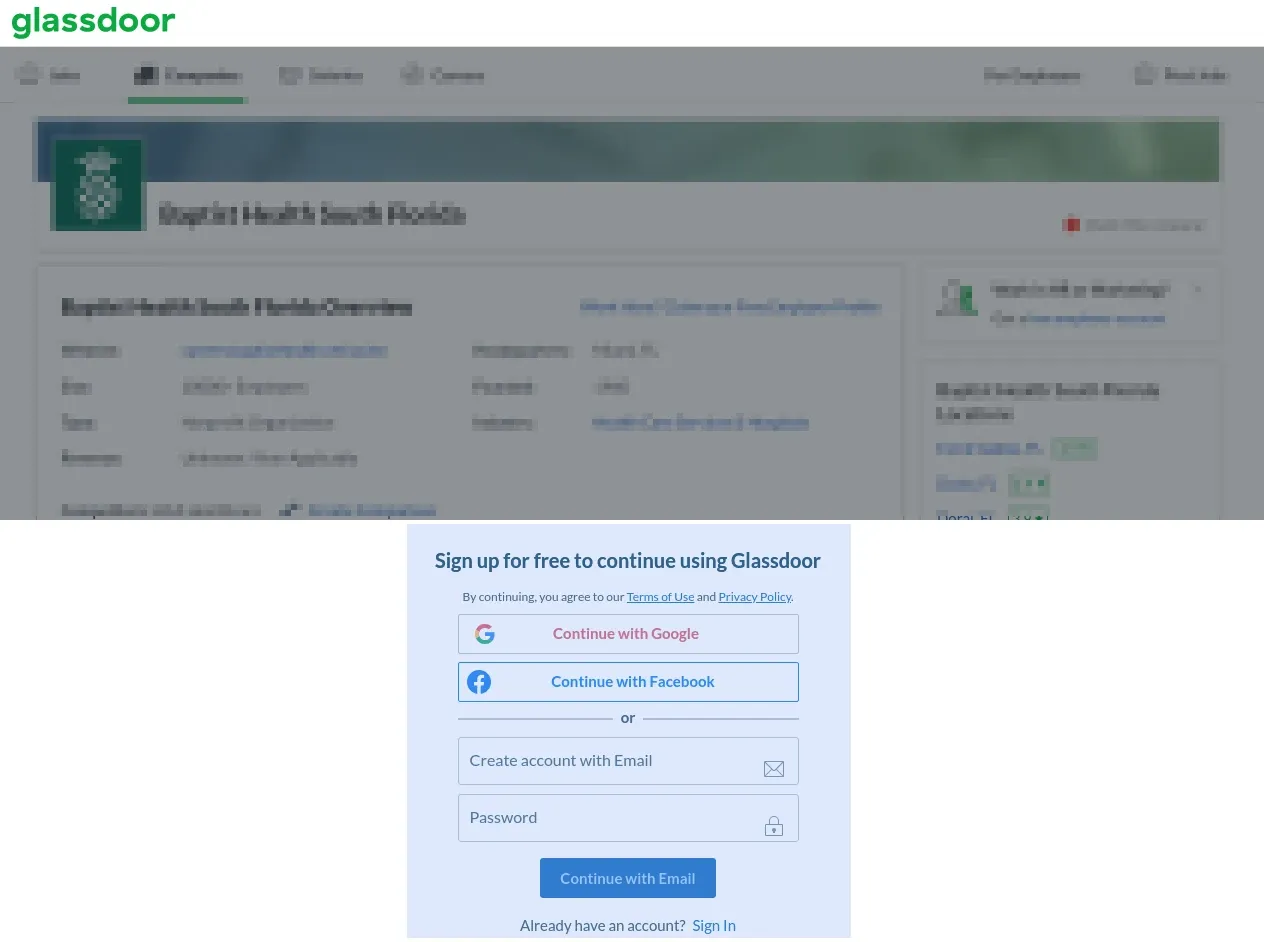
All of the content is still there, it's just covered up by the overlay. So, when scraping our parsing tools will still be able to find this data:
import httpx
from parse import Selector
response = httpx.get(
"https://www.glassdoor.com/Overview/Working-at-eBay-EI_IE7853.11,15.htm"
)
selector = Selector(response.text)
# find description in the HTML:
print(selector.css('[data-test="employerDescription"]::text').get())
# will print:
# eBay is where the world goes to shop, sell, and give. Every day, our professionals connect millions of buyers and sellers around the globe, empowering people and creating opportunity. We're on a mission to build a better, more connected form of commerce that benefits individualsGlassdoor is known for its high blocking rate. So, if you get none values while running the Python code tabs, it's likely to getting blocked. Instead, run the ScrapFly code tabs to avoid Glassdoor scraping blocking.
That being said, while we're developing our web scraper we want to see and inspect the web page. We can easily remove the overlay with a little bit of javascript:
function addGlobalStyle(css) {
var head, style;
head = document.getElementsByTagName('head')[0];
if (!head) { return; }
style = document.createElement('style');
style.type = 'text/css';
style.innerHTML = css;
head.appendChild(style);
}
addGlobalStyle("#HardsellOverlay {display:none !important;}");
addGlobalStyle("body {overflow:auto !important; position: initial !important}");
window.addEventListener("scroll", event => event.stopPropagation(), true);
window.addEventListener("mousemove", event => event.stopPropagation(), true);This script sets a few global CSS styles to hide the overlay and it can be executed either through the web browser's developer tools console (F12 key, console tab).
Alternatively, it can be added to the bookmarks toolbar as a bookmarklet: simply drag this link: glassdoor overlay remover to your bookmarks toolbar and click it to get rid of the overlay at any time:
Selecting Region
Glassdoor operates all around the world and most of its content is region-aware. For example, if we're looking at Ebay's Glassdoor profile on the glassdoor.co.uk website we'll see only job listings relevant to the United Kingdom.
To select the region when web scraping we can either supply a cookie with the selected region's ID:
from parsel import Selector
import httpx
france_location_cookie = {"tldp": "6"}
response = httpx.get(
"https://www.glassdoor.com/Overview/Working-at-eBay-EI_IE7853.11,15.htm",
cookies=france_location_cookie,
follow_redirects=True,
)
selector = Selector(response.text)
# find employee count in the HTML:
print(selector.css('[data-test="employer-size"]::text').get())
# will print:
# Plus de 10 000 employésHow to get country IDs?
All country IDs are present in every glassdoor page HTML which can be extracted with a simple regular expressions pattern:
import re
import json
import httpx
response = httpx.get(
"https://www.glassdoor.com/",
follow_redirects=True,
)
country_data = re.findall(r'"countryMenu\\":.+?(\[.+?\])', response.text)[0].replace('\\', '')
country_data = json.loads(country_data)
for country in country_data:
print(f"{country['textKey']}: {country['id']}")Note that these IDs are unlikely to change so here's the full output:
Argentina: 13
Australia: 5
Belgique (Français): 15
België (Nederlands): 14
Brasil: 9
Canada (English): 3
Canada (Français): 19
Deutschland: 7
España: 8
France: 6
Hong Kong: 20
India: 4
Ireland: 18
Italia: 23
México: 12
Nederland: 10
New Zealand: 21
Schweiz (Deutsch): 16
Singapore: 22
Suisse (Français): 17
United Kingdom: 2
United States: 1
Österreich: 11Some pages however use URL parameters which we'll cover more in the web scraping sections of the article.
Scraping Glassdoor Company Data
In this tutorial, we'll focus on scraping company information such as company overview, job listings, reviews etc. That being said, the techniques covered in this section can be applied to almost any other data page on glassdoor.com
Company IDs
Before we can scrape any specific company data we need to know their internal Glassdoor ID and name. For that, we can use Glassdoor search page recommendations.
For example, if we search for "eBay" we'll see a list of companies with their IDs:
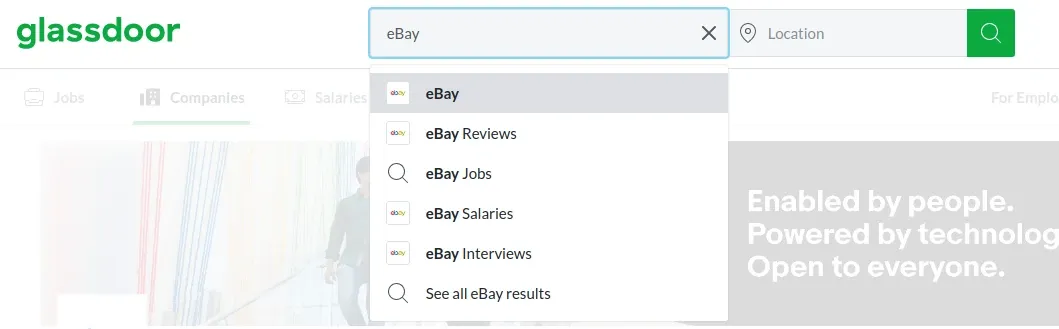
To scrape this in Python we can use the typeahead API endpoint:
import json
import httpx
def find_companies(query: str):
"""find company Glassdoor ID and name by query. e.g. "ebay" will return "eBay" with ID 7853"""
result = httpx.get(
url=f"https://www.glassdoor.com/api-web/employer/find.htm?autocomplete=true&maxEmployersForAutocomplete=50&term={query}",
)
data = json.loads(result.content)
return data
print(find_companies("ebay"))
["eBay", "7853"]import json
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
def find_companies(query: str):
"""find company Glassdoor ID and name by query. e.g. "ebay" will return "eBay" with ID 7853"""
result = client.scrape(
ScrapeConfig(
url=f"https://www.glassdoor.com/api-web/employer/find.htm?autocomplete=true&maxEmployersForAutocomplete=50&term={query}",
country="US",
asp=True,
cookies={"tldp":"1"}, # sets location to US
)
)
data = json.loads(result.content)
return data
print(find_companies("ebay"))
["eBay", "7853"]Now that we can easily retrieve company name id and numeric id we can start scraping company job listings, reviews, salaries etc.
Company Overview
Let's start our scraper by scraping company overview data:
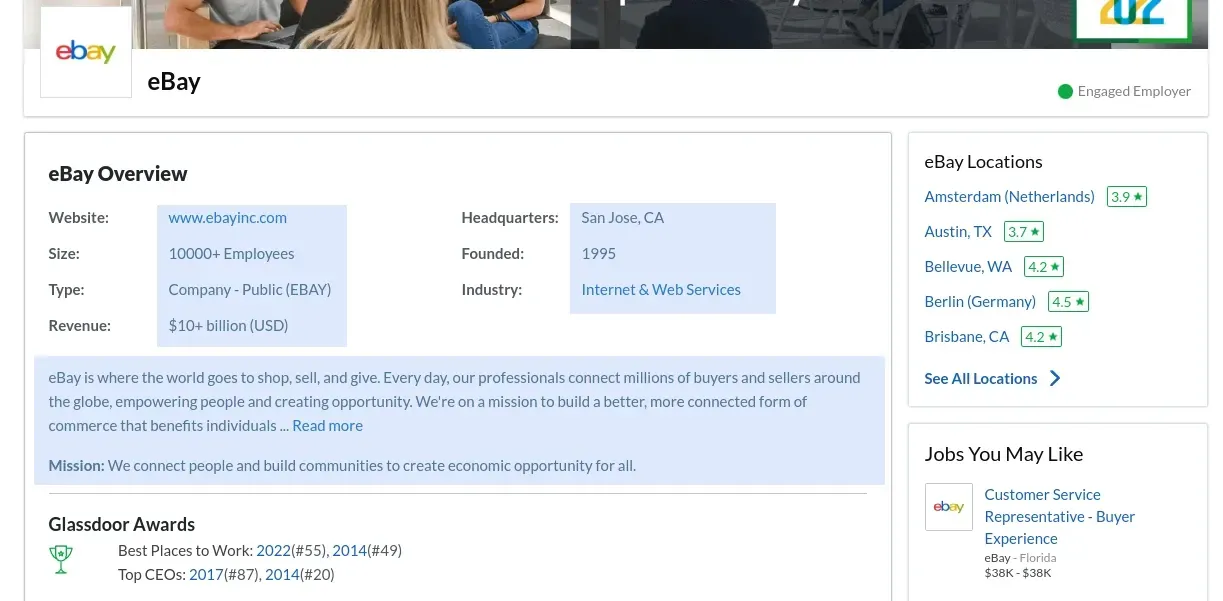
To scrape these details all we need company page URL or generate the URL ourselves using company ID name and number.
import httpx
from parsel import Selector
company_name = "eBay"
company_id = "7671"
url = f"https://www.glassdoor.com/Overview/Working-at-{company_name}-EI_IE{company_id}.htm"
response = httpx.get(
url,
cookies={"tldp": "1"}, # use cookies to force US location
follow_redirects=True
)
sel = Selector(response.text)
print(sel.css("h1::text").get())from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
company_name = "eBay"
company_id = "7671"
url = f"https://www.glassdoor.com/Overview/Working-at-{company_name}-EI_IE{company_id}.htm"
result = client.scrape(ScrapeConfig(url, country="US", cookies={"tldp": "1"}))
print(result.selector.css("h1 ::text").get())To parse company data we can either parse the rendered HTML using traditional HTML parsing tools like BeautifulSoup. However, since Glassdoor is using Apollo Graphql to power their website we can extract hidden JSON web data from the page source.
Advantage of scraping Glassdoor through hidden web data is that we get the full dataset of all the data available on the page. This means we can extract even more data than it's visible on the page and it's already structured for us.
Let's take a look how can we do this with Python:
import re
import httpx
import json
def extract_apollo_state(html):
"""Extract apollo graphql state data from HTML source"""
data = re.findall('apolloState":\s*({.+})};', html)[0]
return json.loads(data)
def scrape_overview(company_name: str, company_id: int) -> dict:
url = f"https://www.glassdoor.com/Overview/Worksgr-at-{company_name}-EI_IE{company_id}.htm"
response = httpx.get(url, cookies={"tldp": "1"}, follow_redirects=True)
apollo_state = extract_apollo_state(response.text)
return next(v for k, v in apollo_state.items() if k.startswith("Employer:"))
print(json.dumps(scrape_overview("7853"), indent=2))import re
import json
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
def extract_apollo_state(html):
"""Extract apollo graphql state data from HTML source"""
data = re.findall('apolloState":\s*({.+})};', html)[0]
return json.loads(data)
def scrape_overview(company_name: str, company_id: str) -> dict:
url = f"https://www.glassdoor.com/Overview/Working-at-{company_name}-EI_IE{company_id}.htm"
result = client.scrape(ScrapeConfig(url, country="US", cookies={"tldp": "1"}))
apollo_state = extract_apollo_state(result.content)
return next(v for k, v in apollo_state.items() if k.startswith("Employer:"))
print(json.dumps(scrape_overview("eBay", "7853"), indent=2))Example Output
{
"__typename": "Employer",
"id": 7853,
"awards({\"limit\":200,\"onlyFeatured\":false})": [
{
"__typename": "EmployerAward",
"awardDetails": null,
"name": "Best Places to Work",
"source": "Glassdoor",
"year": 2022,
"featured": true
},
"... truncated for preview ..."
],
"shortName": "eBay",
"links": {
"__typename": "EiEmployerLinks",
"reviewsUrl": "/Reviews/eBay-Reviews-E7853.htm",
"manageoLinkData": null
},
"website": "www.ebayinc.com",
"type": "Company - Public",
"revenue": "$10+ billion (USD)",
"headquarters": "San Jose, CA",
"size": "10000+ Employees",
"stock": "EBAY",
"squareLogoUrl({\"size\":\"SMALL\"})": "https://media.glassdoor.com/sqls/7853/ebay-squareLogo-1634568971365.png",
"primaryIndustry": {
"__typename": "EmployerIndustry",
"industryId": 200063,
"industryName": "Internet & Web Services"
},
"yearFounded": 1995,
"overview": {
"__typename": "EmployerOverview",
"description": "eBay is where the world goes to shop, sell, and give. Every day, our professionals connect millions of buyers and sellers around the globe, empowering people and creating opportunity. We're on a mission to build a better, more connected form of commerce that benefits individuals, businesses, and society. We create stronger connections between buyers and sellers, offering product experiences that are fast, mobile and secure. At eBay, we develop technologies that enable connected commerce and make every interaction effortless\u2014and more human. And we are doing it on a global scale, providing everyone with the chance to participate and create value.",
"mission": "We connect people and build communities to create economic opportunity for all."
},
"bestProfile": {
"__ref": "EmployerProfile:7925"
},
"employerManagedContent({\"parameters\":[{\"divisionProfileId\":961530,\"employerId\":7853}]})": [
{
"__typename": "EmployerManagedContent",
"diversityContent": {
"__typename": "DiversityAndInclusionContent",
"programsAndInitiatives": {
"__ref": "EmployerManagedContentSection:0"
},
"goals": []
}
}
],
"badgesOfShame": []
}
By parsing the embedded graphQl data we can easily extract the entire company dataset with few lines of code!
Let's take a look at how we can use this technique to scrape other details such as jobs and reviews next.
How to Scrape Glassdoor Job Listings
To scrape job listings we'll also take a look at embedded graphql data though this time we'll be parsing graphql cache rather than state data.
For this, let's take a look at Ebay's Glassdoor jobs page:
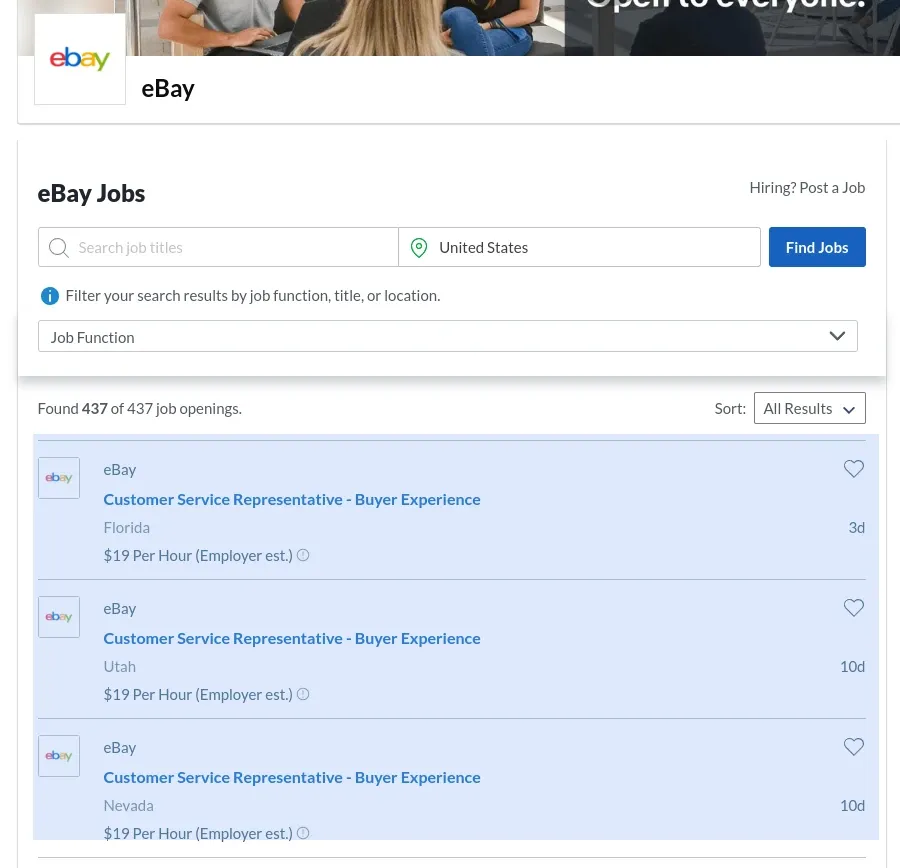
If we look around the page source we can see all of the job data is present in the javascript variable window.appCache in a hidden <script> node:

To extract it, we can use selectors and regular expressions:
def find_hidden_data(result: httpx.Response) -> dict:
"""
Extract hidden web cache (Apollo Graphql framework) from Glassdoor page HTML
It's either in NEXT_DATA script or direct apolloState js variable
"""
# data can be in __NEXT_DATA__ cache
selector = Selector(result.text)
data = selector.css("script#__NEXT_DATA__::text").get()
if data:
data = json.loads(data)["props"]["pageProps"]["apolloCache"]
else: # or in direct apolloState cache
data = re.findall(r'apolloState":\s*({.+})};', result.text)[0]
data = json.loads(data)
def _unpack_apollo_data(apollo_data):
"""
Glassdoor uses Apollo GraphQL client and the dataset is a graph of references.
This function unpacks the __ref references to actual values.
"""
def resolve_refs(data, root):
if isinstance(data, dict):
if "__ref" in data:
return resolve_refs(root[data["__ref"]], root)
else:
return {k: resolve_refs(v, root) for k, v in data.items()}
elif isinstance(data, list):
return [resolve_refs(i, root) for i in data]
else:
return data
return resolve_refs(apollo_data.get("ROOT_QUERY") or apollo_data, apollo_data)
return _unpack_apollo_data(data)Our parser above will take the HTML text, then find a <script> node that contains apolloCache or search for the apolloState through the HTML and extract the cache objects. Let's take a look at how it handles Glassdoor's job page:
import asyncio
import json
import httpx
import re
from typing import Dict, List, Tuple, Optional
from parsel import Selector
from urllib.parse import urljoin
session = httpx.AsyncClient(
timeout=httpx.Timeout(30.0),
cookies={"tldp": "1"},
follow_redirects=True,
)
def find_hidden_data(result: httpx.Response) -> dict:
"""
Extract hidden web cache (Apollo Graphql framework) from Glassdoor page HTML
It's either in NEXT_DATA script or direct apolloState js variable
"""
# data can be in __NEXT_DATA__ cache
selector = Selector(result.text)
data = selector.css("script#__NEXT_DATA__::text").get()
if data:
data = json.loads(data)["props"]["pageProps"]["apolloCache"]
else: # or in direct apolloState cache
data = re.findall(r'apolloState":\s*({.+})};', result.text)[0]
data = json.loads(data)
def _unpack_apollo_data(apollo_data):
"""
Glassdoor uses Apollo GraphQL client and the dataset is a graph of references.
This function unpacks the __ref references to actual values.
"""
def resolve_refs(data, root):
if isinstance(data, dict):
if "__ref" in data:
return resolve_refs(root[data["__ref"]], root)
else:
return {k: resolve_refs(v, root) for k, v in data.items()}
elif isinstance(data, list):
return [resolve_refs(i, root) for i in data]
else:
return data
return resolve_refs(apollo_data.get("ROOT_QUERY") or apollo_data, apollo_data)
return _unpack_apollo_data(data)
def parse_jobs(result: httpx.Response) -> Tuple[List[Dict], List[str]]:
"""Parse Glassdoor jobs page for job data and other page pagination urls"""
cache = find_hidden_data(result)
job_cache = next(v for k, v in cache.items() if k.startswith("jobListings"))
jobs = [v["jobview"]["header"] for v in job_cache["jobListings"]]
other_pages = [
urljoin(result.context["url"], page["urlLink"])
for page in job_cache["paginationLinks"]
if page["isCurrentPage"] is False
]
return jobs, other_pages
def change_page(url: str, page: int) -> str:
"""update page number in a glassdoor url"""
new = re.sub("(?:_P\d+)*.htm", f"_P{page}.htm", url)
assert new != url
return new
async def scrape_jobs(employer_name: str, employer_id: str, max_pages: Optional[int] = None) -> List[Dict]:
"""Scrape job listings"""
# scrape first page of jobs:
first_page = await session.get(
url=f"https://www.glassdoor.com/Jobs/{employer_name}-Jobs-E{employer_id}.htm?filter.countryId={session.cookies.get('tldp') or 0}",
)
jobs, other_page_urls = parse_jobs(first_page)
_total_pages = len(other_page_urls) + 1
if max_pages and _total_pages > max_pages:
other_page_urls = other_page_urls[:max_pages]
print(f"scraped first page of jobs, scraping remaining {_total_pages - 1} pages")
other_pages = [
session.get(
url=change_page(first_page.url, page),
)
for page in range(2, _total_pages + 1)
]
for result in await asyncio.gather(*other_pages):
jobs.extend(parse_jobs(result)[0])
return jobs
async def main():
jobs = await scrape_jobs("eBay", "7853")
print(json.dumps(jobs, indent=2))import asyncio
import json
import re
from typing import Dict, List, Optional, Tuple
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
from urllib.parse import urljoin
client = ScrapflyClient(key="YOUR SCRAPFLY KEY")
BASE_CONFIG = {
"country": "US",
"asp": True,
"cookies": {"tldp": "1"}
}
def find_hidden_data(result: ScrapeApiResponse) -> dict:
"""
Extract hidden web cache (Apollo Graphql framework) from Glassdoor page HTML
It's either in NEXT_DATA script or direct apolloState js variable
"""
# data can be in __NEXT_DATA__ cache
data = result.selector.css("script#__NEXT_DATA__::text").get()
if data:
data = json.loads(data)["props"]["pageProps"]["apolloCache"]
else: # or in direct apolloState cache
data = re.findall(r'apolloState":\s*({.+})};', result.content)[0]
data = json.loads(data)
def _unpack_apollo_data(apollo_data):
"""
Glassdoor uses Apollo GraphQL client and the dataset is a graph of references.
This function unpacks the __ref references to actual values.
"""
def resolve_refs(data, root):
if isinstance(data, dict):
if "__ref" in data:
return resolve_refs(root[data["__ref"]], root)
else:
return {k: resolve_refs(v, root) for k, v in data.items()}
elif isinstance(data, list):
return [resolve_refs(i, root) for i in data]
else:
return data
return resolve_refs(apollo_data.get("ROOT_QUERY") or apollo_data, apollo_data)
return _unpack_apollo_data(data)
def parse_jobs(result: ScrapeApiResponse) -> Tuple[List[Dict], List[str]]:
"""Parse Glassdoor jobs page for job data and other page pagination urls"""
cache = find_hidden_data(result)
job_cache = next(v for k, v in cache.items() if k.startswith("jobListings"))
jobs = [v["jobview"]["header"] for v in job_cache["jobListings"]]
other_pages = [
urljoin(result.context["url"], page["urlLink"])
for page in job_cache["paginationLinks"]
if page["isCurrentPage"] is False
]
return jobs, other_pages
def change_page(url: str, page: int) -> str:
"""update page number in a glassdoor url"""
new = re.sub("(?:_P\d+)*.htm", f"_P{page}.htm", url)
assert new != url
return new
async def scrape_jobs(employer: str, employer_id: str, max_pages: Optional[int] = None) -> List[Dict]:
"""Scrape job listings"""
first_page_url = f"https://www.glassdoor.com/Jobs/{employer}-Jobs-E{employer_id}.htm?filter.countryId={BASE_CONFIG['cookies']['tldp']}"
first_page = await client.async_scrape(ScrapeConfig(url=first_page_url, **BASE_CONFIG))
jobs, other_page_urls = parse_jobs(first_page)
_total_pages = len(other_page_urls) + 1
if max_pages and _total_pages > max_pages:
other_page_urls = other_page_urls[:max_pages]
print(f"scraped first page of jobs, scraping remaining {_total_pages - 1} pages")
other_pages = [
ScrapeConfig(url=change_page(first_page.context["url"], page=page), **BASE_CONFIG)
for page in range(2, _total_pages + 1)
]
async for result in client.concurrent_scrape(other_pages):
jobs.extend(parse_jobs(result)[0])
return jobs
async def run():
"""this is example demo run that'll scrape US jobs, reviews and salaries for ebay and save results to ./results/*.json files"""
emp_name, emp_id = "ebay", "7853"
ebay_jobs_in_US = await scrape_jobs(emp_name, emp_id, max_pages=2)
print(json.dumps(ebay_jobs_in_US, indent=2))
if __name__ == "__main__":
asyncio.run(run())Above, we have a scraper that goes through a classic pagination scraping algorithm:
- Scrape the first jobs page
- Extract GraphQl cache for jobs data
- Parse HTML for total page count
- Scrape remaining pages concurrently
If we run our scraper, we should get all of the job listings in no time!
Example Output
[
{
"header": {
"adOrderId": 1281260,
"advertiserType": "EMPLOYER",
"ageInDays": 0,
"easyApply": false,
"employer": {
"id": 7853,
"name": "eBay inc.",
"shortName": "eBay",
"__typename": "Employer"
},
"goc": "machine learning engineer",
"gocConfidence": 0.9,
"gocId": 102642,
"jobLink": "/partner/jobListing.htm?pos=140&ao=1281260&s=21&guid=0000018355c715f3b12a6090d334a7dc&src=GD_JOB_AD&t=ESR&vt=w&cs=1_9a5bdc18&cb=1663591454509&jobListingId=1008147859269&jrtk=3-0-1gdase5jgjopr801-1gdase5k2irmo800-952fa651f152ade0-",
"jobTitleText": "Sr. Manager, AI-Guided Service Products",
"locationName": "Salt Lake City, UT",
"divisionEmployerName": null,
"needsCommission": false,
"payCurrency": "USD",
"payPercentile10": 75822,
"payPercentile25": 0,
"payPercentile50": 91822,
"payPercentile75": 0,
"payPercentile90": 111198,
"payPeriod": "ANNUAL",
"salarySource": "ESTIMATED",
"sponsored": true,
"__typename": "JobViewHeader"
},
"job": {
"importConfigId": 322429,
"jobTitleText": "Sr. Manager, AI-Guided Service Products",
"jobTitleId": 0,
"listingId": 1008147859269,
"__typename": "JobDetails"
},
"jobListingAdminDetails": {
"cpcVal": null,
"jobListingId": 1008147859269,
"jobSourceId": 0,
"__typename": "JobListingAdminDetailsVO"
},
"overview": {
"shortName": "eBay",
"squareLogoUrl": "https://media.glassdoor.com/sql/7853/ebay-squareLogo-1634568971326.png",
"__typename": "Employer"
},
"__typename": "JobView"
},
"..."
]Now that we understand how Glassdoor works let's take a look at how we can grab other details available in the graphql cache like reviews.
How to Scrape Glassdoor Company Reviews
To scrape reviews we'll take a look at another graphql feature - page state data.
Just like how we found graphql cache in the page HTML we can also find graphql state:

So, to scrape reviews we can parse graphql state data which contains all of the reviews, review metadata and loads of other data details:
import asyncio
import re
import json
from typing import Tuple, List, Dict
import httpx
def extract_apollo_state(html):
"""Extract apollo graphql state data from HTML source"""
data = re.findall('apolloState":\s*({.+})};', html)[0]
data = json.loads(data)
return data
def parse_reviews(html) -> Tuple[List[Dict], int]:
"""parse jobs page for job data and total amount of jobs"""
cache = extract_apollo_state(html)
xhr_cache = cache["ROOT_QUERY"]
reviews = next(v for k, v in xhr_cache.items() if k.startswith("employerReviews") and v.get("reviews"))
return reviews
async def scrape_reviews(employer: str, employer_id: str, session: httpx.AsyncClient):
"""Scrape job listings"""
# scrape first page of jobs:
first_page = await session.get(
url=f"https://www.glassdoor.com/Reviews/{employer}-Reviews-E{employer_id}.htm",
)
reviews = parse_reviews(first_page.text)
# find total amount of pages and scrape remaining pages concurrently
total_pages = reviews["numberOfPages"]
print(f"scraped first page of reviews, scraping remaining {total_pages - 1} pages")
other_pages = [
session.get(
url=str(first_page.url).replace(".htm", f"_P{page}.htm"),
)
for page in range(2, total_pages + 1)
]
for page in await asyncio.gather(*other_pages):
page_reviews = parse_reviews(page.text)
reviews["reviews"].extend(page_reviews["reviews"])
return reviewsRun Code & Example Output
We can run our Glassdoor scraper the same as before:
async def main():
async with httpx.AsyncClient(
timeout=httpx.Timeout(30.0),
cookies={"tldp": "1"},
follow_redirects=True,
) as client:
reviews = await scrape_reviews("eBay", "7853", client)
print(json.dumps(reviews, indent=2))
asyncio.run(main())Which will produce results similar to:
{
"__typename": "EmployerReviews",
"filteredReviewsCountByLang": [
{
"__typename": "ReviewsCountByLanguage",
"count": 4109,
"isoLanguage": "eng"
},
"..."
],
"employer": {
"__ref": "Employer:7853"
},
"queryLocation": null,
"queryJobTitle": null,
"currentPage": 1,
"numberOfPages": 411,
"lastReviewDateTime": "2022-09-16T14:51:36.650",
"allReviewsCount": 5017,
"ratedReviewsCount": 4218,
"filteredReviewsCount": 4109,
"ratings": {
"__typename": "EmployerRatings",
"overallRating": 4.1,
"reviewCount": 4218,
"ceoRating": 0.87,
"recommendToFriendRating": 0.83,
"cultureAndValuesRating": 4.2,
"diversityAndInclusionRating": 4.3,
"careerOpportunitiesRating": 3.8,
"workLifeBalanceRating": 4.1,
"seniorManagementRating": 3.7,
"compensationAndBenefitsRating": 4.1,
"businessOutlookRating": 0.66,
"ceoRatingsCount": 626,
"ratedCeo": {
"__ref": "Ceo:768619"
}
},
"reviews": [
{
"__typename": "EmployerReview",
"isLegal": true,
"reviewId": 64767391,
"reviewDateTime": "2022-05-27T08:41:43.217",
"ratingOverall": 5,
"ratingCeo": "APPROVE",
"ratingBusinessOutlook": "POSITIVE",
"ratingWorkLifeBalance": 5,
"ratingCultureAndValues": 5,
"ratingDiversityAndInclusion": 5,
"ratingSeniorLeadership": 5,
"ratingRecommendToFriend": "POSITIVE",
"ratingCareerOpportunities": 5,
"ratingCompensationAndBenefits": 5,
"employer": {
"__ref": "Employer:7853"
},
"isCurrentJob": true,
"lengthOfEmployment": 1,
"employmentStatus": "REGULAR",
"jobEndingYear": null,
"jobTitle": {
"__ref": "JobTitle:60210"
},
"location": {
"__ref": "City:1139151"
},
"originalLanguageId": null,
"pros": "Thorough training, compassionate and very patient with all trainees. Benefits day one. Inclusive and really work with their employees to help them succeed in their role.",
"prosOriginal": null,
"cons": "No cons at all! So far everything is great!",
"consOriginal": null,
"summary": "Excellent Company",
"summaryOriginal": null,
"advice": null,
"adviceOriginal": null,
"isLanguageMismatch": false,
"countHelpful": 2,
"countNotHelpful": 0,
"employerResponses": [],
"isCovid19": false,
"divisionName": null,
"divisionLink": null,
"topLevelDomainId": 1,
"languageId": "eng",
"translationMethod": null
},
"..."
]
}Other Glassdoor Scraping Details
The embedded graphql data parsing techniques we've learned through the Glassdoor review and job scraping can applied to scrape other company details like salaries, interviews, benefits and photos.
For example, we can scrape Glassdoor salary data in the same way we scraped the reviews earlier:
import httpx
import json
import asyncio
from typing import Dict, Optional
def parse_salaries(result) -> Dict:
"""Parse Glassdoor salaries page for salary data"""
cache = find_hidden_data(result)
salaries = next(v for k, v in cache.items() if k.startswith("aggregatedSalaryEstimates") and v.get("results"))
return salaries
async def scrape_salaries(session: httpx.AsyncClient, url: str, max_pages: Optional[int] = None) -> Dict:
"""Scrape Glassdoor Salary page for salary listing data (with pagination)"""
print("scraping salaries from {}", url)
first_page = await session.get(url)
assert first_page.status_code == 200, "request is blocked, use ScrapFly code tab"
salaries = parse_salaries(first_page)
total_pages = salaries["numPages"]
if max_pages and total_pages > max_pages:
total_pages = max_pages
print("scraped first page of salaries of {}, scraping remaining {} pages", url, total_pages - 1)
other_pages = [
session.get(
url=change_page(str(first_page.url), page=page)
)
for page in range(2, total_pages + 1)
]
for result in await asyncio.gather(*other_pages):
salaries["results"].extend(parse_salaries(result)["results"])
return salariesimport json
import asyncio
from typing import Dict, Optional
from scrapfly import ScrapeApiResponse, ScrapeConfig, ScrapflyClient
client = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# Glassdoor.com requires Anti Scraping Protection bypass feature.
# for more: https://scrapfly.io/docs/scrape-api/anti-scraping-protection
"asp": True,
"country": "US",
}
def parse_salaries(result: ScrapeApiResponse) -> Dict:
"""Parse Glassdoor salaries page for salary data"""
cache = find_hidden_data(result)
salaries = next(v for k, v in cache.items() if k.startswith("aggregatedSalaryEstimates") and v.get("results"))
return salaries
async def scrape_salaries(url: str, max_pages: Optional[int] = None) -> Dict:
"""Scrape Glassdoor Salary page for salary listing data (with pagination)"""
print("scraping salaries from {}", url)
first_page = await client.async_scrape(ScrapeConfig(url=url, **BASE_CONFIG))
salaries = parse_salaries(first_page)
total_pages = salaries["numPages"]
if max_pages and total_pages > max_pages:
total_pages = max_pages
print("scraped first page of salaries of {}, scraping remaining {} pages", url, total_pages - 1)
other_pages = [
ScrapeConfig(url=change_page(first_page.context["url"], page=page), **BASE_CONFIG)
for page in range(2, total_pages + 1)
]
async for result in client.concurrent_scrape(other_pages):
salaries["results"].extend(parse_salaries(result)["results"])
return salaries
async def main():
url = "https://www.glassdoor.com/Salary/eBay-Salaries-E7853.htm"
result_salaries = await scrape_salaries(url, max_pages=3)
# save to JSON
with open("salary.json", "w", encoding="utf-8") as f:
json.dump(result_salaries, f, indent=2, ensure_ascii=False)
asyncio.run(main())Run the code
async def main():
session = httpx.AsyncClient(
timeout=httpx.Timeout(30.0),
cookies={"tldp": "1"},
follow_redirects=True,
)
url = "https://www.glassdoor.com/Salary/eBay-Salaries-E7853.htm"
result_salaries = await scrape_salaries(session, url, max_pages=3)
# save to JSON
with open("salary.json", "w", encoding="utf-8") as f:
json.dump(result_salaries, f, indent=2, ensure_ascii=False)
asyncio.run(main())By understanding how Glassdoor web infrastructure works we can easily collect all of the public company datasets available on Glassdoor.
However, when collecting all of this data at scale we're very likely to be blocked, so let's take a look at how we can avoid blocking by using ScrapFly API.
Bypass Glassdoor Scraping Blocking
ScrapFly offers several powerful features that'll help us to get around Glassdoor scraper blocking:
For this, we'll be using the ScrapFly SDK python package. To start, let's install scrapfly-sdk using pip:
$ pip install scrapfly-sdkTo convert our httpx powered code to use ScrapFly SDK all we have to do is replace our httpx requests with SDK ones:
from scrapfly import ScrapflyClient, ScrapeConfig
client = ScrapflyClient(key='YOUR_SCRAPFLY_KEY')
result = client.scrape(ScrapeConfig(
url="https://www.glassdoor.com/Salary/eBay-Salaries-E7853.htm",
# we can enable anti-scraper protection bypass:
asp=True,
# or select proxies from specific countries:
country="US",
# and change proxy types:
proxy_pool="public_residential_pool",
))For extended example of using ScrapFly to scrape glassdoor, see the Full Scraper Code section.
FAQ
Is it legal to scrape Glassdoor?
Yes. Data displayed on Glassdoor is publicly available, and we're not extracting anything private. Scraping Glassdoor.com at slow, respectful rates would fall under the ethical scraping definition. That being said, attention should be paid to GDRP compliance in the EU when scraping data submitted by its users such as reviews. For more, see our Is Web Scraping Legal? article.
Can I scrape Glassdoor Reviews without login?
Yes, glassdoor reviews are public and accessible without the need to login though Glassdoor front-end limits the number of reviews visible or blocks the view with a modal. The modal can be disabled when scraping or viewing with javascript mentioned in this article and paging limit does not apply to scrapers.
How to find all company pages listed on Glassdoor?
Glassdoor contains over half a million US companies alone but doesn't have a sitemap. Though it does contain multiple limited directory pages like directory for US companies. Unfortunately, directory pages are limited to a few hundred pages though with crawling and filtering it's possible to discover all of the pages.
Another approach that we covered in this web scraping Glassdoor tutorial is to discover company pages through company IDS. Each company on Glassdoor is assigned an incremental ID in the range of 1000-1_000_000+. Using HEAD-type requests we can easily poke each of these IDs to see whether they lead to company pages.
How to view Glassdoor without account?
To view Glassdoor pages without account disable glassdoor overlay using javascript. In this article, we're using a simple javascript bookmarklet but this can be done with any tools that is capable of executing javascript like browser console.
Glassdoor Scraping Summary
In this web scraping tutorial, we've taken a look at how we can scrape Glassdoor for various details details, such as metadata, review, job listings and salaries.
We did this by taking advantage of graphql cache and state data which we extracted with a few generic web scraping algorithms in plain Python.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


