

Akamai Bot Manager is a popular web service that protects websites from bots, such as web scrapers. It's used by many popular websites including How to Scrape Amazon.com Product Data and Reviews, How to Scrape Ebay Using Python (2026 Update), Airbnb and many others.
Akamai is primarily known for using AI in their bot detection software but it's powered by traditional bot detection methods like fingerprinting and connection analysis. In 2026, TLS fingerprinting (JA3/JA4) has become Akamai's most effective detection vector, making tools like curl-cffi essential for impersonating real browser TLS signatures. This means that we can bypass Akami while web scraping by reverse engineering it.
In this article, we'll be taking a look at how to bypass Akamai Bot Manager and how to detect when a request has been blocked by Akamai. We'll also cover common Akamai errors and signs that indicate that requests have been blocked. Let's dive in!
Key Takeaways
Learn to bypass Akamai Bot Manager's AI-powered detection system by understanding fingerprinting techniques, implementing proper browser headers, and using residential proxies to avoid blocking.
- Identify Akamai blocks through HTTP status codes (403, 429) and "Pardon Our Interruption" error messages
- Bypass browser fingerprinting by mimicking real browser headers, TLS signatures, and connection patterns
- Use residential proxies with proper IP rotation to avoid geographical and reputation-based blocking
- Handle JavaScript challenges by implementing browser automation with undetected Chrome or Playwright
- Implement exponential backoff retry logic with 403 status code detection for rate limiting
- Use specialized tools like ScrapFly for automated Akamai bypassing with built-in anti-detection
What is Akamai Bot Manager?
Akamai offers a suite of web services and the Bot Manager service is used to determine whether connecting user is a human or an automated script. While it has a legitimate use of protecting websites from malicious bots, it also blocks web scrapers from accessing public data.
Akamai also provides a CDN used to deliver static content from a distributed network, adding additional security benefits to the websites. Next, let's take a look at some popular Akamai errors and how the whole thing works.
How to identify Akamai Block?
Most of the Akamai bot blocks result in HTTP status codes ranging from 400 to 500. Most commonly, status code 403 with the message "Pardon Our Interruption" or "Access Denied" is returned. However, Akamai can also trick bots by returning status code 200 with the same messages.
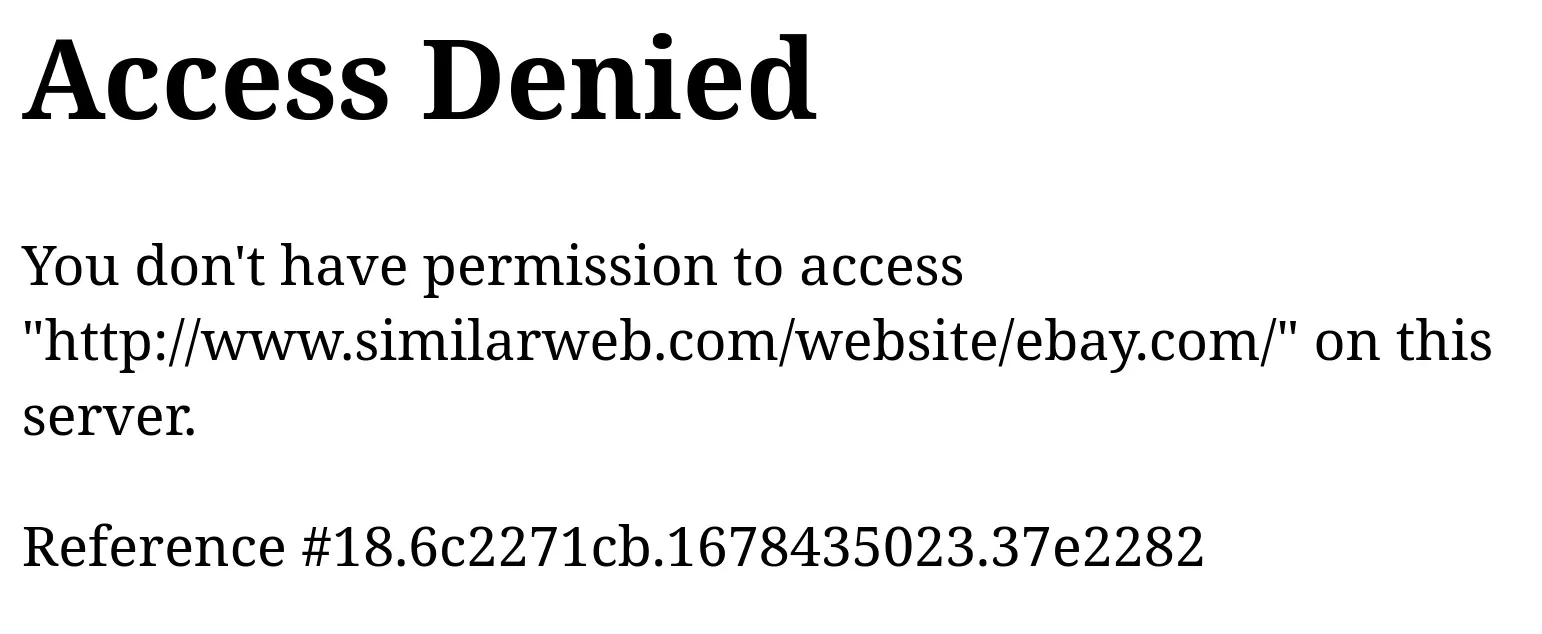
This error is mostly encountered on the first request, as Akamai can detect bots at the first stages of the connection. However, Akamai's AI behavior analysis can block connections at any point.
Let's have a closer look at how Akamai detects bots and web scrapers.
How Does Akamai Detect Web Scrapers?
Akamai Bot Manager uses various web technologies to determine whether the request sender is a human or a bot. Moreover, Akamai continuously tracks users' behavior to adjust the detection algorithm to create a trust score.

The trust score is calculated in many different stages. The final score is a weighted average of all the previous stages, determining whether the user can bypass Akamai.

This complex process makes web scraping difficult as developers have to manage multiple different factors to bypass Akamai. However, if we study each stage individually, we can see that bypassing Akamai is very much possible!
TLS Fingerprinting
TLS (or SSL) is the first step in the HTTP connection process. It's used in the end-to-end encryption of the HTTPS connections.
At first, both the client and server have to negotiate the encryption method. And since there are many different ciphers and encryption options, both parties have to agree on the same one. This is where TLS fingerprinting comes into play.
The previous TLS negotiations lead to creating a JA3 fingerprint. However, different computers, programs and even programming libraries have different TLS capabilities. Therefore, the fingerprint can vary from that of a regular browser.
So, if a web scraper is using a library with different TLS capabilities compared to a regular web browser it can be identified through this method.
To avoid being JA3 fingerprinted ensure that the libraries and tools used in HTTP connection are JA3 resistant. For that, see ScrapFly's JA3 fingerprint web tool that shows your fingerprint.
For more details, refer to our full introduction to TLS fingerprinting, which covers TLS fingerprinting in detail.
IP Address Fingerprinting
The next step in Akamai's detection is IP address analysis and fingerprint.
To start, there are a few different types of IP addresses:
- Residential are home addresses assigned by internet providers to average people. So, residential IP addresses provide a positive trust score as these are mostly used by humans and are expensive to acquire.
- Mobile addresses are assigned by mobile phone towers and mobile users. So, mobile IPs also provide a positive trust score as these are mostly used by humans. In addition, since mobile towers might share and recycle IP addresses it makes it much more difficult to rely on IP addresses for identification.
- Datacenter addresses are assigned to various data centers and server platforms like Amazon's AWS, Google Cloud etc. So, datacenter IPs provide a significant negative trust score as they are likely to be used by bots.
Using IP analysis, Akamai can determine whether the IP address is residential, mobile or datacenter. This is achieved by comparing the IP address to a database of known IP addresses and inspecting public IP provider details.
So, when a web scraper uses a datacenter IP, it can easily be identified as a bot since real users rarely browse from them. So, use high-quality residential or mobile proxies to avoid being blocked by Akamai at this stage.
Akamai can also detect the requests as coming from bots if the requesting rate is high through a narrow time window. Therefore, hiding your IP address by splitting the requests across different IPs can help avoid Akamai blocking while scraping.
For a more in-depth look, see our full introduction to IP blocking.
HTTP Details
The next trust score calculation stage is the HTTP connection itself. The HTTP protocol is becoming more complex. Hence, Akamai is using its complexity to detect bots.
To begin with, most of the modern web operates on HTTP2 and HTTP3 protocols, whereas many web scraping libraries still utilize HTTP1.1. Therefore, if a web scraper is using HTTP1.1, it's a clear giveaway that it is a bot.
While many newer HTTP libraries like cURL and How to Web Scrape with HTTPX and Python support HTTP2 it can still be detected by Akamai using HTTP2 fingerprinting. See ScrapFly's http2 fingerprint test page for more details.
HTTP request headers also play an important role. Akamai is looking for specific headers that are used by web browsers and not by web scrapers. So, ensuring that request headers and their order match that of a real web browser and context of the website is crucial for bypassing Akamai.
For example, headers like Origin, Referer can be used in some pages of the website but not in others. Other identity headers like User-Agent and encoding headers like Accept-Encoding can also be used to identify bots.
For more details, see our full introduction to request headers role in blocking
Javascript Fingerprinting
Finally, the most complex and challenging to bypass stage is the Javascript fingerprinting.
As the web server can execute arbitrary JavaScript code on the client's machine, it can be used to gather vast amounts of information about the connecting client, such as:
- Javascript engine details
- Harware details and capabilities
- Operating system information
- Web browser context information
The above data is combined together and then used to create a unique fingerprint for tracking users and identifying bots.
Fortunately, JavaScript is complex and takes time to execute. This limits practical Javascript fingerprinting techniques. In other words, not many users can wait 3 seconds for the page to load or tolerate false positive blocks.
For an in-depth look see our article on javacript use in web scraper detection.
To bypass Akamai's javascript fingerprinting we generally have two very different options.
The first one is to intercept and reverse engineer JavaScript behavior and feed Akamai with fake data. However, this is a very complex and time-consuming process as Akamai's tot team is constantly adjusting and changing its algorithm logic.
Alternatively, we can run a real web browser using browser automation libraries like Web Scraping with Selenium and Python, How to Web Scrape with Puppeteer and NodeJS in 2026 or Web Scraping with Playwright and Python that can start a real headless browser and navigate it for web scraping.
So, use browser automation libraries to bypass Akamai's javascript fingerprinting.
This approach can even be mixed with traditional HTTP libraries, as we can establish trust score using real web browser and switch session to HTTP library for faster scraping - this feature is also available using Scrapfly sessions.
Behavior Analysis
With all of the above methods bypassed, Akamai can still detect bots using behavior analysis. As Akamai is tracking all the actions that happen on the website, it can detect scrapers and bots by detecting abnormal behavior.
So, it's important to distribute web scraper traffic through multiple agents.
This is done by creating multiple profiles with proxies, header details and other settings. If browser automation is used then each profile should use a different browser version and configuration, such as the screen size.
How to Bypass Akamai Bot Management?
Now that we're familiar with all of the methods being used to detect bots we have a general understanding of how to bypass Akamai bot protection by avoiding all of these detection methods.
There are different approaches to this challenge, but to bypass Akamai in 2026, we can summarize the general approach as follows:
- Use high-quality residential or mobile proxies
- Use browser automation libraries to bypass Akamai's javascript fingerprinting
- Patch browser automation libraries with fingerprint resistance extensions, such as puppeteer-stealth.
- Distribute web scraper traffic through multiple profiles
Bypass Akamai with ScrapFly
Bypassing Akamai anti-bot while possible is very difficult - let Scrapfly do it for you!

It takes Scrapfly several full-time engineers to maintain this system, so you don't have to!
Learn more about Web Scraping API and how it works.
For example, to scrape pages protected by Akamai or any other anti-scraping service, when using ScrapFly SDK all we need to do is enable the Anti Scraping Protection bypass feature:
from scrapfly import ScrapflyClient, ScrapeConfig
scrapfly = ScrapflyClient(key="YOUR API KEY")
result = scrapfly.scrape(ScrapeConfig(
url="https://amazon.com/",
asp=True,
# we can also enable headless browsers to render web apps and javascript powered pages
render_js=True,
# and set proxies by country like Japan
country="JP",
# and proxy type like residential:
proxy_pool=ScrapeConfig.PUBLIC_RESIDENTIAL_POOL,
))
print(result.scrape_result)FAQ
Is it legal to scrape Akamai-protected pages?
Yes. Web scraping publicly available data is perfectly legal around the world as long as the scrapers do not cause damage to the website.
Is it possible to bypass Akamai using cache services?
Yes, public page caching services like Google Cache or Archive.org can be used to bypass Akamai protected pages as Google and Archive tend to be whitelisted. However, since caching takes time the cached page data is often outdated and not suitable for web scraping. Cached pages can also be missing parts of content that are loaded dynamically.
Is it possible to skip Akamai entirely and scrape the real website directly?
This threads closer to security research and it's not advised to partake when web scraping. While scraping and bypassing Akamai pages is perfectly legal abusing security flaws can be illegal in many countries.
What are some other anti-bot services?
There are many other anti-bot WAF services like How to Bypass Cloudflare When Web Scraping in 2026, How to Bypass PerimeterX when Web Scraping in 2026, How to Bypass Datadome Anti Scraping in 2026, Imperva Incapsula and How to Bypass Kasada Anti-Bot When Web Scraping in 2026. However, the technical concepts used are very similar to what is described in this tutorial and can be applied to them as well.
Akamai Bypass Summary
In this article, we've taken a look at how to bypass Akamai Bot Management when web scraping.
We've started by identifying all of the ways Akamai is using to develop a trust score for each new connection and the role of this score in web scraping. We've taken a look at each method and what can we do to bypass it.
Finally, we've looked at how to bypass Akamai using ScrapFly web scraping API and how to use ScrapFly to scrape Akamai-protected pages, so give it a shot for free!
Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens protected by GDPR.
- Do not repurpose entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow. For more you should consult a lawyer.


