How to Ignore cURL SSL Errors
Learn to handle SSL errors in cURL, including using self-signed certificates. Explore common issues, safe practices.
In this guide, we'll explain how to copy requests as cURL with Edge. We'll copy the requests on review data on web-scraping.dev. However, the same approach can be applied to other websites as well:
Open the browser developer tools on Edge by pressing the F12 key.
Empty the request log (Ctrl + L) to clear it for the desired request.
Activate the request to record it. It can differ based on the target, such as:
Filter the requests by the target request type, Doc (HTML) or Fetch/XHR (JSON). You will find the requests recorded:
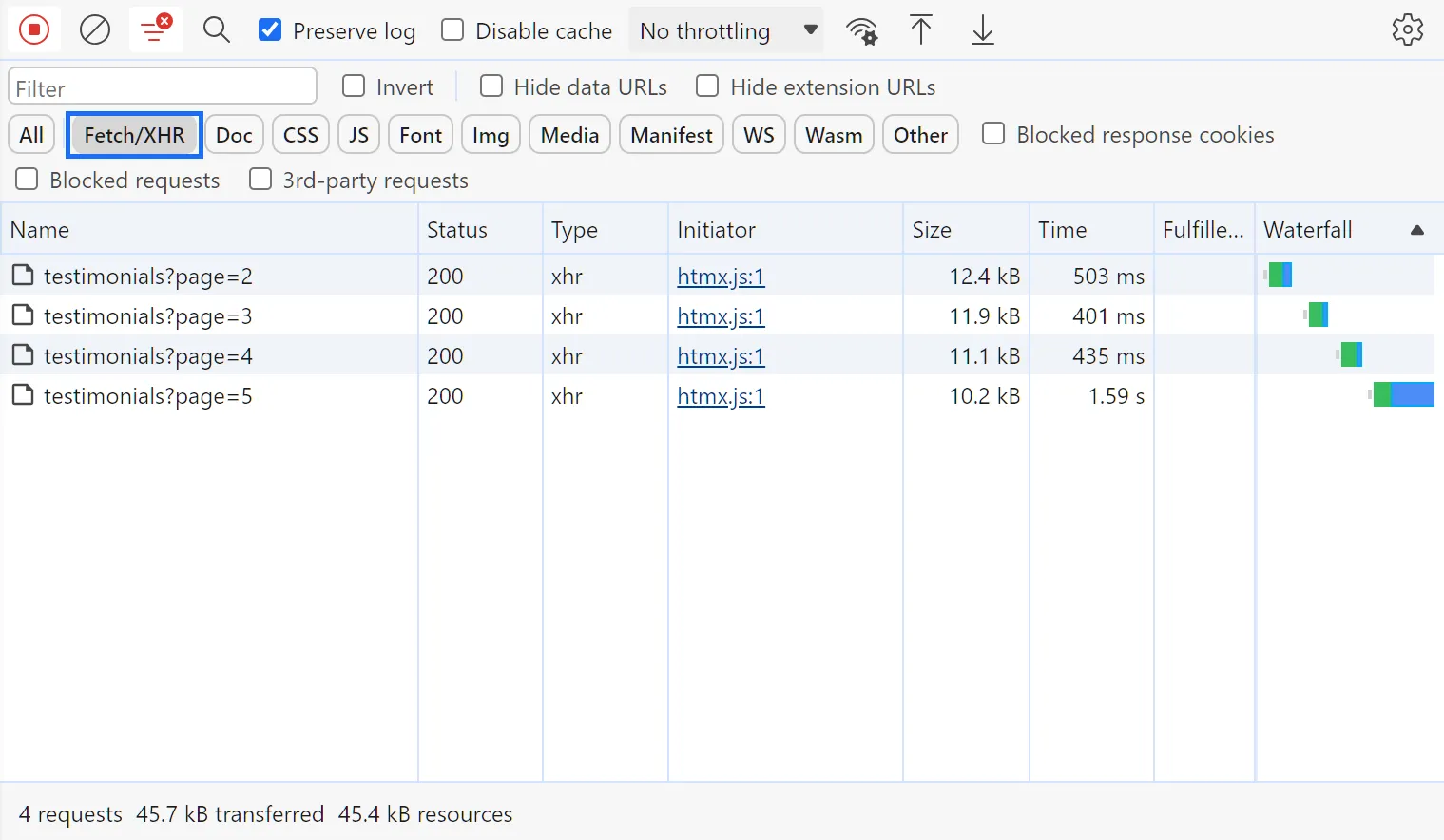
Right-click on the request, select copy, and then copy as cURL (bash):
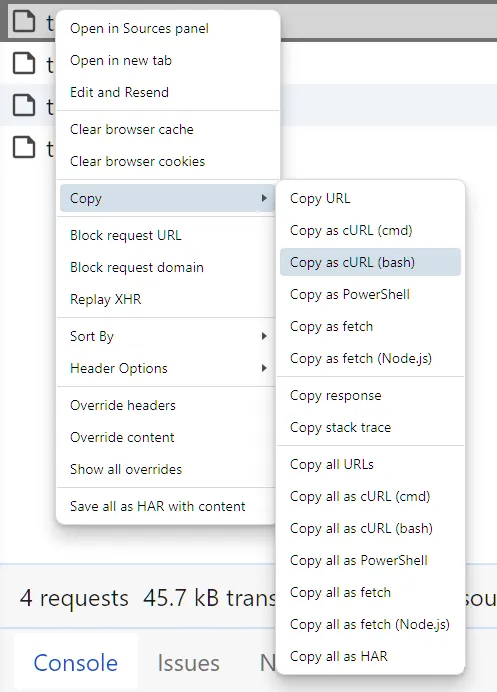
We have explained converting cURL requests into Python. However, the same apporach can be used to convert cURL into Node.js and other programming languages using HTTP clients. For further details, refer to our dedicated guide on Postman.
This knowledgebase is provided by Scrapfly data APIs, check us out! 👇

Learn to handle SSL errors in cURL, including using self-signed certificates. Explore common issues, safe practices.

Master file downloads with curl and discover advanced use cases.

curl and wget are both popular terminal tools but often used for different tasks - let's take a look at the differences.

Here's everything you need to know about cURL GET requests and some common pitfalls you should avoid.