

One of the major challenges in web scraping is scraper blocking and when it comes to web scraping images there are several unique ways image scrapers can get blocked.
In this guide, we'll take a look at the most common image scraping blocking causes and how to overcome them with Python.

Key Takeaways
Avoid image scraping blocking by using browser automation, proper headers, and proxy rotation to bypass TLS fingerprinting, IP reputation analysis, and request pattern detection.
- Use browser automation tools to avoid TLS fingerprinting and provide authentic browser behavior
- Implement proxy rotation to distribute requests across different IPs and avoid reputation analysis
- Configure proper headers including User-Agent strings and Accept headers to mimic real browsers
- Handle cookies and sessions to maintain consistent user behavior and avoid detection
- Control request patterns by managing timing, frequency, and sequence to appear human-like
Can Websites Block Image Scraping?
Image scraping is the process of parsing the HTML to scrape image URLs and downloading them using HTTP clients. We have covered image scraping in detail before.
Since image scraping involves sending HTTP requests, it's possible that websites block image scraping. However, the idea behind web scraping and image scraping blocking is almost the same. Which is comparing the web scraper connection configurations to normal web browsers.
In the following sections, we'll cover the key factors leading to image scraping blocking and how to overcome them.
Let's dive in!
Basic Request Details
Just like with any web scraping request basic request details can play a major role whether any HTTP requests succeeds or fails. These details include HTTP request headers, HTTP version, cookies and more.
So, the first step to avoid image scraping blocking is to make sure that the request details match expected values. The easiest way to handle this is to use Browser Developer Tools to inspect real traffic and mimic it in your web scraping code.
However, next lets take a look at some specific details that can lead to image scraping blocking.
TLS Fingerprinting
Transport Layer Security (TLS) is a protocol responsible for securing an HTTPS connection between a client and a web server. This allows encryption of all the data exchanged over the two-way connection. Though, before TLS can be used, both the client and the web server go through a process called TLS handshake which negotiates the security details.
During this negotiation handshake, both parties exchange essential information to establish a secure connection. Which are:
- TLS Versions The TLS version used in the client browser, mostly it's either 1.2 or 1.3.
- Cipher Suites List of encryption algorithms that both client and server support. It's ordered by priority and both parties agree on the first matching value.
- Enabled Extensions List of features that the client supports and some metadata like the server domain name.
The above values are combined together to create a JA3 fingerprint. Which is a token string separated by a - character:
771,6682-4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,56026-0-23-65281-10-11-35-16-5-13-18-51-45-43-27-17513-27242-21-41,31354-29-23-24,0Websites compare the request sender fingerprint with normal users to determine if this is a real human user or a bot blocking the latter.
That being said, maintaining a proper TLS fingerprint is quite complicated as you need to configure low-level device details. For more information on that, refer to our previous guide on TLS fingerprinting.
CDN Protection
Content Delivery Network (CDN) is a group of geographically disturbed data centers and proxy networks.
CDNs play a vital role in increasing websites' performance by delivering static content from the nearest geographic place to users. However, CDNs can be configured to restrict access to files and block image scraping using different methods like image request validation. Let's take a look at some popular techniques.
User-Agent Filtering
One of the essential headers for web scraping is the User-Agent header. It identifies the request sender device, which includes information about the device type, operating system, browser name and version.
CDNs look for this header value and may block requests without a User-Agent header. While throttling down user agents with unusual operating systems like Linux or unknown web browser versions.
To avoid image scraping blocking, consider rotating User-Agents while scraping images.

Request Rate Limiting
CDNs can also set limit rules for the amount of requests sent from a specific IP address. When an IP address exceeds this limit, the CDN can throttle down access or even block the IP address.
To prevent rate limiting from blocking image scraping, you need to rotate proxies to split the traffic between multiple IP addresses.

IP Reputation
IP addresses of requests used for web scraping usually have low trust scores. Most of the CDN providers have access to databases that include these types of IP addresses. And when the request IP address is recognized as part of these databases, the request may get blocked.

Residential proxies are assigned to real IP addresses of real users, they aren't often included in bot-tracking databases. Which can help avoid image scraping blocking.
Another great tip is to use the same IP addresses for HTML and image scraping as it can greatly reduce the chance of getting blocked.
Signed Image URLs
Singed image URLs provide a limited permission and time window to access a specific image. It contains authorization keys in the URL query. Which allows anyone with the URL to access it as long as the authorization key and the time period don't expire.
Signed image URLs have a structure similar to this:
https://domainname.com/image.png?X-Expires=900&X-SignHeader=header-name&X-Signature=signature-valueThe above image URL contains the image link with additional headers metadata, let's break them down:
X-Expires: The date and time this URL gets unusable, which follows the ISO date format.
X-SignHeader: The signature header, which must be included in order to validate the signature.
X-Signature: The actual authorization key used to access the image.png file.
In order to scrape these types of images without getting blocked, you must update the image URLs by scraping them from the web page.
CAPTCHA Chellenges
CAPTCHAs are a common anti-scraping challenge that is used to prevent bots from accessing web pages. Some of the most popular CAPTCHA providers are:
- How to Bypass Cloudflare When Web Scraping in 2026
- How to Bypass PerimeterX when Web Scraping in 2026
- How to Bypass Akamai when Web Scraping in 2026
- How to Bypass Datadome Anti Scraping in 2026
- Imperva Incapsula
While these are different types of CPATCHAs, they detect web scrapers in almost the same way:
- TLS fingerprinting A fingerprint that is created while exchanging TLS information during the TLS handshake.
- IP address fingerprinting Websites match the IP address of the request against an IP address database. And if the IP address belongs to a known proxy or datacenter service, it can be easily identified as a bot.
- HTTP details Websites search for request headers to determine if the request sender is a real user. Requests with missing headers are most likely to get blocked.
- Behavior analysis Websites analyze the request sender behavior to determine if this is a bot or not. These analyses include the number of requested pages, cursor moves and browsing profile.
Anti-bot providers use the above analysis to calculate a score for each analysis method. These scores are combined together to form a trust score. Which is used by websites to decide whether to proceed with the web page, request a challenge to solve or even block the request sender entirely.

For example, this petsathome.com website uses Cloudflare firewall which interferes with all sort of web scraping be it images or HTML content:
If we were to scrape this website using Python and the usual tools like httpx we can see that we get a "403 Forbidden" error:
import httpx
url = "https://media.petsathome.com/wcsstore/pah-cas01//300/P687L.jpg"
with open(f"image" +'.jpg', 'wb') as file:
response = httpx.get(url)
file.write(response.content)
print(response)
# <Response [403 Forbidden]>By opening this scraped image file, we can see that we got an invalid file error. This happened because we didn't get valid binary data. Instead, we got the Cloudflare captcha page:
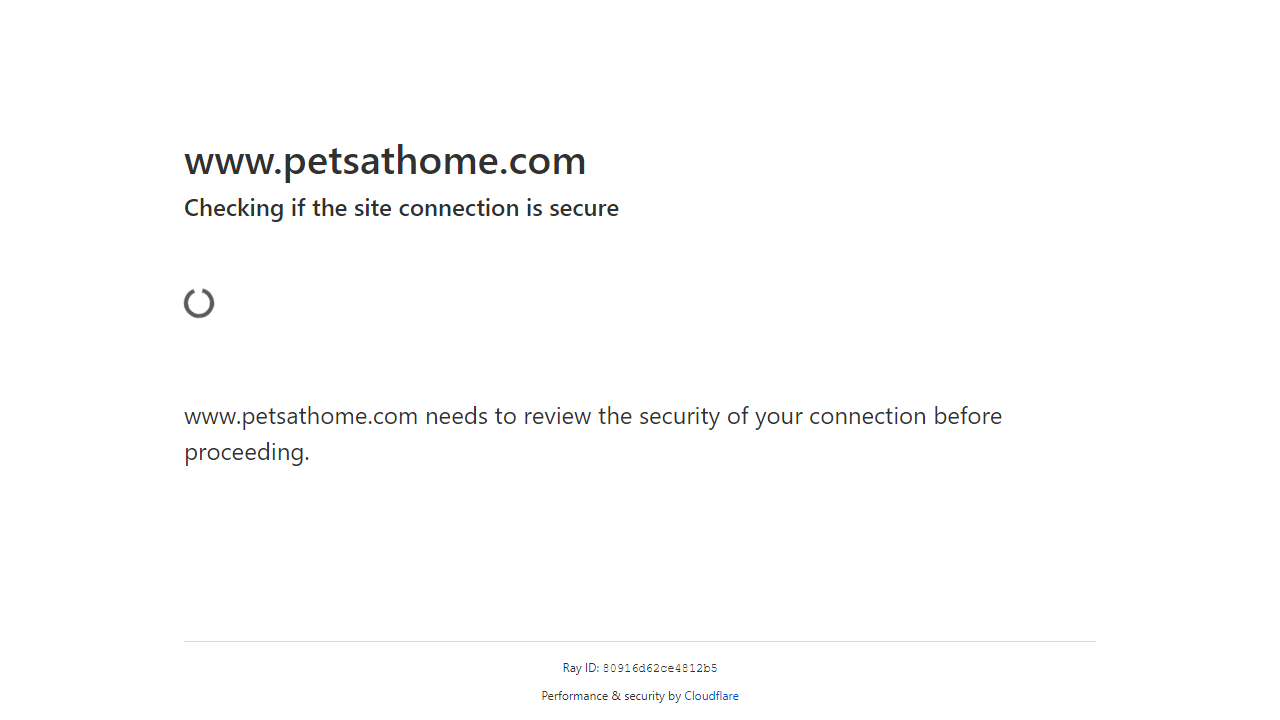
Bypassing the Cloudflare captcha challenge is possible but it's quite complicated. For that let's take a look at how Scrapfly can streamline this process next.
Avoid Image Scraping Blocking With ScrapFly
We have seen that image scraping blocking is a complicated topic with different aspects you need to pay attention to. This is why ScrapFly API was found, handling all anti-scraping logic so that you can focus on the web scraping process.

By using ScrapFly SDK with the previous example, we can easily avoid image scraping blocking and bypass Cloudflare:
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
scrapfly = ScrapflyClient(key="You API key")
scrape_config = ScrapeConfig(
url="https://media.petsathome.com/wcsstore/pah-cas01//300/P687L.jpg",
# Enable the anti scraping protection feature
asp=True,
)
api_response: ScrapeApiResponse = scrapfly.scrape(scrape_config)
# Download the image binary data
scrapfly.sink(api_response, name="image")
print(api_response.upstream_status_code)
# 200You can try to manage all image scraping blocking techniques yourself, or let ScrapFly do the heavy lifting for you. Sign up now for free!
FAQ
How do websites detect image scraping?
Websites compare web scraper connections and configurations with real web browsers controlled by real users. Through fingerprinting and complex analyses websites can have a rough estimation how likely the request sender is a bot or a real user. So, to scrape images without being blocked it's important to mimic a real user connection.
How to scrape images without getting blocked?
Websites use different methods to identify web scrapers from real human users. To avoid image scraping blocking, we need to mimic a real browser connection and configuration. This is possible by keeping an eye on the factors that identify web scrapers. Including TLS fingerprint, IP reputation, headers and cookies.
What Python tools can I use to scrape images from websites?
You can use HTTP clients like httpx combined with HTML parsers like BeautifulSoup to extract image URLs and download them. For dynamically loaded images, headless browsers like Playwright are needed. See our full tutorial on scraping images with Python for step-by-step examples.
Summary
In this article, we've covered how image scraping is being detected by websites. Image scraper detectors are usually analyze and compare web scraper image requests with real web browsers requests to determine the likelyhood of bot connections. In a nutshell, these techniques include:
- TLS fingerprinting.
- Searching through cookies and headers.
- IP reputation.
These methods allow websites to detect image scraping. Which leads to limiting requests, CAPTCHA challenges or even blocking.
We have seen that it's possible to scrape images without getting blocked. However, you need to pay attention to a lot of details as many attributes can lead to web scraping detection.


