

Cloudflare stands between your scraper and the data you need. It checks TLS fingerprints, runs JavaScript challenges, watches how you browse, and throws Turnstile CAPTCHAs at anything that looks like a script. A standard Playwright or Selenium script will get blocked in seconds. The most effective approach in 2026 is a mix of stealth browser automation and residential proxy rotation.
In this guide, we cover every current bypass technique with working Python code, from Nodriver and SeleniumBase UC Mode to curl-impersonate and production scaling.
What Is Cloudflare Bot Management?
Cloudflare Bot Management detects and blocks scrapers and automated traffic. It looks at TLS fingerprinting, IP reputation, JavaScript challenges, behavior, and Turnstile CAPTCHAs to give every request a trust score.
Based on this score, Cloudflare either allows the request, challenges it with JavaScript or a Turnstile CAPTCHA, or blocks it. The system adjusts scores based on what you do, so a scraper that passes the initial check can still get blocked later.
Knowing what Cloudflare checks is helpful, but if you want to bypass it, the techniques below are the place to start.
How to Bypass Cloudflare Bot Protection?
To get past Cloudflare, you need stealth browser automation, proxy rotation, and fingerprint management. Cloudflare blocks scrapers through five layers:
- TLS fingerprinting
- IP reputation
- JavaScript checks
- Behavior analysis
- Turnstile challenges
Each technique below targets specific detection vectors, from JA3 fingerprint spoofing to navigator.webdriver patching. Raw Playwright or Puppeteer scripts get blocked quickly, but the tools below modify browser behavior at the driver level to stay hidden.
How do I bypass Cloudflare with Nodriver? (2026 Recommended)
Cloudflare detects standard Selenium and Playwright browsers through the navigator.webdriver property and Chrome DevTools Protocol signatures. Nodriver, created by the author of undetected-chromedriver, patches these at the driver level. This makes automated Chrome look like manual browsing.
Nodriver takes a different approach than traditional Selenium:
- No WebDriver patches needed because the authors built it from scratch to avoid detection.
- Uses Direct Chrome DevTools Protocol to talk to Chrome without leaving traces.
- Includes native stealth capabilities.
- Under active development to counter new detection methods.
- Better performance with lower overhead than patched Selenium drivers.
Nodriver Example for Cloudflare Bypass
First, install Nodriver:
pip install nodriverThen run this script to visit Scrapfly's fingerprint tool, which shows how your browser appears to anti-bot systems:
import asyncio
import nodriver as uc
async def scrape_cloudflare_protected_site():
# Launch undetected Chrome browser
browser = await uc.start()
# Navigate to fingerprint checker
page = await browser.get('https://scrapfly.io/web-scraping-tools/browser-fingerprint')
# Wait for Cloudflare challenge to complete
await asyncio.sleep(5)
# Save screenshot to verify stealth
await page.save_screenshot("fingerprint.png", format="png")
# Extract content after bypass
content = await page.get_content()
print(content[:500])
browser.stop()
# Run the scraper
asyncio.run(scrape_cloudflare_protected_site())Nodriver's async architecture and native stealth make it the best choice for new projects in 2026, especially when dealing with Cloudflare and Turnstile.
How do I use SeleniumBase UC Mode for Cloudflare?
Teams with existing Selenium tests can't easily switch frameworks. SeleniumBase UC Mode wraps Selenium's API with Cloudflare evasion, including automatic patching of fingerprints and CDP leak prevention.
- Tested in production environments.
- Built-in CAPTCHA helpers for handling Turnstile.
- Extensive examples and tutorials.
- Regular updates in response to Cloudflare changes.
- Easy migration as a drop-in replacement for standard Selenium.
- Includes features for retries, session management, and proxy rotation.
SeleniumBase Example
First, install SeleniumBase:
pip install seleniumbaseThen run this script to visit the fingerprint tool:
from seleniumbase import SB
with SB(uc=True) as sb: # uc=True enables undetected mode
# Open fingerprint checker
sb.uc_open_with_reconnect("https://scrapfly.io/web-scraping-tools/browser-fingerprint", 4)
# SeleniumBase handles Cloudflare challenges automatically
sb.sleep(3)
# Extract data after bypass
title = sb.get_page_title()
content = sb.get_page_source()
# Save screenshot
sb.save_screenshot("fingerprint.png")SeleniumBase UC Mode is a good fit for production scraping where reliability is the priority, especially for teams already on Selenium.
Can Camoufox bypass Cloudflare's fingerprint detection?
Most bypass tools target Chromium, but some Cloudflare setups profile Chrome-based automation. Camoufox uses a modified Firefox build with genuine fingerprints to avoid Chrome-specific detection.
- Firefox-based to provide a different fingerprint than Chrome tools.
- Built specifically for Python automation.
- Patches Firefox to prevent fingerprinting.
- Lower resource usage than Chrome.
- Uses actual Firefox user profiles.
Camoufox Example
First, install Camoufox and the browser binary:
pip install camoufox
python -m camoufox fetchThen run this script:
from camoufox.sync_api import Camoufox
# Launch Camoufox with stealth settings
with Camoufox(
headless=False, # False works better with Cloudflare
humanize=True # Enable human-like behavior
) as browser:
# Create a new page
page = browser.new_page()
# Navigate to fingerprint checker
page.goto('https://scrapfly.io/web-scraping-tools/browser-fingerprint')
# Wait for Cloudflare challenge
page.wait_for_timeout(5000)
# Save screenshot
page.screenshot(path="fingerprint.png")
# Extract content
content = page.content()
print(content[:500])Camoufox is useful when Cloudflare detects Chrome-based solutions or when you want to use different browser fingerprints across your scrapers.
Can I bypass Cloudflare without a browser?
Not every protected page requires JavaScript. Some only check TLS fingerprints and HTTP headers. curl-impersonate reproduces the exact TLS signatures of real browsers (JA3/JA4 hashes) at a fraction of the cost of a full browser.
curl-impersonate and similar clients don't parse HTML natively, but they can modify TLS details for other HTTP clients. One example is curl_cffi, a Python interface for curl-impersonate.

How do I warm up a scraper to avoid Cloudflare blocks?
Cloudflare's behavior analysis flags scrapers that go straight to target pages without natural browsing. Warming up a session by visiting the homepage, loading assets, and accepting cookies builds a legitimate fingerprint before you hit protected endpoints.
Real users usually explore in steps:
- Start at the homepage.
- Browse categories.
- Search for something.
- View the product page.
Adding this behavior to your script makes the scraper look human and improves your trust score.
Does rotating browser fingerprints help bypass Cloudflare?
Cloudflare tracks fingerprints across sessions. Reusing the same canvas hash or screen resolution across hundreds of requests will flag you. Rotating fingerprints from real-user datasets makes each session look unique.
For long-term scraping in 2026, mix headless browsers with different, realistic profiles. Screen resolution, OS, and browser type are all key. Configure each browser library to use different rendering capabilities to stop Cloudflare from spotting a pattern.
See Scrapfly's browser fingerprint tool to see how your browser looks to Cloudflare.
Do IPv6 proxies work for bypassing Cloudflare?
Cloudflare's IP reputation databases focus on IPv4 addresses, where datacenter ranges are well-known. IPv6 addresses from residential ISP allocations have less reputation history, making them less likely to trigger blocks.
Why IPv6 Works
- Many anti-bot systems don't track IPv6 reputation as thoroughly as IPv4.
- The massive IPv6 address space makes it hard to block individual IPs.
- Some Cloudflare setups don't monitor IPv6 as strictly.
- IPv6 reputation scoring is less developed than IPv4.
Considerations
IPv6 has some limits:
- Not all proxy providers offer it.
- The target site must support it (check with
ping -6 example.com). - You still need to combine it with fingerprinting and behavior patterns.
- Datacenter IPv6 addresses still have lower trust than residential ones.
IPv6 Proxy Configuration Example
First, install httpx with HTTP/2 support:
pip install "httpx[http2]"Configure your IPv6 proxy using the provider's address and credentials:
import httpx
# IPv6 addresses must be in brackets in the proxy URL
client = httpx.Client(
proxy="http://username:password@[2001:db8::1]:8080",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
},
http2=True
)
response = client.get("https://web-scraping.dev/products")
print(response.status_code)IPv6 proxies work best when mixed with residential pools and proper fingerprinting to avoid rate limits.
Legacy Tools: Nodriver replaces
undetected-chromedriver. The maintainers deprecatedpuppeteer-stealthin Feb 2025 and it doesn't bypass current Cloudflare versions.FlareSolverrrelies on undetected-chromedriver and has the same issues. If you use these, move to Nodriver or SeleniumBase UC Mode.
Framework Comparison
| Framework | Best For | Success Rate | Learning Curve |
|---|---|---|---|
| Nodriver | General Python scraping | High | Medium |
| SeleniumBase UC | Selenium users | High | Low |
| Camoufox | Firefox fingerprints | High | Medium |
| curl-impersonate | TLS-only bypass | Medium | Low |
| Puppeteer + Stealth | Node.js (deprecated) | Medium | Low |
| Playwright + Stealth | Multi-browser | Medium | Medium |
| Cloud Browser (Scrapfly) | Production scale | High | Low |
How do I scale Cloudflare bypass to production?
Running one stealth session is one thing. Running thousands at once adds massive operational complexity.
Browser Fleet Challenges
Production scale requires managing:
- CPU and RAM: Each Chrome instance needs about 500 MB. Large fleets need heavy servers.
- Session isolation: Prevent fingerprint leakage. Shared cookies or cache will get you caught.
- Crash recovery: Browsers crash. You need logic to restart them and check health.
- Version pinning: Cloudflare updates its detection based on browser versions. You need to coordinate updates.
- Proxy management: Handling pools, rotation, and health across hundreds of sessions.
- Observability: Monitoring success rates and knowing when a bypass technique stops working.
Scaling Approaches
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| Self-hosted K8s/ECS | Total control | High overhead | Teams with DevOps capacity |
| Selenium Grid | Mature ecosystem | Resource-heavy | Teams on Selenium |
| Managed browser APIs | Low overhead | Vendor dependency | Teams prioritizing speed |
| Avoid browsers | Lowest cost | Doesn't work everywhere | When HTTP/TLS bypass is enough |
For self-hosting, container orchestration like Kubernetes is best. Each session runs in its own isolated container. Managed cloud browser APIs handle the setup for you via a CDP WebSocket:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Connect to remote browser
browser = p.chromium.connect_over_cdp("wss://your-provider.example.com/browser")
page = browser.new_page()
page.goto("https://web-scraping.dev/products")
content = page.content()
print(content[:500])Want to skip the setup? Scrapfly's Cloud Browser API provides stealth browsers with proxy rotation out of the box.
How Does Cloudflare Detect Web Scrapers?
Cloudflare uses different technologies to decide if traffic is a real user or a script. Anti-bot systems combine results from many analyses into a trust score.
Based on that score:
- You get the resource.
- You solve a CAPTCHA or JS challenge.
- You get blocked.
Cloudflare also tracks behavior over time, so a scraper might get past the first few checks but get blocked later as the score changes.
TLS Fingerprinting
The TLS handshake is the first step of an HTTPS request. The client and server create a fingerprint called JA3. Since HTTP clients differ in configuration, they create unique fingerprints.
Anti-bot systems use JA3 hashes to spot automated clients. Use clients that mimic normal browsers. You can check your signature with Scrapfly's JA3 tool.
IP Address Fingerprinting
Cloudflare looks at the IP type:
- Residential: Assigned by ISPs to home networks. These have high trust.
- Mobile: Assigned by cellular towers. Also have high trust and rotate often.
- Datacenter: IPs from AWS or Google Cloud. These have low trust and are often blocked.
Cloudflare also monitors request rates. If an IP sends too many requests too fast, it gets blocked. Rotate residential or mobile proxies to stay safe.
HTTP Details
Most people use popular browsers like Chrome or Firefox. These browsers have specific request patterns. If your request looks different, it stands out.
Headers
Request headers are important. You need to replicate browser headers to avoid blocks.
- Accept: Should match the data type you are requesting.
- Accept-Language: Indicates supported languages.
- User-Agent: Represents the device and browser. Rotate this regularly.
- Cookie: Keeps session state. Reusing cookies helps you look like a returning user.
HTTP2
Most browsers use HTTP2, but many scripts still use HTTP1.1. This is a clear signal to Cloudflare. Use clients like httpx or cURL and turn on HTTP2.
JavaScript Fingerprinting
JavaScript fingerprinting lets Cloudflare probe your hardware, OS, and browser details. While JS execution is slow and prone to errors, Cloudflare uses it to collect data. You can't easily fake this with a script, so using a real browser via automation is the common solution.
Advanced tools mix HTTP clients and browsers. A browser gets the session values and establishes trust, then the scraper passes those values to a faster HTTP client.
Behavior Analysis & Machine Learning (2026 Update)
Trust scores change during a connection. If you request 100 pages in two seconds, your score drops. Real users don't do that.
Per-Customer Machine Learning Models
Cloudflare now uses models that learn the specific traffic patterns of a website:
- Custom Trust Scores for each domain.
- Adaptive Thresholds that learn what is "normal" for that site.
- Pattern recognition to spot residential proxies.
- Consistency checks to make sure a session doesn't suddenly change behavior.
Traffic Pattern Analysis
Cloudflare looks at:
- Request sequencing: Does the navigation make sense?
- Timing: Are delays perfectly even (bot) or variable (human)?
- Resource loading: Are you fetching CSS and fonts?
- Interactions: Are there mouse moves and pauses?
Evading Advanced Detection
To bypass these:
- Add random timeouts (2 to 5 seconds).
- Match User-Agent headers with your TLS fingerprint.
- Randomize viewport sizes.
- Mimic mouse moves and keyboard input.
- Follow natural navigation paths.
- Load page resources like a browser.
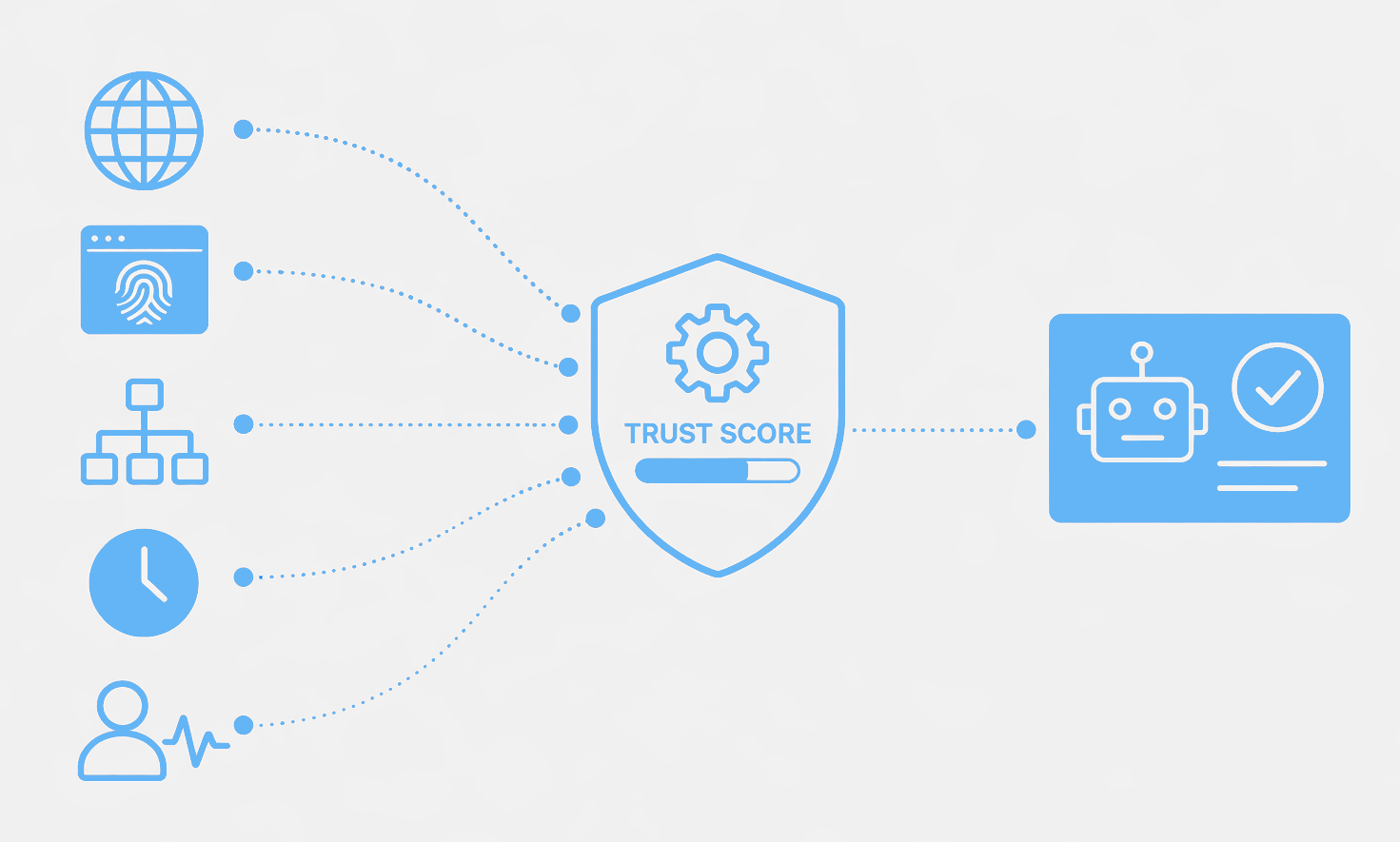
Common Cloudflare Errors When Scraping
| Error | Meaning | Fix |
|---|---|---|
| 1020 | IP or request flagged | Residential proxies |
| 1009 | Country blocked | Proxy in allowed region |
| 1015 | Rate limited | Throttling and IP rotation |
| 1010 | Browser detected | Nodriver or SeleniumBase UC |
| 1003 | Direct IP access | Use domain name via proxy |
| Turnstile | CAPTCHA triggered | Browser automation + solver |
Troubleshooting
If your bypass fails, check this tree:
- 403 / 1020: IP reputation is bad. Use a residential proxy.
- Turnstile loops: Fingerprint detected. Use Nodriver or SeleniumBase UC.
- JS challenge timeout: Wait longer (10 to 15 seconds).
- Rate limited (429): Slow down and add random delays.
- Detected as headless:
navigator.webdriverleaks automation. Use Nodriver.
General Debugging
- Check TLS fingerprint: Verify your JA3 hash looks like a browser.
- Check HTTP2: Make sure it's active.
- Test one request: If one fails, scaling won't help. Fix the fingerprint first.
- Monitor success: Cloudflare updates often. A working script might break tomorrow.
- Check headers: Look for
cf-rayto confirm Cloudflare is active.
Bypass Cloudflare with Scrapfly

Bypassing Cloudflare is hard. Scrapfly does it for you. Set the asp parameter and select a proxy pool to scrape any Cloudflare-protected site:
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="YOUR_SCRAPFLY_API_KEY")
response = scrapfly.scrape(ScrapeConfig(
url="https://web-scraping.dev/products",
asp=True, # bypass anti-scraping
country="US",
proxy_pool="public_residential_pool",
render_js=True
))
html = response.scrape_result['content']
print(html[:500])Scrapfly handles TLS fingerprinting, IP rotation, JavaScript rendering, and behavior simulation behind the scenes. No manual configuration needed.
Power your scraping with Scrapfly
Forget about getting blocked. Scrapfly handles anti-bot bypasses, browser rendering, and proxy rotation so you can focus on the data.
FAQ
How do I bypass the Cloudflare rule when scraping?
Mix a stealth browser (Nodriver) with residential proxies. This covers fingerprints, IP reputation, and behaviour.
How do I stop Cloudflare from blocking me?
Use residential proxies for 1020 errors, random delays for 1015, and Nodriver for 1010 detections.
Why did my Puppeteer-stealth script stop working?
The maintainers deprecated it in February 2025, and Cloudflare now easily detects it. Switch to Nodriver or a maintained stealth plugin.
Summary
We've covered how to bypass Cloudflare in 2026 by targeting its five detection layers. Key strategies include using stealth browsers like Nodriver, rotating residential and IPv6 proxies, warming up sessions, and using managed services like Scrapfly. Cloudflare updates its detection often, so monitoring your success rates is important.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


