

With the recent cloud computing developments, saving web scraped data locally is becoming an outdated data storage format. However, creating cloud pipelines and databases often seems like an overkill. So, what about a simple cloud data storage solution - scraping website data into Google Sheets!
In this guide, we'll explain how to automate Google Sheets using Python. We'll also go through a practical project example on storing web scraping data on Google Sheets. Let's get started!
Why Scrape Data to Google Sheets?
Google Sheets provides a centralized and collaborative data center. By scraping website data to Google Sheets, we ensure that all team members have accessible data, which enhances the data management process.
Google Sheets web scraping allows for real-time data updates. Instead of managing and manually updating data copies, we can automate scripts that refresh the data to always be up-to-date.
Another advantage of using Google Sheets for web scraping is the powerful analytics that comes with Google Sheets. We can leverage its built-in functions, charts and graphs to capture patterns and trends, improving decision-making.
Project Setup
In this web scraping with Google Sheets guide, we'll be using a few Python libraries:
httpxfor sending HTTP requests to the web pages.parselfor parsing the HTML using XPath and CSS selectors.gspreadfor connecting and manipulating Google Spreadsheets within Python.asynciofor running our scraping code asynchronously to increase our web scraping speed.
Note that asyncio comes pre-installed in Python, install the other libraries using the following pip command:
pip install httpx parsel gspread
Setting up Google Sheets For Web Scraping
Before we start web scraping into Google Sheets, we need to create a Google project on the cloud and configure the authentication settings.
First, go to the Google Developers Console, sign in with your Google account and create a new project:
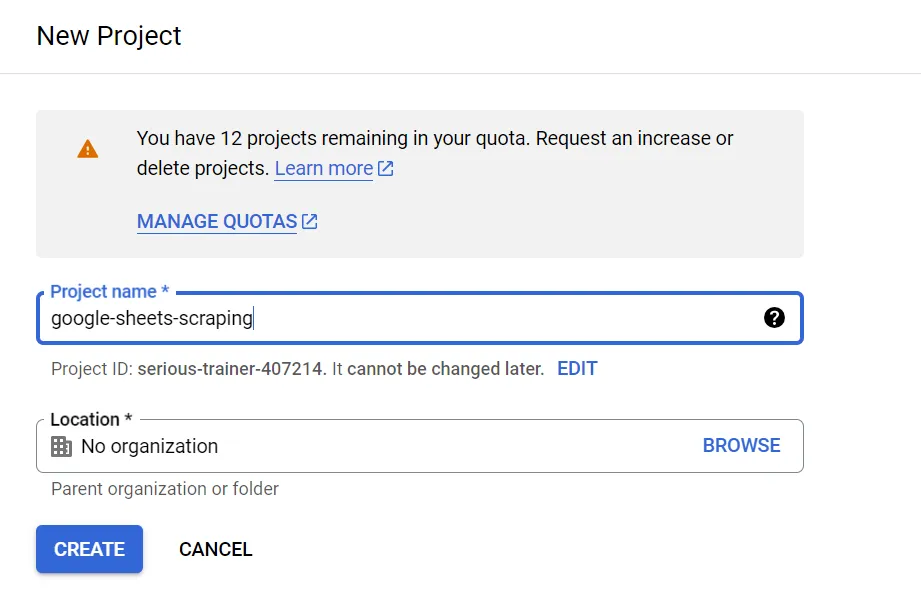
Since we'll use Google Sheets, we need to enable the Google Drive and Sheets APIs with our project. To do that, use the search box to search for them:

Then, click on each search result to enable the APIs:

The next step is to set up the project credentials, find the credentials section from the project dashboard, click on the create credentials button and choose service account:

By following the previous image instructions, you will be required to add a name for the service account. After adding it, it will create an email address with the same service account name:

Then, click on the service account email and choose the keys tab. It will redirect you to a page where you can create keys. Click on the add key button choose and create a new key:

It will then require you to choose either JSON or P12, choose the JSON type and click next. By doing that, the browser will download a JSON file with authentication details. The JSON file content should look like this:
{
"type": "service_account",
"project_id": "axial-paratext-407206",
"private_key_id": "4916f3eb54j579c2de23a8df446ce9a9f7910b64",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvQIBADABgkqhkiG9w0fdBQEFAASCKcwggSjAgEAAoIBAQCerWvjqBdLLr\nUgkCdIo2wW3pfgZAJtq/wQceWA/84+o9EsdS6gGrKTUH/02Fj/7rQ0AStNuygqsdBiY651YIgh7tWDLaJzK+0o5QOns8=\n-----END PRIVATE KEY-----\n",
"client_email": "web-scraping-to-google-sheets@third-runway-417014.iam.gserviceaccount.com",
"client_id": "103059696018695037298",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/scraping-google-sheets%40axial-paratext-407206.iam.gserviceaccount.com",
"universe_domain": "googleapis.com"
}
Rename the file you downloaded to auth.json and copy it to the directory where you will run the code.
Our configuration is finally complete and we are ready to web scrape into Google sheets. But first, let's take a look at how we can manipulate Google sheets with Python!
How to Automate Google Sheets Using Python
To scrape website data into Google Sheets, we need to interact with the spreadsheets using the Google Sheets API. However, we won't be using this API directly. Instead, we'll use a much simpler Python library that acts as a middleware - gspread. It supports authentication, reading, writing and updating spreadsheet cells.
The first step of using gspread is to add our authentication details. All we have to do is add our authentication JSON file we got earlier and create a new spreadsheet file:
import gspread
gc = gspread.service_account(filename="auth.json")
# create a new spreadsheet
sh = gc.create('web scraping sheet')
# share the spread with your Google accout email(the one you used for creating Google cloud project)
sh.share('Your Google account email', perm_type='user', role='writer')
print(sh.url)
"https://docs.google.com/spreadsheets/d/1cmtIch4iwzwxW_n08pi4BDoo37JYAILEtUYQSlhFS8A"
The previous code will create a new spreadsheet in your Google account. We also used the .url method to get the spreadsheet URL, which we can use to view
the spreadsheet file in the browser.
We can also open an existing spreadsheet file using the name, ID or even URL:
import gspread
gc = gspread.service_account(filename="auth.json")
# open an existing spreadsheet using differet methods
sh = gc.open("web scraping sheet")
sh = gc.open_by_key("1cmtIch4iwzwxW_n08pi4BDoo37JYAILEtUYQSlhFS8A")
sh = gc.open_by_url("https://docs.google.com/spreadsheets/d/1cmtIch4iwzwxW_n08pi4BDoo37JYAILEtUYQSlhFS8A/")
print(sh)
"<Spreadsheet 'web scraping sheet' id:1cmtIch4iwzwxW_n08pi4BDoo37JYAILEtUYQSlhFS8A>"
Now that we know how to create and open spreadsheets, let's practise scraping with Google Sheets by writing some data.
To write data into spreadsheets, we have to use the update() method which will add new data to cells if they are empty or update their values if not. We can update cells by explicitly declaring the cells' names, range or by appending a whole list as a row:
import gspread
import warnings
# disable gspread migration warnings
warnings.filterwarnings("ignore")
gc = gspread.service_account(filename="auth.json")
# open the spreadsheet file and select a work sheet page(sheet1)
wk = gc.open("web scraping sheet").sheet1
# update cells by their names
wk.update("A1", "update")
wk.update("B1", "specific")
wk.update("C1", "cells")
# update cells by appending list
wk.append_row(["update", "cells by", "appending rows"])
# update a range of cells
wk.update(range_name="A3:C3", values=[["update a","range of", "cells"]])
Above, we can update the spreadsheet data by specifying columns, rows or cell names.
To retrieve the data however, we'll use the get_values() method to get all the non-empty fields in the spreadsheet as a list of rows:
import gspread
gc = gspread.service_account(filename="auth.json")
# open the spreadsheet file and select a work sheet page(sheet1)
wk = gc.open("web scraping sheet").sheet1
# get all the non-empty fields as a list of lists
list_of_lists = wk.get_values()
print(list_of_lists)
"[['update', 'specific', 'cells'], ['update', 'cells by', 'appending rows'], ['update a', 'range of', 'cells']]"
These are the essential functions when it comes to Google Sheet manipulation. Additionally, gspread also offers other core features like deleting, formatting, searching, and integrating with data frames like Pandas and Numpy. See the official gspread docs for more details.
Next, let's take a look at all of this comes together in web scraping.
Scraping Website to Google Sheets Project
In this section, we'll go over a practical example of web scraping to Google Sheets by scraping HTML data, parsing it using CSS selectors and saving end result into a spreadsheet.
We'll use the product pages on web-scraping.dev as our target website:

We will begin by sending HTTP requests to the target website and parsing the HTML to extract the products' data:
import gspread
import asyncio
import json
from httpx import AsyncClient, Response
from parsel import Selector
from typing import Dict, List
# 1. Create HTTP client with headers that look like a real web browser
client = AsyncClient(
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
}
)
def parse_data(response: Response):
"""parse product data from the HTML"""
selector = Selector(response.text)
data = []
for product in selector.css(".row.product"):
data.append({
"name": product.css("h3 a::text").get(),
"description": product.css(".short-description::text").get(),
"price": product.css(".price::text").get()
})
return data
async def scrape_data(url: str):
"""scrape product pages"""
response = await client.get(url)
data = parse_data(response)
# crawl over product pages
for page_number in range(2, 6):
response = await client.get(url + f"?page={page_number}")
data.extend(parse_data(response))
return data
if __name__ == "__main__":
data = asyncio.run(scrape_data(url="https://web-scraping.dev/products"))
# print the result in JSON format
print(json.dumps(data, indent=2))
In the above code, we create an async httpx client with basic headers and define two functions:
parse_data()for parsing the page HTML to extract each product data.scrape_data()for crawling over product pages by requesting each page.
Here is a sample of the data we got:
[
{
"name": "Box of Chocolate Candy",
"description": "Indulge your sweet tooth with our Box of Chocolate Candy. Each box contains an assortment of rich, flavorful chocolates with a smooth, creamy filling. Choose from a variety of flavors including zesty orange and sweet cherry. Whether you're looking for the perfect gift or just want to treat yourself, our Box of Chocolate Candy is sure to satisfy.",
"price": "24.99"
},
{
"name": "Dark Red Energy Potion",
"description": "Unleash the power within with our 'Dark Red Potion', an energy drink as intense as the games you play. Its deep red color and bold cherry cola flavor are as inviting as they are invigorating. Bring out the best in your gaming performance, and unlock your full potential.",
"price": "4.99"
},
{
"name": "Teal Energy Potion",
"description": "Experience a surge of vitality with our 'Teal Potion', an exceptional energy drink designed for the gaming community. With its intriguing teal color and a flavor that keeps you asking for more, this potion is your best companion during those long gaming nights. Every sip is an adventure - let the quest begin!",
"price": "4.99"
}
]
The next step is to save the scraped data into Google Sheets. We'll use gspread again and use the append_row() method to add each result as a product row:
import gspread
import asyncio
import json
from httpx import AsyncClient, Response
from parsel import Selector
from typing import Dict, List
# the previous code of our web-scraping.dev scraper
def scrape_data(url):
...
def save_to_sheet(data: List[Dict]):
"""save the result data into Google sheets"""
gc = gspread.service_account(filename="auth.json")
# create a new spreadsheet
sh = gc.create('web scraping data sheet')
sh.share('Your Google account email', perm_type='user', role='writer')
# open the spreadsheet file and select a work sheet page(sheet1)
wk = gc.open("web scraping data sheet").sheet1
# write sheet columns names
wk.append_row(["name", "description", "price"])
# write each product as rows:
for product in data:
wk.append_row([product["name"], product["description"], product["price"]])
print(f"Data saved into the spreadsheet: ({wk.url})")
if __name__ == "__main__":
data = asyncio.run(scrape_data(url="https://web-scraping.dev/products"))
# save the data into the spreadsheet
save_to_sheet(data)
"Data saved into the spreadsheet: (https://docs.google.com/spreadsheets/d/1cmtIch4iwzwxW_n08pi4BDoo37JYAILEtUYQSlhFS8A#gid=0)"
Here, we define a new save_to_sheet() function that does the following:
- Create and share a new spreadsheet file with our Google account.
- Open a sheet page in the spreadsheet file.
- Write the column names at the top of the sheet.
- Iterate over the products in the list we got and write each product data as a row in the sheet.
If we take a look at the spreadsheet file we created, we'll find all the data written there:

Cool! With a few lines of code, we were able to scrape website data into Google Sheets!
FAQ
To wrap up this guide, let's take a look at some frequently asked questions about web scraping to Google Sheets.
Can I use Google Sheets as a database for web scraping?
Yes, by creating a Google Cloud project and setting up the authorization for Google Sheets. You can use the Google Sheets API to web scrape into Google Sheets and use it as a database.
How much data can I scrape to Google Sheets?
Google Sheets provides generous data storage, where each sheet can store up to 10 million cells.
What is the gspread.exceptions.APIError:403?
This error code indicates that some authorization settings are missing or invalid. You need to check your authentication keys and ensure you enable the Google Drive and Sheets APIs with your Google project. Refer to the official gspread exception docs for more details.
Web Scraping to Google Sheets Summary
Google Sheets is a powerful cloud data storage that can be used for storing tabular data. In this article, we explained how to connect and automate Google Sheets with Python.
We also went through a step-by-step guide on how to web scrape data into Google Sheets. In a nutshell, these steps include:
- Creating a project and Google Cloud and enabling the Drive and Sheets APIs.
- Creating a service account authentication key as a JSON file.
- Using the authorization file to access the spreadsheets within Python scripts.
- Storing web scraping into Google Sheets by appending the data we scrape as rows.




