

Reddit is one of the most active social platforms, with a significant amount of social and opinionated data added daily making it a popular target for web scraping.
In this article, we'll explore web scraping Reddit. We'll extract various social data types from subreddits, posts, and user pages. All of which through plain HTTP requests without headless browser usage. Let's get started!
Key Takeaways
Learn to scrape Reddit posts, subreddits, and user profiles using Python with httpx and parsel, handling social media data extraction and anti-bot measures.
- Reverse engineer Reddit's public API endpoints by intercepting browser network requests
- Parse Reddit's JSON responses with jmespath to extract structured social media information
- Bypass Reddit's rate limiting using rotating User-Agent headers and request spacing patterns
- Extract post data including titles, content, upvotes, comments, and user information
- Implement exponential backoff retry logic with 403 status code detection for rate limiting
- Use specialized tools like ScrapFly for automated Reddit scraping with anti-blocking features
Latest Reddit Scraper Code
Why Scrape Reddit?
Reddit includes thousands of subreddits for a wide range of subjects and interests. It's data can be useful for various use cases:
- Social Analysis The subreddits include a lot of highly active engagements found as questions, replies, and votes on a given subject. Web scraping Reddit for such social data is a great feed source for research methods like sentiment analysis.
- Competitive Analysis Businesses can scrape Reddit for their related domain data. This allows for gathering opinions and feedback about the market and its competitors, enhancing decision-making.
- Automated Browsing Due to Reddit's high engagement, catching up on a specific subject through manual browser navigation can be tedious. Instead, scraping Reddit enables an automated browsing experience, saving time and effort.
For further details, refer to our dedicated guide on web scraping use cases.
Setup
To web scrape Reddit, we'll Python with a few Python community packages:
- httpx to request Reddit pages and retrieve their HTML source.
- parsel to parse the HTML using web selectors such as XPath and CSS.
- loguru to monitor our Reddit web scraper through colorful terminal outputs.
- asyncio to increase our web scraping speed by executing the code asynchronously.
Since asyncio comes included with Python, we'll only need to install the remaining packages using pip command:
pip install httpx parsel loguruNote that How to Web Scrape with HTTPX and Python can be safely replaced with any other HTTP client, such as requests. As for parsel, another alternative is How to Parse Web Data with Python and Beautifulsoup.
How to Scrape Subreddits?
Let's start our Reddit scraper by extracting subreddit data. We'll extract the subreddit posts as well as the general subreddit details such as bio, links, and rank.
For this example, we'll scrape the popular r/wallstreetbets subreddit. The first thing we notice upon requesting this URL is that the post data are rendered dynamically through scrolls.
The most straightforward way to handle this pagination mechanism would be to use a web driver, such as Web Scraping with Selenium and Python, Web Scraping with Playwright and Python, or How to Web Scrape with Puppeteer and NodeJS in 2026. However, there's an alternative approach: scrape the hidden API!

In order to load more posts, a request is sent to a hidden Reddit API to fetch an HTML page containing the data. To view this API, follow the below steps:
- Open the browser developer tools by pressing the
F12key. - Select the
networkand filter byFetch/XHRrequests. - Scroll down the page to trigger the Reddit API.
After following the above steps, you will find the below request captured:
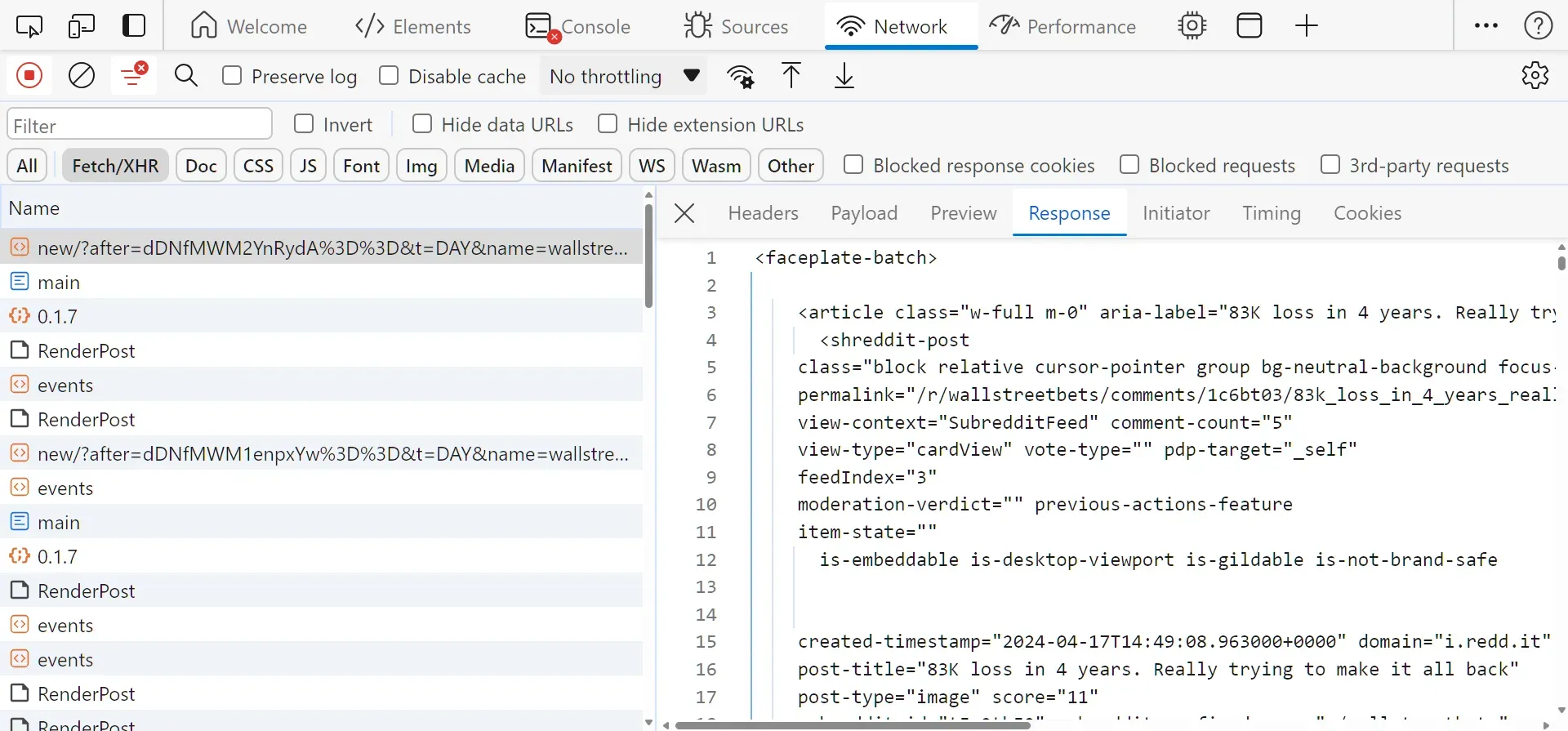
The above request was sent to this URL:
https://www.reddit.com/svc/shreddit/community-more-posts/new/?after=dDNfMWM2YnRydA%3D%3D&t=DAY&name=wallstreetbets&feedLength=3The required pagination parameters for this API are the following:
after: The pagination cursor to start after.name: The subreddit name to retrieve the posts for.
The after parameter value can be found in the HTML using this XPath selector: //shreddit-post/@more-posts-cursor. To scrape Reddit subreddits, we'll parse the HTML and utilize the hidden API for pagination:
import json
import asyncio
from typing import List, Dict, Union
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent getting blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Cookie": "intl_splash=false"
},
follow_redirects=True
)
def parse_subreddit(response: Response) -> List[Dict]:
"""parse article data from HTML"""
selector = Selector(response.text)
url = str(response.url)
info = {}
info["id"] = url.split("/r")[-1].replace("/", "")
info["description"] = selector.xpath("//shreddit-subreddit-header/@description").get()
members = selector.xpath("//shreddit-subreddit-header/@subscribers").get()
rank = selector.xpath("//strong[@id='position']/*/@number").get()
info["members"] = int(members) if members else None
info["rank"] = int(rank) if rank else None
info["bookmarks"] = {}
for item in selector.xpath("//div[faceplate-tracker[@source='community_menu']]/faceplate-tracker"):
name = item.xpath(".//a/span/span/span/text()").get()
link = item.xpath(".//a/@href").get()
info["bookmarks"][name] = link
info["url"] = url
post_data = []
for box in selector.xpath("//article"):
link = box.xpath(".//a/@href").get()
author = box.xpath(".//shreddit-post/@author").get()
post_label = box.xpath(".//faceplate-tracker[@source='post']/a/span/div/text()").get()
upvotes = box.xpath(".//shreddit-post/@score").get()
comment_count = box.xpath(".//shreddit-post/@comment-count").get()
attachment_type = box.xpath(".//shreddit-post/@post-type").get()
if attachment_type and attachment_type == "image":
attachment_link = box.xpath(".//div[@slot='thumbnail']/*/*/@src").get()
elif attachment_type == "video":
attachment_link = box.xpath(".//shreddit-player/@preview").get()
else:
attachment_link = box.xpath(".//div[@slot='thumbnail']/a/@href").get()
post_data.append({
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"authorId": box.xpath(".//shreddit-post/@author-id").get(),
"title": box.xpath("./@aria-label").get(),
"link": "https://www.reddit.com" + link if link else None,
"publishingDate": box.xpath(".//shreddit-post/@created-timestamp").get(),
"postId": box.xpath(".//shreddit-post/@id").get(),
"postLabel": post_label.strip() if post_label else None,
"postUpvotes": int(upvotes) if upvotes else None,
"commentCount": int(comment_count) if comment_count else None,
"attachmentType": attachment_type,
"attachmentLink": attachment_link,
})
# id for the next posts batch
cursor_id = selector.xpath("//shreddit-post/@more-posts-cursor").get()
return {"post_data": post_data, "info": info, "cursor": cursor_id}
async def scrape_subreddit(subreddit_id: str, sort: Union["new", "hot", "old"], max_pages: int = None):
"""scrape articles on a subreddit"""
base_url = f"https://www.reddit.com/r/{subreddit_id}/"
response = await client.get(base_url)
subreddit_data = {}
data = parse_subreddit(response)
subreddit_data["info"] = data["info"]
subreddit_data["posts"] = data["post_data"]
cursor = data["cursor"]
def make_pagination_url(cursor_id: str):
return f"https://www.reddit.com/svc/shreddit/community-more-posts/hot/?after={cursor_id}%3D%3D&t=DAY&name=wallstreetbets&feedLength=3&sort={sort}"
while cursor and (max_pages is None or max_pages > 0):
url = make_pagination_url(cursor)
response = await client.get(url)
data = parse_subreddit(response)
cursor = data["cursor"]
post_data = data["post_data"]
subreddit_data["posts"].extend(post_data)
if max_pages is not None:
max_pages -= 1
log.success(f"scraped {len(subreddit_data['posts'])} posts from the rubreddit: r/{subreddit_id}")
return subreddit_dataimport json
import asyncio
from typing import Dict, Union
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass reddit web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
# use the residential proxy pool for higher success rate
"proxy_pool": "public_residential_pool"
}
def parse_subreddit(response: ScrapeApiResponse) -> Dict:
"""parse article data from HTML"""
selector = response.selector
url = response.context["url"]
info = {}
info["id"] = url.split("/r")[-1].replace("/", "")
info["description"] = selector.xpath("//shreddit-subreddit-header/@description").get()
members = selector.xpath("//shreddit-subreddit-header/@subscribers").get()
rank = selector.xpath("//strong[@id='position']/text()").get()
info["rank"] = rank.strip() if rank else None
info["members"] = int(members) if members else None
info["bookmarks"] = {}
for item in selector.xpath("//div[faceplate-tracker[@source='community_menu']]/faceplate-tracker"):
name = item.xpath(".//a/span/span/span/text()").get()
link = item.xpath(".//a/@href").get()
info["bookmarks"][name] = link
info["url"] = url
post_data = []
for box in selector.xpath("//article"):
link = box.xpath(".//a/@href").get()
author = box.xpath(".//shreddit-post/@author").get()
post_label = box.xpath(".//faceplate-tracker[@source='post']/a/span/div/text()").get()
upvotes = box.xpath(".//shreddit-post/@score").get()
comment_count = box.xpath(".//shreddit-post/@comment-count").get()
attachment_type = box.xpath(".//shreddit-post/@post-type").get()
if attachment_type and attachment_type == "image":
attachment_link = box.xpath(".//div[contains(@class, 'img')]/*/@src").get()
elif attachment_type == "video":
attachment_link = box.xpath(".//shreddit-player/@preview").get()
else:
attachment_link = None
post_data.append({
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"authorId": box.xpath(".//shreddit-post/@author-id").get(),
"title": box.xpath("./@aria-label").get(),
"link": "https://www.reddit.com" + link if link else None,
"publishingDate": box.xpath(".//shreddit-post/@created-timestamp").get(),
"postId": box.xpath(".//shreddit-post/@id").get(),
"postLabel": post_label.strip() if post_label else None,
"postUpvotes": int(upvotes) if upvotes else None,
"commentCount": int(comment_count) if comment_count else None,
"attachmentType": attachment_type,
"attachmentLink": attachment_link,
})
# id for the next posts batch
cursor_id = selector.xpath("//shreddit-post/@more-posts-cursor").get()
return {"post_data": post_data, "info": info, "cursor": cursor_id}
async def scrape_subreddit(subreddit_id: str, sort: Union["new", "hot", "old"], max_pages: int = None) -> Dict:
"""scrape articles on a subreddit"""
base_url = f"https://www.reddit.com/r/{subreddit_id}/"
response = await SCRAPFLY.async_scrape(ScrapeConfig(base_url, **BASE_CONFIG))
subreddit_data = {}
data = parse_subreddit(response)
subreddit_data["info"] = data["info"]
subreddit_data["posts"] = data["post_data"]
cursor = data["cursor"]
def make_pagination_url(cursor_id: str):
return f"https://www.reddit.com/svc/shreddit/community-more-posts/hot/?after={cursor_id}%3D%3D&t=DAY&name=wallstreetbets&feedLength=3&sort={sort}"
while cursor and (max_pages is None or max_pages > 0):
url = make_pagination_url(cursor)
response = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
data = parse_subreddit(response)
cursor = data["cursor"]
post_data = data["post_data"]
subreddit_data["posts"].extend(post_data)
if max_pages is not None:
max_pages -= 1
log.success(f"scraped {len(subreddit_data['posts'])} posts from the rubreddit: r/{subreddit_id}")
return subreddit_dataRun the code
async def run():
data = await scrape_subreddit(
subreddit_id="wallstreetbets",
sort="new",
max_pages=2
)
with open("subreddit.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())In the above Reddit scraping code, we initialize an httpx client with basic How Headers Are Used to Block Web Scrapers and How to Fix It to mimic a normal web browser and define two functions:
parse_subredditto parse the subreddit HTML pages using XPath selectors. It extracts the subreddit info and post data, as well as the cursor id for pagination.scrape_subredditto request the subreddit page while utilizing the parsing logic. It uses the hidden subreddit API for pagination after retrieving the first page data.
Here's an example output of the scraped data:
Example output
{
"info": {
"id": "wallstreetbets?rdt=41952",
"description": "Like 4chan found a Bloomberg Terminal.",
"members": 15311115,
"rank": 49,
"bookmarks": {
"Wiki": "/r/wallstreetbets/wiki/index/",
"YouTube": "https://www.youtube.com/@WSBverse?sub_confirmation=1",
"Discord": "https://discord.gg/wsbverse",
"Twitch": "https://twitch.tv/wsbverse"
},
"url": "https://www.reddit.com/r/wallstreetbets/?rdt=41952"
},
"posts": [
{
"authorProfile": "https://www.reddit.com/user/wsbapp",
"authorId": "t2_qbvp0eq8b",
"title": "Daily Discussion Thread for April 17, 2024",
"link": "https://www.reddit.com/r/wallstreetbets/comments/1c666yb/daily_discussion_thread_for_april_17_2024/",
"publishingDate": "2024-04-17T10:15:18.112000+0000",
"postId": "t3_1c666yb",
"postLabel": "Daily Discussion",
"postUpvotes": 137,
"commentCount": 6366,
"attachmentType": "text",
"attachmentLink": null
},
....
]
}Now that we have scraped Reddit post references, let's gather data from their dedicated pages!
How to Scrape Reddit Posts
In this section, we'll be scraping Reddit posts for their full details and comment replies. However, comments are also rendered dynamically through scrolls. Since posts can have thousands of replies, it's not practical to rely on headless browser usage. Instead, we'll rely on "old.reddit".
Luckily, old.reddit is very lightweight and doesn't rely on JavaScript. To view a Reddit post in the old version, all we have to do is prefix the post URL with "old", such as old.reddit.com/r/scrapfly/comments/1bwf4tf:
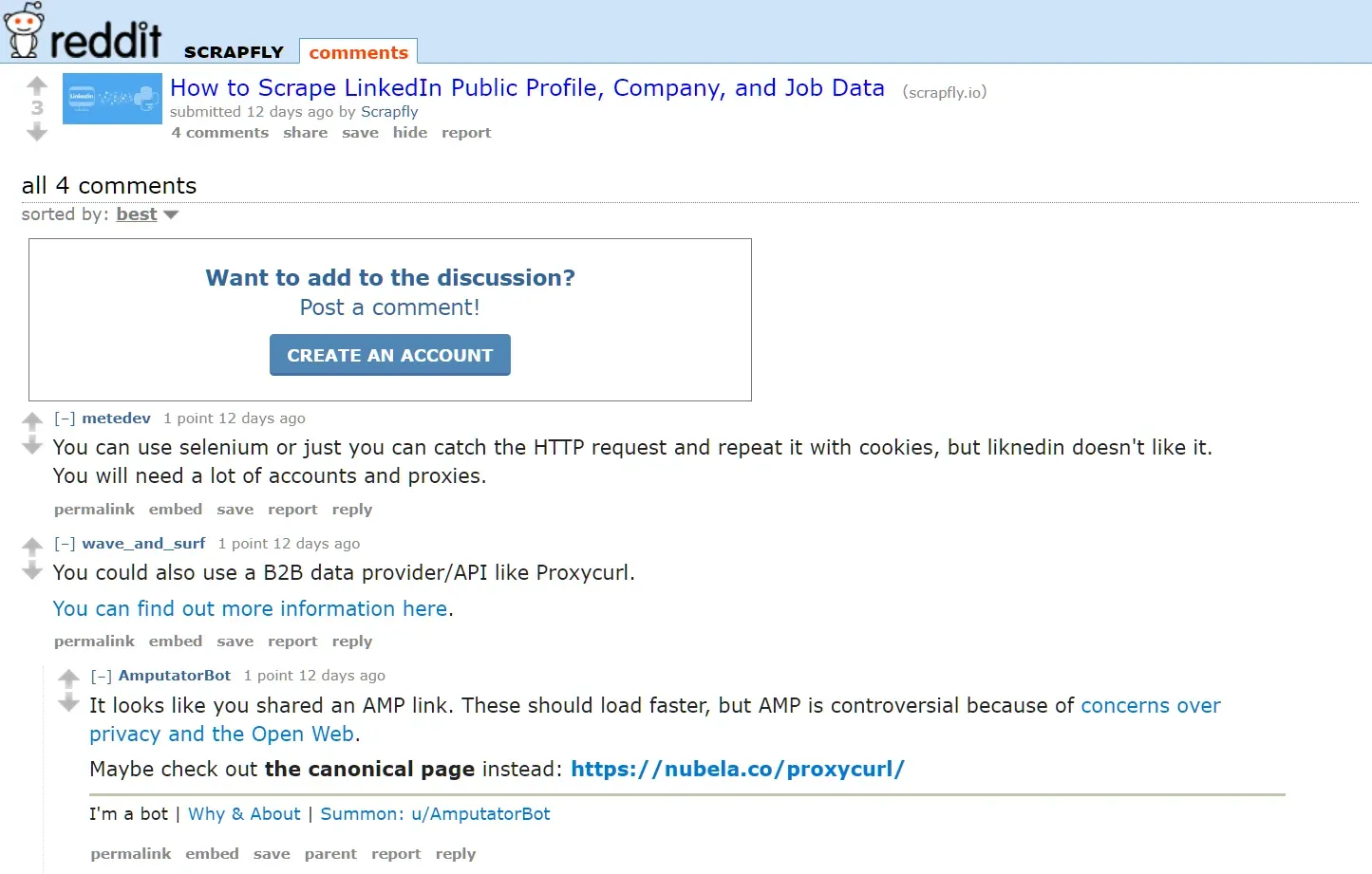
Another advantage of scraping old.reddit is the ability to fetch bulk comments. By adding the limit=500 query parameter to the URL, we are able to load 500 comments in a single request!
Here is how we can apply this logic to our Python Reddit scraping code:
import json
import asyncio
from typing import List, Dict, Union
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
client = AsyncClient(
# previous client configuration
)
def parse_post_info(response: Response) -> Dict:
"""parse post data from a subreddit post"""
selector = Selector(response.text)
info = {}
label = selector.xpath("//faceplate-tracker[@source='post']/a/span/div/text()").get()
comments = selector.xpath("//shreddit-post/@comment-count").get()
upvotes = selector.xpath("//shreddit-post/@score").get()
info["authorId"] = selector.xpath("//shreddit-post/@author-id").get()
info["author"] = selector.xpath("//shreddit-post/@author").get()
info["authorProfile"] = "https://www.reddit.com/user/" + info["author"] if info["author"] else None
info["subreddit"] = selector.xpath("//shreddit-post/@subreddit-prefixed-name").get()
info["postId"] = selector.xpath("//shreddit-post/@id").get()
info["postLabel"] = label.strip() if label else None
info["publishingDate"] = selector.xpath("//shreddit-post/@created-timestamp").get()
info["postTitle"] = selector.xpath("//shreddit-post/@post-title").get()
info["postLink"] = selector.xpath("//shreddit-canonical-url-updater/@value").get()
info["commentCount"] = int(comments) if comments else None
info["upvoteCount"] = int(upvotes) if upvotes else None
info["attachmentType"] = selector.xpath("//shreddit-post/@post-type").get()
info["attachmentLink"] = selector.xpath("//shreddit-post/@content-href").get()
return info
def parse_post_comments(response: Response) -> List[Dict]:
"""parse post comments"""
def parse_comment(parent_selector) -> Dict:
"""parse a comment object"""
author = parent_selector.xpath("./@data-author").get()
link = parent_selector.xpath("./@data-permalink").get()
dislikes = parent_selector.xpath(".//span[contains(@class, 'dislikes')]/@title").get()
upvotes = parent_selector.xpath(".//span[contains(@class, 'likes')]/@title").get()
downvotes = parent_selector.xpath(".//span[contains(@class, 'unvoted')]/@title").get()
return {
"authorId": parent_selector.xpath("./@data-author-fullname").get(),
"author": author,
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"commentId": parent_selector.xpath("./@data-fullname").get(),
"link": "https://www.reddit.com" + link if link else None,
"publishingDate": parent_selector.xpath(".//time/@datetime").get(),
"commentBody": parent_selector.xpath(".//div[@class='md']/p/text()").get(),
"upvotes": int(upvotes) if upvotes else None,
"dislikes": int(dislikes) if dislikes else None,
"downvotes": int(downvotes) if downvotes else None,
}
def parse_replies(what) -> List[Dict]:
"""recursively parse replies"""
replies = []
for reply_box in what.xpath(".//div[@data-type='comment']"):
reply_comment = parse_comment(reply_box)
child_replies = parse_replies(reply_box)
if child_replies:
reply_comment["replies"] = child_replies
replies.append(reply_comment)
return replies
selector = Selector(response.text)
data = []
for item in selector.xpath("//div[@class='sitetable nestedlisting']/div[@data-type='comment']"):
comment_data = parse_comment(item)
replies = parse_replies(item)
if replies:
comment_data["replies"] = replies
data.append(comment_data)
return data
async def scrape_post(url: str, sort: Union["old", "new", "top"]) -> Dict:
"""scrape subreddit post and comment data"""
response = await client.get(url)
post_data = {}
post_data["info"] = parse_post_info(response)
# scrape the comments from the old.reddit version, with the same post URL
bulk_comments_page_url = post_data["info"]["postLink"].replace("www", "old") + f"?sort={sort}&limit=500"
response = await client.get(bulk_comments_page_url)
post_data["comments"] = parse_post_comments(response)
log.success(f"scraped {len(post_data['comments'])} comments from the post {url}")
return post_dataimport json
import asyncio
from typing import List, Dict, Union
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass reddit web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
# use the residential proxy pool for higher success rate
"proxy_pool": "public_residential_pool"
}
def parse_post_info(response: ScrapeApiResponse) -> Dict:
"""parse post data from a subreddit post"""
selector = response.selector
info = {}
label = selector.xpath("//faceplate-tracker[@source='post']/a/span/div/text()").get()
comments = selector.xpath("//shreddit-post/@comment-count").get()
upvotes = selector.xpath("//shreddit-post/@score").get()
info["authorId"] = selector.xpath("//shreddit-post/@author-id").get()
info["author"] = selector.xpath("//shreddit-post/@author").get()
info["authorProfile"] = "https://www.reddit.com/user/" + info["author"] if info["author"] else None
info["subreddit"] = selector.xpath("//shreddit-post/@subreddit-prefixed-name").get().replace("r/", "")
info["postId"] = selector.xpath("//shreddit-post/@id").get()
info["postLabel"] = label.strip() if label else None
info["publishingDate"] = selector.xpath("//shreddit-post/@created-timestamp").get()
info["postTitle"] = selector.xpath("//shreddit-post/@post-title").get()
info["postLink"] = selector.xpath("//shreddit-canonical-url-updater/@value").get()
info["commentCount"] = int(comments) if comments else None
info["upvoteCount"] = int(upvotes) if upvotes else None
info["attachmentType"] = selector.xpath("//shreddit-post/@post-type").get()
info["attachmentLink"] = selector.xpath("//shreddit-post/@content-href").get()
return info
def parse_post_comments(response: ScrapeApiResponse) -> List[Dict]:
"""parse post comments"""
def parse_comment(parent_selector) -> Dict:
"""parse a comment object"""
author = parent_selector.xpath("./@data-author").get()
link = parent_selector.xpath("./@data-permalink").get()
dislikes = parent_selector.xpath(".//span[contains(@class, 'dislikes')]/@title").get()
upvotes = parent_selector.xpath(".//span[contains(@class, 'likes')]/@title").get()
downvotes = parent_selector.xpath(".//span[contains(@class, 'unvoted')]/@title").get()
return {
"authorId": parent_selector.xpath("./@data-author-fullname").get(),
"author": author,
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"commentId": parent_selector.xpath("./@data-fullname").get(),
"link": "https://www.reddit.com" + link if link else None,
"publishingDate": parent_selector.xpath(".//time/@datetime").get(),
"commentBody": parent_selector.xpath(".//div[@class='md']/p/text()").get(),
"upvotes": int(upvotes) if upvotes else None,
"dislikes": int(dislikes) if dislikes else None,
"downvotes": int(downvotes) if downvotes else None,
}
def parse_replies(what) -> List[Dict]:
"""recursively parse replies"""
replies = []
for reply_box in what.xpath(".//div[@data-type='comment']"):
reply_comment = parse_comment(reply_box)
child_replies = parse_replies(reply_box)
if child_replies:
reply_comment["replies"] = child_replies
replies.append(reply_comment)
return replies
selector = response.selector
data = []
for item in selector.xpath("//div[@class='sitetable nestedlisting']/div[@data-type='comment']"):
comment_data = parse_comment(item)
replies = parse_replies(item)
if replies:
comment_data["replies"] = replies
data.append(comment_data)
return data
async def scrape_post(url: str, sort: Union["old", "new", "top"]) -> Dict:
"""scrape subreddit post and comment data"""
response = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
post_data = {}
post_data["info"] = parse_post_info(response)
# scrape the comments from the old.reddit version, with the same post URL
bulk_comments_page_url = post_data["info"]["postLink"].replace("www", "old") + f"?sort={sort}&limit=500"
response = await SCRAPFLY.async_scrape(ScrapeConfig(bulk_comments_page_url, **BASE_CONFIG))
post_data["comments"] = parse_post_comments(response)
log.success(f"scraped {len(post_data['comments'])} comments from the post {url}")
return post_dataRun the code
async def run():
post_data = await scrape_post(
url="https://www.reddit.com/r/wallstreetbets/comments/1c4vwlp/what_are_your_moves_tomorrow_april_16_2024/",
sort="new"
)
with open("post.json", "w", encoding="utf-8") as file:
json.dump(post_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())The above Reddit scraper code utilizes a few functions. Let's break them down:
parse_post_info()to parse the post's basic details, like the author, publish date, score, and comment count.parse_post_comments()to parse the comment data while recursively extracting each comment reply.scrape_post()to request the regular post page for the info details and then theold.redditversion for the comment data. It also specifies the sorting option to use with the URL, such as top posts.
Here is a sample output of the scraped posts:
Example output
{
"info": {
"authorId": "t2_qbvp0eq8b",
"author": "wsbapp",
"authorProfile": "https://www.reddit.com/user/wsbapp",
"subreddit": "r/wallstreetbets",
"postId": "t3_1c4vwlp",
"postLabel": "Daily Discussion",
"publishingDate": "2024-04-15T20:00:20.757000+0000",
"postTitle": "What Are Your Moves Tomorrow, April 16, 2024",
"postLink": "https://www.reddit.com/r/wallstreetbets/comments/1c4vwlp/what_are_your_moves_tomorrow_april_16_2024/",
"commentCount": 8500,
"upvoteCount": 330,
"attachmentType": "text",
"attachmentLink": "https://www.reddit.com/r/wallstreetbets/comments/1c4vwlp/what_are_your_moves_tomorrow_april_16_2024/"
},
"comments": [
{
"authorId": "t2_a0zc3hq9",
"author": "NeedleworkerCrafty17",
"authorProfile": "https://www.reddit.com/user/NeedleworkerCrafty17",
"commentId": "t1_kzyyoax",
"link": "https://www.reddit.com/r/wallstreetbets/comments/1c4vwlp/what_are_your_moves_tomorrow_april_16_2024/kzyyoax/",
"publishingDate": "2024-04-17T11:26:29+00:00",
"commentBody": "TNA",
"upvotes": 2,
"dislikes": 2,
"downvotes": 3,
"replies": [
{
"authorId": "t2_6cd319g",
"author": "Originalink6",
"authorProfile": "https://www.reddit.com/user/Originalink6",
"commentId": "t1_l01me56",
"link": "https://www.reddit.com/r/wallstreetbets/comments/1c4vwlp/what_are_your_moves_tomorrow_april_16_2024/l01me56/",
"publishingDate": "2024-04-17T20:50:24+00:00",
"commentBody": "I hope you are right. I own something extremely similar.",
"upvotes": 1,
"dislikes": 1,
"downvotes": 2
}
]
},
....
]
}We have extracted 500 comments from the old.reddit post page. Let's explore how we can paginate it.
Paginating Comments on Post Pages
Comments on old.reddit post pages can be paginated through the regular "load more button" using headless browsers. There is another alternative using hidden APIs.
Open the browser developer tools and click the button for loading more data, and you will find the following API request captured:
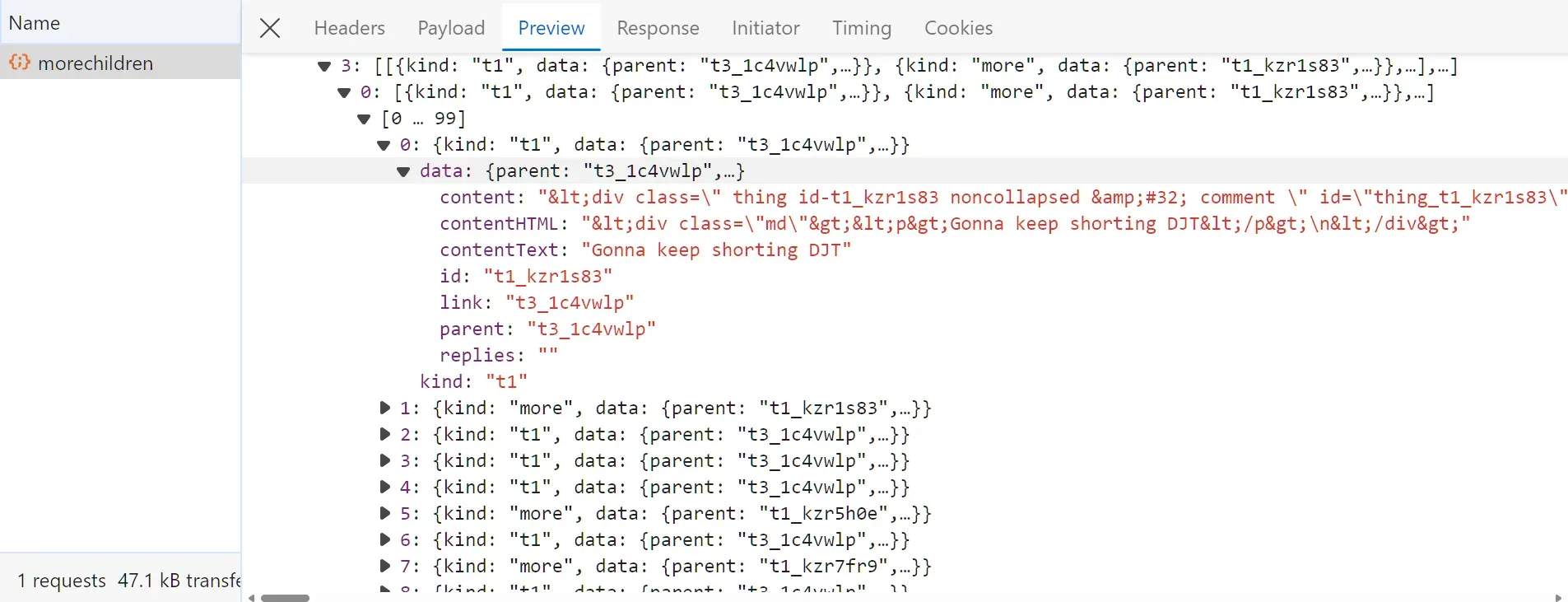
The request was sent to the URL: https://old.reddit.com/api/morechildren. It also uses a request body with these parameters: link_id, sort, and children. These values can be extracted from the a tag button used to fetch more data:

To paginate the post comments, we'll parse the next page cursor from the HTML and use it with the hidden API URL:
import re
import html
import json
import asyncio
from httpx import AsyncClient, Response
from parsel import Selector
client = AsyncClient(
# previous client configuration
)
def extract_comment_data(data):
for i in data["jquery"]:
try:
if "data" in i[-1][0][0]:
return i[-1][0]
except IndexError:
pass
def parse_comments_api(response: Response):
data = []
data = json.loads(response.text)
comment_data = extract_comment_data(data)
for i in comment_data:
selector = Selector(text=html.unescape(i["data"]["content"]))
author = selector.xpath("//div[@data-type='comment']/@data-author").get()
print(author)
# parse the ramining fields using the same previous logic
async def scrape_comments_pagination(url: str):
# parse the pagination values first from the HTML
response = await client.get(url)
selector = Selector(response.text)
# parse the a tag element
a_tag = selector.xpath("//div[@data-type='morechildren']/div/span/a/@onclick").get()
# parse the pagination parameters
next_id = re.search(r"this, '([^']*)'", a_tag).group(1)
children = a_tag.split("'new', '")[-1].replace("', 'False')", "")
subreddit_id = "wallstreetbets"
# form the request body
request_body = f"link_id={next_id}&sort=new&children={children}&limit_children=False&r={subreddit_id}&renderstyle=html"
# request the hidden comments API
next_page_response = await client.post("https://old.reddit.com/api/morechildren", data=request_body)
# parse the API response
parse_comments_api(next_page_response)import re
import html
import json
import asyncio
from parsel import Selector
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass reddit web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
# use the residential proxy pool for higher success rate
"proxy_pool": "public_residential_pool",
"headers": {
"content-type": "application/x-www-form-urlencoded; charset=UTF-8"
}
}
BASE_CONFIG = {
# bypass linkedin.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
}
def extract_comment_data(data):
for i in data["jquery"]:
try:
if "data" in i[-1][0][0]:
return i[-1][0]
except IndexError:
pass
def parse_comments_api(response: ScrapeApiResponse):
data = []
data = json.loads(response.scrape_result['content'])
comment_data = extract_comment_data(data)
for i in comment_data:
# define a selector from the returned HTML
selector = Selector(text=html.unescape(i["data"]["content"]))
author = selector.xpath("//div[@data-type='comment']/@data-author").get()
print(author)
# parse the ramining fields using the same previous logic
async def scrape_comments_pagination(url: str):
# parse the pagination values first from the HTML
response = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
selector = response.selector
# parse the a tag element
a_tag = selector.xpath("//div[@data-type='morechildren']/div/span/a/@onclick").get()
# parse the pagination parameters
next_id = re.search(r"this, '([^']*)'", a_tag).group(1)
children = a_tag.split("'new', '")[-1].replace("', 'False')", "")
subreddit_id = "wallstreetbets"
# form the request body
request_body = f"link_id={next_id}&sort=new&children={children}&limit_children=False&r={subreddit_id}&renderstyle=html"
# request the hidden comments API
next_page_response = await SCRAPFLY.async_scrape(
ScrapeConfig("https://old.reddit.com/api/morechildren", **BASE_CONFIG, method="POST", body=request_body)
)
# parse the API response
parse_comments_api(next_page_response)Run the code:
async def run():
await scrape_comments_pagination(
url= "https://old.reddit.com/r/wallstreetbets/comments/1c4vwlp/what_are_your_moves_tomorrow_april_16_2024/"
)
if __name__ == "__main__":
asyncio.run(run())Here, we start by requesting the main post page to parse the cursor details. Then, the parsed parameters are used as a request body with the API request to the hidden comments API.
The HTTP response of the above API request is a JSON dataset containing the comments data as HTML, which can be parsed using the previous parse_comment function. The response also includes an object containing the next page parameter cursor:
{
"kind": "more",
"data": {
"parent": "t3_1c4vwlp",
"content": "... onclick=\"return morechildren(this, 't3_1c4vwlp', 'new',
'c1:t1_kzt4ocx,t1_kzsnyvn,t1_kzt4msa,t1_kzs0mb4,t1_kzsunbw,t1_kzt1ve7', 'False') ...",
"contentText": "",
"link": "t3_1c4vwlp",
"replies": "",
"contentHTML": "",
"id": "t1_kzt4ocx"
}
}How to Scrape Reddit Profiles
In this section, we'll explore the last part of our Reddit scraper: profile pages, which include the user's posts and comments. Let's begin with posts.
Scraping Profile Posts
To scrape Reddit posts on profile pages, we'll utilize old.reddit again. It allows paginating the results using the following URL as an example:
https://old.reddit.com/user/Scrapfly/submitted?count=25&after=t3_191n6zmThe count query parameter represents the number of results to render on the HTML page. The after parameter controls the pagination cursor. It represents a post id to start after.
Let's translate the above logic into Python code:
import json
import asyncio
from typing import List, Dict, Union
from datetime import datetime
from httpx import AsyncClient, Response
from loguru import logger as log
from parsel import Selector
client = AsyncClient(
# previous client configuration
)
def parse_user_posts(response: Response) -> List[Dict]:
"""parse user posts from user profiles"""
selector = Selector(response.text)
data = []
for box in selector.xpath("//div[@id='siteTable']/div[contains(@class, 'thing')]"):
author = box.xpath("./@data-author").get()
link = box.xpath("./@data-permalink").get()
publishing_date = box.xpath("./@data-timestamp").get()
publishing_date = datetime.fromtimestamp(int(publishing_date) / 1000.0).strftime('%Y-%m-%dT%H:%M:%S.%f%z') if publishing_date else None
comment_count = box.xpath("./@data-comments-count").get()
post_score = box.xpath("./@data-score").get()
data.append({
"authorId": box.xpath("./@data-author-fullname").get(),
"author": author,
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"postId": box.xpath("./@data-fullname").get(),
"postLink": "https://www.reddit.com" + link if link else None,
"postTitle": box.xpath(".//p[@class='title']/a/text()").get(),
"postSubreddit": box.xpath("./@data-subreddit-prefixed").get(),
"publishingDate": publishing_date,
"commentCount": int(comment_count) if comment_count else None,
"postScore": int(post_score) if post_score else None,
"attachmentType": box.xpath("./@data-type").get(),
"attachmentLink": box.xpath("./@data-url").get(),
})
next_page_url = selector.xpath("//span[@class='next-button']/a/@href").get()
return {"data": data, "url": next_page_url}
async def scrape_user_posts(username: str, sort: Union["new", "top", "controversial"], max_pages: int = None) -> List[Dict]:
"""scrape user posts"""
url = f"https://old.reddit.com/user/{username}/submitted/?sort={sort}"
response = await client.get(url)
data = parse_user_posts(response)
post_data, next_page_url = data["data"], data["url"]
while next_page_url and (max_pages is None or max_pages > 0):
response = await client.get(next_page_url)
data = parse_user_posts(response)
next_page_url = data["url"]
post_data.extend(data["data"])
if max_pages is not None:
max_pages -= 1
log.success(f"scraped {len(post_data)} posts from the {username} reddit profile")
return post_dataimport json
import asyncio
from datetime import datetime
from typing import List, Dict, Union
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass reddit web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
# use the residential proxy pool for higher success rate
"proxy_pool": "public_residential_pool"
}
def parse_user_posts(response: ScrapeApiResponse) -> List[Dict]:
"""parse user posts from user profiles"""
selector = response.selector
data = []
for box in selector.xpath("//div[@id='siteTable']/div[contains(@class, 'thing')]"):
author = box.xpath("./@data-author").get()
link = box.xpath("./@data-permalink").get()
publishing_date = box.xpath("./@data-timestamp").get()
publishing_date = datetime.fromtimestamp(int(publishing_date) / 1000.0).strftime('%Y-%m-%dT%H:%M:%S.%f%z') if publishing_date else None
comment_count = box.xpath("./@data-comments-count").get()
post_score = box.xpath("./@data-score").get()
data.append({
"authorId": box.xpath("./@data-author-fullname").get(),
"author": author,
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"postId": box.xpath("./@data-fullname").get(),
"postLink": "https://www.reddit.com" + link if link else None,
"postTitle": box.xpath(".//p[@class='title']/a/text()").get(),
"postSubreddit": box.xpath("./@data-subreddit-prefixed").get(),
"publishingDate": publishing_date,
"commentCount": int(comment_count) if comment_count else None,
"postScore": int(post_score) if post_score else None,
"attachmentType": box.xpath("./@data-type").get(),
"attachmentLink": box.xpath("./@data-url").get(),
})
next_page_url = selector.xpath("//span[@class='next-button']/a/@href").get()
return {"data": data, "url": next_page_url}
async def scrape_user_posts(username: str, sort: Union["new", "top", "controversial"], max_pages: int = None) -> List[Dict]:
"""scrape user posts"""
url = f"https://old.reddit.com/user/{username}/submitted/?sort={sort}"
response = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
data = parse_user_posts(response)
post_data, next_page_url = data["data"], data["url"]
while next_page_url and (max_pages is None or max_pages > 0):
response = await SCRAPFLY.async_scrape(ScrapeConfig(next_page_url, **BASE_CONFIG))
data = parse_user_posts(response)
next_page_url = data["url"]
post_data.extend(data["data"])
if max_pages is not None:
max_pages -= 1
log.success(f"scraped {len(post_data)} posts from the {username} reddit profile")
return post_dataRun the code:
async def run():
user_post_data = await scrape_user_posts(
username="Scrapfly",
sort="top",
max_pages=3
)
with open("user_posts.json", "w", encoding="utf-8") as file:
json.dump(user_post_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())Here, we define two functions for scraping Reddit profile posts:
parse_user_posts()to parse all the posts' data on the HTML using XPath selectors.scrape_user_posts()to request the user post pages. It uses the parsed link of the next page button for pagination as long it exists.
Here's a sample output of the scraped data:
Example output
[
{
"authorId": "t2_saicgkn9",
"author": "Scrapfly",
"authorProfile": "https://www.reddit.com/user/Scrapfly",
"postId": "t3_1bwf4tf",
"postLink": "https://www.reddit.com/r/scrapfly/comments/1bwf4tf/how_to_scrape_linkedin_public_profile_company_and/",
"postTitle": "How to Scrape LinkedIn Public Profile, Company, and Job Data",
"postSubreddit": "r/scrapfly",
"publishingDate": "2024-04-05T12:58:19.000000",
"commentCount": 4,
"postScore": 3,
"attachmentType": "link",
"attachmentLink": "https://scrapfly.io/blog/posts/how-to-scrape-linkedin"
},
....
]The extracted data misses the comments of each post. However, we have already defined the parsing logic earlier, which can be implemented here as crawling logic.

Scraping Profile Comments
We can scrape Reddit profile comments using the same approach as the previous section. All we have to do is replace the starting URL and the parsing the logic:
def parse_user_comments(response: Response) -> List[Dict]:
"""parse user posts from user profiles"""
selector = Selector(response.text)
data = []
for box in selector.xpath("//div[@id='siteTable']/div[contains(@class, 'thing')]"):
author = box.xpath("./@data-author").get()
link = box.xpath("./@data-permalink").get()
dislikes = box.xpath(".//span[contains(@class, 'dislikes')]/@title").get()
upvotes = box.xpath(".//span[contains(@class, 'likes')]/@title").get()
downvotes = box.xpath(".//span[contains(@class, 'unvoted')]/@title").get()
data.append({
"authorId": box.xpath("./@data-author-fullname").get(),
"author": author,
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"commentId": box.xpath("./@data-fullname").get(),
"commentLink": "https://www.reddit.com" + link if link else None,
"commentBody": "".join(box.xpath(".//div[contains(@class, 'usertext-body')]/div/p/text()").getall()).replace("\n", ""),
"attachedCommentLinks": box.xpath(".//div[contains(@class, 'usertext-body')]/div/p/a/@href").getall(),
"publishingDate": box.xpath(".//time/@datetime").get(),
"dislikes": int(dislikes) if dislikes else None,
"upvotes": int(upvotes) if upvotes else None,
"downvotes": int(downvotes) if downvotes else None,
"replyTo": {
"postTitle": box.xpath(".//p[@class='parent']/a[@class='title']/text()").get(),
"postLink": "https://www.reddit.com" + box.xpath(".//p[@class='parent']/a[@class='title']/@href").get(),
"postAuthor": box.xpath(".//p[@class='parent']/a[contains(@class, 'author')]/text()").get(),
"postSubreddit": box.xpath("./@data-subreddit-prefixed").get(),
}
})
next_page_url = selector.xpath("//span[@class='next-button']/a/@href").get()
return {"data": data, "url": next_page_url}
async def scrape_user_comments(username: str, sort: Union["new", "top", "controversial"], max_pages: int = None) -> List[Dict]:
"""scrape user posts"""
url = f"https://old.reddit.com/user/{username}/comments/?sort={sort}"
# the same logic for sending requests and as profile posts
return post_datadef parse_user_comments(response: ScrapeApiResponse) -> List[Dict]:
"""parse user posts from user profiles"""
selector = response.selector
data = []
for box in selector.xpath("//div[@id='siteTable']/div[contains(@class, 'thing')]"):
author = box.xpath("./@data-author").get()
link = box.xpath("./@data-permalink").get()
dislikes = box.xpath(".//span[contains(@class, 'dislikes')]/@title").get()
upvotes = box.xpath(".//span[contains(@class, 'likes')]/@title").get()
downvotes = box.xpath(".//span[contains(@class, 'unvoted')]/@title").get()
data.append({
"authorId": box.xpath("./@data-author-fullname").get(),
"author": author,
"authorProfile": "https://www.reddit.com/user/" + author if author else None,
"commentId": box.xpath("./@data-fullname").get(),
"commentLink": "https://www.reddit.com" + link if link else None,
"commentBody": "".join(box.xpath(".//div[contains(@class, 'usertext-body')]/div/p/text()").getall()).replace("\n", ""),
"attachedCommentLinks": box.xpath(".//div[contains(@class, 'usertext-body')]/div/p/a/@href").getall(),
"publishingDate": box.xpath(".//time/@datetime").get(),
"dislikes": int(dislikes) if dislikes else None,
"upvotes": int(upvotes) if upvotes else None,
"downvotes": int(downvotes) if downvotes else None,
"replyTo": {
"postTitle": box.xpath(".//p[@class='parent']/a[@class='title']/text()").get(),
"postLink": "https://www.reddit.com" + box.xpath(".//p[@class='parent']/a[@class='title']/@href").get(),
"postAuthor": box.xpath(".//p[@class='parent']/a[contains(@class, 'author')]/text()").get(),
"postSubreddit": box.xpath("./@data-subreddit-prefixed").get(),
}
})
next_page_url = selector.xpath("//span[@class='next-button']/a/@href").get()
return {"data": data, "url": next_page_url}
async def scrape_user_comments(username: str, sort: Union["new", "top", "controversial"], max_pages: int = None) -> List[Dict]:
"""scrape user posts"""
url = f"https://old.reddit.com/user/{username}/comments/?sort={sort}"
# the same logic for sending requests and as profile posts
return post_dataRun the code
async def run():
user_comment_data = await scrape_user_comments(
username="Scrapfly",
sort="top",
max_pages=3
)
with open("user_comments.json", "w", encoding="utf-8") as file:
json.dump(user_comment_data, file, indent=2, ensure_ascii=False)
if __name__ == "__main__":
asyncio.run(run())Here is an example output of scraped Reddit data:
Example output
[
{
"authorId": "t2_saicgkn9",
"author": "Scrapfly",
"authorProfile": "https://www.reddit.com/user/Scrapfly",
"commentId": "t1_kzry9ar",
"commentLink": "https://www.reddit.com/r/webscraping//comments/1c4jd72/where_to_begin_web_scraping/kzry9ar/",
"commentBody": "You can check out our web scraping academy resource, (it's totally free and independent of our service), which has a visual roadmap and allows you to learn/dig branch by branch. I hope this helps!Also, the website in the resources link looks very neat",
"attachedCommentLinks": [
"https://scrapfly.io/academy",
"https://webscraping.fyi/"
],
"publishingDate": "2024-04-16T02:47:18+00:00",
"dislikes": 7,
"upvotes": 7,
"downvotes": 8,
"replyTo": {
"postTitle": "Where to begin Web Scraping",
"postLink": "https://www.reddit.com/r/webscraping//comments/1c4jd72/where_to_begin_web_scraping/",
"postAuthor": "RasenTing",
"postSubreddit": "r/webscraping"
}
},
....
]With this last snippet, our Reddit web scraping code is ready. Finally, let's explore a Reddit scraping tip!
Reddit Scraping Tip: JSON Suffix
Not only can we preview regular Reddit pages as the lightweight version using reddit.old, but we can also use it to get the page data as a full JSON dataset!
To use this tip, all we have to do is append the .json suffix to the old.reddit URL, such as https://old.reddit.com/user/Scrapfly/comments.json:
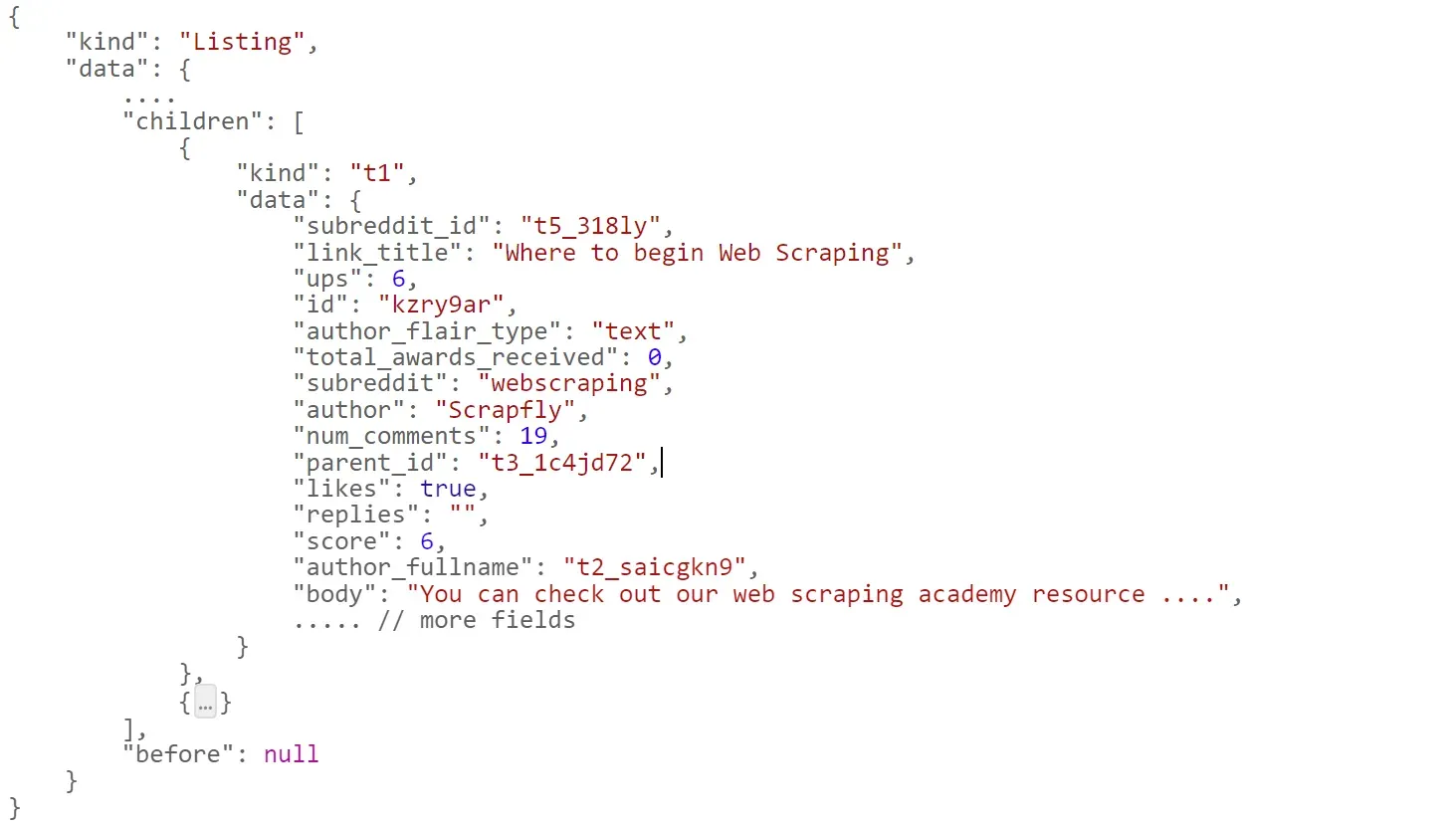
That being said, the JSON response of this approach is very comprehensive, and it can be challenging to filter. Hence, JSON parsing libraries like Introduction to Parsing JSON with Python JSONPath or Quick Intro to Parsing JSON with JMESPath in Python.
Powering Up with ScrapFly
Scraping Reddit is surprisingly straight-forward however such scraper projects can be difficult to scale up and this is where Scrapfly can lend a hand!

For example, here is how we can scrape Reddit without getting blocked using ScrapFly. All we have to do is replace the HTTP client with the ScrapFly client, enable the asp parameter, and select a proxy country:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some reddit.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="web page URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
proxy_pool="public_residential_pool", # select a proxy pool
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']Check out Scrapfly's web scraping API for all the details.
FAQ
Are there public APIs for Reddit?
Reddit provides subscription-based APIs. However, using Reddit's API for scraping isn't necessary as it can easily be scraped using parses or the .JSON suffix, which can be used to turn them into web scraper APIs.
Can I scrape Reddit for sentiment analysis?
Reddit contains a vast amount of text-based data covering various topics and interests. These data can be utilized for sentiment analysis to evaluate theories or train the model.
Are there alternatives for Reddit?
Yes. There are different social media targets available similar to Reddit, such as How to Scrape X.com (Twitter) in 2026, How to Scrape Instagram in 2026, and How to scrape Threads by Meta using Python (2026 Update). For more similar scraping targets, refer to our #scrapeguide blog tag.
Does Reddit block web scrapers?
Yes. Reddit employs rate limiting, CAPTCHAs, and IP-based blocking to prevent automated access. Using the .json suffix on old.reddit.com URLs is more reliable than scraping HTML directly, but you still need proper request headers and proxy rotation to avoid blocks at scale.
Summary
In this guide, we went through a step-by-step tutorial on how to create a Python Reddit web scraper for extracting data from:
- Subreddits details and their posts.
- Post pages for the post details and comments.
- Profile pages for post and comment data.
Finally, we have explored a Reddit scraping tip that allows for retrieving the JSON data representation of a web page by appending the .json prefix to old.reddit URLs.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


