

Websites use anti-scraping mechanisms to identify bot traffic and automated requests, such as web scrapers. Thus, the first step to scrape without getting blocked is identifying the web application firewall used.
In this guide, we'll answer a commonly asked question: "How do you know what anti-bot a website uses?". For this, we'll explore two tools to identify which WAF service is used. Additionally, we'll explore four factors that trigger anti-bot detection and how to optimize them for web scraping. Let's get started!
Key Takeaways
Master anti bot detection identification with advanced WAF analysis tools, fingerprinting techniques, and bypass strategies for comprehensive web scraping protection.
- Use WhatWaf and Wafw00f tools to identify Cloudflare, Datadome, and PerimeterX anti-bot services on target websites
- Implement HTTP tampering techniques and request modification to bypass WAF detection and blocking
- Configure proxy rotation and IP address distribution to avoid IP-based anti-bot detection
- Implement fingerprint management for User-Agent, headers, and browser identification to avoid detection
- Use specialized tools like ScrapFly for automated anti-bot bypass with advanced protection features
- Monitor anti-bot signatures and implement retry logic for handling detection and blocking scenarios
WhatWaf
WhatWaf is an open-source tool that identifies most of the existing WAFs on websites. Its workflow can be explained in three steps:- A request is sent to the target page to retrieve the response object.
- The returned HTML and response headers are analyzed to search for the common anti-bot signatures, such as the popular "attention required" message of Cloudflare.
- If the anti-bot service is detected, it uses a combination of "HTTP Tampering" techniques to attempt bypassing the WAF.
WhatWaf provides several features to configure the HTTP requests and organize the anti-bot identification process, including:
- Passing a file containing URLs to request.
- Customizing the request headers and payload.
- Adding proxies and using Tor to change the IP.
- Adding timeouts and rate-limiting throttlers.
How to Install WhatWaf
WhatWaf is built using Python. The easiest way to install and run it is using Linux. If you are on Windows, you can easily install Ubuntu from the Microsoft store or use WSL2.
The first step is ensuring that Python is installed:
python --version
# or
python3 --version
Most Linux systems have Python pre-installed. If it's not, use the following command to install it:
sudo apt-get install python3
Next, clone the WhatWaf repository for the source code and install the required packages:
git clone https://github.com/Ekultek/WhatWaf.git
cd whatwaf
sudo pip install -r requirements.txt
Now that our installation is complete, let's jump into the WhatWaf usage details.
How to Use WhatWaf
To start, let's explore the available WhatWaf features using the --help flag:
sudo ./whatwaf --help
You will get the below output:
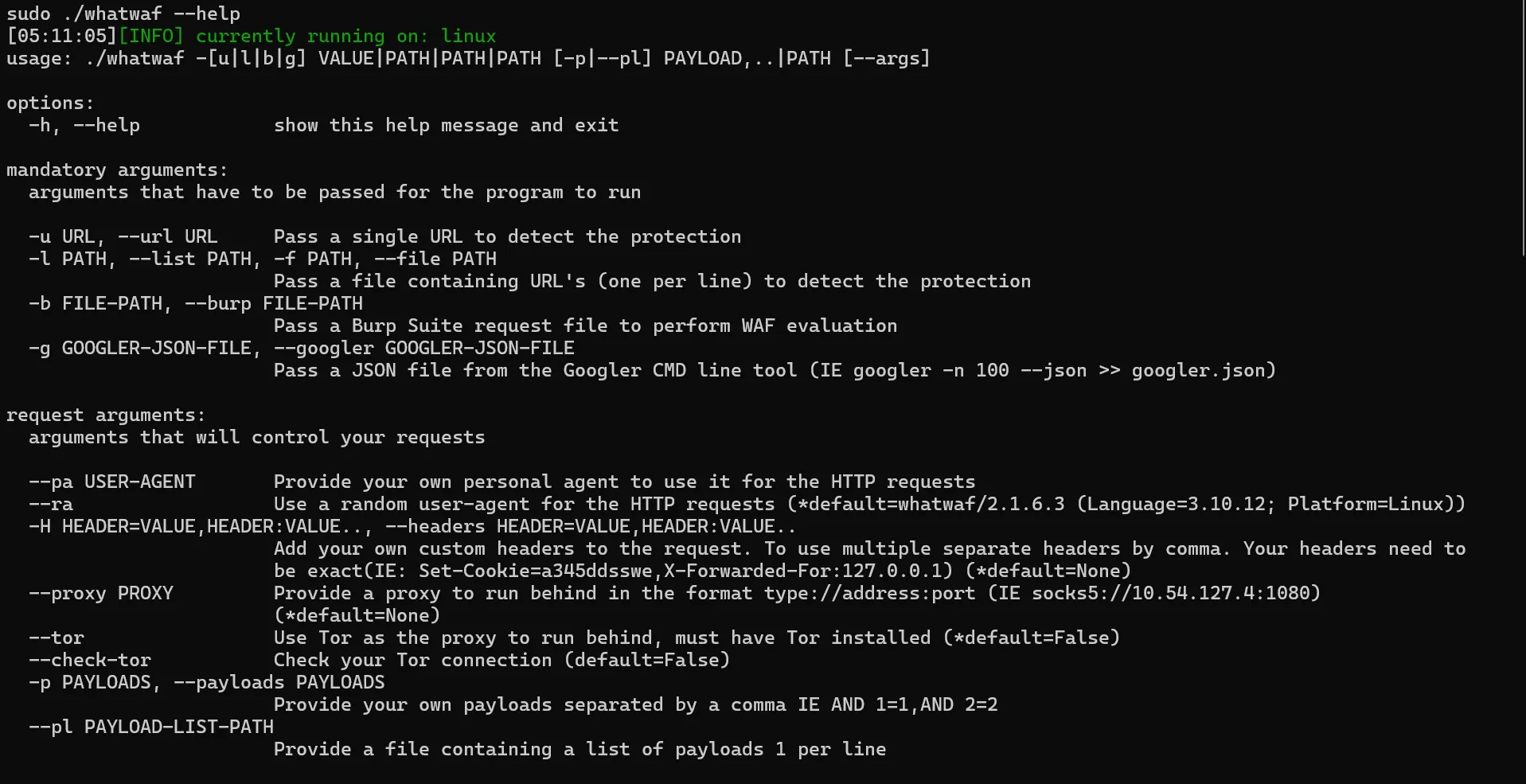
In the above image, we can see the mandatory arguments.
To request a web page, we can use the --url argument. Let's attempt to identify the anti-bot service used by Indeed.com:
sudo ./whatwaf --url https://indeed.com
Here is the result we got:
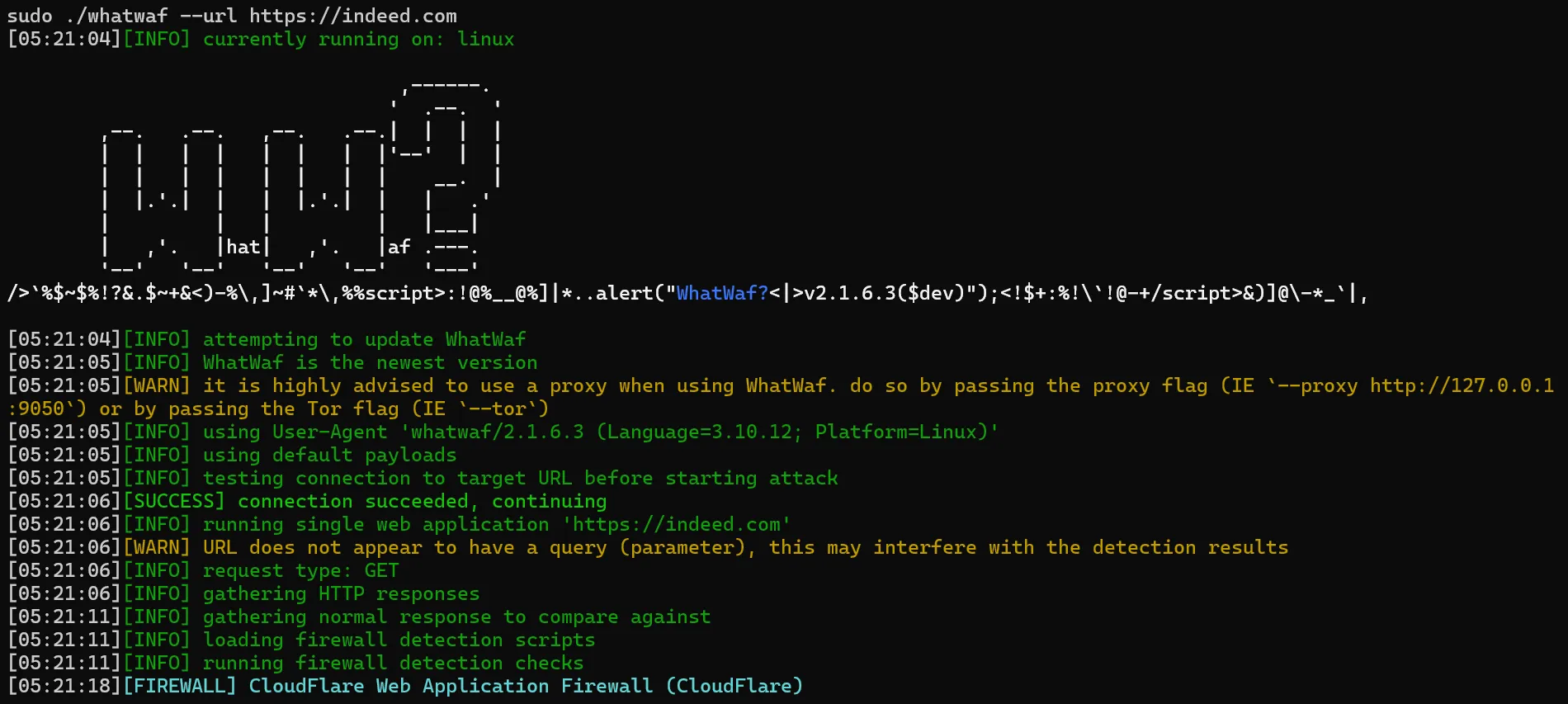
WhatWat has successfully identified Cloudflare as the protection service used. It also tried the tampering bypass checks scripts, but it failed with our target domain.
That being said, WhatWaf results aren't always accurate and shouldn't be taken for granted. For example, let's identify the WAF service used on Leboncoin.fr, which we know that it uses Datadome:
sudo ./whatwaf --url https://www.leboncoin.fr/recherche?category=9&real_estate_type=1
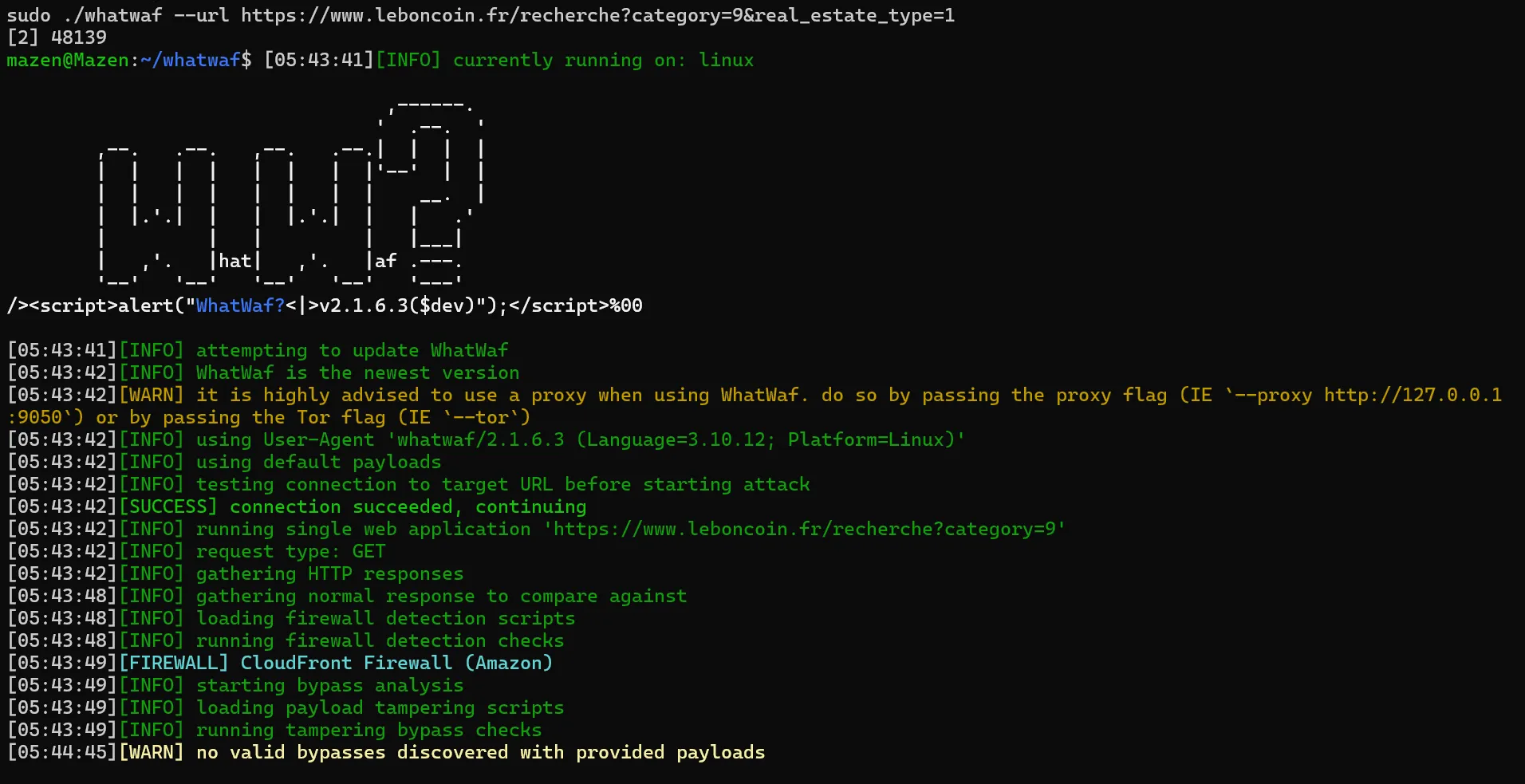
We can see that WhatWaf has incorrectly identified the protection service as CloudFront. Let's explore another tool to see if we get any better results!
Wafw00f
Wafw00f is another popular tool for identifying WAFs. Its technical concept can be briefly described by the following steps:- Sending a regular HTTP request to the target domain server.
- Analyzing the response object if the WAF protection is encountered.
- Sending multiple requests with potential malicious configurations to further trigger the WAF if it isn't encountered.
- Analyzing the previous responses using simple algorithms to guess the WAF service if it wasn't detected.
Unlike the WhatWaf tool we explored earlier, the Wafw00f tool doesn't provide additional utilities for bypassing the WAF services.
How to Install Wafw00f
To install Wafw00f, we have to clone its source code repository first:
git clone https://github.com/EnableSecurity/wafw00f.git
Next, move to the cloned directory and execute the setup.py file for installation:
cd wafw00f
python setup.py install
The Wafw00f installation is now complete. It can be used with the following command:
# Linux
wafw00f https://example.com/
# Windows
python main https://example.com/
How to Use Waf00f
To start, let's explore the available options using the wafw00f --help command:
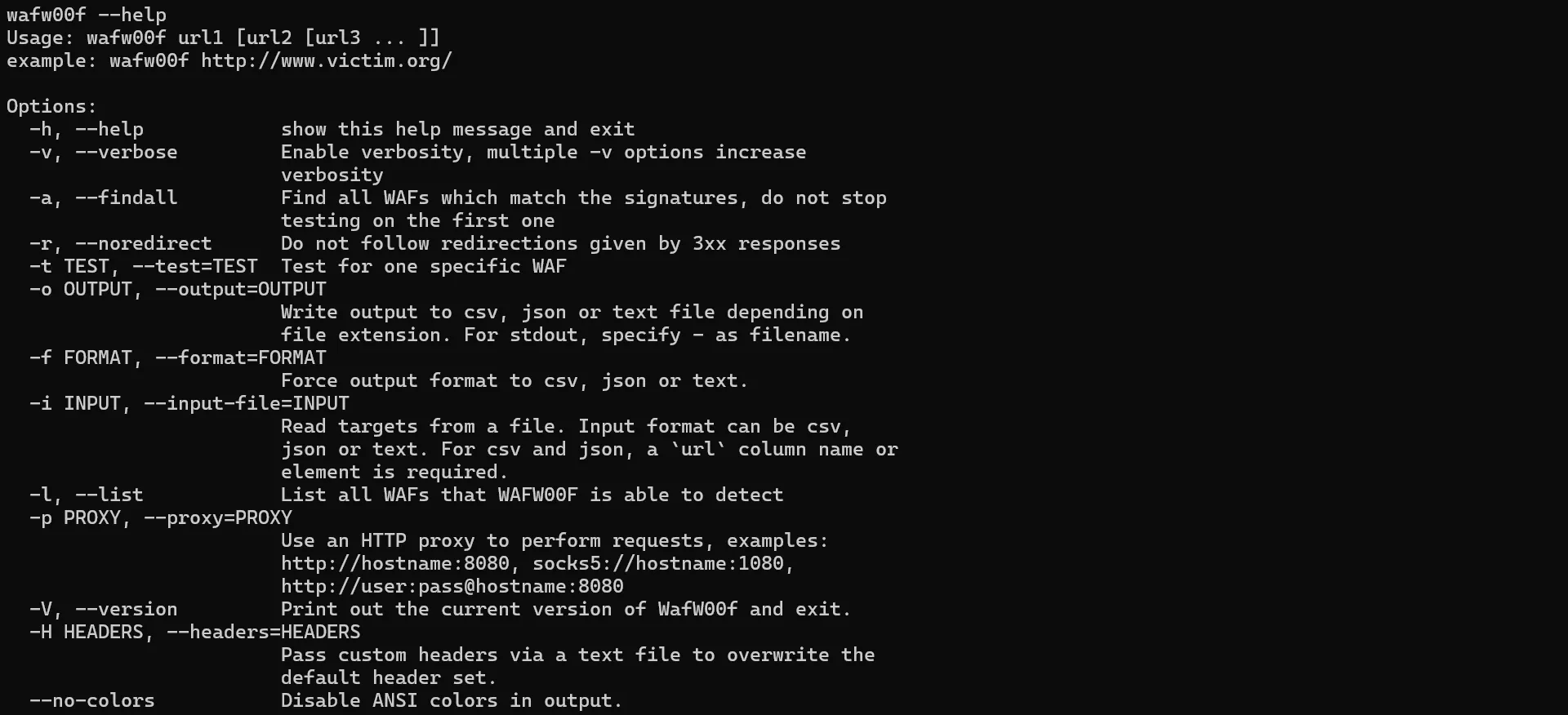
We can see that wafw00f comes with minimal features. In the web scraping context, we are interested in the following arguments:
--findall: To list all the detected firewalls on a given web page. It can prevent getting false results as websites can include multiple anti-bot services.
--noredirect: To disable request redirections, which can be useful as anti-bots can redirect the request to a different web page if it's detected.
--proxy: To change the request IP address using proxy servers if the domain is restricted to a specific geographical location.
Let's attempt to identify the protection services on the previously evaluated websites. All we have to do is pass the URL with the wafw00f command. We'll also use the --findall argument to list all the detected WAFs:
wafw00f https://indeed.com --findall
Here is the output we got:
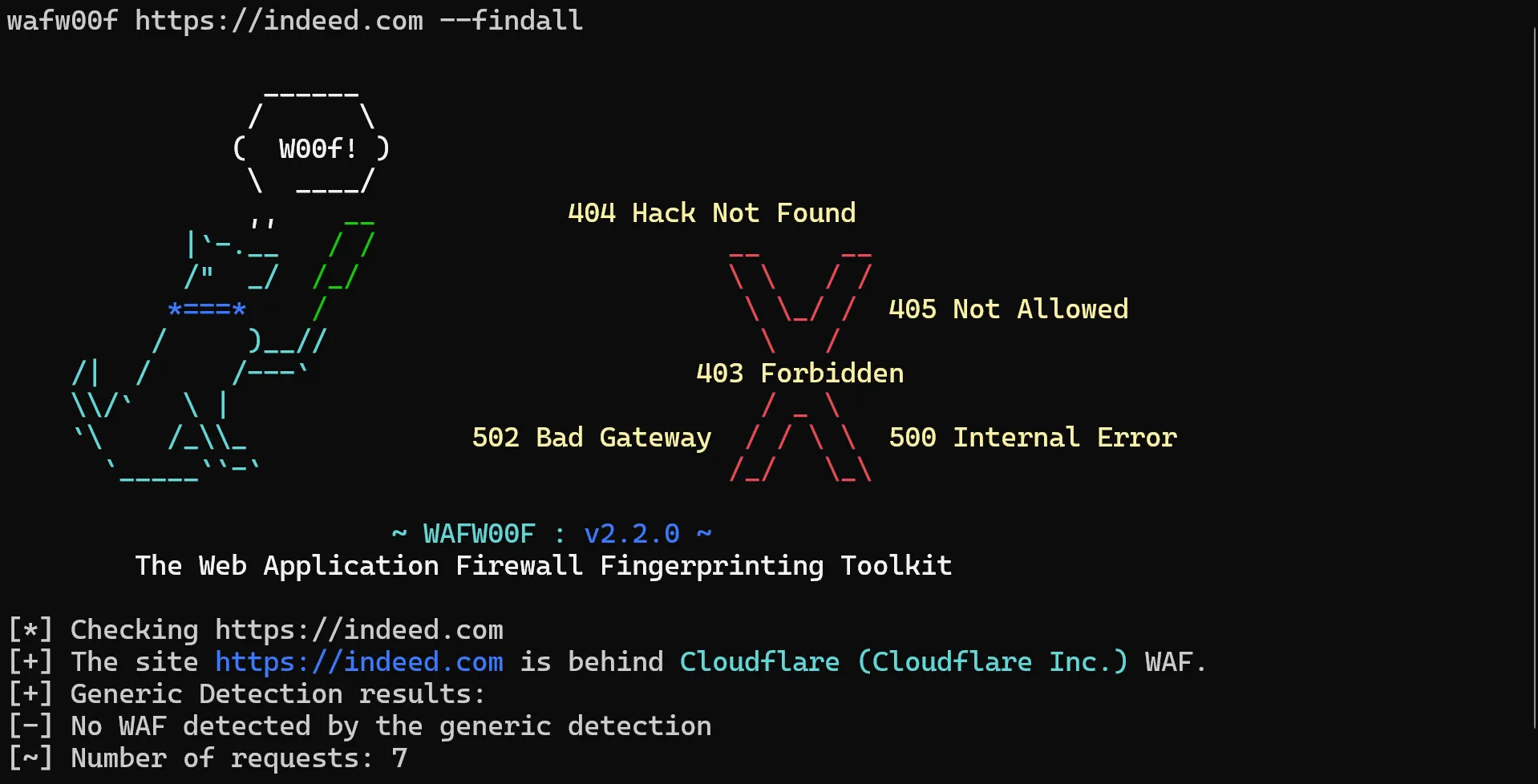
Wafw00f has correctly identified the WAF service used as Cloudflare.
Next, we'll request leboncoin.fr again to see if we get any better results than the previously failed example with WhatWaf:
wafw00f https://leboncoin.fr --findall
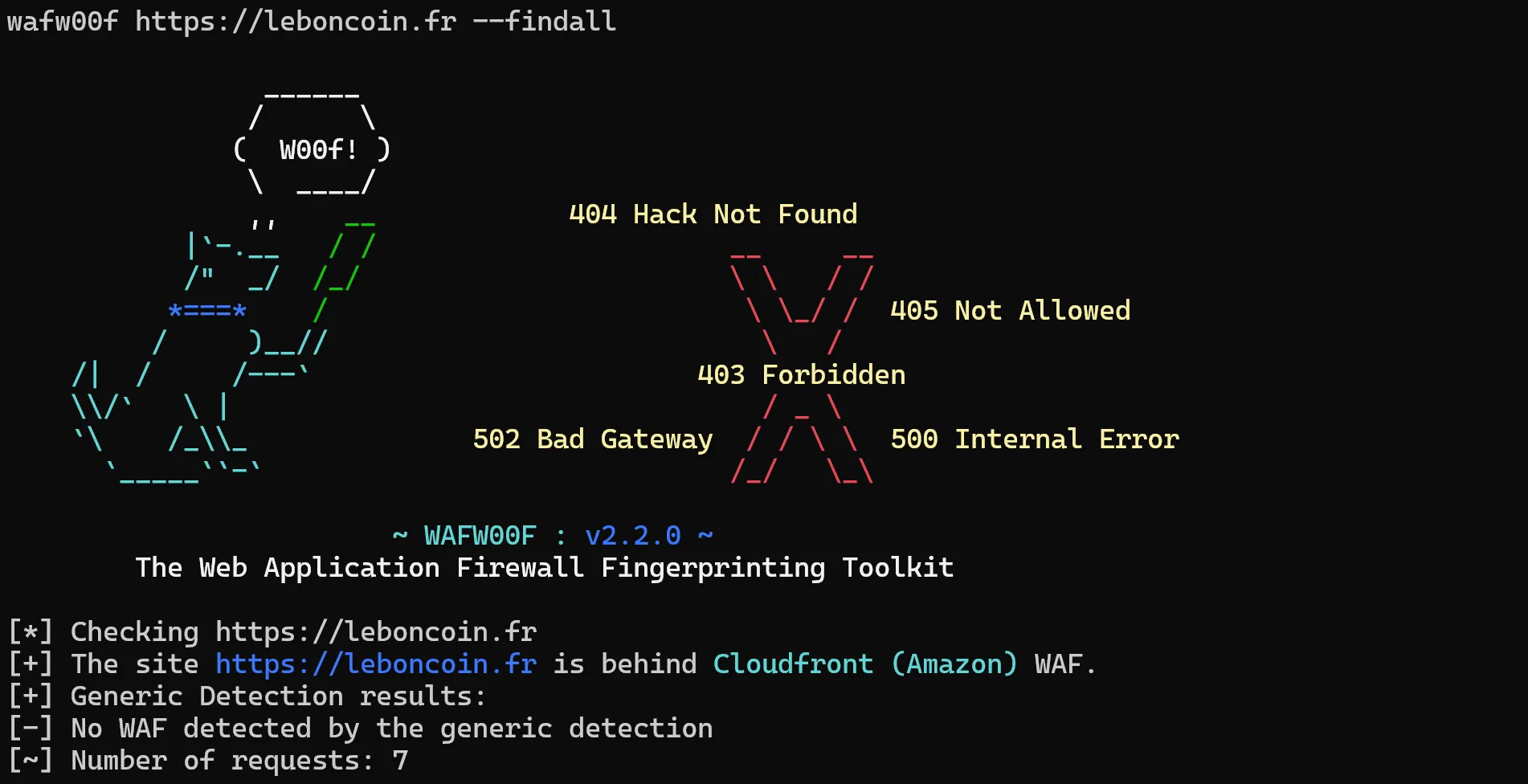
Again, the WAF service was incorrectly identified. From this, we can conclude that the most available tools for identifying WAFs aren't always accurate, and we have to put in extra manual effort.
How to Bypass Anti-Bot Services
In this section, we'll briefly explore how to bypass anti-bot services. Each of the below factors plays a significant role in calculating a trust score for the incoming traffic. Based on this score, the anti-bot decides on one of the below scenarios:
- Proceed to the final resource behind the protection.
- Request a CAPTCHA challenge.
- Block the request entirely.

TLS Fingerprint
When a request is sent to a domain using the HTTPS protocol, both the client and host have to negotiate the encrypting methods to initiate the connection challenge. This leads to creating a JA3 Fingerprint.
If this fingerprint is different from those of normal browsers. The request can be detected. Thus, having a resistant TLS fingerprint is essential to prevent detection.

IP Address
The IP address contains metadata about the request, such as reputation, location, and ISP, which are used as a part of the trust score calculation.
Moreover, anti-bot services count the number of requests sent from a particular IP address. If the requesting rate is high during a specific time interval, the IP address can be throttled or blocked.
Therefore, using high-quality residential or mobile proxies is essential to avoid IP address blocking of protection systems.

HTTP Details
The HTTP details, including headers and cookies, exchange essential information with the requested web server. These header values are managed automatically when navigating using web browsers. However, these values can be neglected when web scraping, resulting in requests that differ from those made by normal users. Hence, the requests get detected.
Another important aspect is the HTTP protocol. Most of the websites and web browsers currently operate over HTTP2, while many HTTP clients still use HTTP1.1. Hence, a request sent with the HTTP1.1 can provide an obvious sign of automation.
Hence, correctly managing and rotating headers, like the User-Agent, while using HTTP2 is important to mimic human traffic and prevent anti-bot systems identification.

JavaScript
JavaScript on the browser allows anti-bot services to gain several details about the connecting client, such as operating system, hardware specification, browser name and version. These values can be used to detect the usage of headless browser automation libraries, such as Selenium, Playwright, and Puppeteer. Since human users don't browse these libraries, requests get detected and blocked.
WAF services can also use automatically solvable JavaScript-based challenges before proceeding with the final resource. However, many web scraping requests are sent from HTTP clients without JavaScript support, leading to blocking.
Therefore, using headless browsers while hiding their traces using tools like Puppeteer-stealth and Undetected ChromeDriver can help bypass anti-bot blocking.

Based on the details explored, we can draw two conclusions.
- Available tools for identifying web application firewalls on websites aren't always accurate.
- Bypassing anti-bot mechanisms while scraping is complicated and requires paying attention to different details.
What about a tool that manages all this for us?
Bypass Anti-Bots With ScrapFly
ScrapFly is a web scraping API that automatically identifies and bypasses any anti-scraping protection. It also allows for scraping at scale by providing:

ScrapFly provides web scraping, screenshot, and extraction APIs for data collection at scale. Each product is equipped with an automatic bypass for any anti-bot system and we achieve this by:
- Maintaining a fleet of real, reinforced web browsers with real fingerprint profiles.
- Millions of self-healing proxies of the highest possible trust score.
- Constantly evolving and adapting to new anti-bot systems.
- We've been doing this publicly since 2020 with the best bypass on the market!
Here is how we can bypass anti-bot services using ScrapFly by simply sending an API request. All we have to do is enable the asp argument, select a proxy pool and country:
from scrapfly import ScrapeConfig, ScrapflyClient
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
proxy_pool="public_residential_pool", # select the residential proxy pool
country="US", # set the proxy location to a specfic country
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']
Learn more about Web Scraping API and how it works.
FAQ
To wrap up this guide, let's have a look at some frequently asked questions about identifying anti-bot services on websites.
Are there available tools for bypassing anti-bot services?
Yes, FlareSolverr is a popular tool for bypassing Cloudflare using Selenium while managing bypass sessions. Other modified headless browsers are Puppeteer-stealth and Undetected ChromeDriver, which don't easily get identified by WAF services.
Can I bypass anti-bot services?
Yes, there are different WAF services available, including Cloudlfare, Akami, Datadome, PerimeterX, Imperva Incapsula, and Kasada. However, they all function similarly, and the technical concepts described in this guide can also be applied to them.
Summary
In this guide, we explained how to know which anti-bot service a website uses. For this, we went through a step-by-step guide on installing and using two similar tools: WhatWaf and Wafw00f.
Then, we briefly explored how to bypass web application firewalls while scraping using four aspects. In a nutshell, these are:
- Using resistant TLS fingerprint.
- Using residential or mobile proxies to split the traffic across multiple IP addresses.
- Correctly managing and rotating request headers.
- Using modified headless browsers that are hard to detect, such as Puppeteer-stealth.
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.




