G2.com is a leading website for software product and service data. It features thousands of product profiles, their reviews and alternative suggestions in various categories. However, due to the high protection level and the heavy use of CAPTCHA challenges, scraping G2.com can be challenging.
In this article, we'll explore web scraping G2. We'll explain how to scrape company data, reviews and alternatives from the website without getting blocked. We'll also use some web scraping tricks to make our scraper resilient, such as error handling and retrying logic. Let's get started!
Key Takeaways
Learn to scrape G2.com software reviews and company data using Python with ScrapFly SDK, bypassing Datadome protection and CAPTCHA challenges for comprehensive business intelligence.
- Use ScrapFly SDK to bypass G2's Datadome anti-scraping protection and CAPTCHA challenges automatically
- Parse HTML with XPath and CSS selectors to extract software product reviews and company information
- Handle G2's heavy anti-bot measures with proper error handling and retry logic implementation
- Extract structured data including product ratings, reviews, alternative suggestions, and company profiles
- Implement asynchronous scraping with proper rate limiting to avoid triggering additional security measures
- Use robust error handling to manage blocked requests and maintain scraper stability
Latest G2.com Scraper Code
Why Scrape G2?
G2 provides comprehensive software product and service details as well as metadata, review and alternative information with detailed pros/cons comparisons. So, if you are looking to become a customer, scrapping G2's company data can help in decision-making and product comparisons.
Web Scraping G2's reviews can also be a good resource for developing Machine Learning models. Companies can analyze these reviews through sentiment analysis to gain insights into specific companies or market niches.
Moreover, manually exploring tens of company review pages on the website can be tedious and time-consuming. Therefore, scraping G2 can save a lot of manual effort by quickly retrieving thousands of reviews.
Project Setup
To scrape G2.com, we'll use a few Python packages:
scrapfly-sdkfor bypassing G2 anti-scraping challenges and blocking.asyncfor increasing our web scraping speed by running our code asynchronously.
Note that asyncio comes pre-installed in Python, you will only have to install the other packages using the following pip command:
pip install scrapfly-sdkAvoid G2 Web Scraping Blocking
G2 heavily relies on How to Bypass Datadome Anti Scraping in 2026 challenges to prevent scraping. For example, let's send a simple request to the website using How to Web Scrape with HTTPX and Python. We'll use headers similar to real browsers to decrease the chance of getting detected and blocked:
from httpx import Client
# initializing an httpx client
client = Client(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"accept-language": "en-US,en;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US;en;q=0.9",
"accept-encoding": "gzip, deflate, br",
}
)
response = client.get("https://www.g2.com")
print(response)
"<Response [403 Forbidden]>"The above requests get detected and required to solve a CAPTCHA challenge:

To scrape G2 without getting blocked we don't actually need to solve the captcha. We're just not going to get it at all! For that, we'll use ScrapFly - a web scraping API that allows for scraping at scale by providing:
- Cloud headless browsers - for scraping dynamically loaded content with running headless browsers yourself.
- Anti scraping protection bypass - for bypassing any website scraping blocking.
- Residential proxies from over 50+ countries - for avoiding IP address blocking and throttling, while also allowing for scraping from almost any geographic location.
- And much more!
By using the Scrapfly's asp feature with the ScrapFly SDK. We can easily bypass G2 scraper blocking:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
api_response: ScrapeApiResponse = scrapfly.scrape(
ScrapeConfig(
# some g2 URL
url="https://www.g2.com",
# cloud headless browser similar to Playwright
render_js=True,
# bypass anti scraping protetion
asp=True,
# set the geographical location to a specific country
country="US",
)
)
# Print the website's status code
print(api_response.upstream_status_code)
"200"We'll use ScrapFly as our HTTP client for the rest of the article. So, to follow along, you need to get a ScrapFly API key 👇
How to Scrape G2 Search Pages
Let's start by scraping search pages on G2. Use the search bar to search for any keyword on the website and you will get a page similar to this:
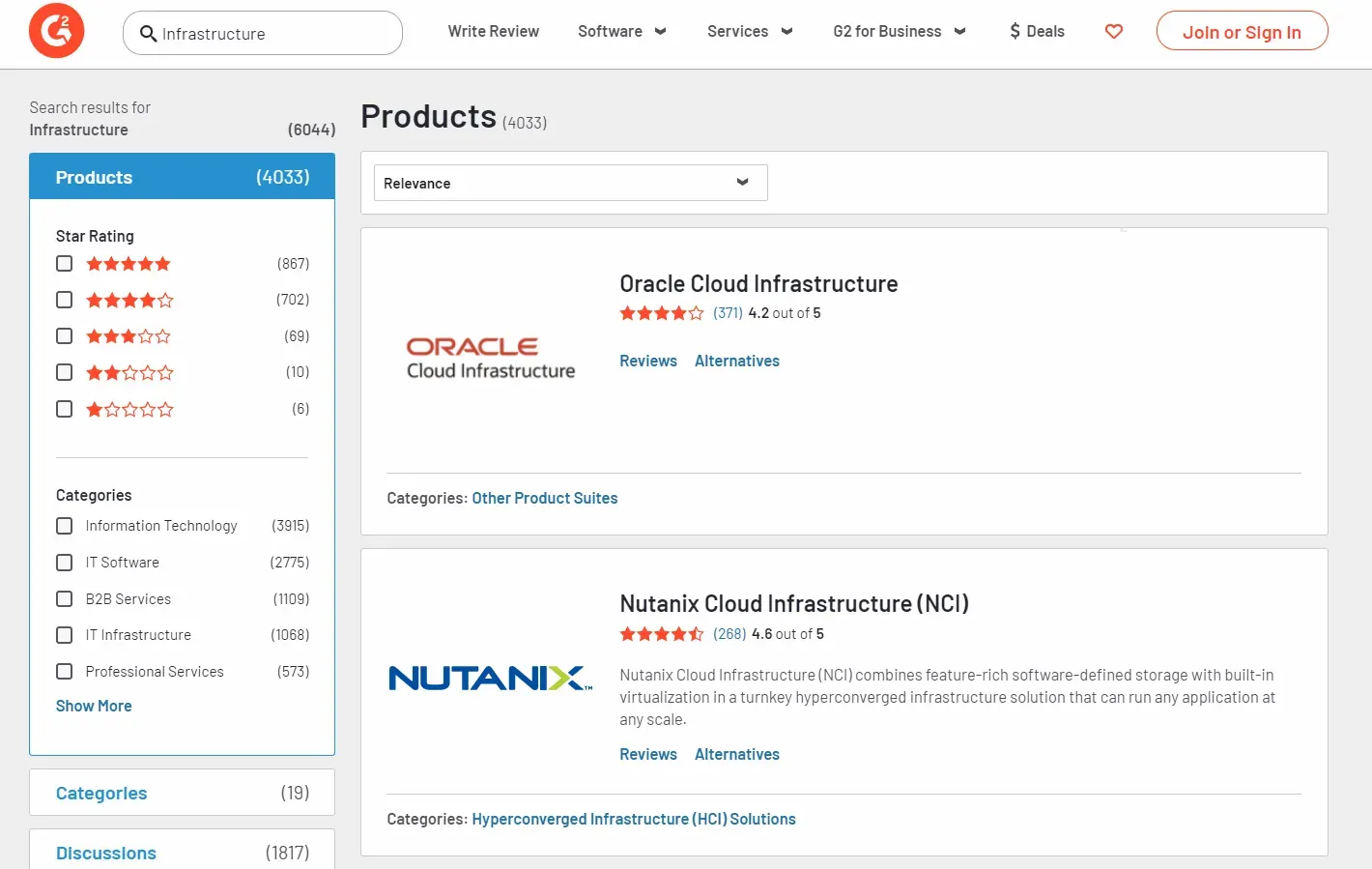
The search pages support pagination by adding a page parameter at the URL:
https://www.g2.com/search?query=Infrastructure&page=2The above parameter can be used for crawling over search pages.
We'll request the search pages using ScrapFly and use the function we created to parse the data from the HTML:
Here, we've added a scrape_search() function that sends a request to the first search page using the ScarpFly client. Then, we extract its data using the parse_search_page() function we defined earlier. We also defined a parse_search_page() function, which parses the company data from the page HTML using XPath selectors. We also extract the total search results to get the number of total pages, which we'll use later to crawl over search pagination.
As for pagination crawling, we add the remaining search page URLs to a scraping list and scrape them concurrently. Next, we remove the successful requests from the URL list and extend the first page data with the new ones.
Here is a sample output of the result we got:
Sample output
[
{
"name": "Oracle Cloud Infrastructure",
"link": "https://www.g2.com/products/oracle-oracle-cloud-infrastructure/reviews",
"image": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_2753ea8c7953188158425365667be750/oracle-oracle-cloud-infrastructure.png",
"rate": 4.2,
"reviewsNumber": 371,
"description": null,
"categories": [
"Other Product Suites"
]
},
....
]Our G2 scraper can successfully scrape company data from search pages. Let's scrape company reviews next.
How to Scrape G2 Company Reviews
In this section, we'll scrape company reviews from their pages. Before we start, let's have a look at the G2 review pages. Go to any company or product page on the website, such as digitalocean page and you will find the reviews that should look like this:
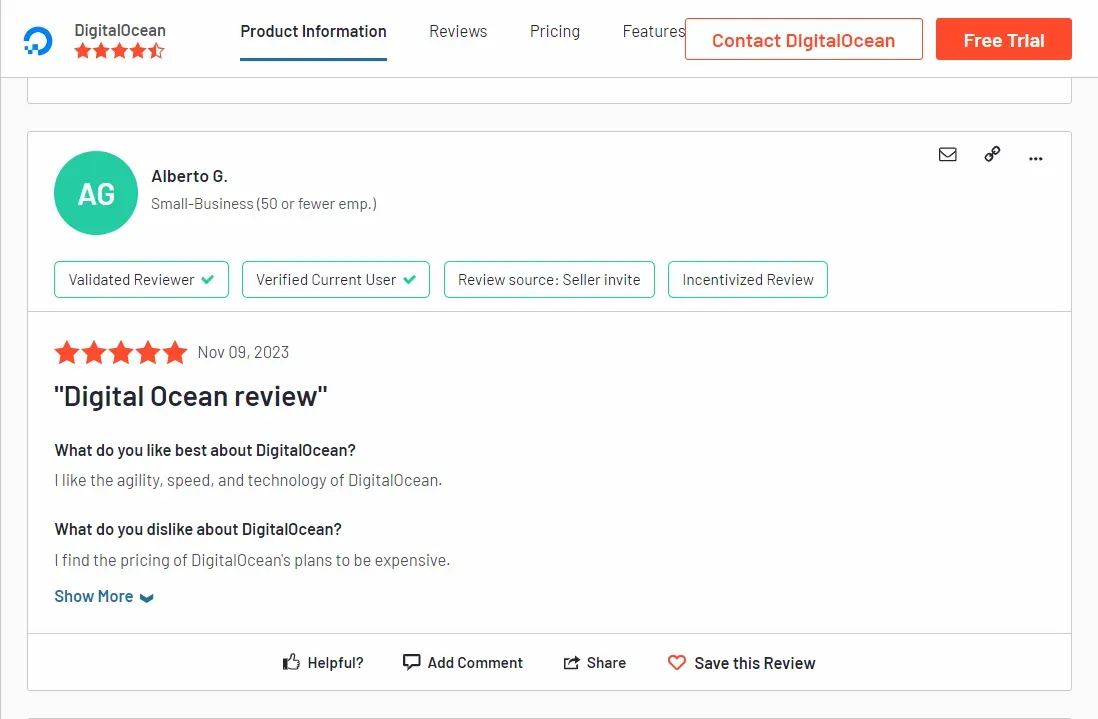
Review pages also support pagination by adding the same page parameter:
https://www.g2.com/products/digitalocean/reviews?page=2Since each review page contains 25 reviews, we'll iterate over the review cards to extract each review data. Like we did earlier with search pages, we'll request the first page and then crawl over the remaining ones:
The above code is similar to the G2 search scraping logic we wrote earlier. We start by scraping the first review page and the total number of reviews. Next, we add the remaining review pages to a scraping list and scrape them concurrently. Finally, we save the result to a JSON file.
Here is a sample output of the result we got:
Sample output
[
{
"author": {
"authorName": "Marlon P.",
"authorProfile": "https://www.g2.com/users/d523e9ac-7e5b-453f-85f8-9ab05b27a556",
"authorPosition": "Desenvolvedor de front-end",
"authorCompanySize": []
},
"review": {
"reviewTags": [
"Validated Reviewer",
"Verified Current User",
"Review source: Seller invite",
"Incentivized Review"
],
"reviewData": "2023-11-14",
"reviewRate": 4.5,
"reviewTitle": "Good for beginners",
"reviewLikes": "It was very simple to start playing around and be able to test the projects I'm learning about for a cool price. I use it at work and it's easy to create new machines. Initial configuration is simple with the app Free tier is so short. is now than the company need money but, for me 90 days it was very fast to user the credits. \n\nThere is an app configuration file that I find very annoying to configure. It would be cool if there was a way to test that locally. I've had a lot of problems that doing several deployments in production to see my app's configuration is ok. leave personal projects public. And in the company, when I have to use it, I find it very simple to use the terminal via the platform ",
"reviewDilikes": "Free tier is so short. is now than the company need money but, for me 90 days it was very fast to user the credits. \n\nThere is an app configuration file that I find very annoying to configure. It would be cool if there was a way to test that locally. I've had a lot of problems that doing several deployments in production to see my app's configuration is ok. "
}
},
....
]Our G2 scraper can successfully scrape review pages. Next, we'll scrape company competitor pages for company alternative listings.
How to Scrape G2 Company Alternatives
G2 company competitor pages offer detailed company product comparisons. However, we'll be focusing on the company's alternative listings. However, other comparison details can be scraped in the same way.
First, go to any company alternative page, like the digitalocean alternatives page. The company alternatives listing should look like this:
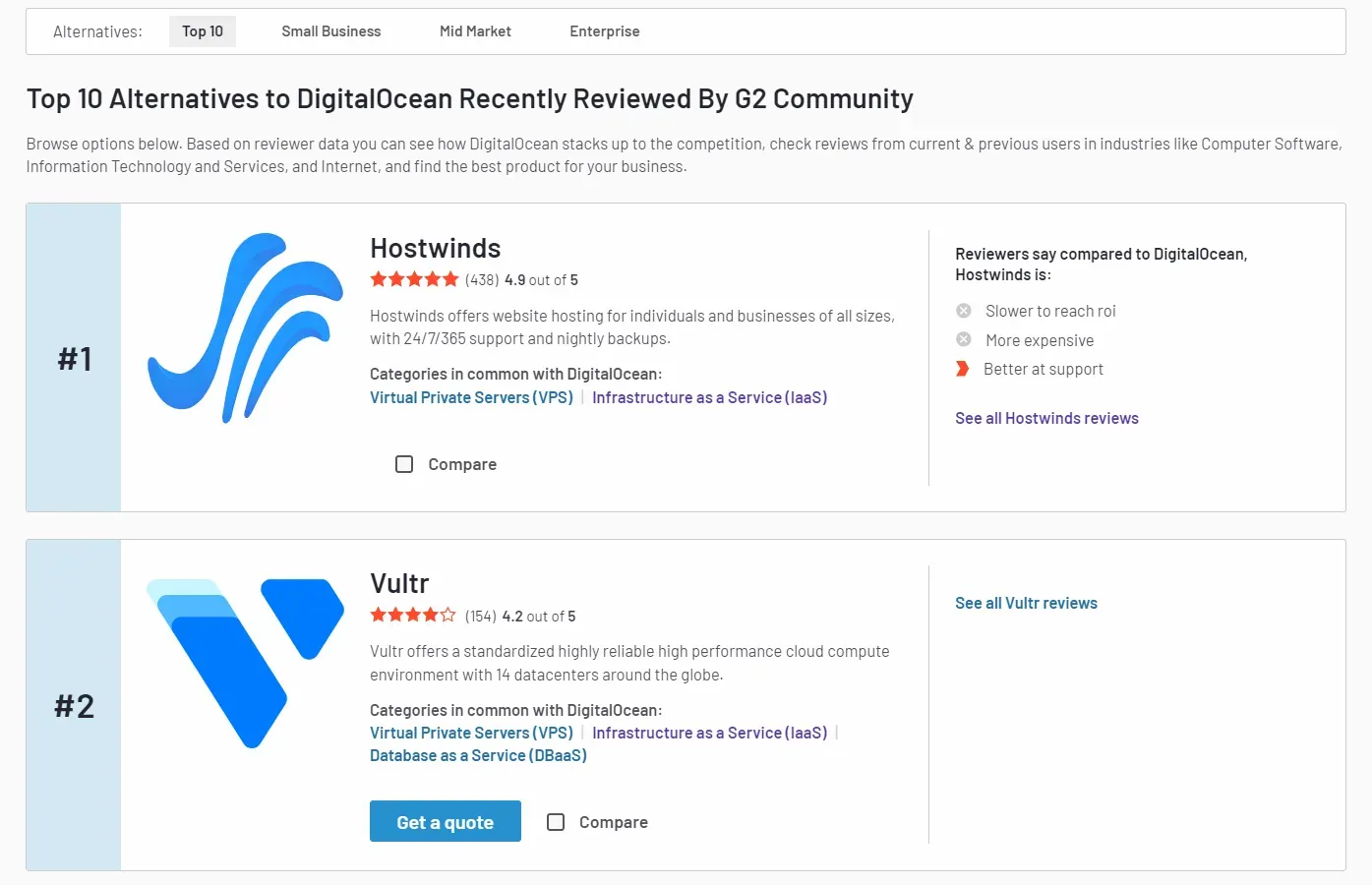
As we can see from the image, the company listings can be narrowed down according to a specific market niche, like small business, mid-market and enterprise alternatives. While the default URL represents the top 10 alternatives filter, we can apply other filters by adding the filter name at the end of the URL:
https://www.g2.com/products/digitalocean/competitors/alternatives/small-businessWe'll make use of this filter to control the G2 scraping alternatives:
Above, we define a parse_alternatives() function. It iterates over the alternative cards in the HTML and extracts the company listings data from each card. It extracts the data from the HTML after we request alternative page URL.
Here is a sample output of the result we got:
Sample output
[
{
"name": "Hostwinds",
"link": "https://www.g2.com/products/hostwinds/reviews",
"ranking": "#1",
"numberOfReviews": 438,
"rate": 4.9,
"description": "Hostwinds offers website hosting for individuals and businesses of all sizes, with 24/7/365 support and nightly backups."
},
....
]With this last piece, our G2 scraper is complete! It can scrape company data from search, competitor and review pages on G2.com. There are pages on the website that are worth scraping, such as detailed company comparison pages. These pages can be scraped by following the steps in our previous G2 scraping code snippets.
FAQ
Is it legal to scrape G2?
Yes, all the data on G2.com is publicly available and it's legal to scrape as long as the website is not harmed in the process. However, commercializing personal data such as reviewers' emails may violate GDPR compliance in the EU countries. Refer to our previous article on web scraping legality for more details.
Is there a public API for G2.com?
At the time of writing, there are no public APIs for G2 we can use for web scraping. Though G2's HTML is pretty descriptive, making scraping it through HTML parsing viable.
Are there alternatives for G2?
Yes, Trustpilot.com is another popular website for company reviews. Refer to our #scrapeguide blog tag for its scraping guide and for other related web scraping guides.
Web Scraping G2 - Summary
G2.com is a global website for company reviews and comparisons, known for its high protection level.
We explained how to avoid G2 scraping blocking using ScrapFly. We also went through a step-by-step guide on how to scrape G2 using Python. We have used HTML parsing to scrape search, review and competitor pages on G2.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.